基于訪問控制模塊與原始信息注入的圖像描述①
2022-08-04 09:58:26郝宇欽韋學艷吳春雷
計算機系統應用 2022年7期
李 陽,路 靜,郝宇欽,韋學艷,吳春雷
(中國石油大學(華東)計算機科學與技術學院,青島 266580)
1 引言
計算機根據給定的圖像自動生成簡短的描述圖像的句子,這個任務被稱為圖像描述[1]. 在當前的計算機視覺領域中,圖像描述融合了機器學習、計算機視覺等多個不同領域,是一項具有挑戰性的任務. 主流的圖像字幕模型大多數采用卷積神經網絡(CNN)獲取圖像視覺特征,并對顯著區域和對象施加注意力,通過遞歸模型生成描述. 隨著對圖像描述任務的研究逐漸增多,圖像的場景圖被用來增強圖像描述模型,從而利用場景圖的結構語義,如對象、關系和屬性. 然而當前基于場景圖的圖像描述模型并未考慮到長短期記憶神經網絡(LSTM)[2]對于先前輸入信息的保留,這可能會導致丟失細節信息. 原始輸入信息中的細節能夠指導句子的生成,因為對于模型生成的句子,其中每個單詞的生成都要依賴于輸入信息,假如丟失了先前的原始輸入信息,則很難生成準確的句子. 此外,當前的場景圖更新機制中存在結點更新程度過大的問題,導致生成句子的準確度降低.
為了在一定程度上解決丟失原始信息和圖更新程度過大的問題,本文提出了基于訪問控制模塊與原始信息注入的圖像描述網絡,該網絡改進了基線模型的圖更新機制及語言LSTM 中的輸入信息,目的是使圖更新程度的大小更合理,并減少原始信息的細節損失. 首先,每張圖像對應一個場景圖信息,網絡對場景圖進行編碼,對編碼后的場景圖特征施加注意力,網絡將得到的上下文特征傳遞給雙層LSTM 進行解碼,其中將原始信息注入到語言LSTM 中,最后通過訪問控制模塊將已訪問過的結點權重降低,既可以使網絡關注未關注過的結點,又盡可能保留結點的內容信息.
本文中,創新點可以總結歸納為如下3 點:
(1)本文對基線模型中語言LSTM 的輸入變量做了改進,將原始特征與經過注意力LSTM 所得的特征拼接后得到新特征作為語言LSTM 的輸入,以充分利用全局圖像信息和嵌入信息來生成句子.
(2)本文設計了一種新的訪問控制模塊(VCM)來實現圖更新機制,改進了現有的基于場景圖的圖更新方法,它可以使網絡關注重要信息的同時盡可能保留原始結點的信息,我們設計了圖更新系數(GUF)來指導圖更新,以確定更新程度的大小.
(3)通過大量實驗對提出的模型進行了分析與驗證. MSCOCO 數據集上的實驗結果表明了所提出的基于訪問控制模塊與原始信息注入的圖像描述方法的有效性.
2 相關工作
2.1 圖像描述
隨著深度學習技術的發展,在圖像描述領域中,對于神經網絡的編碼器-解碼器框架的研究越來越多,近年來已經取得了顯著的改進. Vinyals 等人[3]采用卷積神經網絡(CNN)將圖像視覺信息編碼為固定長度向量,遞歸神經網絡(RNN)作為解碼器,依次生成單詞.為了更有效地關注圖像中重要的區域,注意力機制在圖像描述模型中被廣泛使用[4],在生成描述過程中,模型生成的所有的單詞都和圖像的某一特定區域一一對應. 由于傳統的注意力機制存在強制將每個單詞都對應到圖像某一區域的問題,Lu 等人[5]提出了一種自適應注意力機制,在模型生成單詞時判斷是否需要關注圖像信息及關注的程度. 此外,為了減少順序訓練[6]中的暴露偏差問題,Rennie 等人[7]使用強化學習減少累計誤差和優化不可微函數. 目前大部分圖像描述任務都是基于編碼器-解碼器框架結構,但解碼器對于輸入到LSTM 中的信息經過多次計算后可能會丟失部分原始輸入信息,那么如何在LSTM 中充分利用原始輸入信息,是一個值得思考的問題.
2.2 場景圖
當前,最流行的圖像特征提取方法是使用Faster R-CNN[8]獲取特征,在自下而上的注意力模型[9]中采用的就是此方法. 根據觀察習慣,人類視覺往往不是將圖像分割為多個區域來觀察的,而是針對圖像中較明顯的物體來獲取信息,但僅關注物體信息會忽略多個物體之間的關聯. 因此,有研究進一步探索了一種在圖像描述研究中更結構化的圖像表示,即場景圖[10–12],場景圖的引入有效地促進了圖像描述的發展,它可以在圖像描述任務中利用檢測到的對象及其關系,獲得對圖像更有條理的表述.
場景圖顯式地描述了圖像中物體以及它們互相具有的關系. 場景圖生成任務是建立在目標檢測[13]的基礎上,當前的一些研究介紹了場景圖生成(SGG)[14,15].大多數模型使用預先訓練的Faster R-CNN 或類似的體系結構來預測對象,在此基礎上加入一個額外的組件來預測對象之間的關系. Zellers 等人[16]提出完成場景圖生成任務可以利用很多先驗知識. 在使用場景圖生成描述的研究中,Chen 等人[17]提出了一個圖更新模塊,在每一步解碼后更新當前的圖,改變圖結點的權重以保證結點不被重復使用,但是改變權重的方式容易丟失有效的信息,那么如何在更新過程中保持刪除信息和保留信息的平衡,是一個值得思考的問題. 因此,本文設計了一個訪問控制模塊更新已訪問過的結點權重,有效解決了結點內容丟失的問題.
3 基于訪問控制模塊與原始信息注入的圖像描述網絡
3.1 整體框架
給定一個輸入圖像I,本文采用文獻[17]的方法來獲得場景圖特征G=(V,E).G表示圖像的場景圖特征,是一個有向圖,V表示圖像I中檢測到的對象對應的結點集,包含物體結點和關系結點,E表示對應于結點之間連接的邊集,表示兩個結點之間有連接,模型最終生成一組句子. 整個網絡架構如圖1 所示.

圖1 網絡架構
具體來說,本文的模型首先使用圖卷積網絡集成G中的信息得到Gm. 本文采用文獻[17]的圖注意力方法將圖內容注意力和圖流向注意力融合得到集成上下文信息. 然后將得到的集成上下文信息饋入解碼器進行字幕生成. 解碼器包括兩層LSTM 結構,分別用來處理注意力信息和單詞信息. 并且本文對基線模型中語言LSTM 的輸入變量做了改進,以充分利用全局圖像信息和嵌入信息,在第3.2 節將詳細介紹. 最后,在生成單詞yt后,本文通過訪問控制模塊將結點嵌入Xt的權重更新,并根據本文提出的圖更新系數作為調整結點權重的依據,使下一時間步的結點Xt+1權重更為合理,本文將在第3.3 節詳細介紹.
3.2 原始信息注入
本文解碼器采用兩層LSTM 結構,如圖2 所示. 其中,注意力LSTM 表示視覺注意LSTM,作用是整合視覺信息以及隱藏層信息,并將自身計算得到的隱藏層信息作為模型注意力機制的一部分輸入; 語言LSTM表示用來生成語言的 LSTM,實現順序地預測單詞生成的功能.
全部患者接受護理之后,共有65例順利的度過了圍手術期,有5例患者在治療階段有并發癥產生,經過護理人員針對性的積極的護理,患者均痊愈,全部患者順利康復出院。

圖2 LSTM 模型圖
本文認為全局圖像編碼嵌入和單詞嵌入不僅可以指導注意力LSTM 整合當前信息,而且對于指導語言LSTM 生成單詞也是有價值的,因此將全局圖像編碼嵌入、已生成的單詞嵌入wt–1注入到語言LSTM 中,充分利用視覺信息和單詞嵌入信息指導句子的生成,模型如圖2 所示.
注意力LSTM 在每個時間步中會接收輸入圖像的特征編碼嵌入、詞嵌入向量以及之前時間步的信息,注意力L STM 將以上輸入的信息進行整合得到LSTM 的隱藏狀態,然后將輸出的隱藏層信息作為注意力機制輸入的一部分,計算得到上下文特征. 最后,計算得出的上下文信息和注意力LSTM 的隱藏狀態一起作為模型語言LSTM 的輸入. 另外,本文模型為了充分利用原始信息,將全局圖像編碼嵌入、已生成的單詞嵌入wt–1與經過注意力LSTM 所得的特征拼接后得到新特征作為語言LSTM 的輸入,得到語言LSTM 的輸出. 最后,在t時刻要生成的單詞yt由模型利用語言LSTM 的隱藏狀態預測得到,具體公式如式(1)–式(3):其中,是語言LSTM 前一時刻的輸出,是注意力LSTM 前一時刻的輸出,Attn為注意力操作,上下文向量zt經過Attn操作后得到.wt–1是已生成單詞的嵌入,是全局編碼嵌入,Wu是參數. 在時間步長t處單詞分布的概率如下:
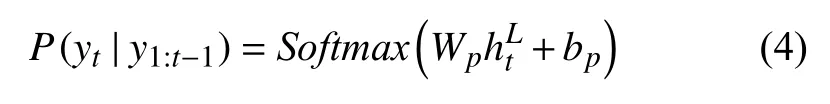

其中,Wp是學習權重,bp是偏差. 句子概率分布計算公式如下:
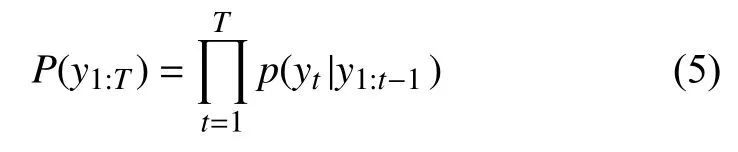
3.3 訪問控制模塊
為了充分表達場景圖中的信息,必須在不丟失且不重復的情況下表達場景圖G中的所有結點,本文結合了文獻[17]的圖更新機制,在每一時間步生成單詞yt后,將t時刻的結點嵌入Xt重新賦予權重,更新為下一時刻使用的Xt+1,即更新結點的訪問狀態,如圖3所示.

圖3 圖更新機制
本文在此基礎上改進了結點更新過程,提出了訪問控制模塊,如圖4 所示.

圖4 訪問控制模塊結點更新
注意力分數αt表示每個結點的訪問強度,當t時刻某一個結點注意力高時,代表已經使用過當前結點,為了不重復使用,當前結點的權重應該被更新為較低的權重,注意力分數越高的結點下一時刻權重被降低的幅度應越大.
在生成一些特殊單詞,如“a”和“this”時,盡管訪問了圖結點,但這些單詞是非可視的,此時不更新結點.因此,本文采用了文獻[5]的自適應更新機制,用來修改注意力強度,如式(6)所示:

其中,fvs是一個全連接網絡,θvs是參數,該網絡輸出一個標量來表示當前注意的結點是否由已生成的單詞表達的.

其中,et, i代表t時刻對第i個結點的注意力強度,取值在0–1 之間,如果et, i取值為0,代表結點在t時刻未被使用,因此不應被更新,如果et, i取值為1,代表結點需要被更新的程度最大.ut, i是視覺哨門,控制更新的程度,在0–1 之間,ut, i的值越高代表更新的程度越大. 根據對變量取值的分析,GUF的取值在0.5–1 之間.
使用GUF來指導圖更新,GUF的取值決定了結點下一時刻被訪問的程度,從而實現訪問控制. 通過式(9)來更新圖結點:

根據本文對圖更新系數GUF的分析,GUF的取值在0.5–1 之間,即使更新程度最大,Xt+1也將更新為0.5Xt,并不會被設為0,即并不會被完全刪除. 因此本文模型更新的幅度比完全刪除更小,結點保存的信息仍能在一定程度上起到指導句子生成的作用.
通過這種方式,我們將結點嵌入Xt更新為下一個解碼步驟使用的Xt+1.
3.4 目標函數
本文在訓練模型時使用的損失為標準的交叉熵損失. 在訓練過程中,對于給定標簽序列y1:T、場景圖G和圖像I的描述模型,采用最小化交叉熵損失:

經過訓練,本文的模型可以通過給定的圖像生成圖像描述.
4 實驗
4.1 數據集
本文實驗使用的數據集為MSCOCO[18],它在圖像描述領域是被廣泛應用的官方數據集. 數據集中的圖像數量超過12 萬張,其中每一張圖像都有大約5 個注釋. 本文采用了MSCOCO 數據集的圖像及注釋,并采用“Karpathy”劃分設置. 當前的圖像描述評測標準分別有BLEU1–BLEU4[19],ROUGE[20],METEOR[21],CIDEr[22],本文使用以上評測標準來評估模型的性能,通過比較模型生成的句子描述和參考句子的相似程度來評估生成的圖像文本描述語句的得分.
在上述評測標準中,BLEU 是一種來源于機器翻譯中計算精度的評估方法,是用于計算模型所生成的句子和參考句子差異的方法,重點考慮了生成句子中單詞的準確性,計算的結果在0.0–1.0 之間,結果越接近1 代表句子的匹配程度越高. BLEU 方法的缺點是極少關注召回率. ROUGE 也是計算精度常用的方法之一,基于查全率的相似度來計算模型生成描述的準確率,與上文的BLEU 具有相似的計算方法. METEOR在機器翻譯評估中也是常用的方法之一,計算時對齊模型生成的描述與圖像的正確描述,這種自動評估標準對生成句子的準確率和召回率都進行計算. CIDEr引入了“共識”的概念,是用于衡量圖像描述的一致性的標準,它將句子表示成向量,根據余弦相似度的標準來判斷,該評價方法對生成描述句子的語義考慮較多.
4.2 實驗結果
4.2.1 模型消融測試
為了分析模型在引入訪問控制模塊和原始信息注入對于圖像描述生成的作用,本文進行了消融實驗測試,測試了模型在3 種方法作用下的模型性能: ① 僅引入訪問控制模塊; ② 僅引入原始信息注入; ③ 同時采用原始信息注入+訪問控制模塊,即本文模型所采用的實驗情況. 測試結果如表1 所示.

表1 在數據集MSCOCO 上的模型消融測試結果(%)
從表1 可以看出,在上述3 種情況中,采用“訪問控制模塊+原始信息注入”對于圖像描述具有最好的性能,在生成語句的準確度、流暢度上的表現都得到了最高的指標值. 其主要原因是原始信息注入充分利用了原始輸入信息,另外,本文設計的訪問控制模塊可以使更新的程度大小更合理,從而生成與圖像內容更相符的描述.
4.2.2 與其他模型的比較
圖5 是本文提出的方法訓練的模型與基線模型(ASG2Caption 模型)[17]在官方數據集MSCOCO 上的結果對比,可以清楚地看出,本文模型生成的句子與圖像實際內容更加契合,語言更加準確.

圖5 實驗結果對比
如表2 所示,對于本文提出的模型,本文在官方數據集MSCOCO 上測試句子得分,以評估模型的有效性. 表2 中的數據表明,與基線模型(ASG2Caption 模型)[17]和其他方法相比,本文訓練的模型具有更高的評分. 本文模型在CIDEr 評分中提升最為明顯,約提高了5.6 個百分點. 本文訓練的模型通過GUF來指導圖更新,可以使更新的程度大小更合理,從而使用更豐富的細節信息生成更高質量的圖像描述.
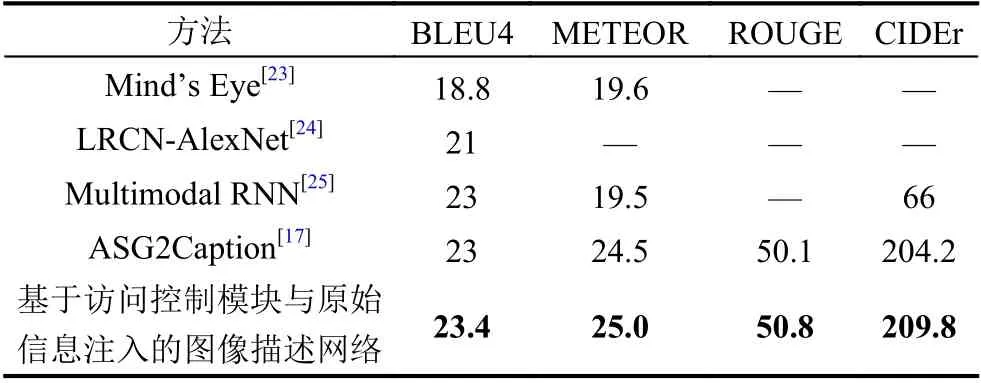
表2 在數據集MSCOCO 上的實驗結果對比(%)
4.3 實驗分析
在MSCOCO 數據集上,本文模型的注意力權重可視化圖如圖6 所示. 3 組圖的左邊為在MSCOCO 中選取的圖像,圖像右邊是句中對于劃線單詞將注意力權重表示在圖中的結果. 圖中的3 張可視化圖對應了3 張不同的圖像,圖像下方的句子為本文提出的基于訪問控制與原始信息注入模型生成的圖像描述.
在圖6(a)中,“a baseball player” 在整體圖像中重要程度較大,可以看出,本文模型能夠很好地關注棒球運動員和球場地面,其中對球場的關注度最大,從而準確地判斷出棒球運動員擊球的信息. 因此,在理解圖像時,本文模型能夠關注相應的圖像區域,為句子的生成提供準確的依據.

圖6 模型注意力權重可視化圖
在圖6(b)中,“beach” 在圖像中占有較大的區域,是較為重要的信息. 當生成描述時,本文模型對圖像的上半部分的沙灘和海浪關注程度最大,且注重沙灘和沖浪板的關聯性.
在圖6(c)中,當生成 “airplane” 時,本文模型對飛機輪廓的判斷能夠達到較高的準確度,且對于飛機前半部分和機翼關注度較高,對包含信息較少的部分關注度較低.
由上述分析可知: 本文模型能夠準確地判斷重要信息所在的位置,關注圖像目標之間的關系,實現準確表達圖像中有效信息的功能.
5 結論與展望
本文提出了一種基于訪問控制模塊與原始信息注入的圖像描述網絡,該網絡對基線模型中語言LSTM的輸入變量做了改進,以充分利用全局圖像信息和嵌入信息來生成句子. 此外,提出訪問控制模塊的概念,用于實現圖更新機制. 同時,本文設計了圖更新系數,用于指導圖更新來確定更新的程度大小,可以在一定程度上優化結點的更新程度. 本文進行了充分的實驗證明該方法的有效性. 在未來的工作中,本團隊會繼續研究場景圖及模型框架的改進方式,并考慮研究立體場景下的圖像描述模型來進一步提升應用價值.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
海外英語(2006年8期)2006-09-28 08:49:00
