基于自動編碼器的時間序列預測混合模型①
2022-08-04 09:58:14滕進風黃健剛
計算機系統應用 2022年7期
路 強,滕進風,黎 杰,凌 亮,丁 超,黃健剛
1(合肥工業大學 計算機與信息學院,合肥 230009)
2(黃山旅游集團水電開發有限公司,黃山 245899)
3(南京航空航天大學 經濟與管理學院,南京 211106)
時間序列預測在許多工業和商業應用中發揮著重要作用,例如金融市場、網絡流量、天氣預報和供水行業等. 在這些場景中,人們可以利用大量關于過去行為的時間序列數據來預測將來的值[1–3]. 時間序列預測的主要挑戰是提高預測能力以滿足日益增長的多步預測需求. 目前,時間序列預測在實際應用中關系到經濟社會生活的各個方面. 因此,在這項工作中,本文將研究時間序列的多步預測性能.
傳統的線性回歸方法主要包括自回歸,移動平均,自回歸綜合移動平均模型(ARIMA)等. 而非線性機器學習模型主要包括人工神經網絡、支持向量回歸和梯度提升決策樹等[4–6],它們在時間序列預測方面也取得了良好的效果. 目前,深度學習技術可以更加高效的提取數據的特征. 經典深度學習框架有深度神經網絡,卷積神經網絡,循環神經網絡(RNN)[7]等. RNN 是一種在時間上進行遞歸的神經網絡,但它存在梯度消失和梯度爆炸的問題. 長短期記憶網絡(LSTM)[8]使用3 個門控機制來解決梯度爆炸和梯度消失問題,它在長序列預測中表現得更好. 門控循環單元(GRU)[9]作為LSTM 的變體,GRU 與LSTM 具有相似的性能,它簡化了LSTM 的門控結構,降低了網絡的訓練時間. 然而這些方法在對序列數據中的長期和復雜關系進行建模時仍然具有局限性. 為了提高預測精度很多信號處理方法被用于時間序列預測,在這些模型中,信號處理方法將時間序列進行分解和去噪處理[10,11]. 在時間序列數據中,不同的數據分量可能具有不同的特征,現有的常見混合模型無法充分利用不同分量的特征.
為了解決上述問題,本文提出了一種新型的混合多步預測模型. 通過采用奇異譜分析對數據進行預處理,再結合本文設計的自動編碼器網絡結構對預處理后的數據進行預測,可以實現對復雜數據建模的能力.主要貢獻如下:
1)提出了一種端到端的時間序列預測混合模型,該模型可以用于時間序列數據的多步預測. 該混合模型的預測精度優于單一模型.
2)采用SSA 將原始時間序列數據分解為不同的趨勢分量,SSA 可以從原始數據中提取數據的不同趨勢信息. 同時設計了新的基于ConvLSTM 和BiGRU自動編碼器結構,該模型能夠進行短期和長期特征學習.
3)使用真實世界的2 個供水數據集和3 個公開的時間序列數據集評價所提出的模型. 實驗結果表明,與所有基線方法相比,該模型在多步預測評價指標下幾乎都獲得了最好的預測性能,證明了模型在時間序列預測方面的優越性.
本文的其余部分安排如下: 第1 節介紹了相關的工作. 第2 節闡述了所提出模型的設計與實現. 第3 節評價了模型的預測性能,并對實驗結果進行了詳細討論. 第4 節對本文進行總結.
1 相關工作
目前,為了更好地提高時間序列預測的準確性,很多信號處理的方法被用于時間序列預測. 例如,Zhang等人[12]采用小波變換(WT)獲取交通流的時變和周期性特征,建立了季節性ARIMA 進行預測. Ahani 等人[13]提出了一種多步預測系統,集成了經驗模式分解(EEMD),最小二乘支持向量回歸(LSSVR)和長短期記憶神經網絡(LSTM). Chang 等人[14]提出了一種基于小波變換和Adam 優化的LSTM 神經網絡混合模型,用于時間序列數據預測. 此外,很多方法采用了數據分解技術來提取數據不同的趨勢信息進行預測. 例如,Tang 等人[15]通過WT 和SSA 對金融時間序列進行分解重構去噪,將平滑序列引入LSTM 得到預測值. Li 等人[16]利用變分模式分解(VMD)將非平穩月降水時間序列分解為幾個相對穩定的固有模式函數(IMFs),然后為每個IMF 建立一個極限學習機預測模型,最后將預測值累加得到預測結果. Liu 等人[17]采用SSA 將原始數據進行分解,同時使用CNNGRU 和SVR 分別預測不同的分量數據. Zhu 等人[18]通過VMD 來捕捉時間序列的趨勢和可變性信息,通過引入雙向門控循環單元實現對天然橡膠期貨的短期預測. 在這些信號處理方法中,WT 可以提取時頻信息,EEMD 和VMD 可以提取趨勢信息. 然而,SSA 具有嚴格的數學理論和少量的參數,并且可以有效地提取信號的趨勢信息,因此被選為信號處理的方法.
由于深度學習算法在數據特征提取方面的強大功能,目前也有大量的工作在時間序列預測領域取得了令人矚目的成績. 例如,Sagheer 等人[19]提出了一種深度長短期記憶(DLSTM)模型用來捕捉時間序列數據中的非線性動態和長期依賴關系. Zhang 等人[20]提出了一種基于雙向長短期記憶(Bi-LSTM)網絡模型用于時間序列數據的預測. Hu 等人[21]采用了一種將卷積神經網絡與雙向長短期記憶網絡相結合的模型,用于預測城市的用水需求. Essien 等人[22]提出了一種用于多步預測的端到端模型,該模型包含一個深度ConvLSTM編碼器-解碼器架構,應用于智能工廠時間序列數據的預測. Salinas 等人[23]提出了DeepAR,這是一種產生精確概率預測的方法,基于對大量相關時間序列訓練自動回歸的遞歸網絡模型. 因此,深度學習方法在時間序列預測方面具有廣泛的應用. 同時,它們使用由多個非線性變換組成的架構來映射數據中的高級抽象.
根據以上文獻,信號處理方法和深度學習方法在時間序列預測方面有著廣泛的使用. 然而,由于不同數據具有不同的特征,單一的深度學習方法在對數據中的長期和復雜關系進行建模時具有一定的局限性. 基于此背景,在本研究中,提出了一種新的混合模型. 使用奇異譜分析對數據進行預處理,再結合本文設計的自動編碼器網絡用于對預處理后的數據進行預測,該模型可用于供水數據的預測,同時模型也可以應用于其他時間序列數據的預測任務.
2 方法
2.1 問題描述
在本研究中,多步(即序列到序列)預測是一個重要的時間序列預測問題,本文將時間序列預測制定為有監督的機器學習任務. 多步時間序列預測的目標是使用大量關于過去行為的時間序列數據來預測將來的值,給定一個一維的單變量時間序列,xt∈{x1,x2,···,xN?1,xN},N為原始序列的長度. 對于多步提前預測,監督機器學習模型的輸入X是xt?w+1,···,xt?1,xt,輸出是yt+1,yt+2,···,yt+k. 本文使用固定長度的滑動時間窗口方法構建X、,得:
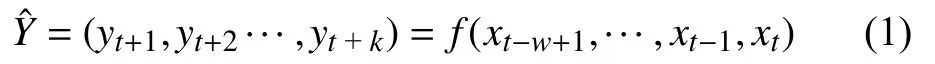
其中,w是滑動窗口時間序列的長度,k是需要預測的時間序列的長度.
2.2 總覽
在本節中,將描述如何使用SSA-ConvBiAE 模型實現時間序列數據的預測任務. SSA-ConvBiAE 模型的總體流程如圖1 所示. 首先,對原始數據進行處理,主要是對數據的缺失值進行填充和歸一化操作,處理后的數據被劃分為訓練集和測試集; 通過數據分解步驟,將訓練集和測試集進行分解和重構,來獲取不同趨勢的分量數據; 然后,將獲取到的訓練集不同的分量數據分別輸入到自動編碼器網絡用于模型的訓練,經過迭代保存訓練好的模型. 最后,將測試集分量輸入到對應訓練好的模型中用于預測,將不同分量的預測結果相加得到最終的預測結果.
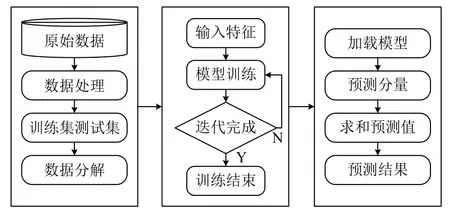
圖1 總體預測模型的管線圖
2.3 提出的模型
本文提出的SSA-ConvBiAE 模型的整個過程如圖2 所示,詳細說明如下.
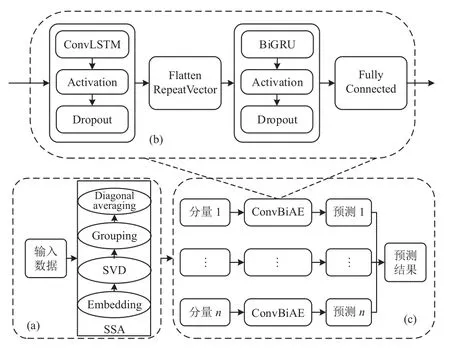
圖2 SSA-ConvBiAE 模型結構圖
2.3.1 數據分解
為了提高模型預測的準確性,采用SSA 信號處理方法將原始的時間序列數據進行預處理,SSA 是用于時間序列分析有效的非參數算法,SSA 可以有效地實現信號的分解和重構. 此外,SSA 具有嚴格的數學理論和較少的參數,并且可以很好地識別時間序列的周期、準周期和趨勢信息. 本文選擇這種非參數方法將原始的時間序列分解并從原始數據中提取不同的趨勢分量. 具體如圖2(a)所示,SSA 經過4 個步驟分別是: 嵌入(embedding)、奇異值分解(SVD)、分組(grouping)和對角平均化(diagonal averaging),可以將原始的時間序列數據進行分解和重構,并獲取數據不同的趨勢信息,用于模型的訓練和預測. SSA 的詳細步驟描述如下:
1)嵌入. 首先選擇適當的窗口長度L(2 ≤L≤N),將一維的原始時間序列X=(x1,x2,···,xN)轉化成多維的序列Z=(Z1,Z2,···,ZK),Zi=(xi,xi+1,···,xi+L?1)T∈RL,其中,K=N?L+1,可得軌跡矩陣Z=(Z1,Z2,···,ZK)=表示為:

可以看出矩陣Z為漢克爾矩陣,即沿對角線元素相等.
2)奇異值分解. 通過SVD,軌跡矩陣Z可表示為:
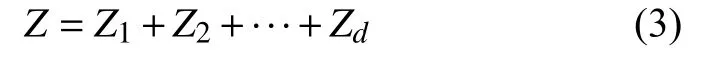
3)分組. 該過程將區間{1,2,···,d}劃分為多個離散子集I1,I2,···,Im,其中m是組數,則矩陣Z可表示為:
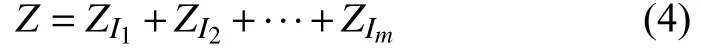
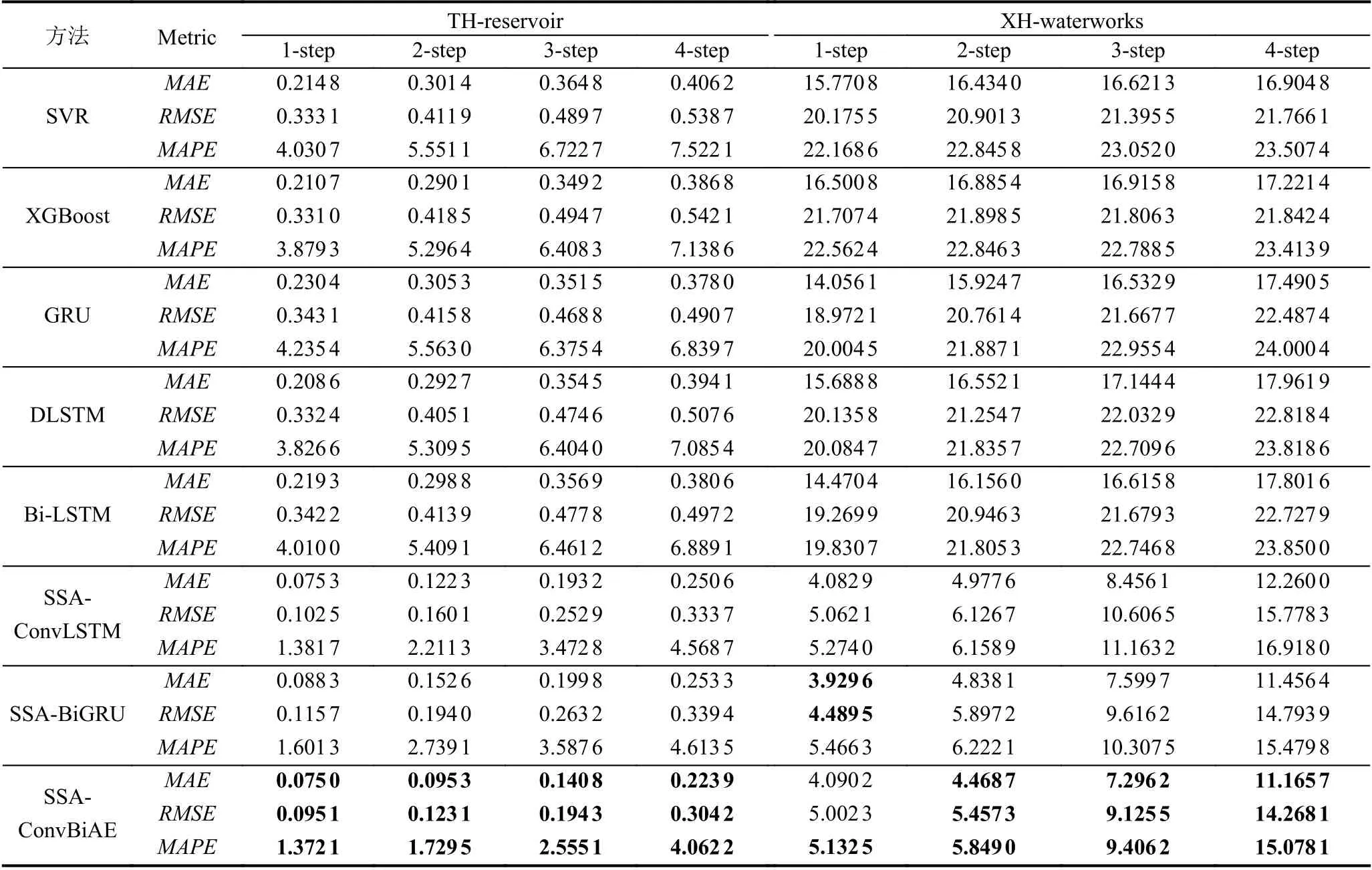
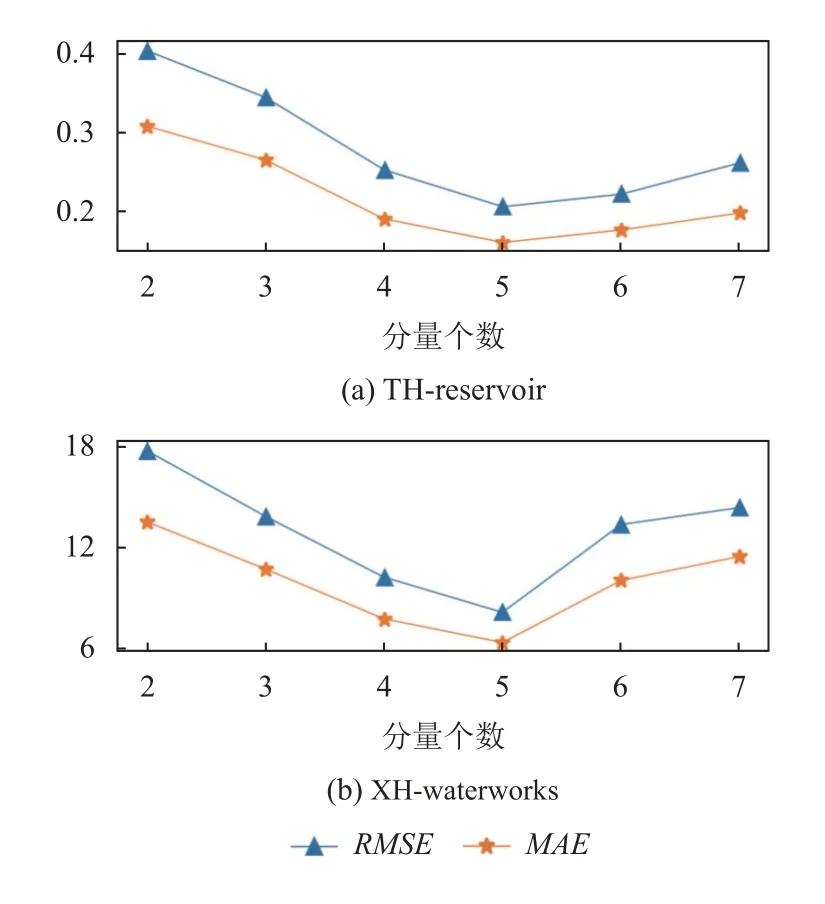
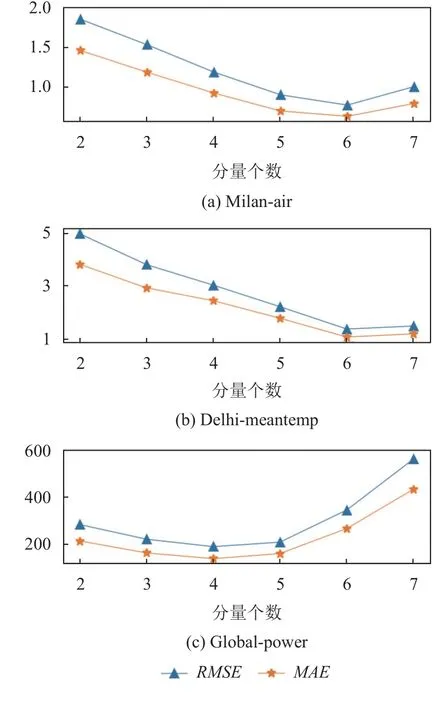
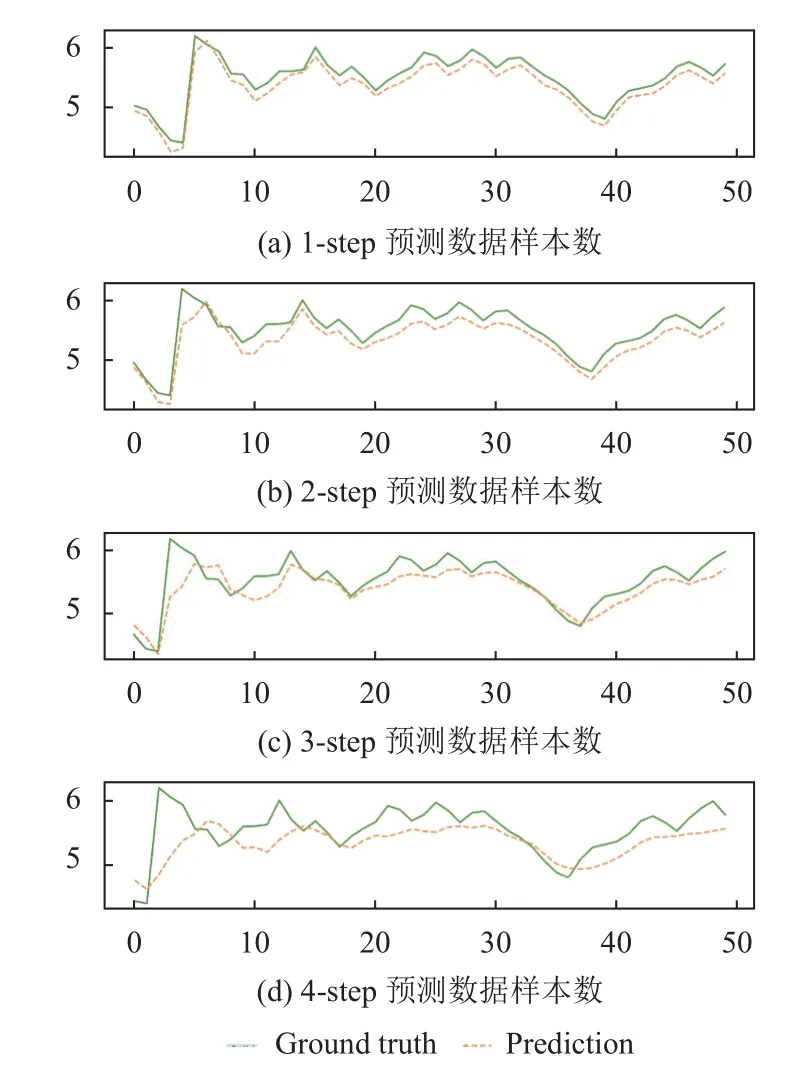
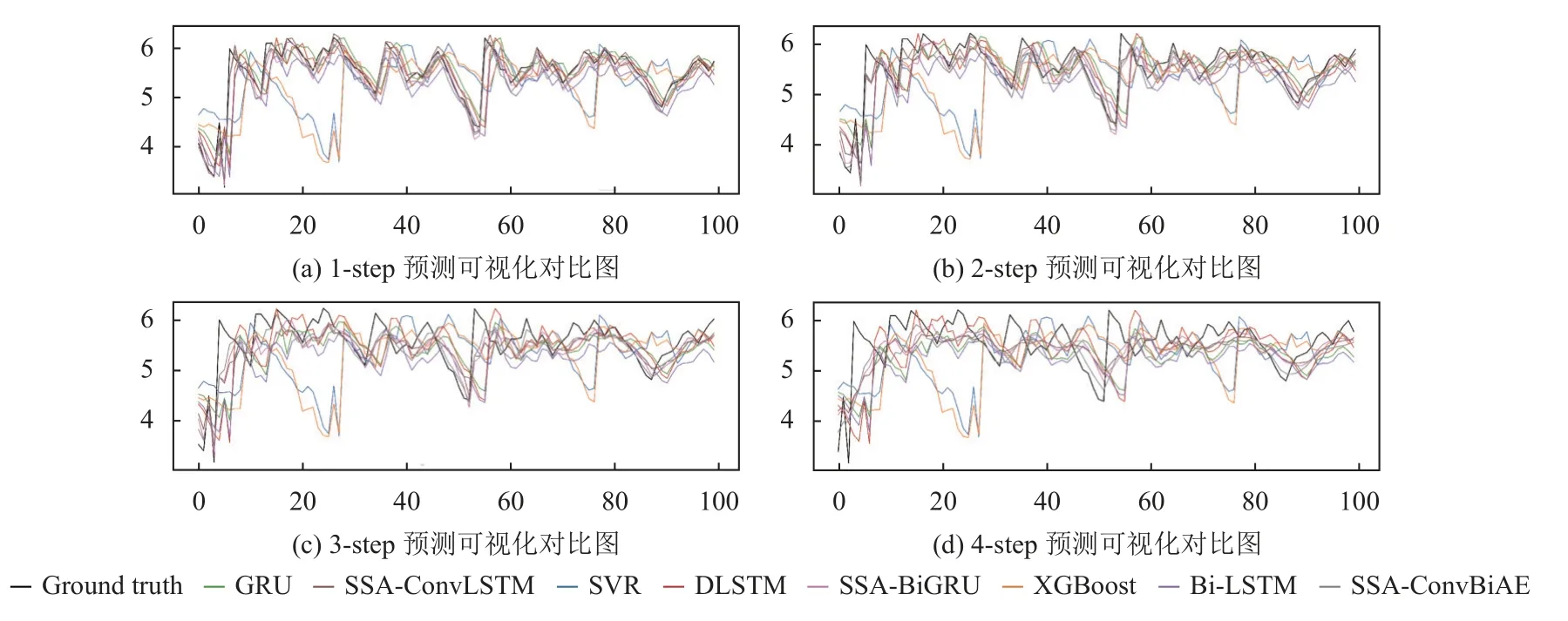
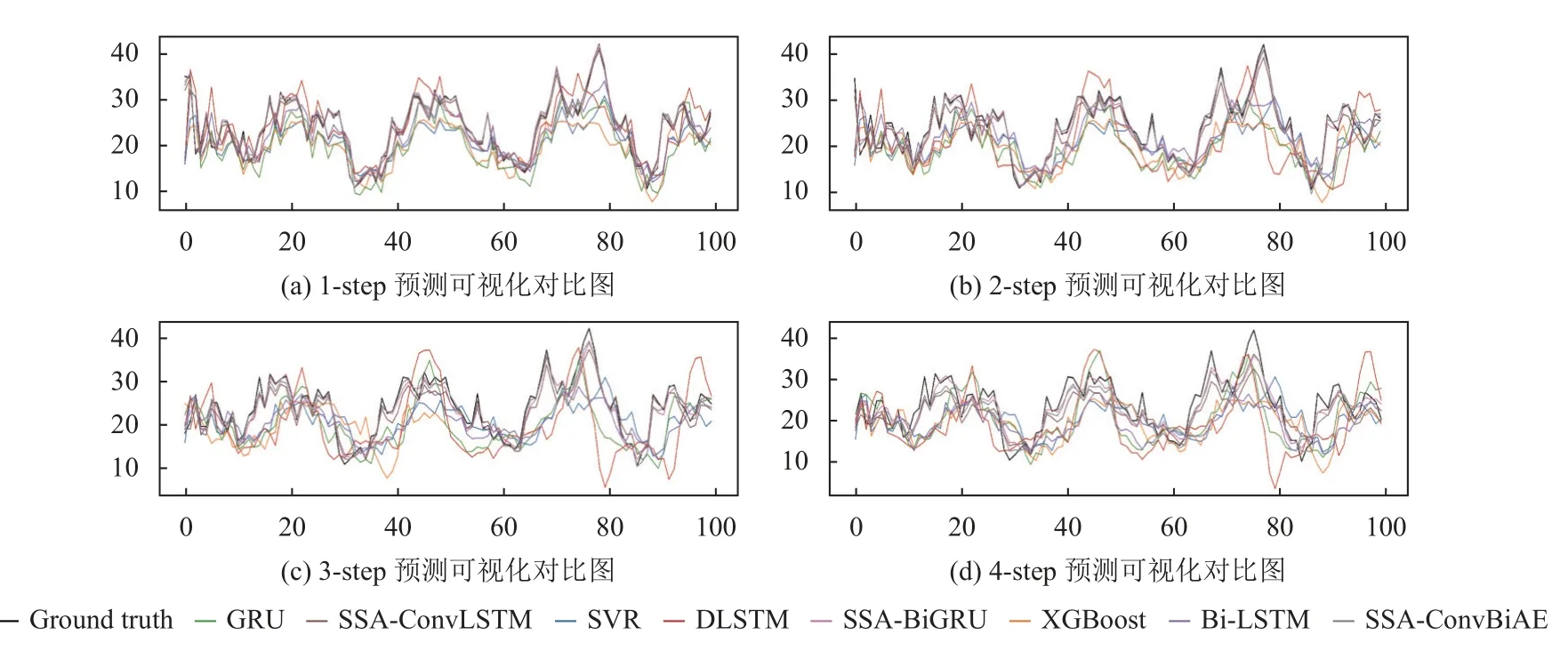
4)對角平均化. 該過程旨在將分組序列的每個矩陣轉換為長度為N的新序列,設Z為L×K的矩陣,L?=min(L,K),K?=max(L,K),N=L+K?1,且當L 2.3.2 自動編碼器 自動編碼器可以解決序列到序列建模的問題,其中輸入和輸出均為序列. 本文設計了基于ConvLSTM和BiGRU 的自動編碼器結構,具體如圖2(b)所示,提出的網絡模型結構主要分為編碼器和解碼器. 1)編碼器有一層ConvLSTM,一層激活函數tanh 和一層Dropout 函數堆疊在一起作為編碼層.ConvLSTM[24]作為LSTM 的一種變體,雖然LSTM 可以有利地捕獲長輸入序列的長期依賴,但它的各個門控結構之間采用的是由全連接的方式構建的,因此模型在訓練時需要更多的參數. 而ConvLSTM 用卷積算子替換了全連接層算子,使得它在輸入到隱藏狀態以及與各個門控結構之間的轉換都具有卷積操作. Conv-LSTM 繼承了卷積算子中稀疏連接和參數共享的優點,可以減少全連接結構的冗余. 此外,ConvLSTM 不僅能夠提取時間特征,通過卷積操作還可以有效對空間信息進行特征提取. 同時,ConvLSTM 通過門控機制克服了梯度消失的問題,也保留了LSTM 可以捕獲長時間記憶的優點. 因此,本文選擇ConvLSTM 作為編碼器.它的計算公式如下: 其中,σ、tanh、? 和°分別表示Sigmoid、tanh 操作、卷積運算和Hadamard 積;it,ft,Ct?1,Ct和ot分別代表各種門控機制;xt表示輸入數據,ht?1表示前一個ConvLSTM單元輸出的循環狀態,ht表示當前時刻的循環狀態;W和b分別代表門控機制的權重向量和偏差向量. 2)解碼器由一層BiGRU、一層激活函數tanh 和一層Dropout 函數堆疊在一起作為解碼層. BiGRU 模型一種雙向循環神經網絡,它可以利用正向和反向信息. 雙向門控循環單元將兩個傳輸方向相反的隱藏層連接到同一個輸出層. 因此,輸出層具有輸入序列中每個點的過去和未來狀態的完整信息,從而做出更準確的預測. BiGRU 是在GRU 基礎上進行正向和反向訓練并將結果進行線性融合,這樣不但可以提取過去的特征,也可以提取未來的特征,同時數據復用,而且每個時刻輸出值是由兩個方向的GRU 共同決定. BiGRU的思想是將常規GRU 神經元分為前向狀態和后向狀態. GRU 的計算公式如下所示: 其中,σ表示激活函數Sigmoid,tanh 是候選狀態的激活函數,?是點積操作,xt表示輸入向量,更新門zt可以確定保留多少先前存儲的信息,重置門rt可以將多少先前存儲的信息與新輸入集成在一起.ht?1表示上一時刻隱藏層的狀態,ht表示當前時刻隱藏層狀態.h?t表示候選狀態.W是與輸入相關的權重矩陣,b表示偏差向量. 為了使編碼層的輸出可以作為解碼層的輸入,在編碼層之后通過使用一個重復向量層(repeat vector).該層的主要功能是重復來自編碼層的最終輸出向量,以便解碼層能夠重建原始輸入序列. 最后,在解碼層之后通過一個全連接層,用來輸出數據的預測值. 2.3.3 預測分量 多個分量的預測過程,具體如圖2(c)所示,將SSA 獲取到的n個分量數據分別作為每個自動編碼器模型的輸入數據進行模型的訓練,保存訓練好的模型.將不同的測試集分量分別輸入到對應的訓練好的自動編碼器模型中進行預測,最后將不同分量的預測值進行求和,得到最終的預測結果. SSA-ConvBiAE 模型是一個健壯的,可擴展的端到端時間序列多步預測模型. 奇異譜分析可以從原始數據中提取數據不同的趨勢信息,同時本文設計的自動編碼器網絡結構能夠進行短期和長期特征學習,該混合模型可以用于時間序列的多步預測. 為了更好地反映出模型的預測值跟真實值的差距,在SSA-ConvBiAE 模型中采用的損失函數是均方誤差. 同時,使用了基于隨機梯度的優化算法Adam,每次迭代時更新模型參數. 損失函數的計算方法如下: 本文的實驗環境是基于Windows 操作系統,使用Python 語言對代碼進行實現. 深度學習框架主要采用了TensorFlow,模型算法的實現是使用Keras,它是基于TensorFlow 的深度學習庫. 硬件環境的配置是Intel(R)Core(TM)i7-7700K CPU @4.20 GHz、32.0 GB內存和NVIDIA GeForce RTX 2080 8 GB GPU. 本文提出的模型在5 個數據集進行了實驗,其中包括2 個真實的供水數據集和3 個公開的時間序列數據集. TH-reservoir 和 XH-waterworks 是由黃山旅游集團水電開發有限公司提供的黃山風景區供水數據集.Milan-air[25],Delhi-meantemp[26]和Global-power[27]是從Kaggle 網站獲得的公開的時間序列數據集. 5 個數據集的詳細描述如下所示: 1)TH-reservoir: 該數據集是黃山風景區某水庫的水位值,數據集包含了黃山風景區某水庫2017 年1 月1 日到2019 年12 月31 日每天的水位值. 2)XH-waterworks: 該數據集是黃山風景區某水廠的供水量,數據集包含了黃山風景區某水廠2017 年1 月1 日到2019 年12 月31 日每天的供水量. 3)Milan-air: 該數據集是米蘭空氣中PM2.5濃度數據,數據集包含2020 年7 月24 日到2020 年9 月20 日每小時PM2.5濃度的平均值. 4)Delhi-meantemp: 該數據集是印度德里市的天氣溫度數據,數據集包含2013 年1 月1 日至2017 年1 月1 日每天溫度的平均值. 5)Global-power: 該數據集是一個家庭在4 年內的有功功率電力消耗數據,數據是每分鐘收集一次,經過累加計算得出每天的消耗量,數據集包含2006 年12 月16 日至2010 年11 月26 日每天消耗量的值. 上述黃山風景區供水數據集包含少量的缺失數據,因此使用線性插值的方法進行填充. 在實驗中,將80%的數據用作訓練集,其余20%用作測試集. 為了評價模型的多步預測性能. 在本文中,使用了輸入步長大小為18 的滑動窗口機制,進行多步預測. 另外,將輸入數據進行歸一化處理,其公式如下所示: 其中,xnor表示歸一化后的數據,x表示輸入的樣本數據中某一個值,xmax,xmin分別表示樣本數據中的最大值和最小值. 為了驗證所提出模型的預測性能,本文進行了5 個實驗. 在每個實驗中,將SSA-ConvBiAE 模型的預測性能與以下基線方法進行比較: 1)SVR[5]: 支持向量回歸,它使用歷史數據來訓練模型并對數據進行預測. 2)XGBoost[6]: 它是一個端到端的梯度提升決策樹模型,是一種高效且廣泛使用的機器學習方法. 3)GRU[9]: 門控循環單元,GRU 通過簡化門控結構使得網絡更易計算,降低了模型的訓練時間. 4)DLSTM[19]: 通過堆疊多個LSTM 塊,構建一個深度LSTM 神經網絡. 5)Bi-LSTM[20]: 主要使用前向和后向LSTM 來捕捉過去和未來隱含的信息,然后將兩部分結合起來形成最終的預測輸出. 6)SSA-ConvLSTM: 消融實驗. 奇異譜分析和ConvLSTM 的混合模型,詳細描述請參見第2.3 節. 7)SSA-BiGRU: 消融實驗. 奇異譜分析和BiGRU的混合模型,詳細描述請參見第2.3 節. 本實驗采用3 種評價指標對模型的預測結果進行評價,具體如下: 平均絕對誤差(MAE): 均方根誤差(RMSE): 平均絕對百分比誤差(MAPE): 在本節中,為了研究所提出模型的多步預測性能,對涉及到的所有模型進行1-step 到4-step 的預測. 表1,表2 和表3 給出了2 個真實的供水數據和3 個公開時間序列數據在幾種不同模型上的預測誤差評價結果. 表1 SSA-ConvBiAE 模型和基線方法對TH-reservoir 和XH-waterworks 數據集的預測結果 通過表1 的實驗結果,可以發現: 在供水數據案例研究中,SSA-ConvBiAE 模型可以實現準確的多步預測結果,混合模型的預測精度優于單一模型. 這表明SSA 對數據的分解,可以獲取數據不同趨勢的分量信息,從而降低了時間序列的復雜度,提高了模型的預測精度. 與其他幾種基線方法相比,SSA-ConvBiAE 模型的多步預測幾乎具有最好的預測精度,這表明設計的基于ConvLSTM 和BiGRU 結構的自動編碼器模型可以有效地提取數據特征,適用于時間序列預測. 同時,為了驗證模型不僅可以用于供水數據預測,本文也在3 個公開的時間序列數據進行了實驗,通過表2 和表3的實驗結果可以發現,所提出的模型在公開的數據集上都有優異的表現,表明模型具有一定的泛化能力. 表1,表2 和表3 顯示了SSA-ConvBiAE 模型和其他基線方法在5 個時間序列數據集上的多步預測任務的性能. 可以看出,SSA-ConvBiAE 模型在多步預測范圍的評價指標下幾乎都獲得了最好的預測性能. 模型與其他基線方法預測結果相比,詳細描述如下. 表2 SSA-ConvBiAE 模型和基線方法對Milan-air 和Delhi-meantemp 數據集的預測結果 表3 SSA-ConvBiAE 模型和基線方法對Global-power 數據集的預測結果 1)預測精度. 以TH-reservoir 數據集為例,從表1中可以看出: 所提出的模型SSA-ConvBiAE 極大地提高了多步預測的性能,這表明該模型在長期預測能力方面取得了優異的效果. 例如,對于1-step 的供水數據預測任務,SSA-ConvBiAE 模型和SVR 和XGBoost 模型相比,RMSE誤差降低了約71.45%和71.27%. 這主要是由于SVR 和XGBoost 等方法難以處理復雜的非平穩時間序列數據. SSA-ConvBiAE 模型和GRU 模型、DLSTM 模型和BiLSTM 模型相比,RMSE誤差降低了約72.28%、71.39%和72.21%,這主要是由于針對具有不同特征的時間序列數據,這幾種模型的預測結果會有所降低. 從表1 可以看出,經過SSA 進行數據分解,預測精度得到了明顯提高,這表明提出的混合模型是有效的. 2)消融分析. 為了驗證SSA-ConvBiAE 模型采用自動編碼器網絡結構的有效性,將SSA-ConvBiAE 與SSA-ConvLSTM 和SSA-BiGRU 模型進行了比較. 以TH-reservoir 數據集為例,從圖3 中可以看出,在RMSE和MAPE兩種不同的實驗評價指標下,可以清楚地看到提出的SSA-ConvBiAE 比SSA-ConvLSTM和SSA-BiGRU 具有更好的預測結果. SSA-ConvBiAE與SSA-ConvLSTM 和SSA-BiGRU 模型相比,從1-step預測可以看出,RMSE分別降低了約7.22%和17.80%.實驗表明,ConvLSTM 充分捕捉了序列數據的時間和空間分布,同時模型中結合BiGRU,使輸出層具有輸入序列中每個點的過去和未來狀態的完整信息,可以融合更多的序列特征,提高了模型的預測性能. 因此,表明了本文提出的自動編碼器網絡結構可以有效地提取數據特征. 圖3 消融實驗預測結果對比 3)多步預測. 從以上的實驗結果可以看出,在5 個不同的數據集上SSA-ConvBiAE 模型預測精度在多步預測范圍內明顯要高于其他基線方法. 以TH-reservoir和XH-waterworks 數據集為例,從表1 中可以看出,本文提出的SSA-ConvBiAE 模型在1-step 到4-step 的預測結果幾乎都獲得了最好的預測性能,這表明提出的混合模型是可行的. 因此,該模型可以用于供水數據和其他時間序列任務的預測,同時本文提出的SSA-ConvBiAE模型不僅可以用于短期預測,還可以用于中長期預測. 在本節中,將選擇SSA-ConvBiAE 模型的相關參數. SSA-ConvBiAE 模型的超參數主要包括: 批次大小、訓練次數、隱藏層單元數、卷積核的尺寸、Dropout和數據分量個數. 在實驗中,將批次大小設置為32,訓練次數設置為100,隱藏層單元設置為128,卷積核的尺寸設置為1×3,Dropout 參數設置為0.1. 數據分量的個數是SSA-ConvBiAE 模型的一個非常重要的參數,本文通過嘗試不同的數據進行對比預測實驗來選擇最佳值. 在實驗中,從[2,3,4,5,6,7]中選擇不同的分量個數并分析預測精度的變化. 如圖4和圖5 所示,橫軸代表不同的分量個數,縱軸代表RMSE和MAE兩種不同的評價指標的變化. 圖4(a)和圖4(b)分別顯示了數據集TH-reservoir 和XH-waterworks 不同分量個數的RMSE和MAE的預測結果. 可以看出,當分量個數為5 時,誤差最小. 同樣圖5(a)和圖5(b)分別顯示了數據集Milan-air 和Delhi-meantemp 的預測結果,當個數為6 時,結果達到最小值,圖5(c)顯示了數據集Global-power 的預測結果,當個數為4 時,結果達到最小值. 這表明不同的分量個數會極大地影響預測精度,因此需要通過不同參數的對比實驗來選擇最佳值. 圖4 不同的SSA 分量在TH-reservoir 和XH-waterworks 數據集上的預測性能比較 圖5 不同的SSA 分量在Milan-air,Delhi-meantemp 和Global-power 數據集上的預測性能比較 為了更好的理解SSA-ConvBiAE 模型的預測結果,選擇對TH-reservoir 的部分測試集樣本數據進行預測結果可視化,圖6(a)–圖6(d)分別顯示了模型1-step到4-step 的預測范圍的可視化結果. 從圖6 中1-step 和2-step 預測的可視化結果來看,SSA-ConvBiAE 模型在數據的局部最小值和局部最大值處的預測結果都非常的接近真實值,這表明SSA 將數據分解成不同的趨勢分量后,自動編碼器結構中ConvLSTM 充分捕捉了序列數據的空間和時間分布,具有自動特征提取方面的優勢,而BiGRU 可以融合更多的序列特征,提高了模型的預測性能. 從圖6 中3-step和4-step 的預測可視化結果來看,模型預測的總體趨勢接近真實值,但在局部最小值和局部最大值處的預測結果要低于前兩步預測. 盡管ConvLSTM,BiGRU可以捕捉數據集中的長期依賴性,但針對復雜數據的預測,長期預測的結果也會有所降低. 從圖6 中的1-step到4-step 的預測結果,可以看出奇異譜分析與自動編碼器網絡的結合是有效的,該模型可以提取序列數據的時間特征,可以很好地擬合數據,以及準確預測數據的變化趨勢. 同時,在5 個數據集上的預測結果可以看出,在針對具有不同特征的時間序列數據,本文提出的模型在預測結果方面都具有優異的表現. 圖6 SSA-ConvBiAE 模型的可視化預測結果(其中,縱坐標表示水位 (m)) 為進一步表明模型的預測結果,選擇SSA-ConvBiAE模型與其他基線方法的預測結果進行可視化對比,如圖7(a)–圖7(d)所示,不同的模型對TH-reservoir 數據集進行1-step 到4-step 預測結果可視化,可以看出,采用SSA 對數據進行處理后,混合模型的預測結果明顯優于單一模型,預測結果更接近真實值,與SSA-ConvLSTM和SSA-BiGRU 模型相比,SSA-ConvBiAE 模型在多步預測范圍內獲得了更好的預測性能. 同時本文也選擇了對Milan-air 數據集進行預測結果可視化,如圖8(a)–圖8(d)所示,展示了不同模型的預測結果. 圖7 SSA-ConvBiAE 模型與基線方法對TH-reservoir 數據集的預測結果可視化對比圖(其中,縱坐標表示水位 (m),橫坐標表示樣本數目) 圖8 SSA-ConvBiAE 模型與基線方法對Milan-air 數據集的預測結果可視化對比圖(縱坐標表示: PM2.5 濃度 (μg/m3),橫坐標表示樣本數目) 本文提出的一種端到端的時間序列預測混合模型,SSA-ConvBiAE 模型是一個健壯的,可擴展的端到端模型可以用于時間序列數據的多步預測. 在提出的SSA-ConvBiAE 模型中,采用SSA 將原始時間序列數據分解為不同的趨勢分量,SSA 可以從原始數據中提取數據不同的趨勢信息,同時本文設計了新的基于ConvLSTM 和BiGRU 自動編碼器結構,模型能夠進行短期和長期特征學習,該混合模型的預測精度優于單一模型. 在真實世界的2 個供水數據集和3 個公開的時間序列數據集上進行實驗來評價所提出的模型. 實驗結果表明,與所有基線方法相比,該模型在多步預測評價指標下幾乎都獲得了最好的預測性能,證明了SSA-ConvBiAE 模型在時間序列預測方面的優越性.這表明提出的模型不僅可以應用于供水預測領域,同時對于其他時間序列數據預測也具有一定的適用性.在未來的研究計劃中將繼續深化研究SSA-ConvBiAE模型在時間序列數據方面的預測性能,特別是針對多變量的時間序列預測問題.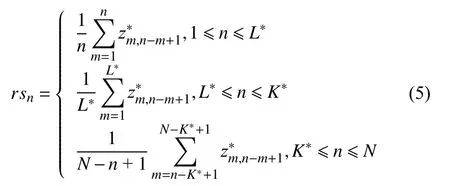
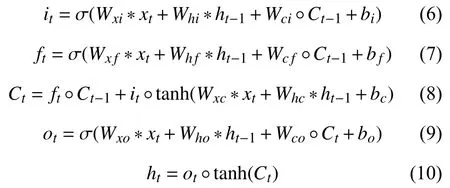
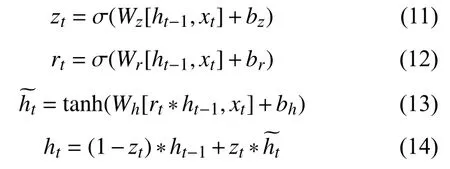
2.4 損失函數
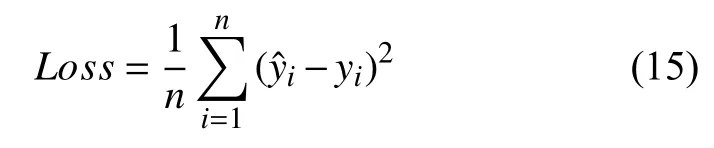
3 實驗分析
3.1 實驗環境
3.2 數據描述
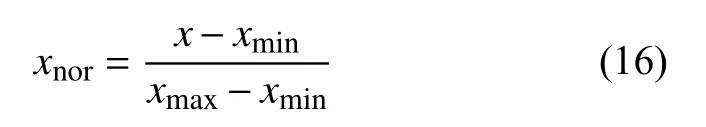
3.3 基線方法
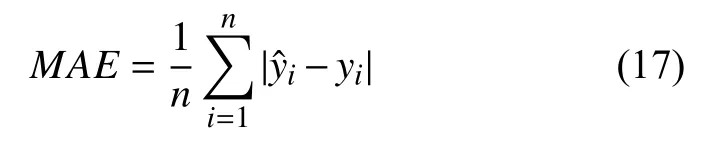
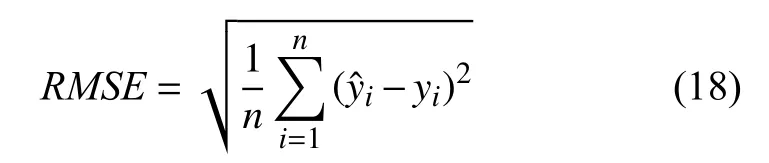
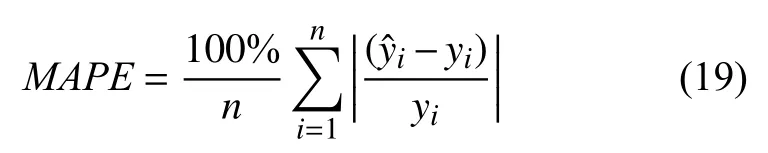
3.4 實驗結果



3.5 模型參數選擇
3.6 模型解釋
4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
