復雜路面小尺度行人檢測綜述①
2022-08-04 09:58:04趙書,陳寧
計算機系統應用 2022年7期
趙 書,陳 寧
(西安工程大學 電子信息學院,西安 710048)
行人檢測是一個預測、定位和標記的過程,在給定的視頻或圖像中檢測是否有行人存在,并返回目標對象的位置信息. 此技術作為計算機視覺的一個重要課題有著深刻的研究意義,并且在自動駕駛、視頻監控、人機交互等領域都有著廣泛的應用. 此外,行人檢測是目標檢測中的一個特例,其研究成果可以對其他目標檢測方法起很好的推動作用.
隨著現代控制技術和汽車技術的發展,智能汽車已經實現了輔助駕駛乃至自主駕駛功能. 行人是交通場景中不可或缺的一部分. 同時,道路行人檢測也是智能汽車能夠應用在各種交通場景中的基本前提. 智能汽車通過車載攝像頭獲取道路信息,然后利用行人檢測技術,自動準確的檢測出道路前方的行人,及時反饋及預警,這有利于保障行車安全和行人通行安全. 近年來,隨著智能交通的提出以及無人駕駛等領域的需要,使得行人檢測技術有了一個更高精度的要求. 當汽車處于復雜的交通環境中時,對于那些尺度較小且分辨率低的行人檢測尤為重要,因為遠處的小尺度行人更容易被忽視從而引發事故. 因此自動駕駛汽車必須具有在一定距離內檢測到小尺度行人的能力,以便能夠讓控制系統可靠且平穩地避免與之碰撞[1–3].
目前行人檢測技術已經實現了較高的準確率,但是由于行人尺度變化、低分辨率、遮擋等問題的存在,行人檢測仍然受限于應用場景. 如何實現小尺度行人的精準檢測一直是行人檢測任務中的需要解決的關鍵問題之一. 文獻[4] 中將行人根據像素高度分為近、中、遠3 個等級對應不同的尺度對象. 如圖1 所示. 然而,在許多行人檢測應用場景中,小尺度行人的占比更高. 據統計,在加州理工學院的行人數據集中,實例高度小于80 像素的占83%. 人眼在檢測小尺度行人時沒有太大難度,但現有的行人檢測方法在檢測大尺度行人時擁有很好的性能,在小尺度行人檢測上性能有所下降.

圖1 小尺度行人樣本示例
近年來,越來越多的學者開始研究如何解決小尺度行人的檢測問題,也取得了一定的進展,但是仍不滿足實際應用的要求. 當前,小尺度行人檢測技術現處于快速發展期. 目前的研究工作與實際應用要求之間的不匹配,使得對小尺度行人檢測問題的解決方法進行探索和討論尤為重要. 然而現在有很多討論小尺度目標檢測問題和行人檢測問題的綜述性文章[5–8],但討論小尺度行人檢測問題的綜述卻幾乎沒有. 因此本文對小尺度行人檢測方法進行了全面的分析和總結,從而更好地促進行人檢測技術的進一步發展和提升.
如今現有的行人檢測的方法可以分為兩類: 傳統方法和基于深度學習的方法. 傳統的行人檢測方法大多基于手工提取特征+分類器的結構. 對傳統方法來說,手工提取特征的設計對于檢測器性能的好壞至關重要.然而手工特征不能捕捉大規模數據集的多層次表示,因此這類方法受到了特征提取的限制,對類內可變性的魯棒性較差.
為克服傳統手工特征的缺點,文獻[9]提出了深度卷積神經網絡. 相對于傳統方法來說,深度學習的提出大大簡化了檢測的工作. 由于深度學習對視覺特征的強大表征能力,使得其現如今在目標檢測領域占主導地位. 因此,本文分析和探討了深度學習方法中小尺度行人檢測存在的問題和解決方法. 首先,以小尺度行人檢測方法的不同思路為依據將現有方法分為5 類并介紹其典型模型. 除此之外,我們還研究了行人檢測的數據集和評估指標. 同時,對每一類方法進行對比分析和綜合評價,并提出了未來需要解決的問題和努力的方向.
1 小尺度行人檢測方法
卷積神經網絡(CNN)是一類相當具有代表性的深度神經網絡,也是行人檢測中最常用的網絡. CNN 網絡模型主要可分為兩類: (1)以RCNN 系列為代表的方法,預先回歸一次邊界框,然后利用骨干網絡再進行訓練,被稱為兩階段檢測器,該類方法精度較高但檢測時間長; (2)以YOLO、SSD 等為代表的只進行一次回歸和評分的方法,稱為一階段檢測器,該類方法檢測速度快但精度稍差. 由于CNN 會隨著網絡的加深弱化小尺度對象的特征表示,所以這些模型只適用于粗粒度的分類任務,在細粒度的分類任務如小目標檢測和語義分割中有一些限制. 因此無論是一階段檢測器還是兩階段檢測器,對于小尺度行人的檢測都存在幾大挑戰,如表1 所示.

表1 小尺度行人檢測存在的挑戰
此外,關于小尺度行人檢測的經驗和知識非常有限,因為大多數先前的工作都是圍繞大尺度行人檢測問題展開研究的. 因此,有必要對現階段的小尺度行人檢測工作進行梳理,探索有效的解決方法,提高其檢測精度.
隨著基于深度學習的目標檢測技術的發展,許多適用和解決小尺度行人檢測難問題的新型網絡模型被提出. 本文從多尺度表示、上下文信息、訓練和分類策略、尺度感知以及超分辨率5 個方面總結了現有的小尺度行人檢測算法.
1.1 基于多尺度表示的方法
對檢測和識別任務來說,特征圖是精準定位和分類的關鍵. 由于行人較小的尺度和低分辨率表示,行人的位置等細節信息在高層特征地圖中逐漸丟失. 最初解決該問題主要有兩種策略: (1)構建圖像金字塔[10],將圖像縮放到不同比例輸入到檢測器中,但由于潛在的圖像比例很大,計算每個比例下的特征非常耗時,因此這種方法已經很少使用; (2)基于單個特征圖生成區域建議,使用不同比例和大小的錨框對應不同的感受野,如Faster R-CNN[11]中的多尺度區域建議網絡RPN,而此類方法檢測小尺度對象的劣勢在于,只利用最后一層特征生成建議,使得具有大的感受野的高層特征因為分辨率太低而不能準確的識別到小目標.
針對上述問題,Liu 等人提出的SSD 分類器首次引入了特征多尺度表示的思想[12],在不同網絡分層中提取特征并依次進行邊界框回歸和分類,SSD 利用淺層特征來檢測小尺寸對象有一定的提升效果. 隨后,Cai 等人構建了多尺度深度卷積神經網絡MS-CNN[13],通過引入反卷積特征上采樣替代輸入上采樣來提高了特征圖的分辨率,并使用多層來匹配不同比例的對象,增強了小尺度目標的檢測能力.
然而MS-CNN 和SSD 并沒有充分利用網絡中的底層信息,直接從網絡的高層構建金字塔. 為進一步充分利用特征信息,Lin 等人進一步結合了單一特征地圖、集成特征和特征金字塔層次的優點,在Fast RCNN中構建了特征金字塔網絡(FPN)[14]. FPN 采用自頂向下的結構,將低分辨率的高層語義圖和高分辨率的低層語義圖進行融合,每一層特征都進行獨立預測,無需成本但在小尺度行人上有很好的表現. 隨后又出現了一系列基于FPN 改進的方法. 由于SSD 速度很快但精度不夠理想,Li 等人提出的FSSD 分類器(feature fusion single shot multibox detector)[15]將FPN 結合到SSD中,將具有不同尺度的多層特征連接在一起,隨后下采樣構建新的特征金字塔,大大提升了檢測精度. 基于FPN,文獻[16]中引入了一個跨尺度特征聚合模塊,通過融合魯棒的語義和不同尺度行人的準確定位來增強特征金字塔表示.
Cao 等人認為FPN 等網絡中小尺度行人的語義水平還不夠高,于是提出了一種多分支高級網絡MHN-D將底層特征轉化為高級語義特征[17]. MHN-D 的分支具有不同的空間分辨率和感受野,適合檢測多個尺度的行人. MHN-D 網絡的分支之間采用跨層連接來提高檢測性能,并利用空洞卷積增加特征圖的分辨率,為小尺寸行人的定位保留更多的空間信息.
圖2 展示了多種方法結構的對比. 具體來說,多尺度表示就是一種將包含豐富語義信息的深層特征和具有詳細位置信息的淺層特征相結合的策略. 這類策略有效地避免了特征圖的重復計算,并提升了檢測精度.并且多尺度表示的方法也從基于多個單層特征預測趨向于多層特征融合,目前此類方法已經成為克服小尺度行人檢測中信息丟失和感受野不匹配問題的主流方法.
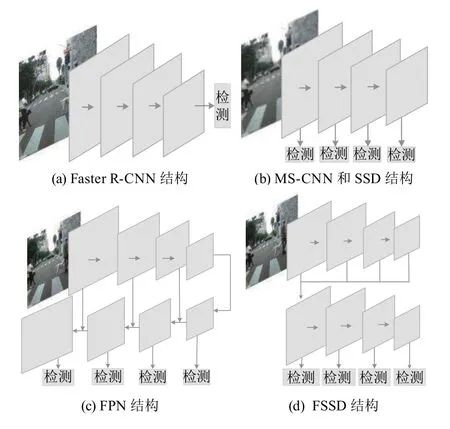
圖2 多尺度特征學習網絡結構對比
1.2 基于上下文信息的方法
上下文信息充分利用視覺對象及其共存環境之間關系,在目標檢測中起著重要作用. 文獻[18]已經證明背景等信息對于小規模目標檢測是有幫助的. 大尺度的行人可以給檢測器提供足夠的感興趣區域特征,相比之下,從小尺度行人對象中提取的感興趣區域特征非常少. 因此提取上下文信息作為原始感興趣區域特征的補充可以有效地解決小尺度行人特征不足和定位不準確的問題.
然而像FPN 等網絡簡單地將不同層的語義圖連接起來隱式的學習上下文信息,所得到的組合特征還不足夠豐富. 因此明確的挖掘上下文信息具有一定的意義. 為了進一步改善檢測性能,文獻[19]提出了一種擴展特征金字塔的FPN++框架,在FPN 檢測器的頭部引入上下文感知檢測模塊,利用上下文信息進行分類和回歸. 文獻[20]提出了一種上下文感知的DIF R-CNN行人檢測方法,通過集成反卷積模塊引入額外的上下文信息. 具體地說,網絡將反卷積層和初始特征圖相結合生成用于收集附加信息的合成特征圖,為檢測提供更多的視覺細節和語義上下文表示. ALFNet[21]中的卷積預測塊CPB 將殘差學習和多尺度上下文語義信息結合到一起,構建了一個上下文編碼塊. 而文獻[22]認為簡單地將不同強度的語義特征圖結合起來,會導致語義不一致從而不能充分的提取到對象周圍的上下文信息. 對此,提出了一個利用可分離大核卷積作為橫向連接的語義轉換模塊,將弱語義特征先經過3 個不同分支的特征映射后進行連接用于跳躍層融合,緩解語義不一致性并提取更多的上下文信息.
表2 展示了幾種上下文信息的不同引入方式. 與多尺度表示的方法的初衷相似,基于上下文信息的方法也旨在給檢測網絡提供更多的信息. 獲取上下文信息主要通過不同特征層之間的跳躍連接實現,此外引入空洞卷積可以獲取到更多的信息. 所獲取的上下文信息主要為興趣域附近的信息,通過學習對象和周圍環境之間的關系來提升檢測效果.
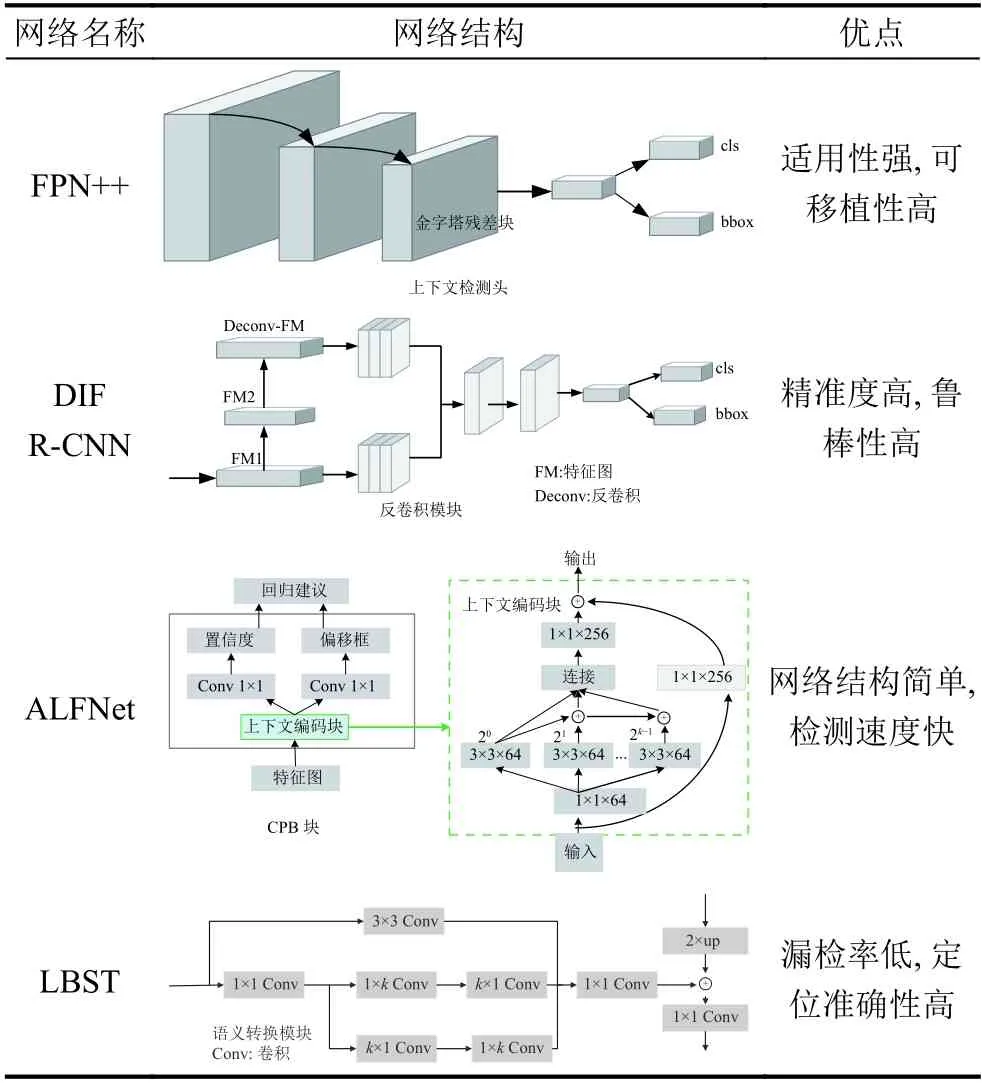
表2 上下文信息方法對比
1.3 基于新的訓練和分類策略的方法
網絡訓練和分類器的性能對檢測器有很大的影響,分類器對行人檢測的精準度起著決定性的作用,不同的訓練策略則影響著分類器的能力. 使用不同分類策略對不同尺度的特征圖進行分類,有助于增強分類器對低像素特征的敏感性,提升檢測器對小尺度行人的檢測和分類能力.
隨著CNN 的在目標檢測上的成功,行人檢測經歷了基于CNN 特征方法和基于端到端的方法兩個階段.復雜性感知網絡(CompACT)通過利用手工特征和CNN 的特性,在每個階段對準確性和復雜性進行權衡[23],先用簡單的特征篩選出行人可能存在的位置,將高復雜性的特征用于級聯的后期. 訓練用于檢測不同尺度行人的分類子網絡,對于增強檢測器處理低像素行人的能力非常有效. 而在文獻[24]中研究發現Faster RCNN 中的區域提議網絡(RPN)作為一個獨立的行人檢測器表現良好,但在下游分類器中由于小尺度行人的影響導致性能降低. 因此他們提出的RPN+BF 方法,在共享的高分辨率卷積特征地圖上訓練級聯增強森林分類器,充分挖掘小尺度行人的特征,不受預訓練網絡結構的限制. 在F-DNN 中,不再使用單個的下游分類器而是利用多個并行的深度分類器結合軟過濾器來進一步驗證每個建議[25].
Zhang 等人考慮到行人身體形狀的不對稱性,提出了一種用于小尺度行人的非對稱多級網AMS-Net[26].檢測過程中網絡根據行人體型設計了非對稱卷積來捕捉行人身體的緊湊特征,并采用非對稱錨框來生成矩形建議. 而Song 等人[27]研究發現大部分方法都過于依賴訓練集的標注,而標注不精準則會影響檢測性能.于是他們提出了一種基于拓撲線定位的方法如圖3 所示,通過建立不同尺度行人拓撲信息作為標注用于訓練階段,同時利用聚集相鄰幀的特征獲取時間信息,可以自動適應小尺度行人.

圖3 TLL 拓撲標注方法
此外,行人檢測有兩種主要方法即目標檢測和語義分割,這兩種方法本質上具有一定的相關性. 目標檢測在定位對象時表現良好,但缺乏對象邊界的信息. 而語義分割在區分類之間的像素邊界方面表現得很好,因此,另一種思路是利用語義分割來提升檢測和分類的準確性,并且已經取得了很好的性能.
文獻[28] 提出了一種分割注入的兩階段網絡(SDS RCNN),在頂層網絡中增加一個語義分割分支,并在訓練期間注入語義信息,將語義分割作為行人檢測輔助信息與區域檢測結合,優化下游行人檢測器.SDS-RCNN 只是增加了語義分割分支,并沒有將語義分割結果直接用于行人檢測. 而SSA-CNN 從具有不同分辨率的多個網絡層執行語義分割[29],將各種尺度粒度的語義信息集成到共享的特征映射中,給檢測提供像素級的分類信息,提高對小尺度行人的分類能力.
基于訓練和分類策略的方法采用不同的訓練方法和分類器,以最終獲得更適用于小尺度行人的檢測器.所設計的訓練分類策略需滿足檢測器對各種場景的適應性,并且研究發現將多種計算機任務如目標檢測、語義分割等結合起來用于行人檢測,會得到更加豐富的信息從而會大幅度的提高單獨任務的精準度.
1.4 基于尺度感知的方法
由于特征不足及感受野不匹配導致網絡發生了漏檢是小尺度行人檢測效果差的主要原因之一. 在其他方法中,不同尺度的行人被網絡進行統一檢測. 然而,不同尺度的行人之間有著巨大的類內差異,比如,大尺度行人有著豐富的細節信息,而小尺度行人往往模糊不清. 為了解決行人間的類內差異問題,有些方法采用“分治”的思想,充分利用不同尺度實例下的顯著特征. 具體來說,網絡將不同尺度的行人分開處理,分別捕獲特定尺度下的特征從而實現檢測特定范圍尺度下的實例.
為解決行人的類內間差距,SAF RCNN[30]的規模感知模型將大、小尺度行人作兩個檢測任務在兩個子網絡中完成,根據建議的高度設置不同尺度子網絡的權重,并采用一個感知加權層來融合檢測結果作為最終的輸出結果. 但由于SAF RCNN 僅利用最后一層卷積檢測行人,使得小尺度行人檢測沒有達到最好的性能. 對此,Han 等人提出了一種小規模感知網絡SSN,充分利用卷積層來提高檢測性能[31]. 為了生成更有效的檢測小規模行人的建議區域,提出了一種尺度建議網絡. 該方法將不同的卷積層與反卷積合并,獲得每個特征點描述更詳細的特征圖,尺度建議網絡用于生成一些更有利于捕捉小尺度對象的建議區域. 而在文獻[32]的GDFL 方法中,如圖4 所示,使用尺度感知的行人注意模塊和放大-縮小模塊(ZIZOM)來實現了更穩定的行人檢測. 他們將細粒度的注意力掩膜編碼加入到卷積中構成注意模塊來引導檢測器聚焦行人區域,而放大-縮小模塊則去探索豐富的上下文語義信息和本地細節,以進一步減輕對小尺度目標的檢測.

圖4 GDFL 框架
基于尺度感知的方法將不同尺度上的行人視為不同的子類別,讓網絡擁有相對獨立的執行小尺度行人的檢測,使得在整體檢測過程中避免漏檢情況的發生.
1.5 基于超分辨率的方法
超分辨率方法旨在提高原有圖像的分辨率,精細的細節信息對于對象實例的檢測和定位至關重要. 對于小尺度行人具有覆蓋像素少、分辨率低的特點,最初的方法通過簡單的對圖像和特征圖進行上采樣處理,這樣也許有效但也可能會造成偽影等其他問題,小目標對象可能仍然會模糊不清、難以檢測.
因此,一些方法試圖通過生成超分辨率圖像進行檢測,與用二次插值等方法重新調整大小生成的圖像相比,超分辨率圖像更清晰,包含更詳細的信息,這些圖像的特征圖包含足夠的信息來區分它們和背景. 由Pang 等人提出的用于檢測小規模行人的JCS-Net,將分類任務和超分辨率任務集成在一個統一的框架中[33],旨在利用大規模行人和相應的小規模行人之間的關系來幫助恢復小規模行人的詳細信息,從而提高檢測小規模行人的性能. Wu 等人開發了一種模擬方法來增強小尺度行人的表示[34]. 他們構造了一個SML (selfmimic learning)組件來改善小尺度行人的檢測性能,通過強制小尺度行人模擬學習大規模行人的特征來豐富和增強自身的表示.
近年來,生成對抗網絡GAN 在合成圖像方面也顯示出了巨大的優勢,可以很好地應用于小物體檢測. 生成對抗網絡有兩個子網絡組成,生成器網絡和鑒別器網絡,兩者通過博弈來實現一個更好的圖像生成效果. 最初人們常用GAN 網絡生成更多的圖像以達到數據增強的目的,近幾年,有些研究嘗試利用GAN進行小目標對象的超分辨率重建,并取得了很好的成效.
Li 等人首次將生成對抗網絡應用在解決小目標檢測問題上,并在行人檢測上表現出了很好的性能. 他們構建了一個感知生成對抗網絡(perceptual GAN)為小目標生成超分辨表示[35],由生成器和感知鑒別器兩個子網絡組成. 生成器基于殘差網絡,從淺層特征引入細粒度細節,將小目標的表示增強為能夠提供高檢測精度的超分辨表示. 感知鑒別器的一個分支區分“真假”,另一個分支對生成的細粒度細節的質量和優勢提供指導. 在文獻[36]中發現利用GAN 一步生成小尺度行人的高分辨圖像質量并不是很好,因此他們將原來的超分辨率網絡改進為兩個生成器級聯,第1 個生成器生成粗略的超分辨率圖像,第2 個生成器進一步生成精細的超分辨率圖像. 生成對抗網絡的優勢在于能夠與任意檢測器相結合,不需要進行額外的處理操作.
細節對于對象實例定位至關重要,此類方法嘗試利用不同尺度之間的內在關系,將原始圖像的低分辨率重建為更高的分辨率,旨在將低分辨小尺度對象的表示增強,生成更高分辨更具有細節信息的類似于大尺度對象的特征信息,從而有效提高檢測性能.
2 數據集與方法評估
在過去的工作中,人們對行人檢測技術的探索不僅限于方法上的研究,許多組織機構還提供了一些用
于評價性能的數據集和基準.
2.1 行人數據集
眾所周知,全面且豐富的數據集能夠推動計算機視覺的發展. 行人數據集如表3 所示,主要分為早期行人數據集和現代行人數據集. 早期的行人數據集相對較小,主要基于傳統方法使用,如MIT[37]、INRIA[38]、Daimler[39]等. CrowdHuman[40]和EuroCity[41]是最新發布的數據集. 目前,主流的行人檢測數據集主要有3 個:Caltech、KITTI[42]和CityPerson[43]. 這3 個數據集在數量上呈現了更大的規模,具有更完整的標注信息和更好的標注效果,并且包含了遮擋和多尺度場景,因此應用更加廣泛. 表3 總結了這3 個行人數據集.
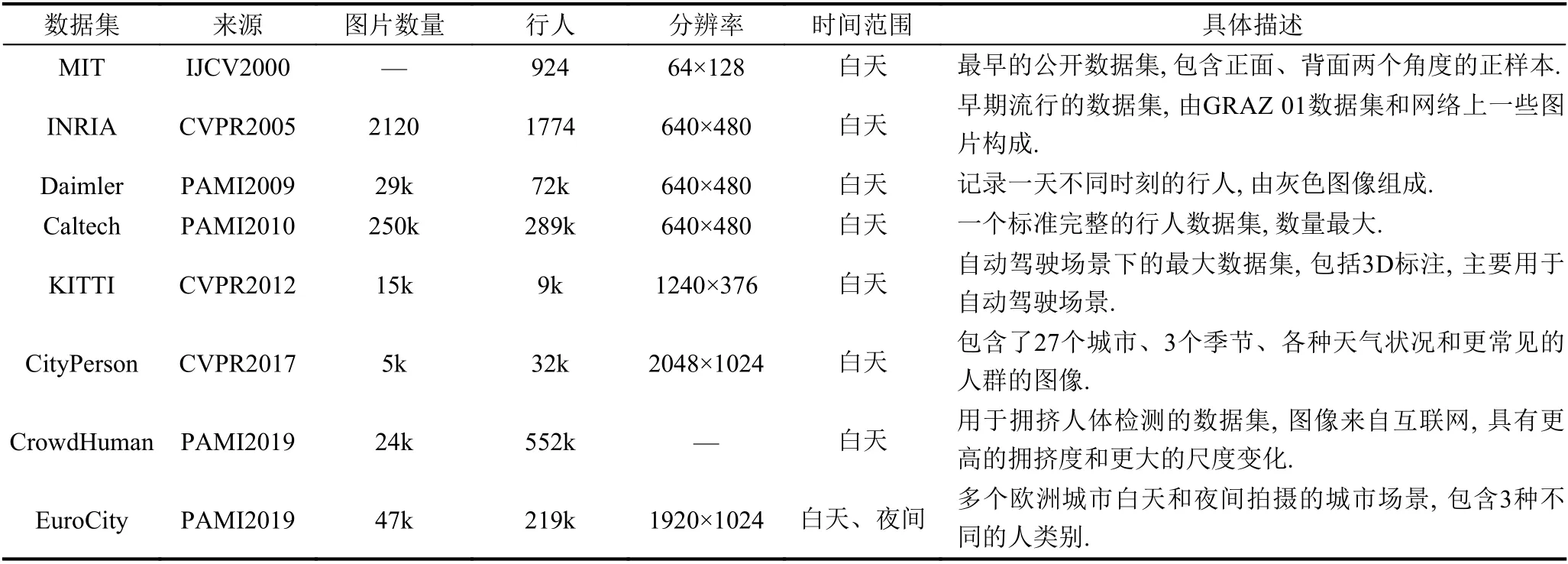
表3 行人數據集概要
Caltech 數據集是在一輛駕駛在洛杉磯不同街道的汽車所拍攝的約10 個小時的11 段行駛視頻中提取的,是最完整的行人檢測基準之一. 其中前6 個視頻用于訓練,后5 個視頻用于測試. 數據集相較于以往的數據集提升了兩個數量級的樣本,并且數據集還詳細標注了包圍盒和遮擋標簽,圖像間具有時間對應關系. KITTI是自動駕駛場景下的數據集,包含市區、鄉村和高速公路等地區采集的180 GB 真實圖像數據,每張圖像中最多達30 個行人,并且數據集的行人比例變化很大(從25 像素到300 像素的高度). 二維目標檢測任務包含汽車、行人和自行車3 大類,評估分為easy、moderate和hard 3 個層次. CityPerson 是在城市街道場景中建立的行人數據集. 相較于前兩個數據集都是在一個城市記錄的,該數據集匯集了27 個城市的街道場景,注釋也更具有多樣性. 它包含2975 幅訓練圖像和500 幅驗證圖像,以及1575 幅測試圖像.
2.2 評價指標
評價一個檢測器的檢測能力需要由相應的評價指標來體現的,一個好的評價標準對于性能檢測來說至關重要. 目前,行人檢測器性能的評估是基于其在數據集上的表現. 現在流行的行人檢測的評價指標有兩個:MR-FFPI和MR?2.
MR-FPPI(miss rate versus false positives per image)曲線以單幀評估的方式更加適合行人檢測的評價指標. 通過改變檢測置信閾值,可以在對數空間中繪制每幅圖像的誤檢率(FPPI). 給定一個檢測置信度閾值,誤檢率(MR)可以通過真陽性數(Ntp)和 基礎真值數(Ng)來計算:
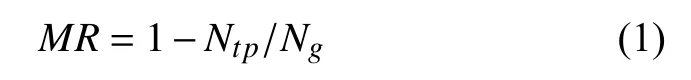
而FPPI可以通過將誤檢數量除以圖像數量來計算.
Log-average miss rate (MR?2),對數平均誤檢率常用來總結檢測器的性能,并作為結果對比的參考. 計算方法是在對數坐標下,從[0.01,1] 區間內均勻的取9 個FPPI值并計算FPPI對應的9 個miss rate 值的平均值MR?2,較低的MR?2反映了更好的結果.
表4 和表5 中展示了一些經典的模型在KITTI和CityPerson 數據集上的檢測結果. KITTI 數據集包含了大量不同尺度的行人,更具有挑戰性. 如表4、表5所示,主流算法在KITTI 數據集上的檢測性能均低于CityPerson 數據集. 表4 對算法的平均檢測精度進行統計,在easy 子數據集中,MHN-D 算法精度最高達到85.81%,實時性也差強人意; AMS-Net 算法檢測速度最快,其檢測精度也十分理想; 在mid 子數據集中,MHN-D稍遜于MS-J 都達到了74% 以上的精度,相較于在easy 子集上的表現,算法精度都降低了10%左右; 而在hard 子數據集中,不同算法的檢測精度之間差距縮小,MS-J 取得了最佳性能. 表5 對算法的誤檢率進行統計,算法整體都實現了較高的精準度,SML 方法在兩個子集上均達到了最低的錯誤率.
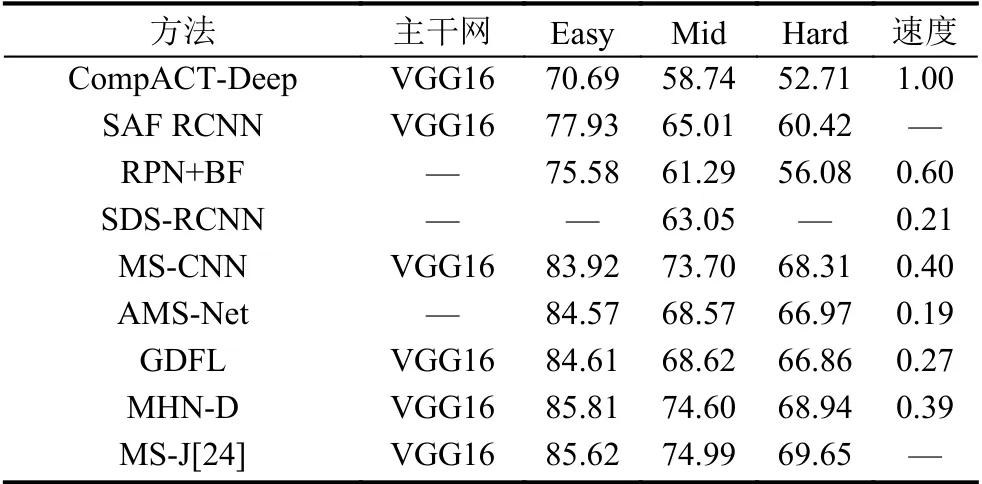
表4 不同方法在KITTI 數據集上的平均檢測精度(%)
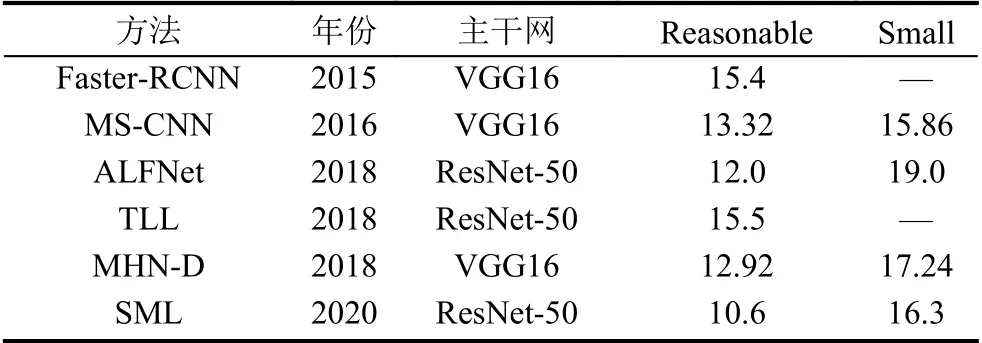
表5 深度學習方法在CityPerson 數據集上的檢測情況(MR–2)
圖5 分別展示了算法在加州理工學院數據集中reasonable 子集和small 子集上不同方法的檢測結果.對于reasonable 子集,不同算法準確率之間差異較小,但在small 子集上所有算法的精度都有一個大幅度的下降,且算法間差距也逐漸變大,證實了小規模行人的存在是當前行人檢測算法的主要瓶頸之一. 而相對于TA-CNN[44]、DeepParts[45]、UDN+[46]算法,SAF RCNN 等在兩個子集上都有著更好的表現,其中TLL實現了最優性能. 同時比發現,同種方法在不同數據集上訓練所展現出的性能存在一定的差異,數據集的選擇對檢測器的性能也產生一定的影響.
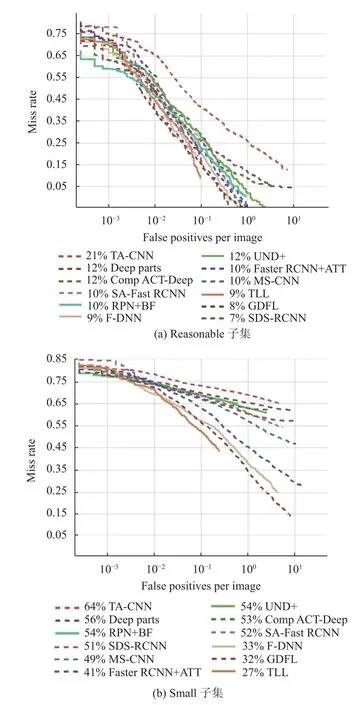
圖5 不同深度學習算法在Caltech 上兩個子集的表現
2.3 方法評價
目前小尺度行人檢測需要研究的核心的問題是如何讓行人的特征表達包含更多的語義信息,這實質上對提高檢測性能起著至關重要的作用. 前面所介紹和討論的解決小尺度行人檢測問題的解決思路也主要是圍繞小尺度行人的特征表示展開的. 并且5 類方法的側重點也有所不同,多尺度表示和上下文信息著手于主干網絡產生的特征圖,而訓練和分類策略以及尺度感知方法則側重對訓練和檢測過程的改進. 基于超分辨率的方法旨在對圖像的恢復及重建,相對于其他方法來說更直接和可觀. 表6 對深度學習中的5 種方法進行對比和分析.
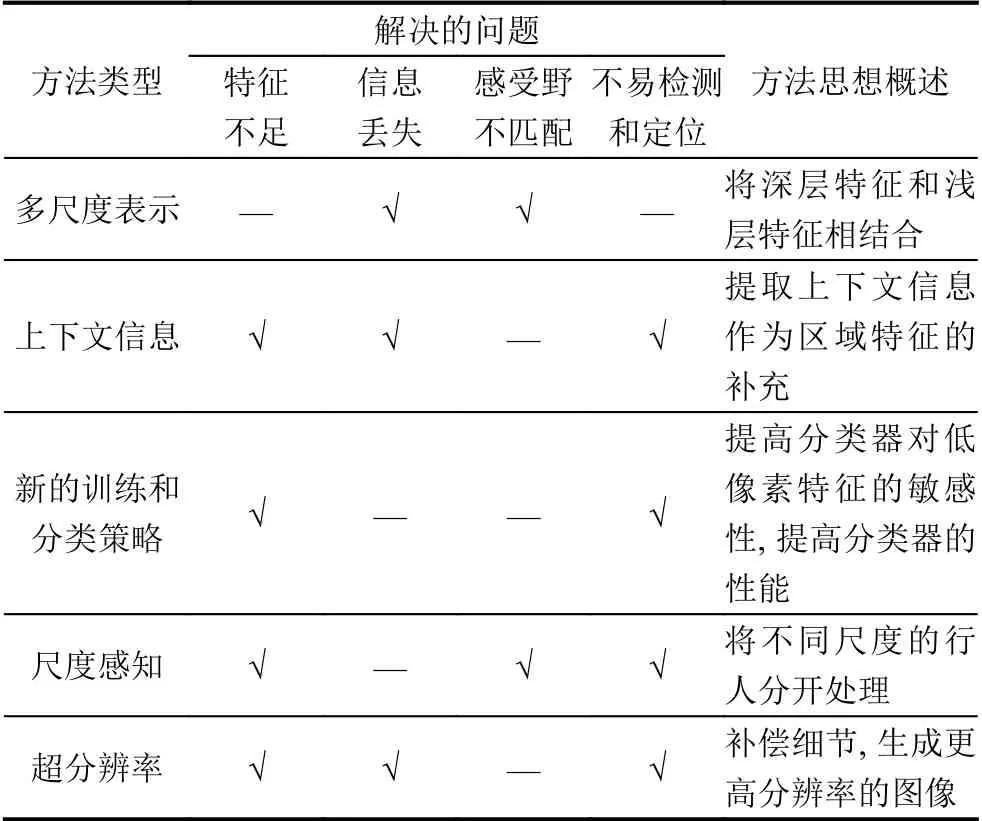
表6 5 種方法對比
(1)基于多尺度表示的方法是處理小尺度和多尺度問題最典型和有效的方法. 但該類方法在提高性能的同時會不可避免的增加計算負擔,因此如何實現準確性和復雜性之間的良好平衡需要更進一步地去探索.目前,處理小尺度行人的大多數方法都基于FPN 進行適當調整和改進作為檢測網絡的基本架構.
(2)上下文信息是近幾年的一個研究熱點,很多方法會利用上下文信息作為輔助信息,但需要注意的問題是并不是所有的上下文信息都有效,因此需要對如何有效控制環境信息的傳遞進一步研究.
(3)在基于訓練和分類策略的方法中,進行多任務聯合學習是一個很好的方向. 同時采用多個計算機視覺任務可以獲得更豐富的信息. 因此如何有效地利用多任務聯合學習和優化來提高小尺度行人檢測的性能是未來的一個研究重點.
(4)基于尺度感知的方法對于小尺度行人檢測是有效的,其關鍵在于如何準確劃分不同尺度的行人,以獲得更多的小尺度行人建議.
(5)基于超分辨率的方法是近幾年解決小尺度行人檢測問題的一個新的發展方向. 該類方法目前主要大多基于GAN 網絡,無需設計特定的架構,最大的挑戰在于GAN 很難訓練,因此如何在生成器和鑒別器之間實現良好的平衡是未來需要探索的方向.
3 結論與展望
行人檢測是計算機視覺中一個重要且具有挑戰性的任務,在取得巨大進步的同時也伴隨著很多問題的產生. 本文針對小尺度行人的檢測所面臨的挑戰進行了剖析,并對小尺度行人檢測方法分類討論. 當前多尺度表示、上下文信息、不同的訓練和分類策略、尺度感知、超分辨率5 種策略在解決小尺度行人檢測問題上均取得了不錯的成績,并且具有很好的發展前景.
盡管行人檢測技術已經取得了較大的進展,但目前仍存在很多的問題亟待解決,主要包括:
(1)缺乏檢測數據集和基準: 在一定程度上,深度學習的性能是通過大量的數據提升的. 像在廣泛使用Caltech 數據集中,“小”對象類中的許多對象實例占據了圖像的很大一部分. 為了更好地評估小目標檢測算法的性能,需要專門用于小目標檢測的大規模數據集,因此,建立大規模的小尺度行人目標數據集和相應的基準是行人檢測領域的一個研究方向.
(2)多變化融合問題: 在實際應用場景中,小尺度問題和遮擋問題大多同時存在,并且天氣、光線等也會給檢測帶來影響. 目前大多數的方法只針對于單個問題的進行改善,因此,有必要進一步研究更加具有魯棒性的檢測算法處理融合的多變化問題.
(3)行人多姿態問題: 目前行人檢測對象多為直立行人,當前技術對于識別一些特殊的行人狀態,如坐、蹲、騎等比較困難. 因此,有必要深入挖掘多模態行人的共同特征,以增強行人檢測器的泛化能力.
(4)檢測實時性問題: 現有的行人檢測方法大多側重于提高檢測精度,而忽略了效率. 而應用在駕駛/監視場景中時,設備的計算資源有限,同時還需要達到實時檢測的速度要求,從而來滿足實際應用的需求. 因此,有必要對嵌入式設備的輕量化和實時行人檢測方法進行研究.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
海峽科技與產業(2016年3期)2016-05-17 04:32:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
