基于關鍵字的數據元語義描述方法
2022-07-29 03:31:48胡青寧董金平李婷玉蘇宏偉
東北石油大學學報 2022年3期
胡青寧, 董金平, 李婷玉, 田 源, 蘇宏偉
( 1. 中國石油冀東油田分公司 勘察設計與信息化研究院,河北 唐山 063004; 2. 中國石油冀東油田分公司 科技信息處,河北 唐山 063004 )
0 引言
中國石油開展石油數據湖建設,統一管理上游業務油氣勘探開發領域的數據資產。石油數據湖由主湖和區域湖構成,主湖負責統一管控和公共數據管理,區域湖負責區域性數據存儲及服務[1]。區域數據湖不僅要管理主湖范圍的業務數據,還要管理大量油田自建數據庫系統。油田區域數據湖中的數據庫具有多源性、多層級、多維度的特點,沒有定義統一的行業領域數據標準,因此不同數據庫、不同層級的管理、不同角度的應用采用的數據相關術語、數據項標識有較大差異,存在大量同名異義、異名同義的數據項名稱,導致出現數據錯誤引用、數據查找難、數據理解難等問題,給數據的管理和使用帶來困擾。
為解決數據標準化,ISO發布系列標準ISO/IEC 11179-1~6,對數據元的框架、分類、模型、定義、命名、注冊等進行規定[2],并持續性改進,國家標準GB/T 18391系列等同樣采用該系列標準[3]。石油行業標準和中石油企業標準也發布數據元設計原則[4]和數據元設計指南[5]。目前數據元相關的標準主要從數據的規范化命名表達數據元的語義,在中文數據項名稱的規范作用上有限[6]。
數據元語義描述方法可用數據元的概念繼承關系和關聯關系表達概念的語義。文獻[7]利用語義泛化層級表達數據元語義,根據中醫臨床癥狀術語描述特點,研究中醫臨床癥狀數據元提取的方法、路徑和原則,并給出符合實際應用的三層提取模型,從概念層、通用數據元層、應用數據元層提取數據元。文獻[8]利用數據元構建通用領域知識圖譜,提出一種綜合相似度計算與知識圖譜融合的語義查詢擴展算法。文獻[9]提出一種基于數據元的數據集成方法,通過對概念的內涵進行形式化的語義描述,可以實現不同模型之間模型級與實例級的語義映射。概念表達語義受上下文語境影響,隨概念外延的擴展,容易產生歧義。為了更加規范、準確地描述數據元的內涵語義,文獻[10-11]提出數據元語義樹,將領域本體概念及概念之間的關系作為語義樹節點和邊,表達數據元特性詞、對象詞、限定詞及之間的關系,并定義基于語義樹結構的語義計算方法。基于數據元語義描述方法,文獻[12]進一步擴展到數據模型的語義描述,將數據模型中實體的語義環境表達為語義樹,與實體的各屬性語義樹共同表達實體的語義。基于語義樹的數據元語義描述方法需要構建語法嚴格的樹形結構,同時依賴預先建立的領域本體,增加語義描述的復雜度和構建成本。
關鍵字研究多集中在搜索引擎、自然語言處理、圖像處理等領域。如基于結構化數據和非結構化數據包含大量語義信息,LOU Y等[13]通過計算語義信息的信息熵確定關鍵詞的語義相關性,利用關鍵詞與語義的相關度,構建基于信息熵的語義模型,從而提高搜索結果的準確性。文獻[14]提出一種利用語義信息改進關鍵字檢測的自動抽取摘要方法,通過對句子進行聚類識別源文檔中的主要主題增加覆蓋率,通過檢測聚類中的關鍵字提高精度。NGUYEN N V等[15]提出圖像—關鍵字的雙向轉換關聯模型,基于處理圖像表示的最先進的詞袋模型,表示語義概念和視覺特征之間的關聯,使用交互式增量學習策略不斷更新關鍵字視覺表示模型。在數據元語義表示上,使用關鍵字的研究相對較少,主要集中在數據元的語義計算方法上,如數據元語義相似性、相關性、數據映射等。文獻[16]綜合考慮語義相似度和語義關聯度的概念語義相關度計算方法,提出一種基于數據元語義樹的概念語義相關度計算方法。文獻[17]利用語義相似度算法進行數據元間的相似性、一致性的檢查,搜索數據元間的匹配關系,建立數據模型間的屬性級的映射關系。文獻[18]提出一種數據項與數據元匹配算法,計算數據項與數據元的相似度,實現數據項與結構化數據項的映射。
針對語義樹描述數據元語義具有較高的復雜性和關鍵字描述數據元語義的研究缺乏,筆者提出一種簡易的數據元語義描述方法。首先,分析基于語義樹的數據元語義描述方法中語義樹構建與應用的特點;然后,給出基于關鍵字的數據元語義描述方法與匹配算法;最后,構建油田區域數據湖的數據元字典及數據模型映射,驗證該方法的有效性。
1 語義樹方法
數據元是基本的、不可分割的數據單元,用一組屬性描述其標識、定義、允許值和表示[2]。在數據元的相關規范中,數據元的語義通過三種方式進行定義或擴展。首先,通過規范的名稱,明確表達數據元的語義;其次,以文字方式說明數據元的含義、使用方式等。此外,通過數據元的數據類型、管理模式等外部信息側面表達數據元語義。數據元標準專門規定數據元的語義規則[6]:
(1)對象詞是對現實世界事物的抽象描述。一個數據元只有一個對象詞,如井、水管、設備、管柱。
(2)特性詞是對象特性的描述。一個數據元只有一個特性詞,如長度、深度、外徑、內徑、尺寸、壓力、產量。
(3)限定詞根據主題域需要添加,添加限定詞后,其修飾的主詞在指定上下文中唯一。一個對象詞或特性詞可以有多個限定詞,限定詞無順序要求。此外,限定詞可以擁有自己的限定詞,如懸掛尾管、回接尾管、下入深度、年產量。
(4)表示詞用來描述數據元素值呈現的方式。一個數據元只有一個表示詞,如噸作產量的表示詞時,用“噸”而不用“桶”。
數據元采用對象詞、特性詞、表示詞、限定詞等語義元素對名稱規范命名是按照英文的語法結構定義的,不適合中文環境,因為中文語法結構不完全等同于英文,中文沒有空格對各詞進行分隔,且分詞不同,造成語義也不相同[19]。時貴英、文必龍等提出利用語義樹描述數據元語義[9-10]的方法,將數據元名稱中的語義元素,按照元素之間的限定或修飾關系,使用語義樹的方式表達為樹形結構(見圖1)。
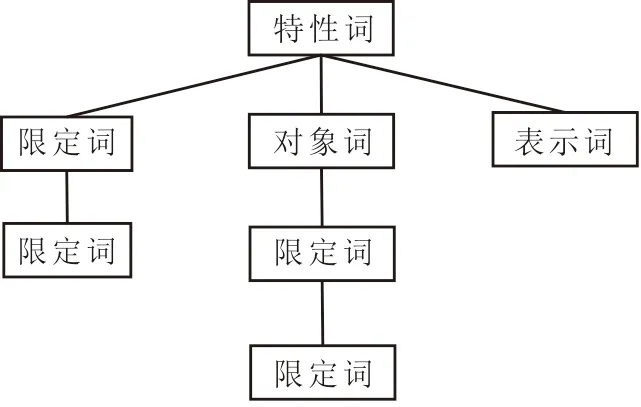
圖1 數據元語義樹結構Fig.1 Structure of data element semantic tree
構建數據元語義樹包括兩個基本元素:一是語義樹中的節點,由對象詞、特性詞、表示詞、限定詞及約束條件構成;二是節點之間的連線,表示節點對應詞匯之間的限定關系。在定義語義樹的過程中,節點名稱與節點關系的梳理復雜,文獻[8]采取從領域本體獲取相關內容,將一個數據元的語義樹看作一個領域本體的子集,通過裁剪領域本體生成語義樹。分析基于本體構建語義樹的方法主要受三方面限制:
(1)語義樹中的節點來自領域本體的概念;
(2)語義樹中的節點之間的連接關系來自于領域本體中概念之間的關系;
(3)語義樹中的約束條件節點需要遵循相應的語法規則。
如果解除限制(1)(2),除節點名稱及連接關系的規范性外,并不影響對數據元語義的定義和理解;對限制(3)將約束條件修改為對約束節點的限定詞,不影響節點的語義。
1.1 數據元描述
通過對數據元語義樹結構與構建特點分析,提出一種基于關鍵字的數據元語義描述方法。
定義對任一數據元e,e的語義可以表達為一個關鍵字集合K(e),稱K(e)為e的語義關鍵字集,即
K(e)= {pty, obj, pre}∪Qobj∪Qpty∪C。
其中,pty為e的特性詞;obj為e的對象詞;pre為e的表示詞;Qobj為obj的限定詞集合;Qpty為pty的限定詞集合;C為約束條件中的常數值集合。按照語義樹定義,約束條件可以表達為邏輯條件表達式,如數據元“新井日產油量”中,約束條件可以用“井的計產類型=‘新井’”或用“井的投產日期>新井計算日期”表示。
將C中的常數值作為相應的限定詞劃分到Qobj與Qpty中,把pre劃分到Qpty,得出進一步簡化結果,即
K(e)={pty,obj}∪Qobj∪Qpty。
實際應用中較少有復雜的約束條件,并且約束條件表達式中通常有常量和屬性,應用中大多忽略屬性,如“新井日產油量”的新井,每年統計時條件相同,但在油田都知道新井的含義。因此,可以把約束條件中的表達式直接用其中的常數替代,不會影響數據元表達的語義。此外,為了將數據元的語義直觀化,便于理解,將K(e)中關鍵字及關系表達為語義樹(見圖2)。
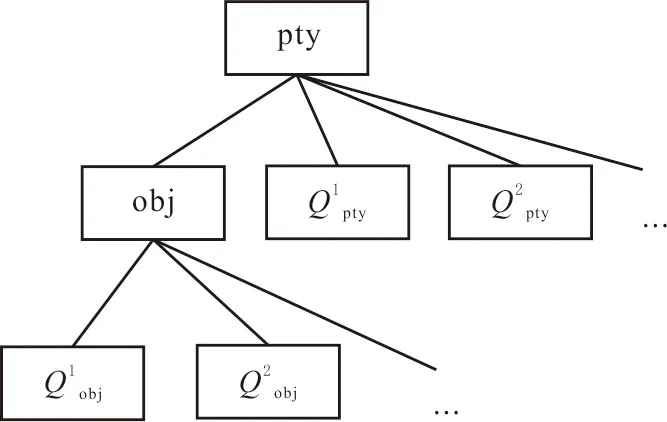
圖2 基于關鍵字的數據元語義樹Fig.2 Data element semantic tree based on keywords
基于關鍵字的數據元語義存儲示例見表1。
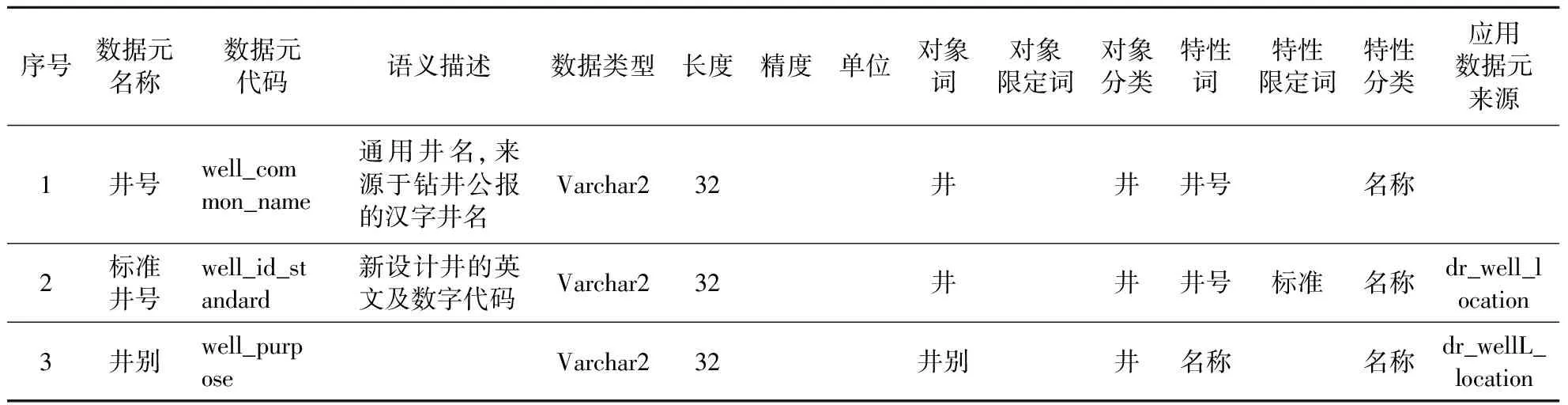
表1 基于關鍵字的數據元存儲示例
比較基于關鍵字的數據元語義樹和基于本體的數據元語義樹,結果見表2。在簡潔性、理解性和靈活性上,采用關鍵字描述數據元的方法比基于本體的描述方法占有一定優勢,適合工程化應用。

表2 數據元語義描述方法特性比較
1.2 數據模型
基于數據元描述數據模型的語義,是為數據模型中實體的屬性指定一個數據元,確認采用指定數據元的定義,包括語義、數據類型等[12]。
定義實體r(a1,a2,…,an)的語義用關鍵字表示為
K(r)=Qr∪K(a1)∪K(a2)…∪K(an)。
其中,ai為r的屬性;Qr為r的應用場景的關鍵字集;K(ai)為屬性ai的語義關鍵字集。
定義實體r(a1,a2,…,an) 的任一屬性ai的語義用關鍵字集表示為
K(ai)={pty,obj}∪Qobj∪Qpty。
其中,pty、obj、Qobj、Qpty與數據元中定義相同。
在企業應用環境中,數據元通常采用數據元標準化字典進行定義,具有企業領域范圍內的通用性。數據模型是對企業的具體應用場景定義,具有一定的特殊性。在許多場合下,并不能為數據模型中的所有實體屬性找到對應的數據元。在無法為實體屬性找到對應的數據元時,需要利用數據元概念的泛化層級性,通過數據元關鍵字擴展描述實體屬性的語義。數據元按概念的泛化層級分為數據元概念、通用數據元、應用數據元。
數據元概念(Data Element Concept)是與數據元具體表現形式無關的數據元。在語義上,數據元概念不包含表示詞[2]。如“日產油量”是數據元概念,因為產油量可以用“噸”表示,也可以用“桶”表示,沒有指定表示方式,因此是數據元概念。通用數據元是適合不同應用場景的數據元,應用數據元是與具體應用場景相關的數據元。通用數據元與應用數據元是相對于一定的應用環境而言的,二者之間并沒有本質的區別,只是應用場景大小的問題。應用數據元是通用數據元在應用場景下,進一步限定后生成的數據元,通用數據元可以看作被泛化的應用數據元。數據元、通用數據元和應用數據元之間的關系用數據元的語義關鍵字集表示為
K(e2)=K(e1)∪pre∪Q2,K(e3)=K(e2)∪Q3。
其中,一個數據元概念e1加上表示詞,可以演化為通用數據元e2。通用數據元e2加上應用場景約束,可以演化為應用數據元;K(e1)、K(e2)分別為數據元e1、e2的關鍵字集合;pre為表示詞;Q2為描述數據元e2的應用場景的關鍵字集,是一組限定詞或約束條件;Q3為描述數據元e3的應用場景的關鍵字集合,是一組限定詞或約束條件。通過Q3進一步特化e3的應用場景。
實體的屬性與數據元是定義數據的基本單元。數據元的語義中已經包含應用場景的定義,不需要再單獨指定應用場景,每一個數據元都具有完整的語義,如數據元“采油廠日產油量”的語義是完整的。實體的屬性需要依賴所屬實體的環境表達,如“采油廠日報數據”中的屬性“產油量”表示“采油廠日產油量”,而在實體“采油廠月報數據”中,屬性“產油量”表示的是“采油廠月產油量”。按數據元的層級性,實體的屬性可以用通用數據元和應用數據元表示。
由于實體的應用場景可以轉化為屬性的應用場景,因此利用數據元e表達實體屬性a的語義,有三種情況:
(1)當ptya=ptye,obja=obje,且a與e的應用場景一致時,直接用數據元表達屬性的語義,即
K(a)=K(e)。
(2)當ptya=ptye,obja=obje,且a的應用場景比e的更小時,K(a)∈K(e) ,通過擴展數據元e的關鍵字表達屬性的語義,即
K(a)=K(e)∪Qa。
其中,Qa為a相對e增加的語義約束,Qa=K(a)-K(e) 。由于增加更多約束,應用場景的范圍變得更小。
(3)當ptya=ptye,obja=obje,且a的應用場景比e的更大時,不能用e表達a的語義。需要定義一個新數據元,通常將a轉換為數據元加入數據元字典。
由于數據元在領域范圍內可以作為標準進行定義,因此利用數據元表達數據模型的語義,可以簡化數據模型的設計及語義描述。
2 數據元語義相似度
利用數據元描述數據模型的語義,關鍵是找到與實體屬性匹配的數據元;同時,異構數據模型自動映射時,需要判斷兩個實體的屬性是否具有一致的語義。前提需要進行數據元語義相似度計算。
在一定程序上,數據元名稱反映數據元的語義[12]。在無法完全保證數據元語義描述完整、準確的情況下,數據元名稱表達的語義對數據元的理解及應用具有指導意義。提出一種綜合數據元名稱及關鍵字集合的語義相似度計算方法。
定義任意兩個數據元e1、e2,其語義相似度為
(1)
式中:dsim(e1,e2)為兩個數據元名稱的相似度;ksim(e1,e2)為兩個數據元的關鍵字集合之間的項集相似度;WD、WK分別為兩個相似度的權重,WD+WK=1。對數據元組成成分與結構分析可知:數據元詞語由語素組成,語素越靠前,作用越小,為它分配的權值越小;語素越靠后,作用越大,為它分配的權值越大[20]。此外,由于油田領域數據元的關鍵字較為短小,具有表達隨意、稀疏性和不平衡性等特性,編輯距離算法作為基于字面進行相似度度量的方法,對短文本的處理具有可行性高、效果好等優點[21]。因此,采用編輯距離計算數據元間語義的相似度。
以中石化數據元字典中1.4×104個數據元為實驗數據,通過不同因數組合發現WD=0.3、WK=0.7[22]時,滿足工程化應用需要。如數據元“油井所屬區塊單元名稱”(設定為M)與數據元“油井所屬區塊單元代碼”(設定為N)在不同因數組合下,計算的編輯距離相似度結果見表3。
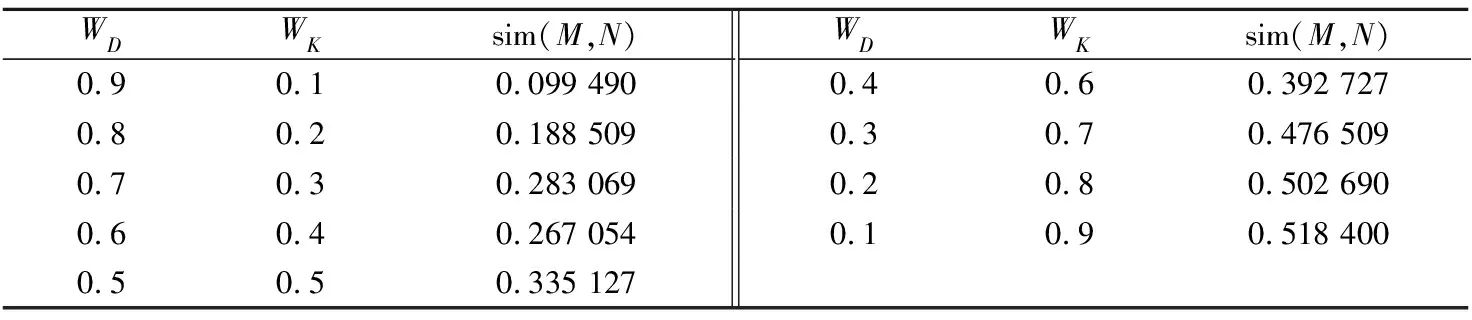
表3 不同因數組合的相似度計算結果
編輯距離算法[16,23]用dist(x,y)表示字符串x轉變到y的最小成本,轉換方式包括刪除、插入和替換字符串。如將字符串x=“累積油產量”轉換為字符串y=“累積地層油產量”的代價是dist(x,y)=2,需要執行的操作依次是在“累積”后面插入一個字符“地”,在“累積地”后面插入一個字符“層”。x和y的轉換操作是對稱的,將x轉換為y的代價和y轉換成x的代價是相同的。編輯距離越小,字符串x轉變到y的成本越少,兩個字符串越相似。編輯距離dist(x,y)可用公式轉換為相似度度量函數DSIM(x,y),即
(2)
式中:length為字符串長度函數。兩個數據元e1、e2的項集相似度公式計算為
(3)
兩個集合A、B的項集相似度J(A,B)=AB的交集項個數/AB的并集項個數,即為杰卡德相似度系數(Jaccard Similarity Coefficient)[23]。杰卡德相似度系數是衡量兩個集合相似度的一種指標,交集等于并集,意味著兩個集合完全重合。
以數據元“尾管懸掛下入深度”為例,按照關鍵詞分類,它的對象詞是“尾管”,對象詞的限定詞是“懸掛”,特性詞是“深度”,特性詞的限定詞是“下入”,在數據元字典中匹配到的前10個數據元及相似度計算結果見表4。

表4 數據元相似度計算結果示例
3 區域數據湖構建及應用
在油田區域數據湖建設中,利用數據資源目錄描述油田勘探開發業務及應用系統的數據資源情況,其中數據資源目錄利用數據元作為標準數據和中間橋梁,將業務模型[24]、應用數據模型、存儲數據模型關聯到一起(見圖3)。業務模型與數據元關聯后,可以從勘探開發業務角度掌握某一業務活動采用和產生的數據有哪些,數據由哪些應用系統產生,被哪些系統使用。數據元與存儲數據模型和應用數據視圖關聯后,可實現以數據元為中介的數據模型之間的自動映射。完成應用的基礎是構建數據元字典,并實現基于數據元的數據映射[25]。

圖3 油田區域數據湖中數據元與數據資源的關系Fig.3 The relationship between data element and data resources in oil field regional data lake
數據元字典的構建分四個步驟。
步驟1數據元原始資料收集。將業務模型中的數據項、應用數據視圖中的數據項、存儲數據模型中的數據項收集到數據元字典模板中,每一個數據項作為一個初始的數據元。數據元字典模板由基本信息、來源、語義組成,其中,基本信息包括數據元名稱、代碼、數據類型、長度、精度、計量單位、描述,來源由源模型、源表、源屬性組成,語義由對象詞、特性詞、對象詞的限定詞、特性詞的限定性組成。初始收集時,語義部分為空。收集完資料后,按數據元名稱合并,合并時記錄來源,同時統一數據類型相關信息。合并過程中,對于數據類型無法統一的,需要將數據元重新命名,表達為不同的數據元。
步驟2數據元語義描述。根據數據元來源信息,定義對象詞、特性詞、對象詞的限定詞、特性詞的限定性,主要由人工填寫。過程中,利用數據元名稱的編輯距離相似度,將相似的數據元排列在一起,相互參照,可加速數據元語義定義,同時具有相互校正的作用。
步驟3數據元質量校正。根據數據元語義信息,計算數據元之間的關鍵字項集相似度。對每一個數據元,將與其相似的其他數據元按相似度從高到低排列,依次作為校正的參照數據元列表。校正過程分三種情況進行處理:
(1)同名異義的數據元。將數據元重命名并表達為兩個不同的數據元,修改對應來源部分,依據數據元拆分為兩組填寫。
(2)異名同義的數據元。將兩個語義相同的數據元合并成一個。
(3)語義需要修正的數據元。修改數據元的語義信息。
步驟4確認數據元,并適當修改源頭模型的信息。對數據元名稱、代碼規范化,并按照數據元的規范定義,修改源頭信息。
基于數據元的數據模型映射包括存儲模型之間的映射、存儲模型與應用數據視圖之間的映射。以數據元為中介,通過數據元匹配,自動建立兩個模型間的映射關系。對于不能完全匹配,但有較高相似度的,作為可能映射關系。
在數據湖的建設中,完成12個業務域梳理,采用基于關鍵字的數據元相似度融合方法,構建數據湖數據元字典,約有2.0×104個數據元,比中石化數據元字典增加超過6.0×103個,統計結果見表5。

表5 數據元統計結果
對鉆井、測井、油氣生產、采油工程四個業務域應用數據視圖與存儲數據模型自動映射,對比結果見表6。基于關鍵字的數據元語義自動數據映射,在匹配結果上刪除干擾項,得到唯一對應的數據元,提高數據湖開發效率及應用的準確性和靈活性。
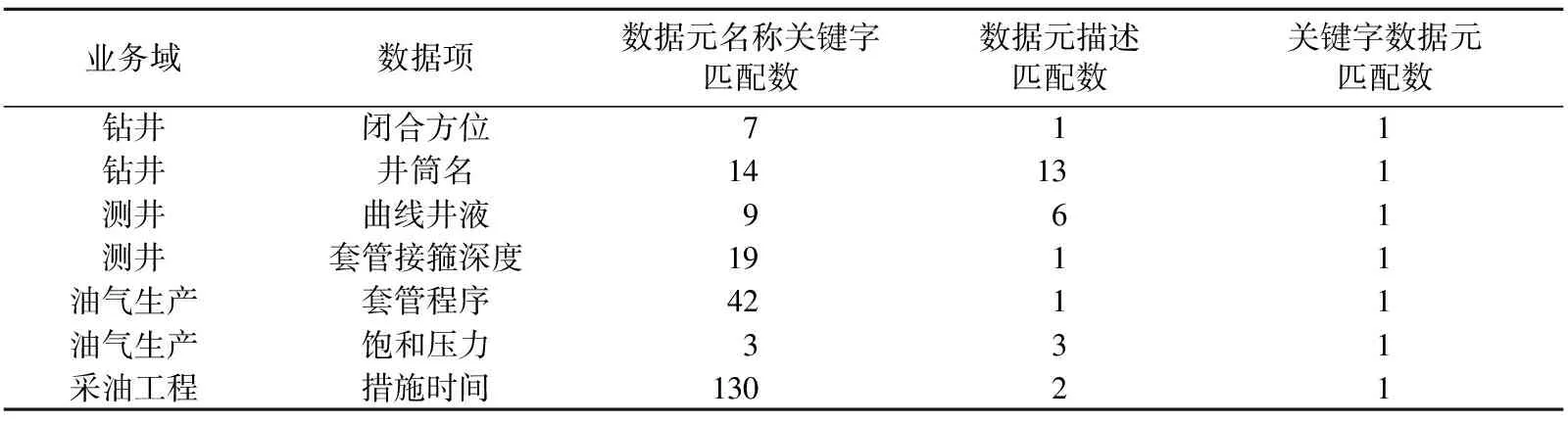
表6 基于數據元的數據模型映射對比結果
4 結論
(1)提出基于關鍵字表達數據元的語義表示方法,給出數據元語義的形式化定義及語義樹定義。由于不需要領域本體作為約束,可用關鍵字自由表達,方法簡單易用。
(2)結合編輯距離算法和杰卡德算法,給出數據元語義相似度計算方法。該方法綜合考慮數據元名稱及關鍵字集合對數據元語義理解的貢獻,適合油田工程化應用,可提高數據模型映射的自動化程度。
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
開放教育研究(2020年2期)2020-03-31 01:54:14
現代語文(2016年21期)2016-05-25 13:13:44
山東青年(2016年1期)2016-02-28 14:25:25
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
