基于衛星視頻影像的車輛提取算法評價
2022-07-29 06:54:04謝曉歡陳仁喜劉世杰
智能計算機與應用 2022年8期
謝曉歡,陳仁喜,劉世杰
(1 同濟大學 測繪與地理信息學院,上海 200092;2 河海大學 地球科學與工程學院,南京 210098)
0 引言
隨著遙感技術的迅速發展,對地觀測衛星的時間分辨率得到有效提升,數據獲取能力也在不斷提高。視頻衛星是一種新型的對地觀測衛星,以視頻的形式獲取擁有高時間分辨率的動態信息,用于運動目標檢測和分析。
運動目標檢測是圖像處理與計算機視覺領域的一個重要研究課題。近幾十年來,研究者們提出了許多基于不同理論的運動目標檢測方法。
20 世紀70 年代末,Jain 等人提出使用幀間差分法(Frame Difference)來提取運動目標。1997年,Wren等人提出利用單高斯模型(Single Gaussian Model)進行背景建模,進而檢測運動目標。1999 年,Stauffer 等人提出了經典的自適應混合高斯模型(Gaussian Mixture Models,GMM),使用加權的混合高斯分布,通過參數來調整背景模型。此后,許多研究者在高斯混合模型的基礎上進行改進,例如:2004 年,Zivkovic 等人提出了混合高斯模型個數自適應的算法。2006 年,Zivkovic 等人從貝葉斯的角度進行改進使其完全自動地適應場景,檢測效果得到改善。
然而,現實條件下的圖像背景變化快速且復雜,有時候不符合高斯分布,故而利用高斯分布的背景建模方法具有許多局限性。
2000 年,Chen 等人提出了同步分割和類參數估計(Simultaneous Partition and Class Parameter Estimation,SPCPE)算法,使用統計學的方法將分割參數和分類參數變量進行聯合估計,用于識別目標及其空間關系。為了得到更精確的提取結果,2003年,Zhang 等人提出了基于SPCPE 算法的自適應背景學習(Adaptive Background Learning,ABL)算法。在此基礎上,2011 年,Ng 等人提出了一種在動態場景中更新背景模型的自適應選擇性背景學習(Adaptive Selective Background Learning,ASBL)算法,增加了動態場景下算法的魯棒性且降低了計算量。
2009 年,Barnich 等人提出了一種名為視覺背景提取(Vision Background Extractor,ViBe)的新背景建模算法。2011 年,通過將一些經典的運動目標檢測算法與視覺背景提取算法進行比較,實驗證明了此算法的高效率。
近年來,基于統計與分析的運動目標檢測方法快速發展,由Cover 等人提出的經典的機器學習算法K-近鄰(K-Nearest Neighbor,KNN)算法也被用于運動目標檢測。
盡管運動目標檢測方法一直都在不斷地改進和發展,但目前沒有任何一種方法能夠適應所有場景。
衛星視頻可以方便地監測城市規模的動態場景,實現許多潛在的應用,研究中的關鍵任務則在于提取和跟蹤衛星視頻中的運動車輛。雖然目前的運動目標檢測算法在傳統地面監控視頻中獲得了較好的效果,但衛星視頻具有不同的特點:
(1)衛星視頻視野廣闊,運動目標非常小,通常只占據幾個像素,沒有任何明顯的顏色或紋理,加上噪聲干擾,原有的技術無法有效地檢測這種微型車輛。
(2)衛星視頻畫面覆蓋的范圍大,提供的動態場景復雜,包括道路、建筑、植被以及各種各樣的交通條件等。
(3)由于衛星的運動,衛星視頻幀的背景呈現亞像素級的不均勻移動。衛星視頻幀本質上是衛星平臺的復雜三維運動在二維平面上的投影,因此衛星視頻的相對運動非常復雜。另外,由于視頻衛星距離地球十分遙遠,在連續的視頻幀之間觀察到的移動非常緩慢,總是亞像素級的。
目前還沒有在衛星視頻中檢測微小移動車輛的技術,適用于傳統場景的運動檢測算法不一定適用于衛星視頻。因此,本文以衛星視頻影像為對象,對現有經典運動目標檢測算法進行定性與定量的評價。
1 運動目標檢測算法
運動目標檢測是指從圖像或視頻序列中檢測出發生動態變化的區域,并將運動目標(前景)與背景分離。常用的方法主要有幀間差分法(Frame Difference)、背景建模法(Background Subtraction)和光流法(Optical Flow)等。
1.1 幀間差分法
幀間差分法是將相鄰2 幀或多幀圖像對應的像素值相減,得到差分圖像,如果對應像素值的變化大于預先設置的閾值,則認為此處是前景,反之則是背景。主要分為兩幀差分法和三幀差分法。對此擬做探討分述如下。
兩幀差分法的算法示意如圖1 所示。兩幀差分法是設相鄰的2 幀圖像第1 幀圖像位置(,)處的像素值為I(,),第幀圖像位置(,)處像素值為I(,),兩者之差小于設定閾值時,判定為背景像素,否則判定為前景像素,用到的數學公式可寫為:

圖1 兩幀差分算法示意圖Fig.1 Schematic diagram of two-frame difference algorithm
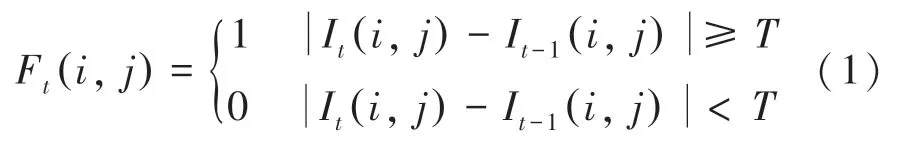
其中,F (,) 表示獲得的二值差分圖像;(,)表示像素所在位置; I(,)和I(,)表示像素值;二值圖像中1(白色)表示前景,0(黑色)表示背景;為設定閾值。
三幀差分法的算法示意如圖2 所示。三幀差分法是對連續的3 幀圖像,用第幀圖像的像素值減去第1 幀圖像的像素值,得到二值圖像(,),再用第1 幀圖像的像素值減去第幀圖像的像素值,得到二值圖像(,),將二者進行“與”運算,得到三幀差圖像(,),研究推導得到的數學公式分別如下:
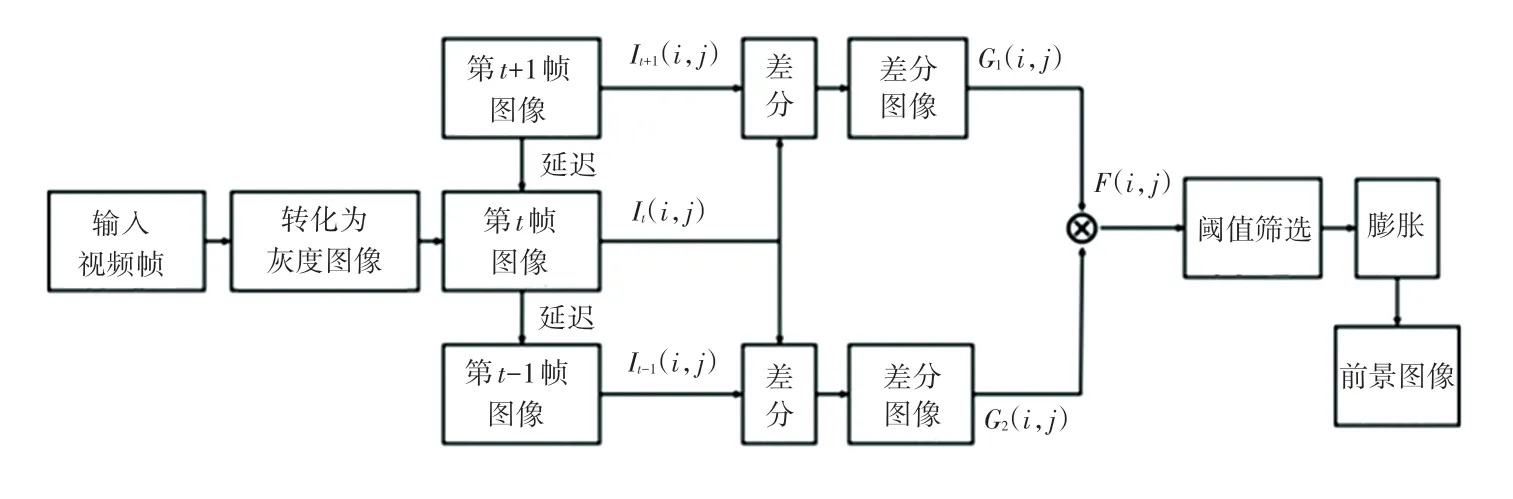
圖2 三幀差分算法示意圖Fig.2 Schematic diagram of three-frame difference algorithm

其中,(,) 為得到的三幀差分二值圖像;(,)和(,)為兩幀差分二值圖像;(,)表示像素所在位置;I(,)、 I(,)和I(,)表示像素值;二值圖像中,1(白色)表示前景,0(黑色)表示背景;為設定閾值。
1.2 高斯混合模型
高斯混合模型(GMM)算法示意如圖3 所示。GMM 算法為每一個像素都建立加權的混合高斯分布,基于高斯模型的期望和方差判斷哪一個高斯模型更可能對應當前的像素,不符合各個高斯模型的像素被判斷為前景,符合的被當作背景。大致分為4 步:模型初始化、模型學習、增加或替換高斯分量以及判斷背景。
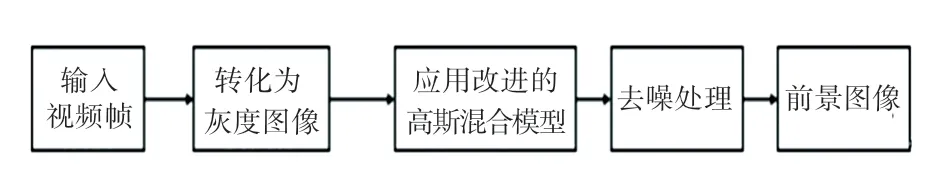
圖3 高斯混合模型算法示意圖Fig.3 Schematic diagram of Gaussian mixture models algorithm
首先,提取在視頻序列幀含有運動目標的圖像,逐個像素求平均值,并將結果作為背景;視頻圖像像素值序列{,…,X} 用個高斯分布描述,每個高斯分布都有權重ω,將每個像素的新像素X與個高斯分布逐個匹配,若某像素的個高斯分布與當前像素值X都不匹配,則剔除權重最低的高斯分布,引入一個新的高斯分布,同時更新個高斯分布的權重。將個高斯分布按照ω/ σ從大到小排列,用前個高斯分布表示背景模型,對此可表示為:
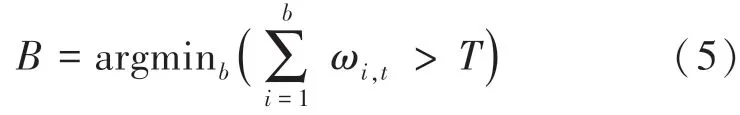
其中,argmin表示加權求和大于的最小值;是判定像素是否屬于背景的最低閾值,即背景閾值。
1.3 K-近鄰算法
K-近鄰(KNN)算法中,選取訓練樣本集,樣本集中每一個數據都有其所屬分類,通過測量待分類樣本到鄰近的訓練樣本集中樣本之間的距離,找到特征空間中距離最近的幾個樣本,根據各類樣本數目多少來決策分類,即待分類樣本所屬的類別就是鄰近樣本中出現次數最多的那個分類。設有個樣本分布到個類中,即為:,,…,ω,每個類有N個樣本,其中1,2,…,。該算法主要分為4 步:
(1)計算待分類樣本與各個鄰近樣本之間的距離。
(2)選取距離最近的近鄰。
(3)確定近鄰出現的頻率。
(4)預測分類。
K-近鄰算法的分類過程示意如圖4 所示。圖4中,為待分類樣本,,,為3 個不同的分類,箭頭表示待分類樣本到各近鄰之間的距離。

圖4 K-近鄰算法分類過程示意圖Fig.4 Schematic diagram of K-Nearest Neighbor classification
1.4 自適應選擇性背景學習算法
自適應選擇性背景學習算法(ASBL)根據每一幀圖像不同部分有不同的動態,為每個像素分配不同的學習率,逐像素更新背景模型,計算當前幀與背景模型的差異,與自適應閾值進行比較,分割前景和背景。
設像素的學習率為α (,),由2 個加權參數,決定,計算公式見式(6):
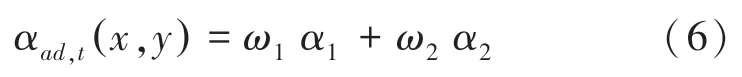
其中,和分別為和的權重,且≤1。
取決于背景模型像素和當前幀之間的差異,差異越大,則越小;取決于像素被分類為背景像素所持續的時間,持續時間越長,則越大。
1.5 視覺背景提取算法
視覺背景提取算法(ViBe)的流程:對于每個像素點,為其建立一個樣本集,選取該像素點歷史像素值和其鄰近點的像素值作為樣本集的采樣值;將每一個新的像素值與樣本集進行比較,預測新的像素值分屬于前景點、還是背景點。
ViBe 算法模型像素樣本集如圖5 所示。圖5中,用()表示在位置處的像素值,隨著時間的推移,該處的背景像素值構成一個大小為的背景樣本集(),數學表達式可寫為:

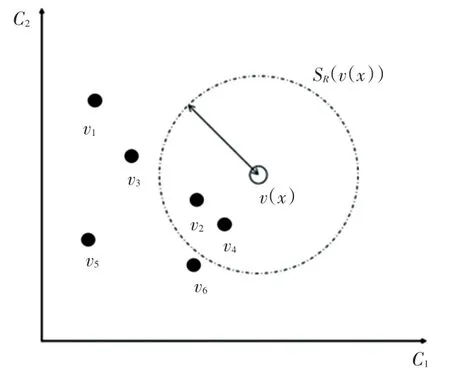
圖5 ViBe 算法模型像素樣本集Fig.5 Schematic diagram of vision background extractor
以當前像素值()為圓心,為半徑,在空間坐標系下構造一個圓球S(()),這個球體與背景樣本集() 的交集的元素個數記為式(8):
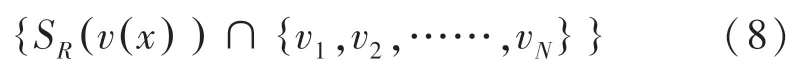
設定一個閾值min,如果上式大于min,那么當前值()就更新為背景,存入背景樣本集()中。
對模型初始化,計算新像素點到背景樣本集() 中樣本的距離,如果距離小于,則該點為近似樣本點,如果近似樣本點的個數多于min,則新的像素點被判斷為背景。遵循時間衰減原則和空間一致性原則,對模型進行更新。
2 算法評價
2.1 評價指標
將運動目標的檢測看作是對每個像素的二分類,結果有4 種,分別是:真正類(True Positives,TP)、真負類(True Negatives,TN)、假負類(False Negatives,FN)、假正類(False Positives,FP)。
評價算法性能常用3 個參數,即:精準率、召回率和分數。文中擬展開剖析論述如下。
(1)精準率()。主要反映檢測的準確性,即被預測準確的正類占所有預測正類的比例,又稱為查準率,定義公式具體如下:
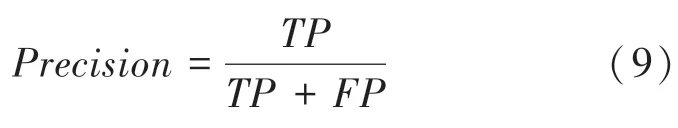
(2)召回率()。主要反映檢測的全面程度,即被預測準確的正類占所有實際正類的比例,又稱為查全率,定義公式具體如下:

(3)分數。精準率和召回率在不同的應用場景下面的關注點是不同的,因而總會出現矛盾,而分數()采用了調和平均數的方式來綜合考慮,因此分數能更好地衡量正樣本的預測效果,分數越大,預測效果越好。定義公式具體如下:
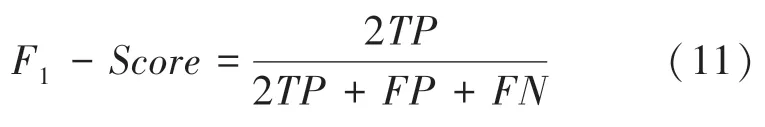
2.2 Ground-Truth 圖
由于視頻分幀后得到的幀數甚多,并且視頻幀中的運動車輛所占像素較小,相鄰幀之間目標的運動多是亞像素級,很難逐幀地人工標注視頻范圍內的所有車輛,權衡標注工作量與標注精度,隨機選取樣本幀進行標注。
首先,將運動車輛檢測結果的二值圖像與對應的單幀圖像疊加,同時將真實運動目標在單幀圖像上用紅色來做標記;其次,人工刪除錯誤的標記結果、添加未標記的目標并補齊“空洞”,制作Ground-Truth 圖用于實驗結果評價。
2.3 噪聲處理
由于噪聲的存在對評價結果會產生較大的影響,因此在進行定量評價之前需要進行處理。首先,設置一個面積閾值,將小于面積閾值的“目標”刪除。為了防止誤刪,面積閾值的設置需要根據實際運動目標在圖像上連通域的大小來進行設置。
為了得到較為客觀的評價結果,本文實驗的面積閾值根據算法不同酌情選擇,盡可能使每一種算法都達到較好的評價結果。
3 實驗與分析
隨機選取視頻幀檢測結果作為評價樣本,設置面積閾值,將小于面積閾值的“目標”認為是噪聲進行刪除,與相應的Ground-Truth 圖進行對比,正確的運動目標標記為紅色,錯誤的標記為黃色,未檢測到的標記為藍色,輸出圖像與評價指標數值。
本文基于6 種算法的結果進行評價,包括自適應選擇性背景學習法(ASBL)、兩幀差分法(Diff2)、三幀差分法(Diff3)、K-近鄰算法(KNN)、高斯混合模型(GMM)和視覺背景提取法(ViBe),從定性和定量兩個角度評價算法的性能。
3.1 SkySat-1 衛星視頻實驗與結果分析
2013 年11 月,美國Skybox Imaging 公司發射了SkySat-1 衛星,是世界上首顆亞米級視頻衛星,可拍攝空間分辨率為1.1 m 的黑白衛星視頻。本實驗使用的衛星視頻拍攝于2014 年3 月25 日,地點為美國拉斯維加斯(Las Vegas)地區局部。選取部分衛星視頻幀作為檢測底圖,6 種車輛檢測結果如圖6 所示。
根據圖6 車輛檢測結果圖定性對比得出,不同的方法都存在一定程度上的漏檢和誤檢。誤檢位置一般集中在建筑物的頂部,主要是由于光線變化、建筑物陰影和高層建筑物的頂端位移,產生了大量的虛假目標。漏檢目標多是小型車輛,在圖像上所占連通域較小,一方面運動檢測算法對微小的運動目標不敏感,另一方面,形態學處理過程中可能會將其誤判為噪聲進行刪除。

圖6 SkySat-1 衛星視頻6 種算法車輛檢測結果Fig.6 Vehicles detection results of six algorithms in SkySat-1 satellite videos
誤檢方面,自適應選擇性背景學習法和視覺背景提取算法得到的結果中存在較大量的虛假目標,尤其是自適應選擇性背景學習法中存在連片的虛假目標區域,誤檢率高。漏檢方面,兩幀差分法和視覺背景提取算法漏檢目標相對較多,而自適應選擇性背景學習法和K-近鄰算法漏檢的目標極少,不過各方法之間的差異并不大,漏檢比例整體可以控制在一個較低的水平。
6 種算法車輛檢測定量對比見表1,算法的精準率整體較低,只有K-近鄰算法的精準率可以達到80%,而其余多數算法精準率都低于70%,這說明各種算法都存在了較多的誤檢目標。除了兩幀差分法和視覺背景提取算法,其余算法的召回率都可以達到70%以上,漏檢目標較少。總體來看,K-近鄰算法的分數可以達到0.8 以上,檢測精確度較高,兩幀差分算法檢測效果最差,整體精度不高。

表1 SkySat-1 衛星視頻6 種算法車輛檢測定量對比Tab.1 Quantitative comparison of six algorithms for vehicles detection in SkySat-1 satellite videos
3.2 吉林一號衛星視頻實驗與結果分析
2015 年10 月,中國長光衛星公司發射了吉林一號視頻衛星組,包含2 顆視頻衛星靈巧01 和靈巧02,可拍攝空間分辨率為1.13 m 的彩色衛星視頻。本實驗使用的衛星視頻拍攝于2017 年,地點是美國亞特蘭大(Atlanta)地區局部。選取部分衛星視頻幀作為檢測底圖,6 種車輛檢測結果如圖7 所示。


圖7 吉林一號衛星視頻6 種算法車輛檢測結果Fig.7 Vehicles detection results of six algorithms in Jilin-1 satellite videos
根據圖7 車輛檢測結果圖定性對比得出,不同的方法都存在一定程度上的漏檢和較少部分的誤檢。
誤檢方面,自適應選擇性背景學習法、兩幀差分法和視覺背景提取算法得到的結果中存在少量的虛假目標。漏檢方面,由于截取的視頻圖像并不清晰,圖像序列中的運動目標面積很小,6 種算法都出現了比較多的漏檢目標,其中高斯混合模型算法和視覺背景提取算法漏檢目標相對較多。
吉林一號衛星視頻6 種算法車輛檢測結果見表2。定量分析可知,K-近鄰算法和混合高斯模型算法精準率可到達90%以上,誤檢較少。自適應選擇性背景學習法和K-近鄰算法的召回率較高,在80%以上,漏檢比例不高。K-近鄰算法的分數可以達到0.8 以上,檢測精確度較高,兩幀差分算法的分數較低,檢測效果相對較差。

表2 吉林一號衛星視頻6 種算法車輛檢測定量對比Tab.2 Quantitative comparison of six algorithms for vehicles detection in Jilin-1 satellite videos
4 結束語
本文應用了多種經典的運動目標檢測算法,利用衛星視頻進行了運動車輛檢測實驗,并通過定性對比和定量分析,將不同算法之間的性能差異直觀地顯示出來。
本文實驗一定程度上證明了現有經典算法的有效性。根據運動車輛提取結果,可以看出幾種算法對于運動車輛的捕捉、提取具有不同的效果。其中,K-近鄰算法表現優秀,檢測結果相對準確,兩幀差分法整體檢測效果較差,對噪聲極其敏感,誤檢率較高。
目前,利用監控視頻對運動車輛進行檢測的應用已相對成熟,但監控視頻無法宏觀地展示大視野場景車流的動態變化,而衛星視頻結合遙感技術可以為運動車輛的提取和分析提供更加宏觀、多源的數據,還可以提供更加細致的地物信息用于輔助,得到全面的分析結果。
本文對幾種運動檢測算法在衛星視頻中的應用做了綜合的對比和分析,發現以下幾點問題:
(1)由于空間分辨率的限制,衛星視頻中的運動車輛都非常小,通常只占據幾個像素,缺乏紋理信息,對運動車輛的提取造成了一定的困難。
(2)復雜的環境條件(例如:陰影、光照等)和場景變化加大了運動車輛的提取難度,影響檢測的精確度,造成誤檢和漏檢的情況。
(3)傳統的運動目標檢測算法受噪聲和應用場景限制大,部分場景下無法得到優良的效果,需要進一步研發新的算法。
許多研究者在傳統算法的理論基礎上,不斷地進行改進優化,結合新興的技術改進傳統的算法,使得檢測效果不斷加強,但是對于現實中復雜多變的場景的處理仍存在許多不足。只有不斷地優化算法或者結合現有新興技術提出新的算法,才能為衛星視頻影像中運動車輛的檢測提供更多的可能。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
當代陜西(2020年14期)2021-01-08 09:30:42
奧秘(創新大賽)(2020年7期)2020-07-27 08:26:32
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
海峽科技與產業(2016年3期)2016-05-17 04:32:12
