基于改進殘差網絡的水稻害蟲識別
2022-07-29 07:04:10雷建云
江蘇農業科學 2022年14期
雷建云, 陳 楚, 鄭 祿, 帖 軍, 趙 捷
(中南民族大學計算機科學學院/湖北省制造企業智能管理工程技術研究中心,湖北武漢 430074)
水稻是我國第一大糧食作物,我國是世界第二大水稻種植國家,隨著人口逐年增長,人們對糧食的需求量也呈增長趨勢,因此,對水稻產量提升的研究成為我國重要的工作。隨著氣候的變化和環境問題日益突出,水稻病蟲害發生率越來越高,尤其是蟲害影響了水稻的生長,導致作物產量下降,因此,水稻害蟲的防治顯得極其重要。傳統的水稻害蟲檢測主要依賴于人工識別,但是害蟲的種類多、數量龐大,人工識別法效率低下、速度緩慢、準確率不高。
近年來,隨著人工智能的興起,深度學習在計算機視覺、自然語言處理、情感計算等領域得到了廣泛關注和應用,很多科研工作者將深度學習應用到農業領域,在作物害蟲的識別上已有了初步探索。吳翔通過卷積神經網絡模型實現了10種螟蛾科類害蟲的識別,基本圖像數據來源于自然環境下的圖像采集,共計900張彩色圖像,每幅圖像只包含單一的害蟲,其卷積神經網絡害蟲識別模型共計有5層,最終識別的準確度約為76.7%。謝成軍等提出了一種基于圖像編碼與空間金字塔模型相結合的農田害蟲圖像表示與識別方法,通過35種害蟲的識別試驗,平均識別準確率達到89.2%。梁萬杰等提出了一種基于卷積神經網絡模型的水稻二化螟識別方法,試驗通過設計一個10層的卷積神經網絡模型,可有效地提取圖像的特征,對水稻二化螟識別具有很好的抗干擾性和魯棒性,模型命中率、分類精度分別為86.21%、89.14%。周愛明基于深度學習技術,實現對水稻害蟲的識別和計數,識別準確率約為90%,該模型同樣采用殘差神經網絡(ResNet)模型,通過卷積神經網絡對害蟲圖像進行特征提取,然后通過分類器對害蟲種類進行甄別,最后完成圖像中害蟲的計數任務。Song等收集了71種35 000張害蟲圖像,將ResNet中的殘差網絡(residual blocks)結構添加到Inception-V4模型中,對害蟲進行分類研究,總體分類準確率達到97.3%。Thenmozhi等建立了一個深度卷積神經網絡(CNN)模型,基于深度神經網絡和遷移學習的方式實現對害蟲的識別和分類,最終在3類害蟲圖像數據集上的準確率均在95%以上。Nanni等將顯著性方法與卷積神經網絡模型進行特征融合,在密集連接的卷積網絡(denseNet)的基礎上,設計搭建了新型的害蟲識別模型,最終在其自建小型數據集的測試過程中準確率達到92.43%,在IP102數據集上準確率達到61.93%。丁永軍等提出將膠囊網絡和VGG16模型相結合,構建卷積膠囊網絡用于百合病害識別,其檢測精度達到99.20%。李靜等提出了一種基于改進的GoogleNet卷積神經網絡模型的玉米螟蟲害圖像識別方法,對玉米螟蟲害圖像平均識別準確率達到96.44%。
以上這些基于機器視覺和卷積神經網絡算法的識別模型,相比常規的人工識別農作物病蟲害方法取得了較好的試驗結果。但是,在構建深層卷積神經網絡的過程中,當梯度信號從底層反向傳播到最頂層時,會逐步衰減,從而導致大量特征信息丟失。為了減少信息的丟失,從原始圖像獲得更多的特征,提高水稻害蟲的識別能力,本研究提出一種改進型ResNet算法,在ResNet卷積網絡的基礎上,加入膠囊網絡,來提升水稻害蟲的識別效果,以期對水稻害蟲的識別和預防提供參考。
1 試驗數據
1.1 數據來源
Wu等公布了一個大規模的害蟲識別數據集IP102,并進行了專業的圖像標注工作,一定程度上解決了害蟲圖像數據集樣本少的問題。該數據集類別是層級結構,分為8種農作物大類和102種害蟲小類。IP102是迄今為止規模最大的害蟲識別數據集,包含75 000張害蟲樣本,其類別幾乎囊括了當前最常見的害蟲種類。目前來說,IP102數據集為害蟲識別領域提供了優秀的試驗基準,從IP102數據集中,選取其中的水稻害蟲進行特定研究,涉及稻卷葉蟲、稻螟蛉、稻潛葉蠅、二化螟、三化螟、稻癭蚊等14個類別,圖像總數為8 417張,作為本研究的水稻害蟲圖片數據集,該數據集的詳細信息見表1,數據集的部分樣本圖像見圖1。
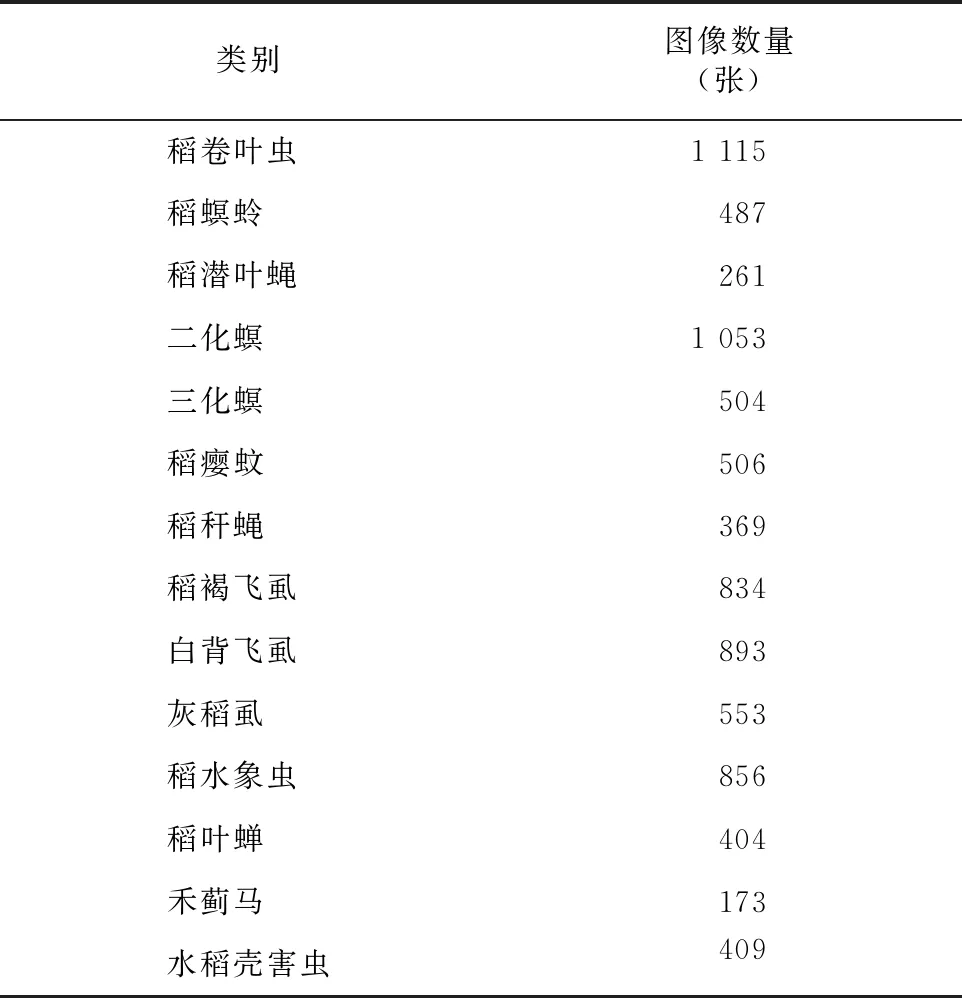
表1 數據集詳細信息
1.2 數據處理
IP102數據集水稻害蟲存在樣本過多或過少的現象,導致樣本分布不平衡。為了彌補樣本存在的種類不平衡對模型識別準確率的影響,在訓練之前,對數量較少的樣本數據進行增強處理。在深度學習中,數據增強是指通過某些技術手段將數據量小的數據集擴充得到更多的數據。通過旋轉(旋轉角度分別為90°、180°、270°)、翻轉(翻轉方式為上下翻轉、水平翻轉)、光照度處理、對比度處理、色彩平衡處理以及銳度處理等數據增強技術,達到數據樣本均勻,總的圖片數量達到20 670張,提升了模型的泛化能力和模型的魯棒性。數據增強后與原圖對比情況見圖2。


2 模型構建與優化
2.1 殘差網絡
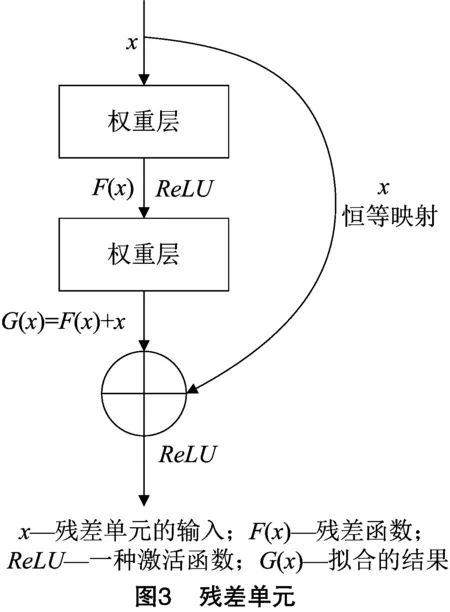
卷積神經網絡可以提取圖像中不同語義層次的特征,隨著網絡層數的增加,提取到的特征也更加豐富。網絡的深度對網絡性能至關重要,但網絡的性能會隨著網絡深度的增加迅速達到飽和,甚至開始迅速下降,稱其為退化問題。為了解決網絡退化問題并能夠訓練上千層的網絡,He等提出身份快捷方式連接,該連接從某些層跳過并使用了先前層的激活功能,由此ResNet模型誕生了,它允許網絡深度大幅提升的同時達到更高的準確率,能夠很好地解決深層網絡訓練時的退化問題,其核心為殘差單元(圖3)。
2.2 膠囊網絡
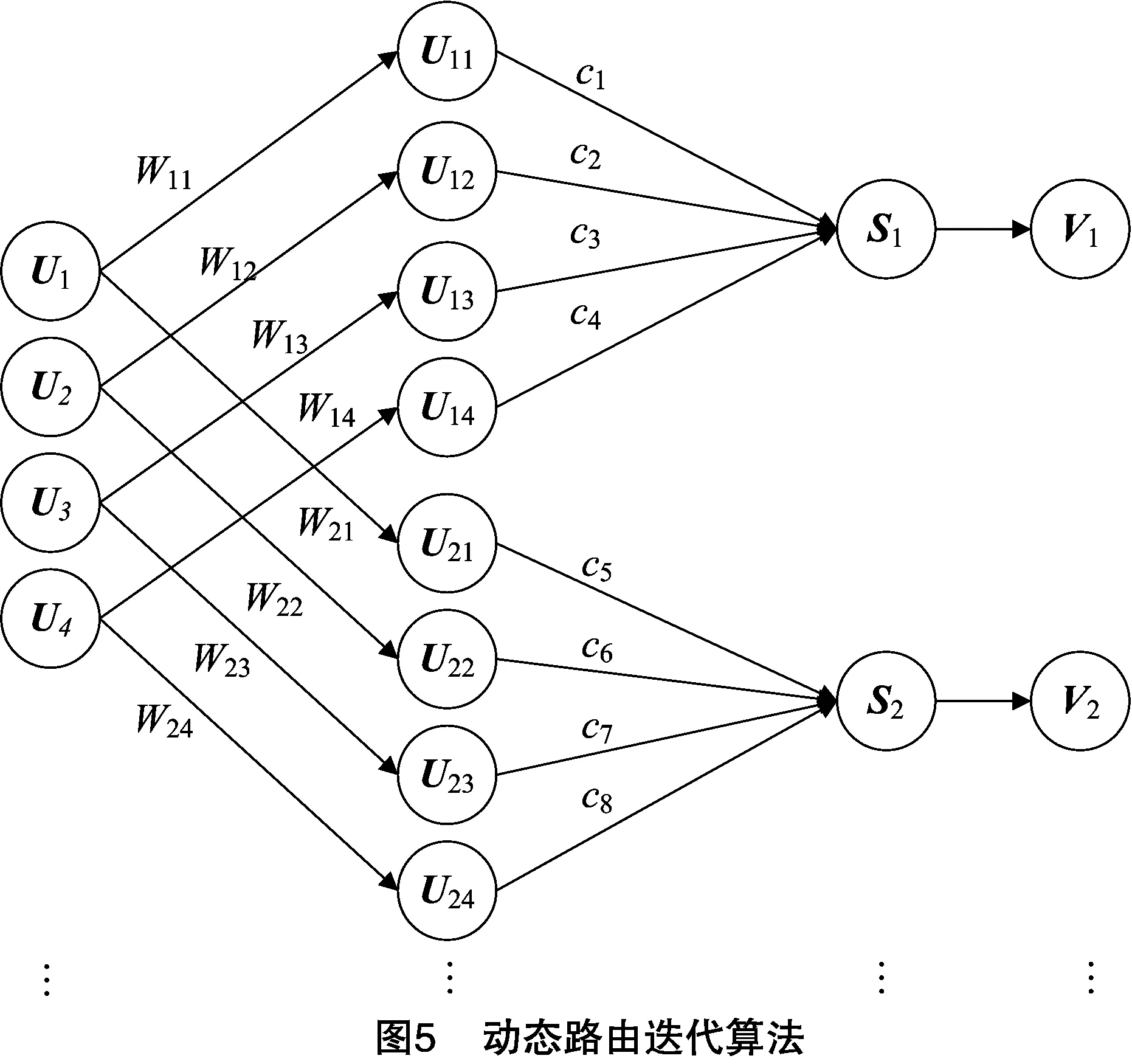
膠囊網絡(capsule network,簡稱Capsnet)是一種具有強泛化能力的深度學習網絡模型,在自動駕駛、語義編碼、醫學圖像分析等領域都得到了成功應用。膠囊網絡是在CNN的基礎上發展而來的,由于CNN需要在大量的圖像上進行訓練,在池化層中丟失了大量信息,降低了空間分辨率,影響了最終的分類精度。雖然后續很多人對CNN進行了改進,但是CNN中有大量的參數,池化層依然必不可少。為解決這些問題,膠囊網絡誕生了,膠囊網絡去掉了造成特征丟棄的池化層,充分利用各個圖像特征之間的空間關系,獲得高層特征和低層特征之間的位置關系作為一種用于分類的特征。膠囊網絡使用矢量膠囊代替標量神經元,對于特征向量具有良好的方向表示。圖4是膠囊網絡的模型結構,Conv1表示卷積層,PrimaryCaps表示初始膠囊層,DigitCaps表示路由膠囊層,代表矩陣。

膠囊網絡架構的第1個卷積層是對原圖進行特征的提取,將最終得到的特征圖作為第1層膠囊層的輸入。網絡的第2層是初始化膠囊層,最后一層是數字膠囊層,每個類別用1個膠囊表示。這一層的膠囊與前一層所有的膠囊都有連接,這2層膠囊層之間采用動態路由算法來更新,提高模型的分類準確率,使模型能夠快速平穩地收斂。在膠囊網絡中,使用動態路由迭代算法來預測高層特征,動態路由迭代的過程見圖5,其中,~表示低層膠囊的輸入,~表示轉換矩陣,~表示預測向量,~表示權重系數,、是高層膠囊總的輸入,、表示最終膠囊的向量輸出。
每個上層膠囊連接到下層的概率為
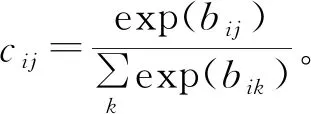
(1)
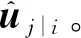

(2)
式中:表示低層膠囊的輸入,接著對所有得到的預測向量進行加權求和:
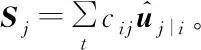
(3)
其中:被稱為高層膠囊總的輸入向量。用非線性壓扁函數squashing來代替傳統的神經網絡的激活函數Relu,確保了向量的方向保持不變,但它的長度被強要求不超過1,最終膠囊的向量輸出()如下:

(4)
2.3 基于改進的殘差網絡
在水稻害蟲識別研究的領域,ResNet雖然有較好的識別效果,但是圖像在訓練的過程中丟失了大量的信息;與ResNet相比,膠囊網絡通過矢量表示實例化參數,并確定輸入對象的空間信息。膠囊網絡的關鍵特性使其可以保留有關水稻害蟲位置和姿勢的詳細信息,這些信息在水稻害蟲圖像識別中占據著突出的位置。
通過將ResNet和膠囊網絡進行整合能有效降低過擬合,提高識別的準確率;以膠囊網絡作ResNet模型的全連接層,這樣可以彌補殘差網絡在輸出時丟失大量信息的缺陷。
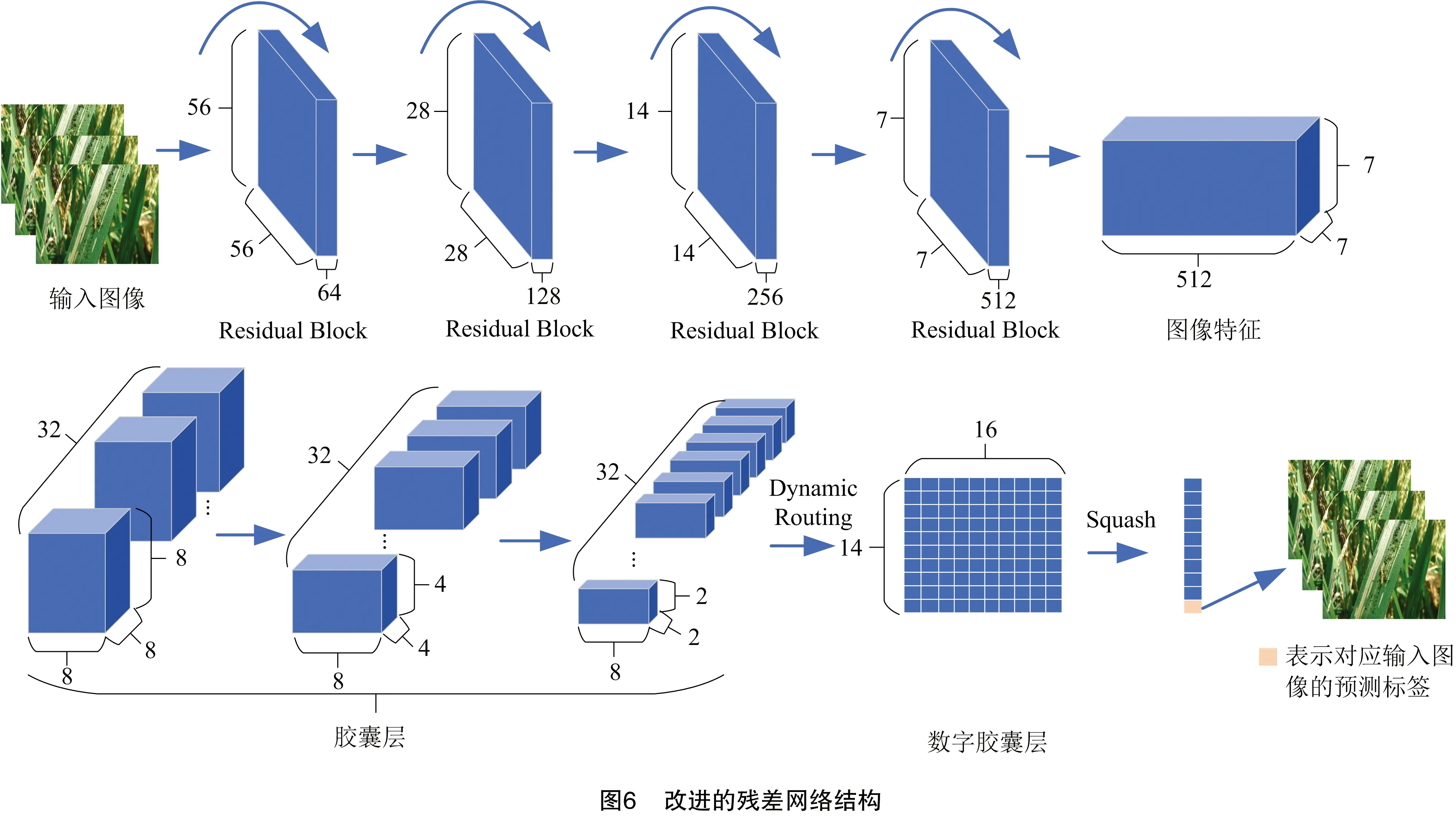
改進的殘差網絡結構模型見圖6,為減少參數量,選取ResNet34網絡作為基本模型。首先對輸入的圖像進行卷積和下采樣,以提取圖像的特征,通過4個Basicblock,將特征圖的尺寸降到7×7、特征圖的通道提升到512,通過這種方式可以捕獲到更多的樣本特征。接著,將512×7×7的特征圖進行膠囊化編碼,轉為32個8×8的膠囊,再經過2次卷積,最終得到32個8×2×2的膠囊。隨后進行層間路由,以一種近似全連接的方式(即dynamic routing)映射到14×16的空間。
在14個害蟲分類識別的問題中,dynamic routing算法將膠囊特征映射到14×16的空間,即每個類對應1個16維的特征,然后使用非線性映射(squash)將其壓縮成1個14 維的向量,取范式的最大值作為最終的預測值標簽。
3 試驗結果與分析
3.1 試驗環境
試驗配置環境為Ubuntu 16.04 LST 64位系統,Intel? Xeon CPU E5-2630(2.20 GHz)處理器,64 GB 內存,Tesla P40顯卡,采用pytorch 1.6.0深度學習框架。
3.2 試驗評價指標
準確率(accuracy)是正確分類的個數占總樣本數的比例,反映了算法對整體樣本的分類性能,計算公式為
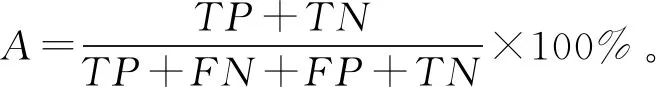
(5)
式中:表示正樣本被正確識別的數量;表示負樣本被錯誤識別的數量;表示正樣本被錯誤識別的數量;表示負樣本被正確識別的數量;表示準確率。


(6)
式中:表示重復試驗的次數,=10。
混淆矩陣(confusion matrix)是用來總結分類模型預測結果的分析圖表,本研究以矩陣的形式來顯示分類模型對每一類的預測結果正確與否,其中對角線上的元素表示各類別水稻害蟲被正確識別的數量,其他元素則表示被錯誤識別的數量。
3.3 結果與分析
為了確保訓練的準確性,隨機將水稻害蟲數據集按8 ∶2劃分成訓練集和測試集。通過分析數據增強對于模型性能的影響,網絡模型不同的超參數對于性能的影響,以及選取Inception V3、DenseNet、Efficientnet、Capsnet、ResNet34等網絡模型進行試驗對比,以此來驗證改進的殘差網絡的準確性。
3.3.1 數據增強對模型性能的影響 水稻害蟲數據集是從基準數據集IP102中選取水稻害蟲的14個類別,但由于樣本分布不均勻,需要對數據進行擴充。數據增強為模型訓練提供了強大的數據支撐,為了驗證數據增強對模型的性能是否有影響,將進行數據增強后的數據集在模型上進行測試。由圖7可知,數據集經過數據增強后,對準確率有一定程度的提升,說明數據增強對于試驗結果的影響較大。
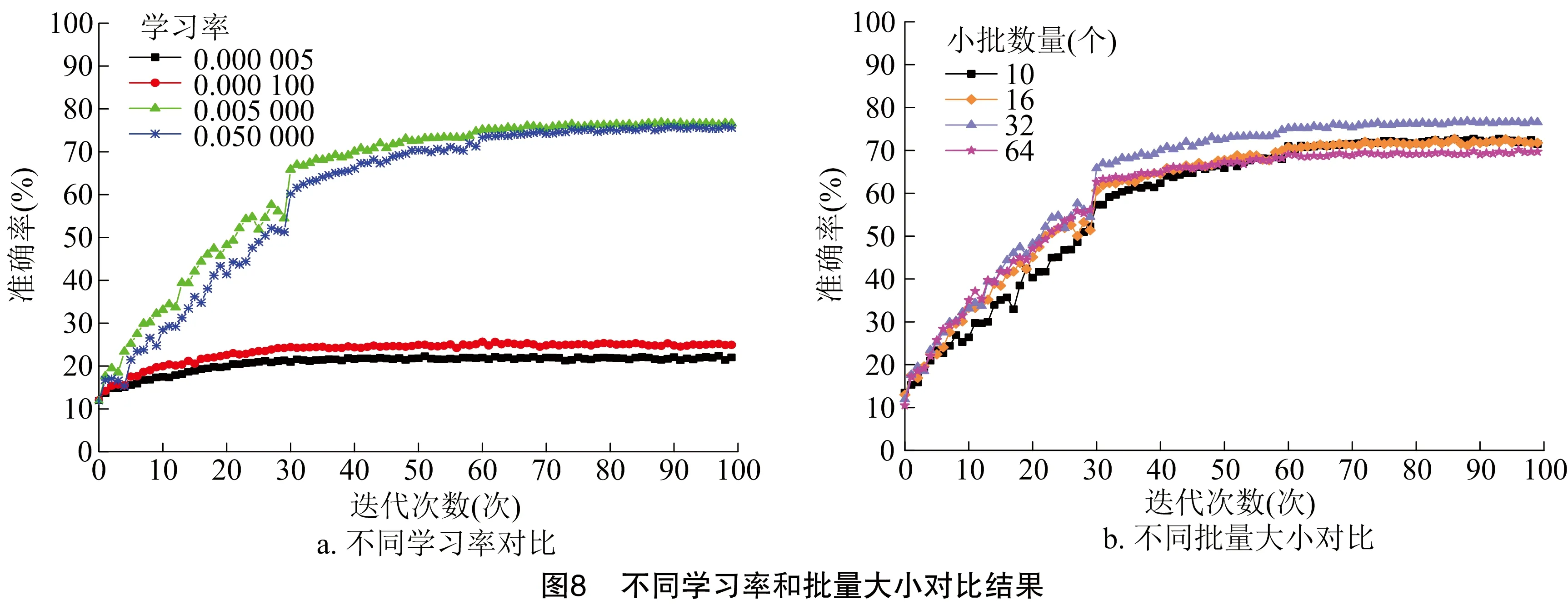
3.3.2 超參數對模型的影響 (1)學習率和批量大小。學習率是影響神經網絡模型效率的一個重要因素。學習速率越高,學習過程越快,損失函數越高;學習速率越低,損失函數越低。在水稻害蟲識別問題中,要選擇最優學習率以使損失函數最小。以0.000 005、0.000 100、0.005 000、0.050 000的學習率訓練模型。經過100輪迭代,小批數量為32個,不同學習率的準確率見圖8-a。當學習率設置的很小時,收斂速度很快,在第10輪的位置就開始收斂,但是準確率不高,當適當增大學習率時,收斂速度降低,但是準確率提升很大。因此,學習率對試驗結果的影響很大,通過試驗驗證,當學習率設置為0.005 000時,可以獲得更好的分類準確率。批量的大小是影響模型分類精度的一個重要參數。更大的批處理規模使模型在恒定權重的情況下運行很長一段時間,這會降低總體性能并影響內存需求。因此,選擇合適的批量大小來提高模型的分類準確率。該模型以10、16、32、64個小批數量進行評估,模型的準確率隨著小批數量的增加,變化不太明顯,小批數量從10個增加到64個。由圖 8-b 可知,該模型運行了100輪,學習率為 0.005 000。在試驗結果的基礎上,選取了32個小批量的模型進行訓練,提高了模型的收斂精度。同樣明顯的是,進一步增加小批量的尺寸并不能提高準確性。所選擇的32個小批尺寸支持所提出的模型,以獲得更好的最終精度。

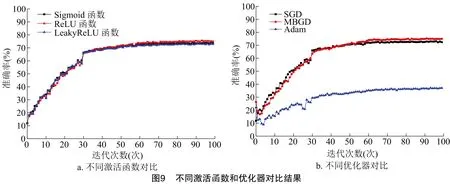
(2)激活函數和優化器。激活函數是神經網絡中非常重要的概念。它們決定了某個神經元是否被激活,這個神經元接受到的信息是否是有用的,是否該留下或者是拋棄。激活函數可以把信號轉換為非線性的,而這種非線性使得我們能夠學習到輸入與輸出之間任意復雜的變換關系。選取Sigmoid函數、ReLU函數、LeakyReLU函數進行評估。由圖9-a可知,激活函數對于本試驗影響并不大,所以選取常規的ReLU函數作為本研究的激活函數。優化器是用來更新和計算影響模型訓練和模型輸出的網絡參數,使其逼近或達到最優值,從而最小化損失函數。以隨機梯度下降(SGD)、小批量的梯度下降(MBGD)、Adam作為優化器進行評估,由圖9-b可知,選取MBGD作為優化器效果最好,MBGD可以利用矩陣和向量計算進行加速,還可以減少參數更新的方差,得到更穩定的收斂。
3.3.3 不同網絡模型之間的性能比較 為了驗證改進的殘差網絡模型性能優勢,訓練了多個對比模型。從表2可以看出,在傳統的網絡模型中,DenseNet的效果是最好的,而參數量最少的是EfficientNet;在水稻害蟲圖像的數據集上,從圖10-a可以看出,使用改進后的殘差網絡模型進行識別準確率可以達到77.12%,與傳統的模型相比,改進后的模型效果更好,進一步體現出改進模型在一定程度上提高了水稻害蟲的識別效率。為了進一步對比各模型的分類性能,本研究繪制了損失函數結果,如圖10-b所示,各模型均使用Softmax交叉熵損失函數進行分析,損失值均呈現先快速下降后緩慢下降再趨于平穩狀態。
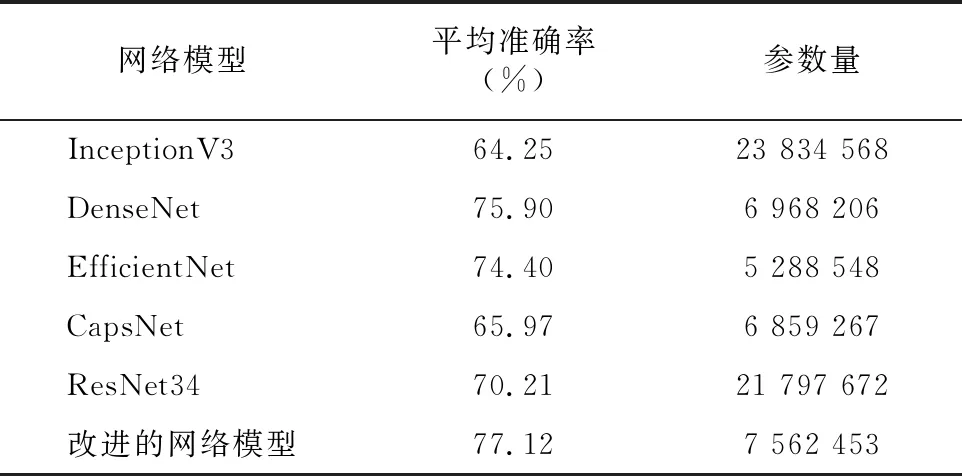
表2 不同網絡模型對比結果

此外,為更好地分析網絡模型獲得圖像特征表達的過程,研究了水稻害蟲經過改進的殘差網絡卷積模塊后的特征圖,如圖11所示。通過對特征圖的觀察,隨著網絡層數的提高,背景越來越模糊,所提取的圖像特征越來越抽象,特征的紋理性逐漸被更高級的語義性所取代。

3.3.4 水稻害蟲混淆矩陣 為了更清楚地展現基于改進殘差網絡方法的識別精度與分類結果,分別選取14類水稻害蟲的100張圖片,在測試集上模型分類結果基礎上繪制得到的混淆矩陣見圖12。混淆矩陣是一個誤差矩陣,通常可以通過混淆矩陣來評定深度學習算法的性能。由圖12可知,二化螟中有14張圖片被錯誤識別成三化螟,三化螟中有15張圖片被錯誤識別成二化螟;稻褐飛虱中有15張圖片被錯誤識別成白背飛虱,白背飛虱中有16張圖片被錯誤識別成稻褐飛虱;水稻殼害蟲中有9張圖片被錯誤識別成稻螟蛉,稻螟蛉中有8張圖片被錯誤識別成水稻殼害蟲;說明二化螟和三化螟、稻褐飛虱和白背飛虱、水稻殼害蟲和稻螟蛉之間有一定的相似性。其他識別效果都不錯,說明改進的殘差網絡模型可靠性很高。
4 結束語
針對傳統水稻害蟲識別方法存在準確率和效率低下的問題,本研究在數據增強的基礎下,在傳統殘差網絡上進行優化,提出了一種改進的殘差網絡模型,通過將膠囊網絡融入進去,代替殘差網絡的全連接層,使得提取的圖像特征更加豐富;同時,還研究了超參數的影響,通過優化組合,選取最合適的超參數以提高分類的準確率。
目前很多在IP102數據集上的研究識別準確率偏低,采用膠囊網絡和殘差網絡相結合的方式在識別準確率上有一定的提高。為了達到推廣應用的效果,今后可以在水稻害蟲數據集上做進一步的擴充和完善,還可以研究模型對水稻害蟲不同生育階段的識別能力,為水稻害蟲防治提供技術支撐和相關參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
青少年科技博覽(中學版)(2022年6期)2022-12-27 19:44:27
今日農業(2021年21期)2021-11-26 05:07:00
軍事文摘(2021年22期)2021-11-26 00:43:51
今日農業(2021年14期)2021-10-14 08:35:40
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
文苑(2020年6期)2020-06-22 08:41:52
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2019年22期)2019-12-07 05:29:00
光學精密工程(2016年6期)2016-11-07 09:07:19
