機器學習在股價預測上的應用
2022-07-22 14:09:14錢琦淼王映艨蔡飛君
中國市場 2022年21期
錢琦淼,張 朵,王映艨,劉 睿,蔡飛君
(無錫太湖學院 會計學院,江蘇 無錫 214064)
1 引言
近年來,機器學習在股票價格預測的應用中越來越廣泛,量化投資的形式也迅速占據著金融市場。徐浩然等人(2020)針對股票預測研究的CNN和LSTM兩種深度學習算法做了優缺點的闡述分析。CNN的特征選擇具有更好的表現,而LSTM則更加關注時間序列的相關性,并且提出將兩種模型融合,各自發揮優勢,得到最優的預測效果。由于股票的復雜以及不確定性,所以到現在為止國內針對單只股票的走勢預測研究較少,大多基于海外市場,而另一部分集中于對算法進行優化。文章學習前人對個股的研究思路,嘗試并選用隨機森林和GBDT兩種機器學習的算法對寧德時代的收益率進行預測,通過不斷的對參數調整,使得模型預測效果達到最優。探索兩種機器學習的算法在預測未來股票的收益情況上的優劣比較和優化,這是文章研究的目的。
2 機器學習及算法理論介紹
2.1 機器學習介紹
機器學習現有的主要研究是在對數據的初步了解和學習目的分析的基礎上,選擇合適的學習算法進行訓練,最后利用訓練后的模型對數據進行分析和預測。文章中運用到的機器學習算法有隨機森林和GBDT。
2.2 隨機森林
何裕(2014)通過決策樹、Logistic回歸模型、神經網絡模型挖掘研究公司財務比率指標的變化和股價變化趨勢的內在聯系,最后組合模型構建,證實了技術對于股價預測的可行性與合理性。隨機森林是對決策樹算法的一種改進,將多個決策樹組合,每棵樹都通過獨立提取的樣本建立,采用自上而下的遞歸方法,對未知數據進行分類,按照決策樹上生成時所采用的分割性逐層往下,直到一個葉子節點,到葉子節點處的熵值為零。在股市的應用中,首先需要找到合適的分類器來闡述各因子與下期收益的關系,要利用歷史數據,訓練分類器。獲得參數后,再代入各股因子數據并分類,從而選取優秀股。
2.3 GBDT
胡謙(2016)結合機器學習、技術分析研究量化選股策略,首次將GBDT和GB Rank用于量化選股領域,自動學習出能對股票未來表現進行排序的模型,證明使用GBDT算法的兩個策略有較強盈利性。GBDT(Gradient Boosting + Dicision Tree)算法是Boosting迭代融合算法,在傳統機器學習算法中GBDT是最適合真實分布擬合的幾種算法之一。使用當前模型中損失函數負梯度方向的值作為殘差的近似值,擬合CART回歸樹。GBDT將累積所有回歸樹的結果,并不斷減小訓練過程中產生的殘差,以實現將數據分類或回歸的算法。
3 數據預處理
3.1 實驗平臺
文章在建模分析部分采用 Python語言,本次實驗選取的數據分析環境是Anaconda,采用Web應用程序Jupyter Notebook進行建模。
3.2 數據來源
由于Tushare返回的絕大部分數據格式都是pandas DataFrame類型,非常便于數據分析和可視化,減輕工作量,所以本次實驗選取的數據來源于Tushare。
3.3 數據預處理
寧德時代(300750.SZ)作為新能源板塊中表現比較突出的股票,文章截取了其2016年1月1日到2021年2月4日的交易數據,分別是交易日期、開盤價、最高價、最低價、收盤價、昨收價、漲跌額、漲跌幅、成交量和成交額,一共649期。
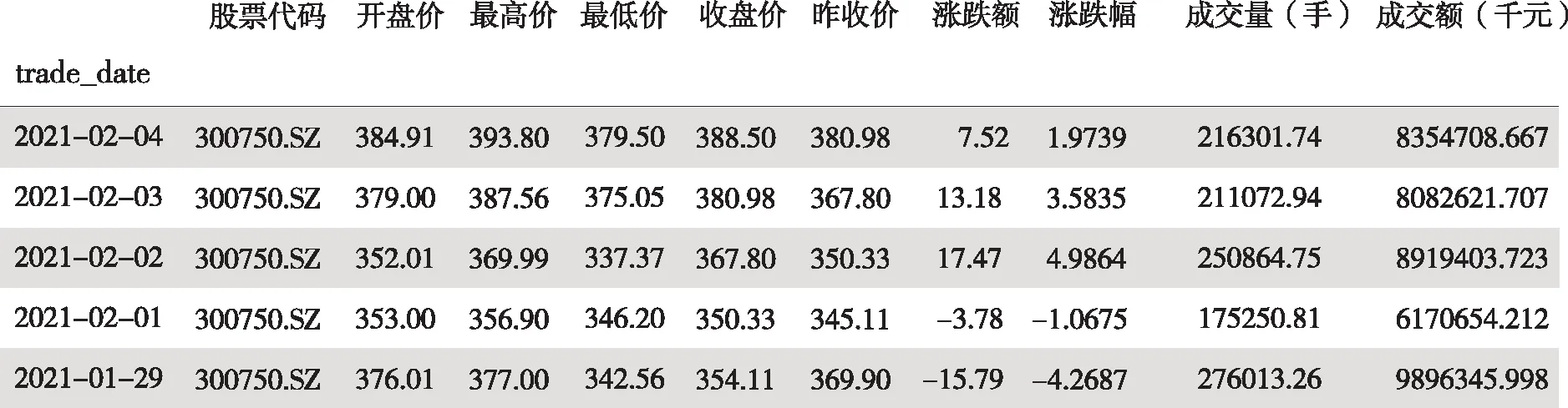
圖1 部分數據集描述
文章還對數據寧德時代的收盤價計算了100天的移動平均值,并取每個滑窗的移動平均值。從圖2中,可以看出2019年11月開始,寧德時代股票價格呈現明顯上升趨勢。
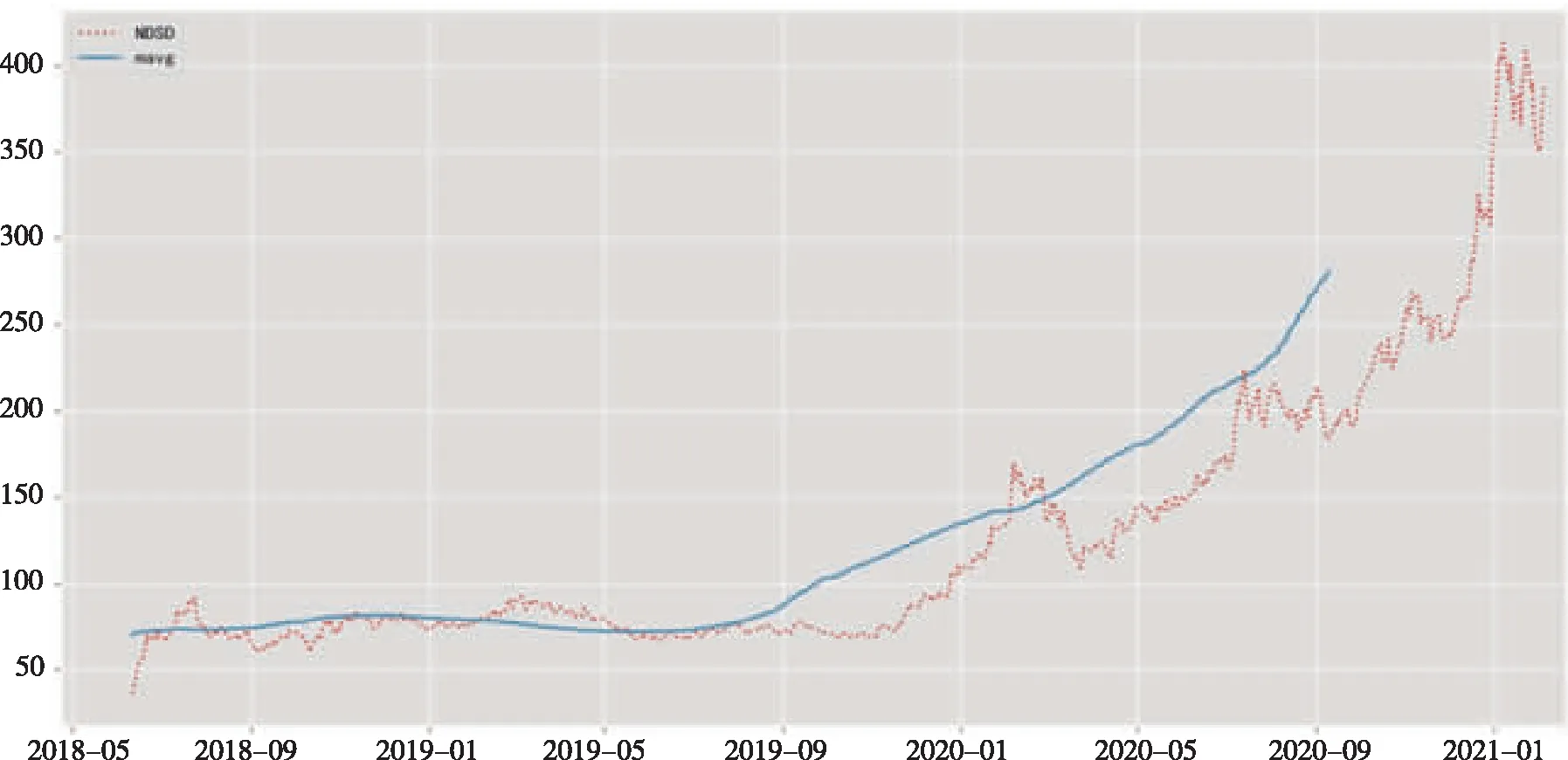
圖2 移動平滑價格線
由于非平穩型的趨勢線,實驗決定預測寧德時代的收益情況。由于時間序列存在滯后性,于是在實驗中設計了一些股票的滯后項——return-1,return-2,return-3。
4 實驗研究分析
文章收集數據的周期為2016年1月1日到2021年2月4日,選擇了開盤價、最高價、最低價等11個影響收益率的因子。文章將2016年1月1日到2020年10月1日之前的數據作為訓練集,一共561期數據。2020年10月1日到2021年2月4日之間的數據作為測試集,一共83期數據。
4.1 隨機森林
實驗過程中,文章首先引入決策樹,在隨機狀態為10,最大迭代次數為100,葉子節點最少樣本數為70的條件下建立模型,在擬合數據后進行預測,訓練集的平均絕對誤差是0.00748,測試集則是0.00752。從隨機森林這一模型中,它的隨機性難以對模型進行解釋,因此猜測模型容易在噪聲過多的分類和回歸問題中過擬合。為了驗證猜想,實驗嘗試通過調參來提高模型的泛化能力。
在整個隨機森林調參過程中,要選擇一個適中的最大迭代次數,故得到了實驗中最佳的弱學習器迭代次數為5。在此基礎上,得到決策樹最大深度范圍為5,內部節點再劃分所需最小樣本數為100。由于內部節點再劃分所需最小樣本數還和決策樹其他的參數存在關聯,實驗還需要對內部節點再劃分所需最小樣本數和葉子節點最少樣本數一起調參,得到葉子節點最少樣本數30,內部節點再劃分所需最小樣本數50。
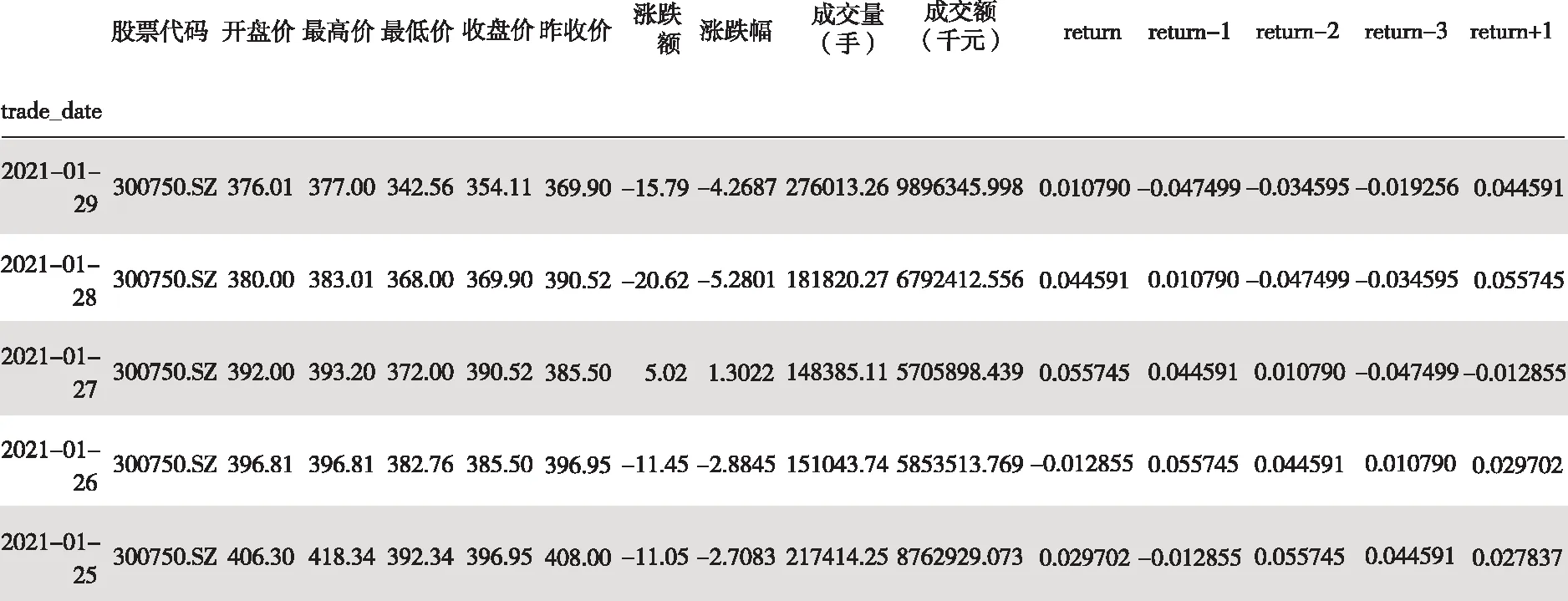
圖3 部分數據集描述
基于上述結果,再對最大特征數做調參,搜索得到最大特征數為5。經過一系列調參,用搜索到的最佳參數,得到最終的模型擬合訓練集的平均絕對誤差值為0.005543,測試集是0.00920,結果發現無顯著變化。
4.2 GBDT
GBDT和傳統的Adaboost有很大的不同,傳統的Adaboost會使用上一次迭代弱學習器的錯誤率來更新訓練集的權重,使迭代繼續進行,而GBDT算法的弱學習器(基模型)是CART,故擬合出一棵CART回歸樹,對實驗過程中構成一個強學習器來說至關重要。在整體的迭代思維上,GBDT的迭代通常使用前向分布算法,損失函數的負梯度在當前模型的值作為回歸提升樹殘差的近似值,在持續擬合的過程中,擬合值和目標值之間的殘差會越來越小,每一棵樹的預測值加起來就是模型最終的預測結果。所以在本次實驗中一共建立了學習器644個,步長為0.1。最大的弱學習器的個數為默認值100。
最終得到訓練集的絕對誤差為0.000153,測試集為0.0137。預測收益率的標準差為0.03217,絕對誤差值過小,模型過擬合。筆者認為應當通過調參來優化模型的泛化能力。為了驗證猜想,筆者開始進行調參。首先調參需要選擇一個較小的步長來網格搜索最好的迭代次數,得到最佳弱學習器的個數為80,樹的最大深度為9,最小樣本劃分樹為5,葉子節點最少樣本數為10,最大特征數目為5,而隨機狀態為10。修改成最優參數后,得到測試集的絕對誤差為0.004412,訓練集為0.001657。
5 結論與展望
從本次實驗來看,能觀察到隨機森林這一模型訓練速度更快,因為特征子集是隨機選取的,就不用做特征選擇。由于待選特征也是隨機選取,所以對特征缺失不敏感,調參后發現結果無顯著變化甚至比原來誤差更大,猜測存在過擬合現象,從而發現了隨機森林的缺點,容易在噪聲過多的分類和回歸問題中過擬合;與單個決策樹相比,它的隨機性讓模型難以進行解釋。
相較于隨機森林模型,GBDT具有以下兩個優點:其一,適用面廣,離散的或是連續的數據都可以處理;其二,GBDT模型的調參過程比較簡單,在相對小的調參過程下,GBDT的預測結果更為準確。GBDT就最終的輸出結果而言,提升樹即是整個迭代過程生成的回歸樹的累加或加權累加,是基于權值的弱分類器集成,通過減少模型偏差提高性能。此外該模型對異常值也比隨機森林更敏感。
因此,從本次實驗中發現GBDT精度略高于隨機森林模型,且在一些調整后,GBDT模型獲得了較好的預測效果。
圖4 訓練集比較
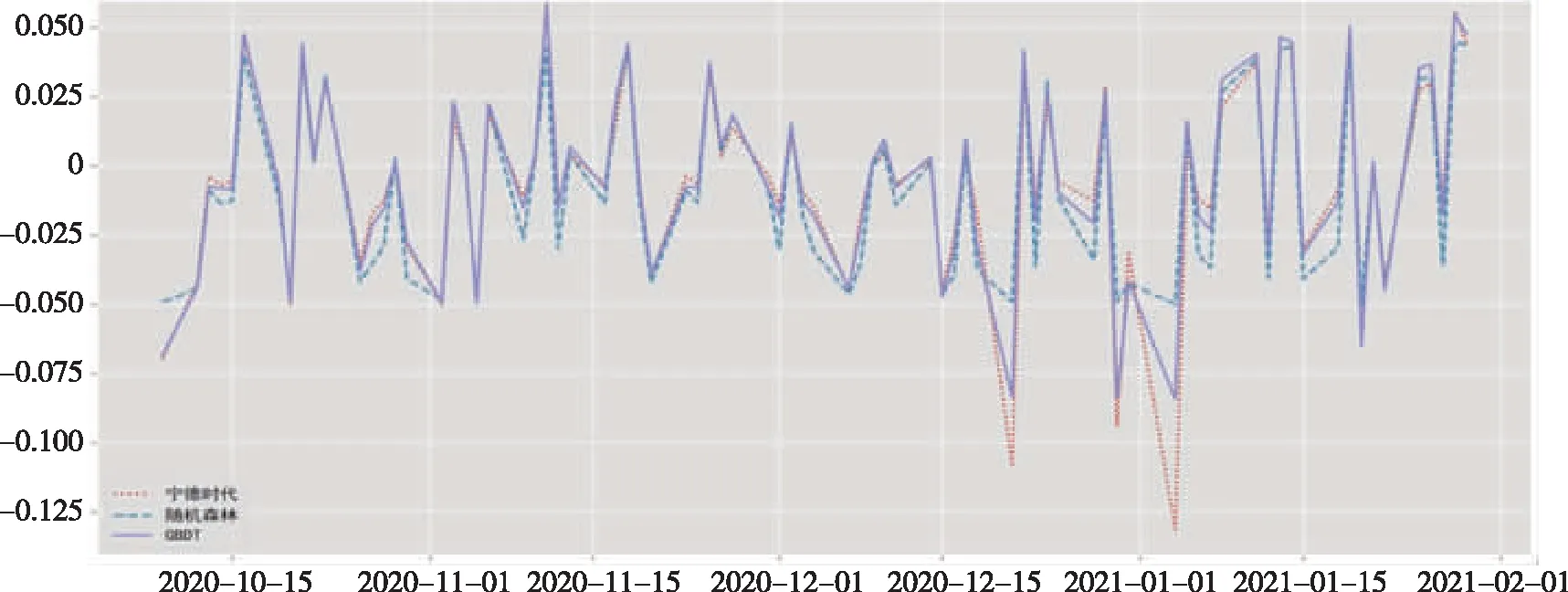
圖5 測試集比較
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
