改進MobileNetV3的脫機手寫漢字識別
2022-07-15 09:53:58程若然周浩軍劉露露
智能計算機與應用 2022年7期
程若然,周浩軍,劉露露,賀 炎
(上海工程技術大學 電子電氣工程學院,上海 201620)
0 引 言
文字是人類社會最重要的交流載體之一,隨著互聯網與人類社會的聯系越發緊密,手寫漢字識別在人們生活中起到越來越大的作用。手寫文字識別主要分為聯機手寫漢字識別和脫機手寫漢字識別。前者使用相關設備記錄書寫軌跡的各項數據,利用筆順信息來進行文字識別;后者則使用圖像采集設備獲取手寫文字圖像,通過學習圖像與漢字字符編碼之間的映射來識別文字。
手寫漢字識別從上世紀80年代起不斷發展,傳統方法逐漸形成“預處理、特征提取、分類”的流程來進行手寫漢字識別,并獲得了不錯的識別效果。但在實際應用中,更復雜的手寫風格和識別模式使得文字識別率下降,用戶難以獲得最佳的性能體驗。近年來,一些研究人員開始利用深度學習方法進行手寫漢字識別。2013年的ICDAR手寫漢字識別競賽的優勝者,利用深度學習方法獲得了遠超傳統方法的識別率,展現了深度學習在文字識別領域的極大潛能。
目前,基于深度學習的手寫漢字識別方法存在訓練時間長、高資源消耗的問題。為此,本文利用MobileNetV3作為主干網絡進行脫機手寫漢字識別,融合多尺度空間特征,提高了訓練速度。
1 MobileNetV3網絡模型
MobileNetV3是2019年Google研 發 的MobileNet系列的新作。MobileNet系列網絡模型是為了能在移動端設備(如在手機上)運行而設計的輕量型網絡,且繼承了V1版本的深度可分離卷積(Depthwise Separable Convolution)和V2版本的逆殘差(Inverted Residuals)和線性瓶頸(Linear Bottlenecks)結構。為了進一步提升分類準確率,V3版本引入了SE(Squeeze-and-excitation)結構,并對網絡進一步剪枝以減少計算量,加快訓練速度。
1.1 深度可分離卷積
如圖1所示,標準卷積是每個卷積核與輸入特征圖的所有通道按位進行卷積計算,參數量為k×k×C×C、計算量是k×k×C×C×W×H。

圖1 標準卷積與深度可分離卷積Fig.1 Standard convolution and depth separable convolution
其中,是卷積核大小;C、C是輸入通道數(輸入特征圖的通道數以及卷積核通道數)和輸出通道數(即卷積核個數);和是輸出特征圖的寬和高。
深度可分離卷積分為深度卷積和點卷積兩步完成:深度卷積是用C個大小為、通道數為1的卷積核,對輸入特征圖的C個通道分別進行卷積計算,參數量為1×C、計算量為1×C×W×H;點卷積是使用C個通道大小為11、通道數為C的卷積核,對深度卷積的輸出進行標準卷積操作,參數量為11×C×C,計算量為11×C×C×W×H。因此,深度可分離卷積在參數量上減少為標準卷積的1/C+1(k×k×C),在計算量上減少為標準卷積的1/C+1()。當使用33大小的卷積核時,理論上深度可分離卷積的計算速度應是標準卷積的89倍,而精度只與標準卷積相差1。
1.2 帶線性瓶頸的逆殘差結構
逆殘差結構是依據ResNet的殘差結構改進而得。殘差結構先用1×1卷積核壓縮輸入特征圖的通道數,再用3×3卷積核進行特征提取,最后用1×1卷積核擴張回原本的通道數,整體流程為“壓縮-特征提取-擴張”,特征圖通道數量先減小后增大。逆殘差結構先用1×1卷積核擴張輸入特征圖的通道數,再用3×3卷積核進行深度卷積,最后用1×1卷積核壓縮回原本的通道數,整體流程為“擴張-特征提取-壓縮”,特征圖通道數量先增大后減小。二者結構如圖2所示。
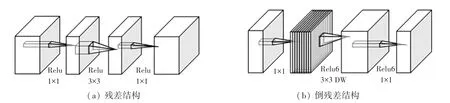
圖2 殘差結構與倒殘差結構Fig.2 Residual structure and inverted residual structure
由于低維分布嵌入到高維空間之后,再使用RELU激活函數由高維空間投影回低維空間,將會造成信息損失。針對該問題,MobileNet V2引入了線性瓶頸,即將逆殘差模塊最后一層的RELU改為激活函數。
1.3 MobileNetV3
MobileNet V3在前代版本的基礎上,首先調整了網絡的輸入輸出層,減少了輸入輸出層的卷積操作,以降低計算機資源消耗,提升了15%的運算速度;其次去除了函數的計算,改用計算消耗更小的函數;在逆殘差模塊中3×3深度可分離卷積之后引入SE模塊,結構如圖3所示。

圖3 MobileNet V3-SE模塊Fig.3 MobileNet V3-SE module
MobileNet V3-SE的基本實現過程為:先進行全局池化壓縮(Squeeze)獲得一個1×1×的向量;然后經過兩次“全連接層-激活(Excitation)”操作(為減少計算時間將第一次“全連接層-激活”操作的輸出通道數壓縮為原來的1/4),輸出1×1×的向量;最后將得到的向量與深度可分離卷積的結果按位相乘,以調整每個通道的權值,從而提升網絡精度。V3總體網絡結構的設計中,首先通過NAS算法,對網絡結構進行搜索優化(如網絡中Block的排列和結構),得到大體的網絡構成,最后使用NetAdapt算法來確定每個filter的channel數量。
2 基于MobileNetV3的脫機手寫漢字識別
本文研究目標是脫機手寫漢字的識別,主要面臨兩個問題:
(1)漢字數量多,相當于數千級別的分類問題。如此大數量的分類網絡,需要更豐富的特征信息。
(2)形近字的識別容易得到錯誤結果(如“巳”和“已”)。
針對上述問題,本文以MobileNetV3為主干網絡,設計了一種多尺度特征提取方案,并使用一種新的注意力機制進行特征融合,改進后的MobileNetV3能夠更好地適應脫機手寫漢字識別任務。
2.1 改進的MobileNetV3
本文在輸入圖像進行多次特征提取之后,加入一個特征提取模塊來豐富特征信息。該模塊包含兩個支路:使用多尺度大小的卷積核來獲取原始輸入圖像上不同范圍大小的感受野,并利用注意力機制融合這兩個分支的特征信息。優化后的網絡模型如圖4所示,其中虛線框所指模塊即為本文的改進之處,MS-CAM是多尺度通道注意力模塊。

圖4 改進的MobileNetV3Fig.4 Improved MobileNetV3
2.2 感受野
在卷積神經網絡中,感受野是一個非常重要的概念,指的是每個網絡層輸出的特征圖像上,每個神經元所能“看見”的原始輸入圖像上對應區域的范圍大小。如圖5所示,每一層的卷積核大小都為3×3,卷積步長為1,填充大小為0。下一層特征圖的每個神經元能看到上一層特征圖3×3大小的區域,進而能看到再上一層5×5大小的區域。也就是說,越深的網絡層越能看到原始輸入圖像上更多的內容。
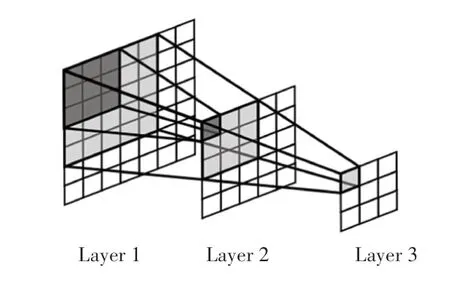
圖5 感受野示意圖Fig.5 Receptive field diagram
網絡中不同大小的感受野會帶來不一樣的性能表現,而感受野的大小則受到各參數的影響(如卷積核大小、卷積步長、填充大小等)。為了能夠從原始輸入圖像獲得更豐富的特征信息,本文網絡使用3×3和5×5多尺度大小的卷積核,來獲取原始輸入圖像上不同范圍大小的感受野。
2.3 多尺度通道注意力特征融合
特征融合是來自不同層或分支特征的組合,是卷積神經網絡中常見的操作內容,通常通過簡單線性的操作(如:求和或拼接)來實現。文獻[8]中認為,這樣的特征融合方式并不是最佳選擇,因此提出了一種新的基于注意力的特征融合方法。本文利用該方法中提出的多尺度通道注意力模塊(MS-CAM),通過不同特征的通道注意力來賦予兩個分支不同的權重,從而完成其融合,其結構如圖6所示。
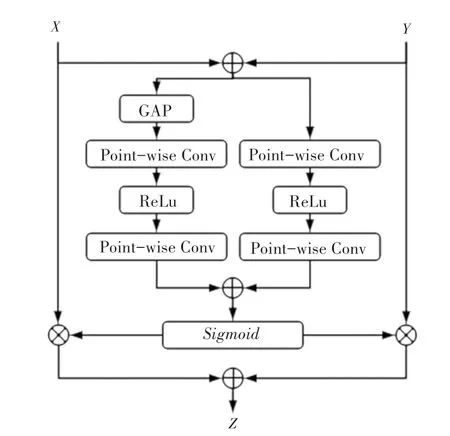
圖6 MS-CAM結構圖Fig.6 Structure of MS-CAM
MS-CAM除了進行池化,還有一個分支使用逐點卷積來進行特征提取,并將兩個特征進行融合。前者更關注全局尺度上的大型對象,而后者更關注通道注意力不同尺度上下文的特征信息。SE的計算方式非常容易丟失原始圖像上的細節信息,而MS-CAM利用多尺度特征提取方式,更好地捕獲局部特征信息。
3 實驗
3.1 數據集
本文使用CASIA-HWDB脫機單字符數據庫中的HWDB 1.1數據集進行實驗。該數據集由中國科學院自動化研究所模式識別國家實驗室建設。脫機單字符數據庫包括3個字符集,其統計數據見表1。其中,HWDB 1.0數據集的3 866個漢字包含GB2312-80字符集3 755個一級漢字中的3 740個漢字;HWDB 1.1數據集的3 755個漢字即為GB2312-80字符集一級漢字全集;HWDB 1.2數據集的3 319個漢字與GB2312-80字符集一級漢字集不相交。
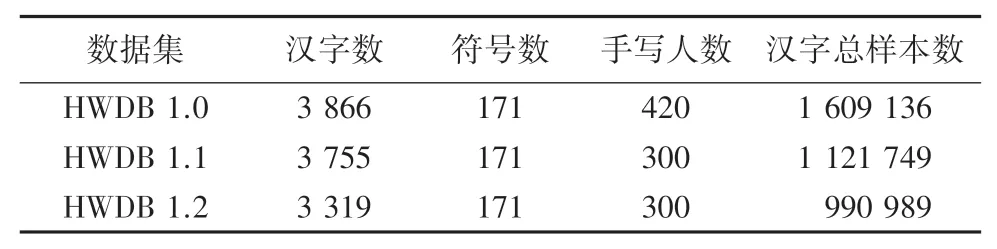
表1 脫機單字符數據庫Tab.1 Database of offline single character
由于樣本尺寸不一致,在輸入網絡之前均將其處理成224×224大小。訓練、測試、驗證集隨機劃分成8∶1∶1。數據集內部分樣本示例如圖7所示。

圖7 部分樣本示例Fig.7 Part of samples
3.2 評價標準
實驗使用準確率()作為評價指標,當進行二分類時,其計算公式如下:

其中,、、、屬于混淆矩陣的概念,其含義見表2。

表2 混淆矩陣及其含義Tab.2 Confusion matrix
準確率的含義就是被正確分類的樣本數量與總樣本數的比值。本文的目標任務是一個多分類(類別數3 755)問題,將二分類擴展為多分類,在計算第個類別的準確率ACC時,應將第類視為正類,其它類別視為負類,計算完所有類別的準確率后計算平均值。因此準確率的計算公式如下:
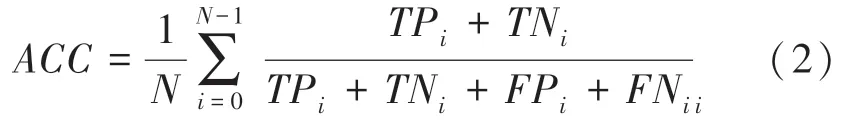
3.3 實驗結果分析
本文所有的實驗均在Ubantu 18.04系統上使用CUDA并行計算架構,并在Cudnn加速計算庫的基礎上搭建PyTorch框架,然后進行加速計算。實驗所用顯卡為NVIDIA GEForce GTX3090(24 G),內存為32.0 GB,CPU為Intel(R)Core(TM)i7-6950X CPU@3.00 GHZ。迭代次數Epoch為100,優化器選擇Adam,優化參數選擇默認。迭代學習率為0.000 1,權值衰減率為1e-5,批大小為80。無預訓練和其他前置任務,每個Epoch后進行一次訓練和一次測試,測試時不更新參數。將結果最好的模型參數保存,最后在驗證集上進行驗證。
本文將VGG19、ResNet18、MobileNetV2、MobileNetV3與改進網絡進行對比實驗。圖8展示了5種網絡使用同一數據集訓練的準確率曲線,可以看出本文所提方法的準確率最高。

圖8 各網絡準確率曲線對比Fig.8 Comparison of accuracy curves of all networks
表3顯示了各網絡模型的準確率和參數量對比結果,其中本文所提方法不但有最好的識別準確率,而且沒有因為進行3 755類漢字的分類而增加過多的參數量。

表3 各網絡模型的對比結果Tab.3 Comparison results of various network models
4 結束語
本文針對目前手寫識別網絡訓練時間長、高資源消耗的問題,提出了一種基于MobileNetV3的脫機手寫漢字識別網絡模型,在不降低識別率的基礎上減少計算機資源消耗,加快訓練速度。本文的主要改進工作:
(1)使用多尺度卷積核獲取不同大小的感受野,豐富特征信息。
(2)采用多尺度通道注意力特征融合將多分支網絡提取的特征進行全局和局部的特征融合,以提高網絡性能。實驗結果表明,本文提出的的改進網絡獲得了更好的識別結果。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
