移動(dòng)機(jī)器人視覺SLAM研究綜述
2022-07-15 09:52:44李延真石立國(guó)徐志根夏清泉
智能計(jì)算機(jī)與應(yīng)用 2022年7期
李延真,石立國(guó),徐志根,程 超,夏清泉
(國(guó)網(wǎng)山東省電力公司青島供電公司,山東 青島 266001)
0 引 言
同時(shí)定位與建圖(Simultaneous Localization And Mapping,SLAM)是移動(dòng)機(jī)器人領(lǐng)域的一個(gè)具有挑戰(zhàn)性的難題。目前SLAM技術(shù)研究主要集中于兩種方法,一是基于便攜式激光測(cè)距儀的方法,即激光SLAM,另一種是基于計(jì)算機(jī)視覺的方法,即視覺SLAM。采用激光雷達(dá)構(gòu)建的點(diǎn)云地圖,在某種程度上無法展現(xiàn)較好的環(huán)境細(xì)節(jié)信息,以至于智能機(jī)器人在環(huán)境復(fù)雜的場(chǎng)景中,不能有效的進(jìn)行環(huán)境信息感知和決策。隨著計(jì)算機(jī)技術(shù)以及視覺傳感器技術(shù)的發(fā)展,視覺SLAM采用相機(jī)來替代激光雷達(dá)重構(gòu)周圍環(huán)境的3D地圖,已取得了巨大且快速的發(fā)展。而且,圖像中包含更加豐富的環(huán)境特征信息,以使得機(jī)器人能夠在更大范圍內(nèi)完成任務(wù)。此外,視覺傳感器的發(fā)展以及深度相機(jī)、立體相機(jī)的出現(xiàn)和改進(jìn),吸引了許多學(xué)者對(duì)視覺SLAM技術(shù)進(jìn)行了大量的研究。視覺SLAM主要由特征提取、特征跟蹤、運(yùn)動(dòng)跟蹤、閉環(huán)檢測(cè)、地圖構(gòu)建、位姿估計(jì)等部分組成。
1 視覺SLAM概述
經(jīng)典視覺SLAM框架如圖1所示,通常包含傳感器數(shù)據(jù)輸入、前端、后端、地圖構(gòu)建以及閉環(huán)檢測(cè)。前端獲取傳感器原始數(shù)據(jù),并對(duì)數(shù)據(jù)進(jìn)行預(yù)處理。例如特征提取,短期和長(zhǎng)期數(shù)據(jù)關(guān)聯(lián)等操作,以便將幾何信息轉(zhuǎn)換為數(shù)學(xué)模型并將其發(fā)送到后端。后端對(duì)前端的輸入模型進(jìn)行優(yōu)化、最小化相機(jī)姿態(tài)的累計(jì)誤差,以及地圖信息的優(yōu)化調(diào)整。閉環(huán)檢測(cè)將相機(jī)圖像的檢測(cè)結(jié)果送到后端處理,通過計(jì)算圖像相似性,對(duì)機(jī)器人經(jīng)過的場(chǎng)景進(jìn)行識(shí)別比對(duì),從而實(shí)現(xiàn)累計(jì)誤差的消除。
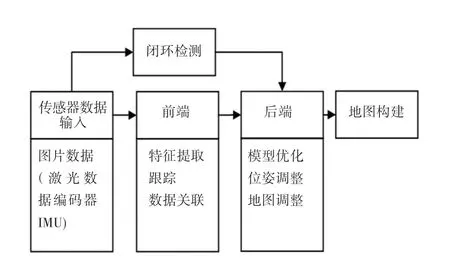
圖1 經(jīng)典SLAM框架Fig.1 Classic SLAM framework
根據(jù)視覺傳感器的不同,視覺SLAM主要分為單目、RGB-D、立體視覺SLAM等方法。其中,采用單相機(jī)解決SLAM問題的方案稱為單目SLAM;而RGB-D SLAM方法不僅需要單目相機(jī),并且需要用到紅外傳感器;立體視覺SLAM則需要在不同方位安裝多個(gè)相機(jī)。視覺傳感器一般具有視覺里程測(cè)量功能,具有足夠的穩(wěn)定性和魯棒性,而且易于實(shí)現(xiàn)。
近十年來,SLAM算法有很多,主要分為基于直接法的視覺SLAM和基于特征點(diǎn)法的視覺SLAM兩大類。
1.1 經(jīng)典SLAM方法
1.1.1 基于特征點(diǎn)的視覺SLAM
Davison等人提出了一種單目SLAM方法,稱為MonoSLAM。MonoSLAM采用EKF算法建立環(huán)境特征點(diǎn)的地圖,這種地圖雖有一定限制,但在解決單目特征初始化的問題上足夠穩(wěn)定。此外,地圖的稀疏性也暴露了機(jī)器人在需要更多環(huán)境細(xì)節(jié)的情況下,無法完成定位任務(wù)的問題。為此,研究出現(xiàn)了UKF方法以及改進(jìn)的UKF方法,用于解決視覺SLAM的線性不確定性。而Sim等人提出的基于PF的單目SLAM方法可以構(gòu)建更精確的映射,但PF方法的算法具有很高的計(jì)算復(fù)雜度,以至于無法在大型環(huán)境下應(yīng)用。Klein等人設(shè)計(jì)了一種基于關(guān)鍵幀的單目SLAM方法,即PTAM。在該方法中,跟蹤和建圖分為兩個(gè)并行化的任務(wù)。關(guān)鍵幀提取技術(shù),即通過數(shù)個(gè)關(guān)鍵圖像串聯(lián),優(yōu)化地圖和運(yùn)動(dòng)軌跡,從而避免了對(duì)每一幅圖像的細(xì)節(jié)進(jìn)行處理。這種方法采用非線性優(yōu)化來替代EKF方法解決線性化的困難,進(jìn)而減少了機(jī)器人在定位中的不確定性。但是,由于PTAM存在全局優(yōu)化的問題,使得該方法無法在大型環(huán)境中應(yīng)用。
2015年,Mur-Artal等人提出了一種新的實(shí)時(shí)視覺SLAM方法---ORB-SLAM。該方法是一種基于特征法的單目SLAM,實(shí)時(shí)估計(jì)3D特征位置和重建環(huán)境地圖,其特征計(jì)算具有良好的旋轉(zhuǎn)和縮放不變性,具有較高的定位精度。但該方法使得CPU運(yùn)算負(fù)擔(dān)大,生成的地圖僅用于定位需求,無法用于導(dǎo)航和避障需求。為此,Mur-Artal等于2017年又提出了一種改進(jìn)算法,即基于ORB-SLAM的ORBSLAM2,其不僅支持RGB-D相機(jī)以外的單目相機(jī)還支持使用立體相機(jī)。
然而,ORB-SLAM2是通過大規(guī)模數(shù)據(jù)生成訓(xùn)練詞匯,當(dāng)詞匯量較大時(shí),其過程對(duì)于移動(dòng)機(jī)器人來說是非常耗時(shí)的。在機(jī)器人工作環(huán)境固定的情況下,使用大數(shù)據(jù)集會(huì)導(dǎo)致大量無效數(shù)據(jù)的產(chǎn)生。此外,ORB-SLAM2還缺乏離線可視化和軌跡建圖的能力。
1.1.2 基于直接法的視覺SLAM
1.ene modo-yi tülekü ɡejü beledkejü bui(我要把這根木頭燒了/我想燒掉這根木頭)
LSD-SLAM、DTAM是基于直接法的單目SLAM方法,使用RGB圖像作為輸入,通過所有像素強(qiáng)度估計(jì)相機(jī)的幀軌跡和重建環(huán)境的3D地圖。DTAM是一種直接稠密的方法,通過在相機(jī)視頻流中提取多張靜態(tài)場(chǎng)景圖片來提高單個(gè)數(shù)據(jù)信息的準(zhǔn)確性,從而實(shí)時(shí)生成精確的深度地圖。該方法計(jì)算復(fù)雜度比較大,需要GPU并行運(yùn)算,對(duì)全局照明處理的魯棒性較差。
LSD-SLAM能夠構(gòu)建一個(gè)半稠密的全局穩(wěn)定的環(huán)境地圖,包含了更全面的環(huán)境表示,在CPU上實(shí)現(xiàn)了半稠密場(chǎng)景的重建。該方法對(duì)相機(jī)內(nèi)參敏感和曝光敏感,需要特征點(diǎn)進(jìn)行回環(huán)檢測(cè),無法在照明不規(guī)律變化的場(chǎng)景中應(yīng)用。
Forster等人提出的SVO(Semi-direct Visual Odoemtry),是一種半直接法的視覺里程計(jì),其是特征點(diǎn)和直接法的混合使用,該方法的時(shí)間復(fù)雜度較低,但是,該方法舍棄了后端優(yōu)化和回環(huán)檢測(cè),而且位姿估計(jì)會(huì)產(chǎn)生累積誤差,因此在移動(dòng)機(jī)器人丟失位置后重定位比較困難。
DSO(Direct Sparse Odometry)也是一種半直接法的視覺里程計(jì),基于高度精確的稀疏直接結(jié)構(gòu)和運(yùn)動(dòng)公式。該方法能夠直接優(yōu)化光度誤差,考慮了光度標(biāo)定模型,該方法不僅完善了直接法位姿估計(jì)的誤差模型,還加入了仿射亮度變換、光度標(biāo)定、深度優(yōu)化等方法,在無特征的區(qū)域中也可以使其具有魯棒性。但是,該方法舍棄了回環(huán)檢測(cè)。
2 視覺SLAM研究熱點(diǎn)
2.1 視覺與慣性傳感器融合的SLAM
VI-SLAM(Visual-Inertial SLAM)將視覺傳感器和IMU優(yōu)勢(shì)結(jié)合,從而為移動(dòng)機(jī)器人提供更加豐富的運(yùn)動(dòng)信息和環(huán)境信息。其主要方式將視覺前段信息與IMU信息結(jié)合,即視覺慣性里程計(jì)(VIO),采用濾波技術(shù)以及優(yōu)化方法,對(duì)采集的物理量信息進(jìn)行處理,進(jìn)而實(shí)現(xiàn)對(duì)自身的運(yùn)動(dòng)和環(huán)境信息估計(jì)。當(dāng)視覺傳感器在短時(shí)間內(nèi)快速運(yùn)動(dòng)失效時(shí),融合IMU數(shù)據(jù)能夠?yàn)橐曈X提供短時(shí)的精準(zhǔn)定位,同時(shí)利用視覺定位信息來估計(jì)IMU的零偏,減少IMU由零偏導(dǎo)致的發(fā)散和累積誤差。通過二者的融合,可以解決視覺位姿估計(jì)輸出頻率低的問題,同時(shí)位姿估計(jì)精度有一定的提高,整個(gè)系統(tǒng)也更加魯棒。目前VI-SLAM已在機(jī)器人、無人機(jī)、無人駕駛、AR和VR等多個(gè)領(lǐng)域有所應(yīng)用。
MSCKF算法將視覺與慣性信息在EKF框架下融合,相較于單純的VO算法,該算法能夠應(yīng)用在運(yùn)動(dòng)劇烈、紋理短時(shí)間缺失等環(huán)境中,而且魯棒性更好;相較于基于優(yōu)化的VIO算法(VINS,OKVIS),MSCKF精度相當(dāng)、速度更快,適合在計(jì)算資源有限的嵌入式平臺(tái)運(yùn)行。ROVIO是基于單目相機(jī)開發(fā)的緊耦合VIO系統(tǒng),通過對(duì)圖像塊的濾波實(shí)現(xiàn)VIO,利用擴(kuò)展卡爾曼濾波進(jìn)行狀態(tài)估計(jì),使用速度更快的FAST來提取角點(diǎn),其三維坐標(biāo)用向量和距離表示。其次,所有角點(diǎn)是通過圖像塊進(jìn)行描述,并通過視頻流獲取了多層次表達(dá);最后利用IMU估計(jì)的位姿來計(jì)算特征投影后的光度誤差,并將其用于后續(xù)優(yōu)化。雖然該算法計(jì)算量小,但對(duì)應(yīng)不同的設(shè)備需要調(diào)參數(shù)(參數(shù)對(duì)精度很重要),并且沒有閉環(huán),經(jīng)常存在誤差,會(huì)殘留到下一時(shí)刻。
2.2 視覺與激光雷達(dá)融合的SLAM
視覺與激光雷達(dá)融合的SLAM,是將激光雷達(dá)在建圖和距離測(cè)量時(shí)準(zhǔn)確度較好的優(yōu)勢(shì),與視覺方法構(gòu)建環(huán)境信息較準(zhǔn)確的優(yōu)勢(shì)相結(jié)合,在一定程度上能夠避免單相機(jī)在使用過程中的單目尺度漂移、雙目深度估計(jì)精度不高、戶外RGB-D稠密重建困難的缺陷,將有效提升SLAM性能。其確定是標(biāo)定和融合比較困難。
視覺與激光雷達(dá)融合的SLAM主要分為:改進(jìn)的視覺SLAM、改進(jìn)的激光SLAM以及并行激光與視覺SLAM。
J.Graeter等人提出了一種激光-視覺里程計(jì)方法(LiDAR-Monocular Visual Odometry,LIMO)。該方法從LiDAR中提取圖片中特征點(diǎn)的深度,不僅考慮局部平面假設(shè)的外點(diǎn),并考慮了地面點(diǎn)。Shin等人利用LiDAR提供的稀疏深度,提出了一種基于單目相機(jī)直接法的視覺SLAM框架。采用滑動(dòng)窗口進(jìn)行追蹤的方法,忽略舊的關(guān)鍵幀,不在大規(guī)模場(chǎng)景下集成了深度的幀與幀的匹配方法。這種方法相機(jī)分辨率比激光雷達(dá)分辨率高,從而導(dǎo)致許多像素缺失深度信息。為處理相機(jī)和激光雷達(dá)分辨率匹配的問題,De Silva等人在計(jì)算兩個(gè)傳感器之間的幾何變換后,采用高斯過程回歸,對(duì)缺失值進(jìn)行插值。Scherer等人采用VIO對(duì)機(jī)器人的狀態(tài)進(jìn)行估計(jì),采用激光雷達(dá)進(jìn)行障礙物及邊界檢測(cè),但是激光雷達(dá)的點(diǎn)云數(shù)據(jù)可能包含遮擋點(diǎn),從而對(duì)精度有一定的影響。為提高精度,Huang等人提出一種基于直接法的SLAM方法,采用遮擋點(diǎn)檢測(cè)器和共面點(diǎn)檢測(cè)器解決這一問題。
在一些研究中,視覺-激光SLAM,采用激光雷達(dá)掃描匹配進(jìn)行運(yùn)動(dòng)估計(jì),相機(jī)進(jìn)行特征檢測(cè),從而對(duì)純激光SLAM的缺陷進(jìn)行相應(yīng)的彌補(bǔ)。Liang等人提出了一種解決激光和相機(jī)傳感器集成的大規(guī)模激光碰撞中的閉環(huán)問題。其利用ORB特征和詞袋特征,實(shí)現(xiàn)了環(huán)路檢測(cè)的快速、魯棒性。通過在不同大規(guī)模環(huán)境下的實(shí)驗(yàn),驗(yàn)證了該方法的有效性。Zhu等人將3D激光SLAM和視覺關(guān)鍵幀詞袋回環(huán)檢測(cè)相融合,并對(duì)最近點(diǎn)迭代(ICP)進(jìn)行優(yōu)化。Pandey等人利用3D點(diǎn)云與可用相機(jī)圖像的共配準(zhǔn),將高尺度特征描述符(如尺度不變特征變換(SIFT)或加速魯棒特征(SURF))與3D點(diǎn)相關(guān)聯(lián),即利用視覺信息對(duì)剛性轉(zhuǎn)換做了預(yù)測(cè),并且建立通用的ICP框架。
此外,并發(fā)視覺激光融合也是一個(gè)研究方向。Seo等人同時(shí)采用激光雷達(dá)和視覺傳感器并行構(gòu)建了兩個(gè)地圖:激光雷達(dá)立體像素地圖和具有地圖點(diǎn)的視覺地圖,并在后端優(yōu)化中運(yùn)用殘差對(duì)里程求解,使其保持全局一致,從而能夠更好的進(jìn)行狀態(tài)估計(jì),是一種緊耦合的方法。Zhang等人提出一種視覺雷達(dá)里程計(jì)的通用框架。該方法使用高頻運(yùn)行的視覺里程計(jì)作為圖像幀速率(60 Hz)來估計(jì)運(yùn)動(dòng),并使用低頻率(1 Hz)激光雷達(dá)測(cè)距儀細(xì)化運(yùn)動(dòng)估計(jì),并消除由視覺測(cè)距漂移引起的點(diǎn)云失真。
2.3 基于深度學(xué)習(xí)的視覺SLAM
將深度學(xué)習(xí)理論引入視覺SLAM中,主要應(yīng)用包含:使用深度神經(jīng)網(wǎng)絡(luò)對(duì)單目視覺深度進(jìn)行估計(jì);將深度學(xué)習(xí)與視覺SLAM前端結(jié)合,從而提高圖像特征提取的準(zhǔn)確度;融入物體識(shí)別、目標(biāo)檢測(cè)、語音分割等技術(shù),進(jìn)而增加對(duì)周圍環(huán)境信息的感知與理解。
Zhou等人提出了一種單目深度和位姿估計(jì)的無監(jiān)督學(xué)習(xí)網(wǎng)絡(luò),其特點(diǎn)是完全無監(jiān)督網(wǎng)絡(luò),從非結(jié)構(gòu)化視頻序列進(jìn)行單視圖深度估計(jì)和多視圖位姿估計(jì),但得到的深度和位姿缺乏系統(tǒng)尺度。Godard等人提出了一種卷積神經(jīng)網(wǎng)絡(luò),替代了直接用深度圖數(shù)據(jù)訓(xùn)練,采用容易獲得的雙目立體視覺的角度,在沒有參考深度數(shù)據(jù)的情況下,估計(jì)單個(gè)圖像的深度,從而可以執(zhí)行端到端無監(jiān)督單眼深度估計(jì),并加強(qiáng)左右視差圖的一致性,從而提升性能和魯棒性。Mahjourian等人提出了一種基于無監(jiān)督學(xué)習(xí)的新方法,對(duì)單目視頻中的深度與自我運(yùn)動(dòng)的估計(jì),最終作者在KITTI數(shù)據(jù)集和手機(jī)拍攝的微景觀標(biāo)定的視頻數(shù)據(jù)集上進(jìn)行了算法驗(yàn)證。Daniel DeTone等人提出了一種DeepSlam,在存在圖像噪聲的情況下進(jìn)行特征點(diǎn)檢測(cè),相比傳統(tǒng)方案,具有顯著的性能差距。此外,DeTone等人還提出了一個(gè)自監(jiān)督框架SuperPoint,適用于計(jì)算機(jī)視覺中大量多視圖幾何問題的興趣點(diǎn)檢測(cè)器和描述符的訓(xùn)練。Jiexiong Tang等人提出了一種基于深度學(xué)習(xí)的GCNv2網(wǎng)絡(luò)(GCN-SLAM),用于生成關(guān)鍵點(diǎn)和描述符。
JohnMcCormac等人提出了Semanticfusion方法,使用CNN進(jìn)行語義分割,加上條件隨機(jī)場(chǎng)對(duì)分割結(jié)果的優(yōu)化,設(shè)計(jì)了semantic mapping系統(tǒng),是一種將CNN和最先進(jìn)的稠密SLAM融合方案。Thomas Whelan等人提出了ElasticFusion,用來構(gòu)建語義三維地圖。Bowman等人提出一種融合尺度信息與語義信息的理論框架,通過對(duì)目標(biāo)進(jìn)行相應(yīng)的檢測(cè),將尺度信息和語義信息結(jié)合,從而實(shí)現(xiàn)對(duì)運(yùn)動(dòng)估計(jì)和地圖的優(yōu)化。
2.4 動(dòng)態(tài)環(huán)境下的視覺SLAM
目前,大部分的研究都是基于靜態(tài)環(huán)境,而且光線良好,且為非單調(diào)紋理特征的情形。但實(shí)際生活場(chǎng)景中還會(huì)有大量動(dòng)態(tài)的行人或者物體,所以研究動(dòng)態(tài)環(huán)境下的SLAM也是極其重要的。其關(guān)鍵技術(shù)就是將動(dòng)態(tài)的行人或物品等特征點(diǎn),能夠在地圖中過濾移除,避免對(duì)定位和閉環(huán)檢測(cè)產(chǎn)生不良影響
為此,Wei Tan等人提出了RDSLAM(Robust monocular slam)方法,其是一種基于關(guān)鍵幀的在線表示和更新方法的實(shí)時(shí)單目SLAM系統(tǒng)。該方法可以處理緩慢變化的動(dòng)態(tài)環(huán)境,能夠檢測(cè)變化并及時(shí)更新地圖。Chao Yu等人提出了一個(gè)面對(duì)動(dòng)態(tài)環(huán)境的語義視覺SLAM系統(tǒng)DS-SLAM。該方法結(jié)合語義信息和運(yùn)動(dòng)特征點(diǎn)檢測(cè),來濾除每一幀中的動(dòng)態(tài)物體,從而提高位姿估計(jì)的準(zhǔn)確性,同時(shí)建立語義八叉樹地圖。其是基于優(yōu)化ORB-SLAM的方法,使其具有更好的魯棒性。 MaskFusion是由RüNZ M等人提出的一個(gè)實(shí)時(shí)的、具備對(duì)象感知功能的、語義和動(dòng)態(tài)RGB-D SLAM系統(tǒng)。該方法在連續(xù)的、自主運(yùn)動(dòng)中,能夠在跟蹤和重建的同時(shí),識(shí)別分割場(chǎng)景中不同的物體并分配語義類別標(biāo)簽。DynaSLAM是一個(gè)在動(dòng)態(tài)環(huán)境下輔助靜態(tài)地圖的SLAM系統(tǒng),通過增加運(yùn)動(dòng)分割方法使其在動(dòng)態(tài)環(huán)境中具有穩(wěn)健性,并且能夠?qū)?dòng)態(tài)物品遮擋的部分進(jìn)行修復(fù)優(yōu)化,生成靜態(tài)場(chǎng)景地圖。StaticFusion是一種面向動(dòng)態(tài)環(huán)境基于面元的RGB-D SLAM系統(tǒng),能夠在動(dòng)態(tài)環(huán)境中檢測(cè)運(yùn)動(dòng)目標(biāo)并同時(shí)重建背景結(jié)構(gòu),但該方法的初始若干幀內(nèi)不能有大量動(dòng)態(tài)物體,否則初始靜態(tài)場(chǎng)景面元地圖的不準(zhǔn)確性增加。
3 結(jié)束語
在視覺SLAM發(fā)展的三十年里,已取得了重大的成果,形成一些常用的框架方法,在機(jī)器人、無人機(jī)、無人駕駛、AR和VR等多個(gè)領(lǐng)域已有所應(yīng)用。針對(duì)視覺SLAM經(jīng)典研究方法的特點(diǎn)做一總結(jié),見表1。
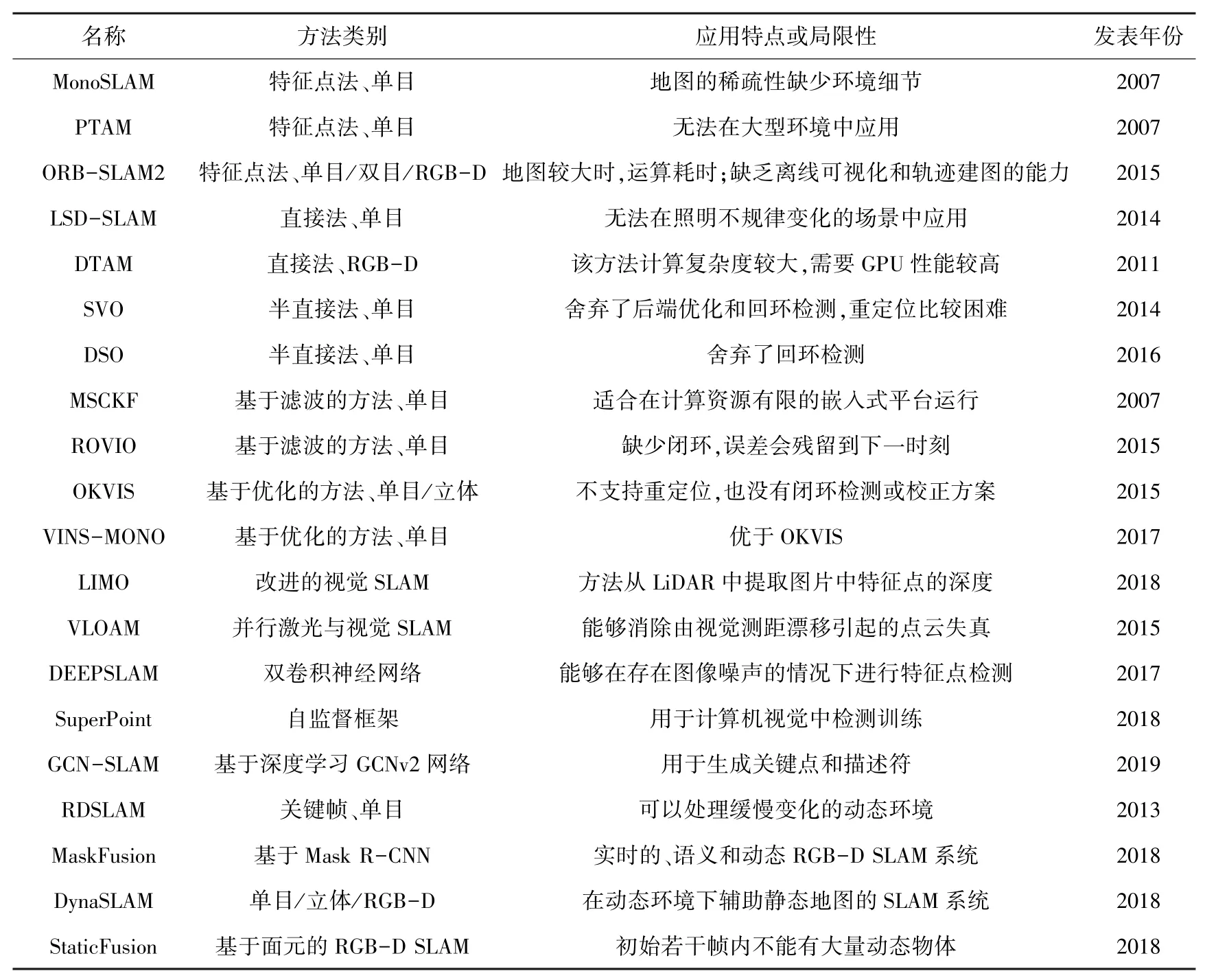
表1 視覺SLAM經(jīng)典方法總結(jié)Tab.1 Summary of classical visual SLAM
綜上所述,目前已有的SLAM方法仍然在計(jì)算力問題、室外動(dòng)態(tài)大規(guī)模地圖構(gòu)建、地圖復(fù)用等方面存在不足,以及在實(shí)時(shí)性與準(zhǔn)確性問題上難以兼顧。目前,SLAM應(yīng)用場(chǎng)景不斷變化,移動(dòng)環(huán)境場(chǎng)景也不斷增多,SLAM算法在動(dòng)態(tài)物體及動(dòng)態(tài)環(huán)境方面要求也不斷升高,同時(shí)實(shí)時(shí)性要求也隨之提高,這也成為今后SLAM算法的研究方向,隨著新型傳感器以及更多算法的研究與發(fā)展,視覺SLAM也不斷提高精度及魯棒性,平衡實(shí)時(shí)性和準(zhǔn)確性,向可移植、多傳感器融合以及智能語義SLAM的方向發(fā)展。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
