基于K-BERT的情感分析模型
2022-07-15 09:52:44王桂江黃潤才
智能計算機與應用 2022年7期
王桂江,黃潤才
(上海工程技術大學 電子電氣工程學院,上海 201620)
0 引 言
大數(shù)據(jù)時代的社交媒體為用戶提供了反饋和信息交流的平臺,對于一件商品,不同的人有不同的看法,了解用戶的看法和態(tài)度,是改進和優(yōu)化的重要途徑。情感分析是對用戶觀點的凝練,代表著用戶的實際感受。
情感分析的發(fā)展經歷了3個主要階段,基于情感詞典、基于機器學習和基于深度學習。情感詞典作為最早的情感分析方式,通過將人們可能的觀點評價構建一個字典,進行內容的匹配,以此來獲得用戶的情感傾向,這類的方法簡單直接,不需要太復雜的方法就能獲取到結果,但是情感詞典的構建卻需要大量的人力、物力和精力。而且隨著社會的發(fā)展,基于情感詞典已經無法跟上時代的變化。機器學習的出現(xiàn),一定程度上解決了情感詞典構建的問題,基于機器學習的方法根據(jù)文本提取的特征進行分類,即利用支持向量機(Support Vector Machines,SVM)等分類器,但是這類方法仍然需要人工標注的數(shù)據(jù),分類器的結果也取決于數(shù)據(jù)的標記效果,泛化能力并不強。
隨著深度學習的發(fā)展,自然語言處理進入了新的發(fā)展階段。基于深度學習的情感分析有3個典型代表:
(1)利用神經網絡訓練詞向量。利用神經網絡訓練得到詞向量,之后將詞向量的結果應用到下游任務中。比較典型的方法是利用Word2Vec訓練詞向量,將訓練好的詞向量送入循環(huán)神經網絡(RNN)進行分析。
(2)利用循環(huán)神經網絡RNN。RNN是處理時序問題的關鍵技術,基于RNN改進的長短時記憶網絡(Long Short-Term Memory,LSTM)、門控循環(huán)單元(Gated Recurrent Unit,GRU)。陳帆利用LSTM對微博情感進行分析,并用于微博特定主題的謠言識別;李輝等利用GRU學習文本詞語,并引入注意力機制實現(xiàn)了比LSTM有競爭力的效果。但是對于情感分析,獲取上下文非常有必要,張俊飛等用BiLSTM來獲取上下文信息,將提取到的信息送入分類器,對評教評語進行情感分析。這類方法的效果依賴于特征提取的效果,而且激活函數(shù)的選擇也關系到最終的分類效果。
(3)無監(jiān)督學習,并充分考慮上下文信息。基于注意力機制的Transformer模型,使用編碼和解碼的機制,通過對注意力機制進行不同形式的構造,取得了比RNN更強的效果;基于Transformer的BERT模型,在傳統(tǒng)的分類、問答和翻譯等十多項任務中取得了歷史最好的成績,郝彥輝等在BERT模型的基礎上引入BiLSTM,根據(jù)上下文判斷情感傾向不明顯的內容的真實情感傾向;李文亮等在BERT的基礎上融合多層注意力機制,在方面級情感分析上取得了不錯的效果。
基于BERT預訓練模型,升級和改造出了如ALBERT、XLNET等表現(xiàn)不俗的模型,基于transformer-XL的XLNET使用相對小的數(shù)據(jù)規(guī)模實現(xiàn)了接近BERT的效果;ALBERT使用相對小的模型實現(xiàn)了與BERT接近的表現(xiàn),甚至在部分場景下效果更好。盡管這一類的預訓練模型在特征提取和詞向量構建上表現(xiàn)出了較好的效果,但卻存在無法理解語義背景的問題,比如:“基督山伯爵在巴黎的住處位于香榭麗舍大街,他很期待在這里遇見莫雷爾先生”是一句包含了地點、人物和社會關系的句子,而且?guī)в虚_心的語氣,如果不能理解其背景,只能感覺他在會見朋友。
綜上所述,基于前人的研究成果和優(yōu)化策略,為更好的獲取文本信息的語義特征,增強對于語義信息的理解,提升模型對文本的情感分析能力,本文提出了結合K-BERT和BILSTM的情感分析模型,使用帶有知識圖譜的K-BERT代替BERT,豐富句子的背景信息,有利于組合句子內容,提高特征提取能力;在K-BERT基礎上引入BILSTM,進一步增強對于上下文之間的語義提取;模型在NLP中文文本任務情感分類數(shù)據(jù)集上表現(xiàn)出了有競爭力的效果。
1 K-BERT語言模型概述
K-BERT是融合知識圖譜的語言訓練模型,該模型在開放域的8個中文NLP任務上超過了Google BERT,模型由Knowledge layer、Embedding layer、Seeing layer、Mask-Transformer Encoder組成。
1.1 Knowledge layer
Knowledge layer的作用是將知識圖譜關聯(lián)到句子中,形成一個包含背景知識的句子樹(Sentence Tree)。知識嵌入句子的過程可以分為知識圖譜查詢(K-Query)和知識譜圖嵌入(K-Inject)。KQuery從知識圖譜中查詢句子所涉及到的命名實體,K-Inject將查詢到的命名實體相關的三元組嵌入到句子中合適的位置上,形成句子樹。假設給定句子{,,…,w}和知識圖譜(knowledge graph,KG),知識層輸出的句子樹結構為{,,…,w{(r,w),…,(r,w)},…,w},句子樹形狀如圖1所示。

圖1 句子樹結構Fig.1 Sentence tree structure
其中w是從知識譜圖中查詢到的命名實體;r是與w相關的第個分支;w是與w相關的第個分支對應的值。
1.2 Embedding layer
Embedding layer層包含token embedding、softposition embedding和segment embedding,其作用是將句子樹轉換成為序列,同時要保留句子樹的結構信息。
Token-embedding主要用于實現(xiàn)句子樹的序列化,將句子中的每個token映射成為一個維度的向量表示,并在每個句子的開頭添加一個[CLS]標記;
一是明確專項工作包聯(lián)主體。項目引進之后,黨委政府明確牽頭領導和責任單位,將轄區(qū)管理和職能部門有效連接,給予回鄉(xiāng)創(chuàng)業(yè)項目全面、實時、無縫的服務,盡最大努力協(xié)調解決項目遇到的困難。二是加強基礎設施建設力度。地方黨委政府加快推進農村路網、管網、電網、通信網等基礎設施建設,為回鄉(xiāng)項目提供硬件條件支持。三是督促項目規(guī)范有序運作。地方黨委政府除了服務項目運作,還積極擔負起監(jiān)督項目規(guī)范運作的職責,督促企業(yè)規(guī)范運用各類優(yōu)惠政策,遵紀守法、安全生產,做好相關職工維權和矛盾調處工作,真正確保項目健康運作、良性發(fā)展。
Soft-position embedding在BERT中,所有句子的輸入信息都對應一個位置信息,在K-BERT中,將句子樹的內容平鋪以后,當分支中的token插入到對應的主干節(jié)點之后,主干節(jié)點后續(xù)的token會發(fā)生移動,導致原有的位置信息發(fā)生變化,軟位置(Soft position)通過對句子樹的位置進行二次編碼,將其原有的順序信息進行恢復,理順了句子的結構。
Segment embedding該層用以區(qū)分一個句子對中的兩個句子,當包含多個句子時,第一個句子中的各個token被賦值為,第二個句子中的各個token被賦值為,當只有一個句子時,segment embedding為。
1.3 Seeing layer
Seeing layer層的作用是通過一個可視化矩陣來限制詞與詞之間的關系,解決句子樹軟位置編碼后的一對多現(xiàn)象。對于一個可視化矩陣,相互可見的取值為0,互不可見的取值為-∞,定義如式(1):

1.4 Mask-Transformer
Mask-Transformer的核心思想是讓一個詞的嵌入只來源于其同一個枝干的上下文,而不同枝干的詞之間相互不受影響,可視化矩陣解決了句子樹位置不同但編碼相同的問題,通過在softmax函數(shù)中添加可見矩陣,控制注意力的影響系數(shù)。Mask-Transformer由12層mask-self-attention堆疊,mask-self-attention的定義如式(2)~式(4):
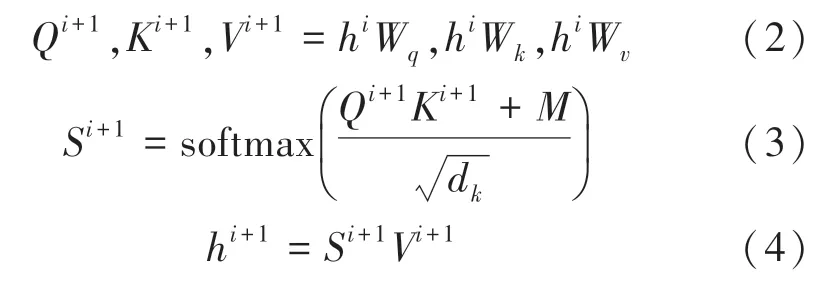
其中:W,W,W是需要學習的模型參數(shù);h是隱狀態(tài)的第個mask-self-attention塊;d是縮放因子;為可見矩陣。
Embedding layer、seeing layer、句子樹和可見矩陣是K-BERT的處理的關鍵技術,四者之間的關系如圖2所示。從knowledge layer得到句子樹后,對句子樹同時構建可視化矩陣和送入embedding layer編碼,這兩個過程得到的信息歸并后輸入到maskselft-attention中進行計算。
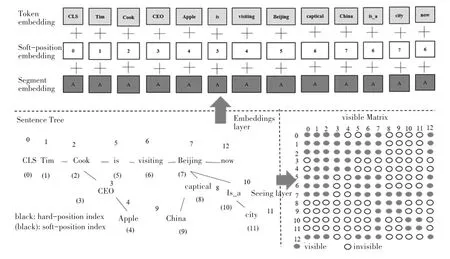
圖2 K-BERT處理的關鍵技術Fig.2 Key technology of K-BERT processing
2 一種改進K-BERT的情感分析模型
本文在K-BERT的基礎上,通過引入雙向LSTM,增強模型對于上下文的語義關聯(lián)能力,使模型既有豐富的背景知識,又能很好的關聯(lián)上下文,獲取更多的語義信息,從而實現(xiàn)情感分類效果的提升。本文的模型如圖3所示,稱其為KB-BERT。
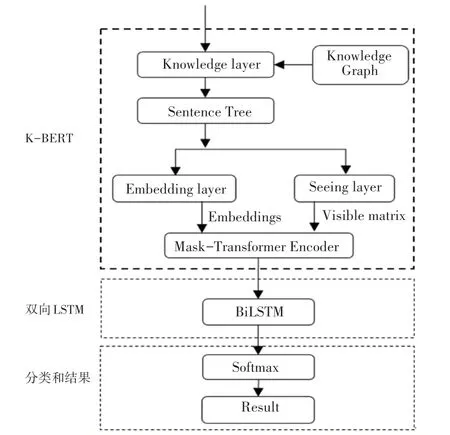
圖3 KB-BERT情感分析模型Fig.3 KB-BERT sentiment analysis model
BILSTM層:雙向LSTM層的目的是學習文本所含特征,K-BERT層計算輸出的詞向量在LSTM層進行再次學習,獲取句子的上下文信息,對語義信息進一步增強;
Softmax層:經過雙向LSTM提取到的特征信息被輸入到softmax層中進行分類,將情感分為正面和負面。
2.1 BiLSTM層
LSTM是一種基于RNN的網絡結構,LSTM由輸入門、遺忘門、記憶單元和輸出門4部分組成,LSTM結構如圖4所示。
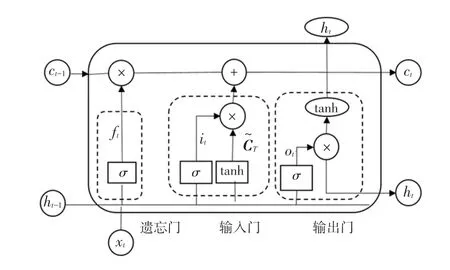
圖4 LSTM網絡結構Fig.4 LSTM network structure
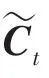
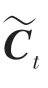
遺忘門:
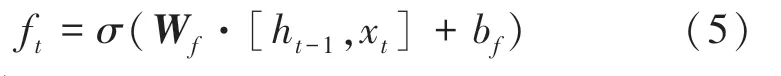
輸入門:

輸出門:

其中,和b分別為遺忘門的權重矩陣和偏置;和b分別為輸入門的權重矩陣和偏置;為候選向量;和b分別為輸出門的權重矩陣和偏置;和b分別是計算單元的權重矩陣和偏置。
2.2 Softmax分類層
經過處理后的信息使用soft max層進行情感分類。softmax為每個輸出分類的結果均賦值一個概率,表示每個類別的可能性,式(11):
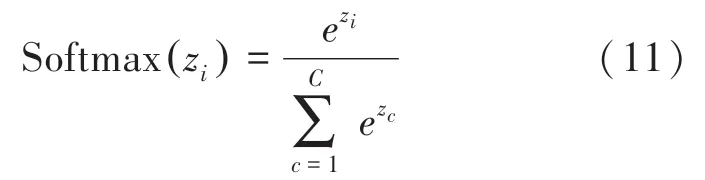
其中,z為第個結點的輸出值;C為輸出結點的個數(shù);s是當前元素與所有元素的比值,即當前元素的概率。
3 實驗
3.1 實驗環(huán)境及數(shù)據(jù)集
本實驗環(huán)境:處理器:E3-1281-V3 3.7 GHz八核;內存:16 GB 1 600 MHz DDR3;GPU:華碩1070Ti 8G;系 統(tǒng) 環(huán)境:Ubuntu 18.04 LTS;編程語言:python3.7,pycharm開發(fā)環(huán)境,深度學習庫為Pytorch。
本文使用Book_review和Weibo兩個情感數(shù)據(jù)集,正面情緒標簽為1,負面情緒標簽為0。Book_review從豆瓣獲取,包含正負情緒各20 000條;Weibo從新浪微博獲取,包含正負情緒各60 000條。
3.2 評價指標
為了驗證模型的有效性,采用準確率()對測試集和驗證集進行分別驗證,準確率的計算公式(12):
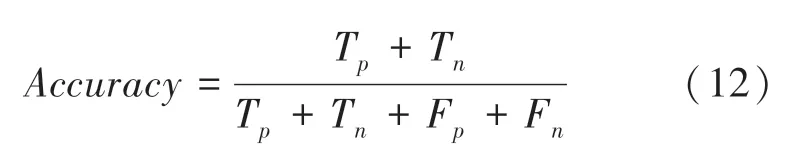
其中,T表示正面評價樣本中被預測為正面的樣本總數(shù);T表示負面評價樣本中被預測為負面的樣本總數(shù);F表示負面評價樣本中被預測為正面的樣本總數(shù);F表示正面評價樣本中被預測為負面的樣本總數(shù)。
3.3 對比實驗設置
為證明本文方法的有效性,取以下對比方法進行驗證:
(1)Google BERT。首先將輸入的文本進行詞向量編碼,對于獲取到的詞向量進行信息提取,之后運用分類器進行結果分類。
(2)K-BERT。首先對輸入的句子進行命名實體識別,之后對識別到的命名實體從知識圖譜中查詢關聯(lián)詞,將查詢到的關聯(lián)詞插入到句子中形成包含背景知識的句子樹,對輸入的句子樹編碼,得到信息豐富的詞向量,將得到的詞向量直接送入分類器進行結果分類。
(3)KB-BERT。首先使用K-BERT獲取信息豐富的詞向量,將得到的詞向量送入LSTM循環(huán)網絡二次特征提取,豐富上下文提取,最后將得到的詞向量送入分類器進行結果分類。
3.4 實驗參數(shù)
實驗一共訓練5個epoch,每次的信息輸入量batch_size為8,使用dropout防止過擬合,dropout的值設置為0.5,使用12層mask-self-attention,學習率設置為0.000 02。
3.5 結果分析
在本地實驗條件下,KB-BERT、K-BERT和Google BERT在Book_review和Weibo數(shù)據(jù)集上的表現(xiàn)如圖5和圖6所示,其中圖5是驗證集上的效果,圖6是測試集上的效果。

圖5 不同模型在驗證集上的準確率(%)Fig.5 Accuracy of different models on the validation set(%)

圖6 不同模型在測試集上的準確率(%)Fig.6 Accuracy of different models on the test set(%)
在Book_review數(shù)據(jù)集上,KB-BERT的效果最好。在驗證集上較K-BERT提升0.6%,較BERT提升0.9%;在測試集上,較K-BERT提升0.2%,較BERT提升0.1%。這說明,在數(shù)據(jù)內容為長文本的情況下,引入LSTM有助于對上下文信息的獲取,本文優(yōu)化后的模型在Book_review數(shù)據(jù)集上的表現(xiàn)最佳,準確率在驗證集上達到87.97%。
在Weibo數(shù)據(jù)集上,BERT、K-BERT和KBBERT表現(xiàn)近乎一致。這說明,在文本內容較為稀疏無規(guī)則的情況下,引入知識圖譜不能很好的得到命名實體,但是簡短的稀疏文本在使用LSTM后,對于上下文的語義獲取有一定的提升,說明在簡短稀疏的文本內容中,LSTM網絡對于增強語義獲取仍舊發(fā)揮效果。盡管三者的區(qū)別不大,但本文所用方法在Weibo數(shù)據(jù)集上仍然取得最佳的效果,準確率在驗證集上達到98.28%。
引入雙向LSTM的KB-BERT模型,由Book_review和Weibo數(shù)據(jù)集上的表現(xiàn)說明,對于增強上下文語義理解,提升準確率均有效果。在涉及專業(yè)知識或背景知識的情況下,對于長文本的分析結果表現(xiàn)更佳,對于短文本和稀疏文本,所提模型仍然有效。
4 結束語
本文給出了一種具有知識圖譜背景的情感分析模型KB-BERT。首先,通過K-BERT對輸入的內容進行處理,豐富其知識背景,增強語義的理解能力;其次,引入雙向LSTM網絡,進一步增強對于語義的上下文內容理解。實驗結果表明,改進后的KB-BERT在涉及背景信息的長文本數(shù)據(jù)上表現(xiàn)更好,在Book_reivew和Weibo兩個中文數(shù)據(jù)集上,準確率分別達到87.97%和98.33%,證明了本文方法的有效性。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
開放教育研究(2020年2期)2020-03-31 01:54:14
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
