基于知識增強(qiáng)的NL2SQL方法
2022-07-15 09:52:34王秋月程路易王志軍
智能計算機(jī)與應(yīng)用 2022年7期
王秋月,程路易,徐 波,王志軍
(東華大學(xué) 計算機(jī)科學(xué)與技術(shù)學(xué)院,上海 201620)
0 引 言
關(guān)系型數(shù)據(jù)庫是信息系統(tǒng)的基礎(chǔ)和核心。用戶可以用SQL查詢來檢索數(shù)據(jù)庫中的數(shù)據(jù),但這通常對用戶的SQL掌握水平有一定要求。而通過自然語言直接與數(shù)據(jù)庫交互可以幫助非技術(shù)用戶獲取到關(guān)系型數(shù)據(jù)庫中的信息,提高用戶的使用效率和體驗。因此,本文研究的任務(wù)是將自然語言問句轉(zhuǎn)化為SQL查詢(NL2SQL)。目前解決此任務(wù)的主流方法是基于草圖的模型,其考慮了SQL的句法模式,通過SQL語句中的關(guān)鍵詞如“SELECT”、“FROM”、“WHERE”等將原任務(wù)拆解為多個子任務(wù)。草圖框架具體實例如圖1所示,以問句“How many number does Fordham school have?”為例,其對應(yīng)的表包含列名Player(選手)、No.(編號)、Position(位置)、School/Club Team(學(xué)校/俱樂部球隊)等。按照草圖框架,需要完成6個子任務(wù)的預(yù)測,根據(jù)模板進(jìn)行槽填充構(gòu)建完整的SQL語句。第一,需要預(yù)測SELECT從句中出現(xiàn)的列(SELECT-COLUMN子任務(wù)),此例中預(yù)測結(jié)果“No.”;第二,需要預(yù)測SELECT從句中出現(xiàn)的列對應(yīng)的聚合操作(SELECT-AGGREGATION子任務(wù)),此例中預(yù)測結(jié)果為“COUNT”;第三,需要預(yù)測WHERE從句中條件的數(shù)量(WHERE-NUMBER子任務(wù)),此例中預(yù)測結(jié)果為1個;第四,需要預(yù)測WHERE從句中出現(xiàn)的列(WHERE-COLUMN子任務(wù)),此例中預(yù)測結(jié)果為“School/Club Team”;第五,需要預(yù)測WHERE從句中條件列對應(yīng)的操作(WHERE-OPERATOR子任務(wù)),此例中預(yù)測結(jié)果為“=”;第六,需要預(yù)測WHERE從句中條件列對應(yīng)的條件值(WHEREVALUE子任務(wù)),此例中預(yù)測結(jié)果為“Fordham”。
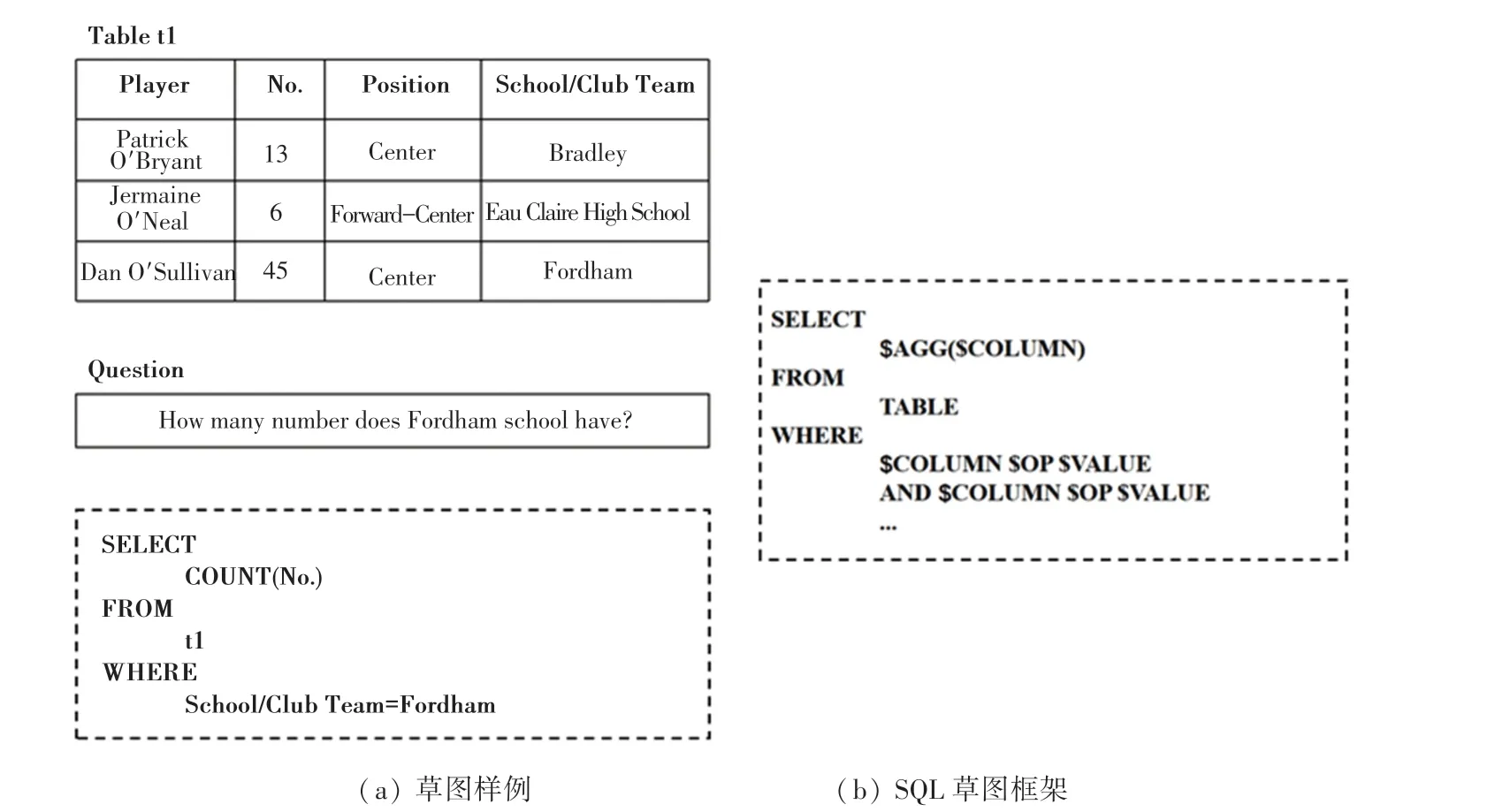
圖1 基于草圖的方法Fig.1 Sketch-based approach
雖然目前NL2SQL任務(wù)上提出的方法達(dá)到了比較好的效果,但仍然不足,這些方法都是對問句進(jìn)行直接編碼,缺乏語義信息,不能充分地理解問句。
針對自然語言問句存在語義缺失的問題,本文考慮利用外部知識圖譜來對自然語言問句進(jìn)行語義增強(qiáng),使其包括充分的語義信息。基于知識增強(qiáng)的NL2SQL方法主要面臨3個挑戰(zhàn):
(1)對問句的哪些部分進(jìn)行增強(qiáng);
(2)用外部知識圖譜中的哪類知識進(jìn)行增強(qiáng);
(3)如何進(jìn)行增強(qiáng)。
針對第一個挑戰(zhàn),本文提出對問句中出現(xiàn)的命名實體進(jìn)行增強(qiáng),并使用現(xiàn)有的實體鏈接技術(shù),將問句中的命名實體鏈接到外部知識圖譜中;針對第二個挑戰(zhàn),本文將知識圖譜中的知識類別分為摘要(Abstract)、類型(Type)、標(biāo)簽(Category)、語義關(guān)系(Infobox)4種,并系統(tǒng)調(diào)研了各種類型知識的增強(qiáng)效果;針對第三個挑戰(zhàn),本文分別提出了一種基于符號化知識的增強(qiáng)方法和兩種基于向量化知識的增強(qiáng)方法。在公開的大規(guī)模的NL2SQL數(shù)據(jù)集WiKiSQL上進(jìn)行實驗,實驗結(jié)果證明了本文提出的增強(qiáng)方法的有效性。
1 相關(guān)工作
NL2SQL的方法主要分為兩大類。
第一類是基于Seq2seq模型,采用“編碼器-解碼器”將此任務(wù)轉(zhuǎn)化為從文本到SQL的翻譯任務(wù),代表方法是Seq2SQL,將SQL語句劃分為SELECT從句和WHERE從句兩部分,并分開獨立生成,這類方法存在兩種缺陷:第一種是WHERE從句中可能包含多個條件三元組,多個條件三元組之間的順序并不影響最終的執(zhí)行結(jié)果,但會極大地影響以之前的標(biāo)記預(yù)測下一個標(biāo)記的方式進(jìn)行預(yù)測的Seq2seq模型的性能,Seq2SQL使用強(qiáng)化學(xué)習(xí)來消除順序問題,但準(zhǔn)確率依然不高;第二種缺陷是Seq2seq模型沒有充分利用SQL句法結(jié)構(gòu)來限制輸出空間,模型復(fù)雜且準(zhǔn)確率不高。
第二類方法是基于草圖的方法。文獻(xiàn)[1]基于此想法提出了SQLNet模型,根據(jù)SQL語句的句法結(jié)構(gòu)將SQL查詢分解為6個子任務(wù)。預(yù)定義草圖包含各個子任務(wù)的依賴關(guān)系,每個子任務(wù)的預(yù)測只基于其所依賴的部分。與Seq2SQL不同,SQLNet采用了順序到集合的方法和基于列字段的注意力機(jī)制,消除了順序問題,提高了準(zhǔn)確率。在此基礎(chǔ)上,文獻(xiàn)[2]提出執(zhí)行指導(dǎo)編碼(Execution-Guided Decoding),可以理解為一種后驗操作,假設(shè)生成的SQL查詢可以執(zhí)行,通過執(zhí)行結(jié)果來排除錯誤的候選SQL查詢。隨著動態(tài)表示學(xué)習(xí)的發(fā)展,更多的方法選擇預(yù)訓(xùn)練語言模型作為編碼器。文獻(xiàn)[3]提出的SQLova使用表感知的BERT作為編碼器,在編碼后提出了3種不同的解碼器變體,其中一種變體類似SQLNet,3種解碼器之間的精度差也論證了預(yù)訓(xùn)練語言模型的有效性;文獻(xiàn)[4]提出X-SQL,使用MT-DNN作為編碼器,將全局上下文信息融合到表模式中,為下游任務(wù)提供更好的表達(dá),顯著地提高了性能。不同于連接問句和表中所有列名作為輸入的SQLova和X-SQL,文獻(xiàn)[5]提出的HydraNet將問句和表中的各個列名單獨拼接送入編碼器,不需要額外的池化操作或長短期記憶網(wǎng)絡(luò)來獲得一個列的向量表示,可以更好地獲得列的表示。
2 方法
2.1 任務(wù)定義
基于知識增強(qiáng)的NL2SQL任務(wù)定義:給定一個數(shù)據(jù)庫,還有一個外部知識圖譜,包括實體的各類知識,如:摘要、類型、標(biāo)簽和語義關(guān)系等,如圖2所示。其中,摘要是對實體的描述,類型說明了實體的所屬類型,標(biāo)簽簡要介紹了實體的特征,而語義關(guān)系包含了實體的屬性及屬性值。在不使用表中字段值的前提下,輸入一個自然語言問句,輸出對應(yīng)的SQL語句。
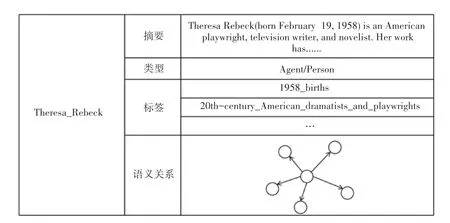
圖2 實體的相關(guān)知識Fig.2 Related knowledge of entity

2.2 系統(tǒng)框架
本文工作的核心思想是利用知識來增強(qiáng)問句的語義信息,實現(xiàn)問句到SQL語句的轉(zhuǎn)化。本文提出基于知識增強(qiáng)的NL2SQL模型KESQL,模型結(jié)構(gòu)如圖3所示。
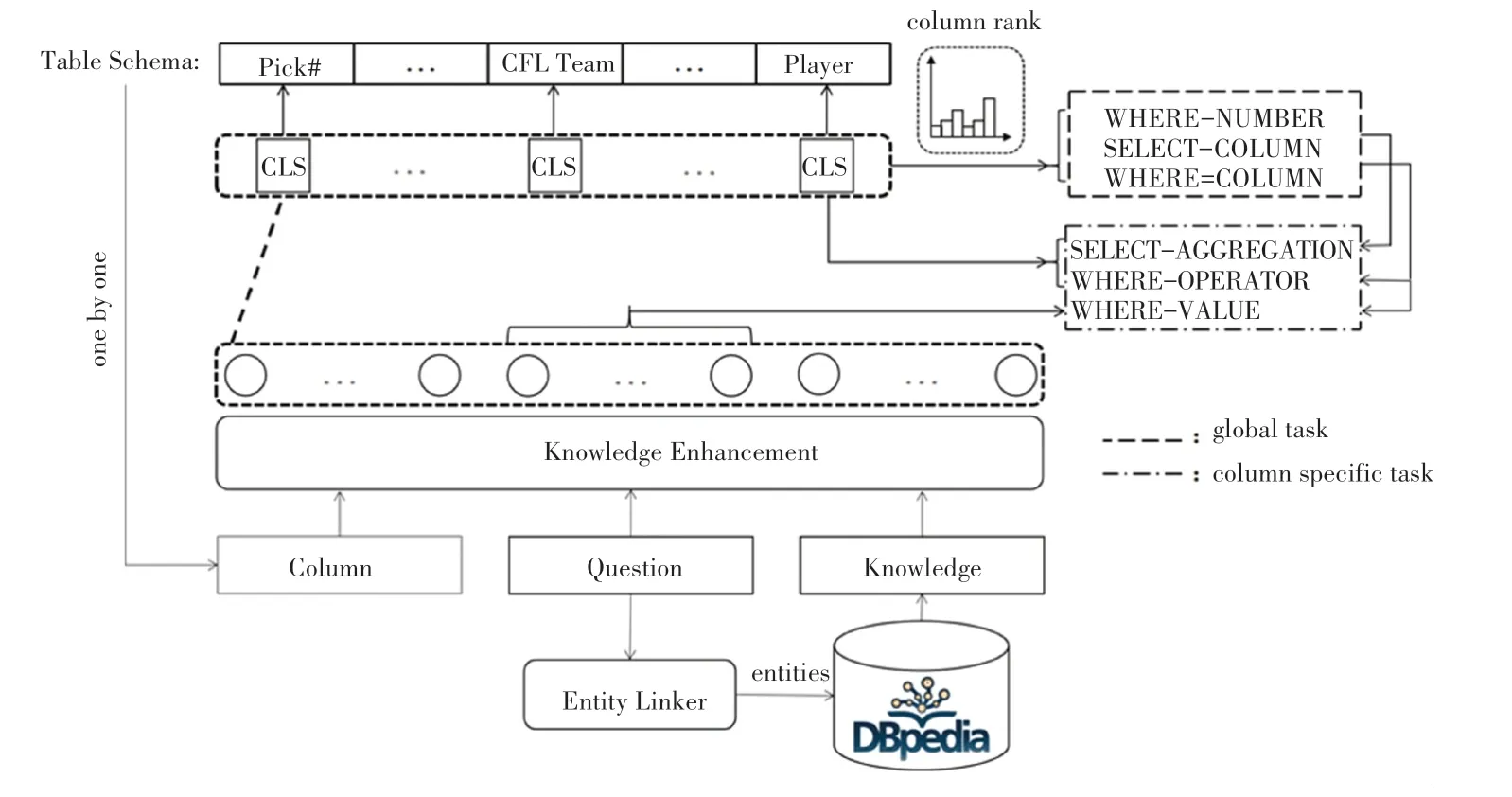
圖3 KESQL模型結(jié)構(gòu)圖Fig.3 Structure diagram of KESQL model
本文的系統(tǒng)框架主要包含3個部分:首先對問句進(jìn)行實體鏈接,找到問句中出現(xiàn)的命名實體,將其鏈接到知識圖譜中,以獲得這些命名實體的更多語義信息;其次,在知識增強(qiáng)模塊從符號化和向量化兩個角度實現(xiàn)增強(qiáng),將問句與知識融合對齊,使模型更充分的理解問句;最后,利用知識增強(qiáng)后的編碼層輸出來解碼草圖結(jié)構(gòu)中的各個子任務(wù)。
目前已經(jīng)有很多成熟的實體鏈接工具,本文選擇了主流的實體鏈接工具DBpedia Spotlight,將自然語言文本中的命名實體鏈接到知識圖譜DBpedia中。
3 模型
3.1 輸入模塊
給定一個問句,問句對應(yīng)的實體的某類知識以及相應(yīng)的表t,對表中的每個候選列c,考慮其字段類型信息t y pe,組成輸入序列((t y p e,c),,)。 其中,(·)表示一個將多個句子連接成一個字符串的函數(shù)。
3.2 知識增強(qiáng)模塊
本文從符號化和向量化兩個角度進(jìn)行知識增強(qiáng),包含一種符號化增強(qiáng)方法和兩種向量化增強(qiáng)方法。
3.2.1 符號化知識的增強(qiáng)方法
符號化知識的增強(qiáng)是指將實體知識表示為一個字符串,直接與自然語言問句拼接,再進(jìn)行后續(xù)的編碼等操作。本文將結(jié)構(gòu)化和非結(jié)構(gòu)化的實體知識統(tǒng)一轉(zhuǎn)化為自然語言作為實體的符號化知識描述,見表1。

表1 實體符號化知識描述的生成Tab.1 The generation of entity symbolic knowledge description
直接拼接問句和實體符號化知識描述,作為編碼器的輸入,輸入序列為[][],[], 其 中,,是列信息(t ype,c)、問句、實體符號化知識分詞后的形式,本文將此方法稱為符號化知識增強(qiáng)(Knowledge Enhancement with Symbolic Knowledge),如圖4所示。
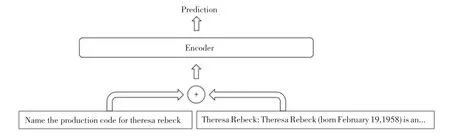
圖4 符號化知識增強(qiáng)Fig.4 Knowledge enhancement with symbolic knowledge
3.2.2 向量化知識的增強(qiáng)方法
向量化知識的增強(qiáng)方法是指將實體知識轉(zhuǎn)化為向量化表示,再與問句中所對應(yīng)的實體指稱項(mention)的向量化表示進(jìn)行融合。具體來說,對于問句中出現(xiàn)的每個實體e,假設(shè)其對應(yīng)的問句中的實體指稱項為[p:q],p、q分別表示實體指稱項的起始索引和結(jié)束索引。首先,通過不同的方法來獲得實體e的向量化表示h,然后將其輸入到一個線性層中,再與向量化后的實體指稱項對齊;其次,通過線性組合實體指稱項和實體的向量化表示來獲得知識增強(qiáng)的實體指稱項的向量化表示,計算方式如公式(1)所示。
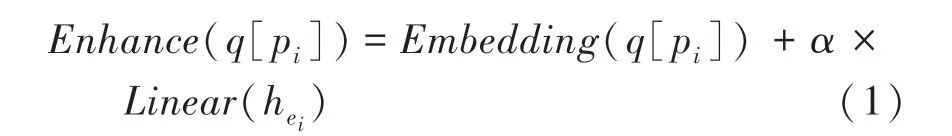
其中,為增強(qiáng)后的實體指稱項的向量化表示,()為語言模型的嵌入層,在訓(xùn)練過程中從0退火到,∈[0,1]。
本文提出了兩種不同的實體向量化方法。第一種方法,即圖向量化知識增強(qiáng)(Knowledge Enhancement with Graph Embedding),在給定圖結(jié)構(gòu)知識的情況下,包含實體與實體之間的語義關(guān)系,來自于全部實體的語義關(guān)系,對圖結(jié)構(gòu)的實體知識進(jìn)行編碼,獲得實體的向量化知識表示。使用知識圖譜向量化(Knowledge Graph Embedding,KGE)的方法來獲得每個實體的向量化表示。本文使用提出的TransE模型來進(jìn)行知識圖譜向量化,稱為圖向量化知識增強(qiáng)(Knowledge Enhancement with Graph Embedding),如圖5所示。
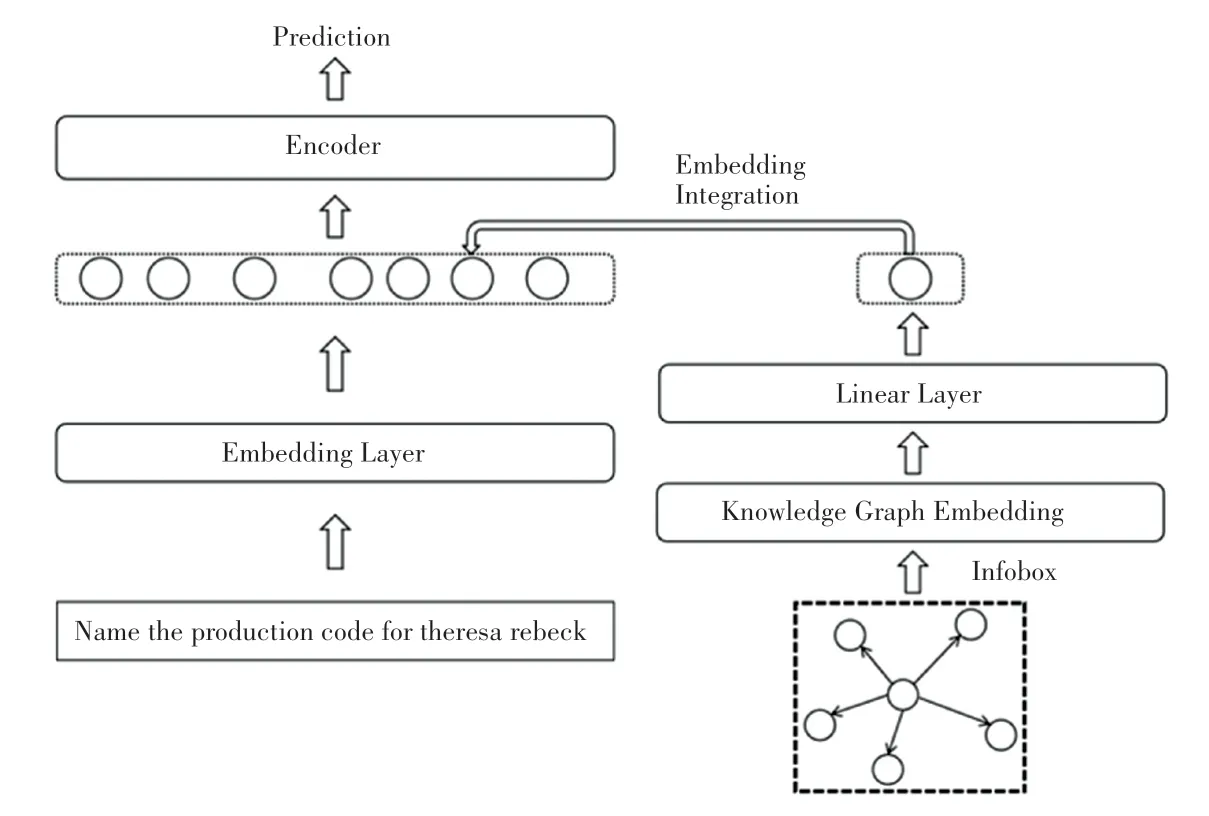
圖5 圖向量化知識增強(qiáng)Fig.5 Knowledge enhancement with graph embedding
第二種方法指在缺乏圖結(jié)構(gòu)知識的情況下,通過語言模型對文本形式的實體知識進(jìn)行編碼,獲得實體的向量化知識表示。因為實體知識總是以被描述的實體開頭,如“Theresa Rebeck:Theresa Rebeck(born February 19,1958)is an American playwright,television writer,and novelist.”,所以采用實體知識描述的第一個標(biāo)記的詞向量作為實體知識的向量化表示,此方法稱為文本向量化知識增強(qiáng)(Knowledge Enhancement with Textual Embedding),如圖6所示。
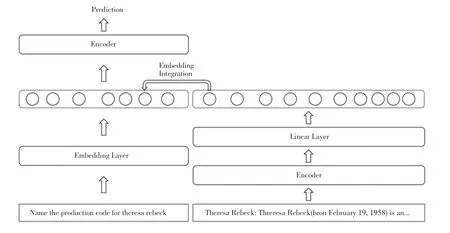
圖6 文本向量化知識增強(qiáng)Fig.6 Knowledge enhancement with textual embedding
在問句和知識融合后,再對增強(qiáng)后的問句進(jìn)行編碼,為下游子任務(wù)提供更好的表示。
3.3 解碼模塊
此模型采用HydraNet模型的解碼方式,采用草圖框架,將SQL查詢劃分為6個子任務(wù),根據(jù)各個子任務(wù)是否依賴具體的列,將其劃分為全局任務(wù)和局部任務(wù)兩類。
全局任務(wù)主要包含3個子任務(wù)SELECTCOLUMN、WHERE-NUMBER、WHERE-COLUMN。SELECT-COLUMN子任務(wù)的目標(biāo)是預(yù)測SELECT從句中出現(xiàn)的列,本研究SELECT從句中出現(xiàn)的列固定為1個。所以,對所有候選列計算其出現(xiàn)在SELECT從句的分?jǐn)?shù),選擇分?jǐn)?shù)最高的列,式(2):
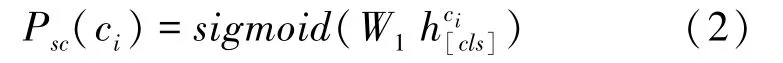

WHERE-NUMBER子任務(wù)的目標(biāo)是預(yù)測WHERE從句中條件列的數(shù)量。本文任務(wù)中WHERE從句中條件列可以為空,至多出現(xiàn)4個條件列,將問題轉(zhuǎn)化為五分類任務(wù)。問句對應(yīng)的SQL中的WHERE從句包含多少條件列,主要取決于問句,但是本模型中的問句和表中每個列單獨交互,得到的多個全局表示都可以預(yù)測出WHERENUMBER,需要根據(jù)每個列的相關(guān)度來對預(yù)測結(jié)果加權(quán),式(3)~式(5):
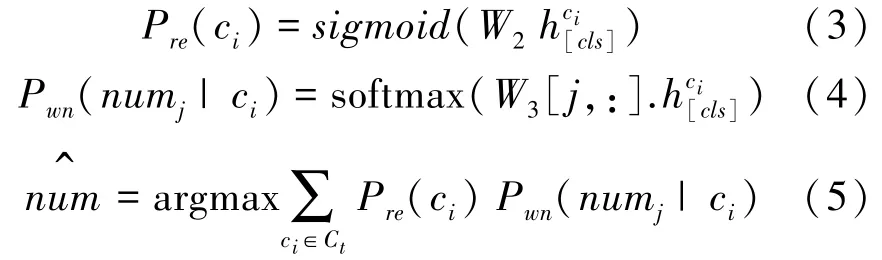
其中,P(c)為第列出現(xiàn)在SQL中的分?jǐn)?shù),P(num|c)為第列與問句交互后得到的全局表示預(yù)測WHERE從句中列數(shù)量為的概率,將P(c)和P(num|c)加權(quán)求和,取概率最高的數(shù)為WHERE-NUMBER。
WHERE-COLUMN子任務(wù)的目標(biāo)是預(yù)測WHERE從句中出現(xiàn)的列,對所有候選列計算其出現(xiàn)在WHERE從句的分?jǐn)?shù),選擇分?jǐn)?shù)最高的前WHERE-NUMBER個列,式(6)。

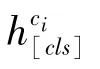
局部任務(wù)依賴從句中的列的預(yù)測結(jié)果,包括SELECT-AGGREGATION、WHERE-OPERATOR、WHERE-VALUE。SELECT-AGGREGATION子任務(wù)的目標(biāo)是預(yù)測SELECT從句中的列對應(yīng)的聚合操作,從A=[′′,′MAX′,′MIN′,′COUNT′,′SUM′,′AVG′]中選擇概率最大的聚合操作,式(7)。
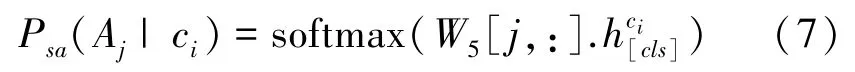
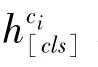
WHERE-OPERATOR子任務(wù)的目標(biāo)是預(yù)測WHERE從句中的條件列對應(yīng)的操作符,從[′=′,′>′,′<′]中選擇概率最大的操作符,式(8)。
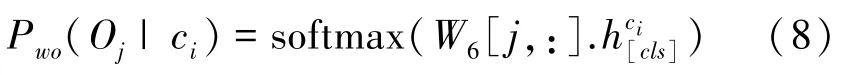
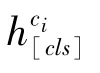
WHERE-VALUE子任務(wù)的目標(biāo)是預(yù)測WHERE從句中條件列對應(yīng)的條件值,可以被理解為從問句中抽取一段文本,預(yù)測條件值在自然語言問句中的起始位置,式(9)和式(10):

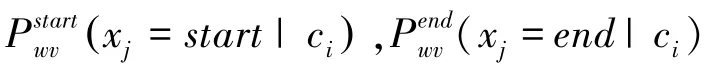
4 實驗
4.1 實驗準(zhǔn)備
實驗使用的WikiSQL數(shù)據(jù)集是大型NL2SQL數(shù)據(jù)集之一,基于維基百科文章構(gòu)造自然語言問句和對應(yīng)的SQL查詢。訓(xùn)練集、驗證集、測試集基于不同的表,分別包含56 355,8 421,15 878個問句-SQL查詢對。本文選用RoBERTa-base作為基礎(chǔ)編碼器,AdamW為優(yōu)化器。
執(zhí)行指導(dǎo)編碼(Execution-Guided Decoding),簡稱EG,利用SQL查詢的執(zhí)行結(jié)果來指導(dǎo)編碼過程。如果預(yù)測的SQL執(zhí)行結(jié)果出錯或返回空結(jié)果,EG將認(rèn)為此條SQL預(yù)測錯誤,會將其排除選擇概率次高的SQL。在模型預(yù)測結(jié)束后,運(yùn)用EG,進(jìn)一步提升模型的效果。
4.2 評估指標(biāo)
使用目前主流的兩種評估指標(biāo),即邏輯形式準(zhǔn)確率()和執(zhí)行結(jié)果準(zhǔn)確率(),來評估模型的效果。邏輯形式準(zhǔn)確率是指預(yù)測生成的SQL與真實標(biāo)注的SQL匹配的比例(這里匹配指SQL語句完全一致);執(zhí)行結(jié)果準(zhǔn)確率是指執(zhí)行預(yù)測生成的SQL的結(jié)果與執(zhí)行真實標(biāo)注的SQL的結(jié)果匹配的比例。
4.3 基線
本文以當(dāng)前最優(yōu)模型HydraNet作為基礎(chǔ)模型,將問句與相應(yīng)表中的所有列名分別交互,得到編碼層輸出,再根據(jù)草圖框架,利用列排序等方法對各個子任務(wù)進(jìn)行解碼預(yù)測。
本文以RoBERTa-base作為基礎(chǔ)編碼器復(fù)現(xiàn)了HydraNet模型,將其作為實驗的基線。統(tǒng)一運(yùn)用EG,對得到的實驗結(jié)果做進(jìn)一步的比較。
4.4 結(jié)果
本文模型的邏輯形式準(zhǔn)確率和執(zhí)行結(jié)果準(zhǔn)確率均優(yōu)于基線,在摘要、類型、標(biāo)簽、語義關(guān)系上分別運(yùn)用符號化知識增強(qiáng)(SK)、文本向量化知識增強(qiáng)(TE)、圖向量化知識增強(qiáng)(GE)得到邏輯形式準(zhǔn)確率和執(zhí)行結(jié)果準(zhǔn)確率見表2、表3。

表2 測試集上邏輯形式準(zhǔn)確率Tab.2 Logical form accuracy(%)on WikiSQL test set of various methods

表3 測試集上執(zhí)行結(jié)果準(zhǔn)確率Tab.3 Execution accuracy(%)on WikiSQL test set of various methods
通過表2和表3,可以觀察到:
(1)類型和語義關(guān)系可以更充分地補(bǔ)全NL2SQL任務(wù)中缺失的語義,對效果的提升最明顯。因為類型信息僅是幾個具體類型的拼接,語義關(guān)系包含的是關(guān)鍵的鍵值對,相對來說帶來的干擾更小;而摘要的第一句話雖然非常重要,但太過精練反而可能會漏掉一些信息;
(2)向量化知識增強(qiáng)的方法都比符號化知識增強(qiáng)的方法好,因為符號化知識增強(qiáng)的方法過于簡單直接,融入外部知識反而帶來一定的噪聲干擾。
5 結(jié)束語
本文針對自然語言問句存在語義缺失的問題,使用了外部知識圖譜來對自然語言問句進(jìn)行語義增強(qiáng),使其包括充分的語義信息。本文提出對問句中出現(xiàn)的命名實體進(jìn)行增強(qiáng),使用現(xiàn)有的實體鏈接技術(shù)來將問句中的命名實體鏈接到外部知識圖譜中,并提出了一種基于符號化知識的增強(qiáng)方法和兩種向量化知識的增強(qiáng)方法。同時,系統(tǒng)調(diào)研了摘要(Abstract)、類型(Type)、標(biāo)簽(Category)、語義關(guān)系(Infobox)等4種類型知識的增強(qiáng)效果,最終發(fā)現(xiàn)使用類型和語義關(guān)系兩種類型的知識來進(jìn)行文本向量化知識增強(qiáng)的效果最好。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
