推薦系統中稀疏情景預測的特征-類別交互因子分解機
2022-07-12 02:44:54黃若然韓傳奇
計算機研究與發展 2022年7期
黃若然 崔 莉 韓傳奇
1(中國科學院計算技術研究所泛在計算系統研究中心 北京 100190) 2(中國科學院大學計算機科學與技術學院 北京 101408)
推薦系統在網絡搜索、在線廣告和商業導購的發展中扮演了關鍵的角色,它解決了網絡大數據給人們帶來的“信息過載”問題,也為顧客提供了個性化信息服務和決策支持.一個成功的推薦系統能為客戶提供高效的推薦服務,提高企業的生產利潤,并產生相應的經濟效益和社會效益.目前,推薦系統已成功應用在電子商務(如Amazon、阿里巴巴等)、社交網絡(如Twitter、微博等)、電影推薦(如Netflix、豆瓣等)、音樂推薦(如LastFM、網易云音樂等)、新聞推薦(如今日頭條、GoogleNews等)[1].
現有的個性化推薦系統面臨的一個主要問題是數據的稀疏性.數據稀疏指的是用戶往往只對比例很小的服務存在反饋,導致用戶-物品的反饋矩陣非常稀疏,其稀疏度通常可達到99%以上[2],即用戶平均只與不到1%的服務有過歷史交互.這使推薦系統難以有效地學習用戶的偏好,無法生成準確的推薦列表.早期在稀疏數據上計算用戶偏好的個性化推薦算法主要為邏輯斯諦回歸(logistic regression, LR)[3]和支持向量機(support vector machines, SVM)[4],但這類算法太過依賴人工特征工程,需要耗費大量的精力,導致計算效率低下.
為了更高效地解決因數據稀疏帶來的人工特征繁瑣和推薦精度不準確的問題,Rendle[5]提出了一種基于矩陣分解的機器學習算法:因子分解機(factorization machine, FM).FM通過構建特征的交叉組合,來學習用戶-物品間潛在的交互關系.FM可以在非常稀疏的數據環境中進行豐富的特征交互計算,且可以應用于任何特征值為實值的情況.相比于其他因式分解模型只能用于一些輸入數據比較固定的情況,FM更加通用和靈活.此后,為了進一步挖掘特征交互思想背后的價值,Juan等人[6]在FM的基礎上引入了“類別”(或“場”)的概念,即“field”,并提出了類別因子分解機(field-aware factorization machine, FFM).FFM的主要思想是把相同性質的特征歸于同一個類別,并單獨進行熱獨(one-hot)編碼,因此在FFM中每一個特征都會針對其他特征的每個類別學習一個隱變量,該隱變量不僅與特征相關,也與類別相關.
隨著深度學習的迅速發展,He等人[7]在2017年提出了神經因子分解機(neural factorization machine, NFM),NFM可以看作是FM的神經網絡推廣,它推遲了FM的實現過程,并在其中加入了更多非線性運算.相比于NFM,注意力因子分解機(attentional factorization machine, AFM)[8]則更多地關注特征交互間的權重計算,它為每一對交互特征分配一個所屬的注意力因子,用以更好地區分不同特征間的重要程度來達到更好的預測效果.隨后,Hong等人[9]受到FFM類別交互的啟發,在AFM的基礎上引入了類別交互的概念,提出了一種將特征和類別分別進行交互的模型——感知交互因子分解機(interaction-aware factorization machines, IFM),并在多個領域取得了最優的效果.
本文在IFM的基礎上,提出特征-類別交互機制(feature-over-field interaction mechanism, FIM)的概念,通過對特征向量和類別向量進行融合,并將融合后的向量兩兩配對交互,以獲取更為豐富的交互語義信息.并以此為支持點,提出了新的因子分解機模型——特征-類別交互因子分解機(feature-over-field interaction factorization machine, FIFM).FIFM從特征交互角度、類別交互角度和特征-類別交互角度出發,更加全面地獲取稀疏場景下的各類交互信息,進一步提高了預測效果.此外,為提高FIFM的泛化性使其適應多種復雜的數據場景,我們還提出了一種基于FIFM的神經網絡版本——廣義特征-類別交互模型(generalized feature-field interaction model, GFIM).相比于FIFM,GFIM的參數和時間復雜度更高,但同時也能捕獲更多高階的非線性特征交互信息,適合算力較高的應用場景.
本文的主要貢獻有4方面:
1) 提出了一種將特征-類別融合后進行交互的機制FIM,使其可以學習特征-類別之間更為深層次的潛在語義信號;
2) 提出了一種面向稀疏情景的特征-類別交互因子分解機FIFM,它從特征交互、類別交互及特征-類別交互的視角出發,能夠更加準確地預測稀疏條件下的用戶意圖;
3) 基于深度學習理論提出了一種FIFM的神經網絡版本GFIM,相比于FIFM,GFIM的參數量和時間復雜度更高,但同時也能捕獲更多高階的非線性特征交互信息,適合高算力應用場景;
4) 在4個真實數據集上的實驗結果表明相比于現有的主流模型,我們提出的模型能夠在參數量近似的情況下,在均方根誤差(RMSE)指標上取得更好的效果.
1 相關工作
1.1 基于機器學習的特征交互預測方法
FM是一種基于矩陣分解的機器學習算法,最大的特點是對于稀疏的數據具有很強的特征交互學習能力.FM通過對交互后特征的低秩展開,為每個特征構建隱式向量,并利用隱式向量的點乘結果來建模2個特征的組合關系,實現了對2階特征組合的自動學習.值得注意的是,FFM的任意2組交叉特征的隱向量都是獨立的,每一個特征都對應一個獨一無二的類別,并為其分配一個隱向量,因此相比于FM的特征數乘以隱向量維度的參數量,它還多乘以一個類別數量,進而引入了更多的計算參數,為實際的運算帶來不小的計算花銷.而Chen等人[10]則從特征選擇的角度,提出了一種基于FM的貝葉斯個性化特征交互選擇算法,來篩選淘汰出那些在特征交互中效率較低的交互配對.通過在FM中集成貝葉斯個性化選擇機制來進一步提高特征交互的效率.除此之外,另一種較為新穎的特征交互學習方法是將特征向量嵌入過程映射到可違反洛倫茲三角不等式的雙曲空間當中[11],由雙曲三角形的特殊幾何特性學習交互信息.
1.2 基于深度學習的特征交互預測方法
隨著近幾年深度學習在各個領域的成功應用[12-14],基于深度學習的特征交互預測方法也相繼被提出.為了能夠直接利用神經網絡層,Wang等人[15]提出了一種簡單的結合方法——因子分解機支持神經網絡(factorization machine supported neural network, FNN),它直接將FM與多層感知機(mul-tilayer perceptron, MLP)進行串聯組合,并采用FM預訓練得到的隱含層及其權重作為神經網絡第1層的初始值,之后再不斷堆疊全連接層,最終輸出預測結果.由于FNN嵌入權重的初始化是FM預訓練好的,因此它不是一個端到端的訓練過程.考慮到FM特征交互方法只進行嵌入向量的兩兩內積求和,因此該改進方法沒有充分利用2階特征組合的信息.He等人[7]提出了基于深度學習的神經因子分解機NFM,它的主要思想是利用2階交互池化層(bi-interaction pooling, BIP)對FM嵌入后的向量兩兩進行元素級別的乘法,形成同維度的向量求和后作為前饋神經網絡的輸入.Guo等人[16]于2017年提出了DeepFM(deep factorization machine)模型,將深度學習的神經網絡部分與FM相結合,用FM做特征間的低階組合,用深度神經網絡層(deep neural network, DNN)做特征間的高階組合,通過并行的方式組合2種方法并獲得了更精確的效果.Xiao等人[8]提出了一種注意力因子分解機AFM,該文作者認為現有的FM交互特征權重未做區分,不是所有特征交互都有同樣的價值,相反低貢獻度的交互特征可能會引入噪聲.該文作者通過對FM不同的特征交互引入不同重要性因子來改善FM的學習方式.
1.3 基于特征交互和類別交互的預測方法
1.1節和1.2節提到的方法中,大多是針對于特征交互的預測方法,如FM,NFM,AFM,也有針對類別交互的預測方法,如FFM.基于此,Hong等人[9]提出將特征交互和類別交互進行融合的IFM,并利用交互后的感知向量共同作用于預測結果.IFM由于其優異的表現效果,現已成為稀疏特征預測方法中的重要對比方法.
本文在IFM分別將特征交互和類別交互獨立交互的基礎上,提出了一種特征-類別融合交互的新機制FIM,用以進一步增強交互信息在稀疏條件下的預測結果.FIM不僅可以對IFM進行信息增益,還可以與其他FM模型進行銜接,在時間和空間的消耗均與主流模型接近的情況下提高其他FM模型在各自適用領域內的精度.
2 因子分解機(FM)和類別因子分解機(FFM)
2.1 基于特征交互的FM相關描述及定義
傳統的SVM難以解決特征稀疏問題,FM主要是為了解決數據稀疏的情況下特征怎樣組合的問題.FM的主要思想是利用多維特征之間的交叉關系,利用矩陣分解的方法進行參數的訓練.基本的符號表示為:
假定每一條訓練數據擁有特征屬性x={x1,x2,…,xm},其中xi表示第i個真實的特征值,m表示特征的數量,它的真實值y可代表用戶是否進行了點擊(或選擇).非零特征交互對表示為
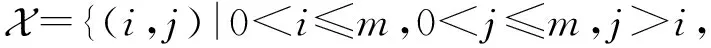
(1)
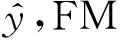
(2)
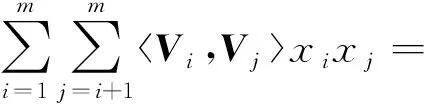
(3)
2.2 基于類別交互的類別因子分解機(FFM)
為了將交互操作擴展到其他維度,FFM在FM的基礎上對同一個類別特征單獨進行one-hot編碼,使得特征在交互時能夠捕獲更多關于類別的學習向量,通過增加可學習的參數空間來提升效果.
假設樣本的m個特征屬于f個類別,那么FFM的二次項有mf個隱向量.而FM模型中,每一維特征的隱向量只有一個.FFM的模型方程為
(4)
如果隱向量的特征維度為d,那么FFM的二次參數則有mfd個,遠多于FM模型的md個.由于FFM參數較多,在實際的運行中需要極大的算力作為支撐,因此為其在工業界的應用和推廣帶來了不小的挑戰.
3 特征-類別交互因子分解機
3.1 神經因子分解機(NFM)
傳統FM只學習到了2階交叉特征和線性回歸特征等此類低階信息,未對深層次信號做進一步的挖掘.NFM通過對FM做神經網絡擴展并添加了更多的非線性運算來進一步提升深層信號的獲取能力.NFM的網絡結構如圖1所示:
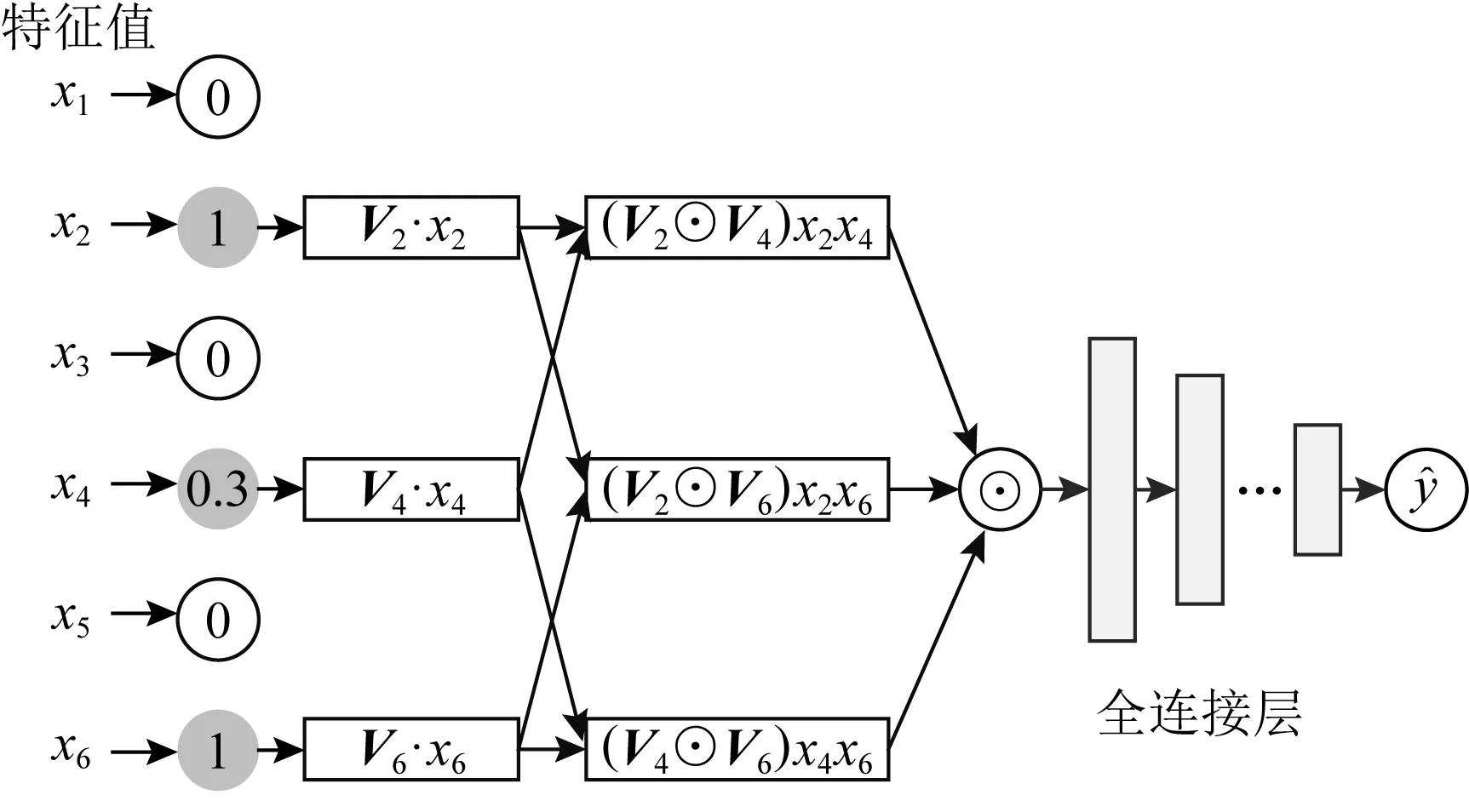
Fig. 1 The network architecture of NFM圖1 NFM的網絡架構
相比于FM,NFM采用2階池化層結構來對2階交叉信息進行處理,使交叉特征的信息能更好地被DNN結構學習,降低DNN學習更高階交叉特征信息的難度.我們將NFM的2階交互部分歸納為
(5)
式(5)為NFM的核心思想(為方便表示,我們省略其線性部分).即對FM嵌入后的向量兩兩進行元素級別的乘法,形成同維度的向量求和后作為前饋神經網絡的輸入,⊙表示逐元素乘法運算.在計算完式(5)后得到一個維度為d的向量,圖1中還使用了多層感知機以捕獲更為高階的交互信號.
3.2 注意力因子分解機(AFM)
相比于NFM,AFM[8]則更加著重于特征交互間的權重計算.它的主要思想是通過在逐元素乘法之后形成的向量進行加權求和,權重是基于網絡自身產生的.此方法是引入一個注意力子網絡(attention net).AFM的網絡結構如圖2所示:
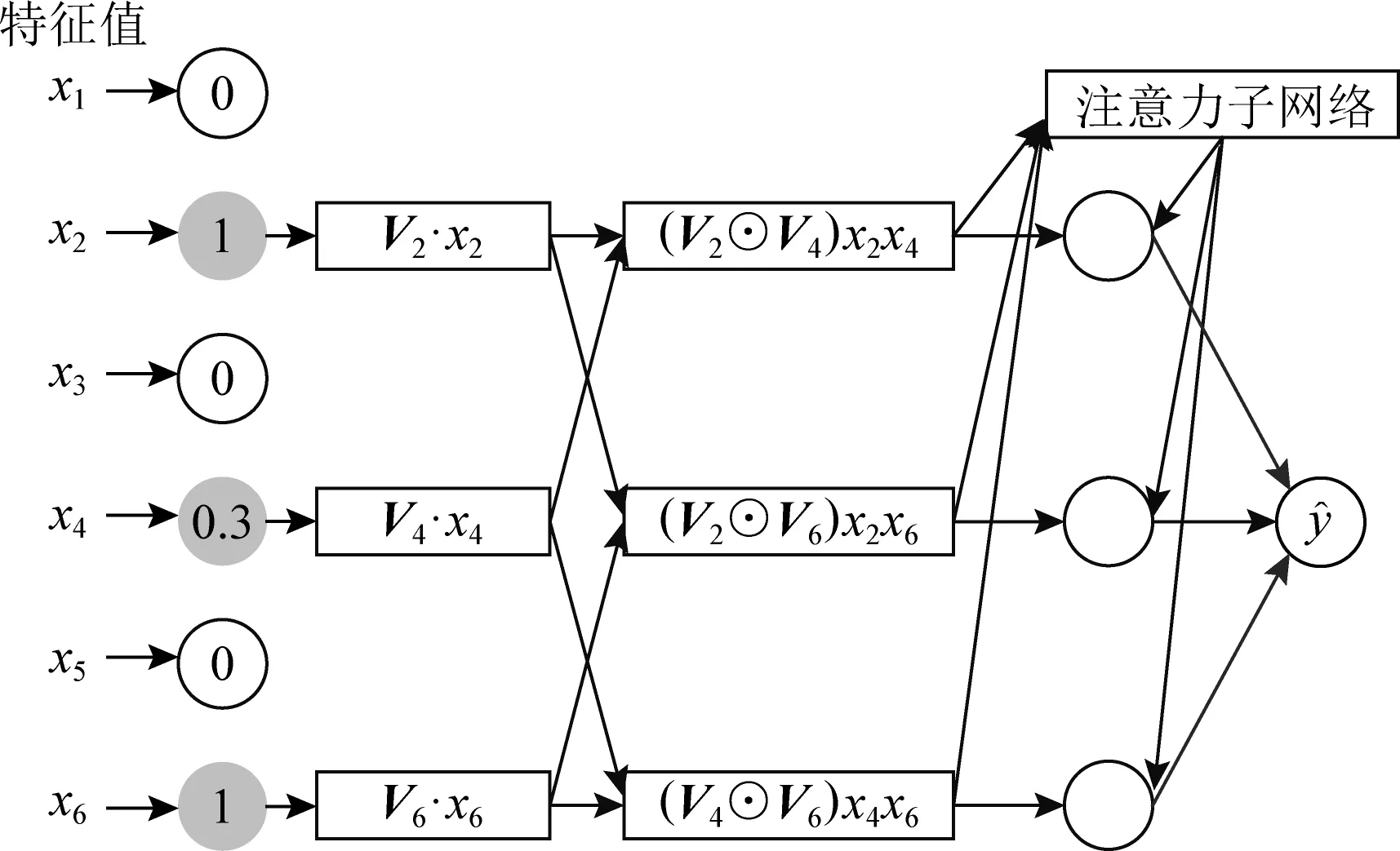
Fig. 2 The network architecture of AFM圖2 AFM的網絡架構
由圖2可以看到,右上角的注意力子網絡是相比于NFM多出的部分,并且AFM沒有MLP部分,當權重都相等時,AFM退化成無全連接層的NFM.AFM的預測值為
(6)
其中αij負責為每一對交叉項分配權重,是特征xi和特征xj進行配對交互時對應的注意力因子,用以衡量二者之間的特征重要程度.其計算過程為
hij=MTReLU(W1(Vi⊙Vj)xixj+b1),
(7)
(8)
其中,W1∈Ka×d,M∈Ka×1,b1∈Ka分別表示權重轉換矩陣、轉換向量和偏置項,Ka表示注意力網絡中隱藏層的單元維度,η控制收縮性.
3.3 感知交互因子分解機(IFM)
受到FFM類別概念的啟發,IFM在AFM的基礎上提出了使用類別感知交互(field-aware inter-action, FAI)來進一步影響交互特征,使其能從類別領域出發發揮預測作用.IFM的網絡結構如圖3所示.
圖3所示的IFM對比圖2所示的AFM,增加了虛線框中的FAI.這里的類別與FFM中“類別”的實現有所不同,FFM是為每一個特征分配與其他特征所在類別相對應的隱變量;而IFM中的類別則認為是當前一個特征下對應一個類別,交互只在特征對應的類別上實現.因此相比FFM,IFM所需要的參數量更少,其結合AFM中的特征交互部分得到:
(9)
其中,fi為特征xi的類別,Ffi,fj表示維度為KF的特征xi和特征xj所屬類別的類別交互向量,用以計算類別級別的關系.
3.4 特征-類別交互機制(FIM)
從3.1~3.3節中FM系列的演化歷史我們可以知道:NFM比原始FM多了2階池化層,AFM在NFM的基礎上為每一對特征交互增加了注意力網絡,IFM則在AFM的架構上添加了類別感知交互.FM,NFM,AFM都是針對特征交互的預測,而IFM則是在特征和類別分別交互的基礎上進行預測.
本文中所提出的FIM則是基于IFM增加了特征-類別融合,并對融合后的向量進行兩兩配對交互.該交互過程后有2種呈現模式:1)矩陣乘法,即FIM最終輸出為每一對交互結果的標量值eij;2)讓每一對特征-類別融合后的交互以元素逐點相乘的形式出現,即向量Eij,用于輸入更為復雜的時間網絡結構.針對這2種FIM對每對交互的輸出形式——元素級eij和向量級Eij,我們提出2種相對應的模型,即FIFM和GFIM.圖4展示了FIFM的網絡架構.
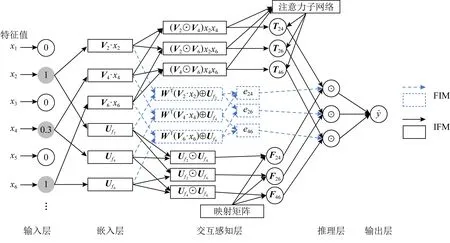
Fig. 4 The network architecture of FIFM圖4 FIFM的網絡架構
不同于FFM靠增加隱式的參數來學習潛在的field信息,FIM顯式地學習特征和類別之間的關聯,降低了學習的成本.為了方便理解,我們將式(9)重新定義為
(10)
其中,第1個“1”表示融合特征和類別交互后的權重系數,第2個黑斜體“1”表示類別交互向量,第3個“1”表示特征交互的注意力系數.至此,我們在IFM的基礎上提出特征類別機制,它綜合了特征、類別及特征-類別3種不同的交互視角,我們可將此過程擴展為
(11)
相比式(9),我們增加了元素特征值eij,用于學習特征-類別后更深層次的隱藏信息,并衡量IFM中特征部分和類別部分組合時的重要性.
Ffi,fj=HT(Ufi⊙Ufj),
(12)
其中,H∈d×KF,U∈n×KF,而KF是H和U隱藏因子的神經元數量.通過式(12)的分解,類別交互的復雜度可以由線性關系表示:d×KF+KF×n.
從式(12)中可以看到,類別交互學習同原始的因子分解機中的2階特征交互(Vi⊙Vj)xixj具有相似的結構.由于最終的維度相同,這2種結構是可以相互影響和計算的.這2種結構映射為雙線性關系:
simH(C,G)=CTHG,
(13)
其中,C=Ufi⊙Ufj,G=(Vi⊙Vj)xixj.
在獲取到特征交互和類別交互之后,本工作對潛在影響因子進行了進一步的挖掘,即融合特征-類別向量,并為其賦予一定的學習參數,使其能夠在擁有特征-類別混合信息的同時還能進行2階交互,提高預測精度.此操作會帶來4個效果:
1) 學習特征-類別之間更為深層次的潛在語義信號,這些語義信號能夠為IFM中特征交互和類別交互在預測階段帶來信息增益,提高預測精度.
2) 融合后的特征-類別向量也可以看作是一個匯集了特征-類別信息的新向量,在2階交互后自身也具有一定的信息預測能力,屬于特征-類別概念中新的衍生模型.
3) 由于FIM的輸出是按特征或類別交互進行逐一配對的(關于i,j索引),因此FIM可以和其他FM模型無縫銜接以增強預測能力.
4) 特征-類別的融合是基于已有的特征向量和類別向量,除了融合時的學習參數外,不會增加額外的空間負擔.在時間復雜度上也僅維持在2階向量交互的級別,與NFM的2階池化操作保持相同.
針對于上述4個效果,我們會在第4節實驗1~3的結果分析中逐一進行驗證.
實現特征和類別的融合,我們需要將二者的維度進行統一,由于KF?d,考慮到計算的時間和空間復雜度,對xi所對應的原始向量Vi做一個線性變換:WT(Vi·xi),其中W∈KF×d,之后將其與類別嵌入向量做逐點相加操作.特征和類別的融合向量可以表示為:
Ri=WT(Vi·xi)⊕Ufi,
(14)
⊕表示向量間的逐點相加.由于類別特征向量是按照特征-類別進行劃分的,即它本身就擁有n個類別,即對應n個非零值,因此我們也可以對其進行兩兩交互.鑒于式(14)已可以分別求得特征交互向量G和類別交互向量C.因此,只需要計算二者結合的向量Ri即可得到兩兩交互的權值影響因子:
eij=Ri·Rj,
(15)
對于式(15),除了為每一對交互向量獲取元素級別的融合交互特征eij外,還可通過元素逐點相乘,為每一對特征交互或類別交互獲取對應交互向量.
Eij=Ri⊙Rj,
(16)
交互向量相比于交互特征具有更為豐富的信息單元,可用于場景數據更為復雜的高階神經網絡預測.
3.5 特征-類別交互因子分解機(FIFM)
3.5.1 FIFM的網絡架構
FIFM通過引入3.4節中的FIM來模型化特征交互.圖4展示了FIFM的網絡架構.
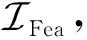
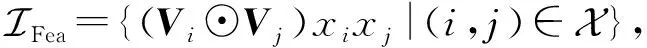
(17)
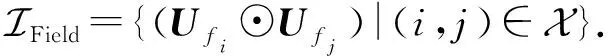
(18)

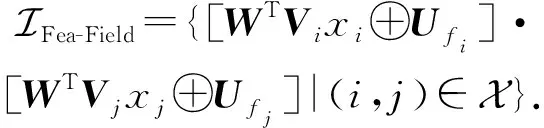
(19)
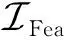

(20)
3.5.2 模型訓練
FIFM的目標主要為推薦系統中的一系列預測任務,可分為二分類、回歸和排序等.對于二分類任務,常用的損失函數為對數損失(log loss)[17];對于回歸任務,常用的損失函數為平方損失.同NFM,DeepFM,AFM,IFM類似,本文主要討論回歸任務并優化平方損失.相似的策略也可以用于分類和排序任務.針對目標函數,我們采用了梯度下降算法中的AdaGrad[18]優化器來迭代地計算每一輪參數的值.為了防止模型過擬合,在模型中為嵌入矩陣V和U添加了L2[19]正則,并且在神經元的計算過程中使用了Dropout[20]技術來進一步規范模型的訓練過程,并加快訓練速度.目標函數定義為:
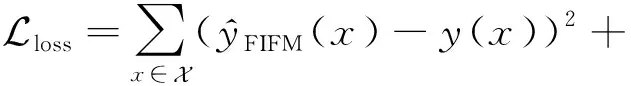
(21)
其中,λ和γ分別用于控制嵌入矩陣V和U的正則化學習率.FIFM模型的算法流程如算法1所示:
算法1.FIFM算法描述.
① 初始化參數矩陣V,M,H,U,W,W1;
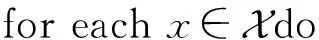
③ 根據式(6)~(8)計算特征交互向量αij·Vi⊙Vj;
④ 根據式(12)計算類別交互向量Ffi,fj;
⑤ 根據式(14)和式(15)計算特征-類別融合交互標量eij;
⑦ 根據式(21)計算損失函數;
⑨ end for
3.5.3 FIFM的時空復雜度
1) 空間復雜度分析(space complexity analysis)
對于嵌入矩陣V的參數量為O(m×d),而類別嵌入矩陣U,除原有的O(n×KF)參數量外,還有式(12)帶來的O(d×KF)參數量.式(7)和式(8)的注意力子網絡引入了參數量O(d×Ka+2×Ka).此外,式(14)引入了O(d×KF)的參數量.因此總的參數量為O(2Ka+(2KF+m+Ka)d+nKF),由于Ka和KF一般均小于d且n?m,因此在特征數m較大,即數據足夠稀疏的情況下,總的參數量可近似為原始的FM參數量O(md).值得注意的是,本文的主要對比模型IFM[9],在文獻[9]中分析指出了空間復雜度的消耗也近似為O(md).相比IFM,FIFM增加的參數消耗主要來源于式(14)中的W∈KF×d,因此FIFM比IFM增加的空間消耗維持在一個以d為變量的線性函數上.
2) 時間復雜度分析(time complexity analysis)
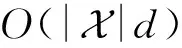
3.6 廣義特征-類別交互模型(GFIM)
針對提出的FIFM,可在此基礎上應用深度神經網絡(DNN)進行進一步拓展,以更好地學習高階特征交互.為此,我們對式(17)~(19)做一個神經網絡下的新定義,將各自獨立為神經網絡學習中的向量模塊.特征向量集合和類別向量集合分別定義為:
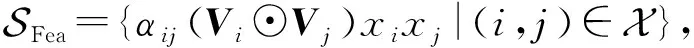
(22)
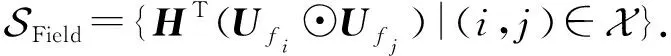
(23)
對于特征-類別融合的標量集合,我們將其擴充到向量級別,以更好地適應神經網絡的學習過程:
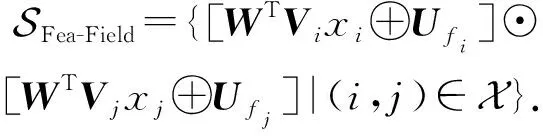
(24)
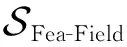
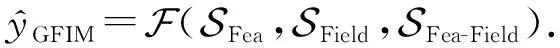
(25)
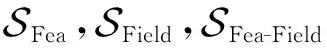

(26)
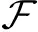
P0=SFea(c)⊕SField(c)⊕[SFea-Field(c)·Ws],
(27)
Pl=σ(QlPl-1+zl),
(28)
其中Ws∈KF×d,σ為神經網絡的非線性激活函數,本文選取ReLU[21]神經元的激活函數.
令rl代表第l層的神經元個數,則有Ql∈rl×r(l-1),zl∈rl分別表示第l層神經元的映射矩陣和偏置項.
Pl∈rl代表第l層的隱藏層輸出,由此,GFIM可表示為:
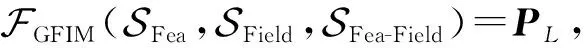
(29)
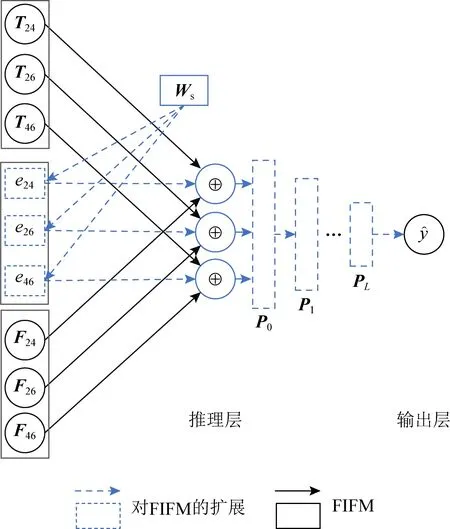
Fig. 5 The inference structure of GFIM圖5 GFIM推理部分的結構
GFIM模型算法流程如算法2所示:
算法2.GFIM算法描述.
① 初始化參數矩陣V,M,H,U,W,W1,Ws,Q;
⑥ 通過式(27)計算融合后的特征向量P0;
⑦ for eachlinLdo
⑧ 執行式(28)以獲取每輪神經網絡迭代后的向量Pl;
⑨ end for
3.7 與主流模型之間的特性比較
為了更好地展現本文所提出的FIFM和GFIM的特點,我們列出了其余6種主流的FM模型,并比較了它們的相關特性,詳細內容如表1所示:

Table 1 Comparison of Characteristics AmongDifferent Models表1 不同模型間的特性比較
4 實驗與結果
為了證明本文提出的FIFM和GFIM的有效性,本文在真實數據集上進行驗證實驗,并將其結果與其他主流模型進行對比分析.
4.1 數據集介紹
本文面向情景預測選用了4個真實的稀疏數據集:MovieLens[22],Frappe[23],Book-Crossing[24],Criteo[25].MovieLens中記錄了來自90 445個特征的2 006 859條用戶物品交互記錄,其稀疏度為99.99%.Frappe記錄了5 382個特征的288 606條用戶物品交互記錄,其稀疏度為99.81%.Book-Crossing記錄了來自Book-Crossing讀書網站的用戶信息,其中包含來自6個類別的226 336個特征,共計1 213 367條記錄.Criteo是一個來自Kaggle競賽的CTR預測數據集,共有來自39個類別的662 913個特征,共計51 871 397條記錄.由于Criteo的數據均為匿名處理后的LIBSVM格式數據,無法獲知具體的用戶及物品數,也無法計算稀疏度.為了保證實驗的公平性,我們采用了與NFM和IFM相同的實驗設計,整個數據集被劃分為訓練集(70%)、驗證集(20%)和測試集(10%).所有的模型在訓練集上進行訓練,并在驗證集上優化和調整訓練結果.由于4個數據集都只包含了正樣例,為保證訓練的合理性,我們隨機為每個正樣例采樣2個負樣例進行配對訓練.具體來說,對于MovieLens數據集,我們會隨機采樣2個用戶未對電影打過的標簽;對于Frappe和Book-Crossing數據集,我們將隨機抽樣2個用戶未交互過的物品進行配對;對于Criteo數據集,我們沿用了原數據集中已經存在的對應比例正負樣本配對實例.對于每個正樣例,我們將目標值設置為1;而對于負樣例,我們將目標值設置為-1.表2記錄了4個數據集詳細的統計信息.

Table 2 Statistics of Datasets表2 數據集統計信息
4.2 度量標準
在主流的推薦系統預測指標評測中,平均絕對誤值差(mean absolute error,MAE)和均方根誤差(root mean square error,RMSE)是評分預測任務的常用評價指標.考慮到RMSE相比MAE受異常值的影響更大,能更好地反映實驗效果,因此在本文中,我們選取RMSE來評價具體的模型性能.RMSE的主要思想是通過計算預測值與真實值之間的差異來衡量推薦算法的準確性,其值越小,推薦的性能越好:
(30)
其中,N表示測試集記錄條數,yi代表真實目標值.
4.3 對比模型
為了驗證本文所提出的FIM模型在預測過程中的最終效果,本文選取6種經典的相關領域預測模型進行對比.
1) LibFM[5]是原始FM的官方實現版本,也是當前經典的推薦預測模型對比模型之一.
2) NFM[7]模型將矩陣分解模型與神經網絡相結合,用于提取項目2階線性特征及高階非線性特征.
3) FFM[6]在FM的基礎上了擴展了“field”的概念,它將每一個特征(feature)都歸屬于一個特定類別.類別與特征是一對多的關系,在學習時通過構造3維的類別-特征-維度嵌入矩陣來進行向量學習.
4) DeepFM[16]通過引入神經網絡來對2階以上的特征交互進行建模.它主要由FM和DNN這2部分組成,分別學習低階和高階的特征交叉關系,底部共享嵌入向量的權重輸入.
5) AFM[8]通過對FM不同的特征交互引入不同重要性因子來改善FM,重要性因子由注意力網絡學習得到.
6) IFM[9]通過構建特征和類別各自的交互向量,來分別學習不同領域的交互信息.
4.4 參數設置
為保證實驗的公平性,所有的模型均在平方差損失函數下進行學習和優化.同NFM和IFM一樣,我們將學習率的取值范圍設置為{0.005,0.01,0.02,0.05},并取其中最好的值進行預測.同時,為了防止過擬合,我們也對L2正則和Dropout率進行了取值上的微調.對于L2,其λ和γ取值范圍可選取為{1E-6,1E-5,1E-4,…,1E-1}.而對于Dropout率,其取值范圍為{0,0.1,0.2,…,0.9}.所有模型均使用AdaGrad[18]優化器進行優化.同時,對于Movie-Lens,Frappe,Book-Crossing,Criteo,每批次的訓練數量依次為1 024,128,256,64,這些數量依據實驗條件在不同數據集下的可計算性而定.所有模型嵌入層的向量維度默認為256.同IFM一樣,我們將η的默認值設置為10.未提及的其他參數會保留原有的參數設置并進行適當的微調.其中,我們將KF的值分別在MovieLens和Frappe上設置為8和32以獲得最佳效果.在Book-Crossing和Criteo數據集上,KF設置為16.我們將實驗的默認迭代數設置為40,并采用Early Stop策略,即當模型在驗證集上連續5次未超過當前已記錄下的最好結果,便停止訓練.
4.5 實驗運行環境
1) 硬件環境.本文所有實驗均在同一Linux服務器環境下進行測試.CPU為Intel?Xeon?Silver 4114@2.20 GHz,顯卡為NVIDIA GeForce RTX 2080 Ti(顯存容量11 GB,顯存位寬352 b,顯存頻率1 4000 MHz),內存為32 GB 2 666 MHz DDR4.
2) 軟件環境.實驗的系統環境為Ubuntu 16.04.實驗編程語言為python 3.6.5,相關的深度學習框架為tensorflow,CUDA及cuDNN的環境分別為10.0和7.4.CPU環境運行下的編譯器為GCC 4.8.為了支持實驗的數據預處理以及相關的統計和分析工作,我們還引入了相關的Python科學計算包,具體用到的版本是:tensorflow(1.14.0),numpy(1.17.4),matplotlib(3.0.2),pandas(0.23.4),scikit-learn(0.20.1).
4.6 實驗結果與分析
實驗1.不同模型的性能比較.
如表3所示,我們將所有的模型在4個通用數據集上進行了比較,并列出了每一個模型所需的參數量.為了增強實驗的說服力,我們給出了10次實驗結果的平均值和實驗方差,以“±”連接,作為最終結果.為方便區分,我們將本文提出的模型進行了加粗標記.由于FFM模型在Criteo數據集上的參數量過大,不便于在當前實驗環境下計算,故我們在此未列出其結果.從結果中我們可以看到,FIFM模型及其擴展版本GFIM在所有比較模型中均獲得最好的表現.其中,FIFM的平均表現在MovieLens,Frappe,Book-Crossing,Criteo數據集上分別比次最優的IFM模型提升1.32%,0.48%,0.67%,1.62%.而GFIM的平均表現在MovieLens,Frappe,Book-Crossing,Criteo數據集上分別比IFM提升3.26%,1.65%,1.17%,2.19%(對應3.4節的效果1).雖然看起來這樣的提升指標并不明顯,但需要指出的是,即使1%的性能提升也可能在實際應用中帶來巨大的經濟收益[12].而對于DeepFM,其在MovieLens及Frappe數據集上的表現差于NFM,而在Book-Crossing及Criteo上實驗結果反超NFM.這得益于DeepFM的2階交互和MLP的并行預測機制,相比于NFM串行的2階交互池化層在訓練時需要的信息量更多,因此在Book-Crossing和Criteo這種涵蓋較為豐富信息的大參數量數據集下更容易捕獲潛在的影響因子.DeepFM在Criteo上還超過了AFM,因此DeepFM可適用于大數據量環境下的工業預測.對于FIFM及GFIM,它們在所有數據集上都能有較為穩定的表現,且都優于其他主流的因子分解機模型,驗證了我們模型的準確性.同時我們所提出的2個模型相比主流模型引入的額外參數量十分有限,且隨著數據記錄規模的增加(例如Criteo和MovieLens的記錄遠大于Frappe),額外的參數花銷占比會越來越小,但帶來的表現增益卻依然得到了不小的提升(對應3.4節的效果4的參數占用).

Table 3 Performance Comparison of Different Models表3 不同模型的性能比較
需要指出的是,GFIM相比于FIFM引入了神經網絡,具有更強的泛化能力,因此也需要消耗更多的參數.但相比于同樣引入field概念的FFM,參數量卻減少了很多.不同于FFM為每一個特征的每一個領域分配一個獨立的d維嵌入向量,我們的模型為每一個類別單獨分配一個低維度的向量進行獨立交互學習,極大降低了所需的向量空間.并且提出的FIM又進一步對特征和類別之間所存在的潛在關系進行更深層次的挖掘,提高了表現效果,這也是本文區別于其他主流模型的根本所在.
實驗2.FIM的影響.
為了驗證FIM的有效性,我們進行了基于FIM的消融實驗.FIM-*代表FIM分別在不同種類的FM模型進行對應組合,此時式(14)中的W會因維度需要而進行變更.此外,FIFM也可以理解為FIM+IFM版本.實驗結果如表4所示:
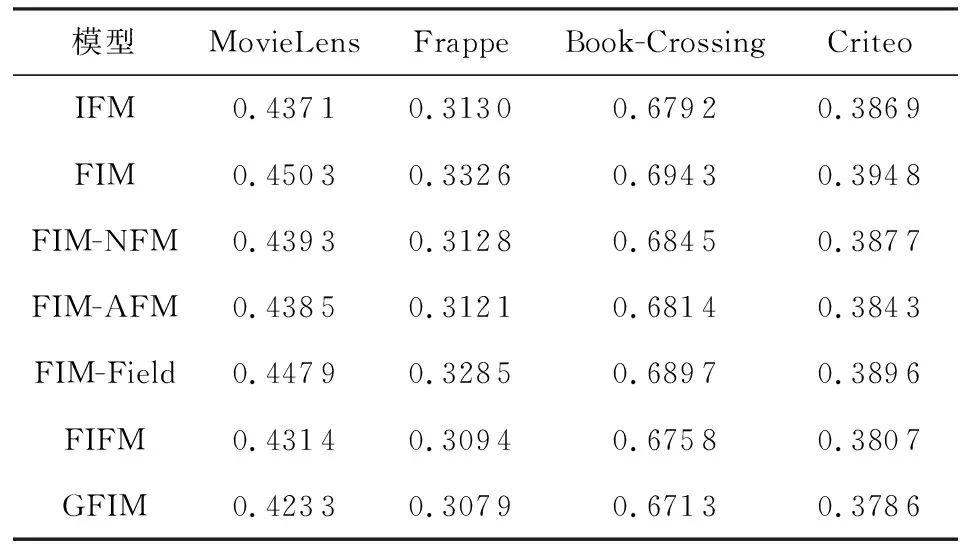
Table 4 Impact of FIM表4 FIM的影響
從表4我們可以分析得到:
1) 單以FIM組件直接作為輸出結果,自身就有較好的預測效果,相比于原始的FM,在MovieLens,Frappe,Book-Crossing,Criteo依次提升了3.95%,0.87%,2.66%,5.90%.與此同時,FIM在MovieLens和Book-Crossing數據集上比表3中的FFM提高了1.55%和0.57%,而在MovieLens數據集上比表3中的DeepFM提高了0.28%,驗證了FIM自身就能攜帶較為豐富的預測影響因子(對應3.4節的效果2).
2) FIM在類別較多的數據集上提升效果更為明顯.例如FIM在Criteo上甚至高于NFM,并與表3中的AFM結果相接近.我們認為主要原因可能是Criteo數據集擁有多達39個類別,具有豐富的類別信息,相比于NFM和AFM只在特征上進行交互,FIM將特征和類別信息進行了融合,更能發揮在多類別數據集上的優勢.
3) 雖然FIM具有一定的預測效果,但其在所有數據集上的表現仍差于IFM,這主要得益于IFM對特征交互和類別交互信息都進行了抽取,也說明了特征交互及類別交互的融合能夠很好地支持模型的預測.
4) 為了充分驗證FIM在各個模型上的影響力,我們還探究了FIM與第3節提到的NFM,AFM,IFM中的類別組件部分的組合版本.從實驗中可以發現,NFM和AFM在集成了FIM組件后在4個數據集上均有不錯的提升效果.其中,FIM-NFM在Frappe數據集上甚至高于了IFM,FIM-AFM在Frappe和Criteo上高于了IFM,說明了本文所提出的FIM不僅自身具有不錯的預測能力,還能為其他的FM模型帶來較好的增益效果(對應3.4節的效果3).
5) 與FFM相比,雖然FIM也使用了類別的概念,但二者的角度完全不同,FFM是為每一個特征都對應一系列存在的類別,初始化的計算模型是一個關于m,n,d的3維張量,而FIM在計算類別時默認非0特征屬于一個類別,計算模型是一個關于n和d的2維矩陣,能極大地節省參數空間.
6) 從上述1)~5)分析得出,所提出的FIM不僅能和各類FM變體無縫銜接,還能為這些FM模型帶來不錯的增益效果,甚至在無任何模型下也可以超越原始的FM模型,證明了FIM的有效性.
實驗3.不同模型的時間消耗.
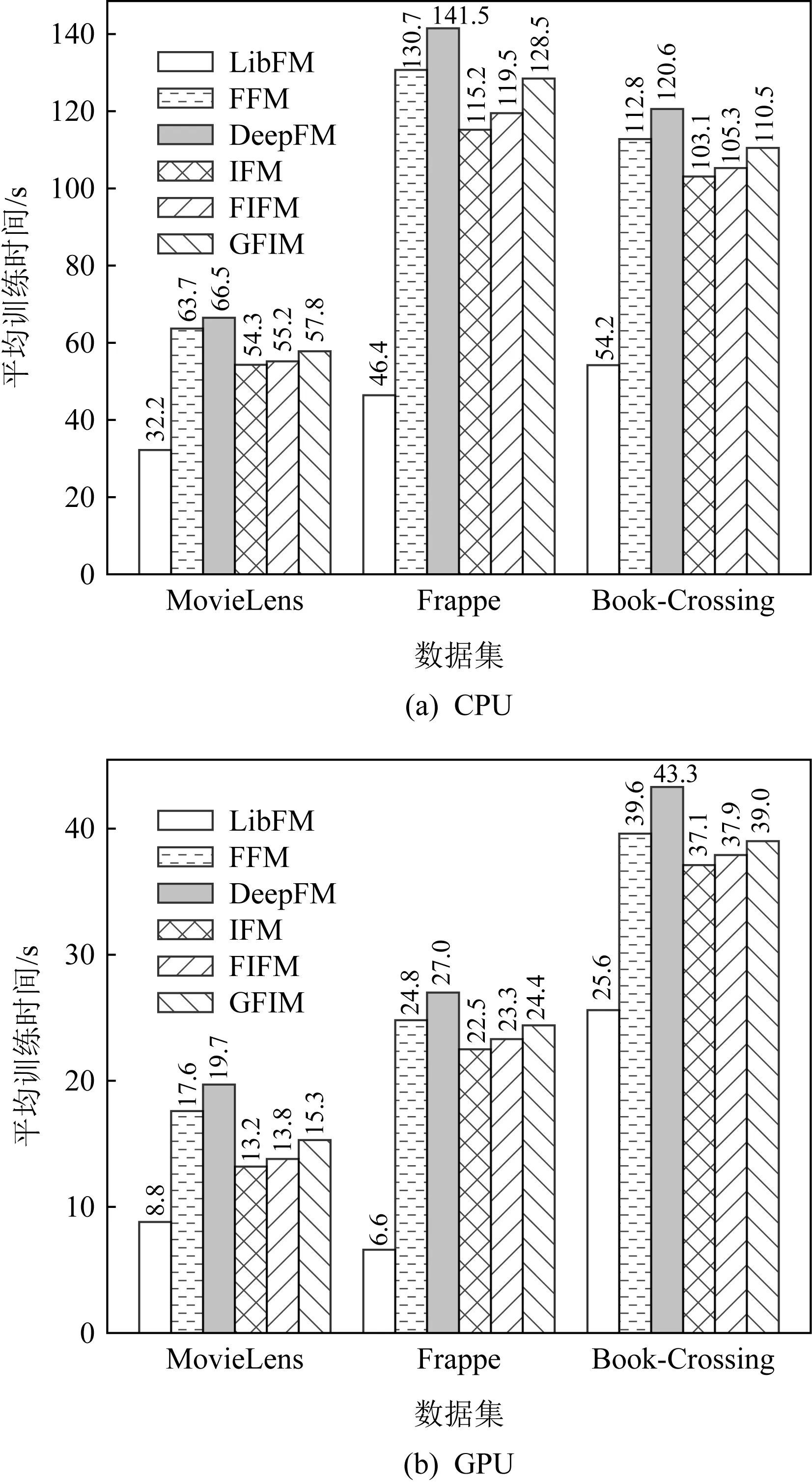
Fig. 6 Average training time of each epoch for different models on CPU and GPU圖6 在CPU和GPU上模型每輪的平均訓練時間
為了進一步驗證參數量對于模型訓練在時間上帶來的影響,我們統計并計算不同模型在CPU和GPU上40輪的平均每輪訓練時間.為方便直觀展示,我們選取了4個有代表性的模型進行對比:LibFM,FFM,DeepFM,IFM.其中FIFM和GFIM參數量要多于LibFM和IFM,并且小于FFM和DeepFM.實驗結果如圖6所示:
從圖6中我們可以發現:
1) 所有模型在GPU的訓練時間要明顯少于CPU,這主要得益于GPU可以在執行深度學習任務時使用更多的核心進行并發計算,也是當前主流服務器都采取GPU進行深度學習的主要原因[13].
2) 雖然FFM在參數上要遠多于其他模型,但訓練時間并未表現出與參數量成正比例的關系,相比DeepFM,FFM的訓練時間甚至還要略短一些,這可能是因為FFM在訓練時只做了通用的2階交互,參數量的增加雖然為其帶來了一定的計算復雜度,但相比于DeepFM復雜的多層感知機網絡計算過程,計算時間花銷更小,因此時間消耗也能保持在可接受的范圍.
3) 得益于FM簡化型的結構,LibFM在CPU和GPU上都有最快的訓練速度,但帶來的不足是交互時學習到的信息量不足,導致它在所有的數據集上的表現最差.
4) 由于FIFM可看作是在IFM的基礎上增加了FIM模塊,因此在訓練時間上要略長于當前最好的IFM.從圖6中CPU實驗結果可以看到,增加FIM后在時間上帶來的每輪花銷在CPU上只體現在1~4 s之間,對于在40輪迭代之前就到達收斂的模型來說也是能夠接受的.此外,得益于GPU的加速能力,FIFM模型的訓練時間在GPU上相比于IFM可以縮短到平均不足1 s,這對于當下GPU作為主流深度學習服務器的場景是完全可以忽略的(對應3.4節的效果4的時間消耗).
5) GFIM作為FIFM的神經網絡版本,由于加入更為高階的多層感知機,訓練時間長于FIFM,但由于GFIM在主體結構上傳承于FIFM,因此它的總體時間也相較FFM和DeepFM有所降低.
6) 從上述1)~5)分析可知,FIFM和GFIM在實際訓練時是完全能夠滿足當下服務器對于時間復雜度的需求.
實驗4.不同策略在數據集上帶來的影響.
為了進一步驗證組成FIFM模型的各個策略在訓練的過程中對最終的表現結果帶來了哪些影響.我們做了對比實驗:將Fea(+)記為僅保留特征交互的方法,線性部分保持不變.將Field(+)記為僅保留類別交互的方法,而將Fea_Field(-)記為FIFM去除特征-類別權重后(保留特征交互和類別交互)的方法.將Fea(+)、Field(+)、Fea_Field(-)這3個方法結合已有的FIFM模型在2個訓練集上進行了40次迭代訓練,并記錄下它們在測試集上每一輪的表現.
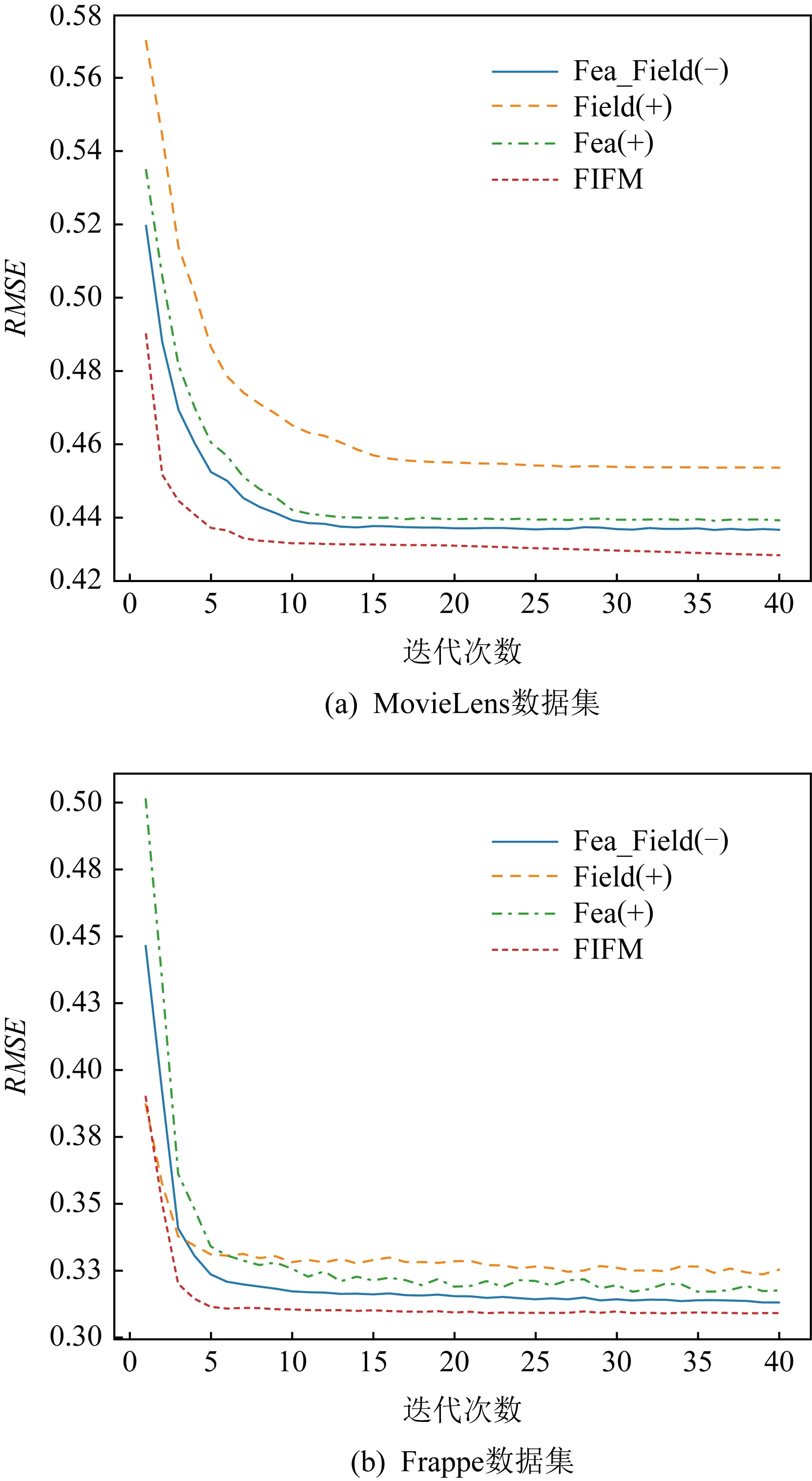
Fig. 7 Performance of different strategies on MovieLens and Frappe datasets圖7 不同策略在MovieLens和Frappe數據集上的表現
圖7展示了不同策略在MovieLens數據集和Frappe數據集上的表現.可以看出,隨著迭代次數的增加,所有的模型都逐漸趨向于收斂.毫無疑問的是,集合了所有策略的FIFM獲得了最好的效果.對于收斂速度而言,在MovieLens和Frappe數據集上獲得最快收斂的分別是FIFM和Field(+).在模型趨于穩定后,不同策略的表現結果從大到小依次為FIFM>Fea_Field(-)>Fea(+)>Field(+).我們可以發現,結合了特征嵌入矩陣和類別嵌入矩陣的Fea_Field(-)比單獨的交互學習具有更明顯的提升作用.此外,特征交互帶來的增益大于類別交互,這也是由于特征向量包含了類別向量不具備的更為精細化的信息.相比MovieLens,Field(+)在Frappe上收斂得更快,這可能是因為Frappe的類別特征具有10個,相比MovieLens的3個,類別嵌入矩陣可以得到更充分的學習.
實驗5.不同維度的模型在數據集上的效果.
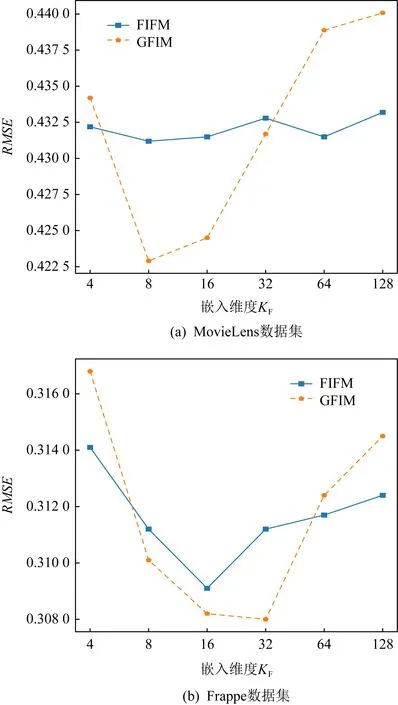
Fig. 8 Performance of varying field embedding KF on MovieLens and Frappe圖8 不同類別嵌入維度KF在MovieLens和Frappe上的表現
我們比較了不同的類別嵌入維度KF在2個數據集上的表現.從圖8中看到,隨著維度的持續上升,表現效果也會因過擬合而有所下降,因此合理的KF值需要取決于不同數據集具體的數據特征.例如圖8(a)中,KF在MovieLens上獲得最佳表現的嵌入維度8要明顯區別于圖8(b)的嵌入維度32.我們也將其歸結為數據集的類別因素.由于Frappe上的類別數10要遠多于MovieLens上的3,因此感知交互層能夠獲取9×10/2=45個交互向量,而同樣的MovieLens只能獲取2×3/2=3個交互向量,故獲取可訓練信息也就遠小于Frappe,導致更小的維度提前達到了訓練的飽和狀態.同時,我們注意到,FIFM隨著維度變化的波動性要小于GFIM,這是由于GFIM引入了逐點相乘的向量級別乘法,對維度變化更為敏感.但相比于特征-類別標量計算的FIFM也容易取得最佳效果,同時也更容易帶來過擬合問題致使后續效果下降.
圖9展現了特征嵌入向量的維度d在MovieLens和Frappe上的表現.不同于類別嵌入矩陣維度KF,特征嵌入矩陣維度d需要更大的數值以獲得最佳的表現效果.FIFM和GFIM在2個數據集上的最佳取值均在256左右,此維度要遠遠大于KF的8和32,間接說明了特征交互相比于類別交互具有更豐富的信息量,這也是此前眾多基于特征交互的FM改進模型獲得成功的原因.而GFIM受到過擬合的影響帶來的RMSE表現下降也沒有圖8中的類別交互那么明顯.
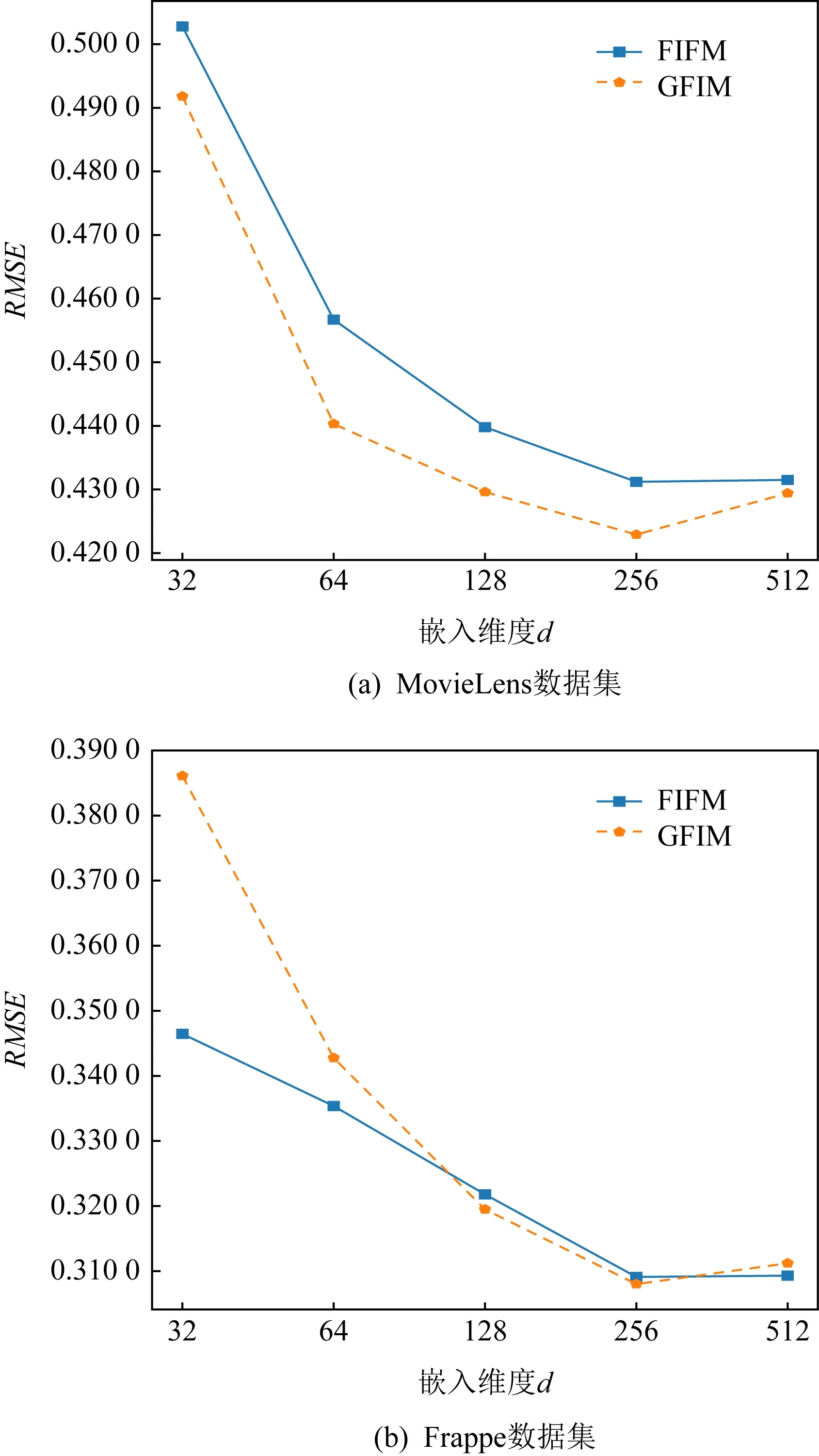
Fig. 9 Performance of varying feature embedding don MovieLens and Frappe圖9 不同特征嵌入維度d在MovieLens和Frappe上的表現
相比于其他稀疏預測模型,本文提出的FIFM具有更好的表現效果.GFIM在FIFM基礎上引入了神經網絡作為支撐,從而進一步提升了實驗效果的上限.
實驗6.數據稀疏環境下不同模型的性能比較
為了進一步評估數據稀疏性對推薦性能的影響,我們在MovieLens上選取不同規模的數據內容,用于模擬不同稀疏程度(10%,30%,50%,70%,90%)的訓練數據集,所有模型在不同程度數據稀疏環境下的性能表現如表5所示:
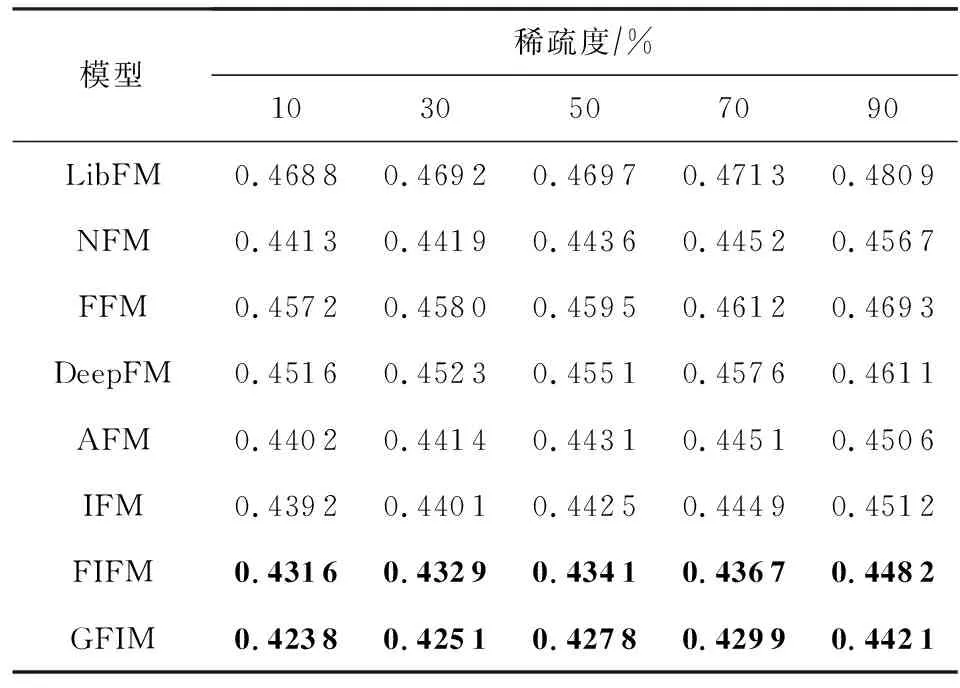
Table 5 RMSE Comparison of All Models with Different Sparse Degrees on MovieLens
從表5中我們可以發現,伴隨著MovieLens數據集稀疏程度的上升,所有的模型表現效果均有不同程度的降低.需要特別指出的是,在90%稀疏條件下,所有模型均有較大幅度的性能下降.而基于FM的改進模型例如AFM或DeepFM,由于采用了神經注意力機制或深度高階特征擬合學習方法,下降幅度小于原始的FM.同時我們還發現,FFM和IFM均引入了類別交互模型,但FFM的表現整體上要差于依賴于神經網絡機制的IFM,也差于未考慮交互模型的DeepFM,這表明了深度學習在特征擬合時仍然具有強大的高階特征擬合能力.
5 總 結
本文從特征-類別融合的角度出發,提出了一種新的特征-類別交互因子分解機模型(FIFM),并基于深度學習的泛化理論給出了相應的神經網絡擴展模型GFIM.相比于從特征交互角度出發的FM,NFM,AFM,從類別交互角度出發的FFM和以特征、類別分別交互角度出發的IFM模型,我們提出的模型加入了從特征-類別融合的視角,并設計了一種新的特征-類別融合交互機制(FIM).FIM計算特征和類別融合后的交互特征,豐富了在各類稀疏場景下的高階語義信息和潛在預測因子,進一步提高了預測的準確性.同時,本文還進行了多類實驗來探究在不同場景下的預測結果,記錄了不同數據集下的時間和空間消耗情況,并分析了原因.在4個真實數據集上的實驗結果表明,在常規實驗環境和稀疏實驗環境下,本文提出的FIFM和GFIM模型相比于主流的預測模型在RMSE指標上都具有提升效果.
作者貢獻聲明:黃若然負責論文框架設計、算法提出、實驗設計和運行,以及論文撰寫、修訂和最終審核;崔莉負責論文整體研究思路的提出、內容設計和最終版本修訂;韓傳奇負責部分內容撰寫、文獻調研以及插圖設計和修訂.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
