基于YOLO的人臉口罩檢測
2022-07-06 11:09:58王克麗景運革
運城學院學報 2022年3期
王克麗,景運革
(運城學院 數學與信息技術學院,山西 運城 044000)
引言
自2020年初新冠疫情暴發以來,戴口罩成為人們出行、復工復產必備的“武器”[1]。通過戴口罩的方式來有效預防新冠病毒和降低呼吸道類病毒的感染已成為人類共識[1,2]。在此疫情影響下,經常發現在一些特定公共場所中,例如航班飛機、高鐵、地鐵、公共汽車、醫院及學校教室等,要求佩戴口罩,但經常會出現個別人忘記佩戴口罩的現象。對于此類現象一般是由相關負責人專門進行提醒和要求,效果明顯但卻增加了人力成本,準確率不高,同時也增大了人與人之間的病毒傳播的機會[3]。在此背景下,研究自動設備來實時準確地檢測人臉是否佩戴口罩的方法意義重大[4]。
疫情期間特殊場所進行人臉口罩檢測的問題實質屬于目標檢測任務。目標檢測任務旨在讓計算機自動檢測出圖像或視頻中關注的目標對象所在的位置及種類,是計算機視覺中的一項經典任務。目前階段比較流行的目標檢測方法就是基于深度學習方法,根據檢測流程的差異進一步可分為兩種類型:兩階段 (Two Stage) 法和單階段 (One Stage) 法[5,6]。顧名思義,兩階段法首先生成預選框后再進行物體分類,而單階段法同時對物體的位置和類別進行預測。兩階段法的代表性算法有:R-CNN,Fast R-CNN,Faster R-CNN 等;單階段法的代表性算法有:YOLOv1-v4, SSD, FPN 等[7]。兩階段法雖然在算法上先使用啟發式法(selective search)或CNN網絡產生Region Proposal,然后再在Region Proposal上做分類與回歸,準確度高一點,但與YOLO相比,其速度較慢。YOLO模型的算法僅僅使用一個CNN網絡直接預測不同目標的類別與位置,可以一目了然地查看圖像,并基于圖像外觀預測與某些類別相關的邊界框,而類別可以是任何內容,此特殊功能使YOLO脫穎而出[8]。
在人臉口罩檢測任務中,感興趣的目標實體有兩類:戴口罩的人臉和不戴口罩的人臉。因此,人臉口罩檢測任務可以簡單定義如下:給定一張圖片,輸出該圖片中所有人臉所在的位置坐標 (x_min, y_min,
x_max, y_max) 以及有無戴口罩 (0:未戴口罩,1:戴口罩)。
因為人臉口罩檢測任務屬于目標檢測任務,所以主流的一些基于深度學習的目標檢測方法均可應用于人臉口罩檢測任務中,有些文獻嘗試使用SSD模型檢測人臉口罩,將戴口罩或未戴口罩的人臉為感興趣的目標,經過足夠的訓練之后,便可以較好地完成人臉口罩檢測任務[9,10]。針對口罩檢測任務主要做了兩方面的工作:(1)圍繞YOLO系列模型構建了三種人臉口罩檢測模型:YOLOv1,YOLOv2,YOLOv3;(2)在預處理后的 AIZOO 數據集上對三種模型從零進行訓練和測試,并進行了基本的性能比較和案例分析。
1. 人臉口罩檢測
1.1 數據整理
人臉口罩檢測任務選用的數據集為AIZOO以及少量真實口罩遮擋人臉識別數據集RMFD(Real-World Masked Face Dataset)。
AIZOO數據集開源了7959張人臉標注圖片,該數據集來自WIDER Face和MAFA數據集, 并重新修改了標注和校驗[11]。對于開源的AIZOO數據集,通過預處理將其原始地標注文件轉化為了YOLO 模型可讀取的標注文件,具體格式為:每張圖像對應一個后綴替換為.txt 的標注文件,標注文件里的每行對應一個目標實體 (戴口罩的人臉或未戴口罩的人臉),具體格式為 (class, x_center, y_center, width, height)。對于RMFD數據集,使用 lableImg 工具標注了少量樣本,格式與AIZOO一致。
為了便于理解,從數據集中挑選了若干已標注的樣例圖像進行可視化展示:如圖 1所示,對于每張圖片,標注文件中包含所有人臉的位置坐標以及是否戴口罩 (0:未戴口罩,1:戴口罩)。

圖1 標注圖像樣例
1.2 模型設計
在模型設計中選擇了三種YOLO系列的模型:YOLOv1、YOLOv2和 YOLOv3。對于每種模型,都從隨機初始化開始訓練,并對其進行了基本的性能比較。
相比于兩階段目標檢測算法,YOLO系列模型沒有顯示提取候選框 (region proposal) 的過程,因此模型更簡單,速度更快,隨之而來的缺點是物體位置識別精度較差,召回率較低。YOLOv1-v3的改進過程總結如下:YOLOv1 使用改進后的 GoogleNet 作為 backbone網絡,輸入分辨率固定為 448x448,相比 Faster R-CNN 速度有很大提升,但精度不夠高;YOLOv2 在YOLOv1中的backbone網絡基礎上借鑒了VGG 網絡中的卷積方式,利用多個小卷積核替代大卷積核,并且利用1x1卷積核代替全連接層,另外還引入了Batch Normalization 操作以及改為預測anchor box的修正量,相對于YOLOv1不僅參數量更少速度更快,而且性能也有所提升;YOLOv3使用了Darknet-53作為backbone網絡,該網絡使用了殘差模塊,同時支持多尺度輸出,解決了YOLO顆粒度粗的問題,這對小尺度目標檢測效果有較大提升。
2. 實驗設計及結果
2.1 數據集劃分
基于上述數據整理階段獲得的數據,按照近似 3 ∶1∶1的比例劃分為訓練集、驗證集和測試集,每種數據集等比例包含WIDER源圖像和MAFA源圖像,這三類數據集的圖像數量如表1所示。

表1 數據集劃分 單位:張
2.2 模型訓練
對于每個模型,從隨機初始化開始訓練,batch大小為16,迭代次數設為80,各模型在訓練集上的損失變化見圖2。可以看出,三個模型均在80次迭代以內趨于收斂,但是YOLOv2和YOLOv3的損失曲線更平滑,是由于這兩個模型中引入了批量標準化(Batch Normalization)等使得神經網絡損失(loss landscape)更平滑的策略導致的;同時可以看到YOLOv3相比YOLOv2收斂速度更快,收斂后的損失值也更低,從一定程度上說明YOLOv3相較于YOLOv2在性能上的提升。

圖2 訓練損失變化曲線
2.3 平均精度均值
平均精度均值(mAP, meanAveragePrecision),即AP(AveragePrecision)的平均值,它是目標檢測的主要評估指標,mAP值越高,表示在所選數據集中對于口罩檢測的檢測效果越好。三個模型在mAP@.5/mAP@.7/mAP@.9/mAP@[.5:.95] 各指標下關于未戴口罩,戴口罩和平均類別的性能如表2所示。從表2的數據可以總結出出,YOLOv3 在各指標上的性能都為最高,戴口罩類別的mAP@.5值達到了0.947,在一定程度上可以投入實際應用;其次是YOLOv2,戴口罩類別的mAP@.5值為0.939;性能最差的是YOLOv1,戴口罩類別的mAP@.5值僅為0.386。從上述可以得出YOLO系列模型的迭代在性能上不斷提升。
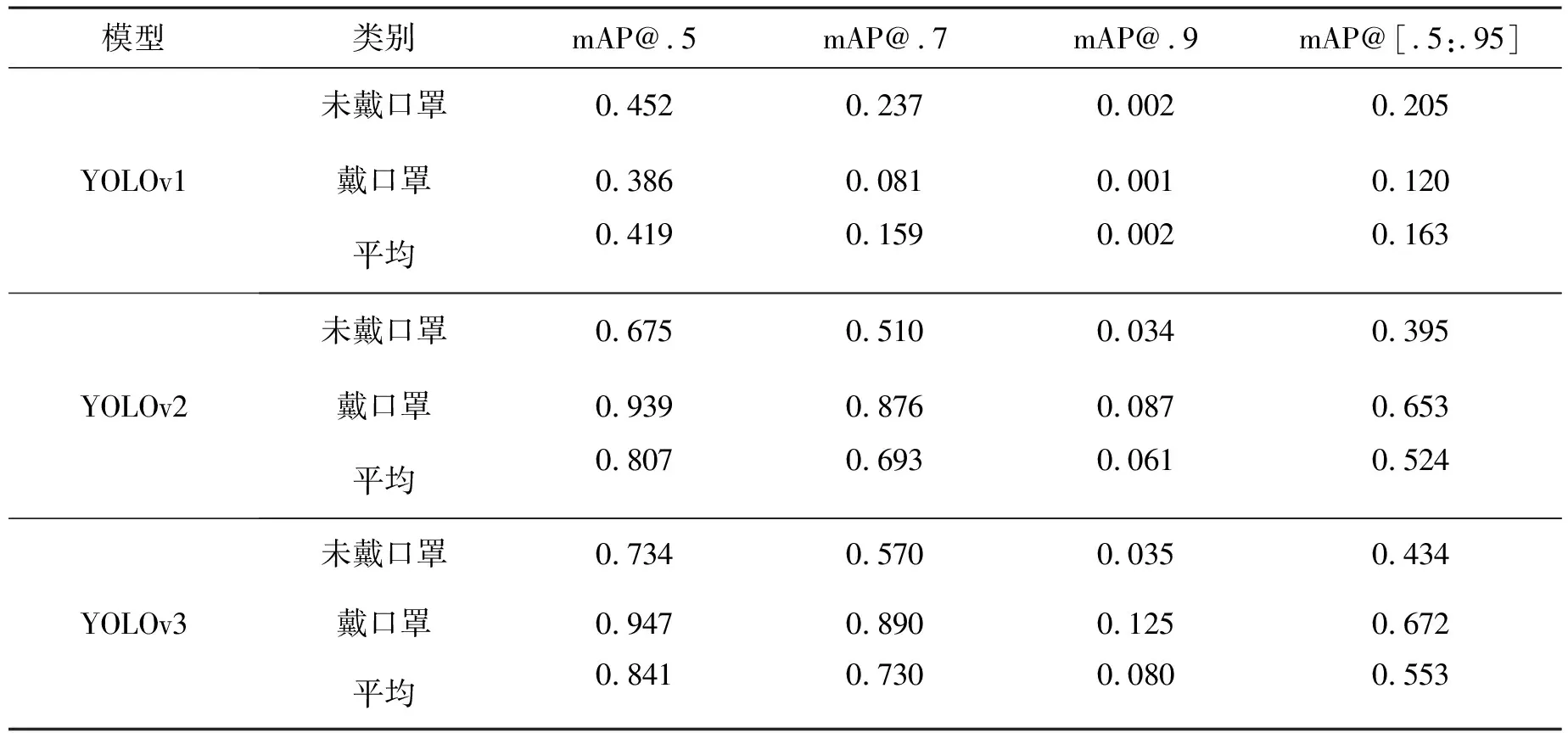
表2 YOLOv1-v3 各指標性能
2.4 準確率和召回率
YOLOv1-v3在IoU閾值分別取0.5、0.7和0.9時每類的準確率和召回率(PR,Precision and Recall)曲線如圖3,圖4,圖5所示。根據PR曲線可以得到以下兩個結論:
(1)對于每個模型,IoU閾值越大,模型的性能越差 (根據PR曲線下方的面積),這是由于IoU閾值越大,對模型預測位置的精度要求越高。
(2)對于相同類別和相同IoU閾值的PR曲線,YOLOv3的性能最好,其次為YOLOv2,最差的為YOLOv1。
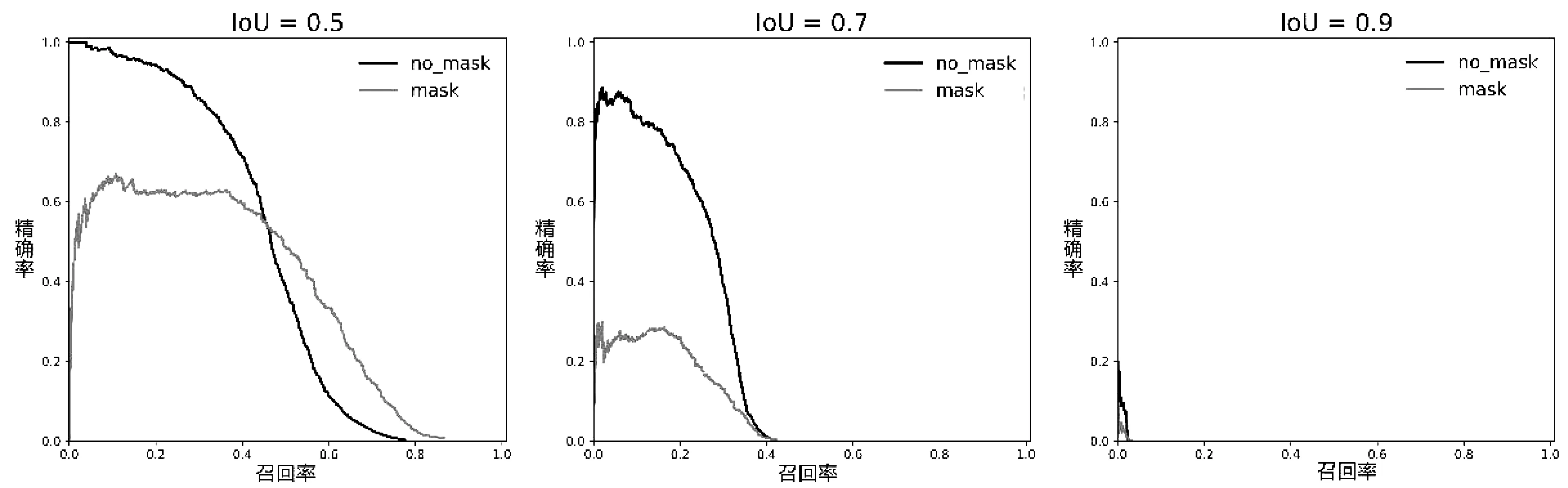
圖3 YOLOv1模型的不同IoUs閾值PR曲線
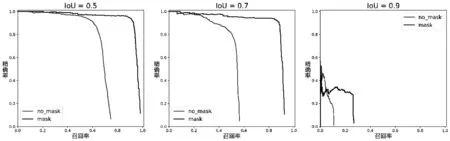
圖4 YOLOv2模型的不同IoUs閾值PR曲線
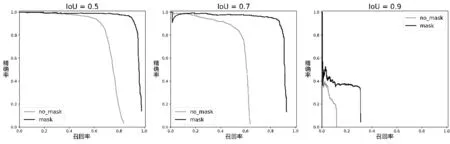
圖5 YOLOv2模型的不同IoUs閾值PR曲線
3. 實驗結果分析
針對 YOLOv3,我們挑選了若干測試樣例對其進行人臉口罩檢測,結果如圖 6所示。從圖中可以看出,紅色方框標出了兩個檢測結果較好的測試樣本,盡管圖像中的人臉較小,但YOLOv3模型依然檢測出了所有人臉并正確識別了是否帶有口罩,這得益于YOLOv3在多尺度目標檢測上的優化。紅色橢圓框標出了兩個檢測結果較差的測試樣本,模型未檢測出人臉,經過分析所檢測結果,發現這兩張圖片中的人臉均為側臉,且圖中第4行第3列的圖像光線較暗,這從一定程度上反映了YOLOv3 模型可能在側臉和弱光線環境下檢測性能會下降。

圖6 測試樣例可視化
4. 結論
針對人臉口罩檢測任務,嘗試構建了三種基于深度學習的人臉口罩檢測模型:YOLOv1、YOLOv2和 YOLOv3,并對三個模型的特點和差異進行了詳細介紹。對于實驗部分,是在預處理后的AIZOO數據集上,對各個模型進行訓練和測試,根據實驗結果顯示YOLOv3模型在各個評價指標(mAP、PR等)上的性能均為最優,排除在個別情況下檢測效果不理想,YOLOv3 在大部分情況下都能完成較好的人臉口罩檢測,應用前景良好。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
