PVANet:針對弱紋理工業零件的像素級6DoF 位姿估計方法
2022-06-23 09:17:26楊純,陳權,王濤
智能計算機與應用 2022年6期
楊 純,陳 權,王 濤
(廣東工業大學 計算機學院,廣州510006 )
0 引言
位姿估計在機器視覺領域扮演著十分重要的角色,尤其是一些應用場景通過使用視覺傳感器進行導航,增強現實等操作,需要找到現實世界和圖像投影之間的對應點。比如,在工業作業場景的抓取任務中,經常會遇到幾種工件堆放散亂、待抓取物體的表面紋理信息不夠豐富的場景,由于材質相同,光線在金屬介質表面的傳播性質,以及在光線不足的情況下,甚至會因為彼此間遮擋產生陰影,導致工件邊緣的重要信息較為模糊,特征提取不夠突出,從而嚴重影響到指定任務的抓取執行。
現如今的位姿估計方法大都在公用數據集上具有很好的魯棒性,由于場景的改變存在諸多不確定性問題。如Tless 等數據集往往體量過于龐大,He等人提出的方法在這些數據集上表現良好,但是受硬件因素的約束導致訓練困難,雖然網絡效果很好,卻因網絡設計復雜而難以快速部署到機器人系統,從而影響實際作業效率。而其他的一些數據集、如linemod 等存在遮擋或截斷等特點,且過于生活化,表面紋理色彩都很豐富,無法滿足一些特殊的場景需求、如本文探討的金屬工件抓取問題,為此本文從數據集的制作開始,結合其他網絡的優點進行弱紋理金屬工件的6DoF 位姿估計的實用型研究。
本文針對上述問題,擬從單個RGB 圖像的角度,結合注意力機制,將像素級上效果良好的一種方法擴展到一個新的位姿估計分支PVANet,使其用于工件的精確抓取任務。本文的主要貢獻是將工件的小型數據集成功擬合進這個網絡,對網絡模型的部分結構做出重要調整,優化精確度。
將注意力機制結合深度學習網絡進行訓練的方法主要是通過掩碼來實現,通過不斷地學習,使深度神經網絡學習到數據集中每一張圖片中感興趣的區域。一些網絡挖掘到了通道注意力機制的優點,指出不同通道的特征圖的作用權重不同會嚴重影響結果,Jaderberg 等人提出的空間注意力機制,發現包含對象的檢測區域相較于其他背景信息的重要性要大很多。鑒于這些優點,很多研究提出了結合通道注意力和空間注意力的方法,充分發揮兩者的重要性,并將其功能進行結構化設計,本次研究合理利用了這一優點來提取了局部信息。
分析可知,對于這種距離相機視點較遠的情況,深度信息已經不太可靠,相較于一些使用3D 定位和旋轉的方法,本文從pixel-wise 或者patch-wise 上進行投票選出2D 關鍵點的方法,如圖1 所示,這在Yu等人的方法中也有體現。但是實驗中忽略像素點和關鍵點之間的距離對假設偏差影響不大的情況,此后將采用(Effective Perspective-n-Point,EPnP)根據2D-3D 對應的方法進行位姿估計,在原工作基礎上提出一些改進,結合目標檢測和位姿估計的端到端通道,通過二維RGB 圖像和相關的3D 模型建立對應關系,回歸位姿參數和。本文主要貢獻如下:

圖1 投票后選出2D 關鍵點Fig.1 The selected 2D keypoints after voting
(1)使用較少的數據模態預測弱紋理工件位姿,彌補了位姿估計數據集在工業零件方面的空缺。
(2)分析網絡深度和數據集規模的關系,將注意力機制融入像素級投票網絡,并進行一些重要的調整使其能夠更好地進行遷移使用。
(3)改進后的方法在自定義數據集和Linemod上的評估精度在0.9 以上,達到工業應用要求,且可視化效果更好。
1 相關工作
目前比較成熟的位姿估計方法包括但不限于基于對應、基于模板、基于投票這三種,并且具有比較完整的實現過程。其中,基于對應的方法通過隱式地回歸3D 點在2D 圖像上的若干投影點,再使用PnP進行位姿細化。基于模板的方法將模型的RGB圖像結合精心設計的CNN 取得很好的位姿估計的結果。使用投票策略的方法中,最重要的是充分利用像素信息,Brachmann 等人充分利用每一個像素來產生一個3D 坐標軸,Peng 等人通過像素投票生成2D 關鍵點,另一部分則是使用霍夫投票獲得很好的結果。這些方法通過直接或間接地從RGB 圖像中恢復6D 位姿。另一個大的分支是在卷積網絡中結合深度信息,自從PointNet 系列的重大創新后,直接通過點云信息進行位姿估計的方法被提出,而Wada 等人使用該方法在處理弱紋理目標時甚至都能獲得很好的效果,但有關的研究一般是在大型公用數據集上不斷提升算法的精確度,這在應用于實際場景時就會出現如下類似問題的探索。
對于工業場景中常見的無紋理金屬工件,在光照等因素的干擾下,RGB 圖像中可用的信息很少,目前主要的解決辦法是利用圖像中邊緣像素的底層特征進行計算,如Zhang 等人提出使用多階段細化的方法實現簡單的抓取任務。由于金屬在不同光照角度導致粗糙表面反光使得RGB 不可忽視,充分考慮這些RGB 圖像和模型本身攜帶的信息能夠在一定程度上降低成本,僅從RGB 圖像檢測6D 位姿對于其他類別的機器人應用也是同樣重要。例如從單目稀疏視角考慮直線輪廓之間的相互關系作為描述金屬零件的高級幾何特征,放棄利用像素這一重要元素,或是在有限樣本數的單RGB 研究上給出了很好的示例,但目前仍是在具有豐富紋理的常見生活物品對象上做進一步的提升。本文的研究對象是弱紋理的金屬工件,從像素級進行探索,并使用投票對遮擋物體進行位姿預測。
投票預測局部不可見點的位置時,先根據3D模型點中的關鍵點投影到2D 像素平面,目前已有方法提供了一些3D 特征描述子的實驗效果,表明都能檢測一定數量的特征點,但是如果限制特征點的數量進行投影,用于表面信息本就不豐富的工件則情況不一定很好。一些基于點對特征的方法試圖通過使用點云上的少量點對構成描述子進行位姿估計,如Drost 等人、Papazov 等人提出的全局建模、局部匹配,Hinterstoisser 等人優化前者也使用到的PPF 描述子來達到最佳效果,但這些方法對于場景簡單、成本低的數據來說很有可能導致過擬合,且需要使用點云掃描儀器進行額外的數據采集。另外一些使用隨機森林的方法,通過霍夫投票逐像素投票,或者使用深度學習的方法提取特征,甚至結合深度信息,這些密集的2D-3D 對應雖然對遮擋場景具有魯棒性,但是網絡體量大,鑒于此,本文采用FPS 隨機選擇8 個點作為候選關鍵點的方法,保證每次的點都不一樣,減少人為因素的影響,將RANSAC 方法重新定義為投票方法,通過逐像素迭代淘汰假設關鍵點的方法對2D關鍵點進行投票,結合了密集融合的方法和基于關鍵點的方法的優點,針對特征提取不夠全面的問題,有效融合了注意力機制,進行網絡效益的提升。
2 工業弱紋理零件位姿數據集的獲取方法
2.1 方法概述
在進行位姿估計之前,首先要構建符合場景并帶有位姿標簽的數據集。目前很多先進的方法都是在公用數據集上進行精度提升,這些通用措施導致的一些局限性無法擴展到其他特殊場景。
本文方法使用Glocker 等人提出的主要步驟進行多邊形模型的3D 重建,并將其用于單個物體的檢測。相較于其他流行的模型重建方法,這是為數不多的利用物體表面信息進行重建的手段,在小場景的重建上相較于其他算法取得更好的效果,和Weise 等人的研究類似,這使得一些操作雖然枯燥、但容易著手,具體的標注流程如圖2 所示。由圖2 可知,獲取視頻流序列中間的100 s,通過對這些序列進行場景稠密重建,截取包含工件的一定范圍場景后,導入工件的CAD 模型進行粗略關鍵點匹配,再利用ICP 進行細化后,手動調整工件模型位姿,并根據獲取的位姿對工件模型進行投影獲取標簽。研究可知,初始場景為包含4 個形狀不同、紋理和材質相同的工件隨意擺放在背景雜亂的工作臺,數據的采集過程是將相機安裝在機械臂末端,通過機械臂的運動來采集數據。
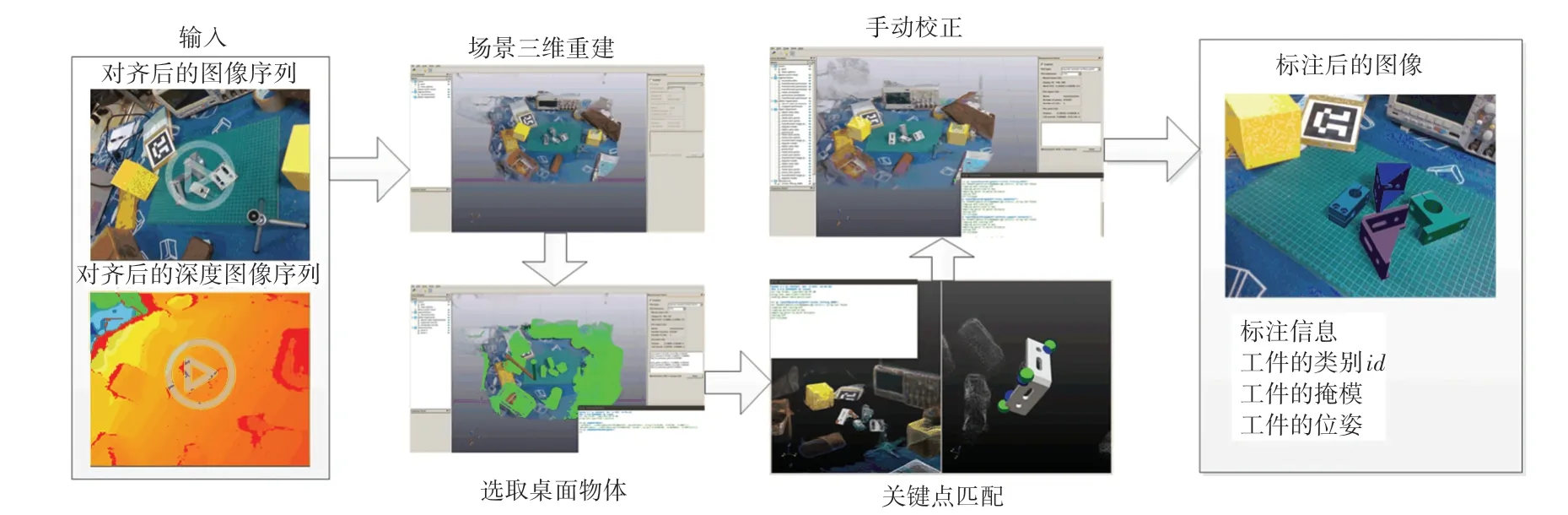
圖2 數據集的標注過程Fig.2 Annotation process of data set
實驗使用的都是真實數據集,經測試按照隨機3:1 的比例分別抽取數據制作訓練集和測試集進行訓練和測試時效果最好,在無合成數據的情況下,能夠盡量維持不同幀之間標簽的語義相關性。為了得到mask 這一重要因素,一些算法通過實例分割把對象從場景中分離出來,但是目前的分割網絡為了得到精度更高的結果,模型體量都比較大,這在工業應用上將顯著影響作業效率,本文在實際使用中利用標注的位姿,通過模型投影可直接獲得。
2.2 位姿描述
對姿態的描述是機器人進行位姿估計的基礎,包括歐拉角、旋轉+平移,以及四元數表示。
對于3D 空間的任一參考系,任何其他的坐標系都可以用3 個歐拉角表示,即通過繞著,,這3個軸旋轉的3 個角度進行組合表示,由于參數的顯式意義,這種表示是直觀的,并且旋轉向量與旋轉矩陣的相互轉換可以用羅德里格斯公式來解決,但是在一些情況下卻不能實現平滑插值,甚至還會產生萬向節死鎖問題,通常在有關旋轉的應用場景中基本不使用歐拉角來旋轉,而是使用上述后2 種進行表示,相互之間也可進行轉換。
相較于旋轉矩陣需要滿足單位正交的限制,如何在訓練目標中加入該限制條件是難點之一,在這項工作中,本文使用的是四元數(1)這種計算量偏小的位姿表示:
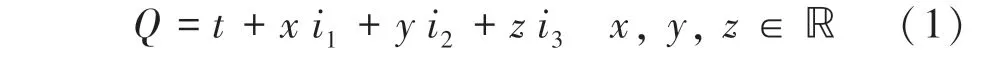
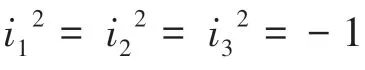
在進行網絡訓練前,本文對真實位姿進行預處理,在數據處理的過程中,尤其要注意實部與虛部的相對位置關系,否則回歸研究后的結果就會出現如圖3 所示的由于旋轉矩陣轉換為四元數時使用了函數的默認順序導致的位姿偏差過大的問題。

圖3 可能出現的偏差過大的問題Fig.3 Possible problems of excessive deviation
3 本文方法
3.1 結合注意力機制的PVNet 網絡架構
圖4 為經過調整后的模型。圖4 中,以ResNet-18為主干網絡,增加注意力機制強化特征提取性能,網絡的輸入為自定義數據集,輸出為掩膜分割和向量,然后用RANSAC 投票出關鍵點,最后使用PnP 回歸位姿。和Peng 等人的相關研究類似,使用預訓練的ResNet-18 為主線,重點在預測像素的方向、而不是從圖像中直接回歸關鍵點的位置,即網絡的主要作用是預測向量場和生成對象標簽,通過重視目標的局部特征,減輕了雜亂背景的影響。對于圖像中的任意一個像素點,坐標表示為(,),將其到目標對象的2D 關鍵點x的方向定義為向量v,即:
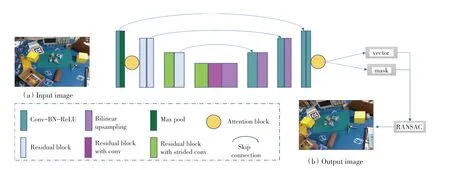
圖4 本文網絡管道說明Fig.4 The network pipeline in the paper
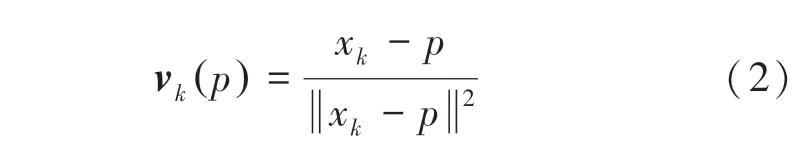
其中, x是通過最遠點采樣方法獲取的模型3D 點通過投影矩陣獲得,的坐標是根據式(1)所得姿態,結合相機內參通過向投影矩陣公式(3)帶入計算得到,即:
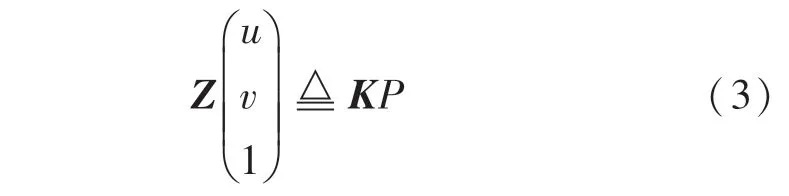
其中,(,,)表示世界坐標系下點的位置,為本實驗中D435 系列相機對應的內參矩陣。
給定語義標簽和單位向量,物體的所有像素都對通過基于投票的RANSAC 機制生成關鍵點假設進行投票,這些投票中會有置信度分數較高的一些假設(大于設定的閾值),通過RANSAC 策略,使用循環迭代計算出來的最好模型再一次生成假設坐標并進行關鍵點的投票,用這些假設表示圖像中關鍵點的空間概率分布是很可靠的,因為這樣與更多的預測方向重合,局部不合適的點的投票只占少量。
本文在對原始網絡進行遷移使用的時候,發現其本身效果已經具有一定的準確性,可視化結果詳見實驗部分,但是網絡龐大,本文在保持原來方法的主要步驟的情況下,對局部結構進行了調整。對此可給出研究分述如下。
(1)對一些效果不明顯的設計進行了更改,具體但不僅僅包括將原來在skip connection 中間部分的Residual block with dilated conv,改為普通的3×3卷積,該卷積結構試圖通過空洞卷積的參與來增加感受野范圍,學習到更多的特征,然而對于本文這種遠離視角的小物體分割,特別是尺寸都差不多的工件來說有弊無利,dla 可能導致局部信息缺失,顏色紋理相近的工件特征相關性匱乏,從而影響最終的分類結果。
(2)將注意力機制模塊結合進ResNet-18 進行特征提取,其有效性已經在某些工作中體現得很充分,本文的工作是在網絡的第一層,即使用最大值池化前、最后一層,即使用均值池化前加入注意力機制模塊,而不是放在殘差塊中,并且是用ImageNet的預訓練權重字典,以充分提取局部特征,不忽略每一層特征圖在訓練時的不同作用比率。值得注意的是,注意力用在位姿估計的場景還不是很廣泛。
(3)PVNet 工作在對ResNet-18 進行fine tuning時,是將最后的1×1 之前的所有的FC 改為Conv,這么做是考慮到FC 如果過多,且形狀都不小,容易導致內存消耗嚴重。但是一些研究中表明適當的FC 設計可在模型表示能力遷移過程中充當防火墻的作用,不含FC 的網絡微調后的結果要差于含FC的網絡,事實確實如此,特別是本文的自定義數據集和原始結構使用的公用linemod 數據集的對象完全不一樣的情況下,FC 可保持較大的模型容忍度,從而保證模型表示能力的遷移,因此本文又一次強調在合適的情況下ResNet-18 的最后一層FC 設計的重要性,以及允許部分FC 存在。另外,ResNet 在很多應用場景中都占有很重要的一部分比重,但是相對于其他很多領域的數據集,所有位姿估計的數據集體量都非常地大,如何減少內存浪費是很重要的事情。
當然網絡的大部分還是值得本文借鑒的,輸入圖像大小為3,當網絡的特征圖的大小為8×8 時,不再為了提高分辨率而對特征圖進行下采樣,丟棄后續的池化層,這在一定程度上阻止了后續無意義的操作導致的消耗。
3.2 損失函數設計
為了訓練網絡,本文使用了比較穩妥的損失函數來聯合訓練包圍框位置、分割、投票、框內的姿態。形式上,損失計算包含2 部分,投票的損失計算使用Smooth損失函數, L、即交叉熵損失,可用于訓練語義標簽,實驗中使用的損失函數定義如式(4)所示:
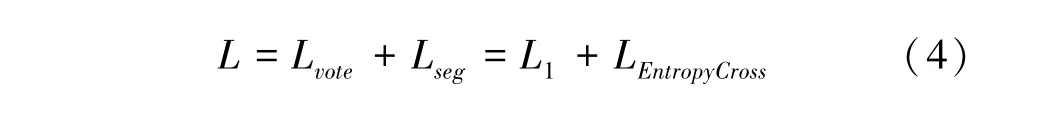
其中,Smooth是Smooth損失,是與損失的結合,L是該分類問題中的常見解決辦法。
4 實驗與分析
本文研究的對象是金屬工件,為了提高分揀抓取等操作的精確度,針對這些弱紋理工件進行6DoF位姿估計。實驗使用的數據集經過格式轉換,以適配一些算法的數據讀取接口。實驗中涉及的高性能計算的網絡訓練部分均在2080Ti 上進行。
研究可知,PVNet 中,輸入RGB 圖像,通過基于RANSAC 的投票方法給所有向量、即像素指向每個關鍵點的方向進行打分,由此得到分數高于一定閾值的關鍵點的空間分布,詳細的介紹參見文獻[2]。
本文的方法步驟也是如此,但是基于本文對數據集更改的考慮、即目標對象完全不一樣,以及新數據集中檢測對象的視點較遠的情況,對網絡進行了一些改動,使其更好地適用于本文的工作。
由于數據集中的數個初始研究對象為3D 對稱物體,本文實驗中使用了由Xiang 等人提出的ADD-s 指標,用來評估網絡輸出位姿和真實位姿轉換后的2 個模型對應點之間的平均距離,即當這個距離小于模型直徑的10%時,就認為估計出來的位姿是正確的,對于這種立體幾何形狀的對象直徑則根據模型最遠對角點的距離進行計算。為此,這里將給出剖析闡釋如下。
(1)Linemod 數據集上的性能。由于本文的方法大多集中在場景不同于BOP 等數據集的弱紋理場景進行位姿估計,而且主要是使用RGB 進行這項工作,因此本文對比了使用Depth 后的先進網絡效果、原網絡進行較大改動后的效果、以及使用本文的方法進行微調后的更好的結果,優化后的算法在Linemod數據集上的性能表現見表1。由表1 可知,相較于PVNet,增加了注意力機制后的效果有所提升。
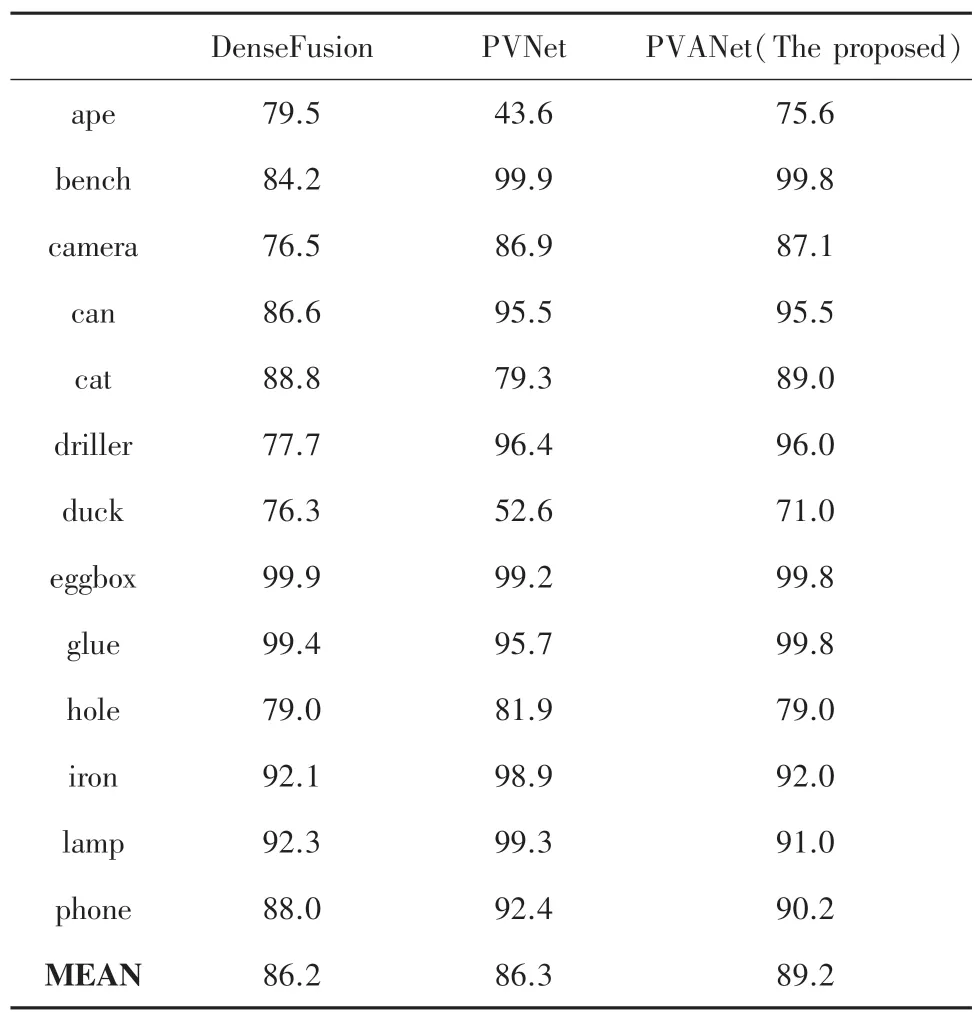
表1 和其他算法在Linemod 數據集上的表現相比較Tab.1 Comparison with the performance of other algorithms on Linemod data set
(2)真實數據集上的性能。對比網絡深度的實驗效果如圖5 所示。圖5 中,綠色框表示ground truth,藍色框表示網絡輸出結果。圖5 從(a)~(d)依次為ResNet50(工件一)、ResNet34(工件一)、ResNet-18(工件二)、ResNet-18(工件一),其中ResNet-18 為調整后的網絡,層數變動不大。仍需指出的是,圖5(a)~(d)中,左側圖為經過網絡調整后的可視化結果,右側圖為意在方便比較進行的相同比例放大。圖5 的結果表明隨著網絡的加深,效果并沒有較大的改進,但是使用較少的殘差塊,對網絡適當地剪枝,得到的效果更好。調整后的算法對比其他網絡使用本文的數據集的結果見表2。由表2 可知,本文的實驗效果更好,但是目前比較好的網絡都已經能達到這樣的效果。本文對場景中的其他數個物體也進行了相同的步驟,但是實驗結果相近就不在文中加以贅述了。

圖5 對比網絡深度的實驗效果Fig.5 Comparing the experimental effect of network depth

表2 調整后的算法對比其他網絡使用本文的數據集的ADD 結果Tab.2 The comparison of ADD results using the dataset in this paper between the adjusted network and other networks
5 結束語
由于不同的抓取場景所針對的研究對象的自身屬性、諸如金屬工件反光等因素會導致不同的位姿估計問題,本文從數據集制作、方法實現等角度探討了輸入RGB 進行位姿估計的框架,并做出一些重要的改進以便執行實際場景下的任務,如抓取、揀選等。但這些方法都是基于一定的使用條件下,并且研究可知一個正確且精確度高的對象模型對于3D目標檢測、位姿估計任務極具重要性。但是為了更好地服務于工業發展的需要,仍會有很多當模型不存在時進行精確操作的情況、如類級別位姿估計。本文雖然對常見的工件進行了探索,但是零件間不同的遮擋情況會導致零件外形在孔的位置、形狀等地方有些許的不一樣,因此后續工作可以在此基礎上進行拓展,以應對更多的特殊場景。
此外,本文在數據集上的規模上還有一些不足,一方面受制于沒有掌握合成包含符合場景的數據集制作方法,另一方面真實數據集的標注需要耗費較大的人力,因此后期在數據集的擴充上也要再做更進一步的探索。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年2期)2014-11-12 13:00:16
