基于改進注意力機制的生成對抗網絡圖像修復研究
2022-06-23 09:18:02張劍飛夏萬貴
智能計算機與應用 2022年6期
張劍飛,張 灑,夏萬貴
(黑龍江科技大學 計算機與信息工程學院,哈爾濱 150022)
0 引言
圖像修復是利用破損圖像和訓練圖像,獲取數據中的結構紋理信息,將破損圖像進行填充。近年來被廣泛地應用于諸多專業技術領域,目前已成為智能圖像處理、神經網絡和計算機視覺等方面的研究熱點。傳統圖像修復方法主要有基于紋理和基于樣本塊,經典模型有基于偏微分方程的BSCB模型、填充的Criminisi算法模型等。但這些方法大多存在缺少高級語義信息且與原圖結構相似度不高等問題。近年來,深度學習的圖像修復方法取得了許多突破性進展,Goodfollow 的上下文自動編碼器(Content Encoder,CE),首次將生成對抗網絡(Generative Adversarial Networks,GAN)應用于圖像修復,對圖像上下文語義信息做出預測,但修復的圖像存在明顯偽影。為了更好地獲取高級語義信息,在全卷積神經網絡(Fully Convolutional Network,FCN)式的特征值逐點相加的基礎上,出現了使用U-Net網絡,Yan 等人在U-Net 的解碼器中添加了一個轉移連接層、即網絡為Shift-Net,有效地結合圖像中相隔較遠的特征進行圖像修復,但當破損孔洞過大時,存在細節紋理不清晰的問題。Hu 等人提出了擠壓和激勵網絡(Squeeze-and-Excitation Network,SENet),擴大感受野,將重要的特征進行強化來提高準確率權重。
針對目前圖像修復中存在語義不連貫、紋理不清晰的現象,本文構建了一個以U-Net 為基礎模型添加轉移連接層和改進的通道注意進行精細修復的圖像修復方法,旨在獲得具有高級語義和清晰紋理的修復圖像。
1 基于改進注意力機制的生成對抗網絡圖像修復
注意力機制分為空間注意力(Spatial attention,SA)和通道注意力(Channel attention,CA),2 種注意力機制對于資源分配的級別不一樣。SA 定位感興趣區域進行變換獲取權重,而CA 則是在于分配各個卷積通道之間的資源,兩者對于不同部分均有側重,為了結合兩者優點,本文使用了空間注意力與通道注意力結合的注意力機制,空間上采用轉移連接層,改變了原本修復只能從破損圖片周圍點像素進行補全,跨越空間限制,尋找與之最相似的點。通道上采用改進的SE block,首先通過對資源分配不同比重,然后專注于圖像的待修復區域,借助于通道和空間注意力的結合,更好獲取圖像全局和局部特征。
1.1 模型框架
為了使圖像修復結果具有更好的語義表達和更精細的結構紋理,本文提出了基于改進注意力機制的生成對抗網絡兩階段圖像修復方法。網絡整體采用2 階段修復,生成器以U-Net 網絡架構為基礎,編碼器、解碼器都采用步長為2、4×4 的卷積。為充分學習圖像特征,提高編碼器中特征的利用率,在編碼階段引入多尺度卷積與通道注意力結合,進行通道特征權重的重新標定,同時為了克服長距離對于信息的依賴,將第層和第層之間通過跳躍連接后再傳遞給下一層,對圖像進行空間特征的重排,保持圖像信息的連貫性。至此得到修復粗糙圖像,同時計算重建損失函數和指導損失函數。將粗糙網絡修復的圖像和真實圖片輸入VGG16 網絡中進行特征提取分析,然后通過鑒別器DCGAN 鑒定圖像的真假,若為假,給生成器反饋重新進行圖像修復,通過設置學習率、迭代次數和損失函數來約束生成器不斷重復進行圖像學習,直至鑒別器無法確認生成器輸入圖像的真假,即完成了圖像修復過程。本文的網絡模型框架如圖1 所示。
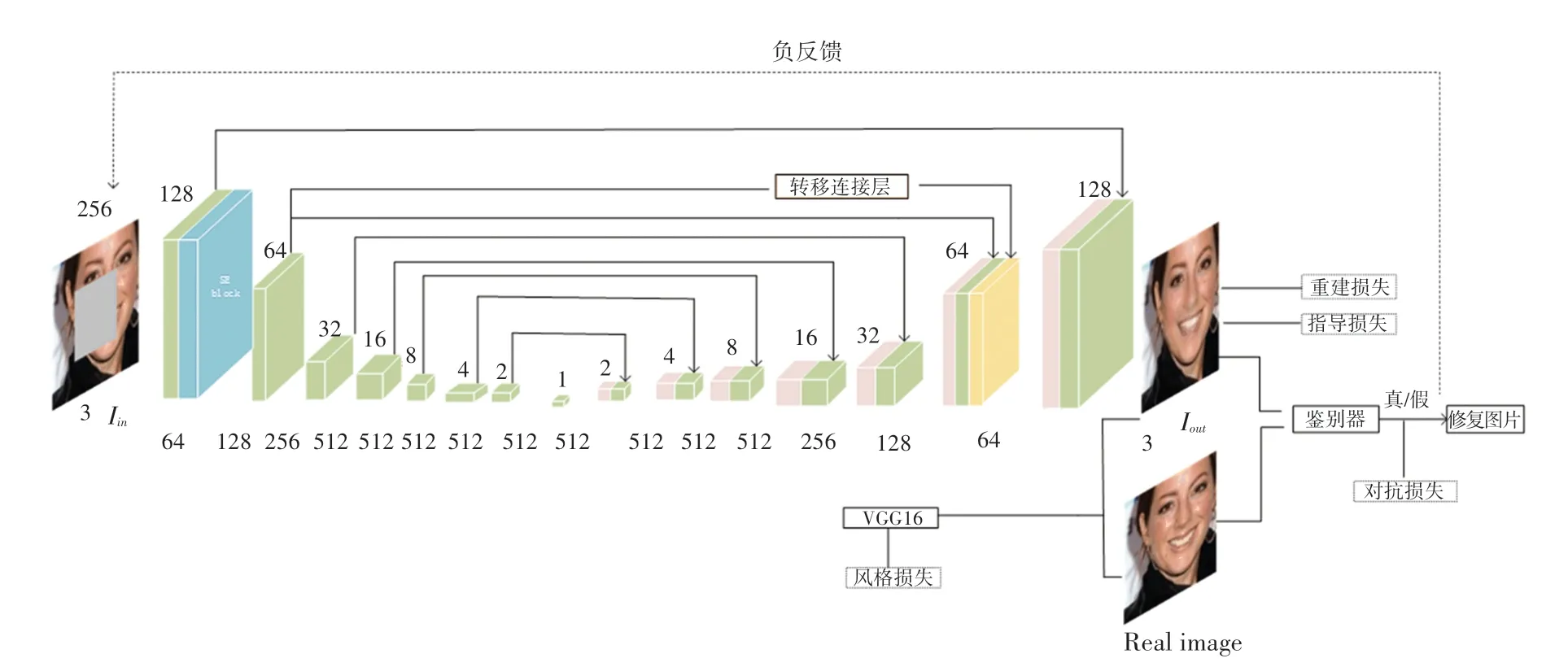
圖1 本文的網絡模型框架Fig.1 The network model framework of this paper
1.2 改進SE block 模型
為了增加在不同尺度卷積得到的特征,同時不增加參數數量,減少計算時間,所以在原來SE block的基礎上同時進行卷積和擴張卷積,用大小為3、5、7 的卷積核,但使用2 個3×3 的卷積核來模擬5×5的卷積核,用3 個3×3 的卷積核來模擬7×7 的卷積核。為了擴大感受野,增加特征圖的均衡性,采用膨脹卷積,卷積采用膨脹系數為2、步長為2、同樣用2個3×3 的膨脹卷積來模擬5×5 的膨脹卷積,2 個3×3 的膨脹卷積來模擬7×7 的膨脹卷積,對于不同尺度卷積結果級連。同時為了增加特征的全局和局部一致性,對圖像進行3×3、5×5、7×7 的卷積,這里的3×3、5×5、7×7 的膨脹卷積,通過函數分別得到不同局部之間的關系為:,,,,,。與此同時,為了得到圖像特征之間更加均衡有效的依賴關系,通過左側基礎SE block 進行通道注意力操作,并從全局池化Global Average Pooling 中得到通道特征Z,過程可以表示為:

通過上述過程得到新特征圖F,則此過程可以表示為:
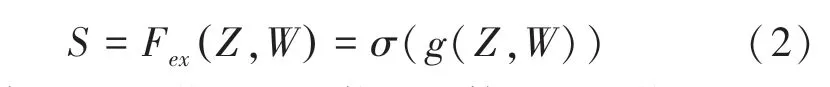
其中,(·)指激活函數,σ(·)指激活函數。與右側多尺度卷積結合得到關系,此過程可以表示為:
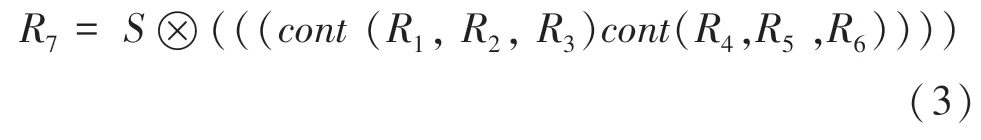
其中,“?”是張量積,(·)為合并連接。融合的特征圖進行運算,特征權重進行重新標定,最終完成了通道資源的分配,通過跳躍連接將原始圖和進行連接,則圖像可以表示為:

其中,是圖像的比例縮放運算、即,“⊕”是通道連接。至此,通過對通道上像素點的權重重新標定和不同尺度得到特征結合,完成這一階段圖像修復得到。原始的SE block 使用作為激活函數,但是當輸入值為負值時,會導致神經元不再學習,且訓練速度較慢,因此,在改進的結構中使用作為激活函數。改進SE block 的模型圖,如圖2 所示。
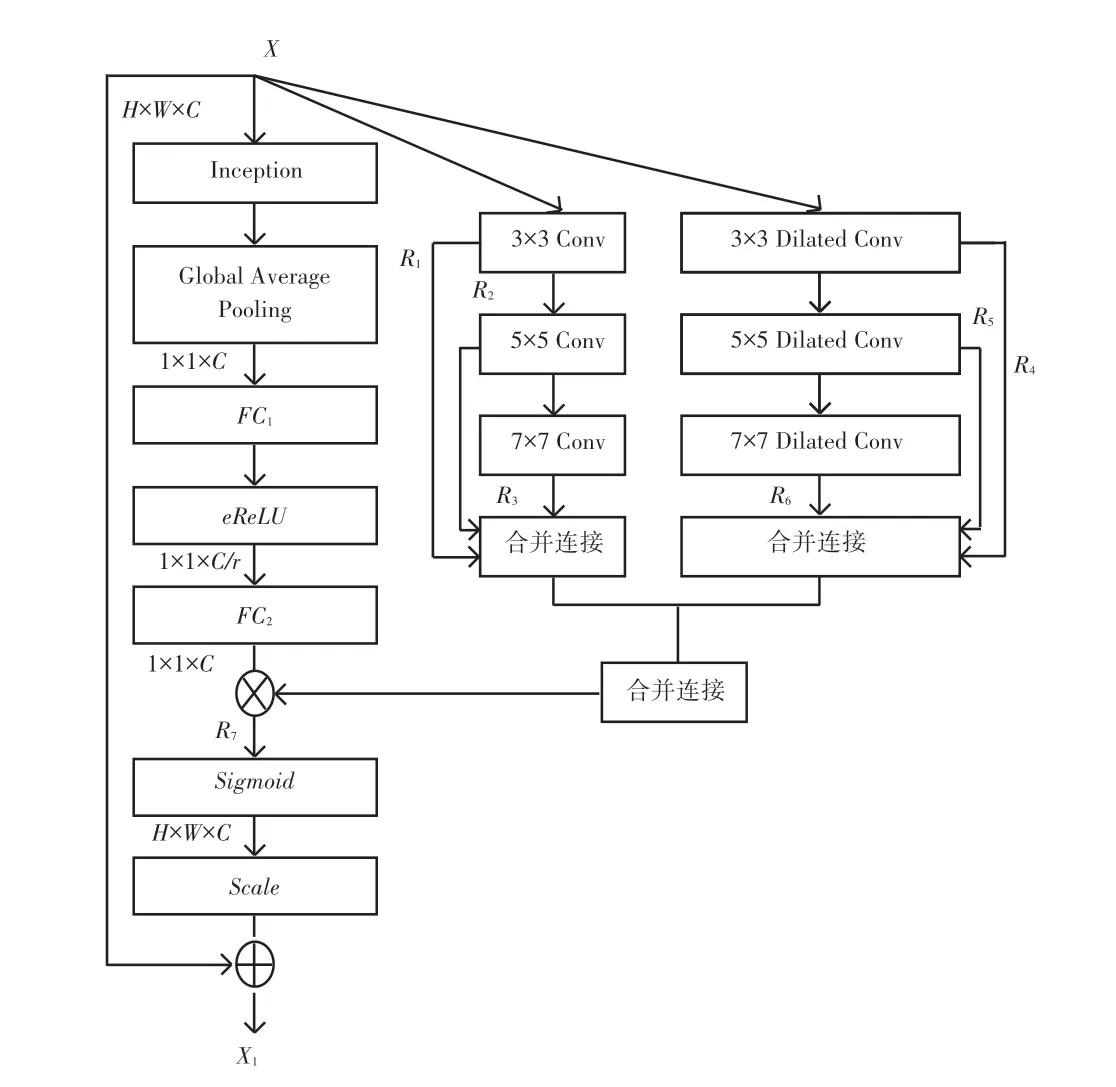
圖2 改進的SE block 模型圖Fig.2 Improved SE block model
1.3 改進損失函數
為了使修復后圖像與原圖像在風格上統一,紋理細節更清晰,在原本損失函數的基礎上加入指導損失函數和風格損失函數。圖像修復的基本損失函數有重建損失函數和對抗損失函數。這里的重建損失函數表示為:
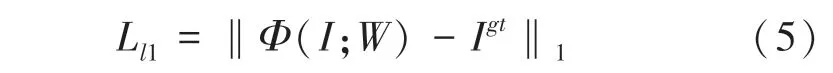
其中,是特征向量;是網絡的第層;是需要學習的模型參數;I是真實圖像。
對抗損失函數表示為:
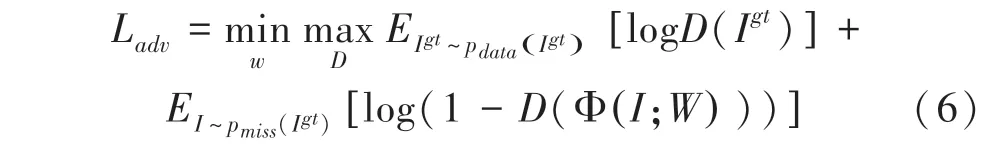
其中,是生成器;是鑒別器; I指真實圖像;是特征向量;是網絡的第層;是需要學習的模型參數;p(I)是真實圖像的分布; p(I)是破損圖像的分布。由于引入了轉移連接層,則加入指導損失函數,指導損失函數表示為:
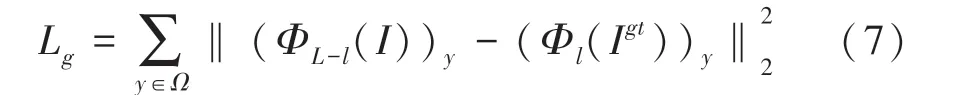
其中,是缺失區域;是圖像全部區域;Φ是層特征圖;Φ是層特征圖;是破損圖片;I是真實圖像。進行圖像訓練時需要尋找某類圖片的風格,便于圖像修復。
進一步地,研究推得的風格損失函可寫為:
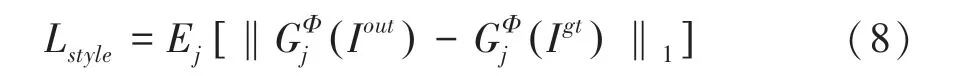

最終將多種損失函數結合起來作為整體損失函數,定義為:
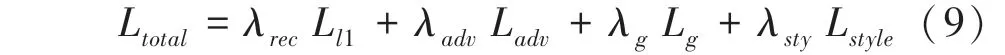
其中,1 為重構損失;L為對抗損失;L為指導損失;L為風格損失; λ,λ,λ,λ分別為各損失函數的參數;參數初始化時, λ=1,λ=0002,λ=001, λ=10。
2 實驗結果與分析
2.1 數據集及環境配置
本文采用了2 種國際標準數據集,即Celeb A人臉數據集和Places2 場景數據集。其中,Celeb A的每張人臉數據都進行了特征標注,Places2 數據集中含有400 多個場景,可以滿足對于數據多樣性的需求。本文的運行設備為:中央處理器是Intel 10th i7,顯卡是GPU GeForce GTX 1650Ti。文中的運行環境使用Pytorch+Tensflow1.4 框架,搭配Python 的多個庫進行實驗驗證與分析。
數據的預處理過程:任意尺寸的圖像輸入,經過預處理,將圖像裁剪成分辨率為256×256 的統一圖像大小。將輸入圖像分別與掩碼和隨機掩碼進行結合,模擬破損圖像。
2.2 評價指標
圖像修復處理的過程中,評價圖像修復質量有2 個指標:峰值信噪比(Peak Signal to Noise Ratio,)和結構相似性(Structural Similarity,)。其中,通常用于描述各種形式的信號的質量屬性,值越大,說明圖像信號質量越高。可由如下公式計算求得:
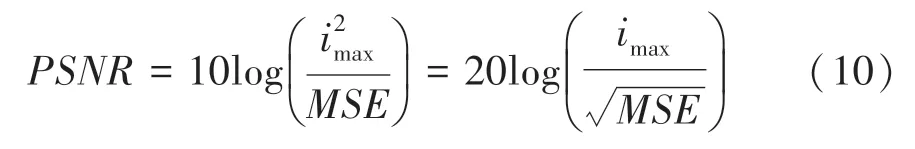
其中,指圖像點顏色的最大值,為均方差。設有2 幅的單色圖像、,這里對的數學定義可以表示為:
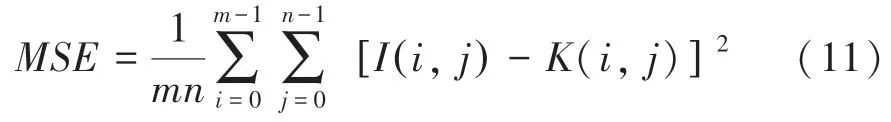
其中,(,) 是真實圖像的像素點,(,)是通過修復得到圖像的像素點。
結構相似性()是一種衡量2 幅圖像相似度的指標,主要通過亮度、對比度和結構三方面來度量圖像之間的相似性。結構相似性的范圍為[0,1],當2 幅圖像一模一樣時,的值為1,即當值越大,圖像相似性越高。研究推得的數學計算公式為:
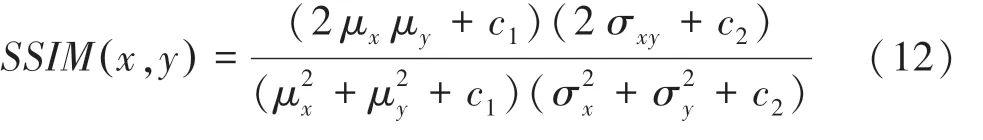
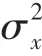
2.3 實驗結果
采用2 種不同的數據集與中心掩碼模擬受損圖像,通過對原始圖像GT、破損圖像、CE 修復圖像、Shift-Net 修復圖像和本文提出方法的修復圖像的有效性進行對比,挑選有代表性的實驗結果加以對比說明,實驗結果如圖3 所示。

圖3 實驗結果圖Fig.3 Experimental results
圖3(c)中CE 使用上下文自動編碼器的生成對抗網絡,對于大面積缺失圖像,修復結果容易出現偽影,不能產生復雜的紋理結構,對于圖像在有些地方有嚴重失真現象,如圖3(b)所示的第一幅圖像,左、右2 只眼睛瞳孔顏色不一致。觀察圖3(c)第一幅圖像發現,出現了明顯的偽影、以及鼻子的失真。觀察圖3(b)的第四幅圖像可知,有明顯的偽影以及缺少細節紋理。圖3(d)中,Shift-Net 采用了轉移連接層,通過跳躍連接,使特征圖具有良好的全局性,修復圖片看起來更加真實,但是缺少對于細節處理、過于簡單,局部有小范圍的偽影,如圖3(d)所示的第一幅圖像,鼻子處有小部分偽影。另見圖3(c)的第四幅圖像可知,整體顏色一致,但是缺少一些內容語義,處理簡單,修復部分缺少與右側對稱的窗戶。本文添加了轉移連接層和改進的通道注意力,對于特征權重重新分配,得到圖像在語義和紋理細節上優于其他2 種方法。表1 則為在2 種不同數據集中,采用中心掩碼的圖像修復,利用評價指標對結果進行定量分析。由表1 可知,本文在像素與結構上優于其他方法。

表1 采用中心掩碼不同算法的比較Tab.1 Comparison of different algorithms using center mask
3 結束語
本文以生成對抗網絡為基礎框架,對模型進行改進,生成器采用具有對稱性的U-Net,在此基礎上對于目前圖像修復中存在語義不連貫、紋理不清晰的問題,引入改進的通道注意力,采用了多尺度和更大感受野與SE-block 結合的方法,進行通道特征的調整,重定特征權重;其次添加轉移連接層,借助于U-Net 的跳躍連接確定破損區域的最相似點進行修復;最后在損失函數上增加了指導損失函數和風格損失函數,加強已知區域與破損區域之間的約束關系。通過實驗結果可知,對于語義不連貫、紋理不清晰的破損圖像,修復取得了較好的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
