基于卷積神經網絡的白細胞二分類的研究
2022-06-23 09:18:06崔兆文
智能計算機與應用 2022年6期
崔兆文,王 武
(貴州大學 電氣工程學院,貴陽 550025)
0 引言
人體外周血是人體的不可或缺的成分,血液細胞數量的檢測是評估健康狀況的一項重要的指標。血液細胞基本分為3 種,分別是紅細胞(Red Blood Cell,RBC)、白細胞(White Blood Cell,WBC)和血小板。傳統的血細胞儀耗時較長,并且會破壞血液中血細胞的形態,不便于醫生對血液細胞的形態進一步觀察。
隨著計算機水平的不斷提高,機器學習與深度學習迎來了快速的發展,特別是在圖像處理領域得到了越來越廣泛的應用。本文主要研究血液中白細胞二分類的問題,即血液中白細胞分為有粒白細胞(又稱為粒細胞)和無粒白細胞。
趙曉晴等人的研究將血液細胞色彩空間從RGB 轉到HSV,從而在HSV 圖層進行分析,同時利用基于距離的分水嶺算法對圖像進行分割。賈洪飛利用HIS 色彩空間對白細胞進行定位,同時利用深度學習網絡完成對白細胞進一步的分類。Bodzás 等人提出一種基于傳統數字圖像處理技術和機器學習算法的自動識別急性淋巴細胞白血病的方法,引入三階段過濾算法獲取最佳分割結果,應用機器學習分類器、人工神經網絡和支持向量機完成分類工作。Chen 等人將特征提取和深度學習與光子時間拉伸實現的高通量定量成像相結合,捕獲定量光學相位和強度圖像,并提取單個細胞的多種生物物理特征,這些生物物理測量形成一個多維特征空間,用于細胞分類。
本文使用改進的卷積神經網絡對人體外周血白細胞進行分類,并在卷積神經網絡的基礎上引入衰減因子,防止卷積神經網絡出現過擬合的情況,再通過粒子群算法優化衰減因子參數。數據集為Kaggle上2018 年發布的數據集。
1 理論與方法
改進卷積神經網絡方法血液白細胞圖像的總體分布框圖如圖1 所示。由圖1 可知,首先設計初始的卷積神經網絡,然后導入通過預處理的外周血白細胞圖片的數據集。在原有卷積神經網絡的基礎上引入衰減因子,防止卷積神經網絡出現過擬合的情況,同時利用粒子群算法對衰減因子的參數進行優化,找到最適合卷積神經網絡的衰減因子的參數。每一次衰減因子參數的更新都需要重新運行一次網絡。接下來,本文擬介紹卷積神經網絡(Convolutional Neural Networks,CNN)結構設計、圖像預處理、學習率衰減以及粒子群算法。

圖1 改進卷積神經網絡方法血液白細胞圖像的總體分布框圖Fig.1 General distribution block diagram of blood leukocytes images by improved convolutional neural network method
1.1 卷積神經網絡結構設計
本文研究基于卷積神經網絡的人體外周血白細胞二分類的方法。卷積神經網絡是一類含卷積計算的前饋神經網絡,是深度學習的代表算法之一,卷積神經網絡具有表征學習的能力,能夠對輸入信息進行平移不變的分類。
卷積神經網絡一般由輸入層、卷積層、池化層、全連接層和輸出層組成。其中,卷積層是實現卷積神經網絡特征提取功能的核心,相當于特征提取器。池化層能夠壓縮數據和減少提取出圖像中的特征,進而壓縮圖片。全連接層的輸入是將卷積層和池化層提取的特征進行加權,將特征空間通過非線性變換映射到樣本標記空間。
卷積神經網絡架構如圖2 所示。研究中,建立初步卷積神經網絡框架,卷積神經網絡由1 個輸入層、6 個卷積層、2 個池化層、1 個全連接層以及1 個輸出層組成。本文卷積核的大小均為3?3,步長均為1,采用“SMAE”方式,保證輸入圖片和輸出圖片大小一致。本文池化核大小為2?2,步長為2,采取最大池化的方法。文中設計的卷積神經網絡,以二分類為例,得到的每層信息見表1。由表1 可知,第一個卷積層的卷積核個數為32,第二個卷積層的卷積核個數為64,第三個卷積層的卷積核個數為128,第四個卷積層的卷積核個數為192,第五個卷積層的卷積核個數為128,全連接層神經元個數為256,輸出層神經元個數為2。
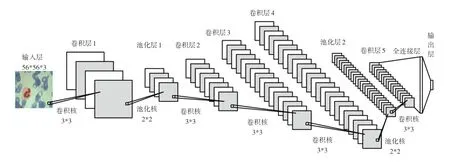
圖2 卷積神經網絡架構圖Fig.2 Architecture of convolutional neural network
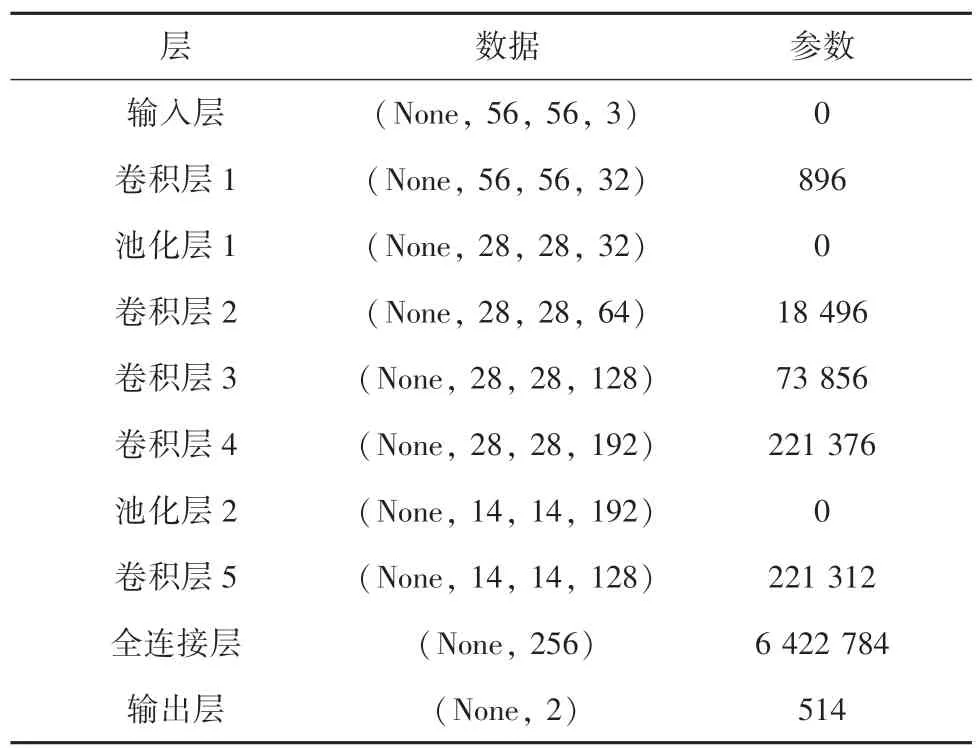
表1 二分類卷積神經網絡信息表Tab.1 Information table of binary convolutional neural network
本文選取的作為神經元在卷積層與全連接層的激活函數的數學公式可寫為:
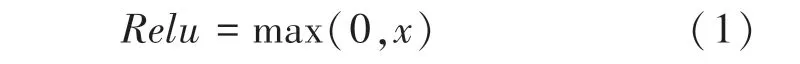
其中,max 表示取0 和中的最大值。
本文選取的作為神經元在輸出層的激活函數,可使得輸出層神經元輸出映射到(0,1)區間內,方便損失函數的建立。該激活函數的數學公式為:
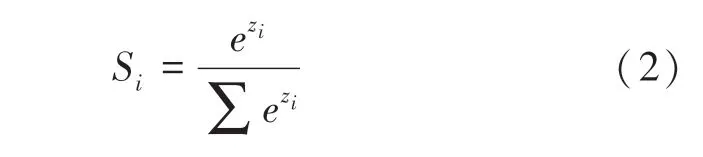
其中,z表示輸出層第激活函數的輸入。
本文選取的作為卷積神經網絡的損失函數的數學公式具體如下:
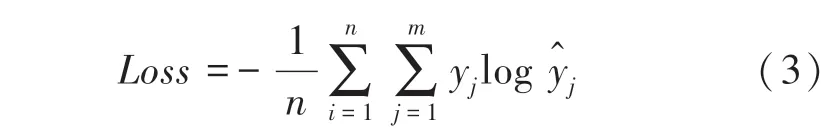
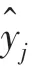
1.2 圖像預處理
數字圖像的采集是在復雜的環境中進行的,在采集與傳輸的過程中,難免會引入噪聲,為了能夠對血液圖像做到更好的識別,即需對原始血液圖像進行處理。所以首先需要進行圖像濾波。圖像濾波的方式主要有2 種:線性濾波和非線性濾波。其中,線性濾波的方式、比如均值濾波,對高斯噪聲有較好的抑制作用,但是并不能較好地保護圖像的細節信息,導致圖片變得模糊。非線性濾波、比如中值濾波,能夠較好地保護圖像的細節信息,保持圖片的清晰度。本文選用的是中值濾波。
在中值濾波后,需要對圖片的尺寸進行處理,原圖像是640?480?3 像素,本文將圖片壓縮成56?56?3 像素的圖片,方便計算機處理與識別。
1.3 學習率衰減
在卷積神經網絡學習的過程中,隨著訓練的進行、學習率將逐漸衰減,這樣有利于卷積神經網絡學習模型的建立。在訓練過程開始時,使用較大的學習率值,可以使結果快速收斂,隨著訓練的進行,逐步降低學習率和收斂的速度,有助于找到最優結果。目前,比較常用的2 種學習率衰減方法:線性衰減和指數衰減。本文采用的是指數衰減的方式。指數衰減的數學定義的公式表述為:
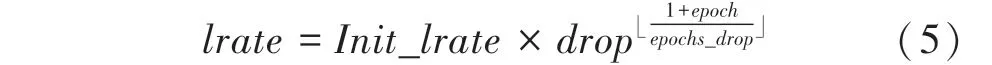
其中,表示當前學習率;_表示初始學習率;表示衰減指數;表示當前迭代次數;_表示調整系數;?」 表示對符號內的數值向下取整。
利用這種衰減方式進行學習率的更新,可以使得學習率的更新速度較慢,容易建立識別率較高的深度學習模型。
1.4 粒子群算法
粒子群算法(Particle Swarm Optimization,PSO),從隨機解出發,并利用迭代尋找最優解,通過適應度來評定解的品質。這種算法具有實現容易、精度高、收斂快等優點。
在維空間中,設有個粒子,粒子的位置為x=(x,x,x,…,x),將x代入適應函數(x)可以求取函數值;粒子的速度為v=(v,v,v,…,v),粒子個體經過的最佳位置:pbest=(p,p,p,…,p),種群所經歷的最佳位置gbest=(,,,…,g),通常迭代中粒子的速度和位置應該被限制,即在第(1 ≤≤)維的位置變化范圍限定 在 [,]內,速度變化范圍限定在[,]內,粒子在第維的速度更新公式見如下:
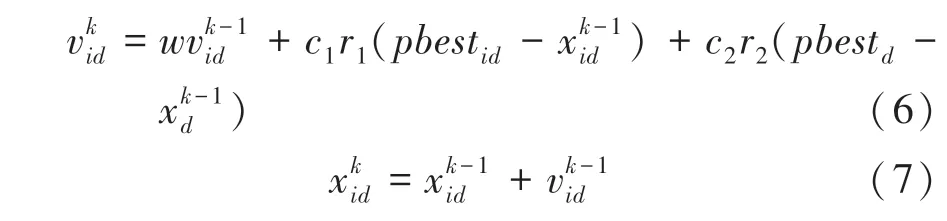
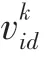
由以上公式推知,粒子速度的更新與粒子先前的速度有關,粒子當前位置與粒子最佳位置的偏差以及粒子當前位置與種群最佳位置的偏差有關。
粒子群算法優化流程如圖3 所示。由圖3 可知,首先對粒子群進行初始化,包括群體的規模大小、粒子的隨機位置以及粒子的初始速度。根據適應度評價函數,確定每個粒子的適應度,每個粒子將其當前適應度與歷史最佳適應度做比較,如果當前適應值比歷史最佳適應值更高,更新當前位置為粒子歷史最佳位置;同樣地,將粒子當前位置與種群最佳位置進行比較,如果當前適應度高,更新當前位置為粒子歷史最佳位置。根據式(6)和式(7)更新粒子的速度與位置。繼續根據適應度評價函數來判斷,確定更新后的參數。繼續反復進行參數的更新,直到滿足條件或達到最大迭代次數。
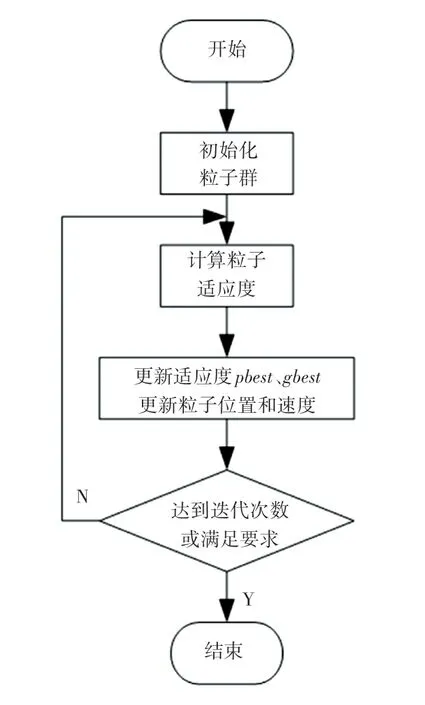
圖3 粒子群算法優化流程圖Fig.3 Flow chart of Particle Swarm Optimization algorithm
本文主要是使用粒子群算法對衰減因子中的_、和_參數進行優化。同時,本文選取的粒子群優化算法的適應度函數可寫為如下形式:
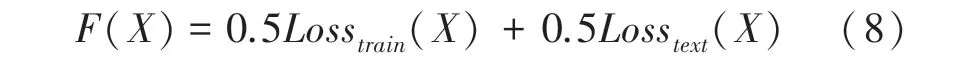
其中,()表示適應度函數;Loss()表示訓練數據的損失函數; Loss()表示測試數據的損失函數;表示衰減因子(_,,_)三個參數的集合變量。
為了減少神經網絡每次初始參數不一致帶來的偏差,取同一參數下3 次神經網絡的損失函數的平均值作為某一粒子的適應度函數。同時,當粒子參數一致時,能夠直接獲取其適應函數,不需要進行復雜的計算就能得到其適應度函數。
2 實驗數據與結果分析
圖像處理與分析實驗的結果是基于Tensorflow的Kears 深度學習框架下進行的,操作系統是Windows10,編程語言為Python,使用的編譯軟件是Pycharm 與Spyder。硬件配置的處理器為Intel(R)Core(TM)i5-9400F CPU,運行內存為16 G,顯卡型號為NVIDIA GeForce GTX 1650。
2.1 實驗數據
數據集為Kaggle 上發布的數據集,數據集中原始圖片共計400 張,數據集發布者通過數據增強手段將400 張原始圖片拓展成12444 張圖片。在原始數據中,無粒白細胞圖片為54 張,有粒白細胞圖片為346 張,無粒白細胞與有粒白細胞數據相差較大,這是上文中提到的要改進損失函數的原因。發布拓展后的圖片訓練集與測試集,訓練數據圖片9957 張,測試數據圖片2487 張。在訓練集中,無粒白細胞圖片為4961 張,有粒白細胞圖片為4996 張;在測試集中,無粒白細胞圖片為1240 張,有粒白細胞圖片為1247 張。血液細胞的示意如圖5 所示。
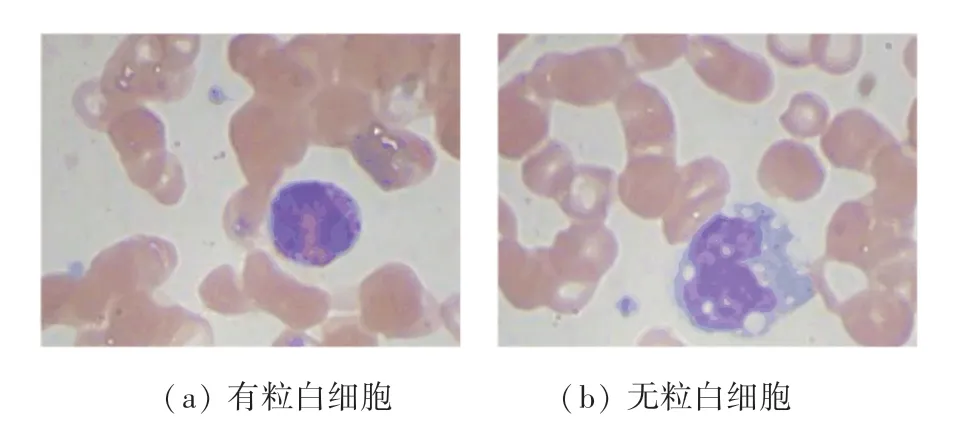
圖4 血液細胞原始圖片Fig.4 Original picture of blood cells
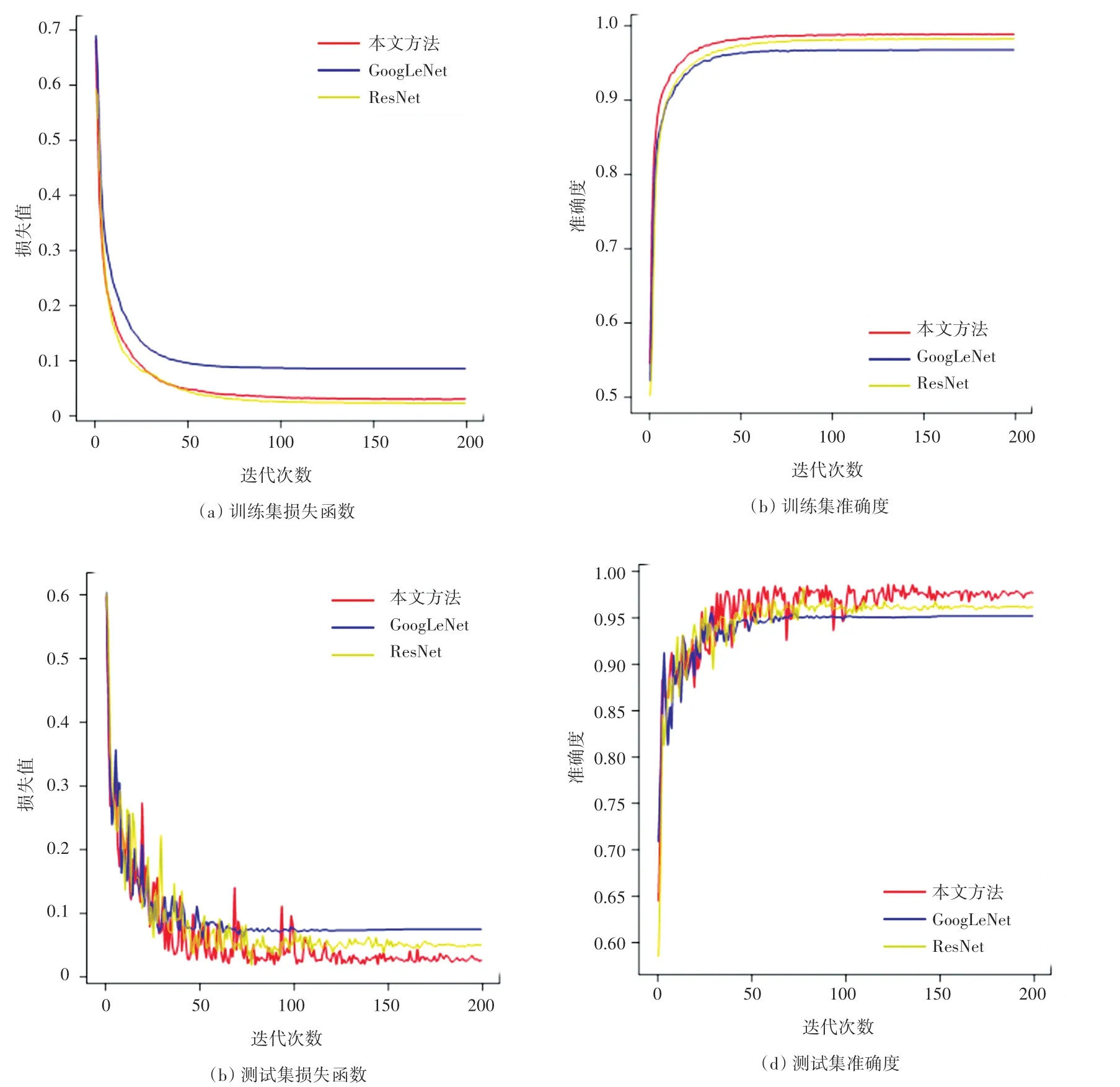
圖5 不同模型下的損失函數和準確度Fig.5 Loss function and accuracy under different models
2.2 模型對比
本文做了3 種網絡模型的對比實驗,分別是:本文提出的網絡、GoogLeNet 網絡和ResNet 網絡。實驗對比結果如圖6 所示。由圖6 可知,本文的算法相較于GoogLeNet 網絡無論在損失、還是在準確度上都有著較為明顯的提升,和ResNet 網絡在訓練集的運行效果上相差不大。在測試集上,本文提出的網絡優于ResNet 網絡。結果說明本文提出的網絡無論在訓練集、還是測試集均有著較好的效果,即本文模型要優于GoogLeNet 網絡和ResNet 網絡。
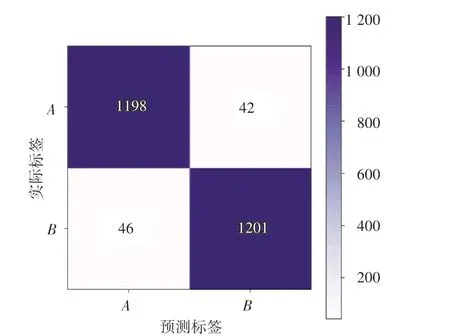
圖6 卷積神經網絡模型混淆矩陣Fig.6 Convolutional neural network model confusion matrix
本文建立的模型混淆矩陣如圖7 所示。圖7中,‘A’表示無粒白細胞,‘B’表示有粒白細胞。由圖7 分析可知,(,)=1198 表示血液圖片中實際標簽與預測標簽均為無粒白細胞有1198 個,識別正確;(,)=1201 表示血液圖片中實際標簽與預測標簽均為有粒白細胞有1201 個,識別正確;(,)=42 表示實際標簽為有粒白細胞、但識別標簽為無粒白細胞有42 個,識別錯誤;(,)=46 表示實際標簽為無粒白細胞、但識別標簽為有粒白細胞有46 個,識別錯誤。卷積神經網絡模型對無粒白細胞識別率為96.61%,對有粒白細胞識別率為96.56%,識別效果基本一致。
3 結束語
外周血白細胞檢測作為一項醫院的常規檢查,對于許多疾病的診療判斷有著重要的作用。實驗結果表明,改進的神經網絡對血液細胞有較好的識別效果。本文研究基于卷積神經網絡框架完成血液白細胞二分類算法的設計,白細胞二分類準確度在96.46%,基本能夠滿足白細胞分類識別的要求。能夠有效地減少相關醫師的工作量,提高工作質量。但是眾所周知,通常對醫療圖像分類的準確率都有較高要求,繼續提高模型的準確率是一個值得長期研究的問題。本文僅研究了外周血白細胞的二分類卷積神經網絡模型的搭建,對疾病的檢測有一定的幫助,未來可以探索外周血白細胞五分類,以及異常白細胞識別的研究。
