基于YOLOv5和DeepSort的視頻行人識別與跟蹤探究
2022-06-20 05:12:29張夢華
現代信息科技 2022年1期
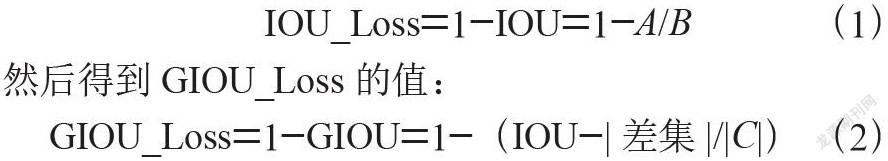



摘? 要:視頻監控在信息化時代尤其是交通系統中占據重要地位,文章提出一種基于Yolov5和DeepSort在可見光環境下將行人識別和行人跟蹤兩大模塊相結合的多目標跨鏡頭跟蹤算法。首先使用Yolov5算法通過保存視頻號、行人序號和位置信息給視頻中行人賦予標簽,得到視頻中所有行人的信息;然后根據信息用DeepSort實現行人跟蹤。經過測試和訓練可以快速準確地完成任務,有一定的理論探索意義和實用價值。
關鍵詞:Yolov5;DeepSort;行人識別;行人跟蹤
中圖分類號:TP391.4? ? ? ? ? ?文獻標識碼:A文章編號:2096-4706(2022)01-0089-04
Abstract: Video surveillance plays an important role in the informatization age, especially in traffic system. This paper proposes a multi-target cross-shot tracking algorithm, which combines two modules of pedestrian recognition and pedestrian tracking in the visible light environment based on Yolov5 and DeepSort. Firstly, Yolov5 algorithm is used to label the pedestrian in the video by saving the video number, pedestrian serial number and location information, and obtain the information of all pedestrians in the video. Then, according to the information, DeepSort is used to achieve pedestrian tracking. After testing and training, it can complete the task quickly and accurately, which has a certain theoretical exploration significance and practical value.
Keywords: Yolov5; DeepSort; pedestrian recognition; pedestrian tracking
0? 引? 言
計算機視覺中的目標檢測是較早開始的研究方向,在智能視頻監控、工業檢測、航空航天等諸多領域上經過幾十年的不斷探索后取得了顯著的發展。其中智能視頻監控中的行人檢測是通過計算機視覺中的方法來獲取圖像或視頻中行人的位置。由于行人剛柔兩方面的特性 ,穿戴、比例、遮掩物、行為等都會影響檢測的準確性,因此研究行人檢測變成計算機視覺領域中富有挑戰價值的熱門課題[1]。
傳統的方法是基于圖像上的行人識別和跟蹤,只包含空間特征,缺少時序信息,在復雜條件下的精度不高;而在視頻序列中兩者都包含進去,因此在視頻行人識別的研究中有重要意義。
隨著大規模視頻數據集的出現,研究者設計了多種模型來實現行人識別與行人跟蹤。對于行人識別的實現,文獻[2]運用背景差法把當前圖像與背景圖像做差判斷像素,根據建模獲得的近似圖像判斷跟蹤效果。文獻[3]運用幀差法將鄰近的兩幅圖像做差,二值化后獲得目標,因為對噪聲的敏感性導致獲取的目標不完整。文獻[4]運用光流法對光流場進行檢測分割,可以輕易地檢測到目標和獲取背景圖像,計算量較大。對于行人跟蹤的實現,文獻[5]運用基于特征的跟蹤方法在原始圖像中提取最明顯的特征。SIFT算法、KLT算法、Harris算法和SURF算法都有很好的魯棒性,是典型算法[6-9]。文獻[10]運用基于貝葉斯的跟蹤方法將行人跟蹤轉為貝葉斯估計。Kalman濾波(KF)[11]可以精準的預測行人下一個時間點的位置,是目前已成熟的方法。
根據已經提出的方法進行改進,本文提出基于Yolov5和DeepSort的視頻行人識別與跟蹤,在可見光的環境下實現多目標跨鏡頭識別與跟蹤,有較高的準確性和實時性。
1? Yolov5實現行人識別
Yolov5是Yolov4工程化的版本,它有更好的靈活性和更快的速度,在模型的快速部署上具有極強優勢。相比Yolov4,該算法有以下優點:
(1)數據增強,通過隨機選取訓練集中四張圖片的中心點,在其四角位置分別放置一張圖片,可以增加batch size。
(2)DropBlock機制。通過Dropout防止過擬合,通過DropBlock隨機去除神經元。標簽平滑,使神經網絡減弱。
(3)損失函數:使用CIoU進行邊框回歸;使用BCEWithLogitsLoss和CIoU進行Objectness;使用BCEWithLogitsLoss進行分類損失。
Yolov5算法中的四種網絡結構Yolov5s、Yolov5m、Yolov5l和Yolov5x在原理和內容上基本一樣,但在寬度和深度上不同。網絡深度通過depth_multiple參數控制,網絡寬度通過width_multiple參數控制。CSP1和CSP2是Yolov5的兩種CSP結構,Backbone主干網絡儲存CSP1,Neck網絡儲存CSP2,四種網絡中每個CSP結構的深度都不相同,且隨著網絡層數的加深網絡的特征提取和融合能力也不斷升高。網絡寬度中特征圖第三維度受卷積核數影響,核數越多,特征圖越寬,網絡提取特征能力越強。各部分具有的主要功能結構為:
輸入端:Mosaic數據增強、自適應錨框計算,以及自適應圖片縮放。
主干網絡:Focus結構、CSP結構。
Neck網絡:FPN+PAN結構。
輸出端:GIOU_Loss。
1.1? 輸入端
1.1.1? Mosaic數據增強
在輸入端選擇Mosaic數據增強方式,首先可以增加數據集的復雜度,其次可以減少GPU 的內存使用。數據集的復雜性體現在對多張圖片進行隨機裁剪縮放,提高訓練后的精度。由于訓練的圖片數量不需要設置的非常大,因此可以減少GPU的內存使用。
1.1.2? 自適應錨框計算
在Yolov5算法中,所有視頻中的行人都使用默認的標簽框距,訓練時會在此基礎上輸出一個預測框,方便將初始框與預測框對比計算差值。
1.1.3? 自適應圖片縮放
對于數據集中一幀一幀的圖片尺寸不同的現象,都會在初始時設置固定的尺寸,在處理完成后可以對其進行縮放裁剪,提高精度。
1.2? 主干網絡
1.2.1? Focus結構
在提取視頻行人特征的過程中,方便對其進行切片處理,對不同層的特征圖有不同的切片選擇,最終卷積后形成特征圖。
1.2.2 CSP結構
在視頻行人識別中使用CSP結構,可以使網絡模型輕量化,便于數據集的訓練,減少了GPU內存的使用,還降低了計算的時間,使效率提高。
1.3? Neck網絡
首先使用自頂向下的FPN層可以使語義特征順利傳達下去,通過PAN結構可以有效定位特征,使每一個主干層中的檢測層完成參數聚合。
1.4? 輸出端
輸出端中的損失函數由分類損失函數(Classificition Loss)和回歸損失函數(Bounding Box Regeression Loss)組成。
由初始框與預測框對比,A為交集,B為并集,C為最小外接集合,可以計算差值得到IOU的Loss:
然后得到GIOU_Loss的值:
2? DeepSort實現行人跟蹤
DeepSort是在Sort目標跟蹤基礎上進行的改進。其優點為:
(1)增加Deep Association Metric:可以實現行人檢測,是在學習卡爾曼濾波和匈牙利算法的基礎上改進的。
(2)添加外觀信息:通過卡爾曼濾波算法和匈牙利算法對行人進行識別和目標分配,添加外觀信息對行人跟蹤有更好的效果。
由于存在多目標跟蹤中一個目標覆蓋多個目標或多個檢測器檢測一個目標的情況,DeepSort算法使用八維狀態空間(u,v,γ,h,x,y,γ,h)定義跟蹤場景。根據算法可知馬氏距離計算公式為:
在設置運動狀態關聯成功后,可以得到示性函數為:
由此類推可以得到d(2)(i,j)和bi,j(2),最終得到2種度量方式線性加權的度量:
當Ci,j位于2種度量閾值交集內,則認為實現了正確的關聯。
為了實現行人跟蹤,使用神經網絡對視頻行人識別數據集訓練。通過DeepSort算法,在行人特征提取后得到一幀一幀的圖像,完成對行人的跟蹤。此方法可以有效改善遮擋問題。
3? 實驗結果及分析
為了驗證Yolov5和DeepSort對視頻中行人識別和跟蹤的效果,本文選取了一段交通環境下的行人視頻,該視頻在AMD Ryzen 5 4600U with Radeon Graphics 2.10 GHz處理器、16 GB內存、Windows 10操作系統的電腦上完成。
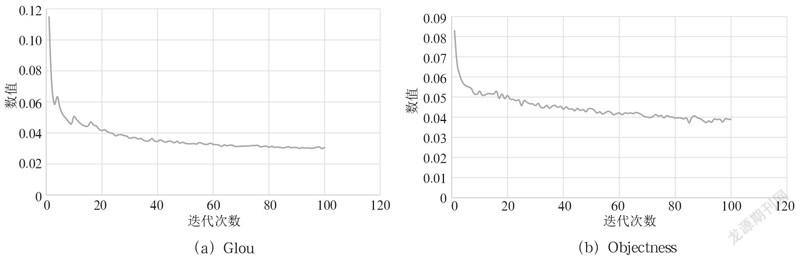
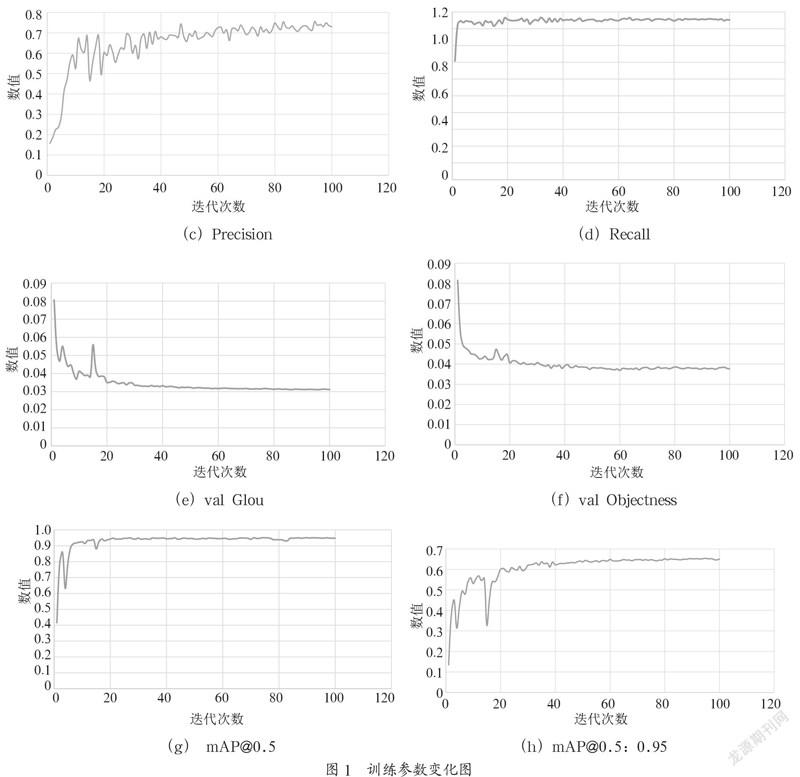
訓練過程的各種數值隨著迭代次數的增加而變化,本次實驗迭代次數100次,各種數值的變化如圖1所示。
GIoU和val Glou:數值越接近0,目標框畫的越準確。
Objectness和val Objectness:數值越接近0,對行人識別得越準確。
Precision:準確率(標記的正確個數除以標記的總個數)越接近1越高。
Recall:召回率(標記的正確個數除以需要標記的總個數)越接近1越高。
mAP@0.5 和mAP@0.5:0.95:AP (以Precision和Recall為坐標軸作圖圍成的面積)越接近1,準確率越高。
從圖1可以看出,訓練迭代次數越接近100,各項數值變化越趨于平穩。
為了驗證視頻中行人的識別與跟蹤效果,這里隨機截取了幾幀行人圖片,如圖2所示。
從圖中可以看到,本次截取了第80幀,第97幀和第115幀的圖片,可以清楚地看到視頻中序號為10,20,23和33的行人被label標簽準確的框起來,并且實現了對序號為10的行人和序號為20的行人的跟蹤,從圖2中可以準確地看到運動軌跡。使用Yolov5算法保存視頻號、行人序號和位置信息給視頻中行人賦予了標簽,得到了視頻中所有行人的信息,實現行人識別。然后根據行人特征信息用DeepSort算法實現了行人跟蹤。經過測試和訓練后快速準確的完成了行人識別與跟蹤任務。
4? 結? 論
由于Yolov5在目標檢測上有更好的靈活性和更快的速度,DeepSort在目標跟蹤過程中可以改善有遮擋情況下的目標追蹤效果,減少了目標ID跳變的問題,本文將兩者相結合,實現視頻行人識別與跟蹤。實驗結果表明,結合后的Yolov5和DeepSort可以快速有效地實現行人識別與跟蹤。但是,在行人有重疊或被遮擋的情況下不能準確的識別出來,還需進一步的改進。
參考文獻:
[1] 宋艷艷,譚勵,馬子豪,等.改進YOLOV3算法的視頻目標檢測 [J].計算機科學與探索,2021,15(1):163-172.
[2] 張詠,李太君,李枚芳.利用改進的背景差法進行運動目標檢測 [J].現代電子技術,2012,35(8):74-77.
[3] 楊陽,唐慧明.基于視頻的行人車輛檢測與分類 [J].計算機工程,2014,40(11):135-138.
[4] SUN S J,HAYNOR D,KIM Y M. Motion estimation based on optical flow with adaptive gradients [C]//Proceedings 2000 International Conference on Image Processing (Cat. No.00CH37101).Vancouver:IEEE,2002:852-855.
[5] 王亮,胡衛明,譚鐵牛.人運動的視覺分析綜述 [J].計算機學報,2002(3):225-237.
[6] 侯躍恩,李偉光.時間連續貝葉斯分類目標跟蹤算法 [J].計算機工程與設計,2016,37(8):2125-2131.
[7] DAVID G L. Distinctive Image Features from Scale-Invariant Keypoints [J].International Journal of Computer Vision,2004,60(2):91-110.
[8] 楊陳晨,顧國華,錢惟賢,等.基于Harris角點的KLT跟蹤紅外圖像配準的硬件實現 [J].紅外技術,2013,35(10):632-637.
[9] HARRIS C,STEPHENS M. A Combined Corner and Edge Detector [C]//Proceedings of the 4th Alvey Vision Conference. Manchester:Alvety Vision Club,1988:147-151.
[10] KASHIF M,DESERNO T M,HAAK D. Feature description with SIFT,SURF,BRIEF,BRISK,or FREAK? A general question answered for bone age assessment [J].Computers in Biology and Medicine,2016,68(C):67-75.
[11] 梁錫寧,楊剛,余學才,等.一種動態模板匹配的卡爾曼濾波跟蹤方法 [J].光電工程,2010,37(10):29-33.
作者簡介:張夢華(1996—),女,漢族,山西臨汾人,碩士在讀,研究方向:計算機視覺。
