基于CRNN 和EnCTC 的英文手寫體識別研究*
2022-06-16 12:46:02朱世聞
計算機(jī)與數(shù)字工程 2022年5期
關(guān)鍵詞:模型
朱世聞
(南京郵電大學(xué)自動化、人工智能學(xué)院 南京 210000)
1 引言
目前離線手寫體識別是OCR 領(lǐng)域的研究熱點與難點,現(xiàn)在無紙化辦公成為了社會發(fā)展的主流,比如票據(jù)識別[1],試卷自動批閱等,隨著深度神經(jīng)網(wǎng)絡(luò)的不斷發(fā)展,印刷體字符在自然場景中識別已經(jīng)能夠準(zhǔn)確地識別出來[2~3]。由于每個人之間的書寫風(fēng)格存在差異,手寫字符存在著文字的重疊、扭曲、粘連以及斷開,這些導(dǎo)致了手寫體字符識別率相對較低。
手寫識別模型大多數(shù)的識別方法是利用CNN網(wǎng)絡(luò)強(qiáng)大的非線性映射能力和特征表達(dá)能力,一般作為底層網(wǎng)絡(luò)來對手寫圖像特征提取,然后利用不同的循環(huán)層和轉(zhuǎn)錄方法來完成對手寫體的識別。Bhagyasree P V[4]等使用一個DAG 模型與CNN 混合神經(jīng)網(wǎng)絡(luò)來訓(xùn)練,將每一層的卷積的輸出都輸送到softmax 層,參與分類決策,這樣就能夠保證更多的原圖片的決策信息。Sun[5]等使用全卷積網(wǎng)絡(luò)(FCNN)進(jìn)行圖像特征提取,使用多維LSTM 作為遞歸網(wǎng)絡(luò)單元,取得了不錯提升效果。Chen[6]等使用能夠同時進(jìn)行腳本識別和手寫體識別的多任務(wù)網(wǎng)絡(luò),它們使用LSTM 單元的變體SepMDLSTM 來作為遞歸網(wǎng)絡(luò)。Sueiras[7]等通過CNN 提取圖像特征后,利用BILSTM 網(wǎng)絡(luò)進(jìn)行編解碼,最后以Attention 作為轉(zhuǎn)錄層。王鑫悅[8]等利用BILSTM 作為編碼器,LSTM 作為解碼器,在中間加入了Attention機(jī)制的結(jié)構(gòu)來對中文手寫進(jìn)行識別。石鑫等[8]利用多層LSTM 形成堆棧式結(jié)構(gòu)和CTC 轉(zhuǎn)錄層來對中文手寫體進(jìn)行識別,識別率也得到了提高。大部分學(xué)者在CNN或RNN的網(wǎng)絡(luò)結(jié)構(gòu)下在各自的手寫數(shù)據(jù)集上都取得不錯的效果[9~12]。還有不少學(xué)者在此基礎(chǔ)上通過數(shù)據(jù)增強(qiáng)的方法來提高識別率[13~14]。
本文將手寫體字符進(jìn)行整體識別,避免了字符的分割,利用CRNN[3]的網(wǎng)絡(luò)結(jié)構(gòu),它結(jié)合CNN 網(wǎng)絡(luò)和RNN 網(wǎng)絡(luò)各自的特性,在轉(zhuǎn)錄層使用了EnCTC[15]損失函數(shù)。同時也對圖像數(shù)據(jù)進(jìn)行增強(qiáng),有助于神經(jīng)網(wǎng)絡(luò)更好地學(xué)習(xí)特定于手寫圖像的不變性,本文還使用合成數(shù)據(jù)集對神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)訓(xùn)練,有效地提高了識別精度,來提高模型的泛化能力。
2 模型設(shè)計
單詞識別是將圖像中的文本內(nèi)容變成機(jī)器可理解的文本問題,本文采用CRNN的基礎(chǔ)結(jié)構(gòu)框架,但CNN 網(wǎng)絡(luò)之前,插入空間轉(zhuǎn)換網(wǎng)絡(luò)層(STN)[16],之后接著卷積神經(jīng)網(wǎng)絡(luò)(CNN),在之后接著一個堆棧式的雙向長短記憶網(wǎng)絡(luò)(BiLSTM),最后以轉(zhuǎn)錄層結(jié)束,結(jié)構(gòu)圖如圖1所示。
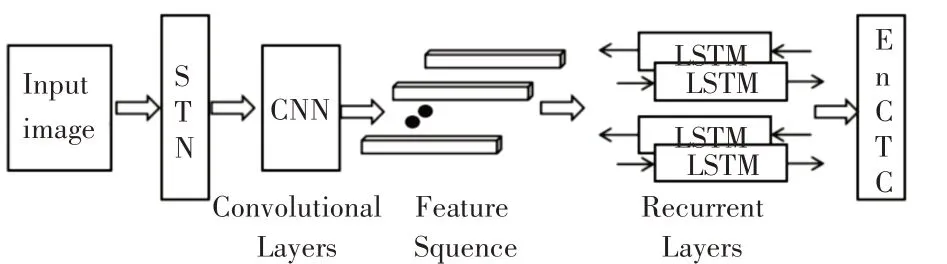
圖1 整體模型網(wǎng)絡(luò)結(jié)構(gòu)
2.1 空間網(wǎng)絡(luò)層(STN)
STN 網(wǎng)絡(luò)是一個端到端的可訓(xùn)練層,它對輸入端進(jìn)行幾何變換,從而矯正手寫體因為手的移動而造成的字形的扭曲,從而彌補(bǔ)了CNN 網(wǎng)絡(luò)容易受到數(shù)據(jù)空間多樣性中的影響,該網(wǎng)絡(luò)不要圖像中關(guān)鍵的標(biāo)定,能夠根據(jù)訓(xùn)練過程中分類的結(jié)果自適應(yīng)地將數(shù)據(jù)進(jìn)行空間的轉(zhuǎn)換和對齊,包括平移、縮放、薄板插條變換等幾何變換,同時STN可以插入到卷積層任意一層,幫助CNN 能夠更好地學(xué)習(xí)到圖像的特征。
2.2 卷積神經(jīng)網(wǎng)絡(luò)層(CNN)
本文采用的卷積神經(jīng)網(wǎng)絡(luò)是VGG16[17]的深度神經(jīng)網(wǎng)絡(luò),包括13個卷積層,13個激活函數(shù)層,4個最大池化層,去除了網(wǎng)絡(luò)中的3 個全連接層,利用神經(jīng)網(wǎng)絡(luò)中的卷積層和池化對手寫單詞圖像進(jìn)行特征提取,形成特征序列輸入到BiLSTM 中進(jìn)行序列特征提取。激活函數(shù)采用的是Mish[18]激活函數(shù),該激活函數(shù)相對于之前常用的RELU 激活函數(shù)能夠?qū)ω?fù)值能夠輕微的允許,使神經(jīng)元學(xué)到更多的特征內(nèi)容,也具有平滑的特性,平滑的激活函數(shù)能夠使神經(jīng)網(wǎng)絡(luò)學(xué)到的特征信息更加深入,從而得到更好的準(zhǔn)確性與泛化能力。Mish 激活函數(shù)曲線如圖2所示。
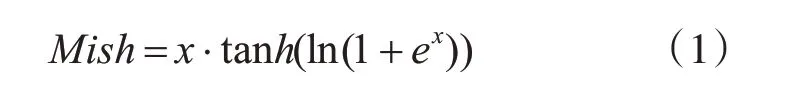
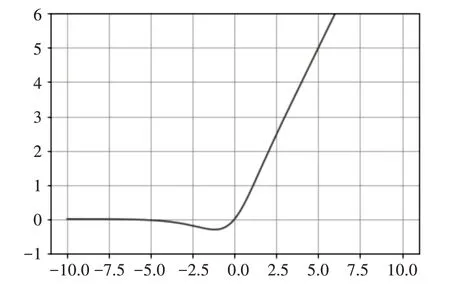
圖2 Mish激活函數(shù)曲線圖
2.3 循環(huán)層(BiLSTM)
本文采用的RNN 結(jié)構(gòu)為雙向長短記憶網(wǎng)絡(luò)(BiLSTM),RNN 結(jié)構(gòu)能夠更好地獲取單詞內(nèi)容的上下文本信息,從而提高識別率,長短記憶網(wǎng)絡(luò)能夠很好地解決RNN 本身存在梯度消失的問題。LSTM 由輸入門it,遺忘門ft和輸出門ot三個門控單元以及記憶單元組成,記憶單元負(fù)責(zé)儲存過去的上下文信息,遺忘門負(fù)責(zé)選擇丟棄記憶單元的上下文信息,讀取當(dāng)前細(xì)胞的輸入值xt,和上層輸出狀態(tài)ht-1,當(dāng)前輸出ht計算出輸入門it,輸出門ft,和遺忘門ot的值:
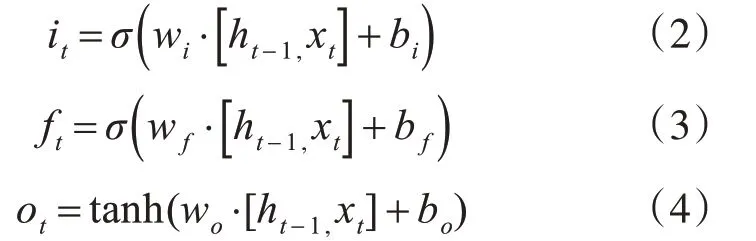
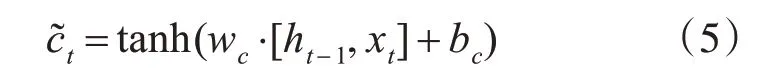
最后LSTM 的輸出ht為輸出門狀態(tài)值乘以激活函數(shù)激活后的上下文狀態(tài)ct:
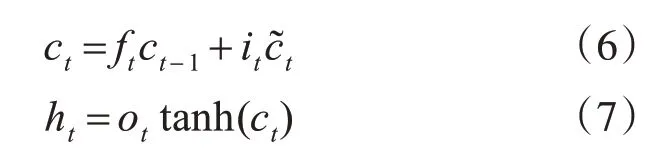
LSTM網(wǎng)絡(luò)是單向的,LSTM都只能依據(jù)之前時刻的時序信息來預(yù)測下一時刻的輸出,但在英文單詞識別任務(wù)中,當(dāng)前時刻的輸出不僅與之前的狀態(tài)有關(guān),還可能和未來的狀態(tài)有關(guān)系,還需要考慮它后面的內(nèi)容,真正做到基于上下文判斷。BiLSTM由兩個LSTM 上下疊加在一起組成的,方向分別向前和向后,輸出由這兩個LSTM 的狀態(tài)共同決定,本文采用的是雙層雙向的LSTM,在保證獲取上下文信息的同時,通過加深網(wǎng)絡(luò)的深度來提取更加深層的特征信息。
2.4 轉(zhuǎn)錄層
轉(zhuǎn)錄層采用的是基于最大熵的CTC改進(jìn)算法[15],CTC[19]模型是手寫識別常用的作于序列預(yù)測對其的模型,將雙向LSTM 中的輸出序列的預(yù)測結(jié)構(gòu)轉(zhuǎn)換成標(biāo)簽序列進(jìn)行輸出,并使得輸出序列與輸入序列對齊,CTC 引入空白標(biāo)簽blank進(jìn)行參與預(yù)測,避免了圖像的分割,實現(xiàn)端到端的識別,當(dāng)數(shù)據(jù)進(jìn)入CTC層時,假設(shè)數(shù)據(jù)的維度是L,在每個時間的數(shù)據(jù)預(yù)測有T 種可能性,共有LT種可能,每一種可能稱為一個Path,條件概率公式(8)如下:
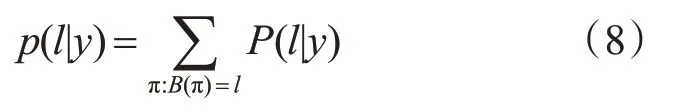
其中,y=y1,y2…yT-1,yT為輸入序列,T 為序列長度,π 代表路徑Path,l代表序列結(jié)果。
CTC 可以認(rèn)為是多實例學(xué)習(xí)的一種,多條路徑經(jīng)過many-to-one 操作后輸出相同的字符串,如果某條路徑π 的概率較大,那么CTC會加強(qiáng)該路徑直至占有所有路徑的絕大部分,是一種正反饋的作用,且由于空白標(biāo)簽blank 在多數(shù)路徑都存在,blank也會加強(qiáng),直至充滿主要路徑,這種現(xiàn)象稱之為CTC尖峰分布,尖峰的存在對路徑的正反饋導(dǎo)致網(wǎng)絡(luò)容易陷入局部最小值之中,也會對序列的分割造成影響,造成對齊不準(zhǔn)確的情況。因此在CTC損失函數(shù)中加入最大熵正則項項來解決尖峰分布的問題,減少CTC 正反饋的影響,選擇出最佳轉(zhuǎn)錄路徑,提高訓(xùn)練過程中的探索能力和模型的泛化能力。CTC 的損失函數(shù)為式(9),Enctc 損失函數(shù)為式(10):
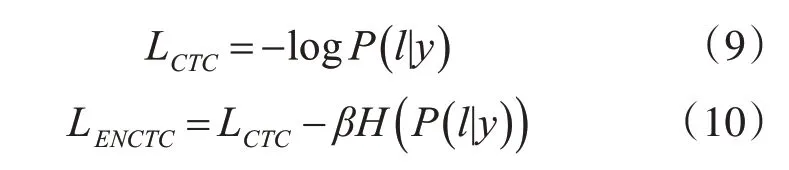
其中,β為比列系數(shù):

3 實驗驗證
3.1 數(shù)據(jù)集
本文采用的數(shù)據(jù)集有IAM[20]英文手寫公開集和采集的學(xué)生樣本真實手寫集,IAM 手寫集來自657 位不同的作者,包括115320 的手寫單詞,本文采用數(shù)據(jù)中的分開好的訓(xùn)練集,測試集和驗證集部分。學(xué)生真實數(shù)據(jù)集包括5000 個單詞,其中4000個作為訓(xùn)練集,500 個作為測試集,500 個作為測試集。數(shù)據(jù)集樣本如圖3 所示。第一行為學(xué)生真實數(shù)據(jù)集,第二行為IAM手寫集。

圖3 數(shù)據(jù)集樣本
3.2 數(shù)據(jù)增強(qiáng)和預(yù)訓(xùn)練模型
本文對訓(xùn)練集數(shù)據(jù)樣本進(jìn)行隨機(jī)的旋轉(zhuǎn)、縮放,平移,旋轉(zhuǎn)的角度范圍在5°之間,上下平移5 個像素以內(nèi),左右平移20 個像素以內(nèi),縮放的倍數(shù)在0.8倍到1.1倍,并隨機(jī)加入少量的噪聲。
深度學(xué)習(xí)模型往往有大量的帶學(xué)習(xí)的參數(shù),因此需要大量的數(shù)據(jù)來進(jìn)行學(xué)習(xí)提高模型的泛化能力,防止模型過擬合。本文利用計算機(jī)合成和仿手寫字體等方式進(jìn)行數(shù)據(jù)合成,得到一個百萬單詞的英文手寫體合成數(shù)據(jù)集,通過采集大量的手寫體字母的基本元素根據(jù)單詞的拼寫順序進(jìn)行合成。同時本文在合成數(shù)據(jù)集上對數(shù)據(jù)樣本隨機(jī)加入高斯噪聲、椒鹽噪聲、伽馬變換等操作。在此數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,得到預(yù)訓(xùn)練模型。
3.3 實驗環(huán)境和設(shè)置
本文使用兩塊Nvidia GTX 1080Ti 11GB 顯存GPU、雙核CPU主頻在4.2GHz以上,深度學(xué)習(xí)開發(fā)框架為PyTorch1.2.0 版本,開發(fā)語言為Python3.6 版本,GPU 并行環(huán)境為CUDA 10.0 版本、CuDNN7.0 版本。本實驗所有圖像高度統(tǒng)一縮放到32 像素,優(yōu)化器算法使用Adam,同時由于網(wǎng)絡(luò)結(jié)構(gòu)較為復(fù)雜采用了Batch Normalization 的方法加快訓(xùn)練速度,學(xué)習(xí)率設(shè)置為0.0001,β設(shè)置為0.2[12],迭代次數(shù)為100次。
3.4 實驗結(jié)果分析
CRNN1+CTC是文獻(xiàn)[3]中的方法,采用的是原始的網(wǎng)絡(luò)結(jié)構(gòu)。CRNN2是將CNN 網(wǎng)絡(luò)中的激活函數(shù)改變?yōu)镸ish激活函數(shù)。
STN+CRNN2+CTC 是在上述結(jié)構(gòu)的基礎(chǔ)上,在卷積層之前加入STN層,并和上述實驗應(yīng)同樣的方法。
STN+CRNN2+EnCTC是在上述結(jié)構(gòu)的基礎(chǔ)上,利用EnCTC損失函數(shù)替換CTC損失函數(shù)。
預(yù)訓(xùn)練+STN+CRNN2+EnCTC是在上述結(jié)構(gòu)的基礎(chǔ)上,先通過合成數(shù)據(jù)集的預(yù)訓(xùn)練,得到網(wǎng)絡(luò)模型的參數(shù),并在手寫數(shù)據(jù)集進(jìn)行參數(shù)的微調(diào)。
通過表1、表2 可以看出,STN 網(wǎng)絡(luò)對輸入圖片的糾正的作用是明顯的,但由于采集的真實手寫集樣本相對于IAM 公開集而言,字跡相對工整,字體扭曲的情況較少,在真實手寫體上的提高不大,EnCTC 損失函數(shù)很好地解決了CTC 損失函數(shù)的尖峰問題,提高了模型在訓(xùn)練過程中的探索能力,從而提高了模型的識別率。通過在合成數(shù)據(jù)上進(jìn)行模型的預(yù)訓(xùn)練能夠提升訓(xùn)練速度,提高模型的識別性能,從數(shù)據(jù)集的角度來看,通過對數(shù)據(jù)集進(jìn)行適當(dāng)?shù)钠揭疲D(zhuǎn),隨機(jī)加入少量噪聲等數(shù)據(jù)增強(qiáng)的方式來擴(kuò)充數(shù)據(jù)集,可以保證CRNN 網(wǎng)絡(luò)能夠?qū)W到更多的特征信息,從而提高模型的識別精度與泛化能力。本文方法通過利用數(shù)據(jù)增強(qiáng),預(yù)訓(xùn)練模型,STN 網(wǎng)絡(luò),更改激活函數(shù)和損失函數(shù)的方式。與原始算法相比,在IAM手寫公開集上訓(xùn)練準(zhǔn)確率提高了5.5%,測試準(zhǔn)確率提高了5.1%。在真實學(xué)生手寫集上訓(xùn)練準(zhǔn)確率提高了2.21%,測試準(zhǔn)確率提高了2.68%,提升效果還是很明顯的。
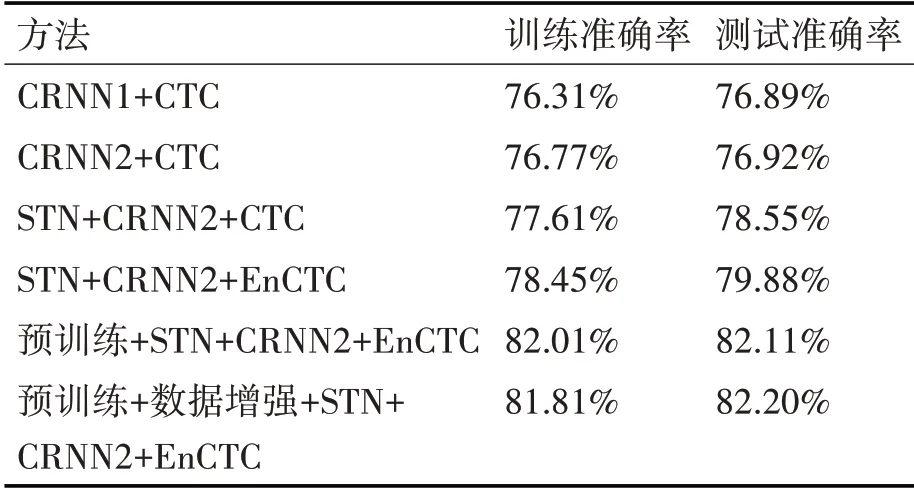
表1 在IAM手寫數(shù)據(jù)集上的研究
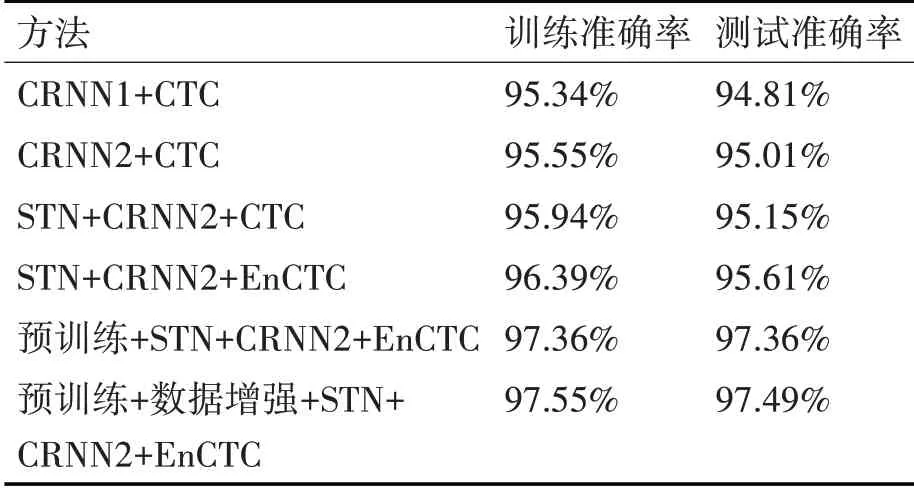
表2 在學(xué)生真實手寫集上的研究
4 結(jié)語
本文在CRNN 結(jié)構(gòu)的基礎(chǔ)上,通過在合成數(shù)據(jù)集上進(jìn)行模型的預(yù)訓(xùn)練,以及對手寫集的預(yù)處理和數(shù)據(jù)增強(qiáng),利用STN網(wǎng)絡(luò)作為神經(jīng)網(wǎng)絡(luò)初始部分對扭曲圖像進(jìn)行矯正,有效地提高了卷積神經(jīng)網(wǎng)絡(luò)對特征的提取效果,從而提高識別效率,利用EnCTC損失函數(shù)很好地解決了CTC 損失函數(shù)存在的尖峰分布問題,抑制了由尖峰問題帶來的正反饋的影響,同時也提高了模型的泛化能力,在IAM 手寫數(shù)據(jù)集以及學(xué)生真實數(shù)據(jù)集兩個數(shù)據(jù)上都顯著地提高了識別效果,同時整體的網(wǎng)絡(luò)結(jié)構(gòu)是端到端的,減少了網(wǎng)絡(luò)的復(fù)雜度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
