基于知識點的個性化試題推薦方法*
2022-06-16 12:45:56王啟亮
計算機與數(shù)字工程 2022年5期
王啟亮 劉 鎮(zhèn)
(江蘇科技大學(xué)計算機學(xué)院 鎮(zhèn)江 212003)
1 引言
2020 年,伴隨著教育信息化由1.0 到2.0 升級步伐的加快,以虛擬現(xiàn)實、增強現(xiàn)實、人工智能、5G、區(qū)塊鏈為代表的新一代信息技術(shù)及其教育應(yīng)用無疑會引發(fā)更多關(guān)注[1]。
通常情況下,用戶的學(xué)習(xí)成效一般都是通過對知識點的掌握情況來衡量的,知識點直接決定了用戶是否掌握了當(dāng)前知識點所表示的知識。怎樣以高效合適的方式來評估一個用戶的知識是一項艱巨的任務(wù),魚龍混雜的試題會不但浪費資源,而且對用戶的學(xué)習(xí)時間造成不必要的浪費。然而,試題的關(guān)鍵在挑戰(zhàn)在于如何使用合適的題目以及問題,來檢測用戶的相關(guān)能力。因此,在進(jìn)行試題的設(shè)計時,應(yīng)該在知識點的基本要求和延伸之間取得平衡。
2 模型框架
2.1 知識點實體抽取
給定輸入句子X,即試題發(fā)布中的知識點要求,將三個元素信息(即字符、單詞和字符的bi-gram)全部考慮在內(nèi)。用{c1,c2,…,cn}表示X的字符序 列,{b1,b2,…,bn} 表示字符 的bi-gram 序列,其中bi=cici+1。使用中文分詞器將X拆 分 為m 個 單 詞,即{w1,w2,…,wm}[2]。計算三類元素信息表征為

其中Wc、Wb、Ww是基于百度百科數(shù)據(jù)的預(yù)訓(xùn)練字符、字符bi-gram 和字向量矩陣初始化的。將字符和字符bi-gram 的表示連接起來,并使用完全連接的層來減少與相同的維度。然后使用一個門機制來動態(tài)地組合語義字符層和單詞層的表示[3],如式(2)所示:
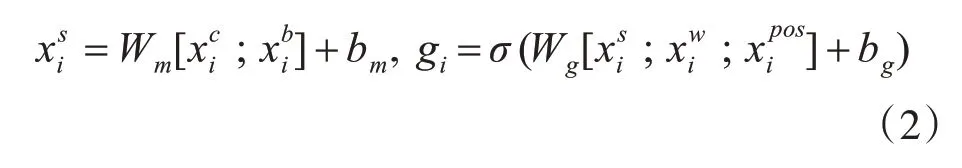
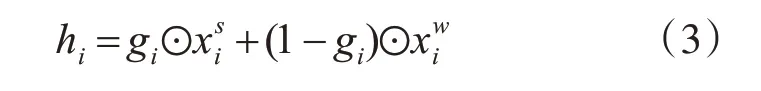
式中⊙表示按元素劃分的結(jié)果,使用隱藏向量hi和POS 標(biāo)記作為雙向LSTM 層的輸入,可以表示為

最后,將隱藏狀態(tài)s={s1,s2,…,sn}作為標(biāo)準(zhǔn)CRF 層的輸入,輸出y={y1,y2,…,yn},其中yi∈{I,O,B,E,S}表示字符在技能實體的內(nèi)部、外部、開始、結(jié)束或單個[4]。所以序列y的條件概率:


其中Y表示s的所有可能的標(biāo)簽序列,Pi,yi是用標(biāo)簽yi指定第i 個單詞的分?jǐn)?shù),Ayi,yi+1表示從標(biāo)簽yi到y(tǒng)i+1的轉(zhuǎn)換分?jǐn)?shù),Wo、bo是可訓(xùn)練參數(shù)。
2.2 知識點實體降噪
創(chuàng)建一個實體-URL 圖G=(V,E)。節(jié)點集V包含兩種節(jié)點,實體Ve和包含在這些實體的查詢?nèi)罩局械腢RLs 集合。邊E的集合同樣包括兩個部分,即Eeu和Eee。Eeu?Ve×Vu是Ve中的點與它們在Ve,Vu中的相應(yīng)URL集合之間的鏈接集。刪除了在標(biāo)記數(shù)據(jù)中同時連接了知識點實體和非知識點實體的URL 的邊。用Weu∈Rpe×pu表示權(quán)重矩陣,對應(yīng)的邊集是Eee。
通過基于LP 的方法計算一個實體為知識點的概率。將y∈Rpe×2表示為實體標(biāo)簽。當(dāng)實體被標(biāo)記為知識點詞時,設(shè)置對應(yīng)的,非知識點詞,則設(shè)置。計算如下兩個歸一化權(quán)重矩陣。

其中Deu和Dee是兩個對角矩陣,其中每個元素為。然后,迭代地使用LP 來更新yeu,yee∈Rpe×2,分別表示W(wǎng)eu和Wee所獲實體標(biāo)簽的得分。
2.3 試題推薦
給定試題J,將當(dāng)前參加這套試題用戶的個人信息表示為R={R1,R2,…,Rp},并且還利用用戶的歷史成績表示為P={P1,P2,…,Pp},通過該試題的用戶為S。將VJ,VRi和VS分別表示為J,Ri和S的知識點集合。將Ri和S中出現(xiàn)的知識點vk的數(shù)量分別計算為CRik和CSk,將 子 節(jié) 點(descendant(vk))表示為Gr 中知識點vk的所有后代節(jié)點集,而父節(jié)點(ancestor(vk))表示為其所有父節(jié)點集[6]。之后,可以根據(jù)歷史成績信息和應(yīng)聘者的簡歷來衡量Gr 中每個知識點vk的權(quán)重。

同時,將主要知識點集V'J定義為VJ中所有基本知識點的集合,即ancestor(vn)=?}。還分別定義了VRi、VR和VS知識點集和VS'。
然后將VJ,VR和VS中的所有知識點分為匹配知識點、個性化知識點和非匹配知識點三部分,分別計算它們的權(quán)重[7]。此外,為了處理冷啟動問題,還考慮了試題信息,但不出現(xiàn)在歷史成績數(shù)據(jù)或用戶的個人信息中。知識點權(quán)重數(shù)學(xué)定義如下。

其中,通過函數(shù)g(vk)來移除用戶沒有的當(dāng)前知識點。例如,假設(shè)歷史試題數(shù)據(jù)表明,C++和PHP 的。如果用戶喜歡C++,并且對C++感興趣,將忽略PHP在歷史試題數(shù)據(jù)中的權(quán)重。



3 實驗結(jié)果與分析
3.1 知識點實體抽取測試
通過一個歷史試題數(shù)據(jù)集用于知識點實體提取,包括3605份試題和17931份用戶歷史試題。在2000 個的需求中手動標(biāo)記了知識點實體句子和3700個試題。如表1所示,為試題申請數(shù)據(jù)集的統(tǒng)計信息。

表1 試題申請數(shù)據(jù)集的統(tǒng)計信息
使用Skipgram 模型對來自百度百科文本數(shù)據(jù)的字符,字符、單詞和字符的bi-gram 進(jìn)行了預(yù)訓(xùn)練。在知識點實體提取模型中,維度在BiLSTM 中的隱藏狀態(tài)設(shè)置為300。同時也遵循了文獻(xiàn)[8]中的思想初始化所有矩陣和向量參數(shù)。所有模型均采用Adam 算法進(jìn)行優(yōu)化。最后,為了驗證模型的性能,選擇幾種模型作為基線方法,包括字符基線,即基于字符的BiLSTM CRF,它直接使用字符作為BiLSTM;字符基線中引入的信息包含單詞和字符的bi-gram信息[9]。
試題發(fā)布和個人信息的整體表現(xiàn)數(shù)據(jù)集如表2 所示。可以看出使用的三類信息(字符、單詞、字符bi-gram)對建模知識點實體抽取的有效性,以及門結(jié)構(gòu)的有效性。

表2 知識點實體抽取結(jié)果
3.2 知識點實體降噪測試
通過收集2019年1月至6月之間的點擊數(shù)據(jù)[10],將kt設(shè)置為20,以便為每個實體選擇點擊最多的URL 標(biāo)題。將主題數(shù)nt設(shè)為100 訓(xùn)練LDA 模型Mt,將α設(shè)為0.5 計算高斯核矩陣S。然后,將ke設(shè)置為20,將kg設(shè)置為0.7,以在每兩個實體節(jié)點之間的Eee中構(gòu)造邊。
模型和基準(zhǔn)的性能如表3 所示。發(fā)現(xiàn)的模型沒有Eee中的信息達(dá)到了0.97 的最高準(zhǔn)確率,表明使用LP算法過濾知識點實體的有效性。實際在模型的變體中,缺少Eee導(dǎo)致20%測試集中的實體節(jié)點不連接任何URL,并且不能被它預(yù)測。因此,盡管它具有很高的精度,但是召回率僅為0.75。而且利用Eee在LP 算法可以預(yù)測所有實體標(biāo)簽并取得最佳性能與所有基準(zhǔn)模型進(jìn)行比較。雖然隨機森林可以達(dá)到最佳召回率,其精度值沒有競爭力。最后通過的LP 算法,總共獲得了4,836 個知識點實體。

表3 知識點實體降噪效果
3.3 試題推薦測試
首先對上述數(shù)據(jù)集依照時間分為訓(xùn)練集和測試集對數(shù)據(jù)特征進(jìn)行抽取,結(jié)果用onehot 熱編碼。通過GBDT 模型進(jìn)行特征提取,用對梯度提升樹中的樹的最大深度參數(shù)進(jìn)行設(shè)置。實驗采取了ROC曲線[11]來作為很亮性能的主要指標(biāo),其中ROC 曲線橫縱坐標(biāo)分別代表了假正率FPR和真正率TPR,由在一系列閾值下FPR 和TPR 中的數(shù)值連接成的曲線。如圖1 所示,為GBDT 的F1 分值與maxdepth參數(shù)之間的關(guān)系圖。

圖1 F1與maxdepth參數(shù)的關(guān)系圖
然后將GBDT 模型的輸出作為LR 的特征進(jìn)行處理,邏輯回歸算法受到正負(fù)樣本比例影響很大因此選取合適的最佳的正負(fù)樣本比例對推薦的結(jié)果有較大的影響,如圖2所示,為LR的F1分值與閾值參數(shù)NP ratio關(guān)系圖。

圖2 LR 的F1分值與NP ratio 關(guān)系
此外,邏輯回歸算法由于使用的sigmoid 函數(shù)[12]進(jìn)行分類,在不同的正負(fù)樣本比例的情況下,其閾值參數(shù)cut_off 的最優(yōu)值也不盡相同。閾值參數(shù)與F1 的關(guān)系如圖4所示。

圖3 LR 的F1與cut_off 關(guān)系

圖4 GBDT 與LR 混合下的ROC 曲線圖
最后經(jīng)過通過混合模型可以進(jìn)一步的提高推薦的性能,其ROC 曲線如圖5所示。

圖5 混合模型框架下的ROC 曲線圖
本文同時將算法與各類算法進(jìn)行對比,如表4所示,通過實驗結(jié)果可以看出,由于進(jìn)行模擬測試時數(shù)據(jù)量較少,導(dǎo)致本算法與其他算法在準(zhǔn)確性、召回率和F1 綜合評價指標(biāo)上差距較小,但在一定程度上還是體現(xiàn)了本文算法的優(yōu)越性,加之之后互聯(lián)網(wǎng)的海量數(shù)據(jù),該算法的精度將愈發(fā)精確。

表4 各類算法對比
4 結(jié)語
本文介紹了一個種基于知識點個性化試題推薦系統(tǒng),用于在線學(xué)習(xí)中的用戶在線對當(dāng)前知識點掌握情況的測試。該系統(tǒng)的關(guān)鍵思想是通過挖掘歷史試題數(shù)據(jù)和從網(wǎng)絡(luò)中獲得的工作技能數(shù)據(jù)來構(gòu)建知識點的知識圖譜。具體來說,首先基于雙向LSTM-CRF 神經(jīng)網(wǎng)絡(luò)設(shè)計了一種知識點實體提取方法。然后基于點擊日志數(shù)據(jù)設(shè)計了標(biāo)簽傳播方法,以提高提取的知識點實體的可靠性。此外,提出基于知識點實體之間的上位詞-下位詞關(guān)系,構(gòu)建知識點圖譜,并提出了一種啟發(fā)式的個性化的試題推薦算法,以改善用戶在線學(xué)習(xí)時的對知識點更加熟悉。最后,通過對比SETB 算法和TBTFIDF 算法體現(xiàn)了本問算法在一定程度上的優(yōu)越性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
