基于半監督支持向量機的電力現貨市場串謀識別
2022-06-09 09:18:16謝敬東魯思薇黃溪瀅孫波孫欣陸池鑫
南方電網技術 2022年5期
謝敬東,魯思薇,黃溪瀅,孫波,孫欣,陸池鑫
(1. 上海電力大學,上海200082;2 國網上海市電力公司市南供電公司,上海200030)
0 引言
中發〔2015〕9號文及其配套相關文件頒布以來,中國電力市場開始了新一輪的改革,提出要以現貨市場發現價格,建立交易品種齊全、功能完善的電力市場[1]。2020年7月,國家發展改革委、國家能源局聯合印發了《關于做好電力現貨市場試點連續試結算相關工作的通知》(發改辦能源規〔2020〕245號)[2],進一步推進電力現貨市場建設。隨著市場改革的不斷深入,社會各界也更加重視市場風險防范問題。在市場交易的過程中,市場主體為了獲取高額利潤,利用市場規則漏洞濫用市場力,嚴重損害現貨市場發現價格的能力[3 - 5]。其中,串謀是濫用市場力的主要方式之一,嚴重危害了市場的有效性,因此,建立一套現貨市場發電企業串謀識別的辦法,對于維護電力市場的安全、穩定、可靠運行,具有積極意義。
目前,國內外關于電力市場串謀行為已經進行了大量的研究,文獻[6]對發電側電力市場二級委托代理機制下發電商的串謀行為和我國電力市場規制串謀行為的法律依據進行了研究,提出了一種負激勵機制來有效抑制串謀行為的方法。文獻[7]應用委托代理理論,構建博弈論模型,分析了發電商采用串謀行為的動機。文獻[8]對市場主體對于風險的厭惡特性進行分析,設計了一套針對中長期電量集中競價市場通過二次分配出清量來抑制市場主體串謀的方法。這些文獻主要采用定性分析的方法,考慮了串謀形成的因素、抑制串謀的方法,但未對串謀行為進行識別。文獻[9]提出了一種基于物理潮流分析的市場力分層評價指標體系。文獻[10]提出了基于模糊集理論和層次分析法的電力市場綜合評價方法。文獻[11]設計了一種發電商報高價的不正當合謀競標行為識別的綜合評判算法。這些文獻通過構建評價指標,利用綜合評價評估市場中的串謀行為,但該方法不能隨著市場的發展進行自我學習。文獻[12]提出基于AdaBoost-DT算法的串謀行為智能識別方法,將AdaBoost-DT集成分類算法用于串謀識別中,解決了串謀行為難以量化識別的問題;文獻[13]構建基于排序多元 Logit模型的卡特爾類機組串謀識別。文獻[14]利用模式識別的辦法,提出基于云模型與模糊Petri網的電力市場濫用市場力識別方法。上述文獻利用有監督的智能算法實現了串謀行為的自我識別和自我適應,但目前我國電力市場正處于起步階段,市場中沒有明確的串謀機組樣本,而有監督的算法需要較多的訓練樣本,利用少量有標簽數據訓練出的模型,泛化能力差,難以適用新鮮樣本。而無監督的方法利用無標簽數據,根據建立的模型評估未知數據,一旦模型建立錯誤,就會造成很大的偏差。
針對以上問題,本文考慮我國電力現貨市場運營時間短、運營模式仍處于探索時期的現狀,結合專家經驗知識,提出采用半監督支持向量機算法,同時利用有標簽樣本和無標簽樣本進行訓練,根據樣本間的內在聯系,訓練出更為可靠的分類器。
半監督支持向量機作為一種半監督方法,已經應用于多個領域。在電力領域,文獻[15]提出了一種基于半監督支持向量機的電壓暫降源定位方法,并表明在少量標簽數據下,該方法定位準確率高,能可靠定位出各類電壓暫降源位置。文獻[16]提出了一種基于半監督支持向量機的電壓暫降源識別方法,在少量標簽數據下半監督支持向量機比傳統支持向量機具有更高的識別精度。文獻[17]提出了一種基于模糊C均值和支持向量機的半監督支持向量機分類算法,評估供電企業的安全性。在圖像分類領域,文獻[18]提出了一種基于均值漂移的meanS3VM圖像分類方法。文獻[19]提出了一種新的圖像分類方法,將基于最優標號和次優標號的主動學習和帶約束條件的自學習引入到基于支持向量機分類器的圖像分類算法中,獲得較高的準確率和較好的魯棒性。文獻[20]提出了一種協同主動學習和半監督學習方法用于海冰遙感圖像分類,獲得較高的分類精度。文獻[21]提出了基于半監督徑向基函數神經網絡的電網自組織臨界態辨識方法,用時少、正確率高,滿足在線辨識電力系統自組織臨界態的要求。
綜上所述,本文提出了一種基于半監督支持向量機的電力現貨市場發電企業串謀識別方法。首先,分析現貨市場發電企業串謀的特點,建立串謀識別指標體系;其次,利用Delphi法修正后的Topsis模型,對機組進行初步判定,將機組串謀的可能性分為“高”、“中等”和“低”3種可能,構成機組串謀識別模型的訓練集;然后,利用訓練集訓練基于半監督支持向量機的串謀識別模型,并利用訓練好的模型對現貨市場中大量未知數據進行識別;最后,將該方法應用于某地區現貨市場,對方法進行驗證。
1 串謀識別指標體系構建
串謀是指參與市場的主體通過主體間的協商、簽訂合同等方式,締結為一個“聯盟”,以獲得更高的利潤[22]。在電力市場中,串謀的途徑大致分為兩類,一類是通過私下簽訂合同的方式,將雙方綁定為一個利益整體。另一類是通過默契串謀,聯盟內成員通過對市場規則以及市場成員報價行為的掌握,經過一段時間后,形成有利于提高聯盟整體利潤的報價方式[23]。在現階段,現貨市場正處于起步,市場成員對市場規則不夠熟悉,對市場成員的報價方式也不夠了解,因此參與串謀的成員往往以等報價或者等報價變化的簡單方式進行串謀[24]。
在現貨市場中,發電企業的串謀是通過其控制的發電機組進行的,并且串謀往往是發生在兩臺或兩臺以上的機組之間的。因此,本文將兩臺機組作為一個機組對,構建基于機組對的指標體系,旨在通過觀察機組對的關聯性,識別機組潛在的串謀行為。同時,本文認為當機組a和機組b發生串謀,機組a和機組c發生串謀,則認為機組a、機組b和機組c之間屬于同一個串謀聯盟。
串謀識別指標體系基于系統性、科學性和可操作性原則,將所有指標分為判斷報價相似性的報價相似情況指標類、判斷報價變化同步性的報價變化同步情況指標類,以及判斷機組參與市場結果的中標情況指標3大類。報價相似指標和報價改變同步性指標主要是考察發電機組在市場中的行為,可以反映機組是否采用相同的報價策略,即反映機組是否串通報價;中標情況指標用來衡量機組報價策略的成功度,通過中標情況指標判定機組是否串謀成功。
下面給出指標的具體定義及其計算方式。
1.1 報價相似性情況
1.1.1 報價一致性
報價一致性指標表示機組i和機組j的報價一致性情況,其計算方式如式(1)所示。
(1)
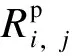
1.1.2 報量一致性
報量一致性指標表示機組i和機組j的報量一致性情況,其計算方式如式(2)所示。
(2)
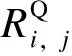
1.1.3 報價曲線差異度[12]
機組報價曲線差異度定義為機組i的報價曲線及機組j的報價曲線之間的陰影面積,如圖1所示。
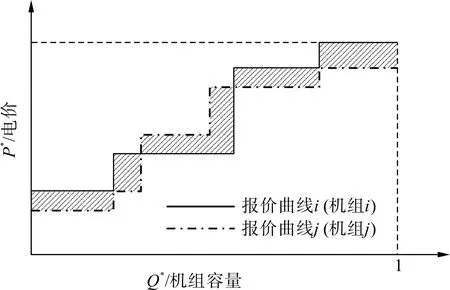
圖1 報價曲線差異度Fig.1 Difference degree of quotation curve
機組報價曲線差異度的計算公式為:
(3)
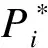
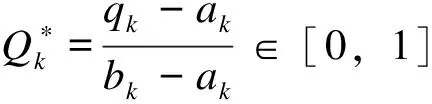

(4)
1.2 報價變化同步性情況
1.2.1 報價變化一致性
機組對報價變化一致性定義為機組i和機組j報價變化的一致性,機組i的報價變化是指機組i本次申報的價格與其前一次申報的價格的差值,機組j的報價變化是指機組j本次申報的價格與其前一次申報的價格的差值,其計算公式如下。
Pc,i=[(pi,1,t-pi,1,t-1),…,(pi,h,t-pi,h,t-1),
…,(pi,H,t-pi,H,t-1)]
(5)
(6)
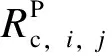
1.2.2 報量變化一致性
機組對報量變化一致性定義為機組i和機組j申報容量變化的一致性,機組i的報量變化是指機組i本次申報的申報容量與其前一次申報的申報容量的差值,機組j的報量變化是指機組j本次申報的申報容量與其前一次申報的申報容量的差值,其計算公式如下。
Qc,i=[(qi,1,t-qi,1,t-1),…,(qi,h,t-qi,h,t-1),
…,(qi,H,t-qi,H,t-1)]
(7)
(8)
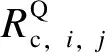
1.2.3 報價變化曲線差異度
機組報價變化曲線差異度定義為機組i的報價變化曲線及機組j的報價變化曲線之間的陰影面積,機組報價變化曲線差異度的計算公式為:
(9)
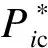
在現實生活中,發電機組的發電成本是發電企業私有的,機組參與市場所獲得的利潤是不可知的,因此,本文用機組中標率來判斷機組間串謀的可能性。
1.3 機組中標情況
1.3.1 中標率
機組對中標率定義為機組i的總中標量與總申報量的比值,其計算方式如下:
(10)
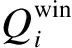
1.3.2 高價中標率
機組高價中標率定義為機組報高價且中標電量占報高價的有效申報電量的比例。高價中標率通過發電商成交情況與申報情況的比較反映發電商的競標策略與自身實力的配合情況,用于評價發電商策略的成功率與所具有的市場力。其計算公式為:
(11)
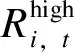
1.4 動態市場份額
機組動態市場份額定義為機組的中標量占市場總中標量的比例,其計算公式為:
(12)
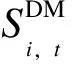
通過計算機組市場份額,可以評估該機組的市場力,若該機組的市場份額過高,說明機組報價策略較為成功。
2 現貨市場串謀機組初步判定
2.1 串謀機組初步判定步驟
智能識別算法可以實現對大規模數據的快速判斷,但需要一定量的訓練樣本。對于現階段的電力市場而言,并沒有足夠的串謀機組樣本來進行模型的訓練。因此,本文先對機組進行初步判定,借助專家的經驗知識,結合數據本身特點,利用上文建立的指標體系,利用Delphi法修正后的Topsis模型,對現貨市場的串謀行為進行初步判定,為下一階段模型的訓練提供數據。文獻[25]使用不同的方法研究發電商串謀,但都考慮了機組通過串謀獲得超額利潤的特性,因此,參考以上文獻,本文采用“漏斗式”分析方法,如圖2所示。首先,重點考察機組的中標情況,并將其作為判斷機組是否串謀的重要因素,通過判斷中標情況,對機組進行初步劃分,當機組中標情況評估分值S1低于閾值W1時,認定機組為“低串謀可能性”。然后判斷機組是否有串謀的行為動作,即考察機組報價相似情況和報價變化同步情況,對機組劃分結果進行修正,對修正后的機組進行再一次的劃分。
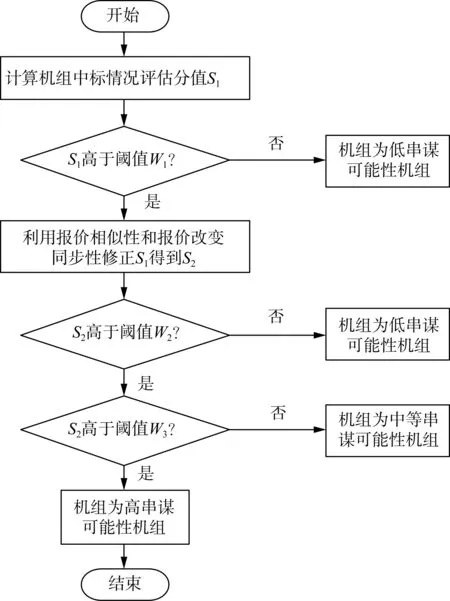
圖2 機組串謀判定整體流程Fig.2 Process of unit collusion judgment
步驟1:利用現貨市場數據,計算相應指標,對指標進行標準化處理;
步驟2:隨機選取機組對如機組i和機組j;
步驟3:判斷機組i和機組j的中標情況,若機組i和機組j的中標情況綜合評價結果S1低于閾值W1, 則認為機組間有“低串謀可能性”;否則轉向步驟2;
步驟4:判斷機組i和機組j的報價相似情況和報價改變情況,利用報價相似情況和報價改變同步情況,對中標情況的綜合評價結果進行修正,若機組i和機組j報價相似或報價改變同步,則認為機組i和機組j更有可能進行串謀,應對評價結果進行放大,當修正后的評價結果超過閾值W3時,則認為機組i和機組j之間有“高串謀可能性”;當修正后的評價結果在閾值W2之間時,則認為機組i和機組j之間有“中等串謀可能性”;當修正后的評價結果低于閾值W2時,則認為機組i和機組j之間有“低串謀可能性”;
步驟5:重復步驟1至步驟4,直至所有機組對判斷完畢。
2.2 Delphi法修正后的Topsis模型
Delphi法作為一種主觀賦權方法,能夠較好適應現貨市場的發展階段,其本質上是一種反饋匿名函詢法。其大致流程為:在對所要預測的問題征得專家的意見之后,進行整理、歸納、統計,再匿名反饋給各專家,再次征求意見,再集中,再反饋,直至得到一致的意見。
Topsis(優劣距離法)是常用的綜合評價方法,能充分利用原始數據的信息,精確反映各個評價方案之間的優劣。其基本思路是,在一個評價方案的集合中,分別找出一個最優解(每個屬性值都是該屬性的最優值)和最劣解(每個屬性值都是該屬性的最差值),并將評價方案集合中的每一個方案與最優解、最劣解的距離進行比較,既靠近最優解又遠離最劣解的方案,就是方案集中的最優方案。
在利用Topsis模型進行評價的過程中,引入Delphi法確定的主觀權重,具體步驟如下。
經過正規手術及合理的治療后,兒童及青少年甲狀腺癌預后良好,治療后長期生存率很高,分化型甲狀腺癌長期生存率超過90%;甲狀腺髓樣癌的5年和15年生存率均超過85%。但與成人相比,其復發比例仍較高,可達10%~35%[28-29],故定期的隨訪很重要,包括超聲以及檢測血清Tg水平,超聲隨訪方案為初次手術后至少6個月內需進行頸部超聲檢查,之后每6~12個月復查1次[5]。
步驟1:對于歸一化后的指標進行正向化處理。
步驟2:利用專家打分法確定指標權重,m個指標的權重分別為{α1,…,αm}。
步驟3:構造加權矩陣如下。
(13)
式中znm為第n個機組對的第m個指標。
步驟4:尋找最優解z+和最劣解z-如下。
(14)
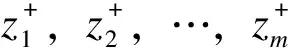
步驟5:求解每個方案到最優解解z+和最劣解z-的距離。
(15)
步驟6: 求解每個方案與最優解相對接近程度。
(16)
式中:Ci為第i個評價方案與最優解的相對接近程度,Ci越大,表明評價對象越接近最優值。
2.3 綜合評估
根據2.1節內容,先利用2.2節的Topsis模型求得中標情況的綜合評價結果S1, 對于S1大于W1的機組進行下一步判斷。在S1的基礎上,結合報價相似情況和報價變化同步情況的綜合評價結果得到S2, 計算公式如式(17)所示。
S2=S1×eγ+θ-1
(17)
式中:γ為報價相似和報價變化同步情況綜合評價結果的歸一化值;θ為縮放因子,可以根據電力市場實際運行情況取值,當縮放因子取值較大時,對S1的放大程度越大,反之越小。
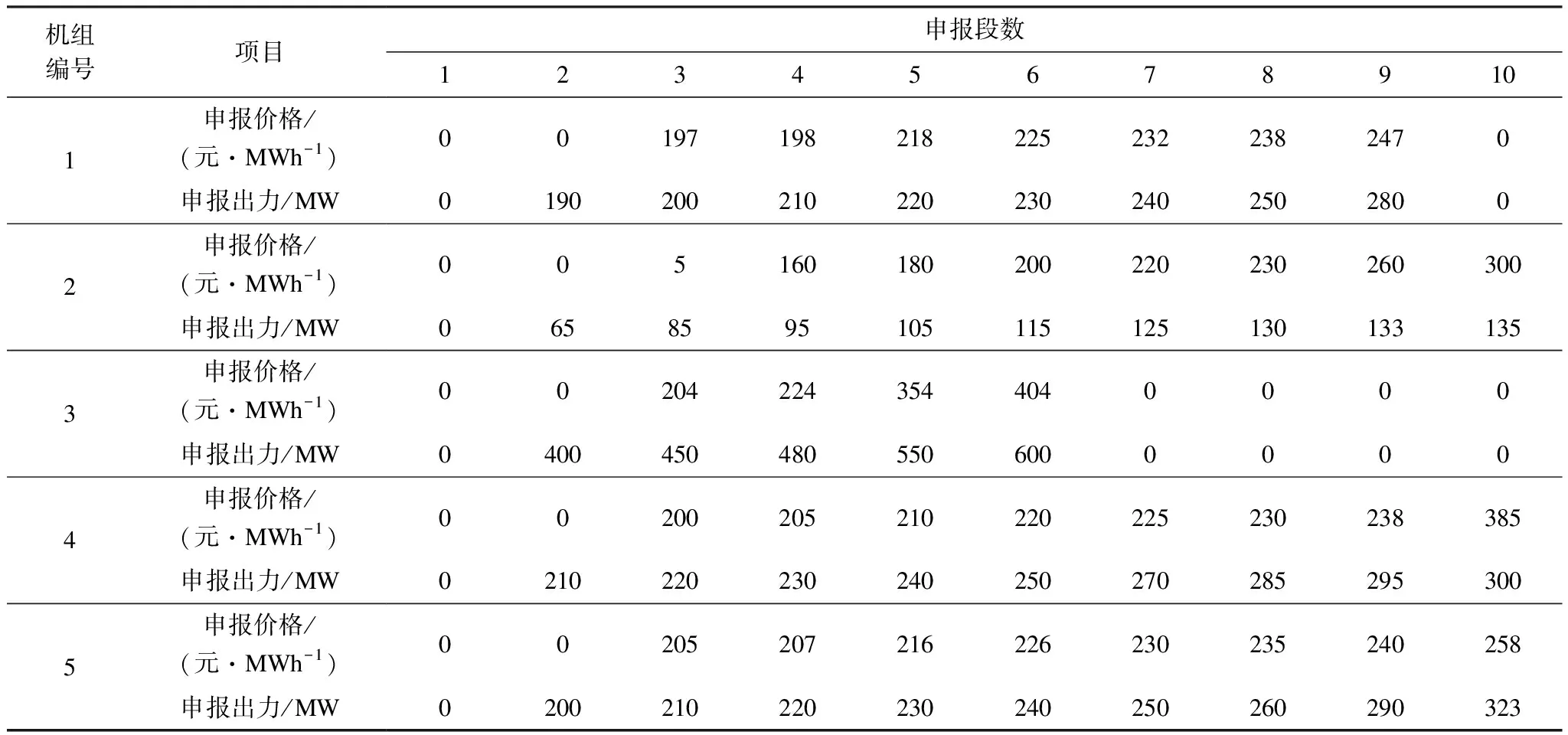
表1 某地區現貨市場報價數據Tab.1 Quotation data of spot market in a region
3 機組串謀識別模型
由第2節可以得到初步判定的串謀機組,利用初步判定的串謀機組進行模型的訓練。
3.1 支持向量機
支持向量機是一種二分類模型,它的目的是尋找一個平面對樣本進行分割。設有標記的樣本數據為{(xi,yi)},i=1,2,…,N, 其中xi∈RP為特征數據集,yi∈{-1,1}為類別標簽。SVM的判別模型為:
f(X)=sign(ωTX+b)
(18)
式中:ω和b為系數向量。
設最優分界面為ωTx+b=0, SVM的目標是求解其最優解,求解問題最終可以轉化為式(19)的帶約束的凸二次規劃問題。
(19)
式中:ξi=1-yi(ωTxi+b)為損失函數;C為懲罰參數,C越大表示對錯誤分類的懲罰越大,C越小表示對錯誤分類的懲罰越小。根據凸優化理論,借助拉格朗日乘子將約束問題轉換為無約束問題。
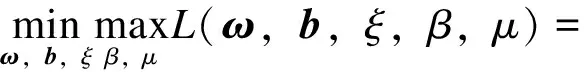
βi≥0,μi≥0
(20)
式中β、μ為拉格朗日乘子。
根據拉格朗日對偶原理,將式(20)化為其對偶問題。
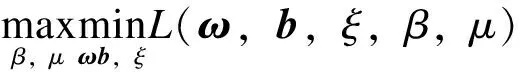
(21)
解式(21)求優化函數對ω,b,ξ的極小值,令:
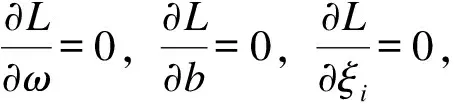
(22)
代入拉格朗日函數中,可以得到:
(23)
則問題最終轉化為:
(24)
3.2 半監督支持向量機的串謀識別模型
基于半監督支持向量機的串謀識別模型訓練集由有標簽機組樣本和無標簽機組樣本組成,兩者符合獨立同分布的假設,有標簽機組樣本集為:
(25)
無標簽機組樣本集為:
Unlab={xN+1,xN+2,…,xN+M},xi∈RP
(26)
則基于半監督支持向量機串謀識別模型的求解問題為:
s.t.yi(ωTxi+b)≥1-ξi,i=1,2,…,N
(27)
半監督支持向量機的求解是從無標記機組樣本中,找到使分類超平面的分類間隔最大的標記,作為無標記機組樣本的最終標記。該方法可以得到全局最優解,具有較好的性能。
4 算例分析
4.1 數據
本文采用某地區現貨市場報價數據,選取其中166臺發電機組,共計13 695條樣本。在該地區現貨市場中,采用十段報價形式,參與市場的機組在日前市場中申報一組價格,同時用于日前市場出清和實時各時段的出清,部分機組報價數據表1所示。串謀機組的初步判定針對指標權重問題,詢問3位專家,對專家的反饋意見進行整理、歸納、統計;然后匿名反饋給專家,再次征求意見,直至意見統一,確定的最終權重如表2和表3所示。

表2 中標情況指標權重Tab.2 Index weights of bidding situation
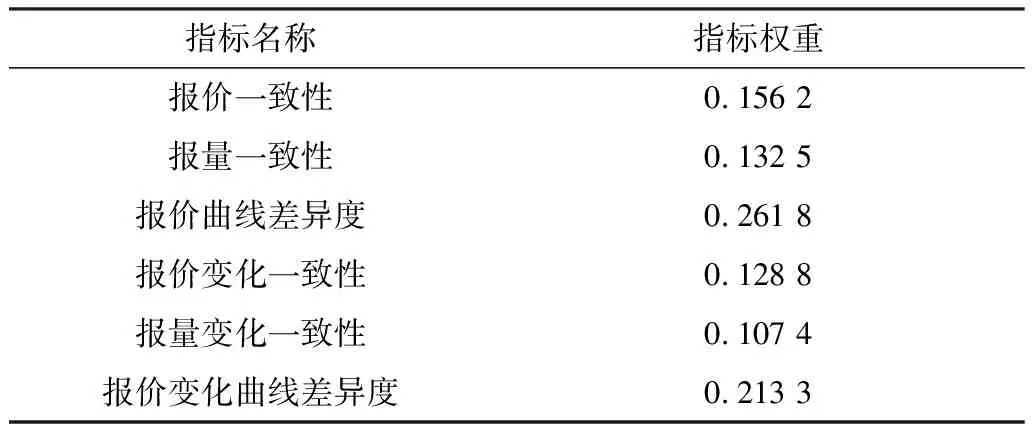
表3 報價相似和報價變化同步情況指標權重Tab.3 Index weights of similar quotation and synchronous quotation change

表4 中標情況評估的最優最劣方案Tab.4 The best and worst cases of bid winning
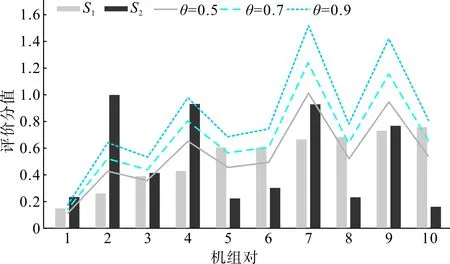
圖3 不同θ下,修正前后結果對比Fig.3 Comparison of results before and after correction under different θ
由計算得到的串謀識別指標體系,分別對各項指標進行同向化處理,將所有指標轉化為極大型指標,然后進行標準化處理,可以得到如表4所示的最優最劣方案。
根據最優和最劣方案計算相對接近度,得到最終的評估結果S1, 同理,可以得到報價相似和報價變化同步情況的綜合評價結果S′2, 利用式(17)對S1的值進行修正,即利用報價相似和報價變化同步情況對S1值進行縮放,對于報價相似性高和報價變化同步性也高的,通過修正,放大S1的值;對于報價相似性低和報價變化同步性也低的機組,縮小S1的值,最終得到S2的值,再次對機組進行劃分。10臺機組對在不同的縮放因子θ下,修正前后的對比如圖3所示。
由圖3中,機組對1和機組對2可以看出,當S1的值較小,S′2值較大時,通過修正,最終的S2值變大,即當機組中標情況評價結果較低,報價相似和報價變化同步情況評價較高時,最終的評價分值也會變高,此時修正前的分值小于修正后的分值,且θ值越大修正后的評價分值越高;由機組對7和機組對8可以看出,當S1的值較大,S′2值較小時,通過修正(θ取值合適,例如上圖中的θ=0.5),最終的S2值變小,即當機組中標情況評價結果較高,報價相似和報價變化同步情況評價較低,且θ取值合適時,最終的評價分值也會變低。
最后,通過對串謀機組的初步判定,“高串謀可能性”的機組樣本共有1 068條樣本,“中等串謀可能性”的機組樣本共有1 515條樣本,“低串謀可能性”的樣本共有11 112條樣本,如圖4所示。
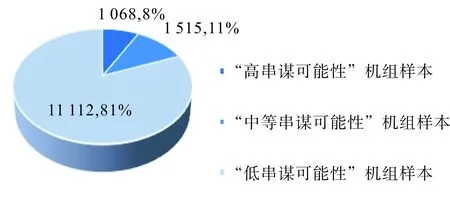
圖4 樣本分類Fig.4 Sample classification
4.2 半監督支持向量機識別模型的有效性驗證
為了驗證半監督支持向量機在串謀識別中的有效性。本文將所有樣本分為兩類,強串謀機組樣本作為正樣本,較強串謀機組樣本和無串謀機組樣本作為負樣本,由于正負樣本數相差巨大,嚴重影響識別的精度,且本文的目的是正確識別強串謀機組樣本即正確識別正樣本,因此對負樣本進行隨機分組,分為10組,每組有負樣本1 263條,將正樣本分別和10組負樣本進行組合,構成10個包含正負樣本的樣本集。
本文采用準確率、召回率及F-Measure對串謀識別模型進行評價,準確率表示所有被識別為正樣本的樣本中,真正的正樣本的比率;召回率是指所有正樣本中被識別為正樣本的比率;F-Measure是對準確率與召回率的一個綜合指標,3個評價指標的計算公式如下。
(28)
(29)
(30)
式中:Rpre為識別模型的準確率,準確率越大,被評價模型越好;Rrec為識別模型的召回率,召回率越大,被評價模型越好;F為識別模型的F-Measure,越接近于1越好;QTP為被正確識別的正樣本數量;QFP表示被識別成正樣本的負樣本數量;QFN為被識別為負樣本的正樣本數量。
不斷改變有標簽樣本數據的占比,用綜合指標F評價來評價模型,對10個樣本集分別進行測試,10組數據分別訓練模型得出的機組串謀識別結果統計如表5所示。
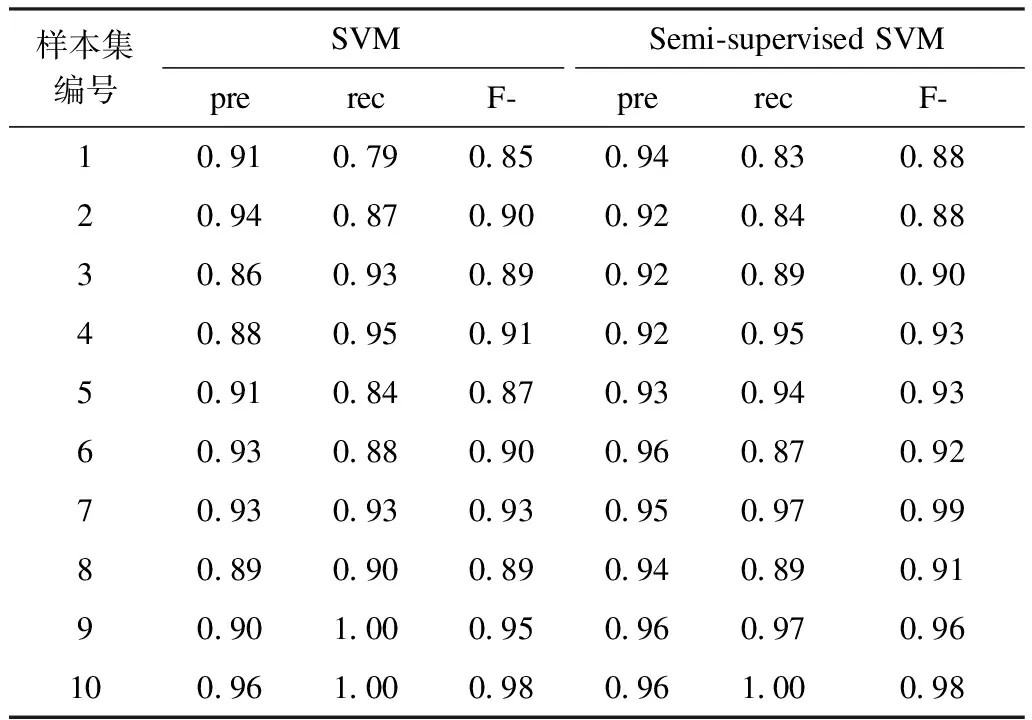
表5 機組串謀識別結果統計Tab.5 Statistics of unit collusion identification results
由表5可以看出,在10組樣本集進行模型訓練中,基于半監督支持向量機的串謀識別模型的識別效果明顯優于基于支持向量機的串謀識別模型。
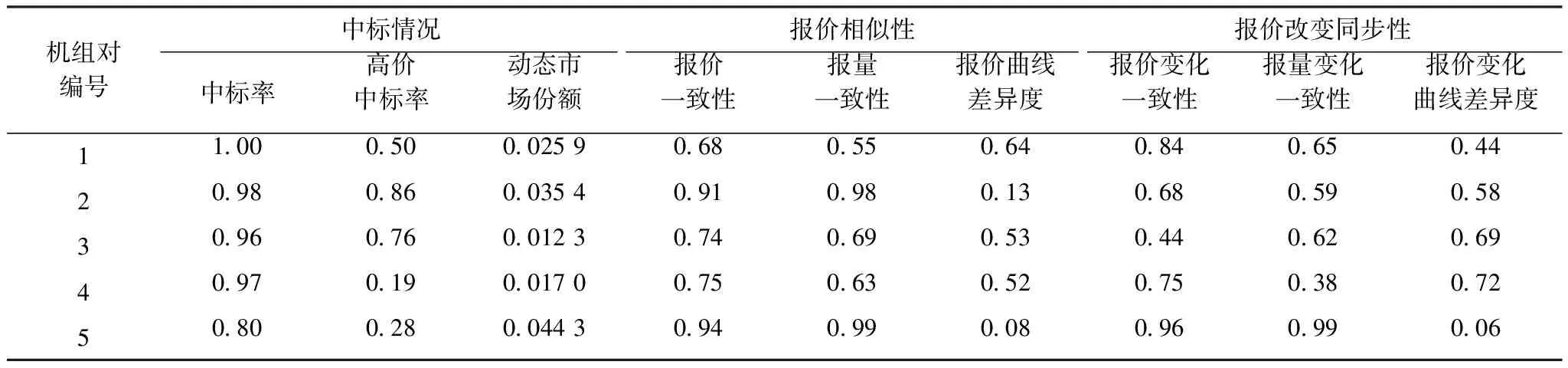
表6 半監督支持向量機模型的識別結果Tab.6 Recognition results of semi supervised SVM model
圖5為有標簽數據占比不同的模型結果。由圖5可以看出,隨著有標簽數據樣本的增多,模型的F值越近于1,模型越好。但當有標簽數據占比超過30%,模型的F值增加速度變慢,并趨于穩定。因此,本文采用30%的數據為有標簽數據來進行模型訓練。
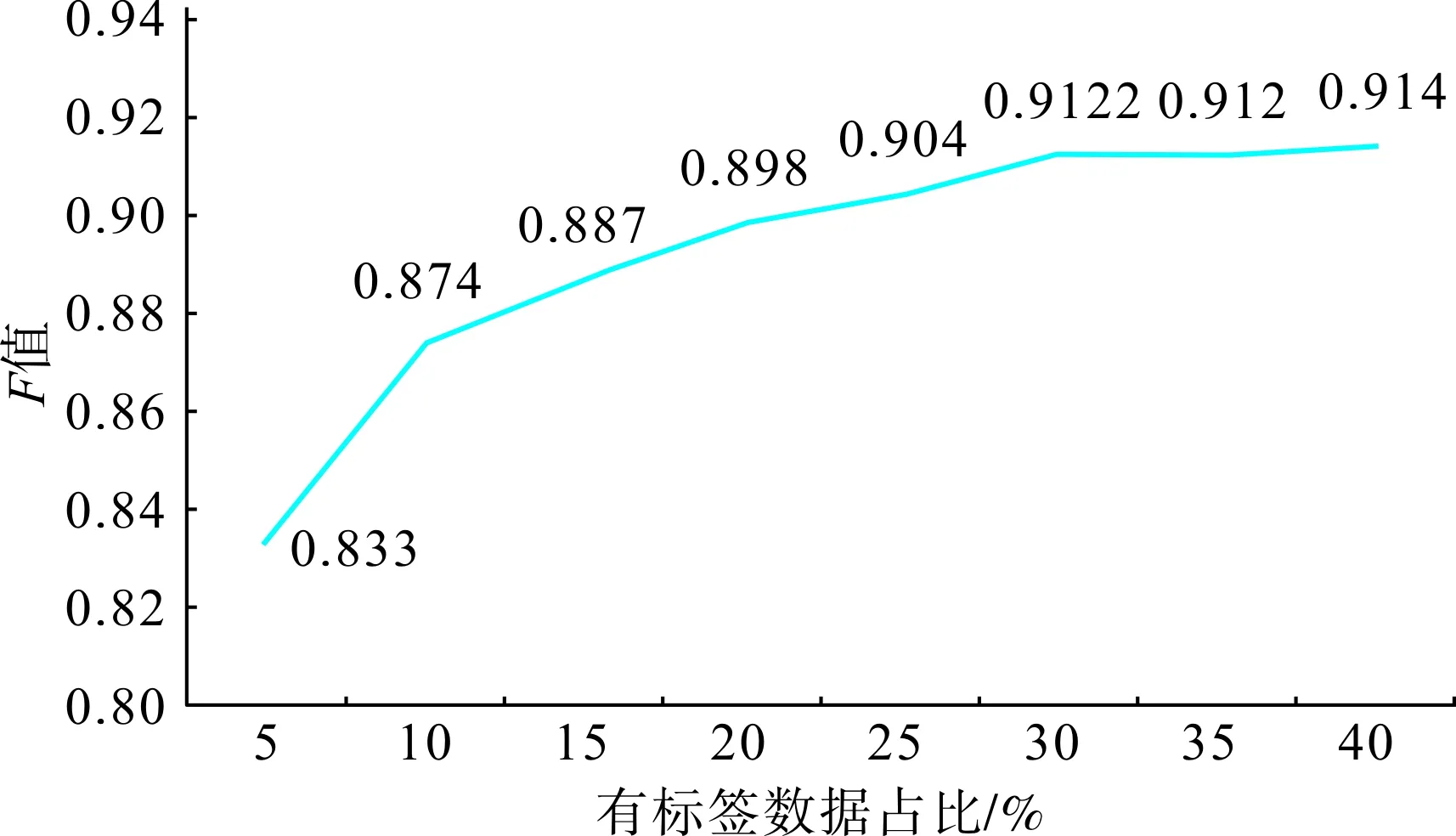
圖5 有標簽數據占比不同的模型結果Fig.5 Model results with different proportion of labeled data
對于每一個包含正負樣本的樣本集,其中30%為測試集,30%為有標簽的樣本,40%為無標簽的樣本,進行模型的訓練。并且將本文的半監督支持向量機方法和傳統支持向量機方法進行對比,其中第1組樣本集的結果展示如圖6所示。所有10組樣本集訓練的模型效果統計如表6所示。
表6對于市場中大量的未知數據,利用訓練完成的模型進行識別,識別出“高串謀可能性”機組。由表6可以看出,機組對1的中標率為1,說明其百分百中標,且其報價和報價變化均較為相似;機組對2中標率較大,且高價中標率指標大,報價和報價變化均較為相似;機組對5雖然其中標率和高價中標率指標較低,但其報價和報價變化非常相似,通過評估分值修正后,依然能夠達到較高的分值,以上機組被識別出,驗證了半監督支持向量機模型的正確性。
5 結論
本文在分析現貨市場機組串謀特點的基礎上,構建了新的機組對串謀識別指標體系。并根據機組串謀特征,將機組串謀狀態進行分類。在電力現貨市場無串謀機組樣本的情況下,利用Delphi法修正后的Topsis模型,對機組進行初步判別,形成模型的訓練集,然后提出了基于半監督支持向量機的串謀識別模型,經實例計算證明,該方法對現貨市場串謀機組的識別有較高的準確性。得到如下結論。
1)本文對現貨市場串謀機組的初步判定,是出于構建訓練集的目的。在判定的過程中,考慮了專家經驗,只適用于現貨市場建設初期,串謀機組樣本缺少的情況。當市場運營發展過程中發現了明確的串謀機組,就可利用市場中明確發現的機組作為訓練集。
2)綜合考慮現貨市場機組串謀特征以及串謀識別指標體系,將機組串謀狀態分為“強串謀”狀態、“較強串謀”狀態和“無串謀”狀態,有助于串謀機組的快速識別。
3)基于半監督支持向量機的串謀識別模型同時利用市場中的有標簽數據和無標簽數據進行訓練,提高了串謀識別的準確率,有助于防范現貨市場機組間的串謀行為。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
