基于深度強化學習算法的車輛行為決策研究
2022-05-18 04:26:34陳名松張澤功吳冉冉吳泳蓉
桂林電子科技大學學報 2022年1期
陳名松, 張澤功, 吳冉冉, 吳泳蓉
(桂林電子科技大學 信息與通信學院,廣西 桂林 541004)
近年來,隨著經濟發展和科技進步,我國城市居民汽車保有量持續增長,據國家統計局發布的2018國民經濟和社會發展統計公報顯示,2019年末全國民用私家車保有量達2.07億,比上年末增長9.37%。然而,汽車出行方便了日常生活的同時也帶來了一系列問題,據國家統計局數據顯示,2018年我國汽車交通事故發生數達到24.5萬起,造成人員傷亡23.5萬人次,直接財產損失13億8 456萬元。另有研究表明,駕駛員失誤導致的交通事故占交通事故總量的90%,主要因素有駕駛員分心、注意力不集中和疲勞駕駛等[1]。所以對于自動駕駛的研究成為一個熱點方向,谷歌、百度、AMD等企業及國內外研究人員均對此進行了相關研究。
自動駕駛是指車輛通過感知周圍環境并在無人工干預情況下進行自主駕駛的行為。首先車輛要感知周圍環境,識別駕駛環境中的行人、車輛、車道等信息。這一過程通常通過計算機視覺技術進行處理,通過對圖像進行獲取、處理、分析和理解等一系列步驟將現實世界中的高維度特征轉換成數字信息并輸入一個策略模型中,在動態的環境信息中,嘗試得到獎勵值最大的駕駛行為,實現最佳的決策。DQN算法[2]是深度強化學習算法的開山之作,它與自動駕駛技術的整合研究是一種非常流行且有效的方式。2015年,Mnih等利用卷積神經網絡計算Q函數,并利用該框架在Atari 2600游戲中成功達到超過職業玩家的水平。2016年,Bojarski團隊使用卷積神經網絡進行端到端自動駕駛系統的研究,通過將攝像頭獲取的數據送入CNN進行訓練,從而實現對方向盤的控制。Sallab團隊[3]利用DQN算法進行了車道保持輔助系統的仿真研究,通過對比實驗分析了不同終止條件下訓練得到的策略的區別。2017年,Chae等[4]利用DQN進行自主剎車系統研究,在經過7萬多次模擬試驗后,Agent可以學習到自主剎車的能力。夏偉等[5]提出了結合聚類算法和DQN算法的自動駕駛策略學習模型,也取得了一定效果。
雖然DQN在不同的模擬器上通過離散化方向盤和剎車等行為實現了對自動駕駛的模擬,但是DQN的本質依然與傳統的強化學習一樣旨在解決離散和低維動作空間,它會產生大量的狀態-動作對,不適用于像油門、剎車和方向盤這樣的連續動作空間。即使通過離散化將DQN應用于連續域也會引起維度災難等問題,不利于后續計算。針對上述問題,深度確定性策略梯度算法[6](deep deterministic policy gradient,簡稱DDPG)應運而生。DDPG算法是一種無模型、異策略的算法,它結合了DQN算法、A-C方法和DPG算法,在連續域控制問題上具有良好的表現,引起了學者們的廣泛關注。張斌等[7]將DDPG算法與策略動作過濾相結合,通過將策略網絡的多輸出改為單輸出來控制油門和剎車,降低了自動駕駛中的非法策略比。吳俊塔等[8]通過基于DDPG算法的多個子策略平均集成的方式進行自動駕駛行為的控制。
1 基于深度強化學習的自動駕駛模型
1.1 強化學習模型
強化學習是機器學習的一個分支,智能體Agent通過與環境的不斷交互學習,提高Agent對于未知環境的探索和適應能力,從環境探索中得到最大回報,從而學習到完整策略[7]。強化學習就是給一個馬爾科夫決策過程(MDP)尋找最優策略π,使得該策略下的累計回報期望最大。
所謂策略指狀態到動作的映射,即:
πθ(a|s)=p[At=a|St=s,θ],
(1)
表示在狀態s下指定一個動作a的概率。若策略是確定的,則給定一個確切動作。整個MDP過程可以用五元組(S,A,P,R,γ)表示,其中S為有限狀態集合,A為有限動作集合,P為狀態轉移概率,R為回報函數,γ∈[0,1]為折扣因子。當Agent與環境進行交互,在狀態st處的累計回報為
(2)
為了評價狀態s的價值和求解最優策略,引入狀態值函數υπ(s)和狀態-行為值函數qπ(s,a),實際應用中采用其貝爾曼方程:
υπ(s)=Eπ(Rt+1+γυπSt+1|St=s),
(3)
Qπ(s,a)=Eπ[Rt+1+γQ(St+1,At+1)|St=s,At=a]。
(4)
求解上述值函數有2種方法:基于表的方法和基于值函數逼近的方法[9]。基于表的方法包括傳統Q-learning和Sarsa算法,該類算法因為無法構建足夠大的Q值表,所以其應用局限于狀態-動作空間很小的情況。為了解決上述問題,DeepMind公司利用神經網絡來逼近狀態值函數,提出了結合深度學習和強化學習的DQN[10]算法,從而完整地表示了狀態-動作空間。
1.2 基于DDPG算法的行為決策框架
1.2.1 DPG算法
DPG算法[11]即確定性行為策略,根據式(1)定義了一個策略網絡。策略網絡的輸入是環境信息S,包括車輛距離車道的距離、車輛速度等,輸出為車輛要進行的下一步動作a,包括轉向、剎車、油門等控制信息,每步的行為通過策略函數直接獲得確定值,該策略網絡的目標函數定義為

Ex~p(x|θ)[R]。
(5)
其中策略網絡的目標函數梯度是狀態-行為值函數梯度的期望,如式(6)所示,這樣可以在不考慮動作空間維度的情況下更好地估計策略網絡目標函數的梯度,提高了計算效率。
(6)
1.2.2 DQN算法
DQN算法是第一個深度強化學習算法,其利用神經網絡對狀態-行為值函數進行擬合,狀態-行為值函數可表示為
Qπ(S,a)≈Q(s,a,w),
(7)
其中ω為神經網絡的的權重,結合式(6),可得DDPG算法:
(8)
1.2.3 DDPG算法流程
DDPG算法將上述2種算法進行了融合,如圖1所示,該算法由Actor(策略)模塊、Critic(評價)模塊和經驗池組成。其中Actor和Critic模塊分別利用神經網絡對策略函數和Q函數進行擬合。同時,由于Actor網絡與環境交互所產生的時間序列是高度相關的,直接利用這些數據進行網絡訓練會導致網絡過擬合,不易收斂。因此,借鑒DQN算法,引入了經驗回放機制(experience replay),通過在經驗池中進行隨機批量取樣對網絡進行訓練,解決了上述問題。
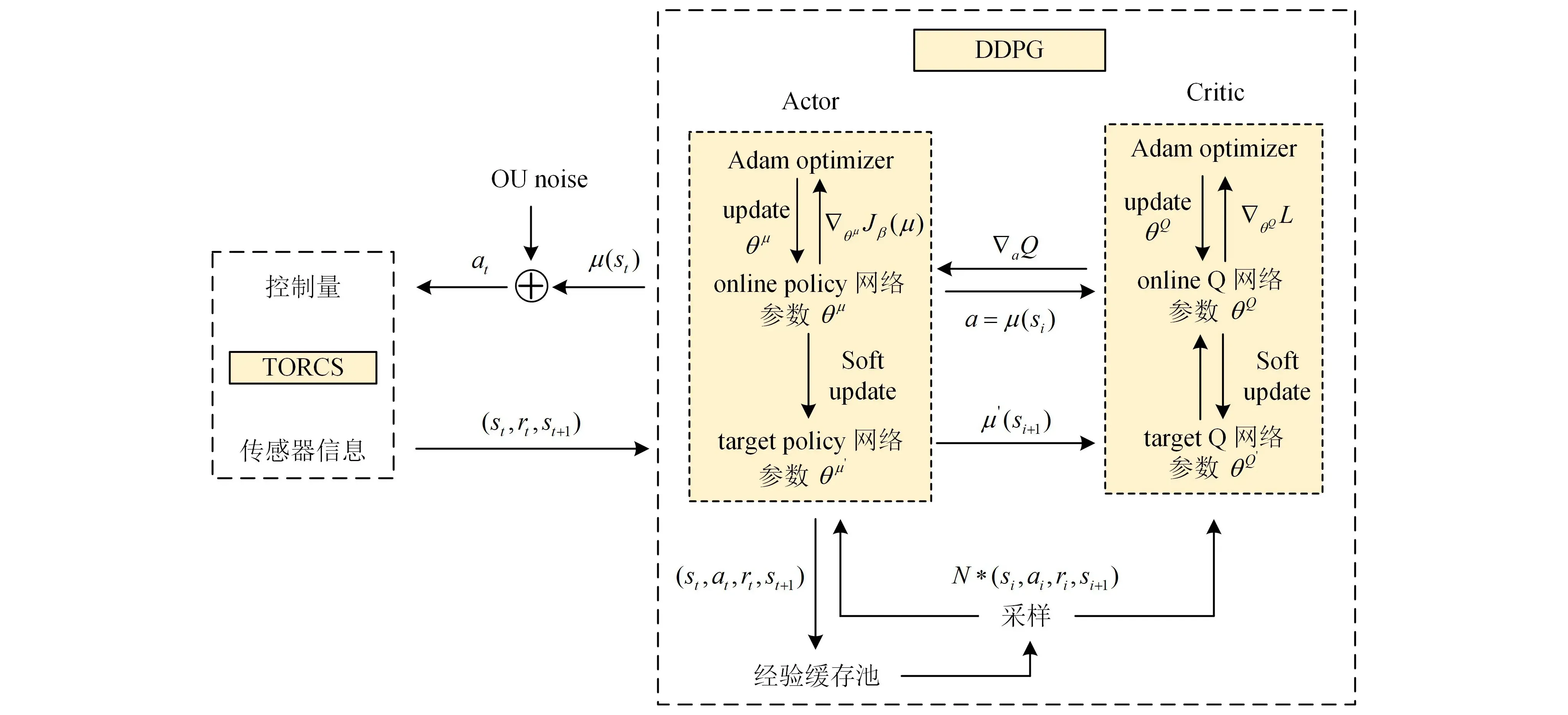
圖1 基于DDPG算法的車輛決策流程
Actor-Critic方法將策略梯度算法和值函數結合在一起。Actor網絡產生當前策略,輸出動作;Critic網絡對該動作進行評判。然后,基于此評判,Actor網絡調整其網絡權重,使得輸出的動作在下一次變得更好。為提高算法訓練的穩定性,DDPG中引入了Target-Actor網絡和Target-Critic網絡,初始結構和參數均與其對應的Actor和Critic網絡一致,后續則根據式(9)即圖中的Soft Update進行參數更新,其中θQ、θQ′、θπ、θπ′分別為Target-Critic網絡、Critic網絡、Target-Actor網絡和Actor網絡的參數。
(9)
2 改進的DDPG算法
為提高算法的訓練效率和網絡的穩定性,針對傳統DDPG算法提出以下幾點改進,主要包括將引導學習和優選經驗回放結合,以下稱之為LS-DDPG。
2.1 引導式學習
一般而言,新手在完成一項任務時,需要具有經驗的師傅對其進行指導,這樣完成任務的效率和準確率會比獨自探索高很多。受此啟發,在利用傳統DDPG算法對TORCS中的車輛進行自動控制時,引入一個專業的控制器,將其作為“老師”來引導,進行網絡預訓練。傳統DDPG算法對于Critic網絡的訓練是通過隨機抽取經驗緩存池中的經驗樣本數據并送入Critic網絡中進行批訓練,經驗數據根據回報函數得到評估值Q。對于Actor網絡的訓練過程則是利用環境信息S對動作a的梯度來進行訓練。
引導式學習的DDPG算法對于網絡的訓練包括預訓練和正常訓練2個階段。預訓練階段不涉及強化學習的內容,僅利用專業控制器來進行網絡訓練,得到一個預訓練模型。在后期強化學習的正式訓練中,先加載此預訓練模型進行Agent與環境的交互,通過采取特定策略,使得訓練前期預訓練模型在動作的輸出方面占主導,然后逐漸減少預訓練模型的主導作用,Actor網絡逐漸占據主導。這樣允許Actor網絡在學習引導行為的同時可以探索更多引導行為之外的動作。
2.2 優選經驗回放
傳統DDPG算法利用經驗回放機制將Agent與環境交互得到的經驗樣本存儲到經驗緩存池中,然后通過隨機抽取BATCH_SIZE數據進行Actor網絡和Critic網絡。這種處理方式消除了經驗樣本之間的相關性,提高了網絡訓練的穩定性。但由于經驗樣本的選取是隨機的,選取的經驗樣本質量參差不齊,網絡訓練速度和效率較低。為解決此問題,Schaul等[12]提出了優先經驗緩存機制(prioritized experience replay),通過計算TD-error得到經驗樣本的重要程度,將重要程度較大的數據送入神經網絡進行訓練。這種算法對于加速神經網絡的收斂有一定作用,但是算法復雜度較高。本著不提升算法復雜度同時提高神經網絡的訓練效率的原則,利用經驗池分離原則,采用優選經驗樣本回放的方式對DDPG算法進行改進。
1)經驗樣本分離存儲。優選經驗樣本回放需要通過設置閾值區分樣本的優劣,然后分別存入不同的經驗池。劣勢樣本包括脫離軌道的經驗樣本、發生碰撞的經驗樣本以及rt為負值的經驗樣本等。同時,根據對應測試的賽道寬度d和車身寬度l設置經驗存放閾值dth=(d-l)/d。車輛行駛在賽道閾值以外所得到的經驗被認定為劣勢樣本,反之則為優勢樣本。
2)調整經驗樣本抽取比例。按一定比例α從不同的經驗池抽取經驗樣本,在1個批處理樣本中2類樣本必須同時存在,以防止神經網絡達到局部最優。同時優勢樣本與劣勢樣本的抽取比例α隨著當前訓練步數的增加而逐漸降低,防止Agent學習到的策略網絡過擬合。
3)降低策略網絡和目標網絡的更新頻率。DDPG算法涉及到了2個神經網絡,且每次都在連續狀態中更新參數,每次參數更新前后都存在相關性。若評價網絡某次評價產生過估計的情況,則在利用差分誤差進行頻繁的網絡參數更新時會導致誤差累積放大,策略更新向著發散的方向進行,不利于算法收斂。因此,應該控制策略網絡和目標網絡的更新頻率低于評價網絡,即在進行策略網絡更新前,最小化估計誤差。
2.3 LS-DDPG算法流程
主網絡和目標網絡的參數初始化方式均為隨機初始化,OU噪聲的添加會隨著訓練步數的增加而改變,是一個線性改變的過程,這樣可以控制預訓練權重和策略網絡的主導比重。LS-DDPG算法偽代碼如下。
1:初始化Actor網絡π(s,θπ)和Critic網絡Q(st,at,θQ), 經驗池大小N, BATCH_SIZE大小M;
2:初始化Target-Actor網絡π′(s,θπ′)和Target-Critic網絡Q′(st,at,θQ′);
3:創建經驗緩存池Bs和Bf, 并設置經驗緩存閾值dth, 加載預訓練權重;
4:Episode循環開始:
5:選擇始化狀態st, 初始化OU噪聲;
6:Step循環開始:
7:將OU噪聲添加到動作策略中, Actor網絡根據當前策略做出動作at;
8:將at送入TORCS環境中, 轉化成車輛控制動作執行, 得到當前動作的回報值rt和新的環境值st+1;
9:根據rt是否大于0與當前環境信息中的車輛位置是否大于dth決定(st,at,rt,st+1,done)存入對應的經驗池;
10:根據樣本采樣比例α, 在Bs和Bf分別采樣數據, 采樣數據總量為M;
11:通過Target-Critic網絡計算當前動作的期望回報;
13:當Step到達設置的Actor網絡的更新頻率時:
15:利用式(9)更新Target網絡;
16:結束Step循環;
17:結束Episode循環。
3 實驗設計
3.1 實驗運行環境
實驗運行環境為Ubuntu 16.04,Python 3.6,Keras 2.1.6,Tensorflow 1.13.2,CUDA 10.0.130,CUDNN 7.5.0,gym,TORCS仿真平臺,地圖為A-Speedway地圖。CPU為Intel i7 7800X,GPU為GTX 2080TI,運行內存32 GiB。
3.2 實驗設計
實驗中對于DDPG算法、LS-DDPG算法設計均采用2層隱藏層的全連接神經網絡,隱藏單元數分別為600、300,而后actor網絡緊接著的3個全連接層的輸出分別對應智能體的轉向、油門和剎車3個控制變量。轉向的取值范圍為[-1,1],分別代表向左到底和向右到底;油門和剎車的取值范圍為[0,1],分別代表不踩踏板和將踏板踩到底。算法中將以下函數作為獎勵函數:
r=(1-tracPos)(Vxcosθ-Vx|sinθ|-
(10)
網絡訓練均以當前賽道的10圈作為目標,而后分析算法的總回報、平均回報、收斂速度及模型表現與訓練步數的關系。
4 實驗結果分析
實驗進行了對于傳統DDPG算法的實現,并在A-Speedway地圖上進行了訓練,訓練中設置了4個約束條件,以便讓小車能夠正確地行駛,盡量行駛在道路中央。這4個約束條件為:1)在車輛與周邊環境中的障礙物發生碰撞時,即時回報值為-50;2)在車輛行駛出當前車道時,即時回報值為-100,且有20%的概率結束此次行駛,重啟TORCS客戶端;3)當車輛行駛100步依然沒有進展或者車輛行駛速度低于5 km/h時,結束當前回合;4)當車輛運行中車身角度處于[-90,90]以外時,結束當前回合。
在DDPG算法運行過程中發現,當車輛學習到的速度過高(超過200 km/h),在進行轉彎時會脫離軌道,對于剎車的學習不理想。長期學習不到會導致車輛一直陷于學習如何順利度過當前彎道的情況,導致算法收斂時間變長,效率降低。因此,在進行LS-DDPG算法訓練時,為了讓車輛學習到更準確的駕駛技能,提高駕駛準確性和算法效率,更改了第2個限制條件來進行彎道行駛的限制,即當前車輛車身靠近車道線邊緣達到閾值但未駛出車道時,返回即時回報值為-100;若車駛出了車道,則返回即時回報值為-200,并結束當前回合。同時,為消除車輛行駛速度過高這種不符合實際情況的狀況,在車輛學習的后期,對于油門進行一定控制,主動剎車降低車速。
4.1 有效行駛距離
圖2和圖3分別為LS-DDPG和DDPG算法訓練車輛在賽道上跑10圈的狀況下,訓練輪數和車輛每輪的行駛距離。DDPG算法下訓練567輪行駛了78 102步,LS-DDPG算法訓練了192輪行駛了61 942步。LS-DDPG相比DDPG算法,訓練輪數上減少了375輪,效率提升了66.14%;訓練步數降低了16 160步,效率提升了20.07%;LS-DDPG平均每輪行駛322步,DDPG算法平均每輪行駛138步,平均每輪行駛步數增加184步,有效行駛距離提升133%。LS-DDPG算法下車輛所學習到的策略從剛開始訓練就比DDPG算法具有更長的有效行駛距離,會減少很多無效操作,提高了車輛探索的效率。后期在完成1圈的情況下,LS-DDPG算法會行駛比DDPG算法更多的步數。這是由于LS-DDPG算法在訓練時有意地控制了其在訓練后期的車輛速度,所以在后期LS-DDPG算法訓練的車輛行駛速度沒有DDPG算法高,導致同樣的行駛距離下行駛步數會相對較高。

圖2 LS-DDPG算法中每個回合的訓練步數

圖3 DDPG算法中每個回合的行駛步數
4.2 回報值
圖4和圖5分別為LS-DDPG和DDPG算法在訓練中對應的訓練輪數和總回報的關系。LS-DDPG算法下的總回報在小范圍內變動較大,在150輪后基本呈平穩上升狀態。DDPG算法在400輪后呈平穩上升狀態。圖6和圖7分別為LS-DDPG和DDPG算法在訓練中對應的訓練輪數和平均回報的關系。LS-DDPG算法在前期由于添加了更加嚴格的懲罰項,導致平均回報較小,但在120輪后會有良好的提升,后期整體處于平穩。DDPG算法在65輪后平均回報穩步上升,在訓練后期平均回報高于LS-DDPG算法。由于上述提到速度控制的原因,導致LS-DDPG算法訓練的車輛后期速度沒有DDPG算法訓練的高,回報值相比DDPG算法小。但是在行駛表現中,LS-DDPG算法訓練出來的車輛在轉彎時會更多地減速慢行,更符合人類的實際操控。

圖4 LS-DDPG算法中隨回合數變化的總回報值

圖5 DDPG算法中隨回合數變化的總回報值

圖6 LS-DDPG算法中每個回合的平均回報值

圖7 DDPG算法中每個回合的平均回報值
5 結束語
分析了DDPG算法下的自動駕駛決策策略,并對傳統DDPG算法進行了改進。在TORCS平臺上驗證了改進算法在訓練效率和有效行駛距離上的提升。但該實驗僅在單車輛且環境相對簡單的情況下進行,缺少在復雜環境下的解決能力,且DDPG算法在高速行駛下也無法高效地學會剎車。如何根據現實情況進行更加規范的駕駛行為是下一步要研究的內容。
猜你喜歡
黨課參考(2021年20期)2021-11-04 09:39:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小哥白尼(軍事科學)(2019年6期)2019-03-14 05:49:56
黨課參考(2018年20期)2018-11-09 08:52:36
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
