全卷積注意力機(jī)制神經(jīng)網(wǎng)絡(luò)的圖像語(yǔ)義分割
2022-05-17 06:02:02歐陽(yáng)柳瞿紹軍
計(jì)算機(jī)與生活 2022年5期
歐陽(yáng)柳,賀 禧,瞿紹軍,2+
1.湖南師范大學(xué) 信息科學(xué)與工程學(xué)院,長(zhǎng)沙410081
2.湖南師范大學(xué) 湖南湘江人工智能學(xué)院,長(zhǎng)沙410081
語(yǔ)義分割(semantic segmentation)是計(jì)算機(jī)視覺(jué)核心研究熱點(diǎn)之一,其目的是為圖像劃分成具有語(yǔ)義信息的區(qū)域,并給每個(gè)區(qū)域塊分配一個(gè)語(yǔ)義標(biāo)簽,最終得到每個(gè)像素都被語(yǔ)義標(biāo)注的分割圖像。語(yǔ)義分割是室內(nèi)導(dǎo)航、地理信息系統(tǒng)、人機(jī)交互、自動(dòng)駕駛、虛擬增強(qiáng)現(xiàn)實(shí)系統(tǒng)、場(chǎng)景理解、醫(yī)學(xué)圖像處理以及目標(biāo)分類(lèi)等視覺(jué)分析的基礎(chǔ)。復(fù)雜環(huán)境的非結(jié)構(gòu)化、目標(biāo)多樣化、形狀不規(guī)則化以及光照變化、物體遮擋等各種因素都給語(yǔ)義分割帶來(lái)巨大的挑戰(zhàn)。近年來(lái),深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域的應(yīng)用越來(lái)越廣泛,卷積神經(jīng)網(wǎng)絡(luò)的分割算法(convolutional neural network,CNN)在圖像分割領(lǐng)域取得了突破性的進(jìn)展。語(yǔ)義分割是圖像理解中的常用技術(shù),它可以預(yù)測(cè)圖像中每個(gè)像素的類(lèi)別,實(shí)現(xiàn)對(duì)圖像的分割歸類(lèi),對(duì)圖像進(jìn)行細(xì)致的理解。Long 等人提出的全卷積網(wǎng)絡(luò)(fully convolutional network,F(xiàn)CN)在圖像分割任務(wù)上表現(xiàn)出巨大的潛力。在深度學(xué)習(xí)的發(fā)展之下,借用深層次卷積神經(jīng)網(wǎng)絡(luò)可以從圖像中學(xué)習(xí)具有不同層次的特征表示方法。全卷積網(wǎng)絡(luò)將分類(lèi)網(wǎng)絡(luò)應(yīng)用到卷積網(wǎng)絡(luò)中,將傳統(tǒng)卷積神經(jīng)網(wǎng)絡(luò)中的全連接層替換為卷積層,使用跳躍層的方法組合中間卷積層產(chǎn)生的特征圖,然后進(jìn)行轉(zhuǎn)置卷積。由于跳躍層和轉(zhuǎn)置卷積的原因,F(xiàn)CN 的預(yù)測(cè)結(jié)果和原始圖像相同。FCN 兼顧全局語(yǔ)義信息和局部語(yǔ)義信息,將圖像級(jí)別分類(lèi)延伸到了像素級(jí)分類(lèi)。FCN使用卷積層替換了CNN 中的全連接層,存在兩個(gè)問(wèn)題:(1)隨著卷積池化,分辨率在不斷縮小,造成部分像素丟失;(2)沒(méi)有考慮特征圖原有的上下文的信息。因此,大量的研究人員在此基礎(chǔ)上提出了改進(jìn)的語(yǔ)義分割模型,如PSPNet(pyramid scene parsing network)中金字塔池化模塊能夠融合多尺度的上下文信息,有效利用了上下文信息。Ronneberger 等人提出了一種編碼器-解碼器的網(wǎng)絡(luò)模型U-Net(U 型網(wǎng)絡(luò))。U-Net 由收縮路徑和擴(kuò)展路徑組成,收縮路徑利用下采樣捕捉上下文信息,提取特征,擴(kuò)展路徑是一個(gè)解碼器,使用上采樣操作還原原始圖像的位置信息,逐步恢復(fù)物體細(xì)節(jié)和圖像分辨率。OCNet(object context network)通過(guò)計(jì)算每個(gè)像素與所有像素的相似度,形成一個(gè)目標(biāo)上下文特征圖,然后通過(guò)聚合所有像素的特征來(lái)表示該像素。DeepLab-v3 網(wǎng)絡(luò)中將帶孔卷積和空洞金字塔池化方法結(jié)合,構(gòu)建了空洞空間金字塔池化模塊(atrous spatial pyramid pooling,ASPP)。通過(guò)使用不同空洞率的卷積來(lái)捕獲多尺度的上下文信息,有效增強(qiáng)了感受野,提高分割結(jié)果的空間精度。
受到OCNet 和DeepLab-v3 的啟發(fā),本文提出了空洞空間金字塔注意力模塊(atrous spatial pyramid pooling attention module,ASPPAM)和位置注意力模塊(position attention module,PAM),在多個(gè)并行分支中使用多個(gè)不同空洞率的卷積來(lái)獲取不同尺度的上下文信息,加入一個(gè)計(jì)算像素之間相關(guān)性的模塊,用以增強(qiáng)像素之間相關(guān)度。高層特征涉及整個(gè)場(chǎng)景的理解,保留了物體的綜合特征,低級(jí)語(yǔ)義信息具有非常豐富的空間信息,保留了很多細(xì)節(jié),PAM 將高級(jí)信息和低級(jí)信息進(jìn)行融合,可以很好地處理圖像的邊緣和細(xì)節(jié),以解決高級(jí)語(yǔ)義信息丟失的問(wèn)題。
本文的主要貢獻(xiàn)如下:
(1)為了學(xué)習(xí)像素之間的相關(guān)性,提出了PSAM(pixel similarity attention module),并將其嵌入ASPP模塊,增強(qiáng)了像素之間的聯(lián)系,得到新的ASPPAM,豐富ASPP 上下文信息。
(2)提出了PAM,通過(guò)融合低層特征和高級(jí)特征,突出低層特征細(xì)節(jié)信息和邊緣信息,提高分割效果。
(3)將ASPPAM 和PAM 結(jié)合,提出一種新的基于注意力感知的全卷積網(wǎng)絡(luò)CANet(context attention network),并在Cityscapes測(cè)試集中取得了較好的結(jié)果。
1 相關(guān)工作
1.1 基于神經(jīng)網(wǎng)絡(luò)方法的語(yǔ)義分割
FCN 極大地推動(dòng)了圖像語(yǔ)義分割的發(fā)展,并且成為許多神經(jīng)網(wǎng)絡(luò)的基本模型。目前提高語(yǔ)義分割的方法有:Deeplab-v1 中使用空洞卷積代替池化層,加上條件隨機(jī)場(chǎng)(conditional random fields,CRFs),目的是改善深度神經(jīng)網(wǎng)絡(luò)的輸出結(jié)果,捕捉邊緣細(xì)節(jié)。該方法的缺點(diǎn)是沒(méi)有注意圖像的多尺度信息,對(duì)小物體分割的分割效果不明顯。進(jìn)而在DeepLabv2 中加入了空洞空間金字塔池化模塊(ASPP)。使用不同的空洞率的卷積來(lái)得到不同的感受野,空洞率小的感受野小,對(duì)小物體識(shí)別效果較好,空洞率大的感受野大,對(duì)大物體的識(shí)別效果好,解決了物體的多尺度信息的問(wèn)題。但是隨著空洞率的增大,卷積核的有效參數(shù)越來(lái)越少,最終會(huì)退化成1×1 的卷積核。在PSPNet中,作者提出了一個(gè)全局先驗(yàn)結(jié)構(gòu),將輸入劃分為不同大小的區(qū)域塊,分別對(duì)這些塊進(jìn)行特征提取,然后上采樣到和輸入尺寸一樣大小,將所有得到的特征在通道上進(jìn)行合并,將不同尺度的特征信息進(jìn)行融合,提高了分割的性能。
1.2 空洞空間金字塔池化
空洞空間金字塔池化是在金字塔池化模塊基礎(chǔ)之上引入了空洞卷積而形成。語(yǔ)義分割中池化層增大感受野的同時(shí),也會(huì)減少圖像的尺寸,然后在上采樣擴(kuò)大圖像尺寸來(lái)獲取分割圖。在通過(guò)池化層時(shí),整個(gè)圖像分辨率會(huì)變小,隨后進(jìn)行上采樣,分辨率會(huì)擴(kuò)大,整個(gè)過(guò)程中必然會(huì)丟失一些信息。如何在不通過(guò)池化層也能達(dá)到增大感受野的效果,空洞卷積是一個(gè)很好的方案。空洞卷積在傳統(tǒng)的卷積核的每個(gè)像素之間填充一定的像素,目的是可以增大感受野。空洞卷積存在一定的缺陷,在空洞率(填充像素變量)越來(lái)越大的同時(shí),卷積核中的不連續(xù)會(huì)造成卷積核中參數(shù)不能全部用于計(jì)算,這會(huì)導(dǎo)致卷積核退化成1×1 的卷積核,提取特征效果會(huì)降低,空洞空間金字塔的解決方案是:將輸入的特征圖進(jìn)行全局平均池化,外加一個(gè)1×1 的256 通道的卷積層和批處理化層。
1.3 編碼器-解碼器結(jié)構(gòu)
在圖像分割領(lǐng)域要解決“池化操作后特征圖分辨率不斷降低,部分像素空間位置信息丟失”等問(wèn)題,除了對(duì)卷積結(jié)構(gòu)進(jìn)行優(yōu)化之外,另一類(lèi)方法是使用編碼器-解碼器結(jié)構(gòu)。編碼器通常由多個(gè)卷積層和池化層組成,作用是從原圖中獲取含有位置信息和語(yǔ)義信息的特征圖,解碼器通常由反卷積層和反池化層構(gòu)成,作用是恢復(fù)特征圖中丟失的空間維度信息和位置信息,生成稠密的預(yù)測(cè)圖。編碼器使用卷積或者池化等操作來(lái)獲取圖像的空間位置信息和圖像的特征信息,卷積或者池化都會(huì)使得圖像的分辨率降低,為了得到和原圖像相同分辨率大小的分割圖,解碼器就是為了恢復(fù)圖像分辨率存在的,解碼器使用轉(zhuǎn)置卷積或者上池化,使得縮小的特征圖恢復(fù)原圖像的分辨率的大小,還原原始圖像的空間位置信息和圖像細(xì)節(jié)信息。U-Net 就是典型的編碼器和解碼器結(jié)構(gòu)。在編碼器過(guò)程使用下采樣操作,縮小分辨率,在解碼器使用上采樣操作,逐步恢復(fù)物體的空間位置信息和圖像分辨率。
1.4 注意力模塊
注意力機(jī)制的基本思想是在運(yùn)算中忽略無(wú)關(guān)信息而關(guān)注重點(diǎn)信息,通過(guò)注意力機(jī)制學(xué)習(xí)上下文信息,并且進(jìn)行優(yōu)化得到自我注意力模塊,捕獲數(shù)據(jù)或者特征的內(nèi)部相關(guān)性。PANet(path aggregation network)中作者認(rèn)為高層的特征信息可以對(duì)低層的特征信息進(jìn)行指導(dǎo),因此注意力機(jī)制必須發(fā)生在不同的層之間。解碼器的作用在于恢復(fù)像素類(lèi)別的位置信息,經(jīng)過(guò)編碼器提取的特征帶有充分的分類(lèi)信息可以作為指導(dǎo)低層的信息。Woo 等人提出了一種輕量、通用的注意力模塊(convolutional block attention module,CBAM)。該模塊分別在特征圖的空間和通道上引入注意力模塊,在不顯著增加計(jì)算量和參數(shù)量的前提下能提升網(wǎng)絡(luò)模型的特征提取能力。文獻(xiàn)[19]提出了自我注意力機(jī)制,并將其運(yùn)用到視頻動(dòng)作識(shí)別任務(wù),自我注意力機(jī)制可以有效地捕捉不同位置之間的遠(yuǎn)程依賴(lài)關(guān)系,每個(gè)位置都可以在不造成特征圖退化的情況下獲得全局感受野。OCNet中,使用自我注意力機(jī)制來(lái)計(jì)算像素之間的相似度,通過(guò)利用同一目標(biāo)的其他像素來(lái)為當(dāng)前像素分類(lèi),獲取目標(biāo)上下文,并且在金字塔池化模塊和空洞空間金字塔池化模塊上做了實(shí)驗(yàn),結(jié)果在Cityscapes和ADE20K數(shù)據(jù)集上取得了SOTA(state of the art)的結(jié)果。
2 本文方法
本章首先介紹論文提出的語(yǔ)義分割網(wǎng)絡(luò)CANet的整體結(jié)構(gòu),然后分別詳細(xì)介紹ASPPAM 和PAM,損失函數(shù)采用常用的交叉熵?fù)p失函數(shù)。
2.1 網(wǎng)絡(luò)的整體結(jié)構(gòu)
本文的整體網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示,該模型由擴(kuò)展的FCN、ASPPAM 和PAM 三個(gè)摸塊組成。采用在ImageNet 上預(yù)先訓(xùn)練的ResNet-101的擴(kuò)展為主干網(wǎng)絡(luò),并且去掉ResNet 最后的全連接層,圖1 中每個(gè)帶有“Res”字樣的藍(lán)色塊的詳細(xì)結(jié)構(gòu)如表1 所示,“7×7,64,stride:2”表示卷積核為7×7,輸出通道數(shù)為64,步長(zhǎng)為2。Res 每個(gè)大塊都包含一個(gè)基本結(jié)構(gòu)(Baseblock:包含殘差(residual)結(jié)構(gòu)),具體結(jié)構(gòu)如表1 中Res 塊的矩陣所示,“1×1,64”表示卷積核為1×1,輸出通道數(shù)為64。矩陣外的“×3”表示輸入數(shù)據(jù)將會(huì)執(zhí)行這個(gè)矩陣結(jié)構(gòu)3 次,后續(xù)結(jié)構(gòu)以此類(lèi)推。在Res4 塊后添加ASPPAM(空洞空間金字塔注意力模塊)來(lái)提取深度特征,獲得高級(jí)語(yǔ)義信息,此時(shí)特征映射的大小減小到原始圖像的1/8。同時(shí),將低級(jí)語(yǔ)義信息傳到PAM(位置注意力模塊),PAM 主要關(guān)注低級(jí)語(yǔ)義信息中的邊緣信息和細(xì)節(jié)信息,補(bǔ)充高級(jí)語(yǔ)義信息丟失的空間信息,最后將兩個(gè)注意力模塊的輸出特征進(jìn)行融合,經(jīng)過(guò)上采樣恢復(fù)成最終的預(yù)測(cè)分割圖。
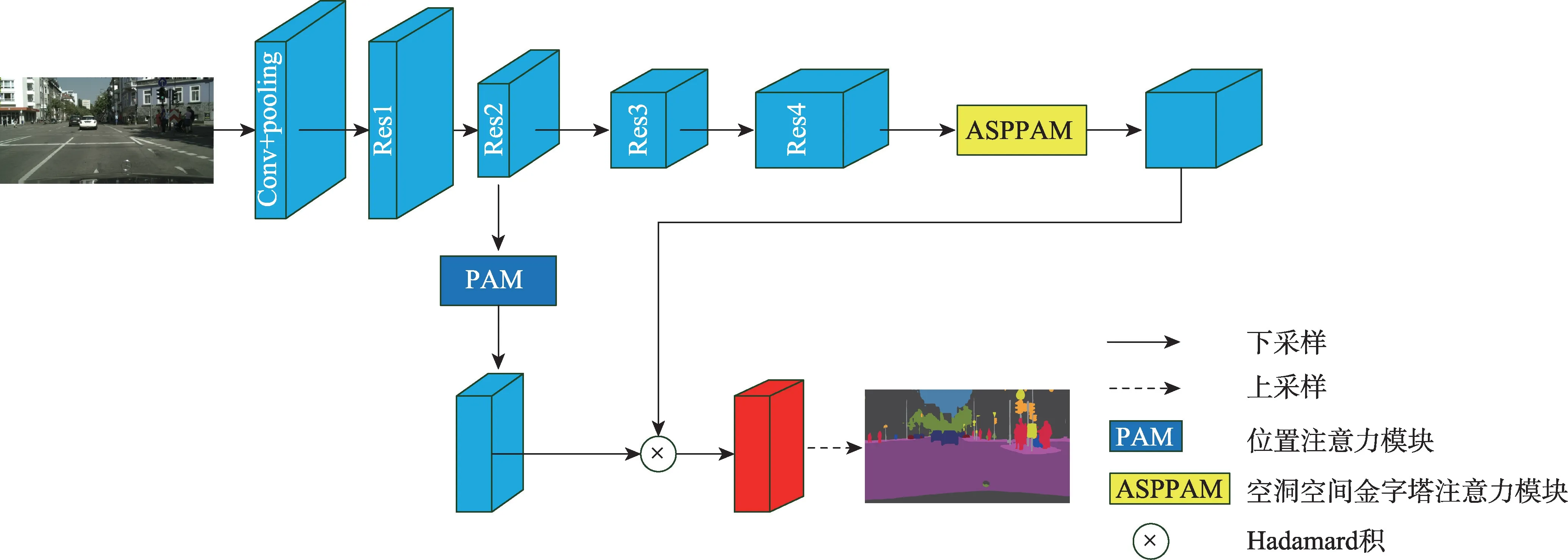
圖1 CANet網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.1 CANet network structure diagram
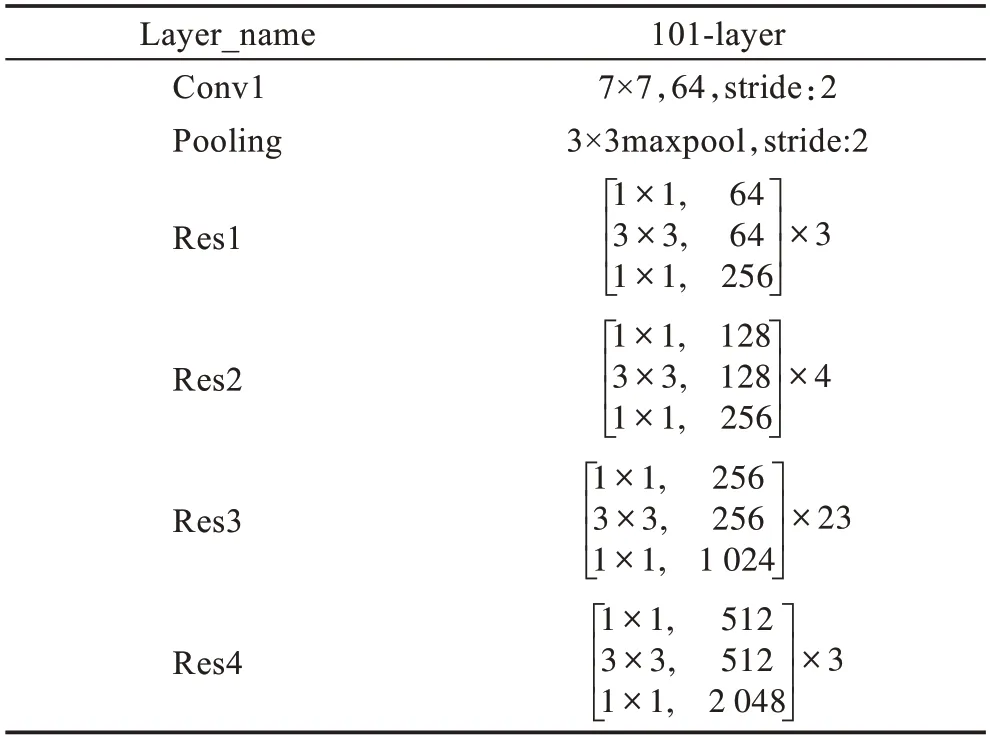
表1 ResNet-101 四個(gè)塊的結(jié)構(gòu)Table 1 Four blocks structure of ResNet-101
2.2 空洞空間金字塔注意力模塊
ASPPAM 結(jié)構(gòu)將深度神經(jīng)網(wǎng)絡(luò)的部分卷積層替換為空洞卷積,在不增加參數(shù)的情況下,擴(kuò)大了感受野,從而獲得更多的特征信息。1×1 Conv 卷積的目的是防止空洞率過(guò)大造成卷積核參數(shù)不能完全利用的問(wèn)題。針對(duì)空洞卷積造成的空間信息丟失的問(wèn)題,DeepLab-v3 采用的是引入解碼器結(jié)構(gòu)來(lái)恢復(fù)目標(biāo)的空間信息。空間信息的丟失不利于像素級(jí)的分類(lèi)任務(wù),本文采用的是在提取特征的并列結(jié)構(gòu)上加入上下文注意力模塊來(lái)解決這個(gè)問(wèn)題。像素注意力模塊的作用是增強(qiáng)像素之間的聯(lián)系,注意力機(jī)制的作用就是將重點(diǎn)放在所注意的目標(biāo)像素上,增強(qiáng)目標(biāo)像素的權(quán)重,ASPPAM 模塊中的空洞卷積則是獲取不同尺度的上下文信息。原始圖片如圖2 所示,大小和通道數(shù)分別為(1 024,2 048)和3,將經(jīng)過(guò)ResNet-101 提取的高級(jí)特征圖可視化,高級(jí)特征圖大小和通道數(shù)分別為(128,256)和512,橫縱坐標(biāo)為分辨率,高級(jí)特征的通道可以看作特定類(lèi)的響應(yīng),將高級(jí)特征圖可視化為512張單通道的圖片,圖3為未使用ASPPAM模塊得到的高級(jí)特征圖,圖中部分特征圖因丟失像素嚴(yán)重和相關(guān)類(lèi)別像素的缺失導(dǎo)致提取特征為空,可視化結(jié)果為黑色,這個(gè)問(wèn)題不利于后續(xù)像素預(yù)測(cè)任務(wù)。圖4 為使用了ASPPAM 模塊可視化的高級(jí)特征圖,相關(guān)類(lèi)別的特征更加聚集,特征為空的現(xiàn)象減少了很多(可視化結(jié)果為黑的特征圖),丟失像素的問(wèn)題得到了解決。從圖4 中可以看出,所提出ASPPAM 模塊起到了一定的作用。SENet(squeeze-and-excitation network)通過(guò)特征圖學(xué)習(xí)特征權(quán)值,然后通過(guò)單位乘的方式得到一個(gè)加權(quán)后的新的特征圖,采用池化操作來(lái)傳播注意力特征圖,但是忽略了像素本身就具有一定的關(guān)系。

圖2 原始圖片F(xiàn)ig.2 Original picture

圖3 未使用ASPPAM 提取的高級(jí)特征圖可視化結(jié)果Fig.3 Visualization results of advanced feature map extracted without ASPPAM

圖4 使用ASPPAM 提取的高級(jí)特征圖可視化結(jié)果Fig.4 Visualization results of advanced feature map extracted with ASPPAM
PSAM 通過(guò)計(jì)算特征圖中每個(gè)像素之間的聯(lián)系,得到一個(gè)經(jīng)過(guò)細(xì)化之后的特征圖。并列結(jié)構(gòu)的四個(gè)分支通過(guò)收集來(lái)自不同感受域的信息獲得更多的上下文信息,然后和經(jīng)過(guò)PSAM 得到的細(xì)化特征圖合并,最終目的是通過(guò)結(jié)合細(xì)化特征圖和全局特征圖來(lái)增強(qiáng)像素之間的依賴(lài)性和類(lèi)之間的區(qū)分。該模塊結(jié)構(gòu)如圖5 所示,計(jì)算方法如式(1)~(3):
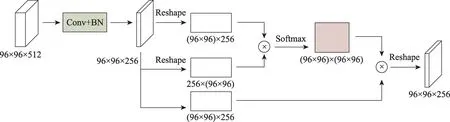
圖5 像素相似注意力模塊Fig.5 Pixel similar attention module
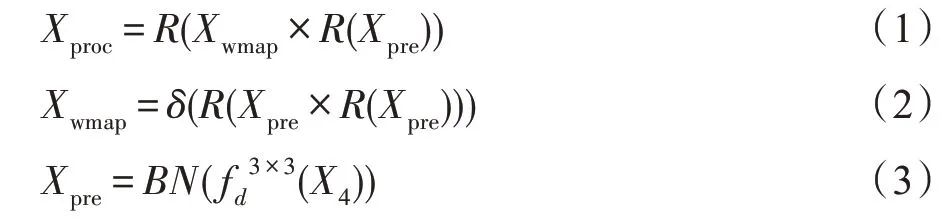
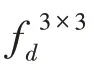
把上述得到特征圖融入到ASPP 模塊,該結(jié)構(gòu)如圖6 所示,計(jì)算方法如式(4)~(7):
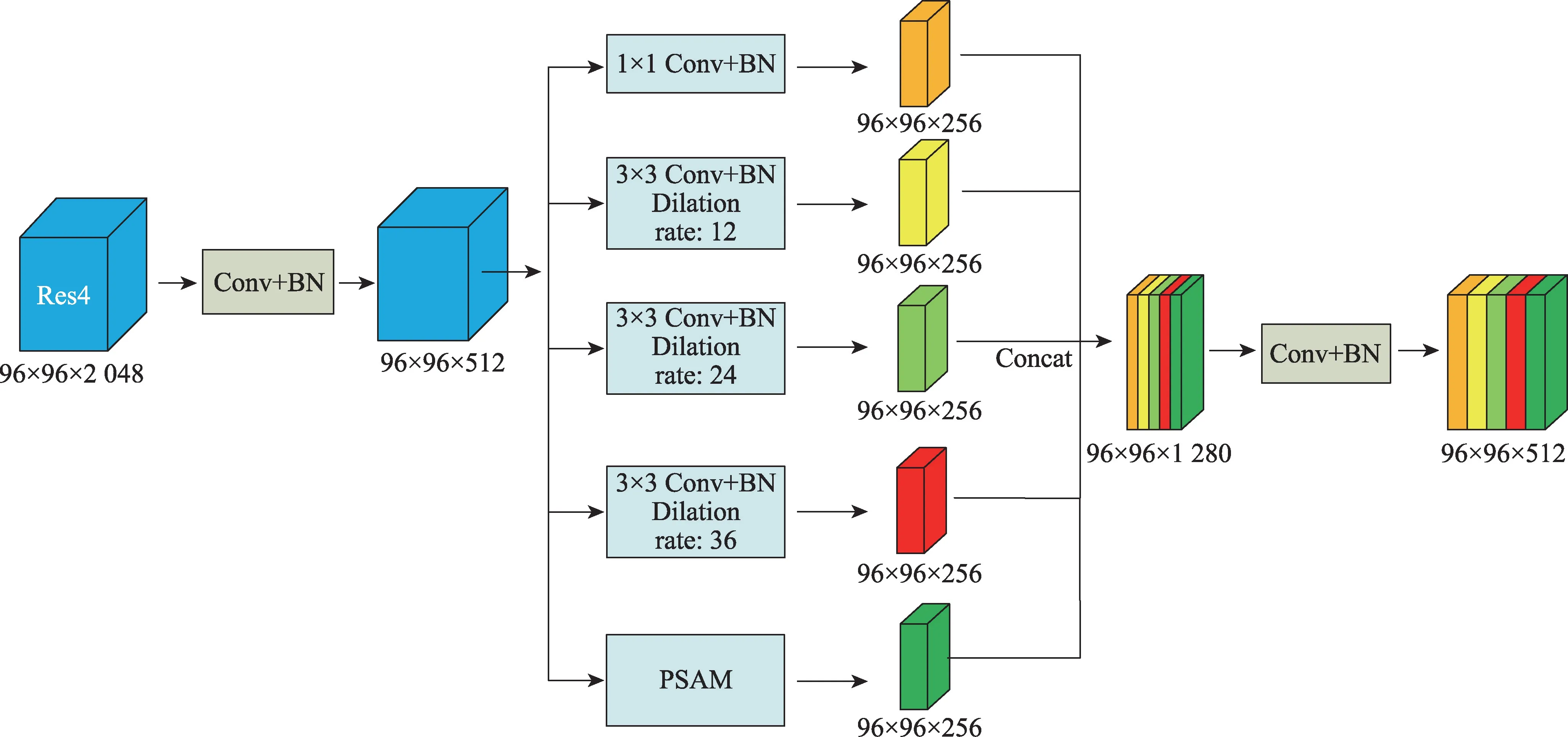
圖6 空洞空間金字塔注意力模塊Fig.6 Atrous spatial pyramid pooling attention module
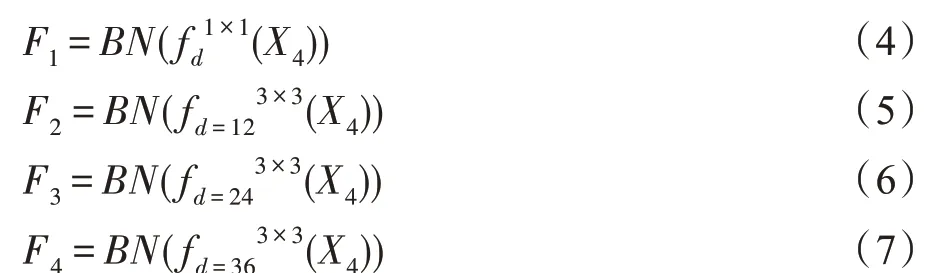
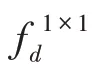
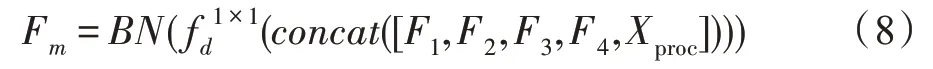
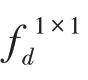
2.3 位置注意力模塊
高級(jí)特征具有非常豐富的語(yǔ)義信息,低級(jí)語(yǔ)義信息保留了更多的細(xì)節(jié),融合高級(jí)特征和低級(jí)特征可以更好地處理圖像的邊緣和細(xì)節(jié),DeepLab-v3+中提出了一種有效的解碼結(jié)構(gòu)。SENet 提出的SE 模塊在通道維度上做聚合操作,這種注意力機(jī)制可以更加注重信息量最大的通道特征,抑制不重要的通道特征。受到CBAM 和SENet 啟發(fā),本文提出的PAM模塊,將高級(jí)特征和跳躍層的低級(jí)特征通過(guò)相應(yīng)點(diǎn)的像素的Hadamard 積(矩陣中對(duì)應(yīng)元素相乘)融合,利用高級(jí)信息指導(dǎo)低級(jí)信息,可以得到很好的分割性能。設(shè)計(jì)結(jié)構(gòu)如圖7 所示,圖7 中“l(fā)ow feature”的藍(lán)色塊是來(lái)自ResNet第二個(gè)塊的特征圖,“high feature”綠色塊是經(jīng)過(guò)ASPPAM 處理過(guò)的高級(jí)特征圖。相對(duì)應(yīng)的計(jì)算方法如式(9):
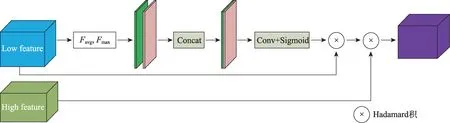
圖7 位置注意力模塊Fig.7 Position attention module

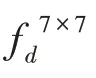
3 實(shí)驗(yàn)結(jié)果和分析
本章先介紹實(shí)驗(yàn)使用的數(shù)據(jù)集、評(píng)估指標(biāo)和網(wǎng)絡(luò)參數(shù)設(shè)置,然后與現(xiàn)有的注意力語(yǔ)義分割網(wǎng)絡(luò)進(jìn)行對(duì)比,最后進(jìn)行實(shí)驗(yàn)分析。
3.1 實(shí)驗(yàn)數(shù)據(jù)集與評(píng)估指標(biāo)
本文使用常用的公共數(shù)據(jù)集Cityscapes 語(yǔ)義分割數(shù)據(jù)集,從全世界50 個(gè)不同城市的街道場(chǎng)景中收集5 000 幅高質(zhì)量的像素級(jí)標(biāo)注的大型數(shù)據(jù)集,其中訓(xùn)練集、驗(yàn)證集和測(cè)試集分別由2 975、500 和1 525張圖像組成。數(shù)據(jù)集分為大類(lèi)和小類(lèi),大類(lèi)包括地面、建筑、人、天空、自然、背景、道路標(biāo)志和車(chē)輛。小類(lèi)包含33 個(gè)類(lèi)別,本文只使用了19 個(gè)類(lèi)別,圖片分辨率均為2 048×1 024,彩色圖片均為RGB 3 通道。數(shù)據(jù)集還提供20 000 張粗注釋的圖像用于訓(xùn)練弱監(jiān)督分類(lèi)網(wǎng)絡(luò)的性能。
本文使用常用的語(yǔ)義分割評(píng)估指標(biāo)mIoU(mean intersection over union),圖像像素每個(gè)類(lèi)的IoU 的值累加后的平均值。詳細(xì)的計(jì)算公式如下:
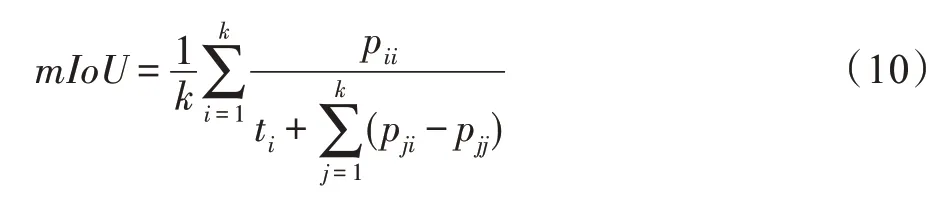
其中,表示像素的類(lèi)別數(shù);p表示實(shí)際類(lèi)別為,實(shí)際預(yù)測(cè)類(lèi)別也為的像素的數(shù)目;t表示類(lèi)別為像素的總數(shù);p表示實(shí)際類(lèi)別為,實(shí)際預(yù)測(cè)類(lèi)別為的像素的數(shù)目。
3.2 網(wǎng)絡(luò)參數(shù)
本文使用深度學(xué)習(xí)框架Pytorch-1.4,并實(shí)現(xiàn)了文章所提出的網(wǎng)絡(luò)模型。圖片預(yù)處理使用了隨機(jī)尺度調(diào)整、隨機(jī)裁剪和隨機(jī)翻轉(zhuǎn)等方法對(duì)訓(xùn)練數(shù)據(jù)進(jìn)行處理,并將圖像的大小調(diào)整為769×769 作為網(wǎng)絡(luò)輸入,將經(jīng)過(guò)PAM 模塊和ASPPAM 模塊處理后的特征圖和標(biāo)簽間的像素級(jí)交叉熵?fù)p失相加作為網(wǎng)絡(luò)的損失函數(shù)。在兩個(gè)Tesla-T4 GPU 上使用帶動(dòng)量的隨機(jī)梯度下降優(yōu)化算法訓(xùn)練本文網(wǎng)絡(luò),批處理大小為2,初始學(xué)習(xí)率設(shè)為0.01,動(dòng)量和衰減系數(shù)為0.9和0.000 5。
3.3 實(shí)驗(yàn)結(jié)果分析
將ASPPAM 模塊和PAM 嵌入到FCN 上,計(jì)算像素之間的依賴(lài)關(guān)系,本文所提結(jié)構(gòu)ASPPAM 和PAM在Cityscapes 驗(yàn)證集上的結(jié)果如表2 所示。為了驗(yàn)證注意力模塊的性能,本文對(duì)兩個(gè)模塊進(jìn)行消融實(shí)驗(yàn),ResNet-baseline 的mIoU 為68.1%,ResNet-baseline 的FPS(每秒傳輸幀數(shù))為25。與基本的ResNet-baseline相比,在ResNet-baseline 基礎(chǔ)上加入ASPPAM 模塊的mIoU 為73.8%,提高了5.7 個(gè)百分點(diǎn),因?yàn)锳SPPAM增加了計(jì)算量,所以FPS 降低了3 幀。而PAM 模塊目的是細(xì)化邊緣與細(xì)節(jié),分割性能提升不明顯,在ResNet-baseline 基礎(chǔ)上加入PAM 的mIoU 為69.3%,提高了1.2 個(gè)百分點(diǎn),PAM 的計(jì)算消耗小,F(xiàn)PS 降低1幀。本文也將沒(méi)有經(jīng)過(guò)任何改進(jìn)的ASPP模塊進(jìn)行了實(shí)驗(yàn),其mIoU 為70.7%,F(xiàn)PS 為23 幀。實(shí)驗(yàn)結(jié)果表明,ASPPAM模塊對(duì)場(chǎng)景分割有很大的幫助,F(xiàn)PS幀數(shù)變化較小。考慮到計(jì)算成本,最終使用下采樣率為8的ResNet-101為骨干網(wǎng)絡(luò),表2結(jié)果均來(lái)自Cityscapes官方提供的工具包Cityspacescripts計(jì)算得出。

表2 兩個(gè)模塊對(duì)網(wǎng)絡(luò)性能的影響Table 2 Impact of two modules on network performance
與當(dāng)前先進(jìn)的網(wǎng)絡(luò)進(jìn)行了比較,數(shù)據(jù)集為Cityscapes 的測(cè)試集,將官方提供的測(cè)試集圖片通過(guò)本文網(wǎng)絡(luò)預(yù)測(cè)出分割圖,經(jīng)過(guò)官方測(cè)試,結(jié)果如表3 所示。
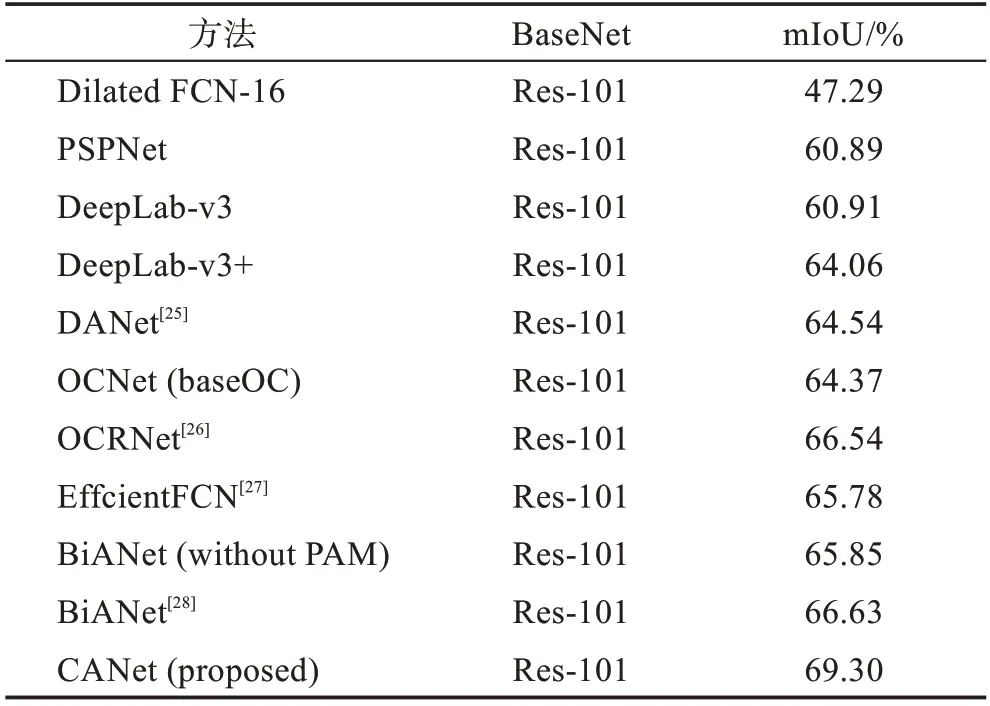
表3 與各種先進(jìn)網(wǎng)絡(luò)的比較Table 3 Comparison with various advanced networks
表3中,本文提出的注意力機(jī)制的mIoU為69.30%,顯著改善了以往FCN 網(wǎng)絡(luò)的性能。ASPPAM 模塊在該數(shù)據(jù)集的驗(yàn)證集上比基準(zhǔn)網(wǎng)絡(luò)提高了5.7 個(gè)百分點(diǎn)。同時(shí),本文與當(dāng)前比較流行的網(wǎng)絡(luò)進(jìn)行了比較:相比于原始的Dilated FCN-16,本文模型提高了接近22個(gè)百分點(diǎn)的性能;和含有ASPP 的DeepLab-v3 相比,本文性能提升了5 個(gè)百分點(diǎn);和最新的雙邊注意網(wǎng)絡(luò)BiANet 相比,本文性能提升了3 個(gè)百分點(diǎn)。本文網(wǎng)絡(luò)兩個(gè)模塊強(qiáng)調(diào)了像素之間的依賴(lài)性和低層次空間的細(xì)節(jié)。該方法在Cityscapes測(cè)試集獲得了更好的性能。在數(shù)據(jù)集上預(yù)測(cè)的19 個(gè)類(lèi)別的準(zhǔn)確率如表4所示,CANet的Bus和Train的分割精度顯著提高,一些細(xì)小物體相比于其他網(wǎng)絡(luò)分割精度有所提升。
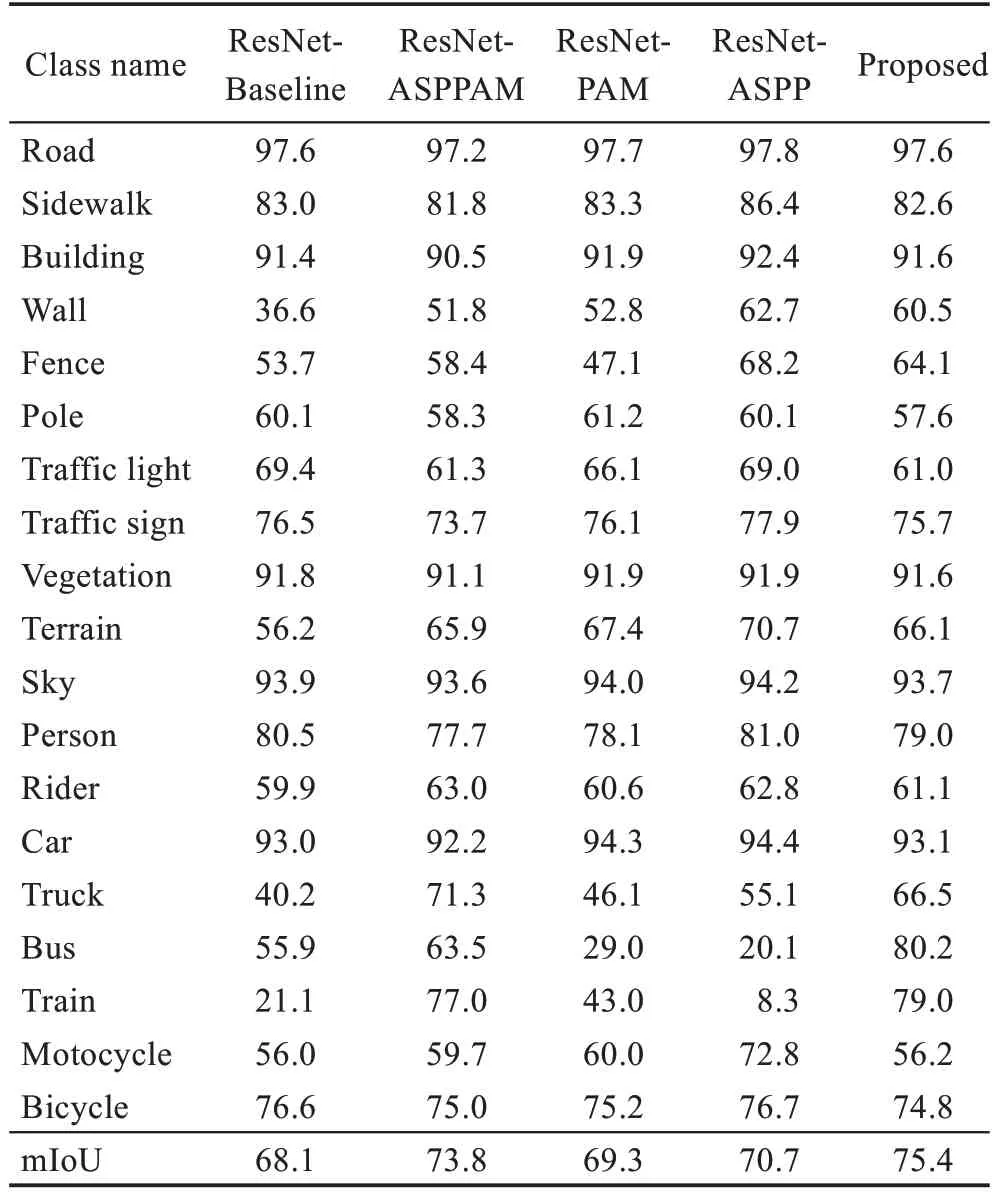
表4 Cityscapes驗(yàn)證集上各個(gè)類(lèi)別的準(zhǔn)確率Table 4 Accuracy of each category on Cityscapes verification set %
本文提出的兩個(gè)模塊對(duì)網(wǎng)絡(luò)性能影響的可視化圖如圖8 所示,可見(jiàn)ResNet-baseline 中有誤分的模塊,并且一些邊緣細(xì)節(jié)分割不是很連貫。誤分造成的原因是ResNet-baseline 中沒(méi)有多尺度信息,造成比較大的物體會(huì)產(chǎn)生誤分的現(xiàn)象。比如:綠化帶里面混有人行道、天空里面混有植物等,加入了ASPPAM模塊后,誤分的現(xiàn)象減少了,原因是增強(qiáng)了像素之間的依賴(lài)信息,并且由于空洞卷積的原因,增加了多尺度的上下文信息,這樣誤分的信息大大減少。添加PAM 模塊后,低級(jí)特征圖保留了邊緣信息,補(bǔ)充缺少的邊緣信息,經(jīng)過(guò)上采樣后進(jìn)行預(yù)測(cè),對(duì)物體邊緣預(yù)測(cè)提供了一定的幫助。如交通標(biāo)識(shí)牌等在分割圖中可以得到直觀的比較。
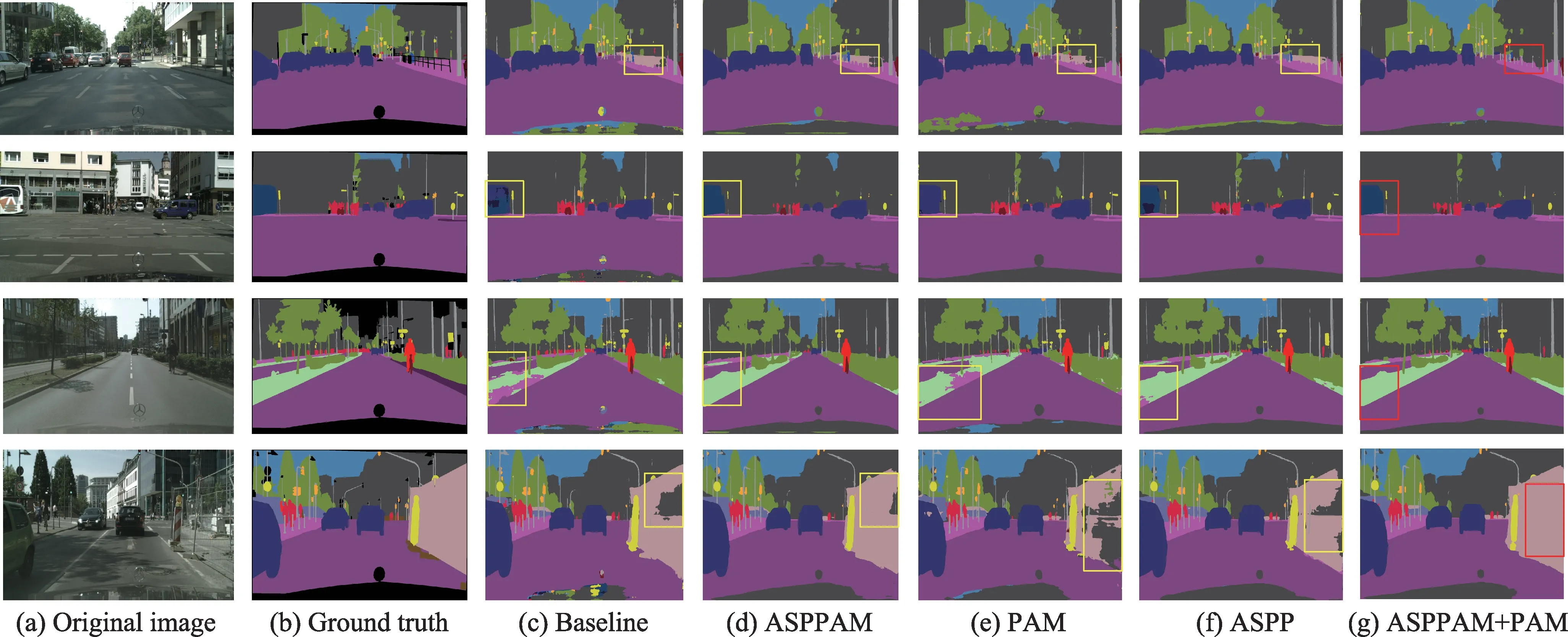
圖8 消融實(shí)驗(yàn)結(jié)果可視化Fig.8 Visualization of ablation experimental results
網(wǎng)絡(luò)的參數(shù)分析:網(wǎng)絡(luò)主干網(wǎng)絡(luò)采用的是ResNet-101,網(wǎng)絡(luò)輸入為3 通道的769×769 的彩色圖片,分析整個(gè)網(wǎng)絡(luò)的參數(shù)(MB)和計(jì)算復(fù)雜度(GFLOPS),Else 表示最后改變通道數(shù)所用卷積和ResNet-101 開(kāi)始所用卷積的參數(shù)量和計(jì)算復(fù)雜度,括號(hào)內(nèi)百分?jǐn)?shù)為該項(xiàng)在整個(gè)網(wǎng)絡(luò)中的占比,整個(gè)網(wǎng)絡(luò)的參數(shù)量和計(jì)算復(fù)雜度如表5所示。數(shù)據(jù)是在一張Tesla-T4 GPU顯卡上測(cè)試的本文模型,輸入為3 通道的769×769 的彩色圖片,F(xiàn)PS 為20 幀。
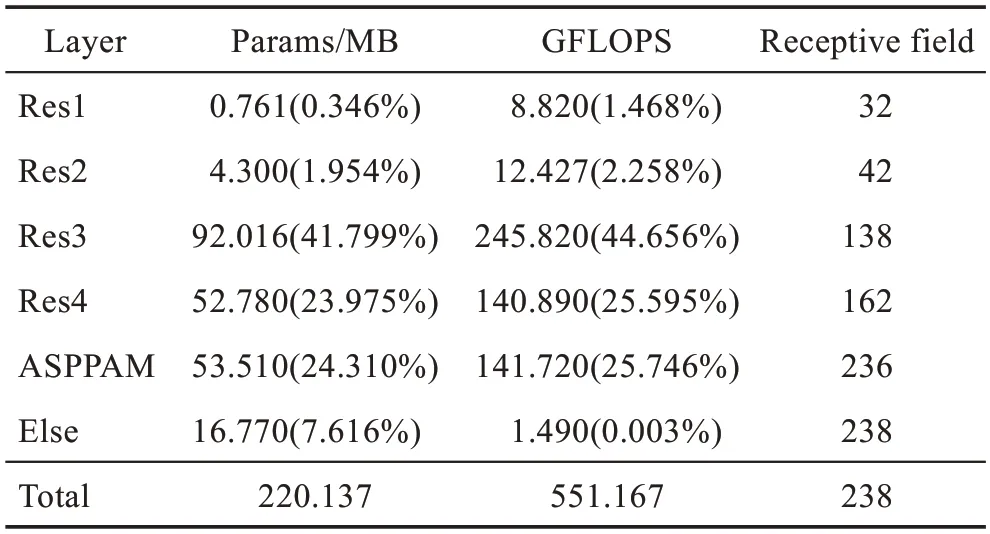
表5 網(wǎng)絡(luò)參數(shù)表Table 5 Network parameters
4 結(jié)束語(yǔ)
本文提出了一種改進(jìn)的全卷積網(wǎng)絡(luò)(FCN)語(yǔ)義分割方法,并且提出了兩個(gè)注意力模塊:空洞空間金字塔注意力模塊(ASPPAM)和位置注意力模塊(PAM)。空洞空間金字塔注意力模塊增加了用以計(jì)算像素之間的依賴(lài)性的模塊,提高分割精度,位置注意力模塊用以融合低級(jí)語(yǔ)義信息,補(bǔ)充下采樣時(shí)丟失的信息。評(píng)估和實(shí)驗(yàn)結(jié)果表明,與PSPNet、OCNet、DeepLab-v3、BiANet等網(wǎng)絡(luò)相比,采用ASPPAM 模塊和PAM 模塊具有更好的性能。未來(lái)考慮怎樣改進(jìn)骨干網(wǎng)絡(luò)ResNet來(lái)進(jìn)一步提高分割效果。
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
外語(yǔ)學(xué)刊(2011年1期)2011-01-22 03:38:33
