高斯混合生成模型檢測健康數(shù)據(jù)異常
2022-05-17 06:02:00朱壯壯周治平
計(jì)算機(jī)與生活 2022年5期
朱壯壯,周治平
江南大學(xué) 物聯(lián)網(wǎng)工程學(xué)院,江蘇 無錫214122
近年來,人們對健康的生活方式越發(fā)重視,越來越多的人通過運(yùn)動手環(huán)來監(jiān)測自己的健康。運(yùn)動手環(huán)可以監(jiān)測人們的運(yùn)動狀況和一些行為方式,如睡眠時長、心率和運(yùn)動步數(shù)等。Lim 等人發(fā)現(xiàn)患有疾病的手環(huán)佩戴者和健康佩戴者的手環(huán)數(shù)據(jù)存在顯著的差異,且特定指標(biāo)與特定疾病的關(guān)聯(lián)較大,如運(yùn)動步數(shù)和靜息心率這兩個指標(biāo)都與心血管疾病和代謝紊亂有關(guān)。對于手環(huán)佩帶者而言,在對數(shù)據(jù)缺乏有效分析的情況下,僅僅依靠手環(huán)顯示的信息并不能準(zhǔn)確地了解其身體的健康狀況。對于手環(huán)收集到的數(shù)據(jù),異常值是指與某些疾病相關(guān)聯(lián)的指標(biāo)偏離個體基準(zhǔn)的數(shù)據(jù)。因此有必要找出手環(huán)數(shù)據(jù)中的異常值,提前判斷出用戶身體是否存在隱患,以便提前做出相應(yīng)治療,這對改善用戶身體健康有重大的作用。
基于距離的異常值檢測方法,包括近鄰(nearest neighbor,NN)和平均近鄰,主要是基于對全維空間中距離的評估,該方法假定異常點(diǎn)與正常點(diǎn)之間的距離較遠(yuǎn),因此計(jì)算每個樣本點(diǎn)之間的距離(或者平均距離),并與距離閾值比較,若大于閾值則視為異常點(diǎn)。然而,當(dāng)處理高維數(shù)據(jù)時,相關(guān)距離和近鄰的概念變得沒有意義,異常檢測的效果也變差。在這個大數(shù)據(jù)時代,數(shù)據(jù)呈現(xiàn)高維度特征,使得在進(jìn)行異常檢測時,容易出現(xiàn)“維度災(zāi)難”問題。為了解決該問題,許多研究都集中在基于降維的異常值檢測方法上。傳統(tǒng)的技術(shù)采用兩步法,即先降維,再進(jìn)行異常檢測,這兩個步驟分別訓(xùn)練,在沒有異常檢測指導(dǎo)的情況下進(jìn)行降維訓(xùn)練,容易丟失異常檢測的關(guān)鍵信息。Zhou 等人將深度神經(jīng)網(wǎng)絡(luò)(deep neural network,DNN)降維和均值(-means)聚類方法結(jié)合起來,便于同時優(yōu)化這兩個任務(wù),減少解耦學(xué)習(xí)的影響,提升檢測效果。
深度學(xué)習(xí)領(lǐng)域的學(xué)者們已經(jīng)提出了多種異常檢測技術(shù)用以改進(jìn)檢測性能。Zong等人提出了DAGMM方法,該方法首先利用深度自編碼器將原始數(shù)據(jù)進(jìn)行潛在空間表示,并將低維特征表示和重構(gòu)誤差特征輸入GMM(Gaussian mixture model)中進(jìn)行密度估計(jì),通過選擇合適的密度閾值,將密度高于該值的數(shù)據(jù)記為異常值。然而,該方法假設(shè)異常是不可壓縮的,因此不能從低維潛在空間中有效重建輸入數(shù)據(jù)。相較于VAE 使用重建概率重構(gòu)原始數(shù)據(jù),重構(gòu)誤差缺乏客觀性,導(dǎo)致DAGMM 方法檢測性能不佳。與GMGM(Gaussian mixture generative model)類 似,Nalisnick 等人提出了將VAE(variational autoencoder)與GMM 結(jié)合在一起的DL-GMM 方法,它采用混合高斯分布近似VAE 的后驗(yàn),從而提高了原始VAE 的容量。但是,它不適用于無監(jiān)督的異常值檢測。Liu等人提出了一種基于多視圖主題模型的異常檢測方法,該方法利用多視圖主題模型對原始數(shù)據(jù)中的特征進(jìn)行建模得到對應(yīng)的關(guān)系,能夠大大降低檢測的誤報率,但是該方法檢測準(zhǔn)確性偏低。
鑒于此,本文利用GMGM,用以進(jìn)行人體活動數(shù)據(jù)的異常檢測。在該模型中,使用生成模型中的VAE生成數(shù)據(jù)潛在分布和重構(gòu)誤差來訓(xùn)練DBN(deep brief network),以預(yù)測樣本的混合成員隸屬度。高斯混合模型通過樣本的混合成員隸屬度預(yù)測得到每個數(shù)據(jù)的樣本密度,將密度高于訓(xùn)練階段閾值樣本視為異常。GMGM 共同優(yōu)化了VAE、DBN 和GMM,從而避免了模型解耦的影響。
本文有三個主要的貢獻(xiàn):
(1)為了盡可能保留原始數(shù)據(jù)的特征,生成網(wǎng)絡(luò)利用VAE為原始樣本生成潛在分布和重構(gòu)誤差特征。
(2)為了避免在計(jì)算樣本密度過程中,由于矩陣的奇點(diǎn)問題導(dǎo)致協(xié)方差矩陣無法求解,GMGM 利用樣本的混合概率、均值和協(xié)方差來構(gòu)造協(xié)方差矩陣的Cholesky 分解,以計(jì)算樣本密度。
(3)由于傳統(tǒng)的兩步法技術(shù)在進(jìn)行異常檢測時會丟失關(guān)鍵信息,GMGM 以一種端到端的方式共同優(yōu)化VAE、DBN 和GMM,以保留數(shù)據(jù)的原始特征。
基于該方法,文本實(shí)現(xiàn)了健康數(shù)據(jù)的異常檢測,并在真實(shí)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),結(jié)果表明,所應(yīng)用算法可以有效地檢測健康數(shù)據(jù)中的異常。
1 相關(guān)工作
1.1 變分自編碼器
變分自編碼器的提出,旨在解決傳統(tǒng)的算法處理復(fù)雜場景中推斷和訓(xùn)練困難且耗費(fèi)大的問題,它能夠生成輸入數(shù)據(jù)潛在變量的低維表示。變分自編碼器可以看作一個特征器,根據(jù)原始樣本分布,構(gòu)建出其概率分布以重構(gòu)數(shù)據(jù)。相比深度自編碼器采用重構(gòu)誤差進(jìn)行重構(gòu)數(shù)據(jù),重構(gòu)概率是一種概率測量,它考慮了變量分布的可變性,比重構(gòu)誤差更具原則性和客觀性。因此,本文選取VAE 進(jìn)行特征提取,解決“維度災(zāi)難”問題,同時保留原始數(shù)據(jù)的多模態(tài)特征。近年來,變分自編碼器逐漸與深層神經(jīng)網(wǎng)絡(luò)結(jié)合,通過隱含層的堆疊以一種無監(jiān)督的方式進(jìn)行參數(shù)優(yōu)化。假設(shè)∈R表示一個維度為的向量,∈R表示對應(yīng)的維度為′的潛在表示,(·)表示概率分布函數(shù),則概率分布的生成過程可以表示為:

1.2 高斯混合模型
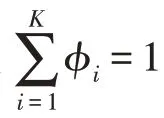
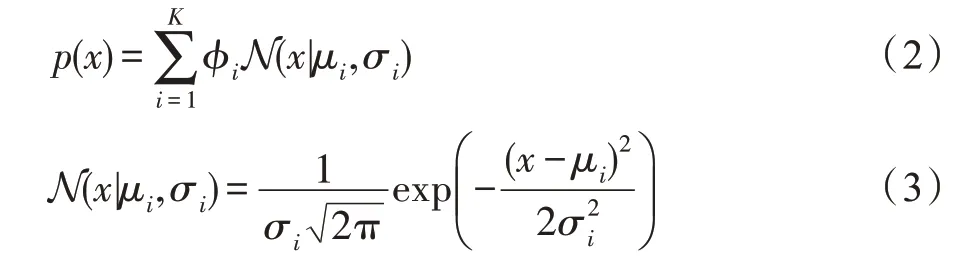
GMM 模型訓(xùn)練階段,使用EM 算法以最大化似然函數(shù)的方式求解模型最佳參數(shù),即混合概率φ、均值μ和協(xié)方差σ,直至模型收斂。
2 本文算法
針對GMM 對高維數(shù)據(jù)進(jìn)行密度估計(jì)時,會出現(xiàn)時間復(fù)雜度較高的問題,本文利用GMGM 對健康數(shù)據(jù)進(jìn)行異常檢測。如圖1 所示,該模型主要由兩部分組成:生成模型和高斯混合模型。GMGM 的工作原理如下:首先,生成模型通過VAE 對輸入樣本進(jìn)行降維處理,以便生成樣本點(diǎn)的潛在空間表示和基于重構(gòu)的特征提供給DBN;接著,DBN 采用饋送,預(yù)測得到樣本點(diǎn)的混合成員隸屬度;最后,利用混合成員隸屬度,GMM 預(yù)測每個數(shù)據(jù)的樣本密度,將樣本密度高于訓(xùn)練階段的閾值的數(shù)據(jù)視為異常。
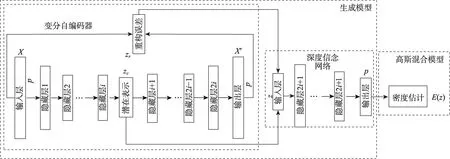
圖1 高斯混合生成模型結(jié)構(gòu)示意圖Fig.1 Structure diagram of Gaussian mixture generative model
2.1 本文算法
在高維空間中,會出現(xiàn)一種“維度災(zāi)難”的現(xiàn)象,即隨著數(shù)據(jù)維度的增加,密度預(yù)測的時間復(fù)雜度會急劇增加,性能下降。為了解決此問題,生成模型通過VAE 對數(shù)量為,維度為的輸入數(shù)據(jù)=[,,…,x]∈R進(jìn)行重構(gòu)處理,提取樣本點(diǎn)的潛在空間表示和重構(gòu)特征,以保留樣本的固有多模態(tài)信息,并將其作為DBN 的輸入。

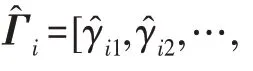

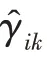
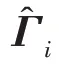
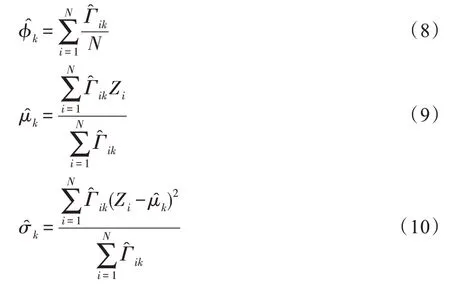
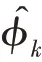
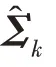
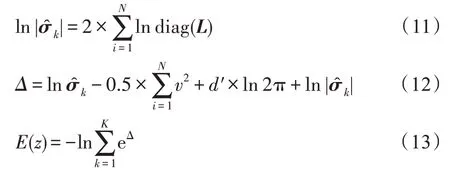
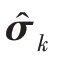
傳統(tǒng)的兩步法技術(shù)在進(jìn)行異常檢測時會丟失關(guān)鍵信息,因此需要將降維過程與密度估計(jì)過程聯(lián)合訓(xùn)練,相互優(yōu)化。GMM 在利用EM 算法進(jìn)行模型訓(xùn)練時,首先根據(jù)當(dāng)前參數(shù)計(jì)算每個數(shù)據(jù)的混合成員隸屬度,接著利用得到的混合成員隸屬度計(jì)算模型參數(shù),直至收斂。因此,本文中GMGM 將期望最大化算法的E 步驟中的樣本屬于各子分布的概率替換為端到端結(jié)構(gòu)中生成模型的輸出,以一種端到端的方式共同訓(xùn)練了生成模型與GMM;接著,利用EM 算法中M 步對GMM 中的均值、協(xié)方差等做參數(shù)估計(jì),然后極大化似然函數(shù),相對于傳統(tǒng)的訓(xùn)練方式,更易達(dá)到理想的檢測效果。
在測試階段,GMGM 可以根據(jù)式(13)預(yù)測樣本的密度,將樣本密度高于訓(xùn)練階段閾值的數(shù)據(jù)視為異常。
2.2 目標(biāo)函數(shù)
由于解耦學(xué)習(xí)性能不佳,在GMGM 中,將VAE、DBN 和GMM 統(tǒng)一起來,共同進(jìn)行模型訓(xùn)練。給定個數(shù)據(jù)點(diǎn)的樣本集,目標(biāo)函數(shù)如下:
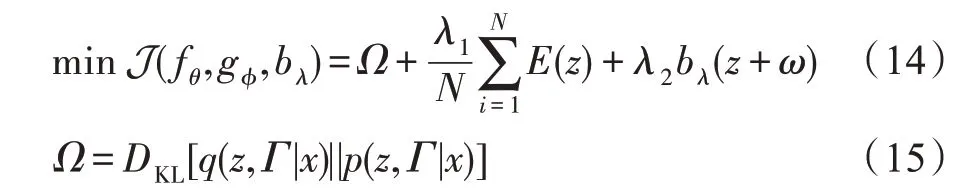
式(15)表示后驗(yàn)分布(,|)和最大似然分布(,|)的KL散度。通過最小化后驗(yàn)分布與最大似然分布的KL散度,以最大程度地提高多維輸入的似然。
()模擬可以觀察輸入樣本的概率。通過最小化樣本密度,以最大化觀察到輸入樣本的可能性,以便得到VAE、DBN 和GMM 參數(shù)的最佳組合。
和是用于規(guī)范目標(biāo)函數(shù)的超參數(shù),實(shí)驗(yàn)中,=0.1,=0.001 通常可以得到較好的結(jié)果。最小化J(f,g,b)可為生成模型和GMM 提供最佳的參數(shù)組合。
2.3 算法復(fù)雜度分析
假設(shè)∈R表示數(shù)量為,維度為的原始輸入數(shù)據(jù),GMGM 方法需要對原始數(shù)據(jù)進(jìn)行重構(gòu)處理,設(shè)定隱含層層數(shù)為3,即三層編碼器、三層譯碼層,′為設(shè)置的各隱藏層節(jié)點(diǎn)數(shù)(即每層輸出維度)中的最大值,該部分的時間復(fù)雜度為(′);DBN分別預(yù)測各樣本屬于個組件的概率,該部分包括反向傳播過程和Softmax 過程,該部分的時間復(fù)雜度為(′);利用GMM 進(jìn)行密度估計(jì),該步驟的時間復(fù)雜度為((+1)),因此GMGM 的時間復(fù)雜度為((+1)+(+1)′)。隨機(jī)異常選擇(stochastic outlier selection,SOS)算法采用相異度矩陣以親和力的概念量化兩點(diǎn)之間的關(guān)系,其時間復(fù)雜度為(),遠(yuǎn)高于本文算法;經(jīng)典的異常檢測算法如VAE,其時間復(fù)雜度為(′),DAGMM 時間復(fù)雜度為((+1)+(+2)′)。
3 實(shí)驗(yàn)評估
實(shí)驗(yàn)平臺配置為Windows10 操作系統(tǒng)、Intel Core i7-7700HQ CPU 處理器、2.80 GHz、20 GB 內(nèi)存,所有算法由Python 實(shí)現(xiàn)。
本文選取了5 個數(shù)據(jù)集,皆來自O(shè)DDS 數(shù)據(jù)庫,這些數(shù)據(jù)集包含異常類,并根據(jù)樣本標(biāo)簽區(qū)分。標(biāo)簽為0 的數(shù)據(jù)為正常類,標(biāo)簽為1 的數(shù)據(jù)為異常類,數(shù)據(jù)集的數(shù)據(jù)特征見表1。
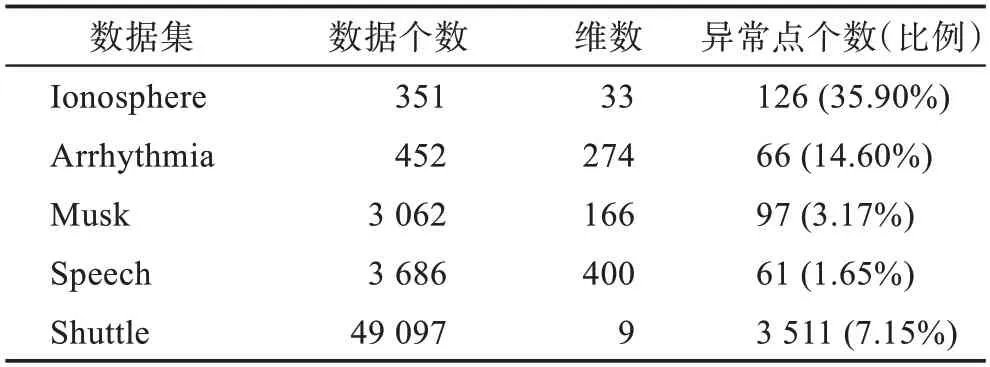
表1 數(shù)據(jù)集信息Table 1 Dataset information
為驗(yàn)證算法性能,將本文算法與SOS、基于變分編碼器的異常檢測算法、深度自編碼器高斯混合模型(deep autoencoding Gaussian mixture model,DAGMM)進(jìn)行了比較。選取的原因是:SOS 算法使用關(guān)聯(lián)的概念來計(jì)算每個數(shù)據(jù)點(diǎn)的異常值概率,這與本文預(yù)測每個樣本點(diǎn)密度的方式類似;本文算法是基于變分自編碼器的異常檢測算法的改進(jìn),因此選取其作對比;DAGMM 采用深層自編碼器提取原始數(shù)據(jù)的特征,通過多層感知機(jī)估計(jì)樣本的混合成員隸屬度,最后通過GMM 計(jì)算每個樣本點(diǎn)能量進(jìn)行異常檢測,其檢測效果較好,并且結(jié)構(gòu)與本文算法相似,因此選取其作為對比算法。
本文所用的評估異常檢測算法的性能指標(biāo)是:召回率(Recall)、1分?jǐn)?shù)(1-Score)、正確率(ACC)和受試者工作曲線(area under curve,AUC)。較好的異常檢測算法應(yīng)該有較高的Recall、1-Score、ACC、AUC。
3.1 實(shí)驗(yàn)對比結(jié)果與分析
對于各樣本集,GMGM 的參數(shù)設(shè)置如下:數(shù)據(jù)集Ionosphere、Arrhythmia、Musk、Speech 和Shuttle 的潛在空間表示維度分別為3、4、4、4、2;為了確定GMM最優(yōu)組件的個數(shù),需要使用一些分析標(biāo)準(zhǔn)來評估模型的可能性。本文參考了文獻(xiàn)[6]與文獻(xiàn)[7],發(fā)現(xiàn)其主要是采用了貝葉斯信息準(zhǔn)則(Bayesian information criterion,BIC)的評價方法來確定組件個數(shù),模型的BIC 值越低,GMM 預(yù)測樣本數(shù)據(jù)樣本密度的性能越好。對于本文中所有的數(shù)據(jù)集,GMM 組件個數(shù)取3時,模型BIC 值最小,因此對于所有的數(shù)據(jù)集,GMM組件個數(shù)設(shè)置為3。
為了驗(yàn)證GMGM 針對高維數(shù)據(jù)檢測性能的優(yōu)勢,選取了維度較大的Speech 數(shù)據(jù)集,采用定性的方式,與SOS、VAE 和DAGMM 算法進(jìn)行ROC 曲線的對比,對比結(jié)果如圖2所示。從圖中可以看出,相較于SOS、VAE和DAGMM算法ROC曲線下面積AUC值,GMGM異常檢測方法的面積最大,即AUC值最高。其中,VAE 算法的檢測效果最差,可能是因?yàn)閂AE 在對數(shù)據(jù)進(jìn)行潛在空間表示的時候,把原始樣本跟異常有關(guān)的關(guān)鍵信息錯誤地進(jìn)行了刪除,導(dǎo)致檢測AUC值較低;而GMGM 采取的是端到端的聯(lián)合訓(xùn)練,可以同時訓(xùn)練VAE、DBN 和GMM,使三者模型參數(shù)達(dá)到最優(yōu),檢測效果較為理想。
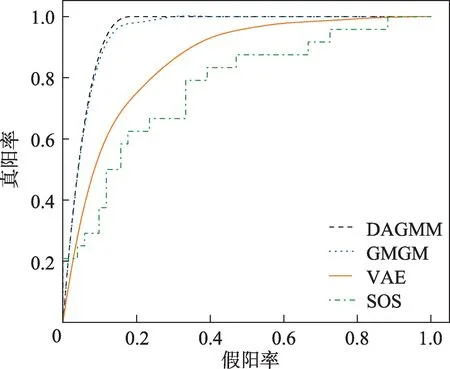
圖2 各算法檢測Speech 數(shù)據(jù)集的ROC 曲線Fig.2 ROC curves of each algorithm for Speech
從圖3 中可以看出,對于不同的數(shù)據(jù)集,本文算法在取得最好的檢測效果時,所對應(yīng)的VAE 編碼器層數(shù)都不同。當(dāng)值增大時,各數(shù)據(jù)集對應(yīng)的AUC值總是先增大后減小。這是因?yàn)橄仍龃笾悼梢允沟镁幋a器很好地進(jìn)行數(shù)據(jù)重構(gòu),較好地學(xué)習(xí)到原始樣本的特征,因此AUC 值增大;但是之后隨著繼續(xù)增大,導(dǎo)致訓(xùn)練過擬合,使得算法AUC 值減小。經(jīng)過綜合考量,對圖3 中5 個數(shù)據(jù)集的值選擇分別是4(33-16-8-3)、5(274-136-64-16-5)、5(166-84-42-12-5)、5(400-200-100-50-5)、2(9-2)。
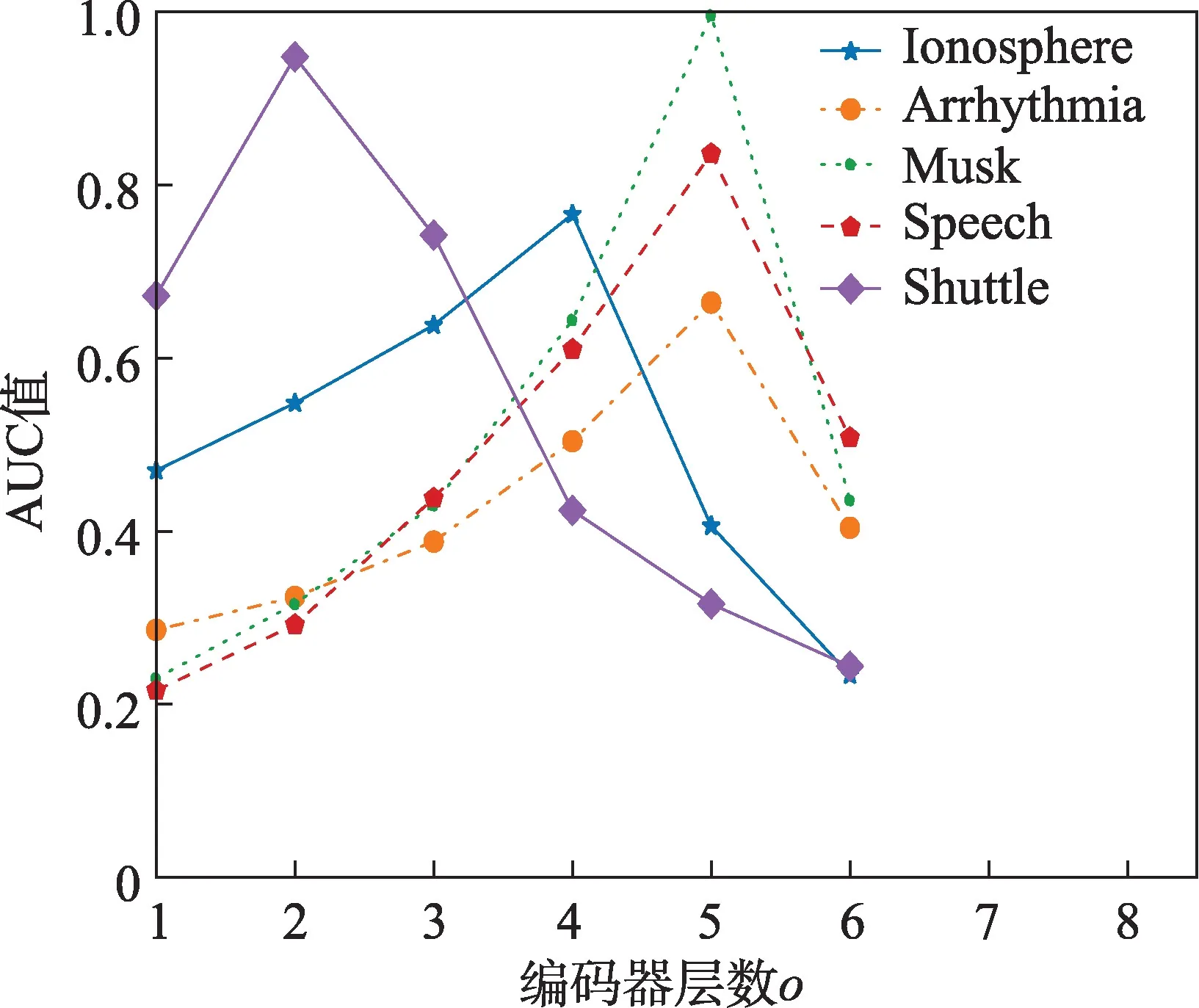
圖3 各數(shù)據(jù)集在GMGM 上的不同o 對應(yīng)AUC 值Fig.3 AUC curves with different o for different datasets on GMGM
為了驗(yàn)證GMGM 在時間復(fù)雜性上的優(yōu)勢,將其與SOS 算法、VAE 算法和DAGMM 算法的平均檢測時間進(jìn)行對比,對比結(jié)果如表2 所示。
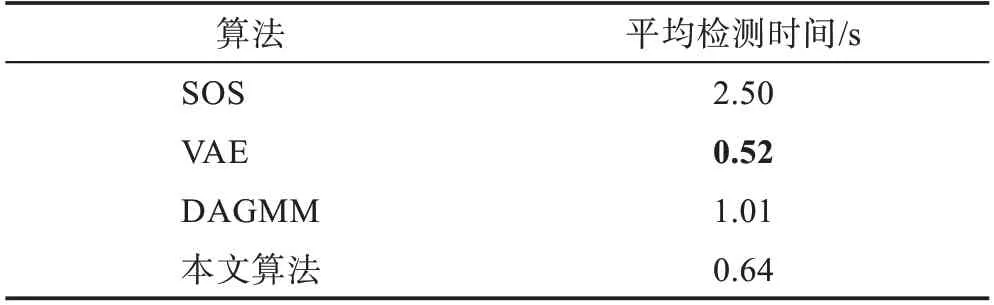
表2 各算法平均檢測時間對比Table 2 Comparison of average detection time of each algorithm
從表2 可以看出,雖然本文算法的平均檢測時間不是最低,但是比平均檢測時間最低的VAE 算法僅相差了0.12 s;并且其平均檢測時間比性能較好的DAGMM 算法提升了37%,體現(xiàn)了本文算法在檢測時間方面的優(yōu)勢。
為了驗(yàn)證本文端到端結(jié)構(gòu)的有效性,將本文算法與獨(dú)立訓(xùn)練的模型進(jìn)行對比,實(shí)驗(yàn)結(jié)果如表3 所示。從表中可以看出,采用端到端訓(xùn)練的GMGM 的各個指標(biāo)均高于獨(dú)立訓(xùn)練的模型。
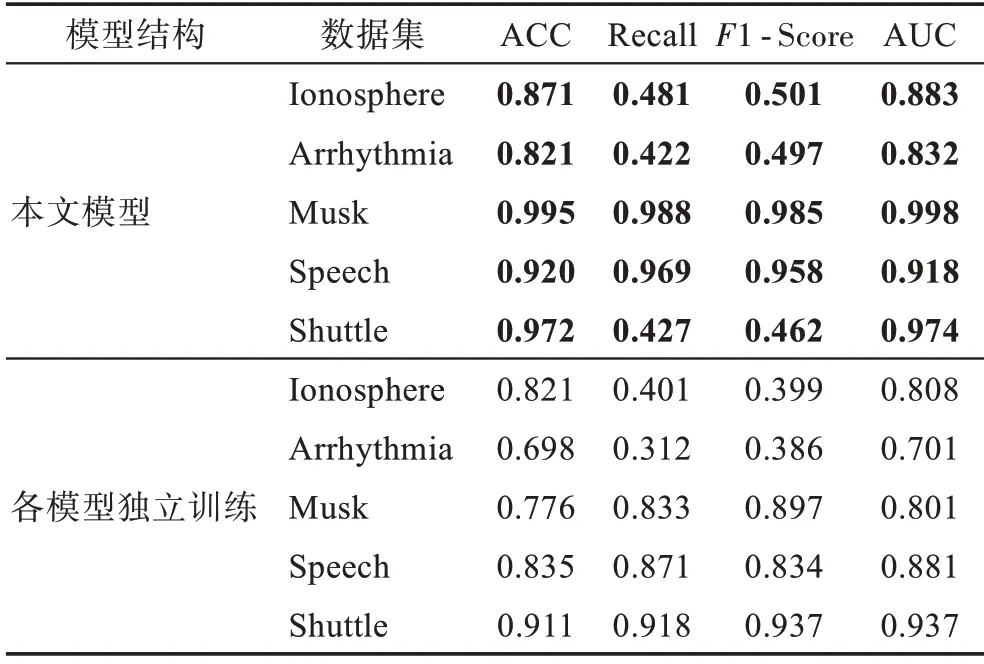
表3 不同模型結(jié)構(gòu)實(shí)驗(yàn)結(jié)果對比Table 3 Comparison of experimental results of different model structures
為了驗(yàn)證本文算法性能的優(yōu)勢,將本文算法與VAE 算法、SOS 算法和DAGMM 算法進(jìn)行對比,計(jì)算各異常檢測算法性能指標(biāo)ACC、Recall、1-Score 和AUC值,列入表4中。其中VAE算法的隱含層層數(shù)和各層節(jié)點(diǎn)數(shù)與生成網(wǎng)絡(luò)中的VAE 相同;DAGMM 與文獻(xiàn)[6]具有相同的參數(shù)設(shè)置。
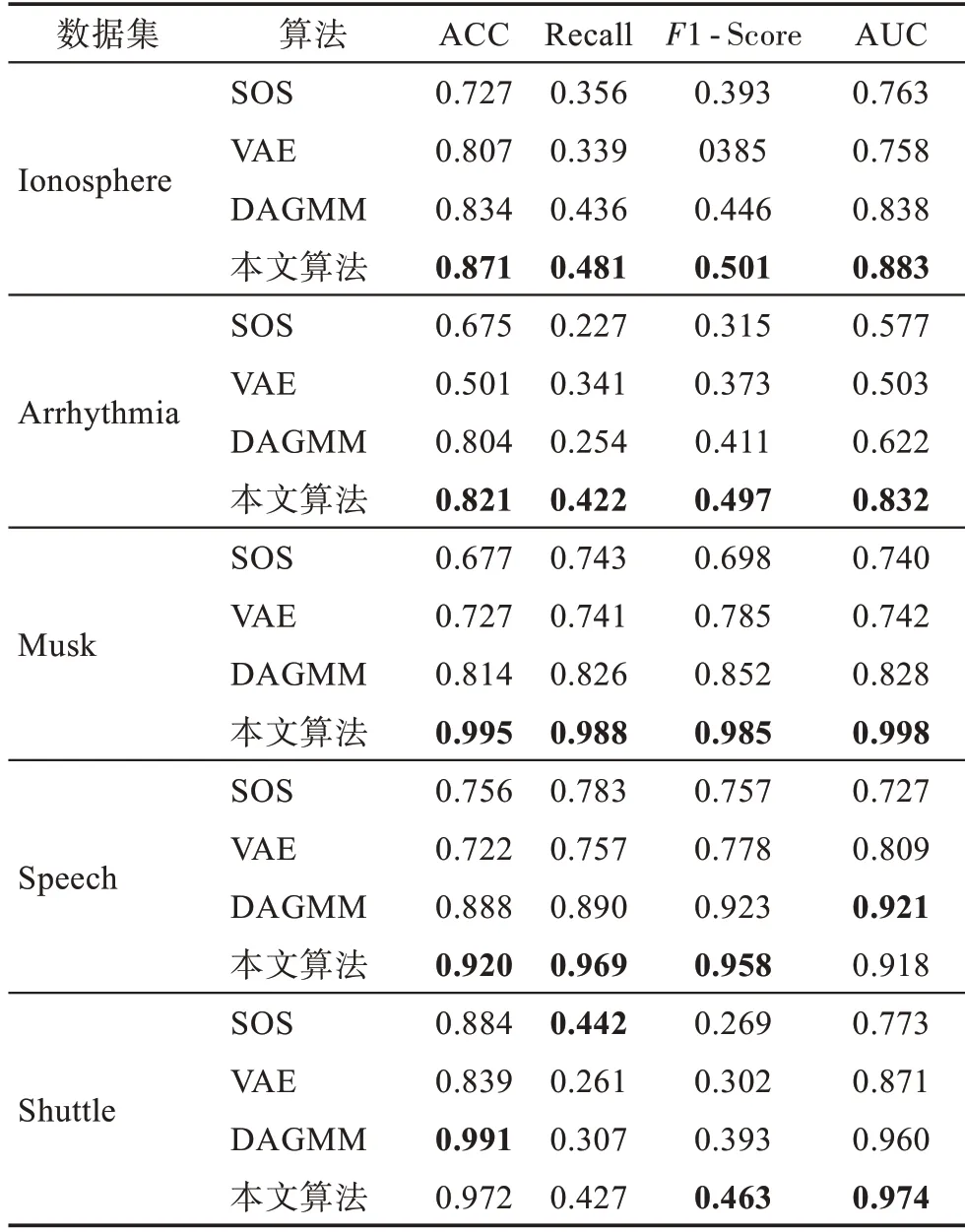
表4 不同算法實(shí)驗(yàn)結(jié)果對比Table 4 Comparison of experimental results of different algorithms
從表4 的對比實(shí)驗(yàn)結(jié)果可以看出,GMGM 的準(zhǔn)確率僅在大數(shù)據(jù)集Shuttle 上稍低于DAGMM 算法;其AUC 值也僅在Speech 數(shù)據(jù)集上稍低于DAGMM算法;在大數(shù)據(jù)集Shuttle 上的Recall 值雖然不是最高,但與最高值相差不多;在高維數(shù)據(jù)集Musk 上準(zhǔn)確率達(dá)到了0.995,遠(yuǎn)高于SOS 算法的0.677,在維數(shù)較高且數(shù)據(jù)量較大的Arrhythmia 數(shù)據(jù)集上也表現(xiàn)出較為理想的檢測效果;在Shuttle數(shù)據(jù)集上,雖然本文算法的ACC 和Recall 稍有降低,但是1-Score 與AUC值分別提高了7 個百分點(diǎn)與1.4 個百分點(diǎn)。這種情況發(fā)生的原因可能是,算法中的潛在空間表示能夠較好地捕捉到數(shù)據(jù)的整體特性,提高了數(shù)據(jù)的局部結(jié)構(gòu)能力,降低了算法的時間復(fù)雜度;但同時,VAE 在對大數(shù)據(jù)集Shuttle 進(jìn)行潛在空間表示的時候,由于數(shù)據(jù)量比較大不可避免地會出現(xiàn)過擬合現(xiàn)象,這也是本文算法需要改進(jìn)的地方。
3.2 健康數(shù)據(jù)異常檢測結(jié)果
算法的性能得到了驗(yàn)證之后,利用該算法在收集到的健康數(shù)據(jù)上進(jìn)行實(shí)驗(yàn),對異常值進(jìn)行檢測。圖4是采用本文算法進(jìn)行異常檢測可視化的結(jié)果。其中黑色點(diǎn)表示正常數(shù)據(jù),紅色點(diǎn)表示異常數(shù)據(jù)。

圖4 GMGM 算法在健康數(shù)據(jù)上異常檢測結(jié)果Fig.4 Detection results by GMGM on health data
為了突出該算法的優(yōu)勢,又采用了檢測效果同樣好的DAGMM 算法在同一實(shí)驗(yàn)環(huán)境下對同樣的健康數(shù)據(jù)進(jìn)行了實(shí)驗(yàn),結(jié)果如圖5。
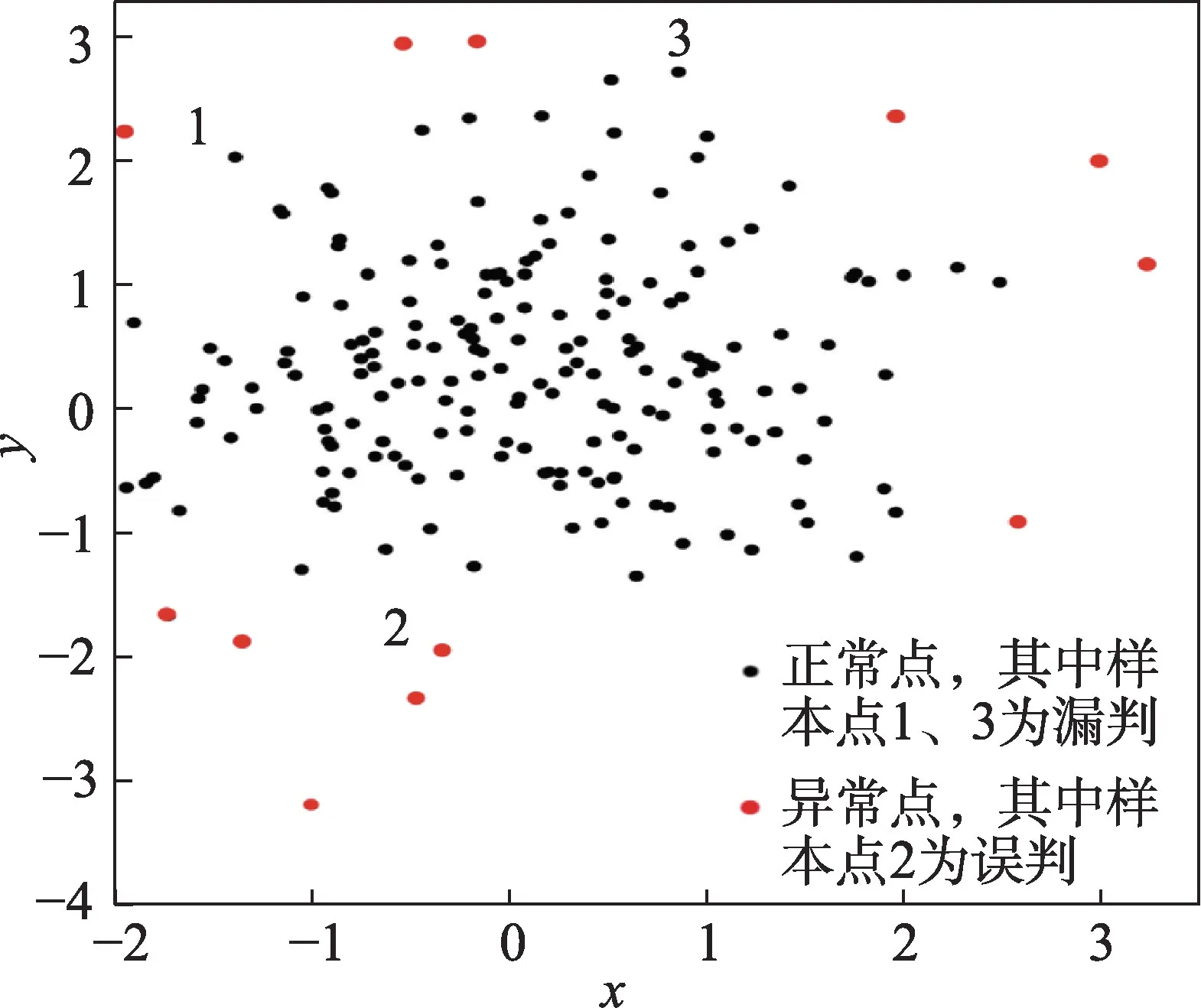
圖5 DAGMM 算法在健康數(shù)據(jù)上異常檢測結(jié)果Fig.5 Detection results by DAGMM on health data
對比圖4 和圖5 可以看出,兩種檢測方法對于比較明顯的異常樣本點(diǎn)都可以檢測出來,但是DAGMM算法在數(shù)據(jù)邊緣存在誤判和漏判現(xiàn)象。標(biāo)號為1、3的樣本點(diǎn)為漏判,標(biāo)號為2 的樣本點(diǎn)為誤判。而本文算法在檢測邊緣異常點(diǎn)時,僅3 樣本點(diǎn)進(jìn)行了漏判,整體性能較好。
4 結(jié)論
針對運(yùn)動手環(huán)采集的活動數(shù)據(jù)存在未知異常數(shù)據(jù)的問題,利用GMGM 用以進(jìn)行異常檢測。在該模型中,使用生成模型中的樣本潛在分布和重構(gòu)特征來訓(xùn)練DBN,以估計(jì)各樣本的混合成員隸屬度;接著,利用GMM 預(yù)測各樣本的密度進(jìn)行異常值的檢測。生成網(wǎng)絡(luò)與GMM 共同優(yōu)化,避免了模型解耦的影響。在實(shí)驗(yàn)部分,采用具有代表性的異常檢測數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),結(jié)果表明,該方法具有理想的檢測效果。最后,利用該方法在真實(shí)數(shù)據(jù)集上可視化異常檢測結(jié)果,結(jié)果表明漏報率和誤報率均低于DAGMM算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
