用于無(wú)監(jiān)督域適應(yīng)的深度對(duì)抗重構(gòu)分類(lèi)網(wǎng)絡(luò)
2022-05-17 06:01:52林佳偉王士同
計(jì)算機(jī)與生活 2022年5期
林佳偉,王士同
1.江南大學(xué) 人工智能與計(jì)算機(jī)學(xué)院,江蘇 無(wú)錫214122
2.江南大學(xué) 江蘇省媒體設(shè)計(jì)與軟件技術(shù)重點(diǎn)實(shí)驗(yàn)室,江蘇 無(wú)錫214122
近年來(lái),神經(jīng)網(wǎng)絡(luò)的發(fā)展已經(jīng)為各種機(jī)器學(xué)習(xí)任務(wù)帶來(lái)了顯著的效果,基于卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)的特征表示已經(jīng)被證明在視覺(jué)識(shí)別任務(wù)上是十分有效的。尤其是CNN 在ImageNet 數(shù)據(jù)集中測(cè)試達(dá)到了非常高的準(zhǔn)確率,深度神經(jīng)網(wǎng)絡(luò)便成為了機(jī)器學(xué)習(xí)領(lǐng)域的一個(gè)重要的分支。深度神經(jīng)網(wǎng)絡(luò)已經(jīng)被證明具有強(qiáng)大的特征表示能力,傳統(tǒng)的深度網(wǎng)絡(luò)模型只建立在單個(gè)域上,難以獲得可遷移的深度表示。深度神經(jīng)網(wǎng)絡(luò)的較高準(zhǔn)確率依賴(lài)于大量的帶有人工標(biāo)簽的數(shù)據(jù)集來(lái)進(jìn)行訓(xùn)練,對(duì)原始數(shù)據(jù)集進(jìn)行人工標(biāo)注的成本是十分昂貴的,這成為阻礙深度神經(jīng)網(wǎng)絡(luò)進(jìn)一步發(fā)展的關(guān)鍵因素。另外,由于計(jì)算機(jī)視覺(jué)中的各種因素(例如分辨率、視點(diǎn)、天氣狀況等),有些應(yīng)用數(shù)據(jù)的分布會(huì)隨著時(shí)間的推移而發(fā)生變化,會(huì)造成訓(xùn)練集和測(cè)試集的數(shù)據(jù)分布不匹配,而傳統(tǒng)的深度神經(jīng)網(wǎng)絡(luò)是基于數(shù)據(jù)同分布假設(shè)的,這樣訓(xùn)練出來(lái)的網(wǎng)絡(luò)會(huì)在訓(xùn)練集上表現(xiàn)出良好的效果,但是在測(cè)試集上表現(xiàn)出的分類(lèi)性能會(huì)大大降低。一個(gè)很好的應(yīng)用場(chǎng)景的例子是用于車(chē)牌號(hào)識(shí)別的分類(lèi)器對(duì)于在雨天場(chǎng)景下的車(chē)牌號(hào)識(shí)別效果會(huì)很差。對(duì)于如何解決標(biāo)簽不足,訓(xùn)練數(shù)據(jù)與測(cè)試數(shù)據(jù)分布不同的問(wèn)題是深度神經(jīng)網(wǎng)絡(luò)所面臨的一個(gè)重要挑戰(zhàn)。
域適應(yīng)算法通過(guò)使用未標(biāo)記的測(cè)試數(shù)據(jù)有效地解決了上述問(wèn)題,未標(biāo)記的測(cè)試數(shù)據(jù)為分類(lèi)器的訓(xùn)練提供了輔助信息,與僅使用訓(xùn)練數(shù)據(jù)來(lái)學(xué)習(xí)的分類(lèi)器相比精度有了明顯的提高,從而避免了對(duì)測(cè)試數(shù)據(jù)重新進(jìn)行標(biāo)記的工作。常用的領(lǐng)域自適應(yīng)方法主要有三種,分別是基于樣本選擇的方法、基于模型參數(shù)關(guān)系的方法和基于特征變換的方法。本文關(guān)注的是基于模型參數(shù)關(guān)系的方法,基于模型參數(shù)關(guān)系的深度域適應(yīng)的主要任務(wù)是將源域和目標(biāo)域的數(shù)據(jù)從原始特征空間映射到一個(gè)新的特征空間。在該特征空間中,源域數(shù)據(jù)和目標(biāo)域數(shù)據(jù)的數(shù)據(jù)分布是相同的。通過(guò)利用機(jī)器學(xué)習(xí)算法對(duì)帶有標(biāo)簽的源域數(shù)據(jù)進(jìn)行分類(lèi),從而實(shí)現(xiàn)對(duì)未被標(biāo)注的目標(biāo)域數(shù)據(jù)進(jìn)行分類(lèi)。
國(guó)內(nèi)外學(xué)者已提出很多域適應(yīng)方法。遷移的概念最初是由Pratt 等人在1991 年首次提出的,并且進(jìn)一步介紹了神經(jīng)網(wǎng)絡(luò)之間的遷移。近年來(lái),域適應(yīng)問(wèn)題引起了廣泛的關(guān)注,在計(jì)算機(jī)視覺(jué)領(lǐng)域也被叫作數(shù)據(jù)集偏差問(wèn)題,主要應(yīng)用于對(duì)象識(shí)別,很多遷移學(xué)習(xí)或域適應(yīng)方法通過(guò)將源域風(fēng)險(xiǎn)、領(lǐng)域之間的差異和聯(lián)合誤差的凸組合最小化來(lái)預(yù)測(cè)目標(biāo)域數(shù)據(jù)集的誤差上限。具體而言,給定一個(gè)帶標(biāo)簽的源域數(shù)據(jù)D和一個(gè)不帶標(biāo)簽的目標(biāo)域數(shù)據(jù)D,根據(jù)Ben-David 定理,目標(biāo)域的風(fēng)險(xiǎn)E()能夠結(jié)合源域風(fēng)險(xiǎn)E ()和領(lǐng)域之間的差異(D,D)來(lái)控制,即通過(guò)最小化E()=E ()+(D,D)的上限來(lái)實(shí)現(xiàn)域適應(yīng)。2014 年,Yosinski 等人在AlexNet 網(wǎng)絡(luò)上證明了深度學(xué)習(xí)的可遷移性,通過(guò)網(wǎng)絡(luò)結(jié)構(gòu)的遷移以及對(duì)網(wǎng)絡(luò)結(jié)構(gòu)的微調(diào)不僅能夠進(jìn)行特征的遷移,而且能夠加速網(wǎng)絡(luò)的學(xué)習(xí)和優(yōu)化,對(duì)于神經(jīng)網(wǎng)絡(luò)的可解釋性以及深度學(xué)習(xí)的可遷移性解釋具有十分重要的意義。研究表明,深度學(xué)習(xí)能夠很好地學(xué)習(xí)到可遷移的數(shù)據(jù)表示形式,但是這種數(shù)據(jù)表示形式只能夠減少而不能消除跨域之間的差異。實(shí)際上,子空間對(duì)齊(subspace alignment,SA)算法通過(guò)計(jì)算源域子空間特征和目標(biāo)域子空間特征之間的距離來(lái)衡量不同域之間的分布差異,這種差異可以通過(guò)學(xué)習(xí)子空間之間的特征變換來(lái)對(duì)齊源域和目標(biāo)域的特征進(jìn)行消除。深度學(xué)習(xí)已經(jīng)被證明在視覺(jué)識(shí)別上具有良好的效果,在領(lǐng)域適應(yīng)方面發(fā)揮著重要的作用,Glorot等人提出的去噪自動(dòng)編碼器是一種簡(jiǎn)單的全連接網(wǎng)絡(luò),解決了大規(guī)模的情感分類(lèi)問(wèn)題。眾所周知,卷積神經(jīng)網(wǎng)絡(luò)在視覺(jué)識(shí)別領(lǐng)域具有更為領(lǐng)先的性能。Chopra 等人通過(guò)對(duì)多個(gè)卷積自動(dòng)編碼器進(jìn)行分層訓(xùn)練,同時(shí)用目標(biāo)域樣本逐漸替換源域樣本,沿著源域和目標(biāo)域之間的“插值路徑”連續(xù)學(xué)習(xí)多個(gè)分布的中間表示。Ghifary 通過(guò)在深度網(wǎng)絡(luò)中嵌入最大均值差異(maximum mean discrepancy,MMD)正則化來(lái)減少不同域樣本之間的隱藏層表示的分布不匹配問(wèn)題。針對(duì)標(biāo)簽空間不同的問(wèn)題,You 等人提出利用貝葉斯法則計(jì)算出(y|y),以此得出不同標(biāo)簽空間之間的映射關(guān)系,通過(guò)協(xié)同調(diào)優(yōu)的方式來(lái)優(yōu)化網(wǎng)絡(luò)以此完成分布適配的問(wèn)題。
2016 年,Ganin 和Ustinova 等人提出了領(lǐng)域?qū)咕W(wǎng)絡(luò)(domain adversarial neural network,DANN)的模型,DANN 通過(guò)對(duì)抗學(xué)習(xí)的思想來(lái)對(duì)齊源域和目標(biāo)域的數(shù)據(jù)分布。雖然DANN 模型完成了從源域到目標(biāo)域的知識(shí)遷移,但是該模型在對(duì)齊域間數(shù)據(jù)分布的同時(shí)使得目標(biāo)域數(shù)據(jù)在經(jīng)過(guò)特征變換前后的數(shù)據(jù)分布差異過(guò)大,破壞了目標(biāo)域數(shù)據(jù)的局部特征,而這些特征對(duì)目標(biāo)域數(shù)據(jù)分類(lèi)精度的提升十分關(guān)鍵。
本文的主要貢獻(xiàn)可以歸納如下:
(1)與傳統(tǒng)的無(wú)監(jiān)督域適應(yīng)算法相比,在深度域適應(yīng)網(wǎng)絡(luò)上引入了局部信息保持的概念,減少了因?yàn)樘卣髯儞Q而導(dǎo)致的目標(biāo)域數(shù)據(jù)信息損失的問(wèn)題,在對(duì)齊源域和目標(biāo)域數(shù)據(jù)分布的同時(shí)有效地保持了原始數(shù)據(jù)的信息。
(2)通過(guò)將用于分布適配的共同特征和提高分類(lèi)精度的局部特征聯(lián)合保持的思想,提出一個(gè)用于無(wú)監(jiān)督域適應(yīng)的深度對(duì)抗重構(gòu)分類(lèi)網(wǎng)絡(luò)(deep adversarialreconstruction-classification networks,DARCN)的模型。DARCN 模型應(yīng)用了生成對(duì)抗網(wǎng)絡(luò)(generative adversarial networks,GAN)和自動(dòng)編碼器的思想提升了域間自適應(yīng)特征的學(xué)習(xí)能力。
(3)通過(guò)共同優(yōu)化和分開(kāi)優(yōu)化這兩種策略來(lái)實(shí)現(xiàn)跨域間的共同特征和局部特征的聯(lián)合保持。在四種傳統(tǒng)的數(shù)字分類(lèi)數(shù)據(jù)集以及遷移學(xué)習(xí)經(jīng)典數(shù)據(jù)集Office-Caltech10 上進(jìn)行了實(shí)驗(yàn),實(shí)驗(yàn)表明,與傳統(tǒng)的領(lǐng)域自適應(yīng)模型相比,DARCN 模型在無(wú)監(jiān)督域適應(yīng)的任務(wù)上具有明顯的優(yōu)越性。
1 相關(guān)知識(shí)
2014 年,GAN 作為目前最先進(jìn)的深度生成模型得到了快速的發(fā)展,GAN 通過(guò)對(duì)抗學(xué)習(xí)的機(jī)制來(lái)生成與目標(biāo)分布相似的數(shù)據(jù),已經(jīng)被廣泛地應(yīng)用在圖像生成、圖像風(fēng)格變換、人體姿態(tài)識(shí)別等相關(guān)領(lǐng)域。生成對(duì)抗網(wǎng)絡(luò)利用二人零和博弈的思想,利用生成器和判別器之間的對(duì)抗來(lái)解決生成問(wèn)題,是一種通過(guò)對(duì)抗過(guò)程來(lái)訓(xùn)練生成模型的新框架。其中,生成器用于捕獲數(shù)據(jù)分布,判別器用來(lái)區(qū)分真實(shí)數(shù)據(jù)分布和模擬數(shù)據(jù)分布。用表示隨機(jī)噪聲,表示真實(shí)數(shù)據(jù),GAN 網(wǎng)絡(luò)的目標(biāo)函數(shù)如下:
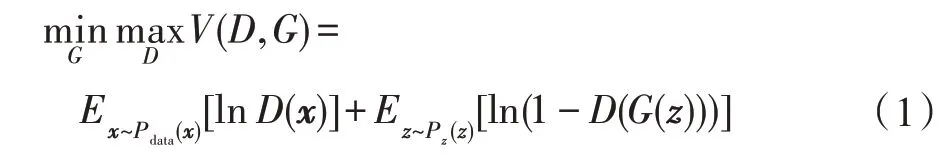
等式(1)的目標(biāo)函數(shù)表明了生成對(duì)抗網(wǎng)絡(luò)的優(yōu)化是一個(gè)最大最小優(yōu)化問(wèn)題,第一項(xiàng)表示判別器對(duì)真實(shí)數(shù)據(jù)的判斷誤差,第二項(xiàng)表示判別器對(duì)生成數(shù)據(jù)的判別誤差。GAN 通過(guò)單獨(dú)交替迭代訓(xùn)練的方式來(lái)優(yōu)化模型的生成器和判別器,最終學(xué)習(xí)出真實(shí)樣本數(shù)據(jù)集的數(shù)據(jù)分布。
深度域適應(yīng)的目的是要學(xué)習(xí)一個(gè)可以很好地從一個(gè)域到另一個(gè)域的泛化模型,這就要求輸入到分類(lèi)器的數(shù)據(jù)不包含有關(guān)輸入來(lái)源的判別性信息。因此,利用GAN 的判別器嵌入到神經(jīng)網(wǎng)絡(luò)用作域適應(yīng)組件可以很好地消除不同數(shù)據(jù)域之間的獨(dú)立特征。
自動(dòng)編碼器是一種無(wú)監(jiān)督的學(xué)習(xí)算法,常用于降維和特征學(xué)習(xí)。自動(dòng)編碼器由兩個(gè)模塊組成:(1)從輸入數(shù)據(jù)提取特征的編碼器網(wǎng)絡(luò)();(2)從低維特征重構(gòu)回原始數(shù)據(jù)的解碼器網(wǎng)絡(luò)()。通常,使用編碼器的最后一層作為瓶頸層來(lái)表示數(shù)據(jù)的低維特征。自動(dòng)編碼器的損失函數(shù)如下:
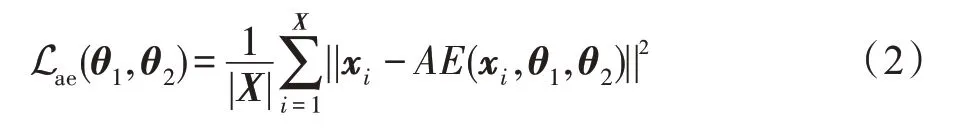
其中,代表輸入數(shù)據(jù)集,AE 代表自動(dòng)編碼器的神經(jīng)網(wǎng)絡(luò),、分別代表編碼器()和解碼器()的參數(shù),||·||表示輸入數(shù)據(jù)的二范數(shù)。自動(dòng)編碼器網(wǎng)絡(luò)是分層且對(duì)稱(chēng)的,在編碼器模塊中,隱藏層的神經(jīng)元數(shù)量逐漸減少,對(duì)稱(chēng)地,在解碼器模塊中,隱藏層的神經(jīng)元數(shù)量逐漸增多,最終輸出層和輸入層有著一樣多的神經(jīng)元。這意味著通過(guò)編碼-解碼的方式,能夠提取出原始輸入數(shù)據(jù)的低維特征并且原始數(shù)據(jù)能夠通過(guò)該低維特征得到高效的重構(gòu)。
自動(dòng)編碼器的優(yōu)化過(guò)程是把編碼層堆疊在原始圖像上將輸入的3D 圖像轉(zhuǎn)化為高維的特征,該層稱(chēng)之為“嵌入層”。為了以無(wú)監(jiān)督的方式訓(xùn)練它,通過(guò)反卷積的手段將解碼層堆疊到嵌入層將高維特征轉(zhuǎn)換為原始圖像,通過(guò)梯度下降法將原始圖像和重構(gòu)圖像的均方誤差最小化來(lái)更新編碼器和解碼器的參數(shù)。因此,嵌入層的高維特征攜帶著原始圖像最為關(guān)鍵的信息。深度域適應(yīng)通過(guò)將源域和目標(biāo)域映射到一個(gè)新的特征空間當(dāng)中,在這個(gè)特征空間源域和目標(biāo)域的數(shù)據(jù)分布相似。把自動(dòng)編碼器的這一優(yōu)點(diǎn)應(yīng)用到深度域適應(yīng)中,在縮小數(shù)據(jù)域之間分布差異的同時(shí),將目標(biāo)域數(shù)據(jù)最為關(guān)鍵的信息嵌入到新的特征空間。
2 深度對(duì)抗重構(gòu)分類(lèi)網(wǎng)絡(luò)
本章首先簡(jiǎn)要地討論了域適應(yīng)問(wèn)題,然后介紹了深度對(duì)抗重構(gòu)分類(lèi)網(wǎng)絡(luò)的思想以及體系結(jié)構(gòu)。
深度學(xué)習(xí)的可遷移性是深度域適應(yīng)能夠?qū)崿F(xiàn)的關(guān)鍵。域適應(yīng)是一種解決源域和目標(biāo)域數(shù)據(jù)分布偏移的一種機(jī)器學(xué)習(xí)算法,通過(guò)特征變換學(xué)習(xí)不同分布數(shù)據(jù)之間的共同特征,將從源域?qū)W習(xí)到的知識(shí)遷移到目標(biāo)域,解決了傳統(tǒng)監(jiān)督學(xué)習(xí)需要大量人工標(biāo)注標(biāo)簽的問(wèn)題。根據(jù)域適應(yīng)理論,深度網(wǎng)絡(luò)可以通過(guò)限制源域的標(biāo)簽分類(lèi)誤差以及源域和目標(biāo)域深度特征的領(lǐng)域差異來(lái)控制目標(biāo)域的分類(lèi)誤差。
深度對(duì)抗重構(gòu)分類(lèi)網(wǎng)絡(luò)(DARCN)應(yīng)用了GAN的對(duì)抗性思想以及自動(dòng)編碼器的重構(gòu)思想。(1)將GAN 的生成模型當(dāng)作DARCN 模型的共同特征提取器,判別模型當(dāng)作DARCN 的域判別器,通過(guò)公共特征提取器和域判別器的組合來(lái)保證數(shù)據(jù)深度特征的領(lǐng)域不變性。(2)將自動(dòng)編碼器的編碼部分當(dāng)作DARCN 的局部特征提取器。解碼部分當(dāng)作DARCN模型的特征重構(gòu)器,通過(guò)在目標(biāo)域數(shù)據(jù)上應(yīng)用特征提取器和特征重構(gòu)器來(lái)保留目標(biāo)域數(shù)據(jù)中對(duì)分類(lèi)精度有提升的關(guān)鍵信息。通過(guò)在數(shù)據(jù)分布相同的特征空間上添加目標(biāo)域數(shù)據(jù)獨(dú)有的信息,使得提取出的特征能夠在保留源域分類(lèi)信息的同時(shí)和目標(biāo)域原始數(shù)據(jù)有更為相似的分布,在遷移源域分類(lèi)信息的同時(shí)盡可能地保留目標(biāo)域數(shù)據(jù)的原始分布。基于這種思想,DARCN 的網(wǎng)絡(luò)架構(gòu)應(yīng)該滿(mǎn)足以下三個(gè)任務(wù):①能夠?qū)υ从驍?shù)據(jù)進(jìn)行分類(lèi);②嵌入的域判別器無(wú)法鑒別數(shù)據(jù)的來(lái)源;③能夠?qū)δ繕?biāo)域數(shù)據(jù)進(jìn)行有效的重構(gòu)。DARCN 卷積架構(gòu)應(yīng)該通過(guò)提取一個(gè)深層的特征表示來(lái)同時(shí)實(shí)現(xiàn)以上三個(gè)任務(wù)。
如圖1 所示,DARCN 由4 個(gè)模塊組成:特征提取器G(·)、標(biāo)簽分類(lèi)器G(·)、域分類(lèi)器G(·)和特征重構(gòu)器G(·),對(duì)應(yīng)的網(wǎng)絡(luò)參數(shù)分別為θ、θ、θ、θ。DARCN 的域適應(yīng)過(guò)程是G(·)和G(·)相互博弈的過(guò)程,域判別器G(·)通過(guò)不斷訓(xùn)練以區(qū)分源域和目標(biāo)域,特征提取器G(·)同時(shí)進(jìn)行訓(xùn)練以使得域判別器不能夠分辨出數(shù)據(jù)是來(lái)自哪個(gè)域。網(wǎng)絡(luò)的目標(biāo)是尋求一個(gè)支持多任務(wù)的共享特征映射參數(shù)θ。對(duì)于輸入到DARCN 的第個(gè)數(shù)據(jù)(x,y),標(biāo)簽分類(lèi)器、域分類(lèi)器和數(shù)據(jù)重構(gòu)器的損失L、L和L分別可以寫(xiě)成:
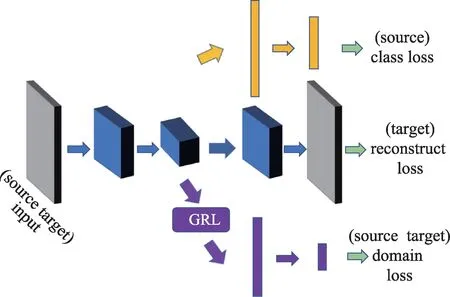
圖1 DARCN 架構(gòu)圖Fig.1 Architecture of DARCN
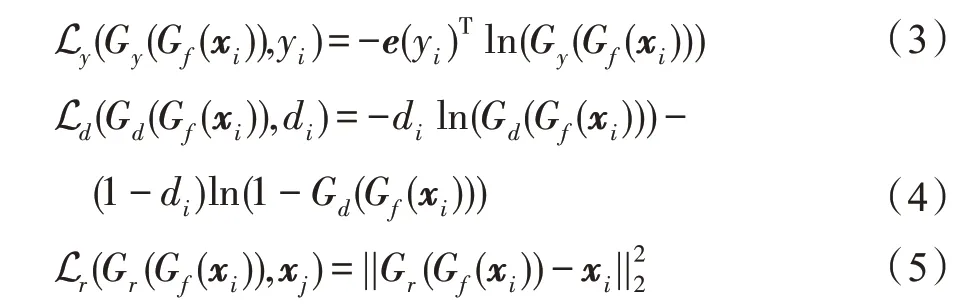
其中,d表示x是來(lái)源于哪個(gè)域,如果x~D,d=0;如果x~D,d=1。為標(biāo)簽y的one-hot形式。交叉熵誤差能夠有效地減少網(wǎng)絡(luò)模型在優(yōu)化過(guò)程中產(chǎn)生的梯度消失問(wèn)題,能夠更好更快地收斂到局部最小值。從等式(6)可以看出,由于訓(xùn)練數(shù)據(jù)的分布是固定的,優(yōu)化交叉熵?fù)p失等價(jià)于優(yōu)化訓(xùn)練數(shù)據(jù)分布和學(xué)習(xí)模型分布之間的KL 散度。當(dāng)網(wǎng)絡(luò)優(yōu)化結(jié)束時(shí),模型會(huì)有效地模擬出訓(xùn)練數(shù)據(jù)的真實(shí)分布。因此在DARCN 模型中用交叉熵?fù)p失來(lái)表示分類(lèi)誤差。由于均方差損失函數(shù)處處可導(dǎo),便于使用梯度下降法較快地收斂到極小值,因此在DARCN 模型中使用均方差損失來(lái)表示目標(biāo)域圖像的重構(gòu)誤差。

通過(guò)優(yōu)化目標(biāo)函數(shù)E(θ,θ,θ,θ)來(lái)實(shí)現(xiàn)源域到目標(biāo)域的知識(shí)遷移,同時(shí)保留目標(biāo)域數(shù)據(jù)的局部特征結(jié)構(gòu),完成通過(guò)源域的分類(lèi)器來(lái)對(duì)目標(biāo)域進(jìn)行分類(lèi)。其中,、是需要手動(dòng)調(diào)節(jié)的超參數(shù),以實(shí)現(xiàn)三者之間的權(quán)衡。通過(guò)等式(10)和等式(11)對(duì)網(wǎng)絡(luò)參數(shù)進(jìn)行優(yōu)化,DARCN 有效地學(xué)習(xí)了來(lái)自D和D數(shù)據(jù)的隱藏層表示G(x)和G(x),G(x)保留了目標(biāo)域數(shù)據(jù)的特征,域適應(yīng)組件不能夠很好地分辨出G(x)和G(x),體現(xiàn)了隱藏層的特征G具有領(lǐng)域不變的特性,從而實(shí)現(xiàn)了利用帶標(biāo)簽的源域數(shù)據(jù)和不帶標(biāo)簽的目標(biāo)域數(shù)據(jù)準(zhǔn)確對(duì)目標(biāo)域數(shù)據(jù)進(jìn)行分類(lèi)。
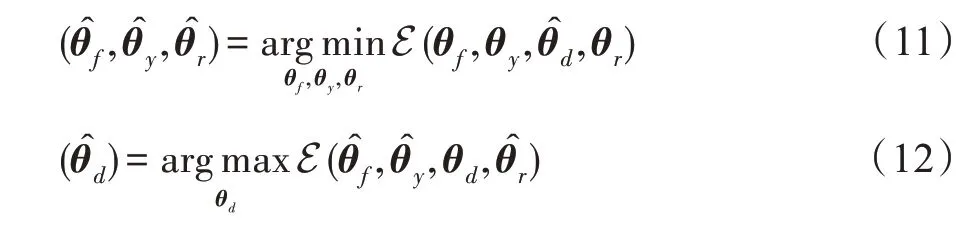
從等式(11)和等式(12)可以看出,DARCN 網(wǎng)絡(luò)的優(yōu)化涉及關(guān)于θ、θ、θ的最小化問(wèn)題以及關(guān)于θ的最大化問(wèn)題。因此,DARCN 網(wǎng)絡(luò)結(jié)構(gòu)與傳統(tǒng)的多任務(wù)神經(jīng)網(wǎng)絡(luò)相比添加了梯度反轉(zhuǎn)層(gradient reversal layer,GRL),即在正向傳播的網(wǎng)絡(luò)流經(jīng)過(guò)該層時(shí)深度特征保持不變,反向傳播的網(wǎng)絡(luò)流經(jīng)過(guò)該層時(shí)梯度乘以一個(gè)負(fù)常數(shù),由于GRL 沒(méi)有與之關(guān)聯(lián)的參數(shù),該層沒(méi)有任何參數(shù)需要更新,較整個(gè)模型相比其運(yùn)算成本可以忽略不計(jì)。DARCN 網(wǎng)絡(luò)采用Adam算法進(jìn)行優(yōu)化,式(13)為參數(shù)更新的迭代公式。


3 實(shí)驗(yàn)與結(jié)果
本章展示了深度對(duì)抗重構(gòu)網(wǎng)絡(luò)在流行數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果。實(shí)驗(yàn)數(shù)據(jù)集包括兩大部分:一部分是用于圖像分類(lèi)的經(jīng)典數(shù)字?jǐn)?shù)據(jù)集;另一部分是遷移學(xué)習(xí)經(jīng)典數(shù)據(jù)集Office-Caltech10。本實(shí)驗(yàn)將提出的DARCN 算法與其他域適應(yīng)算法進(jìn)行了對(duì)比,實(shí)驗(yàn)結(jié)果表示DARCN在圖像分類(lèi)的域適應(yīng)任務(wù)上取得了良好的效果。本文所有實(shí)驗(yàn)均在同一環(huán)境下完成,計(jì)算機(jī)處理器配置為IntelCorei5-4210 CPU@2.6 GHz,內(nèi)存8 GB。在Windows10環(huán)境下配置python環(huán)境以及pytorch 框架。所有實(shí)驗(yàn)均在python3.6 以及pytorch1.0的框架下實(shí)現(xiàn)。
3.1 四種數(shù)字?jǐn)?shù)據(jù)集分類(lèi)
本組實(shí)驗(yàn)研究了DARCN 在MNIST、MNIST-M、SVHN 以及USPS 等數(shù)據(jù)集上的遷移性能。目的是利用源域和目標(biāo)域進(jìn)行訓(xùn)練來(lái)對(duì)未知標(biāo)簽的目標(biāo)域進(jìn)行無(wú)監(jiān)督域適應(yīng)。通過(guò)3 組跨域識(shí)別的任務(wù)來(lái)評(píng)估算法的準(zhǔn)確性:(1)MNIST 數(shù)據(jù)集和MNIST-M 數(shù)據(jù)集;(2)SVHN 數(shù)據(jù)集和MNIST 數(shù)據(jù)集;(3)MNIST數(shù)據(jù)集和USPS 數(shù)據(jù)集。
MNIST 數(shù)據(jù)集是由美國(guó)國(guó)家標(biāo)準(zhǔn)技術(shù)與研究所發(fā)布的圖片分類(lèi)數(shù)據(jù)集,由250 個(gè)不同的人手寫(xiě)的數(shù)字組成的10 分類(lèi)灰度圖像,其中包含60 000 張的訓(xùn)練圖像和10 000 張的測(cè)試圖像,像素大小為28×28。MNIST-M 數(shù)據(jù)集由MNISTI 數(shù)據(jù)集和BSDS500 數(shù)據(jù)集中的隨機(jī)色塊混合而成,其中包含59 000 張訓(xùn)練圖像和測(cè)試圖像,圖像是像素為32×32 的彩色圖像。SVHN 數(shù)據(jù)集是由斯坦福大學(xué)于2011 年發(fā)布的圖像分類(lèi)數(shù)據(jù)集,其中的數(shù)據(jù)均采自Google 街景圖像中的門(mén)牌號(hào),包括4 578 張訓(xùn)練圖像和1 627 張測(cè)試圖像,圖像像素大小為32×32。USPS 數(shù)據(jù)集是美國(guó)郵政手寫(xiě)數(shù)字?jǐn)?shù)據(jù)集,其中包括999 張訓(xùn)練圖像和250張測(cè)試圖像,像素大小為32×32。在MNIST 數(shù)據(jù)集到MNIST-M 數(shù)據(jù)集跨域識(shí)別的任務(wù)上,輸入網(wǎng)絡(luò)的圖像大小為28×28,其他任務(wù)中,輸入網(wǎng)絡(luò)的圖像大小為32×32。另外,所有像素全部歸一化到[0,1]。
現(xiàn)將DARCN算法與以下方法比較。(1)CovNet:僅在源域上訓(xùn)練的有監(jiān)督卷積神經(jīng)網(wǎng)絡(luò)。(2)SDA:堆疊式降噪自動(dòng)編碼器,已經(jīng)成功應(yīng)用到情感分析領(lǐng)域的深度域適應(yīng)模型。(3)SA:子空間對(duì)齊,通過(guò)優(yōu)化映射函數(shù)將源子空間轉(zhuǎn)換為目標(biāo)域子空間來(lái)實(shí)現(xiàn)無(wú)監(jiān)督域適應(yīng)。(4)DANN:域?qū)股窠?jīng)網(wǎng)絡(luò),通過(guò)GAN的思想來(lái)實(shí)現(xiàn)源域和目標(biāo)域的不可區(qū)分性。DANN和DARCN 具有相似的網(wǎng)絡(luò)架構(gòu)。(5)CovNet:在目標(biāo)域上訓(xùn)練的有監(jiān)督卷積神經(jīng)網(wǎng)絡(luò)。
第一個(gè)實(shí)驗(yàn)測(cè)試了經(jīng)典數(shù)字?jǐn)?shù)據(jù)集的跨域識(shí)別。在該數(shù)據(jù)集上的模型主要由4個(gè)模塊組成:(1)特征提取模塊;(2)標(biāo)簽分類(lèi)模塊;(3)域適應(yīng)模塊;(4)特征重構(gòu)模塊。詳細(xì)網(wǎng)絡(luò)結(jié)構(gòu)如圖2、圖3 所示。網(wǎng)絡(luò)所有的隱藏層均使用ReLU 作為激活函數(shù)并且使用了歸一化的技巧,所有參數(shù)均使用Adam 優(yōu)化器進(jìn)行更新,學(xué)習(xí)速率是10,采用學(xué)習(xí)率衰減的策略,分類(lèi)任務(wù)以及域適應(yīng)任務(wù)采用交叉熵誤差作為目標(biāo)函數(shù),重構(gòu)任務(wù)采用均方差誤差作為目標(biāo)函數(shù)。和是需要手動(dòng)調(diào)節(jié)的超參數(shù),根據(jù)源域數(shù)據(jù)的準(zhǔn)確性控制和,取值為[0,1]。圖4 展示了DARCN 在MNIST 和MNIST_M 數(shù)據(jù)集上進(jìn)行域適應(yīng)不同的超參數(shù)對(duì)算法性能的影響(超參數(shù)和DANN 模型設(shè)置相同)。

圖2 實(shí)驗(yàn)1 中的網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.2 Network structure diagram in experiment 1
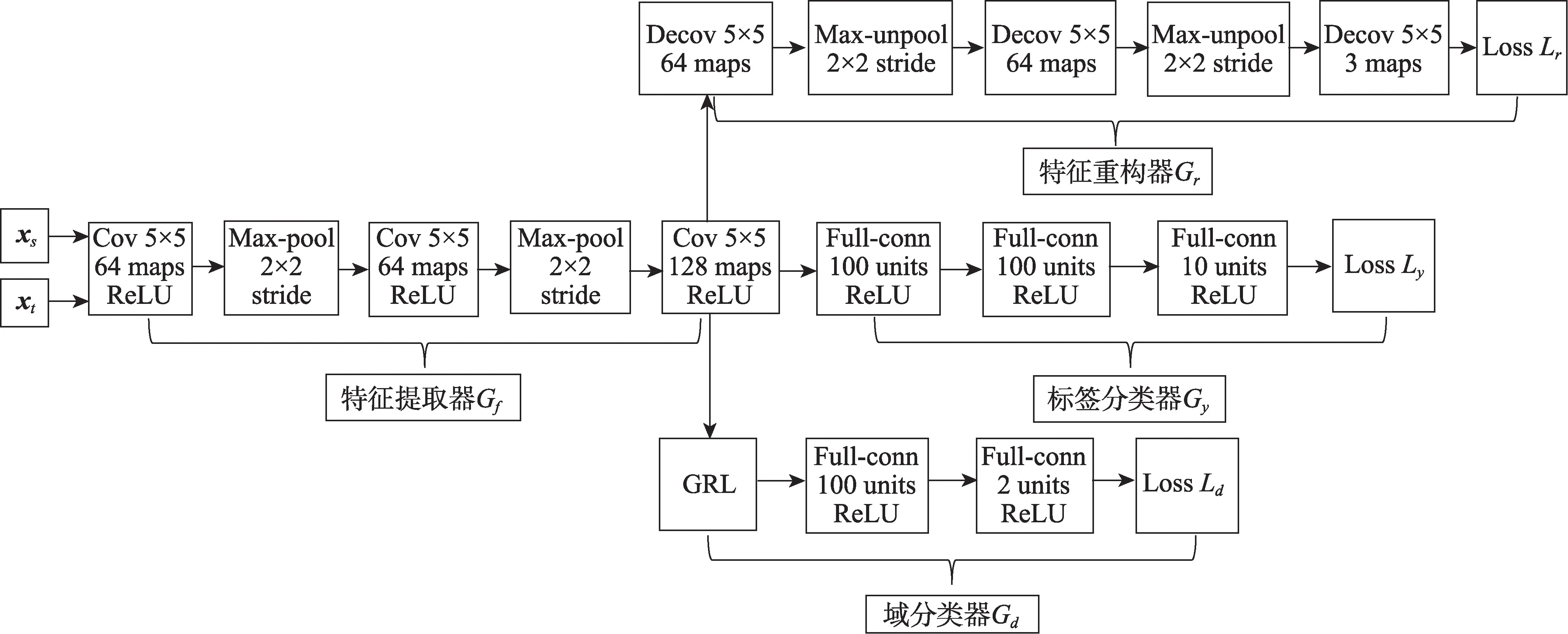
圖3 實(shí)驗(yàn)2、實(shí)驗(yàn)3 中的網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.3 Network structure diagram in experiments 2 and 3
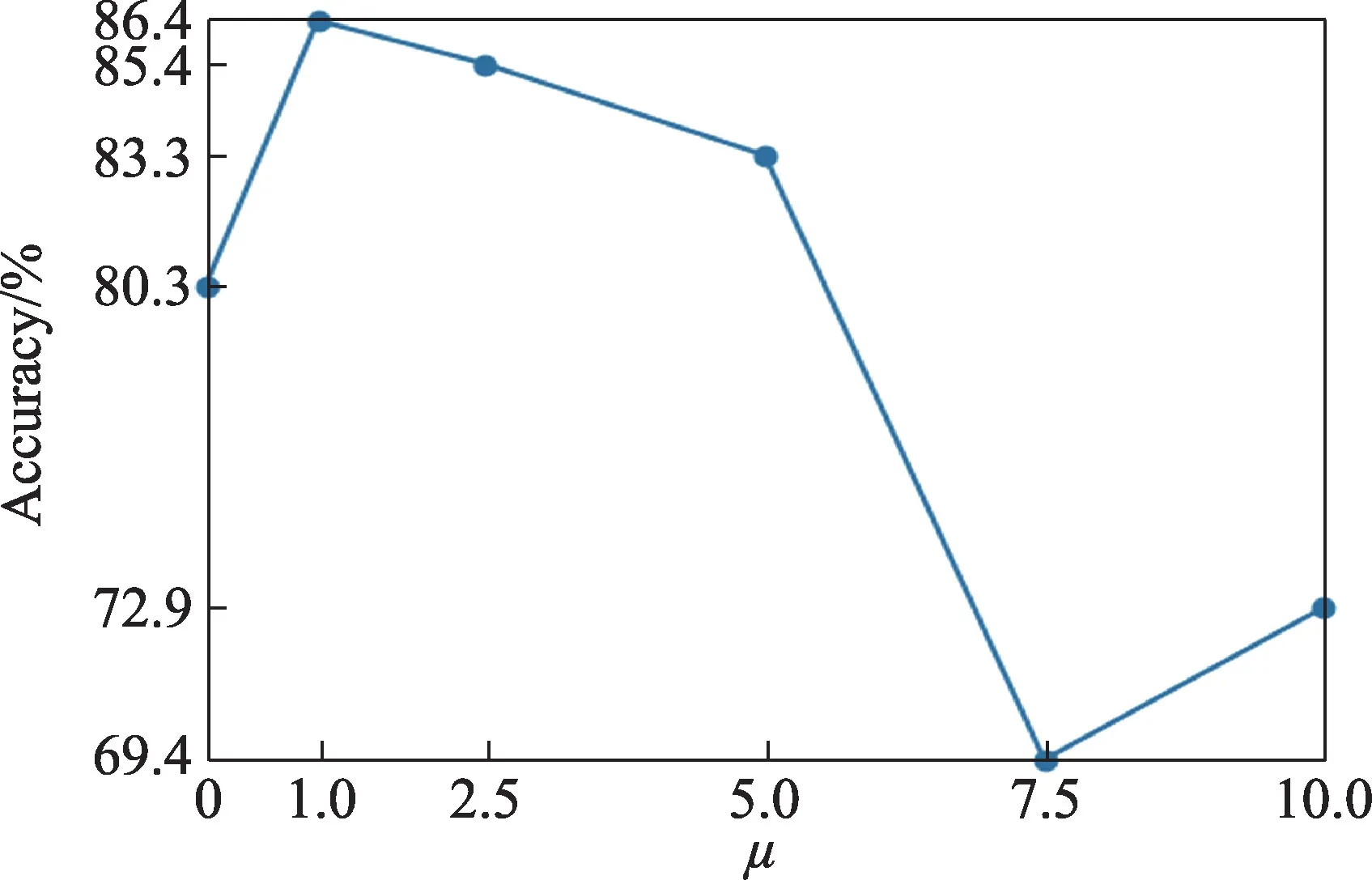
圖4 不同的超參數(shù)μ 對(duì)DARCN 模型性能的影響Fig.4 Influence of different parameter μ on DARCN
表1 總結(jié)了在相同環(huán)境下獨(dú)立運(yùn)行10 次的跨域識(shí)別的平均精度,在數(shù)字?jǐn)?shù)據(jù)集上實(shí)現(xiàn)了3 組無(wú)監(jiān)督跨域識(shí)別的任務(wù)。觀察實(shí)驗(yàn)結(jié)果可以發(fā)現(xiàn),DARCN模型與DANN 模型相比,在數(shù)字?jǐn)?shù)據(jù)集上遷移的精度提升了約0.06。可見(jiàn)在無(wú)監(jiān)督域適應(yīng)任務(wù)上,DARCN模型在數(shù)字?jǐn)?shù)據(jù)集上的分類(lèi)精度較其他算法有明顯的提升。如圖5所示,通過(guò)將源域數(shù)據(jù)輸入到DARCN模型,可視化特征重構(gòu)器的輸出圖像會(huì)發(fā)現(xiàn),輸出的源域圖片會(huì)添加目標(biāo)域圖片的部分特征,重建的MNIST 圖像具有著和MNIST-M 圖像相似的外觀。從實(shí)驗(yàn)結(jié)果上看,DARCN 模型在數(shù)字?jǐn)?shù)據(jù)集之間的自適應(yīng)效果與其他算法相比準(zhǔn)確率有明顯的提高。在實(shí)際的應(yīng)用場(chǎng)景當(dāng)中,對(duì)于像數(shù)字圖像這種比較簡(jiǎn)單的數(shù)據(jù)集建議使用圖2、圖3 中的網(wǎng)絡(luò)結(jié)構(gòu),采用共同優(yōu)化的方式進(jìn)行訓(xùn)練來(lái)完成不同數(shù)據(jù)域之間的知識(shí)遷移。

圖5 源域圖像(MNIST)、重構(gòu)圖像、目標(biāo)域圖像(MNIST-M)的對(duì)比Fig.5 Comparison of source domain(MNIST)image,reconstructed image and target domain(MNIST-M)image
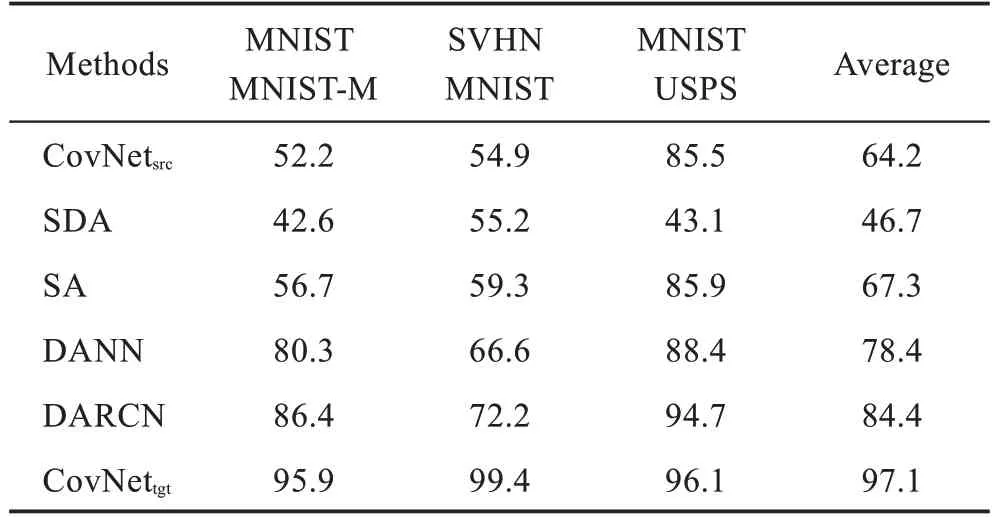
表1 數(shù)字?jǐn)?shù)據(jù)集運(yùn)行10 次平均分類(lèi)精度Table 1 Average classification accuracy of 10 times on digital datasets %
3.2 Office-Caltech10 數(shù)據(jù)集分類(lèi)
本節(jié)研究DARCN 在Office-Caltech10 數(shù)據(jù)集上的遷移性能。Office-Caltech10 數(shù)據(jù)集是在視覺(jué)域適應(yīng)任務(wù)上應(yīng)用得最為廣泛的數(shù)據(jù)集。該數(shù)據(jù)集包括4 個(gè)不同的域:Amazon、Caltech、Dslr、Webcam。4 個(gè)域的圖片分別是在不同的環(huán)境條件下由網(wǎng)絡(luò)相機(jī)和數(shù)碼單反相機(jī)拍攝的。測(cè)試之前,首先對(duì)數(shù)據(jù)集進(jìn)行預(yù)處理,將所有圖像的像素值歸一化成0 到1 之間。在每次迭代過(guò)程中,將所有圖像隨機(jī)裁剪為像素大小為224×224 的圖像,每張圖片按照0.5 的概率對(duì)其進(jìn)行水平翻轉(zhuǎn)。
現(xiàn)將在本組實(shí)驗(yàn)上實(shí)現(xiàn)的DARCN 算法與以下算法進(jìn)行比較:(1)CovNet:僅在源域上訓(xùn)練,目標(biāo)域上測(cè)試的AlexNet網(wǎng)絡(luò)。(2)JGSA:聯(lián)合幾何和統(tǒng)計(jì)對(duì)齊,同時(shí)減少域之間的分布差異和幾何差異來(lái)進(jìn)行域適應(yīng)。(3)DDC:深度域混淆網(wǎng)絡(luò),在AlexNet網(wǎng)絡(luò)的基礎(chǔ)上添加適配層,通過(guò)最大均值差異考察網(wǎng)絡(luò)對(duì)源域和目標(biāo)域的判別能力。(4)DANN:域?qū)股窠?jīng)網(wǎng)絡(luò),通過(guò)GAN 的思想來(lái)實(shí)現(xiàn)源域和目標(biāo)域的不可區(qū)分性。(5)CovNet:在目標(biāo)域上訓(xùn)練并進(jìn)行測(cè)試的AlexNet網(wǎng)絡(luò)。
在Office-Caltech10 數(shù)據(jù)集上實(shí)現(xiàn)的DARCN 在AlexNet 網(wǎng)絡(luò)的基礎(chǔ)上改進(jìn)。在AlexNet 網(wǎng)絡(luò)的卷積層上進(jìn)行微調(diào)來(lái)實(shí)現(xiàn)特征重構(gòu)以及域適應(yīng)的任務(wù)提取網(wǎng)絡(luò)的中間特征,在AlexNet 網(wǎng)絡(luò)的全連接層進(jìn)行微調(diào)實(shí)現(xiàn)分類(lèi)任務(wù)得到分類(lèi)結(jié)果。與在數(shù)字圖像數(shù)據(jù)集上進(jìn)行域適應(yīng)不同的是,該組實(shí)驗(yàn)對(duì)多個(gè)任務(wù)采用分開(kāi)優(yōu)化的方式,首先單獨(dú)優(yōu)化域適應(yīng)任務(wù)以及重構(gòu)任務(wù),將提取出的中間特征圖向量化后進(jìn)行拼接,將拼接后的特征向量傳入分類(lèi)器實(shí)現(xiàn)對(duì)目標(biāo)域數(shù)據(jù)的分類(lèi)。網(wǎng)絡(luò)的參數(shù)更新采用隨機(jī)梯度下降法,域適應(yīng)模塊以及特征重構(gòu)模塊學(xué)習(xí)率大小為10,分類(lèi)器的學(xué)習(xí)率大小為10。網(wǎng)絡(luò)模型示意圖如圖6 所示。表2 總結(jié)了Office-Caltech10 數(shù)據(jù)集在相同環(huán)境下獨(dú)立運(yùn)行10 次的跨域識(shí)別的平均精度。從表2 可以看出,在無(wú)監(jiān)督域適應(yīng)任務(wù)上,DARCN 模型在Office-Caltech10 數(shù)據(jù)集上的平均分類(lèi)精度比DANN 模型高出了約0.03,比DDC 算法高出了約0.08。DARCN 模型在Office-Caltech10 數(shù)據(jù)集上的分類(lèi)精度較其他模型有明顯的提升。在實(shí)際的應(yīng)用場(chǎng)景中,對(duì)于復(fù)雜圖像數(shù)據(jù)集之間的遷移,建議使用圖6 的網(wǎng)絡(luò)架構(gòu)采用不同損失之間分開(kāi)優(yōu)化的方式完成不同數(shù)據(jù)集之間的領(lǐng)域自適應(yīng)。
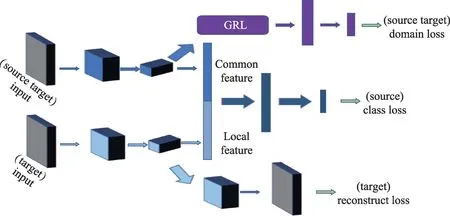
圖6 基于AlexNet網(wǎng)絡(luò)的DARCN 結(jié)構(gòu)Fig.6 DARCN structure based on AlexNet
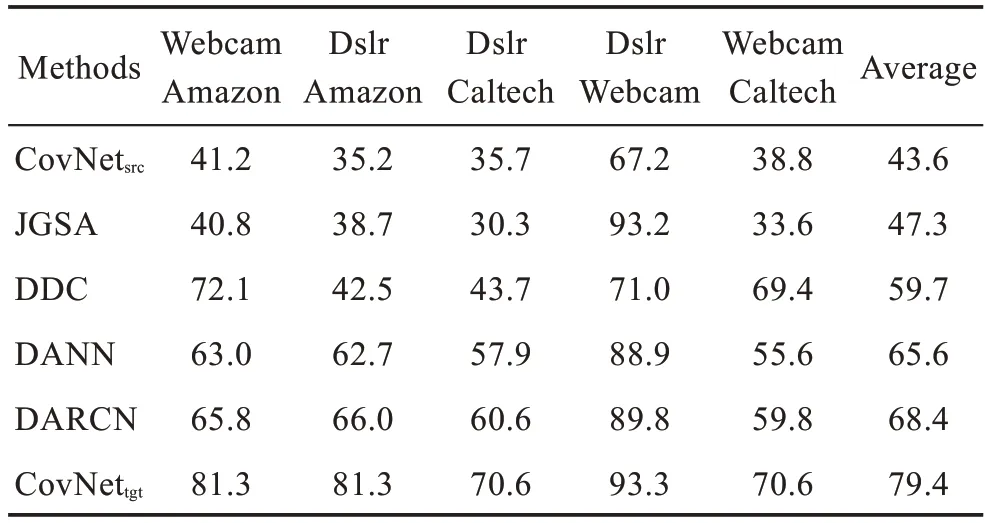
表2 Office-Caltech10 數(shù)據(jù)集運(yùn)行10 次平均分類(lèi)精度Table 2 Average classification accuracy of 10 times on Office-Caltech10 dataset %
從整體上看,無(wú)論是在數(shù)字?jǐn)?shù)據(jù)集上或是Office-Caltech10 數(shù)據(jù)集上,CovNet的表現(xiàn)效果最差,現(xiàn)有的域適應(yīng)算法與CovNet相比精度均有提高。這是因?yàn)樵贑ovNet上的訓(xùn)練集和測(cè)試集數(shù)據(jù)分布不同造成的。而域適應(yīng)算法拉近了源域數(shù)據(jù)和目標(biāo)域數(shù)據(jù)之間的分布,有效地完成了從源域到目標(biāo)域的知識(shí)遷移。從表中的各種域適應(yīng)算法進(jìn)行對(duì)比可以看出,DARCN 模型的表現(xiàn)最好。這是因?yàn)镈ARCN 在對(duì)齊不同域之間的數(shù)據(jù)分布的同時(shí),保留了目標(biāo)域當(dāng)中對(duì)于提高分類(lèi)精度最為關(guān)鍵的特征,盡可能地減少了目標(biāo)域數(shù)據(jù)的信息損失。表3 總結(jié)了本文所使用的三種網(wǎng)絡(luò)的參數(shù)規(guī)模以及將一張彩色圖片輸入到三個(gè)網(wǎng)絡(luò)中一次前向傳播的乘加計(jì)算量。從表3 的數(shù)據(jù)可以看出,在現(xiàn)有GPU 的顯存大小以及計(jì)算能力下,這三種網(wǎng)絡(luò)能夠在輸入大小分別為28×28、32×32、224×224的彩色圖片的情況下以較快的速度完成計(jì)算。

表3 DARCN 參數(shù)規(guī)模分析Table 3 Analysis of parameter scale in DARCN
4 結(jié)束語(yǔ)
針對(duì)計(jì)算機(jī)視覺(jué)中的數(shù)據(jù)集偏差問(wèn)題,本文提出了用于無(wú)監(jiān)督域適應(yīng)的深度對(duì)抗重構(gòu)分類(lèi)網(wǎng)絡(luò)。傳統(tǒng)的對(duì)抗域適應(yīng)算法僅僅利用了生成對(duì)抗網(wǎng)絡(luò)的思想來(lái)實(shí)現(xiàn)領(lǐng)域不變的特性,放棄了自動(dòng)編碼器的解碼部分。DARCN 模型認(rèn)為提取的域不變特征會(huì)削弱目標(biāo)域特征的代表性從而損害分類(lèi)性能,因此該模型添加了自動(dòng)編碼器的解碼部分,通過(guò)優(yōu)化重構(gòu)損失保留了目標(biāo)域數(shù)據(jù)的局部結(jié)構(gòu),增強(qiáng)了目標(biāo)域嵌入特征的代表性。這樣提取的嵌入特征在對(duì)齊不同數(shù)據(jù)域之間的分布的同時(shí)又減少了目標(biāo)域數(shù)據(jù)的信息損失。實(shí)驗(yàn)證明,該模型在視覺(jué)域適應(yīng)方面較其他算法有較為明顯的精度提升。這種通過(guò)自動(dòng)編碼器來(lái)進(jìn)行信息保持的思想也可以推廣到其他深度域適應(yīng)網(wǎng)絡(luò)中。
猜你喜歡
童話(huà)王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
