一種基于三維殘差網絡分組膨脹卷積的人體行為識別方法
2022-05-12 09:25:28王志強
現代計算機 2022年5期
王志強
(上海海事大學信息工程學院,上海 201306)
0 引言
隨著深度學習技術的發展,基于視頻的人體行為識別在人機交互、安全駕駛、智能家居等領域取得了廣泛的應用,行為識別的研究也更加注重人體行為時空的變化。
Ji 等將2D 卷積擴展到3D 卷積,能夠捕獲多個連續幀中的運動信息,學習動態連續的視頻序列,通過支持向量機(SVM)分類識別人體行為,但隨著網絡層數變深會引起梯度彌散。Tran等采用大小為3×3×3(××)的3D卷積核,其中是輸入的幀數,是卷積核空間大小的寬和高,提出了C3D 網絡提取時空特征,計算高效且具有很強的通用性。何愷明等利用殘差網絡結構ResNet 進行行為識別,殘差網絡通過shortcut 操作,不僅緩解了網絡層數的增加帶來的梯度消失問題,還可以優化和提升網絡性能。
為進一步提高人體行為識別準確率,增強其特征表達能力,本文基于三維殘差網絡,利用分組卷積和膨脹卷積的思想,建立了一種三維殘差網絡分組膨脹卷積的行為識別模型。首先將視頻數據輸入到三維卷積神經網絡進行時間維度和空間維度的淺層特征提取,接著通過3D GD-ResNet 殘差塊進一步提取深層圖像特征。3D GD-ResNet 殘差塊利用分組卷積,將殘差塊分成32個并行分組,減少模型參數量,同時在分組卷積中引入膨脹系數,擴大卷積核感受野,以捕獲更豐富的圖像特征信息,最后經過平均池化和全連接層,通過softmax 分類函數輸出。
1 本文模型
傳統三維卷積隨著網絡深度的增加,參數量的增多導致過擬合,影響了網絡的泛化性能。本文模型以3D-ResNet101 為基礎,設計GDResNet 特征提取模塊,以提取更深層次的圖像特征。結構如圖1 所示,模型共100個卷積層,一個最大池化層,一個平均池化層和全連接層。首先對輸入視頻數據進行三維卷積并歸一化,然后輸入到33個GD-ResNet 殘差塊進行特征提取。在每個GD-ResNet 塊使用分組卷積,同時在卷積過程中引入用膨脹系數擴大感受野,使用膨脹卷積替代普通卷積,最后通過全連接層輸出,使用softmax 函數輸出行為識別的最終結果。
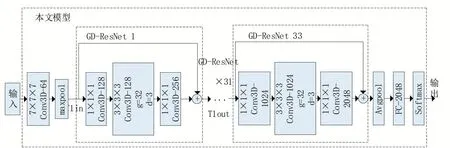
圖1 本文3D GD-ResNet模型結構
1.1 本文模型結構特點
本文模型以3D ResNet101 為基礎進行改進。三維卷積層中的每個特征圖都會與上一層中多個臨近的連續幀相連捕獲人體運動信息,保證時序信息的關聯性,其本質是對多個視頻幀堆疊的立方體進行三維卷積運算,卷積過程如公式(1)所示。
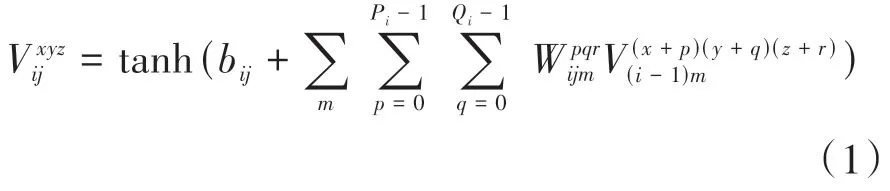
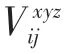
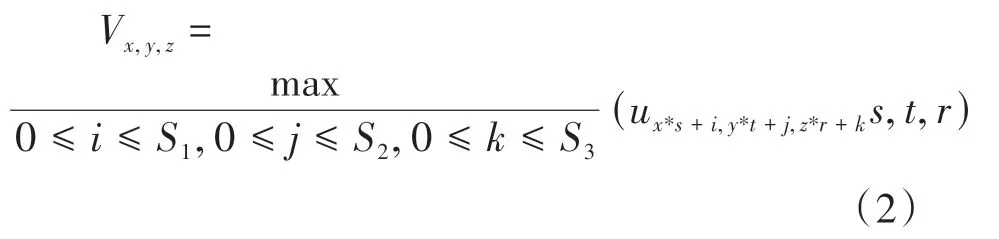
其中V為池化后的輸出,為池化層的輸入,,,為不同方向的采樣步長。
網絡的輸入輸出以及卷積核的大小用××的三維張量來表示,、、分別表示時間長度,寬度和高度,本文3D GD-ResNet 的網絡結構參數如表1 所示(其中表示分組卷積的組數,表示膨脹系數,為了簡化描述,表中省略了輸出尺寸特征的通道數)。

表1 3D GD-ResNet的網絡結構參數
本文采用對輸入視頻幀歸一化處理為224×224 大小的預處理方式,以連續16 幀大小為224×224 的圖像輸入到Conv1 層中,采用大小為7×7×7,步長為1×2×2 的卷積核進行淺層特征提取,其中7 表示時間長度,7×7 表示卷積核空間維度的大小,將得到的8×112×112 大小特征圖通過Conv2_x的最大池化層,池化層卷積核大小為3×3×3,步長為2,通過同時對時間維度和空間維度進行下采樣,減小計算量,輸出特征圖大小為4×56×56,并產生64 維特征圖。之后依次通過33個GD-ResNet 特征提取模塊進行深層特征提取。網絡的Conv2_x-Conv5_x層都采用了殘差連接,并在每個殘差塊中使用了分組膨脹卷積,優化網絡性能。最后通過全連接層和softmax層,輸出101個類別概率。
1.2 GD-ResNet特征提取模塊
殘差結構通過shortcut 操作,在加深網絡的同時,減少了性能下降,但依然存在參數量過多、信息丟失等問題。本文設計GD-ResNet 特征提取模塊,以圖1 中的GD-ResNet1 為例,其內部結構及處理過程如圖2所示。輸入視頻幀經過卷積和最大池化操作后輸出特征圖T1in,大小為4×56×56,輸入到GD-ResNet1 特征提取模塊。在L1 層采用1×1×1 大小的卷積核進行3D 卷積,通道數為128,增加特征的非線性轉換次數。為了降低參數量,將L2層分成32個并行分組,用3×3×3 大小的卷積核在每個分組上做特征變換,輸出特征圖大小不變。不增加參數量的前提下,對每個分組引入膨脹率為3的膨脹卷積代替普通卷積,在不改變卷積核大小的情況下擴大感受野,最后將分組膨脹后的特征圖合并輸入L3 層,卷積核大小為1×1×1,通道數由128 增加到256。在每一層卷積操作后添加BN操作以保持數據分布一致,加快網絡訓練,最后對整個殘差塊使用ReLU 激活函數克服梯度消失。
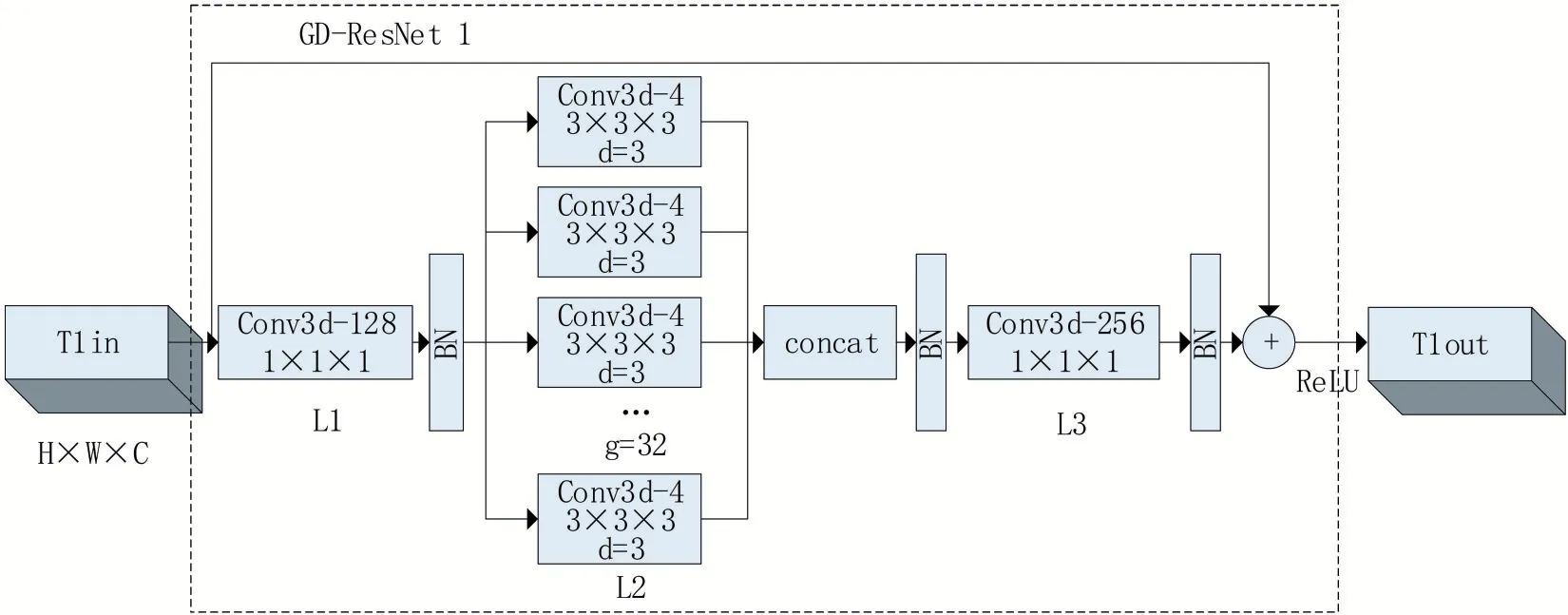
圖2 GD-ResNet1模塊的分組膨脹卷積處理
傳統CNN 中每一個輸出通道都與輸入通道相連接,通道之間采用稠密連接,計算復雜度高且容易產生過量的參數,本文分組卷積中通道被分成了32 組,每組通道數為4,輸出通道只與該組內的輸入通道連接,與其他通道無關。采用分組卷積能減小計算復雜度且擁有較強特征表示能力。
若定義輸入特征圖尺寸為××,卷積核尺寸為×,輸出特征圖尺寸為××,采用標準卷積的參數量為:
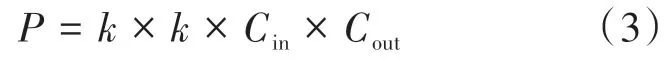
其中、表示輸入和輸出通道數,、分別表示特征圖的寬和高。而采用分組卷積,則輸入特征圖按通道分成組,分別對每組進行單獨的卷積操作,則卷積操作中每組輸入特征圖的尺寸為××,對應卷積核的尺寸為××,卷積操作完成后對組進行組合,輸出特征圖通道數為,每組卷積特征圖通道數為,分組卷積的參數量可表示為:
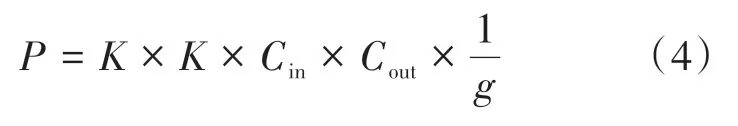
由公式(4)可知,分組數為的分組卷積參數量為標準卷積的1,在GD-ResNet1模塊中,當輸入特征圖尺寸為128×4×56×56 時,其中128表示卷積核個數,4表示時間長度,56表示特征圖的寬和高,普通卷積和本文GD-ResNet1參數量的對比如表2所示。

表2 普通卷積和GD-ResNet1參數量對比
普通卷積和GD-ResNet1分別表示ResNet101和本文分組卷積的第一個殘差塊,分組卷積組數取32,本文3D GD-ResNet 參數量是無分組卷積參數量的132,表明分組卷積能有效降低參數量,防止模型過擬合,提高網絡性能。
感受野是CNN 網絡每一層輸出特征圖的像素點在原始圖像上的映射區域大小,膨脹卷積可通過控制窗口的寬度,擴展感受野區域,提取更多的特征圖信息,能夠保持圖像分辨率不受損失的情況下減少空間信息的損失。經過膨脹處理后,感受野大小如式(5)所示:
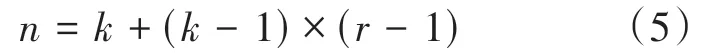
其中表示卷積核的大小,表示膨脹卷積的擴張率,表示擴張后的感受野。
GD-ResNet 模塊中對每個分組的卷積核上增加膨脹系數為3 的膨脹率,由公式(5)計算可知,卷積核大小為3×3×3 時,感受野大小為7×7。以圖1 中GD-ResNet1 為例,當膨脹系數為1和本文膨脹系數為3時,卷積過程如圖3所示。
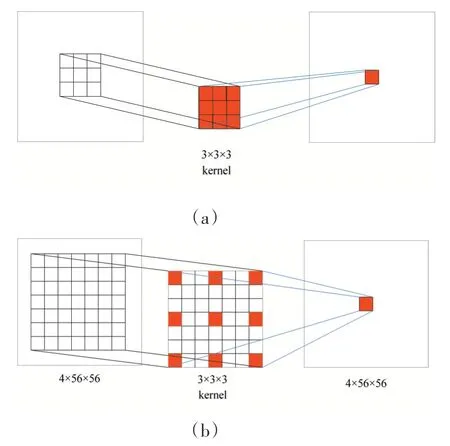
圖3 膨脹系數為1和3時卷積輸出過程
圖中(a)表示膨脹系數為1時卷積輸出過程,卷積核在特征圖上的感受野為3×3,(b)表示本文加入膨脹系數為3 時卷積輸出過程,4×56×56的特征圖T1in為GD-ResNet1殘差塊的輸入,通過加入膨脹卷積,卷積核在特征圖上的感受野為7×7,輸出特征圖大小不變。本文通過實驗表明,膨脹卷積能夠提取更豐富的特征圖信息,優化網絡性能。
2 實驗結果與分析
2.1 實驗環境與數據
本文實驗采用UCF101數據集,包含101個類別,共13320 段視頻,其中訓練數據集9537個視頻,測試數據集3783個視頻,視頻幀圖像大小為320×240。
實驗在Linux 操作系統下進行,計算機顯卡為NIVDIA的Tesla V100,采用PyTorch深度學習框架。用預訓練3D ResNet101 神經網絡初始化本文模型的權重參數,采用隨機梯度下降算法優化模型。網絡訓練的初始學習率為0.1,每經過50epoch 學習率降為原來的10%,動量為0.9,batch_size 設置為128,共訓練200 epoch。分別比 較 了 3D ResNet101、 不 同 分 組 數 3D ResNet101和加入分組卷積基礎上采用不同膨脹率的對比結果,通過實驗驗證了本文方法的有效性。
2.2 原始3D ResNet 101實驗結果
本文實驗以3D ResNet101 為基礎模型,采用Kinetics 數據集預訓練3D ResNet101 初始化權重參數,對模型1 在UCF101 數據集上進行訓練和測試。采用訓練損失loss和acc(accuracy)準確率曲線驗證模型性能和準確率。如圖4所示,橫坐標表示迭代次數,縱坐標表示模型訓練和測試的準確率和損失值,由圖可見,在沒有加入分組膨脹卷積下,3D ResNet101 訓練集準確率高,loss損失值小,而測試集損失值大,準確率低,由于UCF101 數據集相比Kinetics 數據集過小而出現了嚴重過擬合。
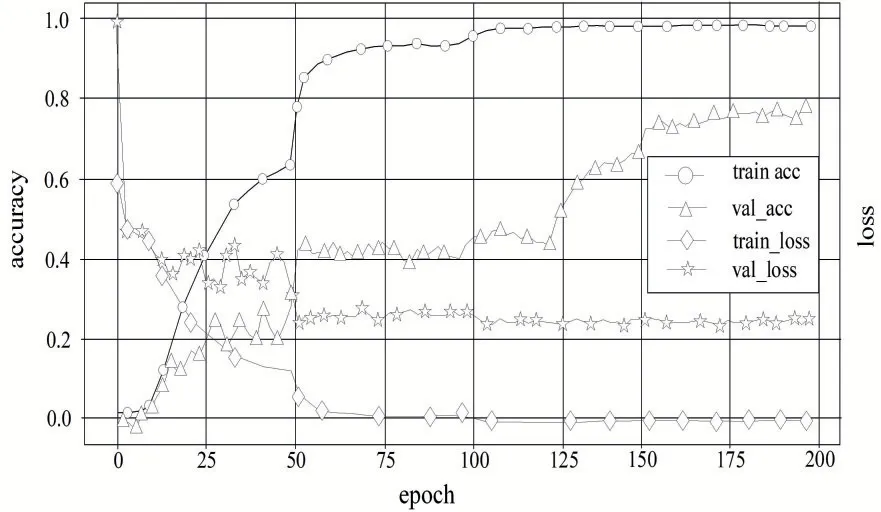
圖4 模型1在UCF101上的準確率和loss損失
2.3 模型完善過程及實驗結果分析
針對模型1存在過擬合嚴重問題,在實驗中加入不同組數的分組卷積,通過對比選擇最優分組數,以模型1 為基礎,模型2 將殘差塊分成64 組,模型3 將殘差塊分成32 組,以驗證不同分組數對模型識別準確率的影響。結果如圖5所示,結果表明,采用32 組分組比64 組穩定,模型識別準確率更高。從圖4和圖3 的實驗結果對比看,引入分組卷積,參數量減少,有效降低了模型過擬合。
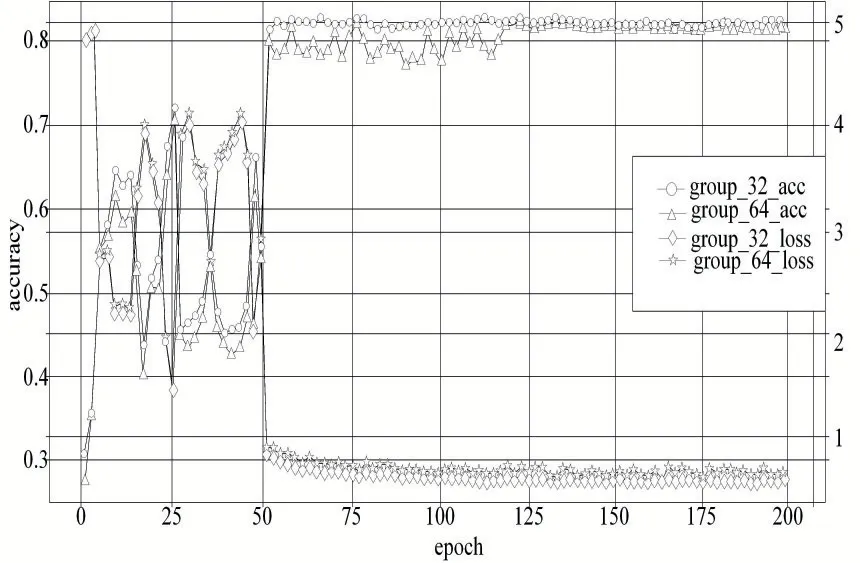
圖5 模型2和模型3的準確率和loss損失對比
為驗證感受野的大小對網絡性能的影響,在模型3 的基礎上,引入不同的膨脹率進行對比。模型4 的膨脹系數為2,本文模型膨脹系數為3,圖6 分別比較了模型4和本文模型不同膨脹系數下的準確率和損失,從圖中可以看出,本文模型比模型4的損失值更小,測試準確率更高,特征更有區分度,測試識別率達到了88.4%。
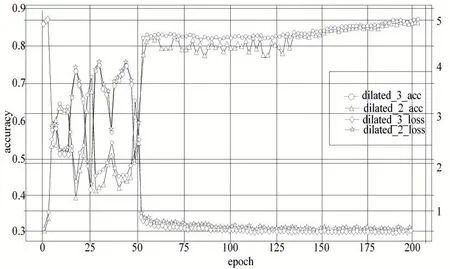
圖6 模型4和本文模型的準確率和loss損失對比
上述五個模型實驗結果對比如表3所示,結果表明,模型1 在UCF101 上存在過擬合;在引入分組卷積以后,由于參數量減少,有效降低了過擬合,當采用分組數為32 的模型3 時,測試效果更好,識別率達到了82%,比模型2 高1個百分點;在模型3基礎上,加入膨脹系數后本文模型行為識別準確率曲線穩定且達到了88.4%,比膨脹系數為2 的模型4 高了1.4%。表明本文模型中的GD-ResNet 特征提取模塊能有效減少模型參數量,提取更多圖像特征,提高人體行為識別準確率。
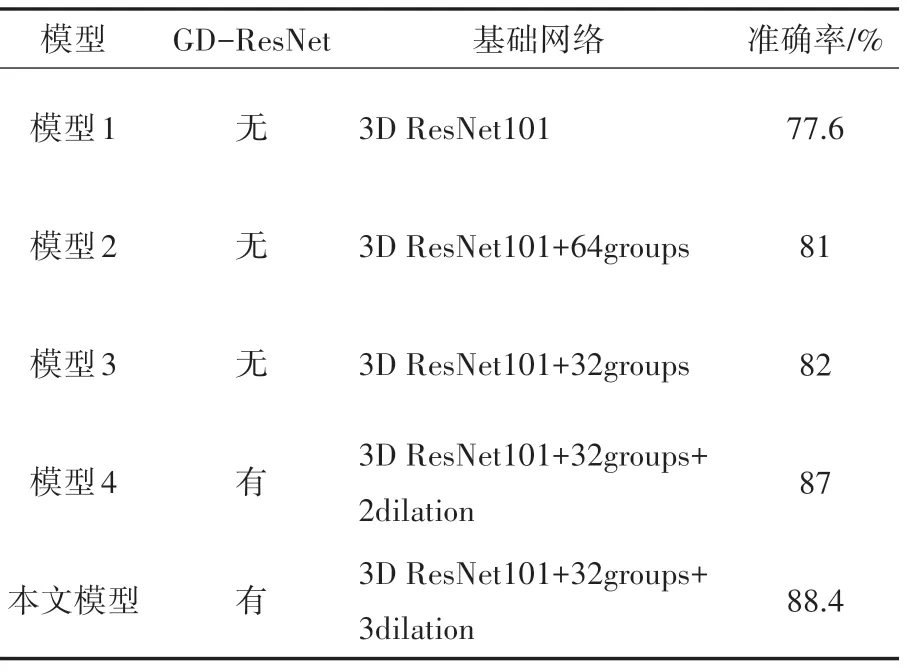
表3 五種不同模型行為識別準確率比較
2.4 與其他方法比較
為了進一步檢驗本文模型對人體行為識別的效果,將本文方法和3D 卷積神經網絡(C3D)模型、劉瀟等提出的三維殘差卷積神經網絡、Varol G 等提出的LTC 網絡模型在相同數據集下進行了對比。結果如表4所示,可見本文模型方法較其他方法行為識別準確率有所提高。

表4 不同方法結果對比
3 結語
本文建立了一種基于三維殘差網絡分組膨脹卷積的人體行為識別方法,以3D ResNet101網絡為基礎,利用三維殘差網絡提取時空特征。GD-ResNet 將殘差塊分成32個并行分組,減少了模型參數量,并在每個分組上使用膨脹率為3的膨脹卷積,增大了模型感受野,提取了更為豐富的特征圖信息,最后通過softmax進行分類。在UCF101數據集上進行測試,行為識別準確率為88.4%,驗證了本文方法的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
光學精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
