機撰文稿的智能識別系統設計與實現
2022-05-12 09:25:40莫永華王可
現代計算機 2022年5期
莫永華,王可,李 嘉
(桂林信息科技學院,桂林 541004)
0 引言
由于近年來互聯網的飛速發展,自媒體網絡文章已成為互聯網輿論來源中體量龐大且不可忽視的一部分。由于新聞與社交平臺的篩選審查能力有限,其中惡意煽動負面輿論的文章極易影響社會穩定。因此,一個可以甄別惡意輿論導向文章的系統已逐漸成為相關部門維護網絡空間與社會穩定安全的重要方向。實現這一課題,旨在提供一個可以從短評論中分辨正負面情感的算法模型,并在該模型的基礎上提供一個功能多樣、操作便捷的Web 平臺,為輿情分析提供一個新思路。
1 機撰文稿的智能識別功能需求與技術介紹
1.1 系統功能需求
機撰文稿的智能識別系統功能需求包括三個方面:數據采集、情感分析模型、業務和數據大屏展示。系統功能需求如圖1所示。業務和數據大屏展示包括系統信息監控、今日新聞排行榜查看、分析任務管理、模型管理、數據大屏功能。情感分析模型模塊包括模型訓練、數據預處理、數據清理、HTTP 接口提供功能。數據采集模塊為業務模塊提供數據支持,通過網絡爬蟲程序從新聞網站中采集系統所需的數據信息。系統和用戶之間的交互主要為用戶與Web 前端的交互。用戶在Web 前端中的今日新聞排行榜中選取所需要的進行分析的新聞,或者直接輸入新聞網址來創建分析任務。業務模塊將和數據采集模塊進行交互,來采集所需要的數據,采集完畢之后,業務模塊負責將數據去重,并且存入數據庫中,并且與情感分析模塊進行交互,用以分析評論的情感,然后將結果存入數據庫,最終Web 前端根據數據庫中的數據來顯示相對應的圖表。
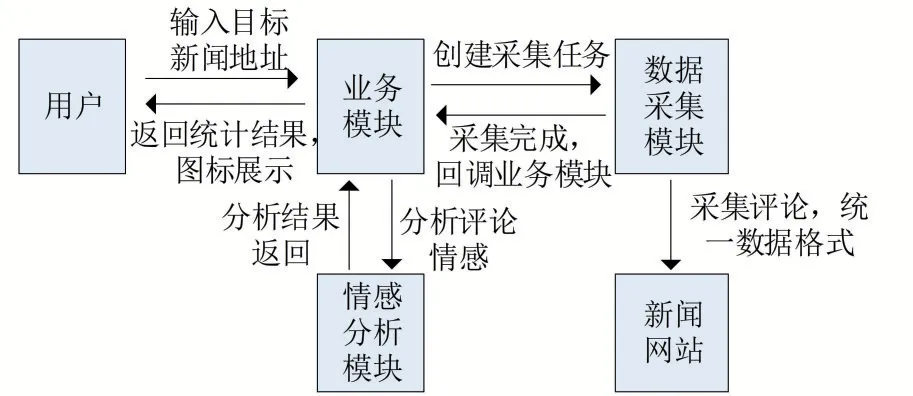
圖1 系統功能需求
功能需求說明如下:
(1)業務模塊。通過可視化界面提供了系統信息監控、今日新聞排行榜查看、分析任務管理、模型管理、數據大屏等功能,并直接與用戶產生交互。
(2)數據采集模塊。通過模擬瀏覽器訪問行為獲得對應新聞的評論后,通過JSON 解析,為模型分析提供統一格式的文本數據;在數據采集模塊中,包含以下功能:采集今日熱門新聞排行榜:向163 新聞網站請求數據,對數據出力后按照所需格式返回;采集新聞評論:根據新聞ID獲取評論JSON,然后對其進行解析并返回。
(3)情感分析模塊。用于判斷一段中文短評論的正負面情感的概率。在情感分析模型模塊中,包含以下功能:訓練數據清洗:刪除特殊字符,空格,null 數據等;切分訓練數據:驗證使用時的性能,將訓練數據切分成訓練集、測試集和驗證集;模型創建:創建出模型的每一層;模型訓練:實例化出數據加載器和模型,對模型進行訓練。
1.2 系統技術介紹
(1)服務器端環境。能夠運行TensorFlow 等深度學習框架,且能夠支持Python 語言的計算機或服務器。
(2)前端環境。能夠支持基于Web 平臺的Spring Boot+Vue。
首先,使用已經標記好的36 萬條情感類別的評論數據集(微博)和深度學習框架(Tensor?Flow)訓練出一個能從短評論中分辨正負面情感的文本識別模型;然后,通過網絡爬蟲抓取等手段分析新聞數據接口,使用Python 語言設計爬蟲,實現輿論數據采集功能;最后使用Spring Boot+Vue 框架編寫業務邏輯模塊和數據大屏展示,對用戶請求的新聞進行判斷甄別,并返回可視化結果。
2 系統設計
2.1 功能模塊設計
機撰文稿的智能識別系統功能設計主要分為三個模塊:情感分析模型模塊、數據采集模塊和業務模塊。系統主要任務有:①訓練數據集清洗。②文本分類問題。③TextCNN。④Web前端平臺提供用戶友好的交互界面及相關功能服務,包括系統模塊監控、今日新聞排行榜監控、分析指定鏈接新聞、模型管理、數據大屏功能。根據需求設計輿論文章智能識別系統需求具體如圖2所示。
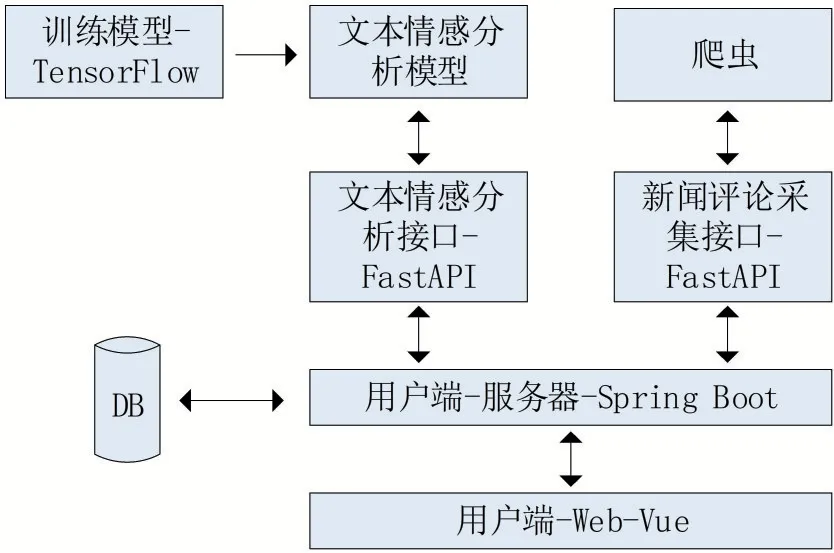
圖2 系統設計
(1)情感分析模型模塊。后臺模型基于深度TextCNN 的情感分析模型,負責接收來自業務模塊的句子,經過運算分析后,返回結果給業務模塊用于最終結果展示。返回的結果有:正面情感概率和負面情感概率,用于為用戶提供結果參考。
該模塊的主要流程為:首先進行對輸入句子的預處理,其中包括:數據清洗、文本分詞、映射詞向量等操作,從而得到輸入數據的矩陣形式,再利用已經使用訓練數據訓練完畢的神經網絡模型進行分析,得出正面情感概率和負面情感概率,并將其返回到業務模塊。模型利用了CNN 的特征提取和識別的特性,可計算出互聯網短評論的正負面情感的概率。
(2)數據采集模塊。數據采集模塊用于給業務模塊提供所需的數據。該模塊的工作是根據業務模塊傳輸過來的請求,在指定新聞文章下采集該新聞的評論,并完成對數據的處理,使得每條數據具有相同的格式,方便后臺程序的讀取。數據采集模塊是基于Python 的網絡爬蟲程序實現,通過模擬瀏覽器訪問行為獲得對應新聞的評論后,通過JSON 解析,為模型分析提供統一格式的文本數據。
(3)業務邏輯模塊。情感分析系統的業務邏輯模塊采用的是互聯網行業軟件開發中成熟的基Spring Boot和Vue的前后端分離架構。前端平臺通過可視化界面提供了系統信息監控、今日新聞排行榜查看、分析任務管理、模型管理、數據大屏等功能,并直接與用戶產生交互。用戶將通過相應的圖形界面在Web 前端中進行響應功能的使用,業務模塊收到用戶的操作后依據觸發的功能調用數據采集模塊,采集完成之后將數據發給情感分析模塊,并負責接收分析,最后將得到的分析結果進行圖表展示返回給用戶。此外,為提高用戶對該系統的信任,該系統同時提供在線測試功能。用戶可以自定義輸入一句話,讓系統進行分析得到結果,進一步提高用戶對分析模型的信任度。
2.2 數據庫設計
(1)概念結構設計,如圖3所示。
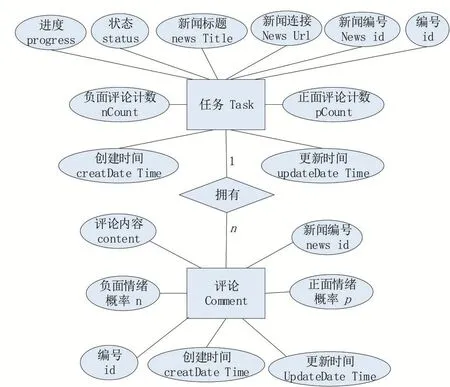
圖3 ER圖
業務模塊實現的任務邏輯結構表設計如表1所示。
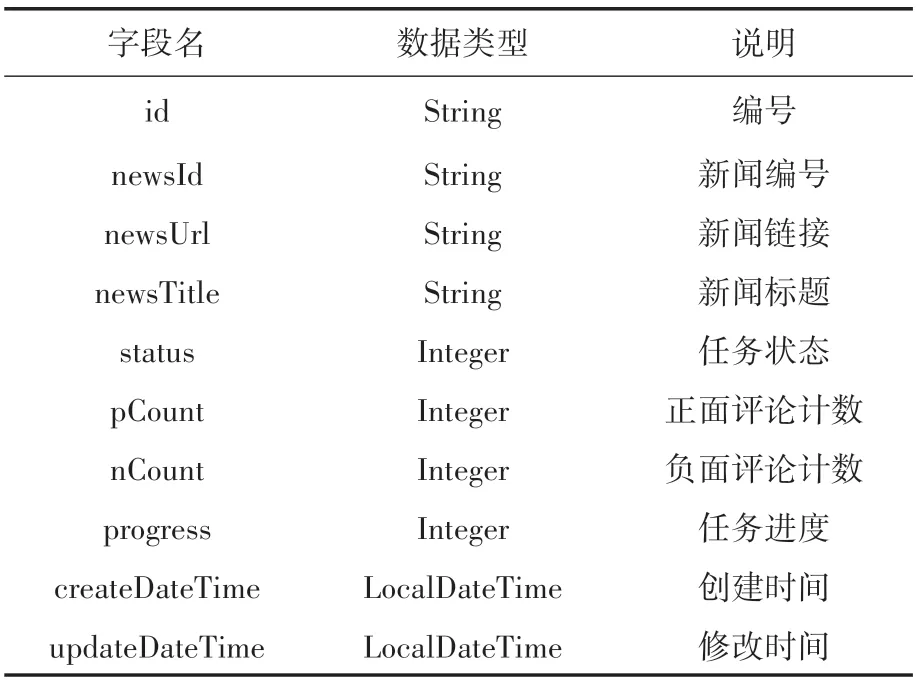
表1 任務Task邏輯結構設計
業務模塊實現的評論邏輯結構表設計如表2所示。
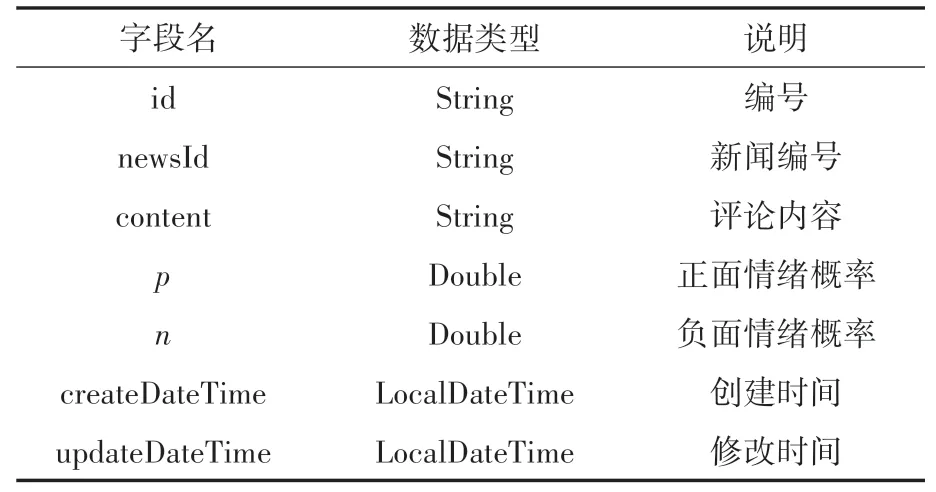
表2 評論Comment邏輯結構設計
(2)物理結構設計。任務Task SQL 如圖4所示。

圖4 Task SQL
評論Comment SQL如圖5所示。
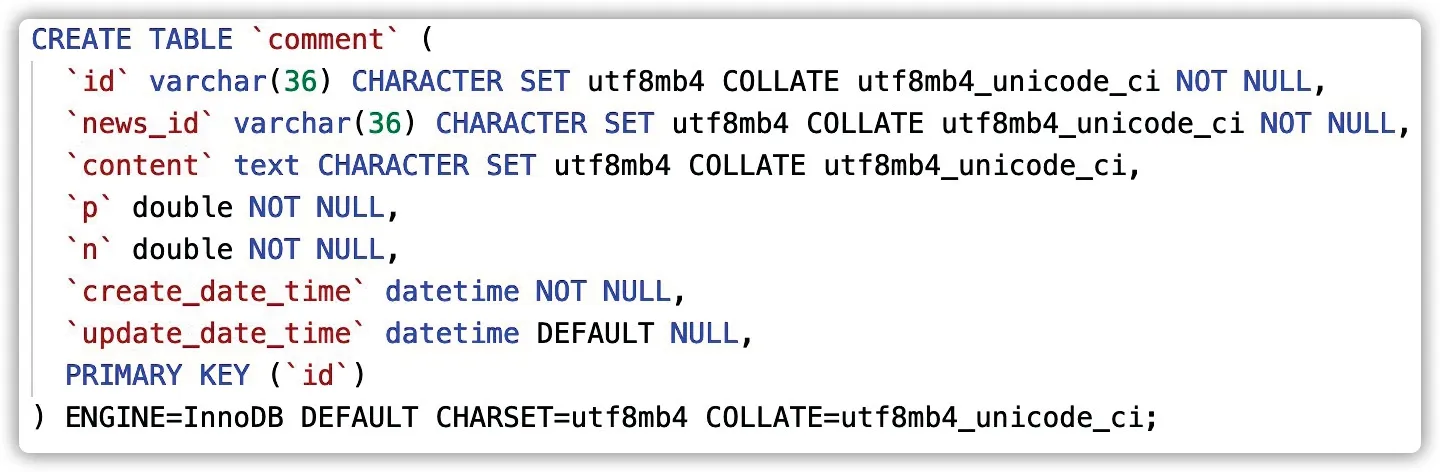
圖5 Comment SQL
3 系統實現與測試
本系統開發實現環境在Linux 環境下進行,具體的實現環境為Python 3.7 環境。核心模型環境:在Python 3.7 環境下完成相關工具包的部署,包括分詞庫jieba、開源第三方算法工具包Gensim、深度學習框架TensorFlow 2.1 等。業務模塊:運用SpringBoot + Vue 的方案,PIP 環境下安裝HTML網頁解析庫BeautifulSoup等。
3.1 核心模型
(1)數據集。模型的數據來源于GitHub 開源社區提供的已標記的數據集,共包括4 種情感,其中約20萬條喜悅,約5萬條憤怒,約5萬條厭惡,約5 萬條低落。共35 萬條。在隨機打亂數據集使其分布平均后,將數據集按8∶1∶1分為訓練集、測試集和驗證集。
(2)模型設置。在測試實驗中,使用了Adam 優化器,模型的訓練正面情感標簽設置為0和負面情感標簽設置為1,詞向量的模型使用Word2Vec 靜態,詞向量的維度設置為300,模型batch 設置大小為64,輸入的文本詞數設置為64,如果文本詞數超過長度的被截斷,如果長度不夠的用詞向量0填充。
(3)測試結果。在經過多次參數調整之后,本系統選擇了靜態詞向量、使用小卷積核、基于TextCNN 的模型作為情緒分辨模型。訓練100輪之后,該模型在訓練集中達到93%的準確率,在驗證集和測試集中達到79%的準確率。項目模型準確率測試如圖6所示。
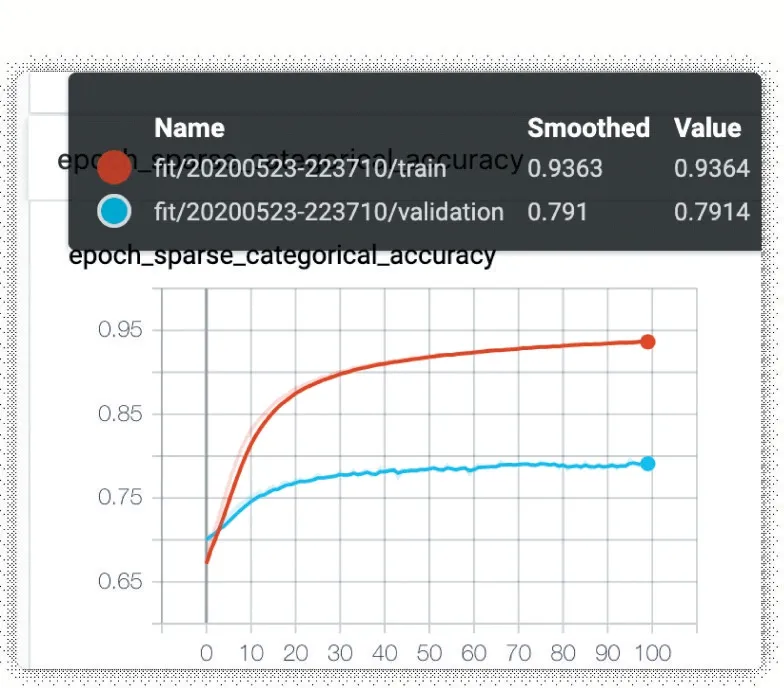
圖6 模型準確率測試
3.2 業務模塊
(1)系統信息監控。系統信息監控功能可以及時顯示情感分析模塊和爬蟲模塊的是否上線、以及系統負載狀況具體流程如圖7所示。
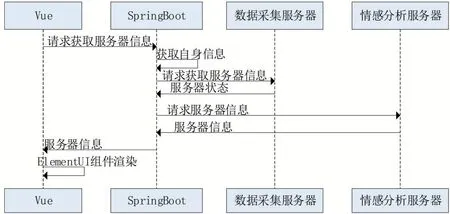
圖7 系統信息監控過程
系統信息界面會顯示情感分析系統和評論采集系統狀態是否正常,如圖8所示。
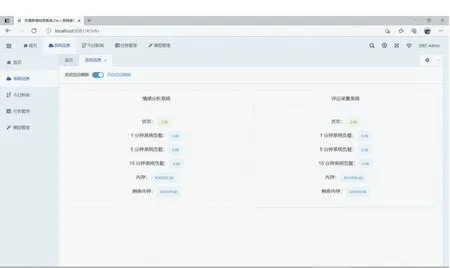
圖8 系統信息頁面
(2)今日新聞監控。通過對新聞網站的活躍評論新聞進行采集,并將其反饋到排行榜。如圖9所示。
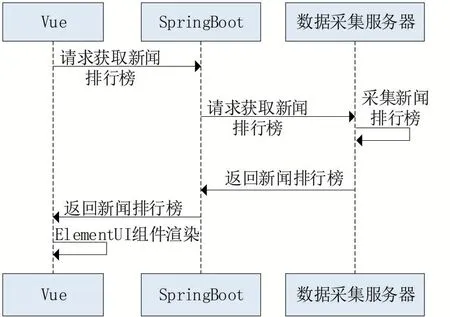
圖9 新聞排行榜過程
通過獲取新聞標題和編號,對新聞進行排序,獲得排行榜,如圖10所示。
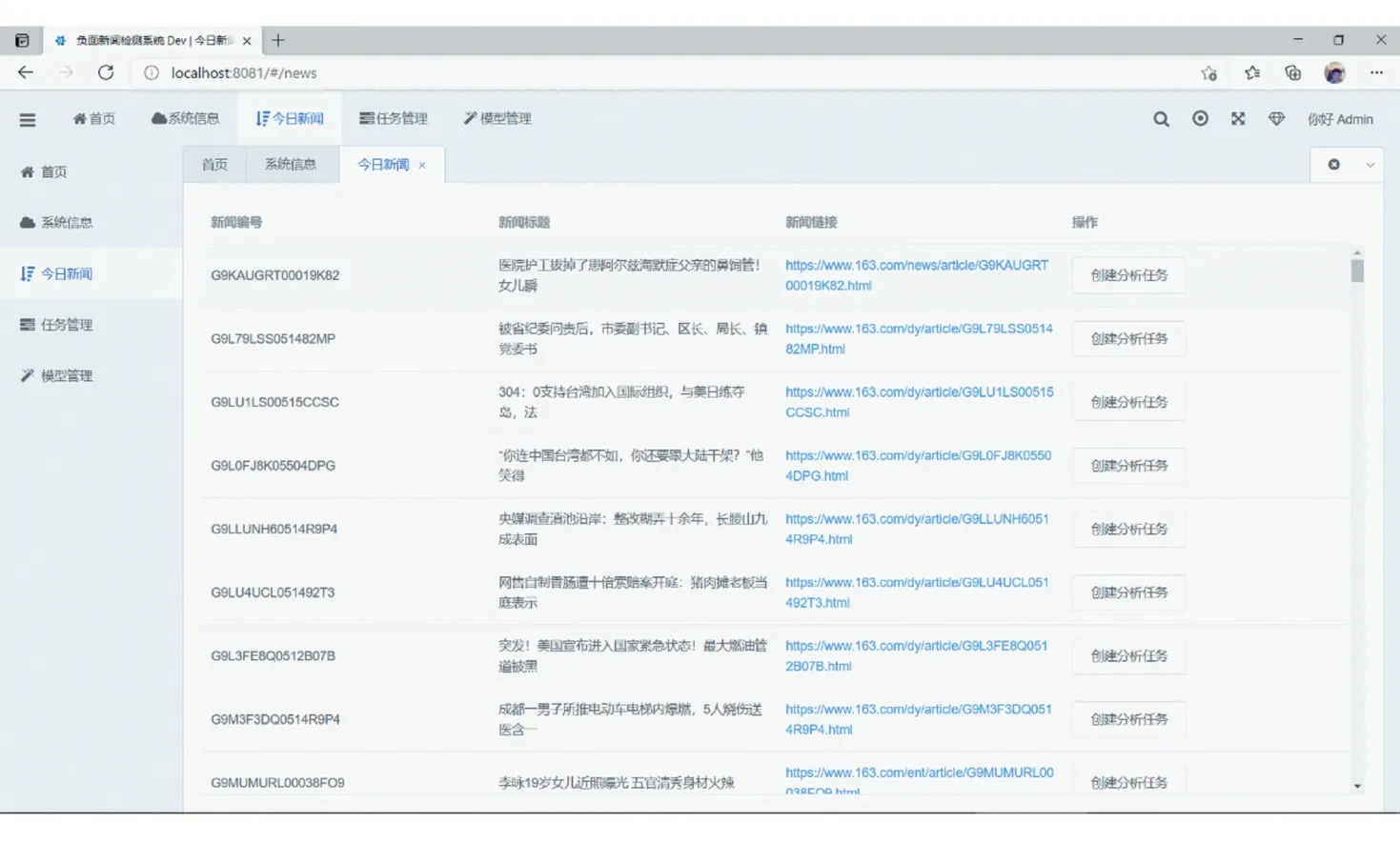
圖10 今日新聞排行榜
(3)模型管理。通過使用模型來分析新聞評論的情感。選擇對應的模型后,系統載入模型,通過對一些基本語句對模型進行測試,如圖11所示。
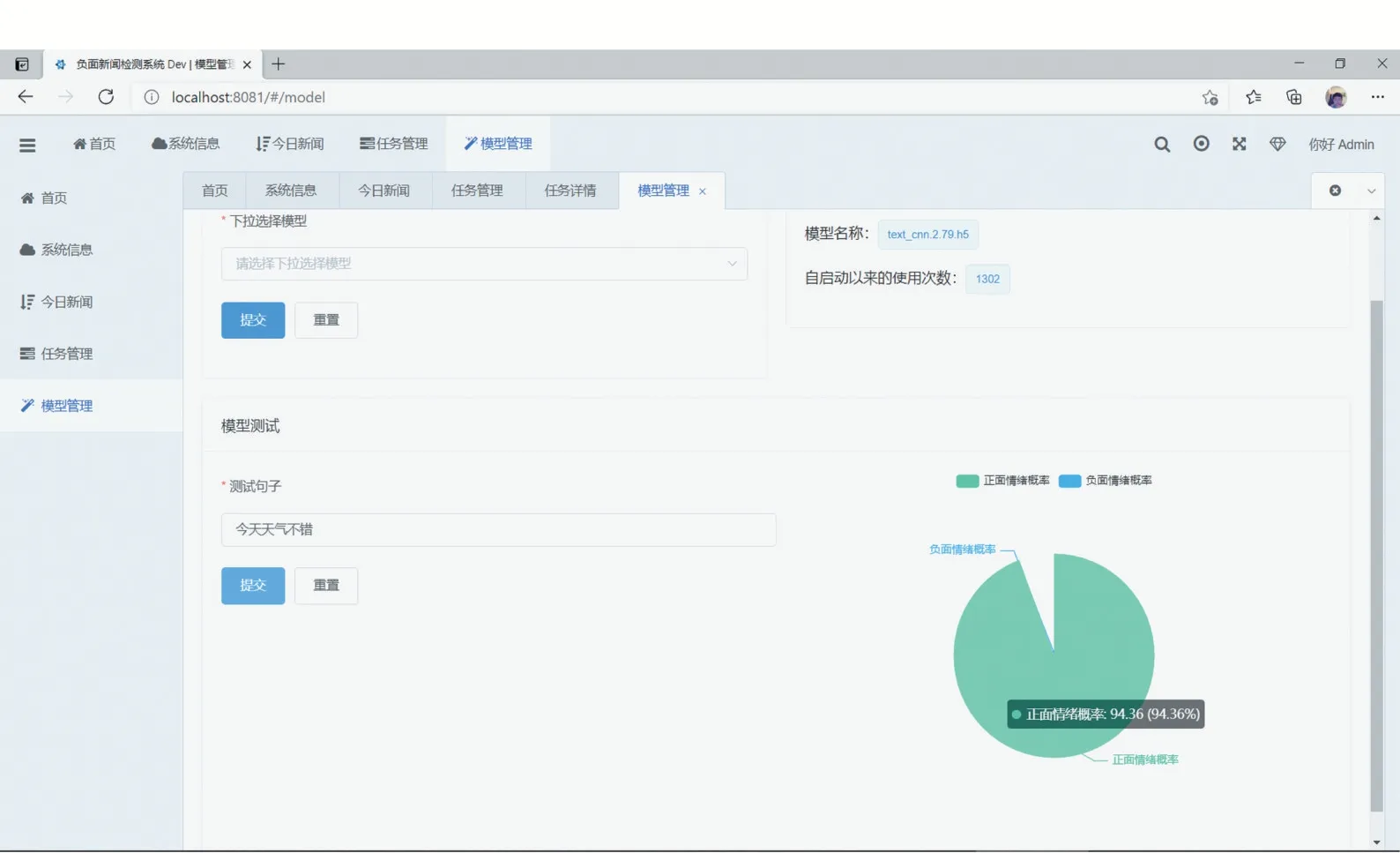
圖11 模型管理界面
(4)數據大屏。數據大屏能及時顯示系統正在運行的任務、系統負載、最近分析的評論情況等信息。如圖12所示。
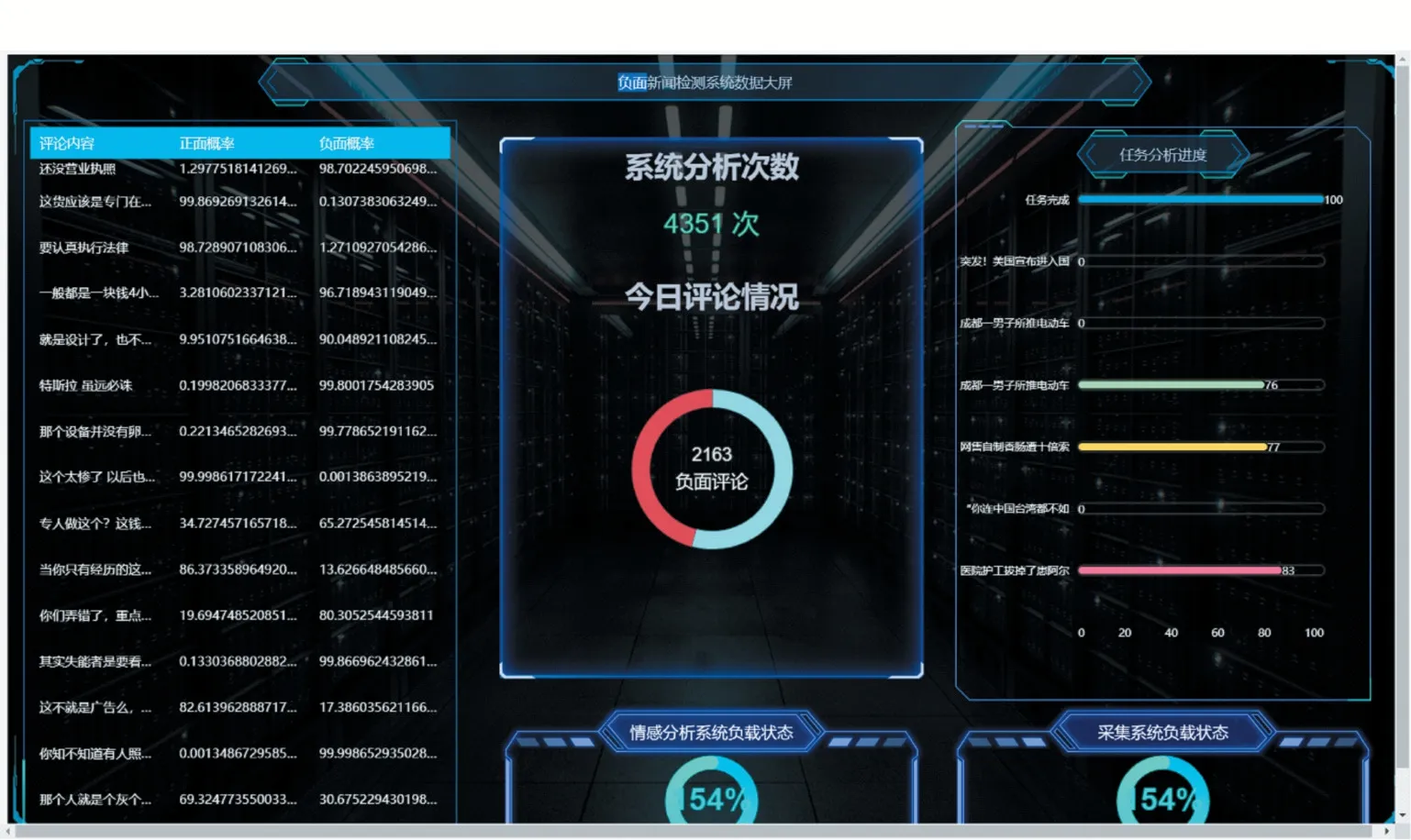
圖12 系統數據大屏
4 結語
該研究將惡意導向社會輿論文章作為互聯網信息的重要部分引入群眾的視線,互聯網中的自媒體為了吸引流量,該類型的文章數量會越來越多,情感識別模型和該系統使得惡意文章的負面影響得到最大化程度的降低,為維護社會穩定與網絡空間安全做出重要貢獻。
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
中國科技論壇(2017年7期)2017-07-25 08:49:53
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
