基于de Bruijn圖和序列比對的長序列混合糾錯算法
2022-05-12 09:25:24劉剛
現代計算機 2022年5期
劉 剛
(廣西大學計算機與電子信息學院,南寧 530004)
0 引言
基因糾錯對于基因工程是很重要的。序列糾錯算法旨在識別和消除(或修復)測序序列中包含的錯誤,從而有利于重新測序或從頭測序分析。序列糾錯算法應能有效地處理越來越多、越來越長的測序數據的糾錯。
為了糾正第三代測序平臺產生的錯誤率高的長序列,人們開發了混合糾錯算法。所謂混合糾錯算法是指利用第二代測序平臺產生的高準確率的短序列來對第三代測序長序列進行糾錯的算法。長序列混合糾錯算法分為4類:基于短序列比對的混合糾錯算法,基于重疊序列或重疊群比對的混合糾錯算法,基于de Bruijn 圖的混合糾錯算法以及基于隱馬爾可夫模型的混合糾錯算法。基于短序列比對和基于重疊序列比對的混合糾錯算法由于長序列的較高錯誤率導致比對會出現偏差,因此需要改進比對方式來提高糾錯效果,且它們將長序列拆分成很多的長度很短的序列片段,這些序列片段會丟失長序列所攜帶的信息,這使得糾錯效果不夠理想。基于隱馬爾可夫模型的混合糾錯算法也需要將長序列與短序列比對,也需要改進比對方式來提高糾錯效果。已有的基于de Bruijn 圖的混合糾錯算法采用固定值的k-mers(長度為的序列片段)構建,其有時很難找到長序列的有效錨點,從而難以擴展序列路徑,這使得糾錯質量不高。
本文研究基于值可變的de Bruijn 圖和序列比對的長序列混合糾錯算法,以糾正第三代測序長序列中與第二代測序短序列比對的區域和未被覆蓋的區域。
1 算法
1.1 算法思想
本文的算法思想:將與長序列同物種的短序列采用短序列糾錯算法其進行糾錯,從糾錯后的短序列中提取出k-mers(長度為的序列片段),將待糾錯的第三代測序長序列與同物種的正確率高的第二代測序短序列進行比對,以生成種子;使用值可變的de Bruijn圖擴展連接形成種子序列,將連接兩個相鄰種子的序列路徑覆蓋位于兩個種子之間未與長序列比對的區域;遍歷de Bruijn 圖擴展種子序列的末端,使得種子序列能夠擴展到待糾錯的長序列的末端;采用短序列比對糾正長序列與短序列對準的區域,并使用種子序列路徑來糾正長序列未與短序列對準的區域,從而得到經糾錯之后的長序列。
1.2 算法描述
算法是通過將待糾錯的長序列與同物種的短序列比對來生成種子的,種子由5 元組(id,pos,len,score,seq)組成,其中id 表示種子與長序列關聯的標識符,pos 表示相同物種的短序列與長序列比對的開始位置,len 表示短序列與長序列比對區域的長度,score 表示比對得分,seq 表示在某個位置上短序列與長序列比對的共有序列。
本文給出的基于值可變de Bruijn圖和序列比對的長序列混合糾錯算法(hybrid de Briujin graph errors correction algorithm,簡記為HdGEC算法)形式描述如下。
HdGEC
輸入:相同物種的長序列long-read[0..n-1]和短序列short-reads[0..m-1],參考基因組R[0..r-1]
輸出:糾正后的長序列long-read[0...n-1]
Begin
1:采用QuorUM 算法糾正短序列short-reads[0..m-1],以減少短序列中包含的錯誤;
2: 使用KMC3 工具從糾錯后的短序列short-reads[0..m-1]中提取出k-mers;
3:過濾掉弱值的k-mers,將強值的k-mers 使用PgSA索引構造值可變的de Bruijn圖;
4: 使用BLASR 工具將經過糾錯的短序列shortreads[0..m-1]與同物種的長序列long-read[0...n-1]比對,以獲得種子seeds(id,pos,len,score,seq);
5: 利用序列比對將種子序列seeds(id, pos, len,score,seq)與參考基因組R[0..r-1]進行比對,以糾正中被短序列short-reads[0..m-1]覆蓋到的區域;
6:遍歷值可變的de Bruijn 圖以找到任意相鄰兩個種子之間的序列路徑,連接這相鄰的兩個種子得到種子序列路徑,并用種子序列路徑來糾正長序列long-read[0...n-1]當中未被短序列short-reads[0..m-1]覆蓋到的區域;
7:遍歷值可變的de Bruijn 圖,以擴展得到種子序列路徑的末端,使得種子序列路徑覆蓋到整條長序列long-read[0...n-1];
8:輸出糾正之后的長序列long-read[0...n-1];
End.
本文算法HdGEC 使用種子作為錨點進行擴展,使用貪心策略遍歷de Bruijn 圖,由于可以選擇1~階的de Bruijn 圖來連接種子序列,所以可以減少de Bruijn 圖的遍歷次數,從而縮短了序列糾錯需要的時間。此外,本文算法HdGEC 結合k-mers 比対和值可變de Bruijn 圖來對長序列進行糾錯,其中通過k-mers 序列比対來糾正長序列中被短序列覆蓋到的區域,通過de Bruijn 圖糾正長序列中沒有被短序列覆蓋到的區域,這使得算法的覆蓋率更高,能夠糾正序列中更多的錯誤堿基,獲得了更高的吞吐量(輸出的糾錯序列的質量)。
2 實驗
2.1 實驗環境與數據
實驗使用的計算機是8 核Intel(R)Core i7-6700 k CPU@4.00 GHz處理器、內存容量32 GB。采用C++語言編程實現算法。實驗數據集采用太平洋生物科學平臺的PacBio模擬數據集和牛津納米孔平臺的ONT真實數據集。模擬數據集與真實數據集都來自于物種A.baylyi、E.coli、S.cere?visiae和C.elegans 中的數據,這4 種物種數據集和參考基因組來源于基因測序中心https://www.genoscope.cns.fr/externe/NaS/datasets。模擬的長序列數據集采用SimLord模擬器生成。實驗使用的參考基因組、模擬數據集與真實數據集的信息如表1所示。
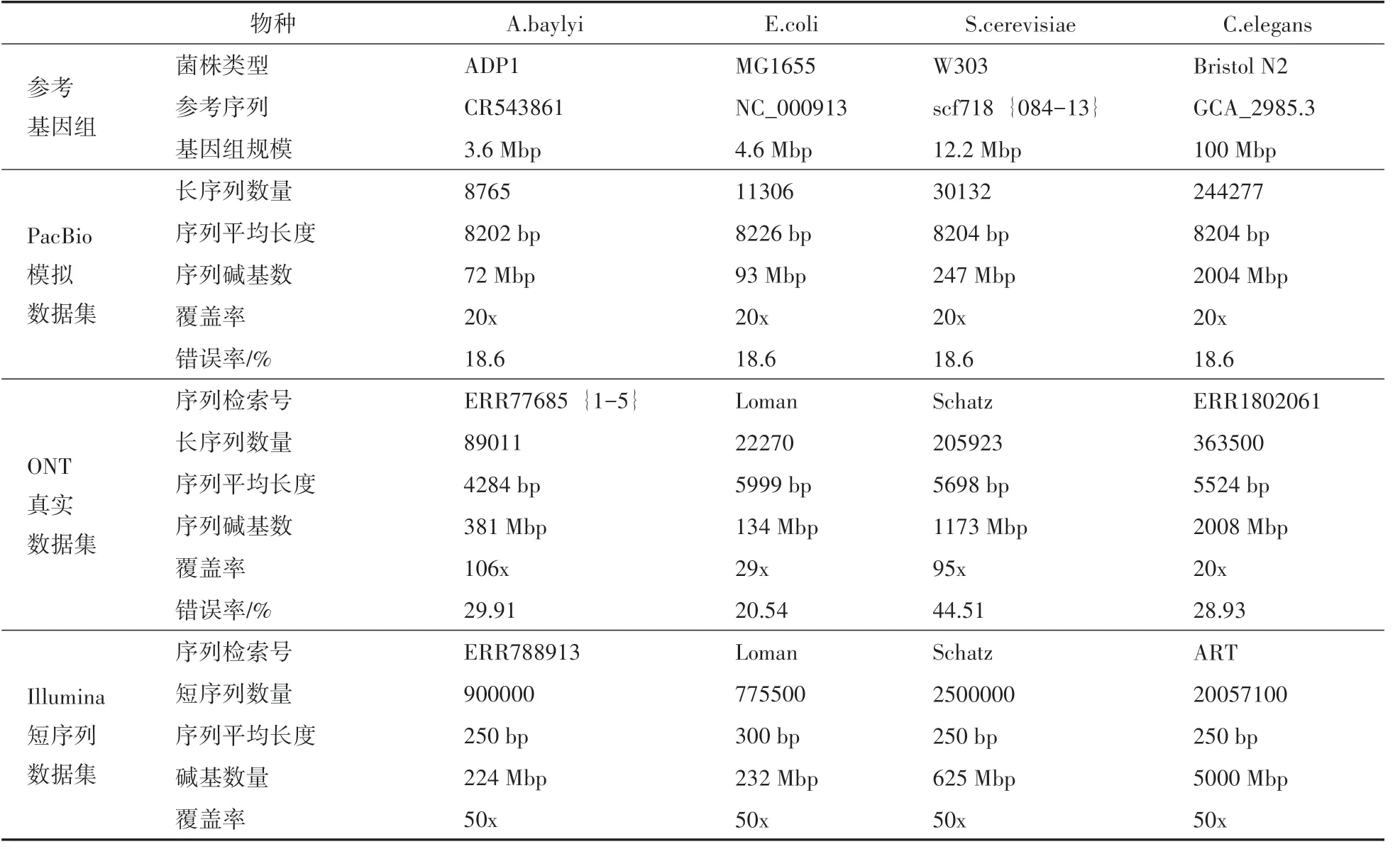
表1 實驗數據集
2.2 模擬數據集上的長序列糾錯實驗
對于模擬數據集上的實驗,采用糾正后的長序列的錯誤率(%)、吞吐量、split reads比率、運行時間這4個指標測試長序列混合糾錯算法的性能,其中、和的值越小越好,值越大越好。使用LRCStats 軟件測量得到算法CoLoRMap、HALC、Jabba、LoRDEC、NaS和HdGEC 在物種A.baylyi和E.coli 模擬數據集上的實驗結果,分別如表2和表3所示。
從表2 與表3 的實驗結果可以看到:在糾正后的長序列的錯誤率上,6 種混合糾錯算法的值均低于0.3%,本文算法HdGEC 對物種A.baylyi 糾正后的長序列的錯誤率最低,對物種E.coli 糾正后的長序列的錯誤率是第二低的,它比Jabbaa 算法糾正后的長序列的錯誤率0.0462%僅高了0.0134%。在吞吐量上,除了NaS算法,其他5種混合糾錯算法的指標值都較高,并且本文算法HdGEC 的吞吐量高于其他5 種混合糾錯算法。在split reads 比率上,算法CoLoRMap、HALC和LoRDEC 的srr值較高,值高意味著長序列的大部分區域沒有被糾正,本文算法HdGEC 的值較低,表明參考基因組與短序列比對的區域有很大的機會被發現,長序列被短序列覆蓋到的更多區域將會被糾正;在運行時間方面,糾錯算法Jabba 所需時間最少,而糾錯算法NaS所需時間最多。

表2 長序列糾錯算法在物種A.baylyi上模擬數據集的實驗結果

表3 糾錯算法在物種E.coli上模擬數據集的實驗結果
這表明,對于物種E.coli和A.baylyi 的模擬數據集的長序列糾錯,本文算法HdGEC 的吞吐量高于其他算法,并且錯誤率較低,產生的split reads 的比例也較小,能糾錯長序列的大部分區域。
2.3 真實數據集上的長序列糾錯實驗
對于在牛津納米孔真實數據集上的實驗,采用糾正的長序列數量、比率(%)、糾正的長序列平均長度、糾正的堿基數量、平均同一性、覆蓋率、運行時間這7個指標測試長序列混合糾錯算法的性能,其中、、、和的 值 越 大越好,和值越小越好。長序列糾錯算法HdGEC、 CoLoRMap、 HALC、 Jabba、LoRDEC和NaS在小型物種A.baylyi和E.coli、中型物種S.cerevisiae、大型物種C.elegans 真實數據集上運行的實驗結果分別如表4~表7所示。
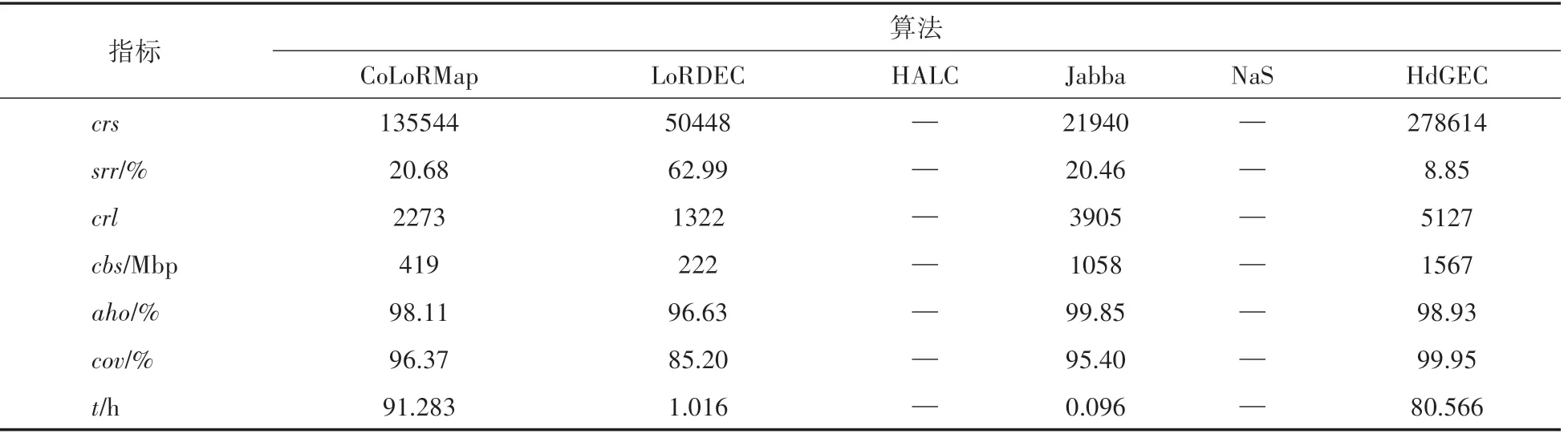
表7 算法在大型物種C.elegans真實數據集運行的實驗結果
從表4和表5可以看到,對于小型物種真實數據集的長序列糾錯,在6個算法中,本文算法HdGEC 糾正的長序列的平均長度是最長;本文算法HdGEC的split reads比率第二低,僅比算法NaS高了一點點;本文算法HdGEC、CoLoRMap、HALC、LoRDEC和NaS 的覆蓋率均達到100%;算法HALC 能糾正的長序列數量最多,本文算法HdGEC 能糾正的長序列數量第二多;在糾正的堿基數量方面,本文算法HdGEC和NaS 是較多的;在運行時間方面,算法Jabba 所需時間最少,本文算法所需時間是第三少。
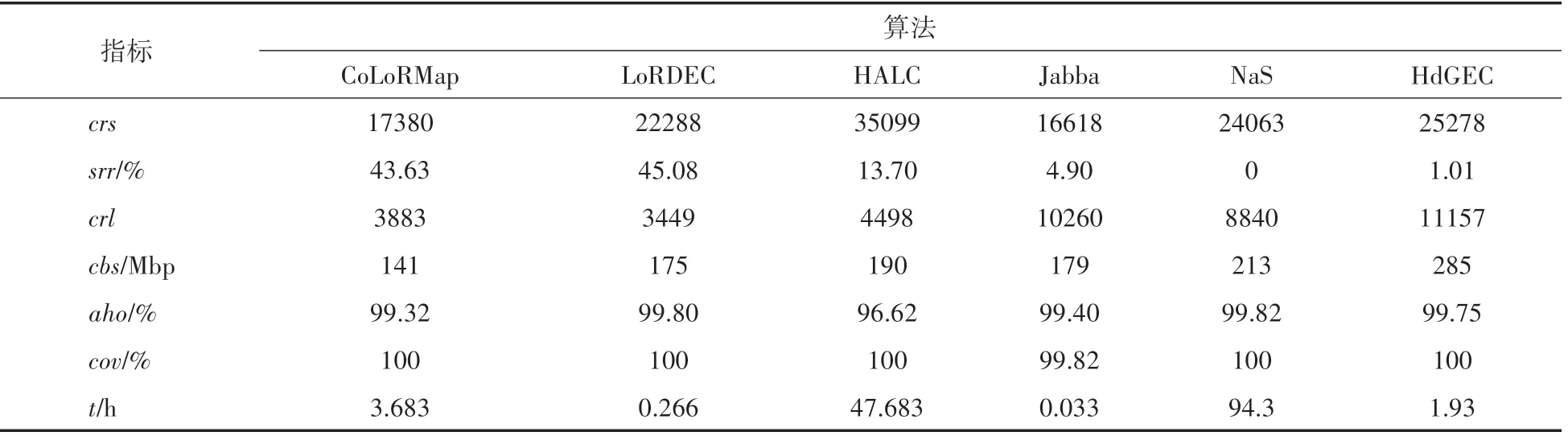
表4 算法在小型物種A.baylyi真實數據集的實驗結果
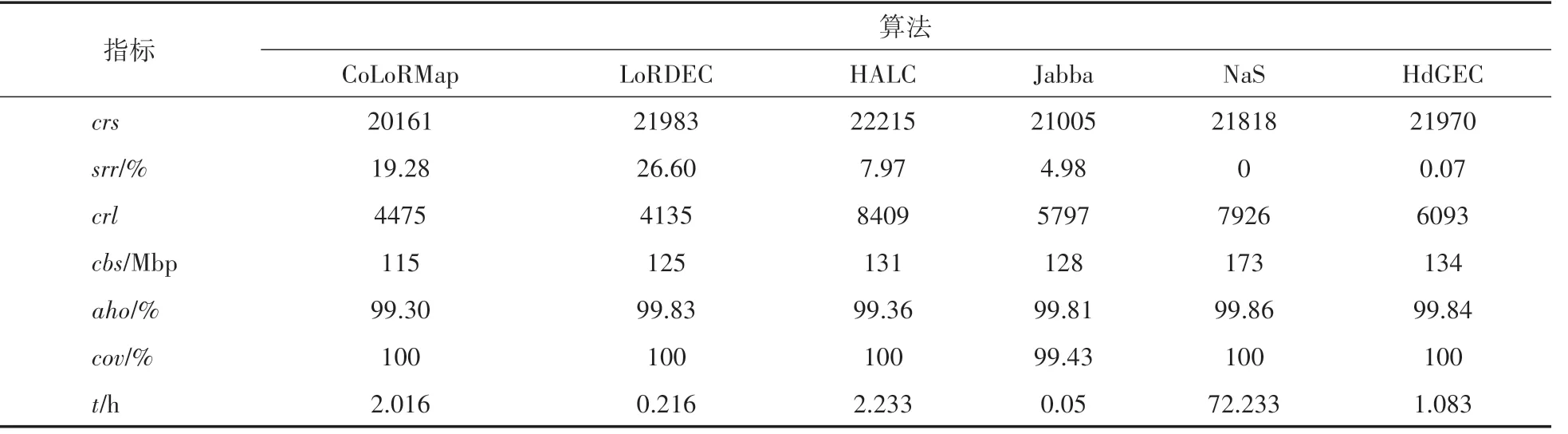
表5 算法在小型物種E.coli真實數據集的實驗結果
從表6可以看到,對于中型物種真實數據集的長序列糾錯,在6個算法中,本文算法HdGEC 能糾正的長序列平均長度最長、能糾正的堿基數量最多、split reads 比率最低、覆蓋率最高;在能糾正的長序列數量方面,算法HALC最多,本文算法HdGEC 第二多;在平均同一性方面,算法Jabba 最高,本文算法HdGEC 第三高;在運行時間方面,Jabba 算法所需時間最少,本文算法HdGEC 所需時間是第四少;而算法NaS運行時間超過了16天尚未計算得到結果。
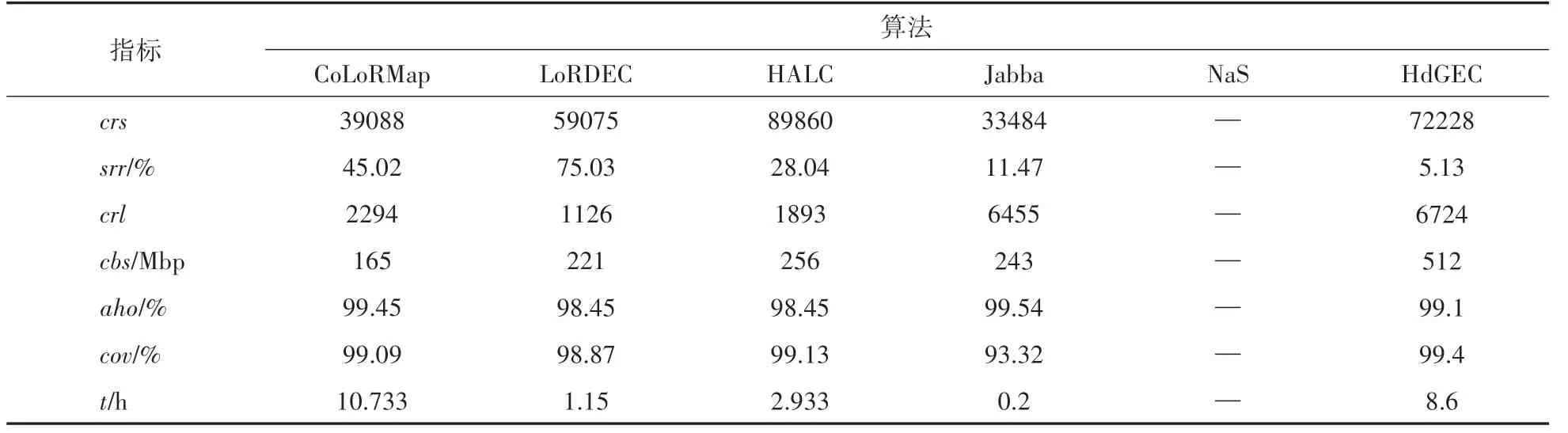
表6 算法在物種S.cerevisiae真實數據集的實驗結果
從表7可以看到,對于大型物種真實數據集的長序列糾錯,在6個算法中,本文算法HdGEC 能糾正的長序列數量最多、能糾正的長序列平均長度最長、能糾正的堿基數量最多、split reads 比率最低、覆蓋率最高;在平均同一性方面,算法Jabba 最高,本文算法HdGEC 第二高;在運行時間方面,Jabba 算法所需時間最少,本文算法HdGEC 所需時間是第三少;而算法HALC和NaS 運行時間超過了16 天尚未計算得到結果。
上述結果表明:對于中型和大型物種真實數據集的長序列糾錯,本文算法HdGEC 的整體糾錯質量最好;對于小型物種真實數據集的長序列糾錯,本文算法HdGEC 的整體糾錯質量也較好。
3 結語
為了有效糾正第三代測序平臺產生的錯誤率高的長序列,本文給出一個基于值可變de Bruijn圖和序列比對的混合糾錯算法。在模擬數據集和真實數據集上的實驗結果表明,與已有的長序列混合糾錯算法相比,本文算法獲得了整體較好的糾錯質量。本文算法為了獲得較高質量的長序列糾錯結果,是利用de Bruijn 圖來尋找種子序列路徑,這需要花費較時間長。下一步工作是研究將本文的算法并行化,以在維持獲得較高質量的長序列糾錯結果的同時,顯著減少糾錯過程所需的時間。
猜你喜歡
課堂內外·初中版(科學少年)(2025年1期)2025-02-28 00:00:00
課堂內外·初中版(科學少年)(2025年2期)2025-02-28 00:00:00
英語世界(2023年10期)2023-11-17 09:18:18
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
科學大眾(中學)(2019年3期)2019-05-17 10:04:30
汽車觀察(2018年10期)2018-11-06 07:05:26
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
