改進YOLOv4 模型的車輛檢測算法
2022-05-11 07:32:12羅素云陳楊鐘
智能計算機與應用 2022年2期
韓 帥, 羅素云, 陳楊鐘
(1 上海工程技術大學 機械與汽車工程學院, 上海 201620; 2 大工科技(上海)有限公司, 上海 200000)
0 引 言
隨著科技水平的不斷發展,自動駕駛技術也不斷成熟。 通過車輛自身的傳感器,對車輛、行人、信號燈以及可行駛區域的檢測,是自動駕駛的重中之重。 由于傳統目標檢測算法的實時性無法滿足自動駕駛的需求,因此基于深度學習的目標檢測算法,逐漸進入了人們的視野。
以RCNN 為代表的二階段檢測算法,具有更高的檢測精度。 但需要經過候選區域篩選以及目標分類兩大步驟,因此網絡的實時性較差。 以YOLO 和CenterNet 為代表的一階段檢測算法,將感興趣區域的篩選和目標分類集成到一個網絡,在保證精度的同時,提升了網絡的實時性。 與此同時,隨著MobileNet 和ShuffleNet 等輕量化網絡的提出,進一步降低了網絡的參數量和計算量,使得網絡可以在移動端進行部署。
1 YOLOv4 簡介
1.1 YOLO 系列算法
YOLOv1和YOLOv2算法是YOLO 系列算法的開山之作,其檢測思路不同于RCNN 系列的二階段算法。 二階段算法先利用RPN(區域生成網絡)等方法選取目標位置所在的候選區域,然后在感興趣區域中利用卷積神經網絡的方法提取圖像特征。 以YOLO 系列為代表的一階段目標檢測算法,其檢測流程是一個單一的網絡,創造性的把目標檢測問題看成一個簡單的回歸問題。 在一個網絡中,直接回歸出檢測框的位置,并得到框內物體的種類以及置信度,可以實現端對端的實時監測。
YOLOv3和YOLOv4算法的輸出都是具有3種不同尺度、不同感受野的特征層,其主干網絡均采用殘差結構。 一般情況下,卷積層數越多,網絡就越深,得到的特征信息也就越豐富。 但是,如VGGNet等網絡,其加深到一定程度便無法繼續加深。 因為隨著網絡深度的增加,其檢測效果不但不會得到優化,反而可能會變的更差。 而殘差網絡可以在網絡不斷加深,得到更強語義信息的同時,避免出現梯度爆炸和梯度消失等情況。
1.2 主干特征提取網絡
YOLOv3 在Darknet53 中,利用殘差網絡共進行了5 次特征提取。 當輸入為416*416*3 的特征圖時,分別得到208*208、104*104、52*52、26*26、13*13 5 層輸出。 隨著圖片不斷被壓縮,特征層深度不斷增加,得到的語義信息更加豐富。 同樣,YOLOv4 的主干網絡在其基礎上改用了跨階段局部網絡(Cross Stage Partitial Network)。 CSPNet 是一個逐層的特征融合機制,通過截斷方式可以有效避免同一梯度信息被反復學習,從而得到最大化梯度組合的差異。 殘差網絡基本結構如圖1 所示。
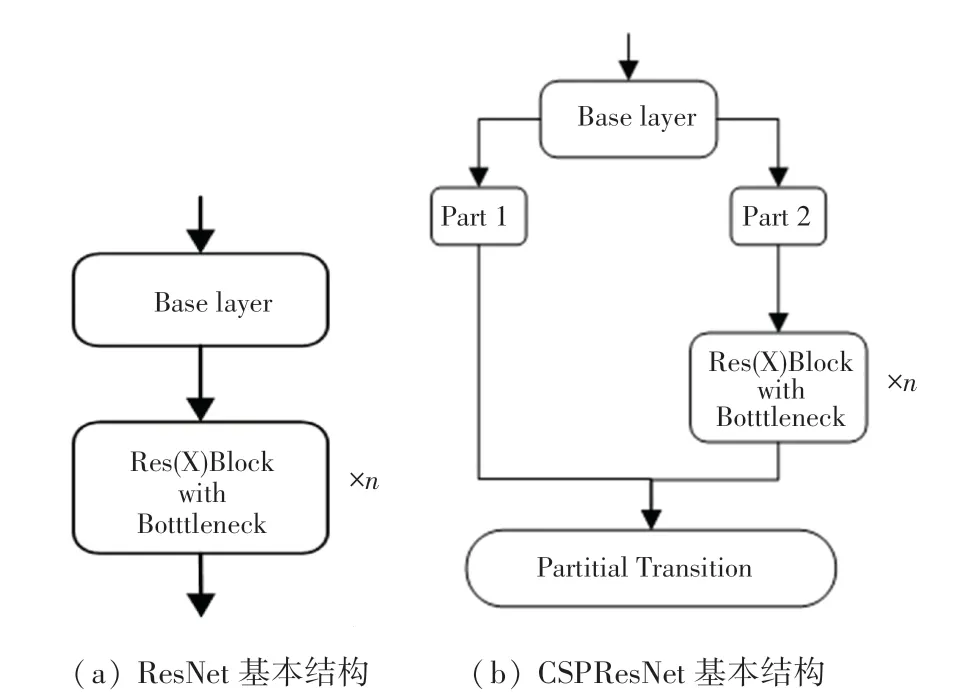
圖1 殘差網絡示意圖Fig.1 Schematic diagram of residual network
1.3 特征融合框架
主干特征提取網絡獲取的特征層需要進一步特征融合,才能得到語義信息和位置信息都強大的特征聚合。 YOLOv4 不僅包含與YOLOv3 相同的自頂向下的Feature Pyramid Networks 網絡, 還在此基礎上對13*13、26*26、52*52 的特征層利用Path Aggregation Network 進行下采樣,提高了淺層特征圖的信息利用率。 圖2 為YOLOv4 網絡中各部分代表的含義;YOLOv4 的整體框架如圖3 所示。
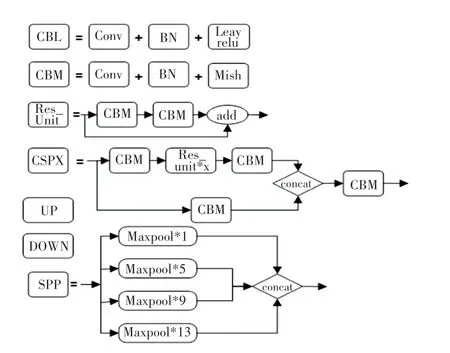
圖2 YOLOv4 框架組成模塊Fig.2 YOLOv4 framework components
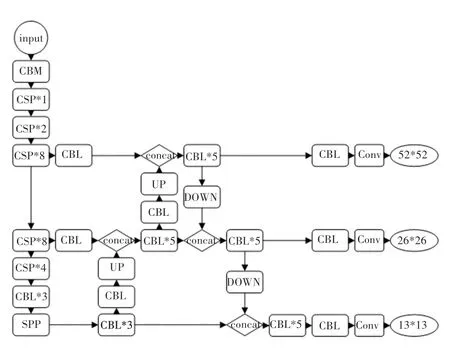
圖3 YOLOv4 整體框架Fig.3 YOLOv4 overall framework
其中:CBL 模塊由卷積層、歸一化和Leaky Relu激活函數組成;CBM 模塊由卷積層、歸一化和Mish激活函數組成;Res_unit 由兩個CBM 模塊經過殘差連接而成;CSP中代表包含幾個Res_unit;UP 代表上采樣的操作;DOWN 代表下采樣的操作;SPP結構將4 次不同尺度的最大池化進行通道的堆疊,然后再輸入特征融合網絡。
1.4 損失函數及預測框
目前,多目標檢測函數通常由兩部分組成,即分類損失函數和回歸損失函數。 近年來,隨著回歸損失函數的發展,目標檢測的精度和速度也有了一定提升。 如: IOU_Loss 主要考慮檢測框和目標框重疊面積;在IOU_Loss 的基礎上,GIOU_Loss解決了邊界框不重合時的問題;DIOU_Loss還將考慮邊界框中心點距離的信息;而CIOU_Loss則將重疊面積、邊界框不重合、邊界框中心距離和邊界框寬高比的尺度信息進行了融合,得到對于目標檢測最優損失函數。
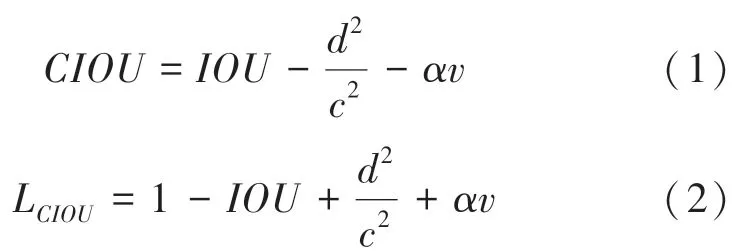
其中:代表縱橫比一致性;
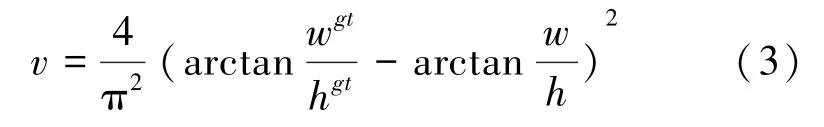
代表折中系數;
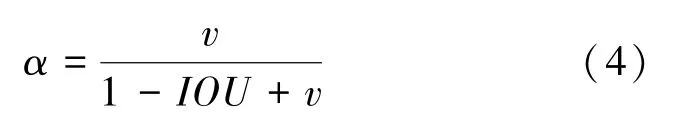
代表預測框和真實框的中心點的歐氏距離;

同時包含預測框和真實框的最小閉包區域對角線距離。
Yolov4 中采用Kmeans 聚類的方式,分別得到3個特征層的9 個不同尺度的先驗框,并采用CIOU_Loss 的回歸方式,使得預測框回歸的速度和精度得到提高。
2 改進的YOLOv4 模塊
2.1 小目標檢測難點
小目標檢測在許多任務中至關重要。 如,從汽車高分辨率場景照片中,檢測小的或遠處的物體對于安全部署自動駕駛汽車是必要的。
在目標檢測實際應用場景中,需要檢測的目標的尺寸往往大小不一,即多尺度檢測。 多尺度檢測要求訓練的模型應具有較強的魯棒性,可以檢測出不同尺度的各類物體。 然而在檢測過程中,大尺度物體占據圖像的面積大,經過多次卷積得到的特征也比較豐富,因此較容易被檢測出來。 所以,對于目標檢測來說,其難點在于如何精確定位和識別出占據圖像比例較小的目標。
小目標物體難以檢測的原因可以分成兩類:
(1)訓練所用的數據集中,小目標物體出現的次數較少。 主要原因有:
①a)數據集包含小目標物體的圖片數量較少;
②即使圖片中包含小目標物體,但其在一張圖片中出現的次數較少,很容易被忽略;
③許多圖片本身的分辨率較低、圖像模糊,導致其攜帶的信息較少。
(2)特征提取網絡無法很好的提取到小目標的特征。 當輸入進來的圖片經過不斷的卷積和采樣,使得圖片不斷地被壓縮,使小目標物體所占據的比例更小,且即使檢測框可以檢測到小物體所在的位置,也會在檢測框內部包含大量不屬于小目標的特征。 此外,特征融合網絡沒有充分利用語義信息和位置信息。
不同階段的特征圖對應的感受野不同,表達的信息抽象程度也不一樣。 淺層特征圖中含有更多的位置信息,深層特征圖中含有更多的語義信息,如何將語義信息和位置信息進行更好的特征融合,得到特征更加豐富的特征層,也是一個亟待解決的難題。
2.2 數據集增強
數據增強就是在現有數據的情況下,讓有限的數據通過變換,得到更多有價值的數據。 傳統的數據增強方式包括翻轉、旋轉、裁剪、變形、縮放等。 本文在Mosaic 數據增強方式的基礎上,增加了對小目標物體的復制與粘貼,使得場景遠處的小目標物體在數據集中占據更大的比例。
首先,在圖片中選取一個小目標物體,在圖片的任意位置進行多次粘貼。 在復制粘貼過程中,要保證粘貼的位置不能與圖像中現有的目標有遮擋,如圖4 所示。

圖4 小目標的隨機增強Fig.4 Random enhancement of small targets
粘貼完成后,利用Mosaic 數據增強方法隨機選取4 張圖片進行縮放,再隨機分布進行拼接,大大豐富了檢測數據集,特別是隨機縮放增加了很多小目標,讓網絡的魯棒性更好。 Mosaic 數據增強實例如圖5 所示。

圖5 Mosaic 數據增強Fig.5 Mosaic data enhancement
2.3 優化的多尺度特征融合
傳統的卷積神經網絡,都是自上而下進行的,隨著網絡層數的加深,圖像包含的語義信息也更加豐富。 但與此同時,小目標的特征可能會隨著網絡層數的加深而逐漸被忽略。 在YOLOv3 當中,通過FPN 中的上采樣結構,將深層特征圖的語義特征傳遞給淺層特征圖,實現特征融合。 YOLOv4 在此基礎上,增加了PANet 結構,將淺層特征圖的強定位特征傳入深層網絡中,進行進一步的特征聚合,得到網絡的3 個用于檢測的輸出層。
本文主要針對解決場景中出現的小目標漏檢及誤檢的問題。 YOLOv4 利用FPN 和PANet 網絡將主干特征提取網絡中13*13,26*26,52*52 的3 層輸出進行融合,得到語義信息和定位信息更加豐富的3 個特征層,然后進行先驗框的預測和回歸。
淺層的特征圖感受野小,比較適合檢測小目標。因此,本文算法在傳統的YOLOv4 的基礎上,將主干特征提取網絡的第二層104*104 的輸出經過上采樣和下采樣,再與前3 層輸出融合在一起,得到4 個特征層,來提高網絡對于小目標物體的檢測能力(如圖6 中紅色虛線部分)。 并且,利用Kmeans 聚類方法,得到適合每個數據集的先驗框的寬和高。 根據聚類得到的4 組先驗框的大小,將其劃分到對應的特征層上,大的先驗框分配到深層上,用于檢測大物體;小的分配到淺層上,用于檢測小物體。
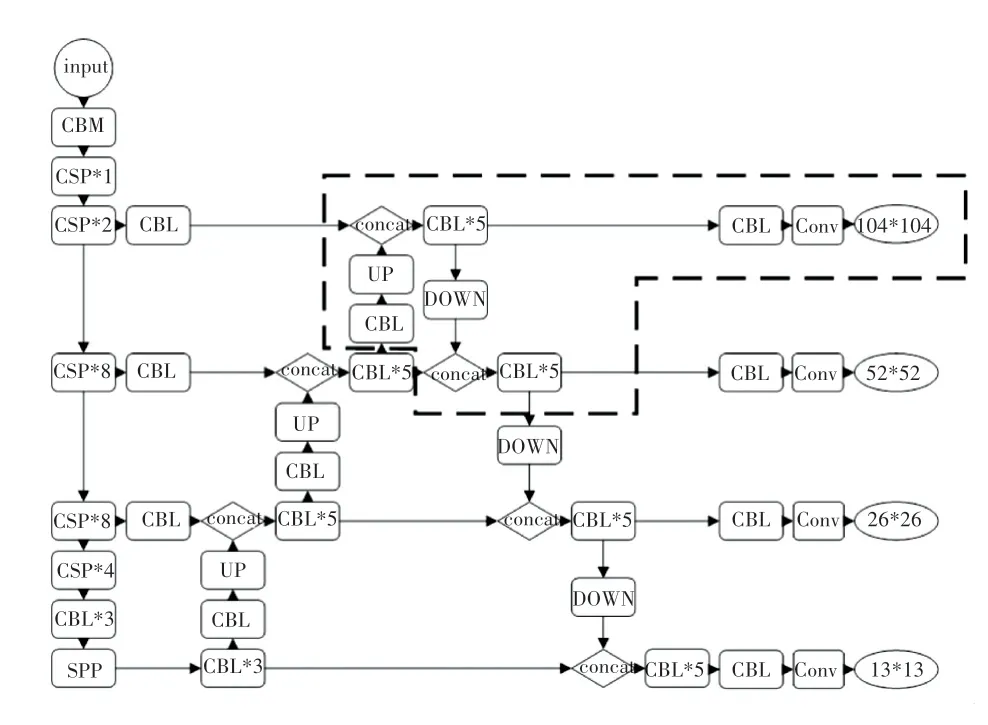
圖6 改進的YOLOv4 結構Fig.6 Improved YOLOv4 structure
3 實驗效果
3.1 數據集
本文采用了在圖像分類、目標檢測和圖像分割比賽中運用最為廣泛的VOC 數據集對網絡進行訓練。 VOC 數據集共包含人、車輛、動物、室內家具、背景等5 大類,總計21 個小類。
首先,選取vehicle 中的4 個公路交通工具進行檢測,分別是bicycle、bus、car、motorbike。 VOC_2007數據集和VOC_2012 數據集分別包含9 963 張和17 125 張尺度豐富的圖像,再從中隨機挑選出16 551張圖片組成VOC_2007+2012 數據集。 這3個數據集中,訓練集、驗證集、測試集的比例分別為8 ∶1 ∶1。
首先,利用VOC_2007、VOC_2012、VOC_2007+2012 數據集分別對vehicle 中的4 類進行訓練。 然后,再對經過數據增強后的3 個數據集進行同樣的訓練,分別得到結果,進行對比。 最后,將改進的YOLOv4 與其它檢測網絡進行對比。
3.2 實驗效果
為了驗證本文所改進的網絡在目標檢測當中的有效性,在服務器上進行了實驗。
圖7 中,圖7(a)是利YOLOv4 網絡在VOC_07+12 數據集上經過100 輪訓練后得到的val_loss 最低的權重進行預測后,得到的效果圖。 圖7(b)為同等條件下,改進的YOLOv4 網絡的預測結果。 從兩圖對比可以看出,改進的yolov4 網絡比原始的網絡可以檢測出更多場景遠處的小目標車輛,提升了小目標的檢測精度,從而使得整體檢測精度有了提升。

圖7 檢測效果對比圖Fig.7 Comparison of detection results
表1、表2 分別為各類檢測器在VOC_2007 +2012 數據集和增強VOC_2007+2012 數據集下的檢測效果。 其中包括YOLOv3 和YOLOv4,以及將YOLOv4 主干特征提取網絡CSPDarkNet53 替換為MobileNetv1、MobileNetv2、MobileNetv3 的輕量化網絡YOLOv4_M1、YOLOv4_M2、YOLOv4_M3。 將以上5 種改進的目標檢測網絡與本文提出的改進YOLOv4 網絡作比較,得到的實驗結果。
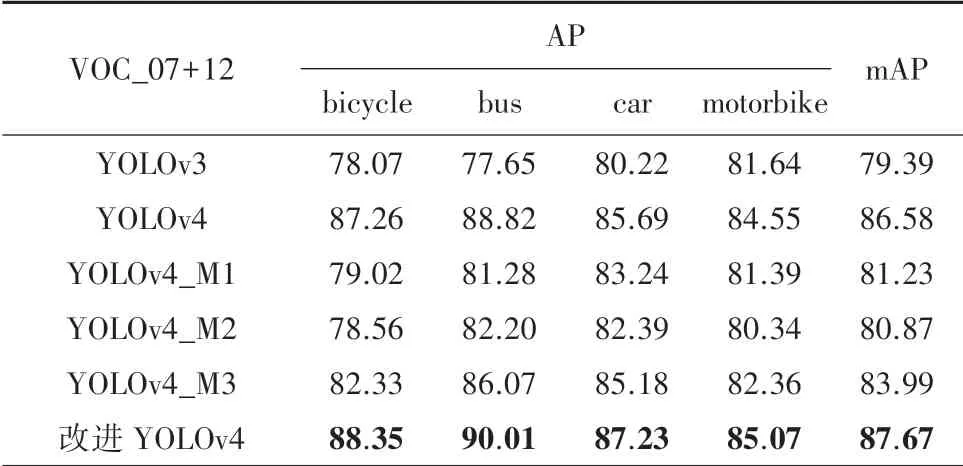
表1 VOC_2007+2012 數據集結果Tab.1 Results on VOC_2007+2012 dataset
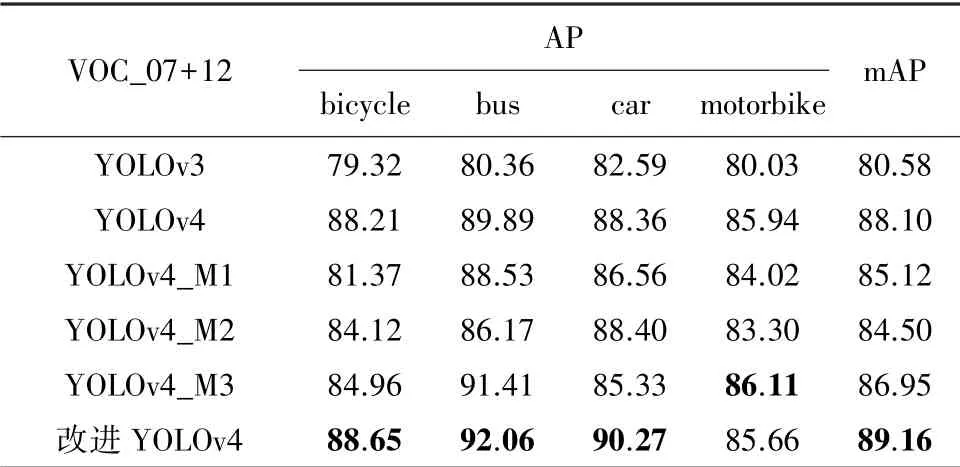
表2 增強VOC_2007+2012 數據集下實驗結果Tab.2 Results under the enhanced VOC_2007+2012 dataset
4 結束語
本文在VOC 數據集基礎上,篩選出屬于Vehicle 的4 類圖片,并利用Mosaic 和增加小目標的方式豐富了數據集中的Vehicle。 同時,在YOLOv4算法的基礎上,增加了特征輸出,使得網絡可以在同等條件下檢測更多場景遠處的小目標物體,提升了整體的檢測精度。 最后,利用改進的YOLOv4 在增強的VOC 數據集下進行訓練,對4 類交通工具的檢測精度均有不同程度的提升。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
