基于記憶網絡模型的學習過程評估方法研究
2022-05-11 07:32:12黃軼文
智能計算機與應用 2022年2期
黃軼文
(廣東工程職業技術學院 信息工程學院, 廣州 510520)
0 引 言
學習過程評估在高等教育中越來越重要。 傳統的“小數據”時代,每個教師就是一個數據的小孤島,依靠自己的直觀經驗判斷,以及考核成績,來反推學生的學習效果,使得評估效果滯后,無法在教學過程中實時發揮作用。 此外,粗放式的整體評估,無法結合每個學生的特點,為每個受教對象提供有益的參考。 在實際中,各種學習過程評估管理,往往淪為績效考核的工具,非但沒有發揮促進教學的效果,反而成了教師日常工作的負擔與桎梏。
2020 年席卷全球的疫情迫使大部分職業院校采用了線上教學模式,因時空距離、設備設施、教學習慣等與傳統的在校面對面的方式有很大差異,迫切需要一種符合現實情況的學習過程評估方法,能對教師的“教”與學生的“學”做出回饋,及時調整教學內容和形式,以求在特殊時期不僅保證學生獲得正常的學習收益,且學習過程評估結果也能為用人單位提供更有價值的建議和推薦。
本研究分為兩大部分:理論研究和應用驗證。一方面研究現有學習過程評價模型,創造新型記憶網絡模型MMN;另一方面應用理論研究的成果,通過實際數據驗證。
1 研究現況
知識追蹤模型由Corbett 和Anderson 于1995 年首次提出,并應用于智能教學系統。 隨后RS Baker和AT Corbett 等人發現,即使做出相同答案,但學生也具備不同的能力,需要根據學生整體答題情況來進行區分;Pardos 和Heffernan 發現,學生的差異性問題,可以通過增加一個特定的參數解決,為此建立了一個新的BKT 模型;Chen Lin 和Min Chi 則認為,在學習過程中,教學干預是重要的外部因素,影響到教師對學習過程輸出的判斷。 因此,在標準模型中增加了一個干預點,來仿真學生在學習過程中受到的外界影響;閭漢原、申麟等深入分析了答題過程對評估學生學習過程的影響。 文中認為,對于不同試題所花費的時間是一個重要因子(稱之為“態度”),不同的態度反饋出學生對知識點的掌握程度。 “態度”因子的加入,以及通過在線考試數據集的深度學習、模型修正,使得標準BKT 向客觀真實性更接近一步。
知識追蹤(Knowledge Tracing,KT)以時間為橫軸,追蹤學生在一系列移動的時間點,對一個或者多個知識點的掌握程度,并可以基于歷史數據建模,預測學生未來的學習狀態,掌握學生的學習需求。 知識追蹤的重要目標是建立學生個性化的學習時間軸,根據學生過去的練習答案,來追蹤學生的知識狀態。 老師可以根據學生的個人強項和弱項,給出適當的提示和調整練習的順序;學生可以意識到其學習進展,并可能會投入更多的精力,提高學習效率。
2 知識點追蹤模型
目前的智能教學系統(Intelligent Teaching System,ITS),主要使用基于貝葉斯網絡的學生知識點追蹤模型(Bayesin Knowledge Tracing,BKT)和基于深度神經網絡的學生知識點追蹤模型(Deep Konwledge Traing,DKT) ,對學生的知識點掌握狀況進行追蹤判斷。
2.1 BKT 模型
BKT 模型最早應用在美國的ITS 體系中。 該模型能對學生知識點的變化序列進行追蹤,記錄學生知識點掌握情況的變化。 BKT 通過stop_policy 準則,判斷學生是否經過多輪做題,掌握了相應的知識點。 典型的BKT 模型中設置4 個主要參數:
0、、、,用以表示學生掌握這個知識點的概率,一般可以從訓練數據里面求平均值獲得,也可以使用經驗值。 通常情況下,掌握的程度是對半概率,那么當005:表示學生經過練習后,知識點從不會到學會的概率;表示學生沒有掌握這項知識點但答對的概率;表示學生實際上掌握了這項知識點,但答錯的概率。 模型需要根據學生以往的歷史答題系列情況,訓練出這4 個對應的參數。
BKT 是根據不同的知識點進行建模,訓練數據有多少個知識點,就有多少組對應的參數(、、、)。 標準的BKT 模型無法描述知識點之間的關聯關系,當老師布置一項作業時,學生必須應用一個或多個知識點來完成這個任務。 在程序設計中,當學生試圖完成“int,int” 的加法運算時,則應采用“整型數值”的概念;當學生試圖求解“float,float,float” 的加法運算時,則應采用“浮點型數值”的概念。 學生能夠正確回答練習的概率,是基于學生的知識狀態,代表了學生掌握基本概念的深度和穩健性。
2.2 DKT 模型
DKT 是一個具有多自由參數的神經網絡模型,而BKT 是一個概率模型,擁有有限的自由參數;DKT 對一個領域內所有知識點建模,而BKT 是根據單一知識點構造模型;DKT 是多知識點的交叉輸入,而BKT 是按照知識點進行拆分;DKT 是隨著時間的推移,所有的知識點都交織在一起的,并按照順序對每個問題做預測。
現有的方法,如貝葉斯知識跟蹤BKT 和深度知識跟蹤DKT 以一種特定于知識點的方式或一種概括的隱藏向量來建模學生的知識狀態。 在BKT 中,學生的知識點狀態被分析成不同的概念狀態{} 和BKT 模型,BKT 特定于知識點,而DKT 使用一個總結的隱藏向量來建模知識狀態。 本文所用模型可同時維護每個知識點狀態,所有知識點狀態構成學生的知識狀態。 BKT 假設知識點狀態為已知和未知的二元潛變量,利用隱馬爾可夫模型更新二元概念狀態的后驗分布。 因此,BKT 不能捕捉不同知識點之間的關系。 此外,為了保持貝葉斯推理的可處理性,BKT 使用離散隨機變量和簡單的轉換模型來描述每個知識點狀態的演化。 因此,盡管BKT可以輸出學生對一些預定義知識點的掌握程度,但其缺乏提取未定義知識點和建模復雜概念狀態轉換的能力。
除了從貝葉斯的角度解決問題外,深度學習方法DKT 還利用了一種稱為長短期記憶(LSTM)的遞歸神經網絡(RNNs)的變體。 LSTM 假設了底層知識點狀態的高維連續表示,與BKT 相比,DKT 的非線性輸入到狀態與狀態到狀態轉換具有更強的表示能力,不需要人工標記的注釋。 然而,DKT 將學生對所有知識點狀態歸納為一種隱藏狀態,這使得追蹤學生對某個知識點的掌握程度和確定學生擅長或不熟悉的知識點變得困難。
3 新型記憶網絡模型(MMN)
BKT 和DKT 模型將學習過程評估研究推向了一個新的高度,BKT 具有開發知識點之間關系的能力,DKT 具有跟蹤每個知識點狀態的能力。 而建立一種新型的模型兼容BKT 和DKT 的能力,是本研究的主要目標。
MMN 通過挖掘知識點之間的關系,使用鍵靜態矩陣存儲知識點基本數據,使用值動態矩陣存儲和更新相應知識點的掌握程度,能評估學生對知識點的掌握程度,并能評估學生不斷變化的知識狀態,具有實時性和客觀性。
3.1 理論研究
MMN 模型結合了貝葉斯知識跟蹤BKT 和深度知識跟蹤的優點,開發知識點之間關系的能力和跟蹤每個知識點狀態的能力。 MMN 能自動學習“練習”和“知識點”之間的相關性,并為每個知識點維護一個狀態。 在每個時間戳里,只有相關的知識點狀態被更新。 例如, 當一個新的練習q出現時,模型發現q需要應用知識點c和c,然后人們閱讀相應的知識點狀態s和s,并預測學生是否會正確回答練習。 學生完成練習后,模型將更新這兩個知識點狀態,所有知識點狀態構成該學生整體認知狀態。 MMN 模型有一個稱為的靜態矩陣,其存儲知識點,另一個稱為的動態矩陣,存儲和更新學生對知識點的理解(知識點狀態)。 靜態和動態矩陣分別類似于字典數據結構(如Python 字典)中的不可變和可變對象作為鍵和值。
相對于標準的BKT 和DKT,記憶網絡模型(MMN)能自動發現知識點之間的聯系,并能描述學生不斷變化的知識狀態。 使得MMN 模型更加符合人類知識追蹤的實際情況。
MMN 引入了一個新的參數矩陣,即知識點之間相互影響的參數矩陣:R。 R表示知識點對于知識點的影響。 這意味著當知識點被更新時,關聯知識點也會被同時更新。 此外,如果和存在R,則知識點也被更新。 以此類推,凡與知識有直接或者間接聯系的知識點都會被更新。 MMN 使用相關權重發現練習的潛在知識點,替代專家手工執行模式,MMN 能描述學生不斷發展的知識狀態,更好的在數字世界中模擬真實的學習過程。 相關權重表示了知識點內在關系的強度,與標準中的條件影響方法(先計算練習之間的依賴關系,然后定義閾值對練習進行聚類)相比,MMN 可直接將練習分配給知識點,不需要預定義閾值。 新創造的模型能夠以智能化的方式發現潛在的知識點,每個練習通常與一個或多個知識點相關聯。 在此情況下,可將練習分配給相關權重值最大的知識點。 通過實驗驗證,MMN 能夠智能地學習知識點間的稀疏權重,發現知識點以及之間的聯系,并能顯示正確的結果。
課程中有個潛在的知識點{,,…,c},存儲在鍵矩陣M(大小為)中,學生對每個知識點的掌握程度,即知識點狀態{,,…,st} 存儲在值矩陣M(大小為) 中,并隨時間而變化。 MMN 使用從輸入練習和鍵矩陣計算的相關權重,通過讀寫到值矩陣,來跟蹤學生的知識。 輸入練習q乘以嵌入矩陣(大小為),得到維度為的向量k,通過取k和M()之間的內積得到權重w()。
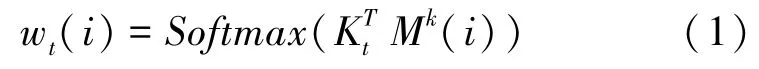
讀寫過程使用權重向量w、輸入練習q。 讀取的表達了學生對本練習的掌握程度。
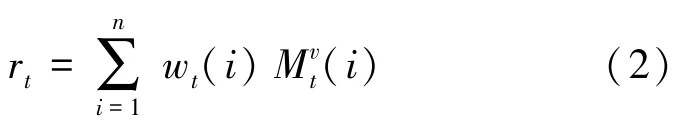
在學生回答問題q后,模型將根據學生回答結果更新值矩陣。 將(q,r) 寫入值矩陣,其相關權重w與讀取過程中使用的相關權重w相同。 變換矩陣的形狀為,e是包含元素的列向量,所有元素都在范圍(0,1) 內。
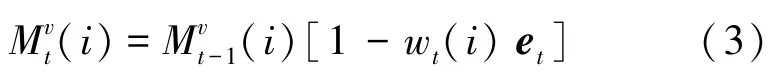
MMN 可以用來描述學生不斷變化的知識狀態。如果學生掌握了所有知識點的狀態,這些狀態能表明其長、短之處,使其更有動力,獨立地填補學習空白。 MMN 可以通過特定步驟,獲得學生不斷變化的知識狀態,并記錄學生在整個學習生命周期里面的起伏狀態,輸出分析報告,同時能夠針對性推薦就業崗位。
3.2 應用驗證
本次應用以軟件測試知識域為例。 2020 年9月份~2021 年1 月份,以軟件測試專業180 名同學為樣本,應用MMN 模型進行動態學習過程評估。將軟件測試的知識點進行分類,以集合的方式劃分為單元測試、集成測試、系統測試和驗收測試4 個知識域。 詳見表1。

表1 軟件測試知識域Tab.1 Software testing knowledge domain
測試期間每月進行一次評估和數據收集,分別是9 月11 日、10 月8 日、11 月2 日、12 月3日和1 月4 日,每次評估由100 道選擇題組成,題目涵蓋了單元測試、集成測試、系統測試和驗收測試4個知識域。 為了便于計算機處理,答案用二進制0、1 表示,0 表示錯誤,1 表示正確。 同一題目中可以包含單元測試、集成測試、系統測試和驗收測試中的一個或多個知識點。 由于傳統的考卷方式只能得到籠統的分數,無法分析其中某個知識點的掌握分布情況。 因此,測試評估使用MMN 模型對學生知識水平進行追蹤和判斷。
共180 名學生參與評估,使用MMN 模型跟蹤學生知識域的掌握程度。 數據結果分為三等級:在0.5 以下表示較差、0.5~0.8 為良好、0.8 以上為優秀。 表2 中的數據為全部學生的中位數,另外還為每個學生建立單獨數據表,從學生的整體知識掌握情況、群體差異和個體差異等方面來分析和應用評估結果。
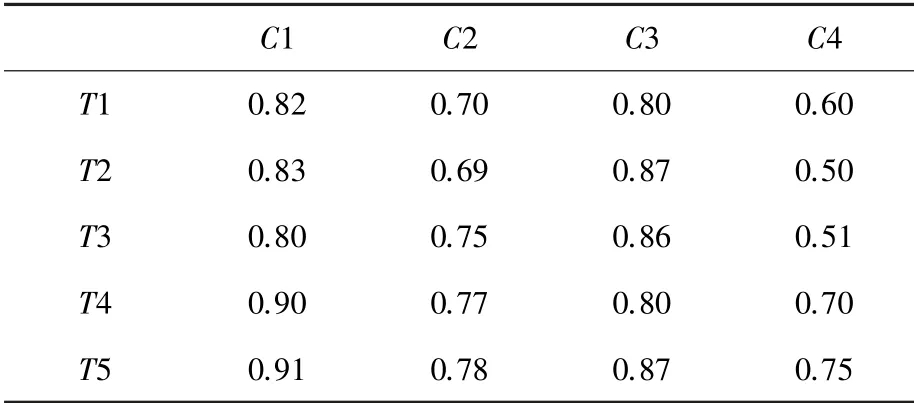
表2 MMN 模型跟蹤學生知識域掌握程度中位數Tab.2 The median of students' mastery of knowledge domain tracked by MMN
整體來看,單元測試和系統測試這兩個知識域,學生掌握程度良好。 授課教師按照教學計劃進行,對課時和課程內容沒有做過多調整,成績預測和實際考核結果呈收斂趨勢。 集成測試和驗收測試這兩個知識域,學生感覺有一定難度,掌握程度一般。 根據跟蹤結果,分析具體原因是:
(1)集成測試需要編寫測試腳本,需具備一定編程能力;
(2)驗收測試要結合實際項目,需根據不用的客戶要求,制定測試方案,而學生缺乏項目實操經驗,難以理解和靈活應對不同的項目要求。 為此,根據跟蹤分析結果,及時采取有關措施:
①調整授課計劃,著重培養學生初步編程能力,能夠編寫基本的測試腳本;
②與合作企業聯合,帶領學生到項目驗收現場,聽取客戶意見并協助部分工作,對項目驗收流程有初步的認知。 經過調整,集成測試和驗收測試這兩個知識域的掌握程度,呈逐步上升趨勢。
與此同時,每個學生根據自己的學習跟蹤數據表,認識到個體知識點的掌握程度差異,根據自身條件有針對性地調整學習計劃。 學生的個體學習跟蹤數據表進入信息化系統,用大數據方法為每個學生進行數據畫像,突顯學生特點。 在學生求職和企業招聘過程中,數據畫像也為企業全面深入了解學生的情況提供了更多的參考。
4 結束語
本研究的價值在于,新型記憶網絡模型MMN融合BKT 和DKT 的優點,更加符合人類知識追蹤的特點,同時利用模型理論研究的成果,從理論研究到實際應用推進一步。 實踐證明在教師側、學生側和社會側,本研究都獲得了良好的社會效益。
教師側:通過學生的個性化、知識、行為、經歷建模,學生大數據畫像、學生階段性考核成績、學生答題時長、知識點分解、關聯知識點權重等方式,以直觀的圖標呈現和分析報告等形式,為教與學的數據挖掘和利用提供了指導。 教師根據學習過程評估的反饋,動態調整教學計劃,調整課時計劃安排。 可以根據學生個性畫像,對薄弱生、薄弱環節、薄弱知識點進行重點研究和加強。
學生側:在學習過程評估中,通過信息化系統的輔助,建立學習過程全生命周期數據集,把現實中的學生模擬進數字世界,從性格、能力、態度、行為等多維度對學生進行畫像。 在學習過程中,同步為學生反饋評價系統的結果,提示學生學習過程中的薄弱環節,調整學習的精力分配。 根據以往學生的學習過程評估,預測學生的學習成績,增強學習的信心和動力,固化優良學習行為習慣,糾正不良學習行為。
社會側:按照傳統的教學模式,通過試卷得分并不能全面、真實地反映學生特質,也無法向用人單位描繪學生的不同差異。 利用學習過程評估結果分析后,可以較全面的發現學生在不同方面的能力和潛力,從而為用人單位提供更有價值的建議和推薦。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
核科學與工程(2015年4期)2015-09-26 11:59:03
