基于TD3 算法的對話策略研究
2022-05-11 07:31:50余承健
智能計算機與應用 2022年2期
洪 洲, 余承健
(廣州城市職業學院 教務處, 廣州 510408)
0 引 言
在人工智能發展時代,許多對話機器人產品逐漸融入了人們的生活。 如:阿里的天貓精靈、百度的小度和騰訊的小微等智能語音助理。 通過與這些智能對話機器人交互,人們能夠獲得更便捷的服務。 正是由于其廣泛的應用前景,工業界和學術界均給予了高度重視和關注。
對話系統分為任務型對話系統和非任務型對話系統。 非任務型對話機器人又稱閑聊機器人,在開放領域內實現盡可能多輪次對話;任務型對話系統的研究方法主要有兩種:多模塊級聯方法和端到端的方法。 多模塊級聯方法又稱為管道方法,各模塊功能獨立且易于理解,缺點是易導致誤差的積累。端到端方法可以將用戶的輸入直接輸入模型,進而得到系統的輸出。 可以觀察到輸入的反饋,但可以用于訓練的數據難以獲取,并且可維護性和解釋性較差。
本文聚焦于任務型對話系統的研究。 其系統主要模 塊 為: 自 然 語 言 理 解( Nature Language Understanding,NLU)、對話管理(Dialogue Manage,DM)、自然語言生成(Nature Language Generator,NLG)。 自然語言理解模塊對用戶輸入的文本進行解析,通常有槽填充、意圖識別。 對話管理模塊的主要功能,是在多輪對話過程中,維護歷史信息和當前的狀態,并且生成下一輪對話的回復策略,同時也可與外部知識庫進行交互。 自然語言生成模塊的主要功能是,根據對話策略模塊的結果及預先定好的規則,生成自然語言形式的回復。
對話管理在整個對話系統中占據重要地位,直接影響整個系統的性能。 本文從強化學習的角度出發,提出一種結合規劃的雙延遲深度確定性策略梯度算法,來優化對話策略,改善模型難以收斂的問題。 在代理方面,針對TD3 算法只適合處理連續空間任務的特點提出了改進,使其能夠處理離散空間的數據。 在配置環境方面,借助經典DDQ 模型的思想,將其與TD3 算法結合。 實驗結果表明,本文提出的模型能夠更快的收斂,取得較好的實驗結果。
1 相關工作
任務型對話系統的對話策略主要任務是:根據當前時刻的對話狀態,在預先定義的動作集中,選擇1 時刻的動作。 對話策略直接決定當前對話任務的優劣,因此, 對話策略的設計及其建模過程一直都是研究的熱點和難點。 當前,主流方法有基于規則的方法、端到端方法和強化學習方法。
1.1 基于規則方法
基于規則的方法利用該領域的專家分析對話流程,并設定預定義的對話狀態及對該狀態的回復。最有代表性的方法就是有限狀態機和槽填充模型。 有限狀態機的狀態轉換和流程都是預先設計的,所以其流程可以有效地控制,而且結構清晰。但是,這樣的狀態機無法移植到另一個領域。 對于槽填充模型而言,槽就是對話系統在特定任務中所需要獲取的特定信息。 如,地點、時間、天氣等。 對話系統通過當前槽的狀態及其優先級,決定下一個動作。 對話過程被建模成序列標注,對話順序是不確定的,獲得的回答非常靈活。 但是,也可能產生狀態爆炸的情況。 基于規則的方法,雖能夠很好的控制對話的流程,卻嚴重依賴專家制定的領域知識,同時很難遷移到新的領域。
1.2 端到端方法
端到端方法是隨著深度學習技術的突破發展而提出的。 使用端到端的訓練模型,將一個域的序列映射到另一個域。 在某一時刻,對話管理根據上一步詞序列和一些結構化的外部數據庫,選擇概率最高的詞匯作為下一步的回答。 通常選擇的模型為編碼器-解碼器,減少了模塊化開發的成本。 然而端到端的方法,也受限于對話數據集的獲取和標注,無法及時對自身策略進行調整和進行在線學習。
1.3 強化學習
將強化學習的思想應用于對話策略的建模,是當前的主流方法。 通過智能體與環境交互過程中的學習,以獲得最大化的獎勵,其結構如圖1 所示。
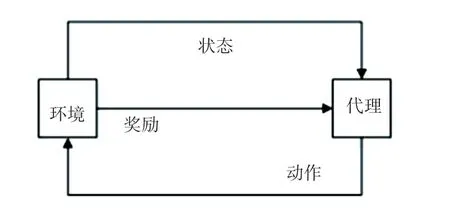
圖1 強化學習模型Fig.1 Reinforcement learning model
對話管理的過程可以看作一個馬爾科夫決策過程,通常被定義為五元組,,,,。 通過策略π 實現一個行為與狀態之間的映射,策略的取值可以是確定值,也可以是隨機值。 映射的動作既可以通過一個連續分布函數取值,也可以是離散值。
強化學習的優勢:一是無須人工制定規則,且提高了泛化能力;二是可以充分利用狀態空間,解決了覆蓋率低的問題。 近年來,隨著深度學習的快速發展,學者們結合深度強化學習的方法用于建模對話策略,其算法性能在一些領域優于人類。 如:Li 等人通過與機器人的交互學習對話策略,構建了一個用戶模擬器;基于DQN模型的算法在訂電影票的任務上比基于規則的方法正確率更高;Volodymyr等提出了BBQN 模型,使用辛普森采樣對狀態空間進行探索,明顯提升了效率;Peng 等人為了解決訓練強化學習的代理需要耗費大量資源和時間問題,引入用戶模擬器來產生大量用于訓練的模擬數據,提出了DDQ(Deep Dyna-Q)模型;Su 等人對DDQ 模型進行了改進,引入RNN 鑒別器,用于區分真實的用戶經驗和生成的模擬經驗,從而過濾掉世界模型生成的低質量訓練數據,同時減少了訓練過程中對于模擬數據的依賴。 從實驗結果可見,D3Q對話管理系統的魯棒性和泛化能力優于DDQ 對話管理模型。
2 結合規劃的TD3 算法
對話系統讓智能機器人能夠使用自然語言的方式與人類溝通,其中任務型對話系統旨在高效溝通并且讓用戶獲取有價值的信息。 在這類對話系統中,通常是由一個任務型對話策略,來提供語言上的行為決策。 近幾年,強化學習廣泛應用在對話策略模型的學習上,即從基于語言的人機交互中訓練對話策略模型。
本文提出一種基于深度強化學習的算法,來提高對話策略的學習效率,即結合規劃的TD3 算法。整體結構由5 部分組成,各模塊功能如下:
(1)基于LSTM 的NLU 模塊,用于識別用戶的意圖和相匹配的語義槽;
(2)根據識別的結果,進行對話狀態的跟蹤并生成對話狀態表述;
(3)對話策略學習:根據對話狀態跟蹤的結果,選擇一個執行的動作;
(4)根據上一步選擇的動作轉化為對應的自然語言;
(5)世界模型:用于生成模擬的用戶行為和獎勵。
本文中的訓練是利用預先收集的數據,采用熱啟動的方式進行的。 模型訓練過程如圖2 所示,其實現步驟如下:
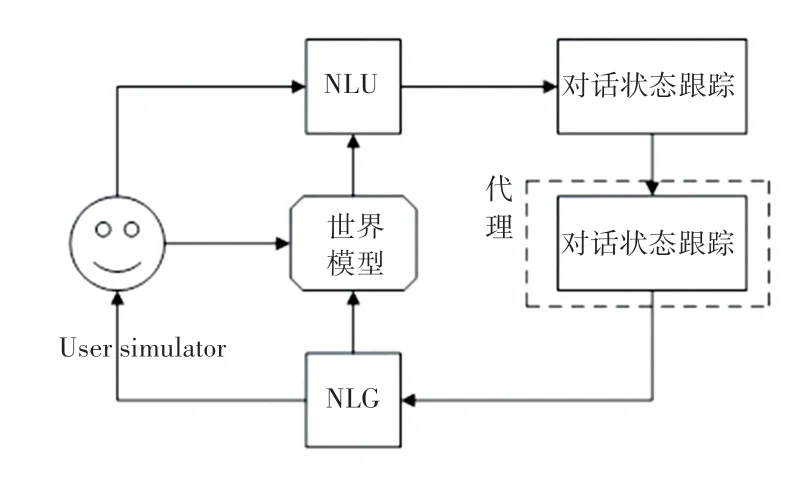
圖2 模型訓練過程Fig.2 Model training process
(1)代理與用戶模擬器交互,利用真實對話數據改進對話策略;
(2)使用真實的對話數據更新世界模型;
(3)將更新后的世界模型的模擬經驗用于改進對話策略。
2.1 直接強化學習
直接強化學習的目標,是讓代理使用用戶模擬器的真實對話數據優化對話策略。 本文利用改進的TD3 算法,根據用戶模擬器產生的對話狀態,由相應的策略選擇動作, 用戶模擬器同時反饋給代理相應的獎勵,此時對話狀態將更新為',最后將對話經驗存儲到預先設置的經驗回放池,繼續循環整個過程,直到結束對話。
本文中改進的TD3 算法共有6 個網絡結構,如圖3 所示。 該算法采用兩個結構完全相同的critic網絡評估值,選取較小值作為更新的目標。 有效緩解了樣本噪聲對動作價值估計的影響,以及不準確估計值累加所導致的無法收斂情況。 TD3 算法對策略采用延時更新的方法,由于target 網絡與online網絡參數的更新不同步,則規定online 網絡更新次以后再更新target 網絡,從而減少了誤差積累,并降低了方差。 TD3 算法采用了一種目標策略的平滑正則化,在target 網絡的動作估計中加入隨機噪聲,使得值函數的更新平滑。
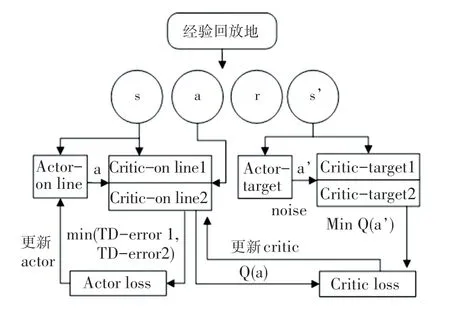
圖3 TD3 算法模型Fig.3 TD3 algorithm model
在critic-online 網絡中,調節、的值來最小化均方誤差損失函數,優化目標函數如下:
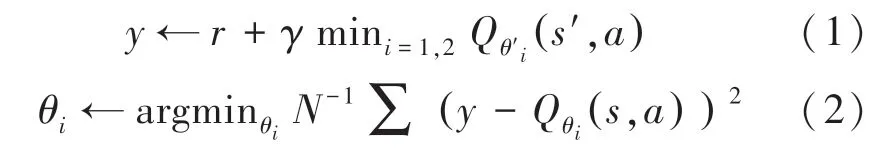
其中,為折扣因子,、和分別為crituonline 網絡和Actor-online 網絡的隨機參數。
原始TD3 算法用于處理連續空間的數據,使用梯度求最優值,如式(3)所示:
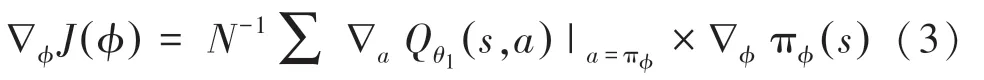
由于本文對話任務數據均為離散數據,因此使用TD-error 代替梯度計算。 表示在當前的環境中,如何選擇動作可以獲得最大的獎勵期望值,并將actor 網絡的輸出進行softmax 計算,使用確定性策略,選擇一個具體的動作值。 因此將式(3)改為如下形式:
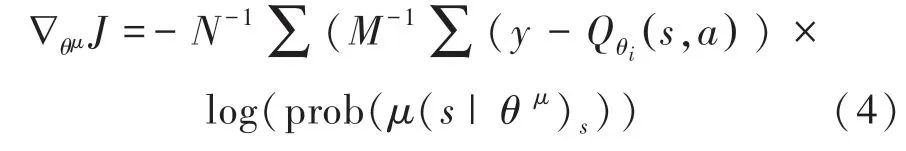
其中,由式(1)可得, log(prob((s |θ)為選擇某一個動作的概率值。 可通過軟更新機制更新參數,如下所示:
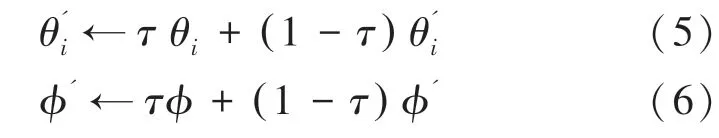
最后,使用深度學習的batch 訓練方式,迭代更新對話策略的參數。
2.2 規劃
在綜合規劃的步驟中,世界模型產生模擬的對話數據,然后用來訓練對話策略。 在訓練本文的模型時,參數是代理用于執行規劃過程的次數。 假定世界模型能夠準確的模擬用戶環境,即在一定程度上增大值來提升對話經驗策略。 用戶模擬器中得到的真實對話經驗記為D,世界模型產生的模擬經驗記為D。 雖然規劃和直接強化學習都使用改進的TD3 算法,但是直接強化學習使用的是D數據,規劃使用的是D數據。
2.3 世界模型
世界模型利用真實的對話數據D來訓練其模型參數。 在每一輪對話訓練中,世界模型將上一輪的對話狀態和上一輪的代理行動作為模型的輸入,得到用戶的回復動作a、 獎勵和一個表示對話是否結束的信號。 網絡結構如圖4 所示。
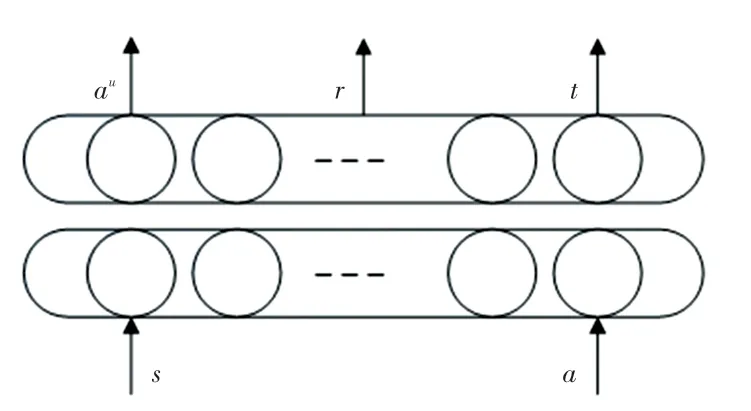
圖4 世界模型結構Fig.4 The world model architecture
其中,a、和的計算公式如下:
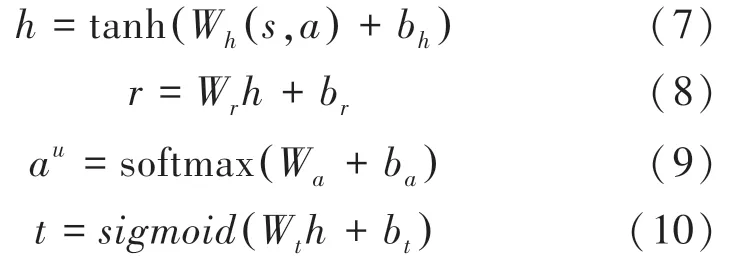
其中, (,) 表示拼接操作,得到的元組數據(,,,') 保存到D中,用于后續代理的訓練。
3 實驗設置
3.1 數據集
本文使用的數據集已經通過標注,其中包括語義槽16 個、對話動作11 個以及帶標記的對話280個,對話平均有11 輪,見表1。

表1 意圖和語義槽Tab.1 Intents and slots
3.2 基準模型
(1)基于規則的模型:使用基于人工制定規則的對話策略;
(2)DQN 模型:基于DQN 算法實現;
(3)A2C 模型:使用優勢函數代替Critic 網絡中的原始回報,作為衡量選取動作值和所有動作平均值好壞的指標;
(4)TD3 模型:即本文中提出的結合規劃改進的TD3 算法,引入世界模型,并且綜合規劃步驟進行學習。
3.3 實驗設置和評估指標
實驗中深度強化學習網絡的激活函數選擇tanh函數。折扣因子的值設為0.9,D與D的大小均為5 000。 規劃訓練過程中,模擬對話的最大回合數為40。 本文所有實驗使用100 輪對話的進行預訓練,即使用熱啟動的方式。
主要評估指標為成功率、平均回報、平均輪數。假定測試中所有完整的對話數目為,成功預定電影票的完整對話為,完整對話所獲得的總回報為,所有完整對話總對話輪數為。 則:
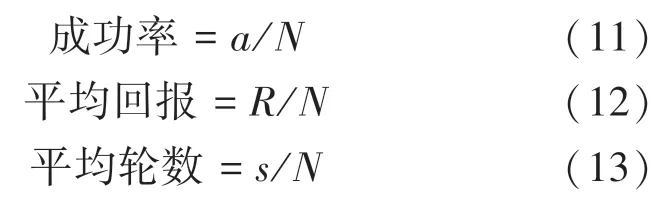
成功率用來衡量模型的主要性能,評估當前的對話策略的優劣;平均輪數和平均回報展示了系統的魯棒性,這兩個指標表明模型所追求的目標,即在最小的輪次獲得最多的回報。
3.4 實驗結果分析
本文中TD3 模型需要學習結構相同,但是參數不同的神經網絡有actor 網絡和critic 網絡。 實驗設置兩個網絡的參數不需同步更新,critic 網絡的打分,決定了actor 網絡的動作。 因此,actor 網絡的參數更新具有滯后性。 DQN 模型只需要學習一種神經網絡參數,其效果要優于A2C 模型。 而本文的TD3 模型要優于A2C 模型,驗證了本文提出模型能更快的收斂,提高對話系統的性能。
在綜合規劃的步驟中,世界模型可以用于減少代理對用戶模擬器的依賴和負面影響。對于不同的值,使得代理的訓練結果不一致。 世界模型的參數在整個實驗的訓練過程中也是需要學習的。 因此,實驗首要任務是尋找最佳值。 通過設置不同的值進行訓練得出:當10 時,世界模型生成的模擬經驗效果較好,模型訓練效果最佳。
表2 展示了不同模型在10輪對話的最終測試結果。 通過分析可以得出:結合規劃的TD3 模型從策略梯度的角度建模對話管理系統,提高了約20%的對話系統性能; 成功率和平均回報稍優于DQN模型所代表的值函數模型;所使用的平均輪數持平。
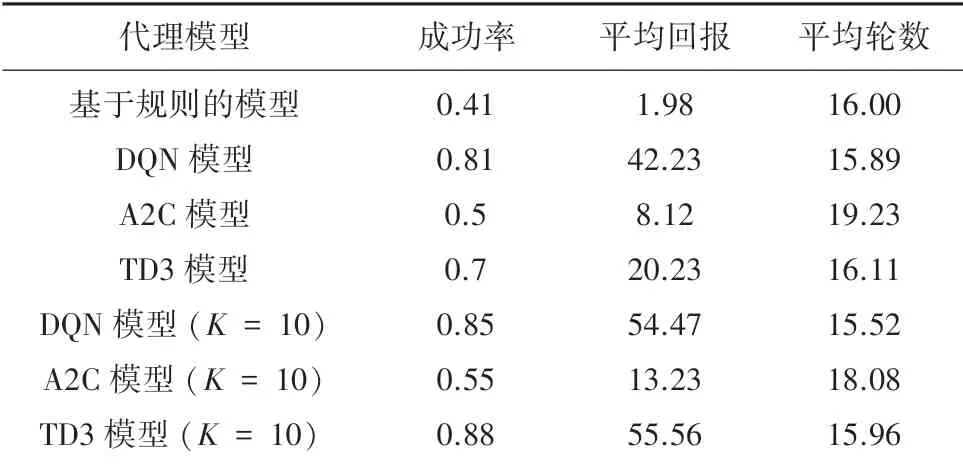
表2 不同模型在10K 輪對話的最終表現Tab.2 The final performance of different models in 10K conversations
綜上所述,可以歸納出模型的優點:本文提出的模型適合于規模較大的離散的對話任務;通過經驗回放和用戶模型的引入,帶來比較好的對話策略學習效果,模型易于收斂。
4 結束語
本文結合規劃的TD3 算法在模型優化和環境建模做出了改進;在代理設置上,使用基于策略梯度的方法建模對話管理,并且使用經驗回放和孿生網絡結構,加快了模型的收斂,提高了對話性能;在環境設置上,引入了世界模型,減少了用戶模擬器在代理訓練的負面影響。 當然,本文在策略梯度函數的設置上還有待進一步的優化,用戶模擬器在功能上可以增加真人的對話數據收集等。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學大世界(2018年1期)2018-04-12 05:39:14
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
