面向新興產業的檢驗檢測服務關系抽取
2022-05-11 07:31:38張婷婷張龍波邢林林蔡紅珍
智能計算機與應用 2022年2期
張婷婷, 讓 冉, 張龍波, 邢林林, 蔡紅珍
(1 山東理工大學 計算機科學與技術學院, 山東 淄博 255000); 2 山東理工大學 農業工程與食品科學學院, 山東 淄博 255000)
0 引 言
新興產業是隨著新的科研成果和新型技術的誕生,應運而生的新的經濟部門或行業,涉及節能環保、生物產業、新能源、新材料等眾多領域。 檢驗檢測是指通過專業技術手段對動植物、工業產品、商品、專項技術、成果及其他需要鑒定的物品所進行的檢測、檢驗、測試、鑒定等活動。 對新興產業檢驗檢測數據研究發現其中包含了大量有用的信息,包括各檢測機構可提供的檢測范圍及機構地理位置信息等,將這些信息結構化保存,可以為領域內的合作關系提供數據指導,有利于后續的產業升級。 關系抽取是自然語言處理(Natural Language Processing,NLP)的基層任務之一,主要是從文本中識別出實體,并抽取實體之間的語義關系。 在新興產業領域使用關系抽取技術能夠快速發現機構可提供的檢測項目,繼而構建新興產業檢驗檢測關系集,不僅能夠為尋求檢測服務的機構提供精準的業務推薦,還能總覽行業整體發展水平,促進新興產業快速發展。
新興產業檢驗檢測關系抽取缺少專業的實驗數據,且數據中廣泛存在語義混亂、一個主實體對應多個客實體的問題,基于此本文構建了領域內數據集并提出了一種適用于新興產業檢驗檢測數據的關系抽取模型,主要工作包括:
(1)在輸入層為每個關系設置不同的關系標簽,并與字詞向量、位置向量混合作為神經網絡架構模型的輸入,其中位置向量能從主實體及客實體兩個層面分析語義位置信息對關系判定的影響;標簽向量可以強化各關系的界限,有利于后續充分學習各關系的特征信息,提高分類準確率;
(2)提出由卷積神經網絡(Convolutional Neural Network,CNN)和雙向長短期記憶網絡(Long Short Term Memory,LSTM)組成的關系抽取模型,既能夠利用BiLSTM 兼顧長序列文本的整體信息,又能夠利用CNN 提取文本局部有價值的特征,同時使用選擇性注意力機制有針對性對字詞賦予不同的權值大小,提升模型在特征提取方面的準確率。
1 相關工作
傳統的關系抽取主要基于模式匹配和基于機器學習的研究,基于模式匹配的方法需要制定關系抽取規則,耗時耗力;基于機器學習的方法利用數據訓練算法,但是不能充分提取數據文本中的語義信息。 深度學習最重要的特點就是可以反向傳播學習,同時自動學習實驗數據中的特征。 將深度學習應用到關系抽取中是目前計算機領域的研究重點,主要以CNN、LSTM、循環神經網絡(Recurrent Neural Network, RNN)、雙向門控循環單元(Gate Recurrent Unit, GRU)等結構來展開。 Liu 等構造了一個由輸入層、卷積層、池化層及最后由Softmax 分類器輸出模型的分類結果的CNN 神經網絡結構,證明了CNN 在提取特征方面有良好的效果,并將其應用到自然語言處理領域;Zeng等人將CNN 應用到關系抽取過程中,同時提取了句子文本中的語義特征;Elman 提出了第一個全連接的RNN網絡結構后,Socher等將RNN 模型用于關系抽取領域,取得了階段性的進展。 但是RNN 在處理長的序列文本時同樣也帶來了嚴重的問題:梯度消失、梯度爆炸以及可能存在訓練時間過長的問題,由此提出了LSTM;Zhang 等人采用BiLSTM 模型結合文本的前后語義進行抽取,提升了模型的準確率。注意力機制的目標是以概率的形式對文本中的特征進行重要性的區分,Mnih 等將RNN、注意力機制與張量層相結合的關系抽取分類算法,有效提高了分類的結果;Cai 等以CNN 和LSTM 為基礎,設計使用雙向CNN,同時從兩個方向學習最短依存信息,取得了階段性新進展。
不同于英文領域存在大規模的ACE2004 實驗語料、NYT-FB 數據集等專業語料庫,受限于標準化語料庫的規模以及數量,中文關系抽取還存有很大的進步空間。 在中文領域中,生物醫療的應用尤為廣泛,文獻[11]提出一種基于雙向GRU 和CNN 相融合的雙層藥物關系抽取模型,在醫藥領域專門數據及DDIExtraction2013 中取得了75%的綜合測評率;文獻[12]在面對高密度分布的實體以及實體間關系的交叉互聯為電子病歷時,提出一種基于多通道自注意力機制的BiLSTM+多通道自注意力機制的神經網絡架構,1 值最高提升了23%;其他領域,如文獻[13]利用高質量的食品安全事件新聞文本完成領域內實體關系抽取工作;文獻[14]在社交媒體領域提出了一種基于注意力機制以及LSTM 的好友關系預測模型,實驗結果的準確率達到了77%;文獻[15]針對煤礦領域數據存在的術語嵌套、一詞多義等問題,基于BiLSTM 提出了一種端到端的聯合學習模型,提高了模型的訓練速度;文獻[16]根據老撾語料庫匱乏的特點,結合“硬匹配”和“軟匹配”的思想,提出了一種基于雙向長短期記憶網絡和多頭自注意力機制的軍事領域實體關系抽取方法,都取得了很好的實驗效果。
2 模型設計
本文提出了一個面向新興產業檢驗檢測領域的神經網絡架構模型,結構如圖1 所示。
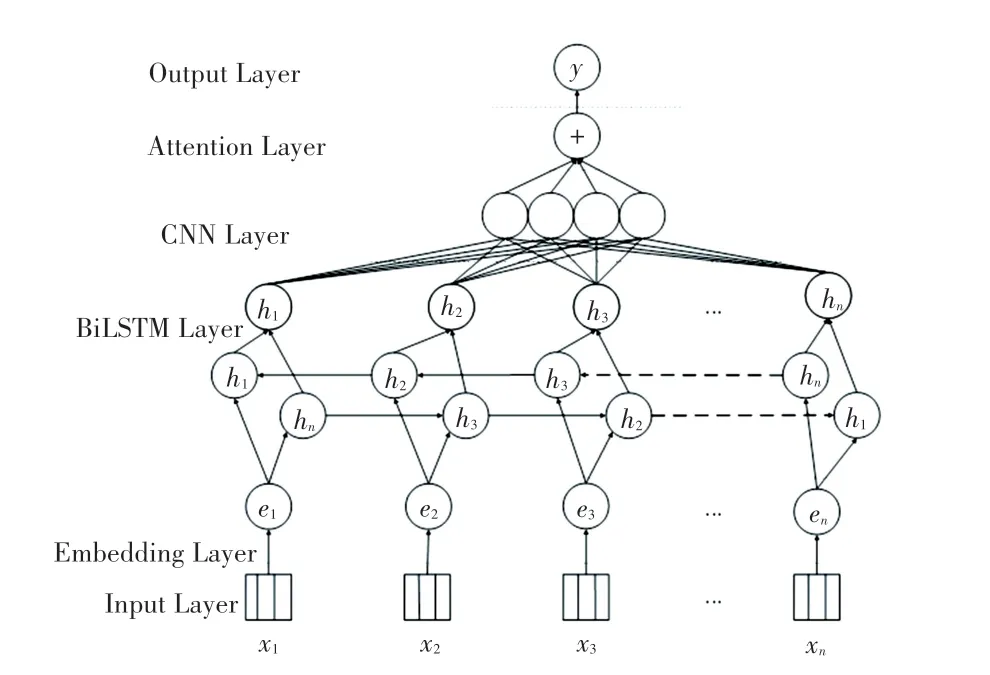
圖1 檢驗檢測神經網絡架構模型圖Fig.1 The architecture of detection neural network model
其核心流程如下:
(1)將數據文本中的字詞集合轉化為包含字詞信息、位置信息、標簽信息的向量表示;
(2)將獲取到的向量傳入由BiLSTM 和CNN 組成的深度神經網絡模型,深度學習每個關系的語義特征信息;
(3)使用注意力機制削弱無關特征的影響;
(4)將關系抽取轉化為分類任務,輸出分類結果。
2.1 輸入向量
輸入向量主要包括3 部分:詞向量,用來將檢驗檢測領域內的字詞轉化為向量表示;位置向量,根據文本中字詞相對于主實體的距離進行標記;標簽向量,根據句子中實體間關系的不同類別,設置相應的標簽向量。
2.1.1 詞向量
將實驗所用的領域文本{,,…,s}, 通過公式(1)將每個字詞s映射到低維的向量空間中,構建出每個字詞特征向量,然后對各個詞向量進行拼接,形成此次實驗的字詞向量,式(1)。

其中,w是通過Word2vec 得到的詞向量矩陣,v是詞s的one-hot 表示。
2.1.2 位置向量
在關系抽取領域,一般越是靠近實體的字詞越能準確的反映數據中實體之間的關系。 為了更準確的描述文本中主實體的關系,本文構建了位置向量p,分別從前后方向兩個不同的角度來表示每個字到實體間的距離,式(2)。

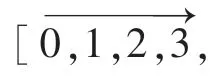

圖2 位置向量示意圖Fig.2 Position vector diagram
2.1.3 標簽向量化
針對事先定義好的幾種分類結果,分別建立相應的標簽,并轉化為向量的形式;最后,將標簽向量、字詞向量與位置向量拼接在一起形成本次實驗的輸入向量,如公式(3)所示。

2.2 神經網絡結構
2.2.1 BiLSTM
LSTM 能夠在有效利用長距離信息的同時解決RNN 存在的梯度消失或者梯度爆炸的問題,LSTM結構如圖3 所示。
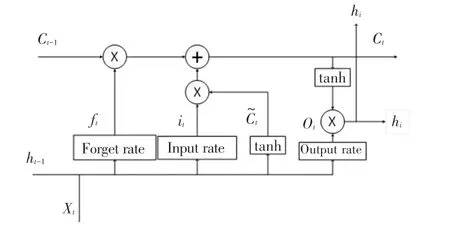
圖3 LSTM 結構圖Fig.3 LSTM structure diagram
LSTM 由遺忘門f、輸入門i和輸出門o以及一個記憶單元組成,其中遺忘門決定什么樣的信息應該被神經元遺忘,輸入門決定什么樣的信息應該被神經元輸入,輸出門決定什么樣的信息應該被神經元輸出,記憶單元用來管理和保存神經元中的參數信息,計算過程如式(4)~式(6)所示:
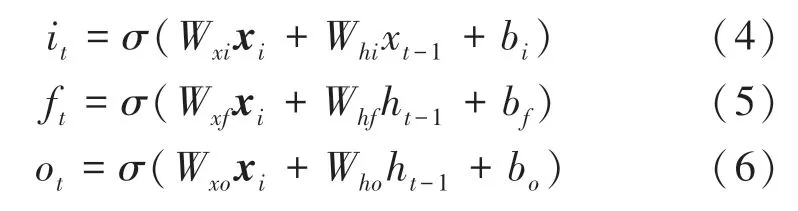
文本中的每個字詞都蘊含著重要的信息,使用BiLSTM 來獲取數據中的特征信息。 BiLSTM 均與輸出層相連,分別作用于文本的前后文信息,在長序列文本數據集上有很好的表現效果。
2.2.2 CNN
CNN 主要由輸入層、卷積層、池化層和Dropout組成,卷積層通過設置不同規模的卷積核提取檢驗檢測領域內不同的文字特征,且共享卷積核參數,公式(7)表示其特征的提取過程,得到特征集合(,,,…,f)。
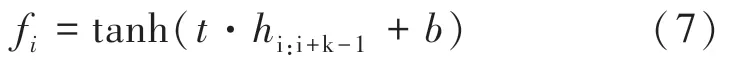
其中,表示偏差,tanh 為雙曲正切函數。
池化層通過對數據進行壓縮來實現數據和參數的降維,從而降低模型過擬合的概率,本次實驗采用最大池化方法,取f中最大的f,挑選最明顯的特征。全連接層主要是把分布式特征映射到樣本標記空間中,對之前提取到的特征進行分類。 Dropout 在訓練模型時按照一定的概率將一部分神經網絡暫時丟棄,不僅能防止模型過擬合還可以提高網絡的泛化能力。
在本次試驗中,通過雙向LSTM 神經網絡從前后兩個方向全面獲取數據文本的文本序列信息,然后將向量拼接傳入CNN 中,進一步提取文本中的關鍵特征。
2.2.3 注意力機制
將預測關系轉化為文本分類過程中,不同字詞發揮著不同的作用,使用注意力機制可以為數據中的字詞設置相應的權重,對分類起正向作用的字詞設置更高的權重,增強正向字詞的影響。 將BiLSTM與CNN 模型提取后形成的詞向量矩陣{,,…,c} 經過tanh 函數映射到[-1,1]之間,再將映射結果傳入softmax 函數,計算得到每個詞的注意力分數,最后對句子的各個單詞的編碼結果進行加權求和,其計算過程如式(8)~式(10)所示:
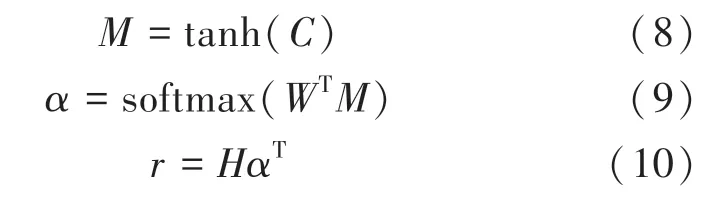
3 實驗結果與分析
3.1 實驗數據
在實驗之前,本文對新興產業檢驗檢測數據研究發現,領域內的文本實體數量相對復雜,以“無錫檢驗檢測中心的檢測業務包括節能環保、生物醫藥、新材料、新能源等重要領域”為例,全句共包含5 個實體,4 種檢測關系,其中無錫檢驗檢測中心同時對應著4 個不同的實體,其關系如圖4 所示,提升了關系抽取難度。
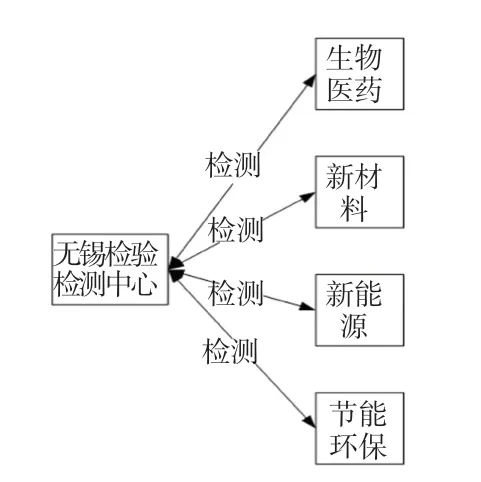
圖4 數據關系示意圖Fig.4 Data relationship diagram
本次實驗共選取1 800 條新興檢驗檢測語料,按照4 ∶1 的比例劃分為訓練數據與測試數據,其中訓練語料中包含7 192 個實體,測試語料中包括1 690個實體,共計8 882 個實體。 通過觀察發現,新興檢驗檢測行業能否達成合作的關鍵在于各檢測機構可以提供的檢測服務類型以及檢測機構的位置。基于此,本次試驗著重抽取“位置”、“檢測”兩大類的數據信息,關系示例見表1。

表1 關系示意表Tab.1 Relationship diagram
3.2 模型訓練與優化
為了使模型作用最大化,本文進行了一系列實驗來確定最合適的參數數值,包括詞隨機丟棄率、LSTM 隨機丟棄率、Attention 隨機丟棄率與學習率等,根據實驗結果,各參數的數值見表2。

表2 參數示意表Tab.2 Statement of parameters
實驗采用Adam 優化器來迭代更新神經網絡的參數,通過計算梯度的一階矩估計和二階矩估計為不同的參數設計獨立的自適應性學習率。 以交叉熵作為實驗的損失函數,熵是對不確定性的度量,交叉熵損失函數通過設置0 或者1 的類別標簽來顯示分類的類別結果,衡量正確值平均起來的不確定性。如果輸出的是期望的結果,不確定性就會小一點,交叉熵就越小,如公式(11)和公式(12)所示:
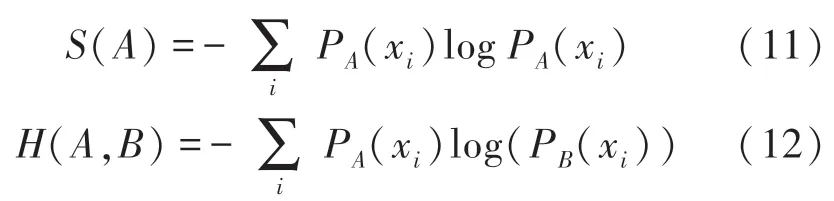
3.3 實驗結果
3.3.1 實驗結果
本文以平均準確率()、平均召回率() 以及1 值的大小來作為評價模型的標準。 在上述各參數的配置下,在迭代100 次以后,本次實驗的準確率、召回率以及1 值的結果如圖5 所示,可以看出,模型迭代次數從70 次開始逐漸收斂,模型各指標趨于穩定。
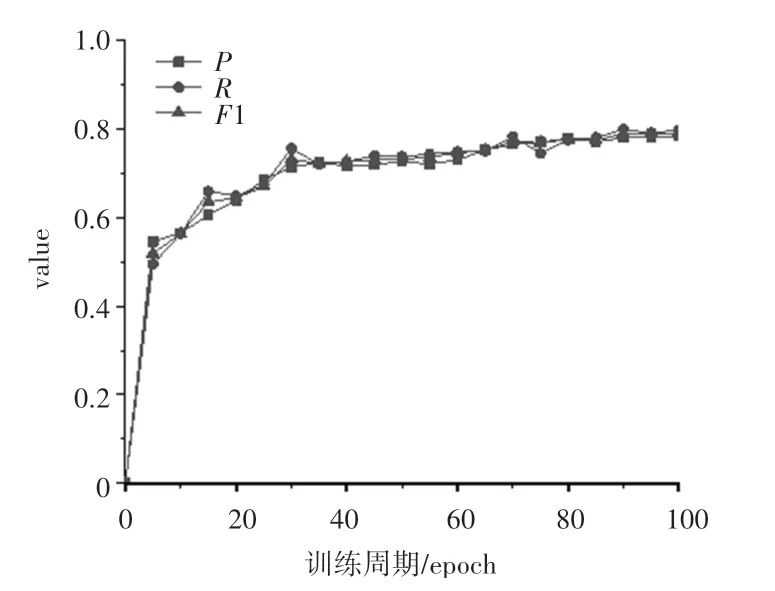
圖5 實驗結果Fig.5 Experimental results
3.3.2 輸入實驗對比
為了驗證本次實驗所提出的四層輸入的有效性,在本次實驗模型及相同的關系抽取模型的基礎上,與普通的輸入進行了實驗結果對比,見表3。 可以發現本文提出的四層輸入相較于普通的輸入,準確率、召回率以及1 值均有所提升,其中召回率與1 值都有19 個百分點的提升。

表3 結果對比Tab.3 Comparison of results %
3.3.3 實驗模型的選擇
分別 以BiLSTM +Attention 與LSTM +CNN +Attention 關系抽取為實驗對比模型,在新興檢驗檢測領域的數據上展開關系抽取實驗,結果見表4。
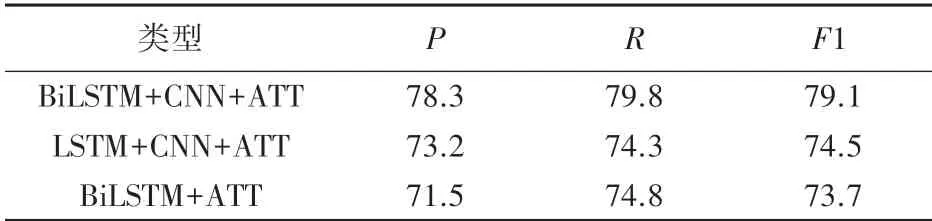
表4 結果對比Tab.4 Comparison of results %
由此,可以得出以下幾個結論:
(1)在同樣的實驗背景下,雙向LSTM 能夠兼顧前后兩個不同方向的信息,實驗準確率高于單向的LSTM;
(2)在同樣的實驗背景下,CNN 利用不同規模的卷積核分別提取實驗數據里的特征信息,在BiLSTM+ATT 模型的基礎上加入CNN 后實驗結果有小范圍提升;
(3)結合新興檢驗檢測數據具有文本序列長、語義混亂的特點,BiLSTM 能夠兼顧長文本中的序列信息,但由于實體密集,添加引入CNN 之后,通過設置卷積層能夠提取數據中豐富的特征信息,最后利用注意力機制為各特征賦予合適的權重,提升了模型整體分類的準確率。
3.3.4 在人物關系抽取數據集上的驗證
為了驗證本文所提出的實體關系抽取模型在其他領域的表現效果,選擇人物抽取數據集作為實驗對照組。 將百度公開人物關系抽取數據集經過處理轉化為本模型所需要的數據形式,共選取了十大類50 000條數據進行實驗,其中1 的損失率如圖6 所示。 在迭代100 次以后,結果逐漸趨于穩定,損失最低為21.4%,即1 值最高達78.6%,與本文取得的實驗結果差別不大。 相較于人物關系數據,無論是從文本的序列長度還是相同句子長度下所含有的實體數量,新興檢驗檢測數據都更為復雜,而這一點恰恰驗證了本文提出的模型在相同單位體量的數據集下處理復雜語句的能力。
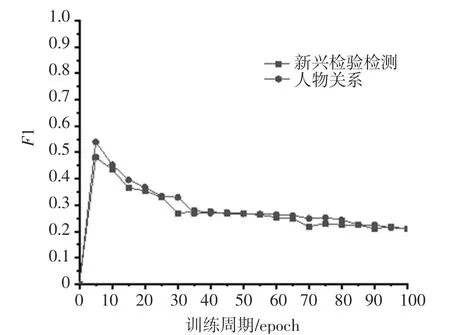
圖6 實驗對比結果Fig.6 Comparison of experimental results
4 結束語
在新興檢驗檢測領域內展開關系抽取可以發現機構可提供的檢測服務類型以及檢測機構的位置信息,能夠為后續機構之間的合作提供數據支持,加速機構之間的合作化進程。 根據新興產業檢驗檢測領域數據的特點,本文提出了一種將BiLSTM 與CNN 結合起來的領域關系抽取模型。 實驗結果證明LSTM在長序列文本中有較好的表現效果,對于特征混亂且多的句子,加入CNN 能顯著提升特征提取的效果。
未來,隨著深度學習的發展,NLP 領域內也會出現更多更簡潔、高效的關系抽取算法模型,也可以從模型自身及其他方面進行下一步有針對性的研究,如深入利用字詞之間的依存關系或在模型中加入最短依賴或進行遷移學習等等。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產業(2016年3期)2016-05-17 04:32:12
