基于深度學習+自學習的小盒外觀檢測系統
2022-05-11 23:31:28陳天麗柳盼汪魁謝茜
今日自動化 2022年3期
陳天麗 柳盼 汪魁 謝茜



[摘 ? ?要]針對目前傳統機器視覺方法配置參數繁瑣,操作復雜,存在誤剔或漏剔率偏高,及單一使用深度學習的方法檢測效率偏低等問題,文中提出了一種基于深度學習+自學習的卷包香煙外觀缺陷檢測系統。利用圖像增強、變換、濾波等方法對原始圖像進行預處理得到處理后圖像,后對處理后的圖像進行評估,選擇使用深度學習還是自學習的方法進行檢測。結果表明,基于深度學習+自學習技術的卷包香煙外觀缺陷檢測方法比使用傳統的機器視覺檢測方法,或單一深度學習檢測方法在檢測耗時、準確率、誤剔率的綜合性能上要優越,具有較強的實用價值。
[關鍵詞]機器視覺;缺陷檢測;深度學習;自學習
[中圖分類號]TM912 [文獻標志碼]A [文章編號]2095–6487(2022)03–0–05
Design of small box appearance defect detection system
based on deep learning + self-learning
Chen Tian-li,Liu Pan,Wang Kui,Xie Qian
[Abstract]In view of the cumbersome configuration parameters of the traditional machine vision method, the complicated operation, the high false or missed rejection rate, and the low detection efficiency of the single deep learning method,a method of appearance defects detection of cigarette box based on deep learning + self-learning is proposed. Use image enhancement, spatial filtering and other methods to preprocess the original image to obtain the processed image, and then evaluate the processed image, and choose whether to use deep learning or self-learning methods for detection. The results show that the cigarette box appearance defects detection system based on deep learning + self-learning technology is superior to traditional machine vision detection methods or a single deep learning detection method in terms of detection time, accuracy, and false rejection ,and has strong practical value.
[Keywords]machine vision;defects detection;deep learning;self-learning
在當前卷煙行業的包裝機生產中,小盒外觀檢測普遍采用機器視覺的方法進行檢測,機器視覺檢測方法又分為基于傳統圖像處理檢測方法及深度學習檢測方法,這兩種方法各有優缺點。例如使用傳統檢測算法,在對圖像尺寸測量和對一些特征較為明顯的固定區域進行檢測時,其檢準確率度及效率具有一定優勢,但是對圖像復雜特征的檢測效果卻不盡人意。而使用深度學習算法對圖像的一些復雜特征的檢測則具有較高準確率但其檢測耗時相對較長,效率不高。現行業中普片使用的方案是基于單一的傳統圖像檢測算法或是深度學習檢測算法,鮮有將這兩種算法的優勢融合在一起進行外觀檢測的方案,其檢測的綜合效果上還存在一定的不足。
傳統圖像檢測算法通常的做法是采集1張樣本圖片,然后使用閾值分割及形態學算法將缺陷特征篩選出來,這種做法的缺點是采集的樣本單一且需要人工將閾值調節到適合的值,其穩定性及可操作性不高。本文提出的自學習算法則是基于傳統的圖像檢測算的高層次封裝,通過采集多張樣本建立特征模型,可實現很好的檢測效果。近年來基于深度學習的方法發展迅猛,越來越多的科研人員及企業開始投入到深度神經網絡的研究中。根據深度神經網絡檢測框架的不同可以分為兩類:①基于候選窗口的網絡框架結構。這種網絡結構首先用設定的窗口在圖像上遍歷,選出概率較大的目標區域,然后在對所選區域進行預測。這類網絡結構的優勢是精度比較高,但檢測速度較慢,例如R-CNN、S PP-Net、Fast R-CNN、Faster R-CNN、R-FCN、Mask R-CNN等。②基于回歸的網絡框架結構。這種結構將檢測看成回歸問題,不需要計算候選區域,預測一步完成。這類框架檢測速度比較快,但在精度方面一般弱于基于候選窗口的網絡結構,例如YOLO系列、SSD、DSSD、FSSD、RetinaNet等。基于機器視覺的方法在工業檢測領域有著良好的應用背景。付斌設計的機器視覺技術在煙草包裝設備上的應用,該方案對單張樣本使用閾值分割確定閾值然后對缺陷特征篩選,其檢測效果對光照環境的依賴性較高,魯棒性不強。張文、林建南等人設計的基于機器視覺的卷煙污點面積測量系統,該系統使用傳統的圖像算法,檢測速度快,精度高,但其檢測的缺陷特征簡單,滿足不了卷包多種缺陷類型及復雜特征的缺陷檢測。陳智斌、農英雄、梁冬等人提出了基于深度學習的卷煙牌號識別方法,該方法使用CenterNet檢測算法,在檢測準確率及模型的魯棒性取得了很好的效果,但是該方法不能兼容卷包檢測中的一些測量性質的檢測需求。為了滿足卷包外觀多種缺陷的檢測需求,同時在檢測的準確率、效率及算法的穩定性上達到最優的性能,本文設計1種基于深度學習+自學習技術的小盒煙包缺陷檢測系統。
1 系統組成
基于深度學習+自學習的小盒外觀缺陷檢測系統包含硬件設計和檢測算法設計兩個主要模塊,其中檢測算法又包含深度學習檢測算法和自學習檢測。
1.1 硬件單元設計
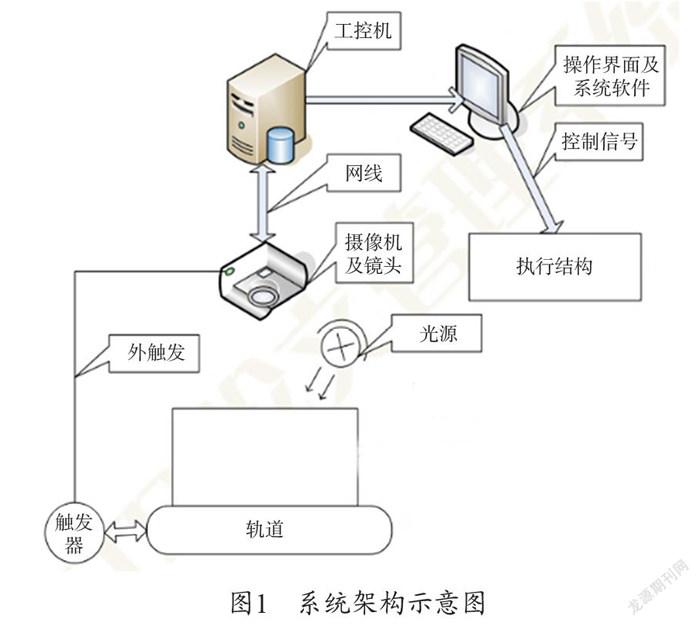
本系統是由鏡頭、光源、工控機、工業CCD、光電傳感器、圖像處理軟件及執行機構等部分組成,系統的整體架構如下圖1所示。系統設計的原理是小盒煙包運動到光電傳感器的位置觸發相機拍照,相機將采集到的煙包圖像數據通過千兆網傳送給工控機,然后圖像處理軟件通過本文設計的算法對采集到的煙包圖像做缺陷檢測,當檢測到缺陷時,檢測程序會通過工控機輸出剔除信號通知執行機構執行剔除動作。
1.2 檢測算法設計
系統的檢測算法是通過深度學習+自學習的方案來實現,根據小盒外觀的缺陷類型及背景的復雜程度來決定是使用深度學習檢測方法還是自學習檢測方法。檢測算法流程圖如圖2所示。
1.2.1 深度學習模塊
在深度學習檢測模塊中,本文采用的是1種改進的深度可分離的YOLO v5檢測算法,相對于未改進的YOLO v5算法在參數量和模型大小上有明顯的優勢,在檢測的mAP(均值平均精度)也有提升。
(1)YOLO v5。YOLO v5算法使用1種殘差神經網絡(Darknet-53)作為特征提取層,在花費更少浮點運算和時間的情況下達到與ResNet-152相似的效果。在預測輸出模塊,YOLO v5借鑒FPN(Feature Pyramid Network)算法思想,對多尺度的特征圖進行預測,其結構示意圖如圖3所示。
(2)深度可分離卷積。傳統的卷積算法在做計算時,每次參數的更新迭代都會對所有通道的對應區域進行計算,這就使得在卷積計算過程中需要涉及大量的模型參數和更多的浮點運算。而深度可分離卷積則是通過分組卷積的設計(每個通道作為一組),即先對每個通道的對應區域進行卷積運算,然后再在通道間進行信息交互,從而達到了將通道內卷積和通道間卷積分離的目的。
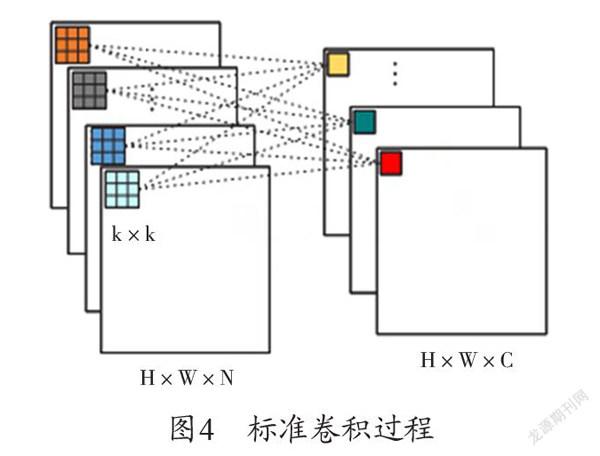
假設在傳統卷積網絡算法中,其輸入圖片的尺寸為H×W×N(H代表圖片的高,W代表圖片的寬,N代表圖片的通道數)與C個尺寸為k×k×N(k×k代表卷積核的高和寬,N代表卷積核的通道數)的卷積核進行卷積運算時,其輸出特征圖的尺寸為H×W×C(padding=floor(k/2),stride=1)。在不考慮偏置(bias)的情況下,所需參數量為N×k×k×C,計算復雜度為O(H×W×k×k×N×C),卷積過程如下圖4所示。
在深度可分離卷積中,是將卷積過程分為深度卷積(Depthwise Convolution)和逐點卷積(Pointwise Convolution)兩個部分。在深度卷積中,用尺寸大小為k×k卷積核對輸入的同一通道類進行卷積運算,提取到的是1個通道內的特征信息,其參數量為N×k×k,計算復雜度為O(H×W×k×k×N),深度卷積不進行通道間的信息融合。逐點卷積則是利用C個尺寸大小為1×1×N的卷積核對通道間的信息進行融合,在實現通道間信息交互的同時可調控通道數量,其參數量為N×1×1×C,計算復雜度為O(H×W×1×1×N×C),卷積過程如下圖5所示。
以3×3的卷積核為例,經過改進的深度可分離卷積網絡所需的參數量僅約為傳統卷積網絡的1/9,并且運算量也降到約為原來的1/9,在不犧牲算法準確率的情況下降低了計算開銷,提升了算法效率。
1.2.2 自學習模塊
在自學習的缺陷檢測算法中,通過學習正樣本的特征建立起缺陷檢測模型,可精確檢測出煙包常見的缺陷。在實際使用中還可將誤剔的煙包圖像動態地添加到正樣本圖片中,實時優化模型。這種通過學習正樣本圖像特征的自學習算法,無論是檢測準確性還是操作的方便性,相對于傳統的基于單張圖片的檢測算法都具有無法比擬的優越性。自學習檢測方法通過學習若干正樣本的圖像,建立器基于像素點的檢測模型,在檢測模型中計算出樣本圖像像素點的平均值及標準偏差。
像素點平均灰度計算公式:
M(x,y)=[P1(x,y)+P2(x,y)+……Pn(x,y)]/n (1)
像素點灰度標準偏差計算公式:
V(x,y)=sqrt(((P1(x,y)-M(x,y))2+(P2(x,y)-M(x,y))2+……(Pn(x,y)-M(x,y))2)/(n-1)) (2)
樣本檢測模型建立好之后,可以用此模型來檢測煙包的缺陷,對于新輸入的一張煙包圖片,其檢測算法流程如下。
(1)設置參數絕對閾值AbsThreshold和相對系數閾值VarThreshold。
(2)計算允許正常灰度值的最大值與最小值。
最大值:Gmax(x,y)=M(x,y)+max {AbsThreshold,VarThreshold*V(x,y)} ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (3)
最小值:Gmin(x,y)= M(x,y)-max{AbsThreshold,VarThreshold*V(x,y)} ? (4)
(3)將當前值C(x,y)與Gmax(x,y),Gmin(x,y)做對比,滿足如下條件的像素點將被檢測為缺陷點:
C(x,y)>Gmax(x,y) U C(x,y)<Gmin(x,y) (5)
2 實驗與分析
2.1 試驗設計
操作系統:Window10系統
硬件環境:CPU型號為Inter(R) Core(TM) i7-8700;主頻為3.2 GHz安裝內存為16 GB;深度學習框架是Tensor flow1.14;顯卡配置為1塊 Nvidia GeForce RTX 2080 Ti,顯存為11 GB。具體實驗環境見表1。
數據集選用武漢卷煙廠黃鶴樓軟藍的煙包圖像,圖像原始分辨率為640*480。該數據集中包含正常圖片及漏煙、封簽歪斜、邊口炸裂、邊角折疊4種常見的缺陷圖片(圖6所示),缺陷圖像使用Labimg進行標注。實驗時共選用16933圖片進行測試,其中正常圖片5124張,漏煙圖片2955張,封簽歪斜圖片2933張,邊口炸裂圖片2980張,邊口折疊圖片2941張。具體實驗數據見表2所示。在實驗中,將圖像裁剪成512*512的大小并輸入到骨干網絡,批量大小(batch size)設置為8,學習率設定為0.000125,并使用數據增強來提高模型的泛化能力,共訓練100個epoch。
在自學習模塊中采集正樣本圖片200張,設置絕對閾值AbsThreshold=20,相對系數為VarThreshold=2。
2.2 實驗結果與分析
單一使用深度學習網絡對數據集中的幾種類型圖片進行測試,其準確率、誤剔率、平均耗時如表3所示。
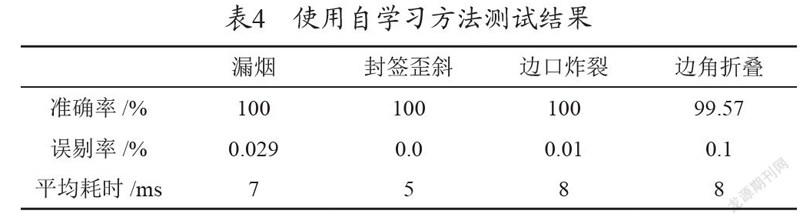
單一使用自學習的方法對數據集中的幾種類型圖片進行測試,其準確率、誤剔率、平均耗時如表4所示。
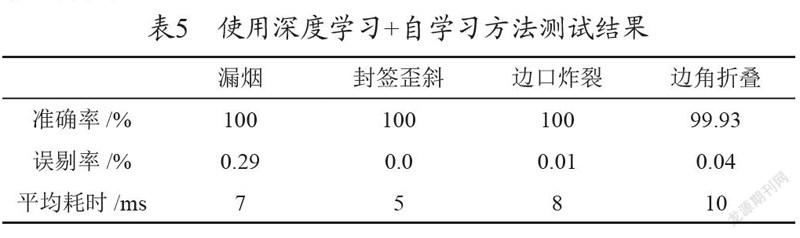
使用深度學習+自學習的方法對數據集中的幾種類型圖片進行測試,其準確率、誤剔率、平均耗時如表5所示。
由上表測試數據可得出:
(1)封簽歪斜這種缺陷,使用深度學習的方法檢測效果并不理想,其準確率僅為96.57%,誤剔率為0.11%,而使用自學習的方法準確率可達100%,誤剔率0.0%。
(2)對于邊角折疊這種缺陷,由于存在鐳射過曝與折疊的白色區域在灰度和形態上存在一定的相似性,這種使用自學習方法在準確率和誤剔率指標上沒有使用深度學習網絡檢測的效果好。
(3)對于封簽歪斜缺陷,使用傳統測量這種定量方法進行檢測效果更好;對于邊角折疊這種缺陷,使用擅長模糊檢測的深度學習網絡來做檢測更合適。
結論:使用深度學習+自學習的方法可以充分結合出兩種檢測方法的優勢,其綜合檢測效果要優于單一使用深度學習檢測方法或單一使用自學習檢測
方法。
3 結語
本文提出了一種基于深度學習+自學習的方法來檢測小盒外觀表面缺陷。根據小盒外觀的缺陷類型及缺陷背景的復雜程度,來分配使用深度學習方法檢測或使用自學習方法檢測,可以充分結合兩種檢測方法的優勢,使其綜合檢測效果要優于單一使用深度學習方法或單一使用自學習的方法。在后續的研究中,研究的重點將集中在決策模塊的開發,使其能根據缺陷類型及背景的復雜程度自動選擇使用深度學習的方法或自學習的方法進行檢測。
參考文獻
[1] 李煒,黃心漢,王敏,等.基于機器視覺的帶鋼表面缺陷檢測系統[J].華中科技大學學報(自然科學版),2003,31(2):72-74.
[2] LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7533):436-444.
[3] IGLOVIKOV I,SEFERBEKOV S,BUSLAEV A,et al.TernausNetV2:Fully convolutional network for instance segmentation[C].2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.2018:233-237.
[4] 姚群力,胡顯,雷宏.深度卷積神經網絡在目標檢測中的研究進展[J].計算機工程與應用,2018,54(17):1-9.
[5] GIRSHICK R,DONAHUE J,DARRELLAND T,et al.Rich feature hierarchies for accurate object detection andsemantic segmentation[C].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.2014:580-587.
[6] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis & Ma-chine Intelligence,2015,37(9):1904-1916.
[7] GIRSHICK R.Fast R-CNN[C].IEEE International Conference on Computer Vision.2015:1440-1448.
[8] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[C].International Conference on Neural Information Processing Systems,2015:91-99.
[9] CHEN X L,GUPTA A.An implementation of faster R-CNN with study for region sampling[J].arXiv:1702.02138,2017.
[10] DAI J F,LI Y,HE K M,et al.R-FCN:Object detectionvia region-based fully convolutional networks[J].Computer Vision and Pattern Recognition,2016,20:379-387.
[11] HE K M,GKIOXARI G,DOLL R P,et al.Mask R-CNN[C].IEEE International Conference on Computer Vision,2017:2980-2988.
[12] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:Unified,real-time object detection[C].IEEE ?Conference on Computer Vision and Pattern Recognition,2016:779-788.
[13] REDMON J,FARHADI A.YOLO9000:Better,faster,stronger[C].IEEE Conference on Computer Vision and Pattern Recognition,2017:6517-6525.
[14] REDMON J,FARHADI A.YOLOv3:An incremental improvement[C].IEEE Conference on Computer Vision and Pattern Recognition,2018:89-95.
[15] LIU W,ANGUELOV D,ERHAN D,et al.SSD:Single shot multibox detector[C].European Conference on Computer Vision,2016:21-37.
[16] FU C Y,LIU W,RANGA A,et al.DSSD:Deconvolutional single shot detector[J].arXiv:1707.06659,2017.
[17] LI Z,ZHOU F.FSSD:Feature fusion single shot multibox detector[J].arXiv:1712.00690,2017.
[18] LIN T Y,GOYAL P,GIRSHICK R,et al.Focal loss for dense object detection [C].Proceedings of the IEEE International Conference on Computer Vision,2017:2980-2988.
[19] 陳治杉,劉本永.基于機器視覺的晶圓表面缺陷檢測[J].貴州大學學報(自然科學版),2019,36(4):68-73.
[20] 姚明海,陳志浩.基于深度主動學習的磁片表面缺陷檢測[J].計算機測量與控制,2018,26(9):29-33.
[21] 魏若峰.基于深度學習的鋁型材表面瑕疵識別技術研究[D].杭州:浙江大學,2019.
[22] 高欽泉,黃炳城,劉文哲,等.基于改進CenterNet的竹條表面缺陷檢測方法[J].計算機應用:1-8[2021-03-10].
[23] LIN T Y,DOLLáR P,GIRSHICK R,et al.Feature pyramid networks for object detection[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE,2017:936-944.
猜你喜歡
電腦知識與技術(2016年28期)2016-12-21 12:13:14
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
科技視界(2016年26期)2016-12-17 17:31:58
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
科教導刊(2016年25期)2016-11-15 17:53:37
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:55:22
軟件工程(2016年8期)2016-10-25 15:47:34
