基于BERT的《中圖法》文本分類系統及其影響因素分析
2022-05-10 07:58:02姜鵬
圖書館研究與工作 2022年5期
姜 鵬
(上海圖書館 上海 200031)
《中國圖書館分類法》(原稱《中國圖書館圖書分類法》)是新中國成立后編制出版的一部具有代表性的大型綜合性分類法,是當今我國圖書館使用最廣泛的分類法體系,簡稱《中圖法》[1]。長久以來,《全國報刊索引》基于《中圖法》的文獻分類工作主要依靠人工進行,但有限的人工標引目前已很難應對爆炸式增長的文獻,迫切需要引入文本分類系統以增加文獻標引量。
1 文本分類調研
文本分類一直是自然語言處理任務中的一項基礎工作,是指機器按照一定的分類規則或者標準自動對文本進行類別標記的過程,其目的是對文本資源進行整理和歸類[2]。文本分類一般包括傳統的分類方法和基于深度學習的分類方法。典型的文本分類算法包括支持向量、循環神經網絡、卷積神經網絡等。侯漢清等人以《中圖法》為主干體系,分類號—關鍵詞串對應表為知識庫主題,構建了基于《中圖法》的文本分類系統[3];孫雄勇等人利用CNKI已人工標注的期刊數據,采用基于詞典的方法,構建含有詞條、分類號、權值等信息的特征短語詞典,實現了基于中圖法的自動分類模型[4];郭利敏利用《全國報刊索引》數據,通過TensorFlow平臺上的深度學習模型,構建了基于題名、關鍵詞的自動分類模型,其一級準確率為75.39%,四級準確率為57.61%[5]。
2018年10月,GOOGLE公司發布了一種基于雙向Transformer[6]編碼器的自然語言處理模型BERT(Bidirectional Encoder Representation from Transformers)[7],并刷新了11項自然語言處理任務的精度,引起了廣泛的重視[8]。Adhkari A等人首次將BERT用于文本分類,通過對BERT模型進行微調以獲取分類結果,并證實BERT在文本分類中依然可以取得較好的結果[9];SUN C等人在8個數據集上進行BERT在文本分類的應用,并介紹了一些調參及改進的經驗,進一步挖掘了BERT的潛力[10];趙旸等人以34萬篇中文醫學文獻摘要為預訓練語料,通過構建BERT的中文基礎模型(BERT-Base-Chinese)和BERT中文醫學預訓練模型(BERT-Re-Pretraining-Med-Chi),對R大類下16個類別的中文醫學文獻進行分類研究[11];呂學強等人在BERT的基礎上,提出了TLA-BERT模型,用于解決多標簽文本分類問題[12];羅鵬程等人通過構建基于BERT和ERINE的文獻學科分類模型,實現文獻的教育部一級學科自動分類[13]。
為了解基于《中圖法》的文本分類系統實際應用情況,筆者在文獻調研的基礎上,走訪了同方股份有限公司(以下簡稱“同方”)、北京萬方數據股份有限公司(以下簡稱“萬方”)等數據庫廠商,并調研了拓爾思信息技術股份有限公司(以下簡稱“拓爾思”)、云孚科技(北京)有限公司(以下簡稱“云孚科技”)等涉及文本分類方面業務的商業公司。調研結果如下:
(1)同方、萬方都有專門從事基于《中圖法》的文本分類人員,且都開發出相應的文本分類系統并投入使用。其中同方采用傳統的分類方式,可以做到30%以上的分類結果不需要人工校對。
(2)拓爾思、云孚科技等商業公司雖然對《中圖法》不熟悉,但具有類似文本分類系統開發經驗,傾向采用深度學習方法。本次調研選取了《中圖法》經濟類(F類)約75萬條數據分別委托進行測試,測試準確率(分類層級控制在四級以內)均能達到70%以上。
(3)本次還調研了中國醫學科學院信息研究所。得益于長期的數據、詞表積累,中國醫學科學院信息研究所采用傳統分類方法對醫學類文獻進行分類,中文標引系統的正確率約為80%,西文標引系統的正確率大約為78%。
2 基于BERT的文本分類結果及分析
《全國報刊索引》擁有專門從事文本分類工作的隊伍,在2004年和南京農業大學侯漢清教授團隊合作,研發出基于《中圖法》的文本分類系統并投入使用,同時不斷跟進自然語言處理技術的發展,先后嘗試貝葉斯、最近鄰算法、Tensorflow、BERT等方法用于文本分類。本文采用BERT-Base(Chinese)為例,闡述目前所遇到的難點以及對應解決思路。
2.1 BERT原理
BERT在雙向transformers的基礎上,通過預訓練(Pre-training)和微調(Fine-turning)兩個過程來完成自然語言處理任務。其預訓練階段包括兩個任務:隨機掩碼機制(Masked language model,MLM)和上下句預測(Next Sentence Prediction,NSP)。其中的MLM任務中,BERT會隨機遮擋住15%的詞語,用“[MASK]”代替,并通過不斷的迭代來預測這部分詞語,以此學習語義和句法信息。為了使模型更加穩定,在隨機的15%的詞語中,有80%的概率會用 “[MASK]”替換,有10%的概率會替換為隨機的單詞,有10%的概率不做任何替換。NSP任務用以判定輸入的兩段語句是否連續,從語料庫中隨機選擇50%的正確語句對和50%錯誤語句對進行訓練,這一任務可以從任何的單語料庫中生成。MLM與NSP任務相結合,可以更好地刻畫語句甚至篇章層面的整體信息,為微調任務提供更好的初始參數值。
BERT模型的輸入如圖1所示,輸入層通過詞向量(Token Emmbeddings)、段向量(SegmentEmbeddings)以及位置向量(Position Embeddings)三部分求和組成,且在每個句子首位加入“[CLS]”和“[SEP]”標志,其中[CLS]對應的輸入向量可用于文本分類任務。
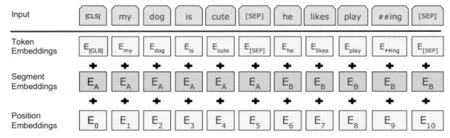
圖1 BERT模型輸入示意圖[7]
2.2 基于BERT的中文文本分類
本文主要使用BERT-Base-Chinese進行基于《中圖法》的中文文本分類。樣本數據的選擇方面,本文選取《全國報刊索引》篇名庫所收錄的2008—2019年發表并經人工標引的核心學術期刊數據,其中僅包含題名、關鍵詞、摘要、來源、作者信息等索引信息,并沒有全文。經《中圖法》四、五版類號轉換、錯誤分類號剔除等清洗工作后,訓練數據總量400余萬條(2008—2018年收錄數據),測試數據近24萬(2019年收錄數據)。
分類深度方面,由于目前受限于人工標引效率、學者研究熱點等客觀因素的影響,各數據量分布不均勻。以《全國報刊索引》所收錄的F類數據為例,涉及分類號26 202個,數據量超過500條的類目僅有20個,84%的類目(21 980個)對應數據量不到10條。更甚者,2008年至今所收錄的數據,F02(前資本主義社會生產方式)及其下位類中,僅有8篇文獻,且均集中在F023(封建社會)類。為保證訓練數據量,本文將單類層級限定在《中圖法》第四級。
為了驗證BERT模型分類效果,本文首先在F類進行對比測試。將BERT與TEXT-CNN(Convolutional Neural Networks)、LSTM(long-short term memory)、百度飛槳等模型進行對比測試,除百度飛槳模型測試結果在10%至60%之間徘徊,不具有參考性,未將其列出外,其余結果如表1所示。通過對比結果可以看出,BERT模型分類測試結果要優于TEXT-CNN等模型,可進一步進行全類測試。
在進行全類標引測試前,首先根據實際工作需要,對《中圖法》基本大類進行微調。《中圖法》共5個基本部類,22個基本大類,目前總類目5萬余個[14]。本文將D9(法律)以及T(工業技術)大類下二級類目,如TB(一般工業技術)、TD(礦業工程)等均作為一級類目處理,并去除Z大類,調整后共有38個基本大類。
具體分類思路,首先實現38個一級類目的自動分類,然后進行四級類目自動分類。輸入結果方面,根據之前測試結果發現,雖然輸出多個分類號(一般是前三個)時,系統準確率較高,但在實際工作中,標引人員僅給出最接近文獻內容的一個分類號,為了更貼切工作需要,本文僅輸出閾值最高的分類號。性能指標的選取方面,需要的是系統較高的準確率,以減輕人工工作量,經綜合考慮,本文僅采用了準確率這一指標。模型主要參數設定為批訓練大小(train_batch_size)為32;批預測大小(predict_batch_size)為32;學習率(learning_rate)為3e-5。一級類目測試結果如表2所示,準確率最高為97.41%,最低為52.05%。社科一級類目(A—K)平均分類準確率為88.65%,且大部分類目準確率在90%以上;而科技類目(N—X)平均分類準確率在78.12%左右,略低于社科類目。四級類目測試中,本文選取了一級類目準確率較高的四個類目:F(經濟)類、J(藝術)類、R(醫藥、衛生)類以及TG(金屬學與金屬工藝)進行后續測試,測試結果如表3所示。
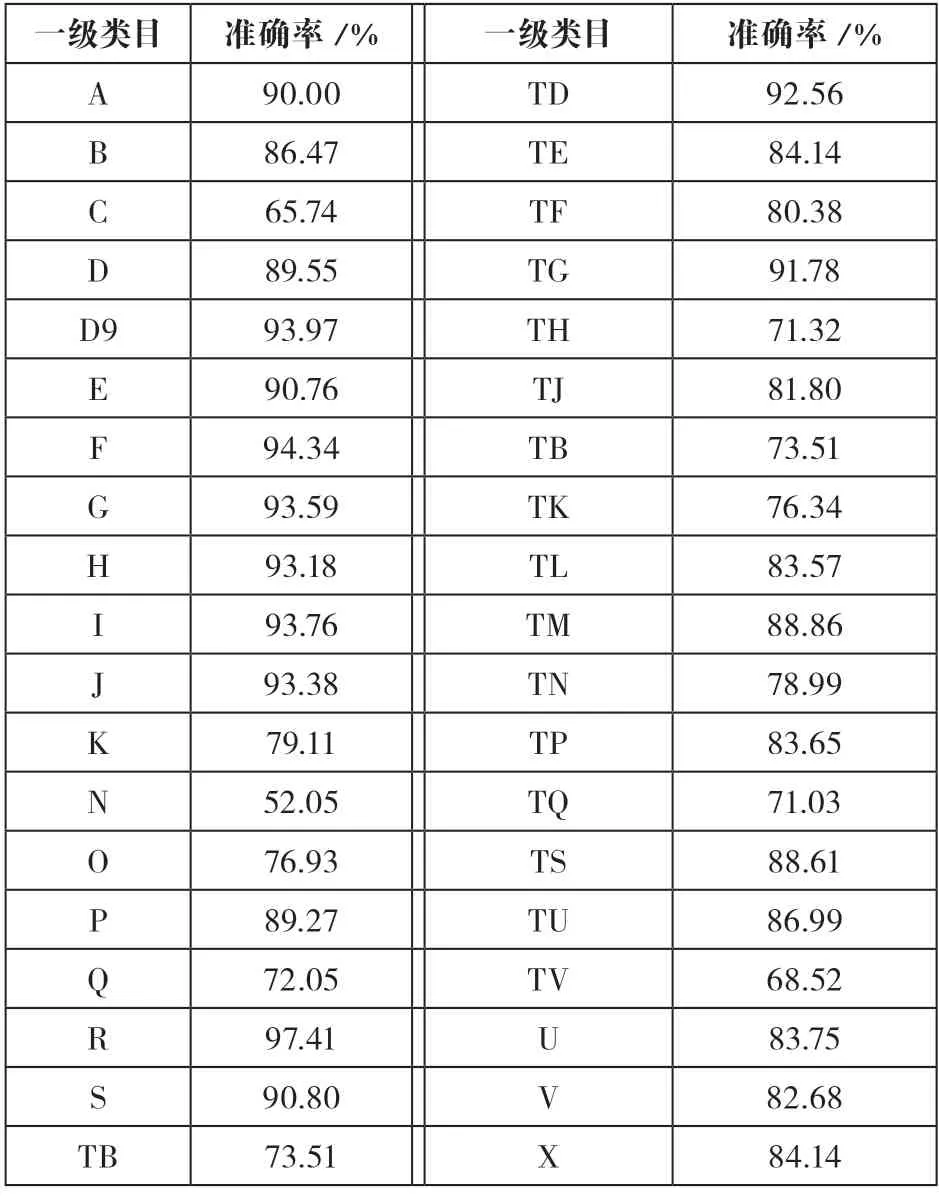
表2 各一級類目分類準確率
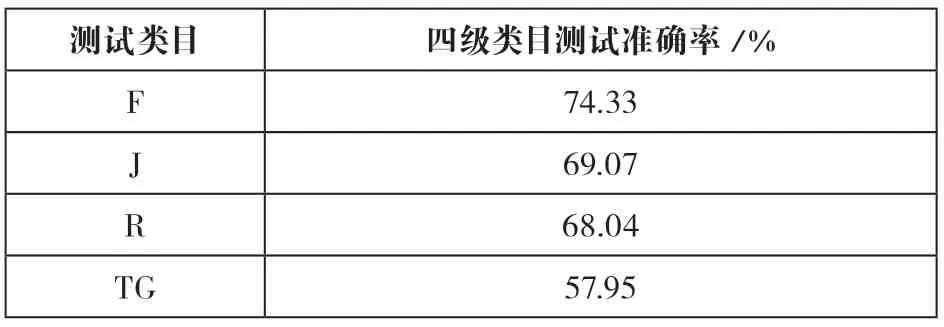
表3 F、J、R、TG類目測試結果
2.3 測試結果及難點分析
通過測試發現,一級類目準確率較高的類目主要集中在專指度較高,與其余類目交叉內容較少的類目。后經標引人員分析,此部分類目相對O(數理科學和化學)、P(天文學、地球科學)等類目而言,對標引人員專業知識背景要求相對較低。C(社會科學總論)和N(自然科學總論)在沒有通覽全文的情況下,很難準確入類,這點也可在表1中反映出來,實際工作中,這兩類數據全部需要進行人工復驗。I大類(文學)雖然主要以文學作品體裁作為主要立類依據,系統難以判定,但由于《全國報刊索引》所收錄的學術文獻主要屬于相關文學評論,內容相對集中,系統分類準確率較高。
四級類目測試方面,通過閾值篩選可有效地將一部分標引結果設置為免檢,無需再次人工標引。目前免檢率最高為F類,在閾值大于0.9999的情況下,分類準確率可達到92.77%,所涉及數據占測試數據總量的38%。具體數據如表4所示。
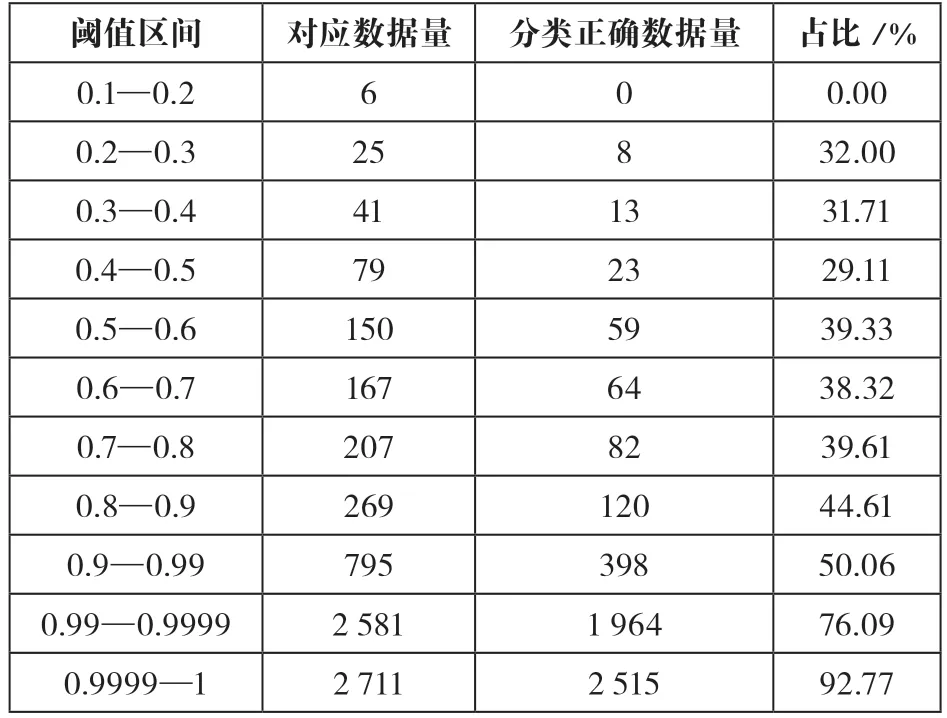
表4 F大類測試結果分析
中文文本分類,一般包括預訓練、待分類預處理、特征提取、分類等步驟[15]。影響文本分類的因素有訓練數據集質量、數據分布、輸入文本質量等[16]。為提高分類準確率,本文在前人基礎上,分析BERT環境下影響分類質量的因素,調整測試方案,并提出解決對策。
2.4 《中圖法》對分類準確率的影響
《中圖法》本身是一個詳盡且有巨大容納力的類目系統,其基本類目高達四萬多個。同時《中圖法》廣泛采用了類目復分、仿分、組配等方法增強文獻的分類能力,這就造成了類號數量的不可控制性。同時這也導致同一大類不同下位類間、相近主題間區分度小,給機器分類帶來極大困難。
《中圖法》對類目進一步進行劃分時,如涉及總分標準時,通常把類目劃分為兩大部分,第一部分是總論性或理論性類目,第二部分是專論性或具體性類目,遵循能入具體問題、事物的類目,不入總論性或理論性類目的原則。此外,社科一級類目(A—K)劃分時,國家和時代成為這部分類目下重要分類標準,以D大類(政治、法律)為例,下設D5(世界政治)、D6(中國政治)、D73/77(各國政治),D6下又設D67(地方政治)。系統在區分總論或專論以及“世界”—“中國”—“各國”及“地方”時很容易判斷錯誤。以“高收入者個人所得稅國外征管經驗及對我國的啟示”為例,其側重點在于對我國的啟示,應放入F812中國財政,而系統將其劃入F811世界財政。
部分類目類名相同或接近,系統難以從數據中獲取區分因素。如H2(中國少數民族語言)下設“朝鮮語”(H219),而H5(阿爾泰語系)下同樣含有下位類“朝鮮語”(H55),按《中國圖書館分類法第五版使用手冊》(以下簡稱《使用手冊》)中的說明“外國出版的與我國少數民族文字相同的語文著作入各語系的具體語言、文字”[17],這給機器的理解帶來很大困難。另外,如J51(圖案設計)下設J516(各種圖案設計)、J519(其他)類目,如何準確區分這三個類目之間,尤其是“各種”和“其他”的區別,對系統而言是個考驗。
類目更新緩慢,《中圖法》第五版2010年9月第一次出版,截止到2021年,共發布過9次修訂信息,最近一次修訂為2019年8月正式發布[18],修訂速度落后于技術或時代的發展。同時還存在《中圖法》與《使用手冊》描述不一致的情況,如“國際商務英語”《中圖法》建議入“F7-43”,而《使用手冊》建議入“F74-43”。
2.5 提高分類準確率對策
(1)提高訓練數據質量。文獻分類是一項相對主觀的工作,對標引人員有較高的要求,且并沒有嚴格的標準答案。標引人員知識背景的不同、對文章內容理解的差異、對分類規則應用角度的不同,均可能造成分類結果的不同。對測試結果進行人工抽樣分析發現,由于主觀性因素導致的模型分類準確率誤差在±1%—4%之間。為進一步測試數據質量對分類結果的影響,本文在F類訓練數據中混入部分低質量數據,這部分數據主要為僅含題名數據以及分類結果錯誤數據,占訓練數據總量的15%。測試結果對比顯示分類準確率下降約3%。
為提高訓練數據質量,將導入模型的F類訓練數據進行自動分類,后將機標閾值在0.5以下的數據從訓練數據庫中清除,重復4遍后,將清洗后的數據對模型重新進行訓練,測試結果平均準確率提升至81.2%,提升幅度為2.76%。后續擬采用訓練數據清洗與交叉驗證并行的方法來提高訓練數據質量。
(2)平衡數據分布。由于研究熱點等客觀因素,各類目間數據量差異較大。為測試數據量對測試結果的影響,本文在F大類上進行兩組試驗:一是在訓練集中刪除數據量在8 000以上的類目,并在測試集中刪除對應類目,測試結果顯示剩余類目分類準確率基本沒有變化。二是在訓練集中刪除數據量在500以下的類目,并在測試集中刪除對應類目,測試結果顯示剩余類目分類準確率基本沒有變化。
《中圖法》為了保證實用性,根據文獻分類的需要,采用多種方法對類目進行劃分。最典型的在于法律類目采用雙標列類(D9以及DF類),同時規定“各館可根據各自的性質、特點,選擇使用”。此外,交替類目、專類復分表、類目仿分設置、冒號組配法是否使用等,各館所或數據提供商使用標準并不統一,這也導致不同來源的數據需要花費大量人工進行處理后才可以使用。在標引人員有限的情況下,本文無法通過引入外部數據的方式來測試小樣本數據量的提升對分類準確率的影響,后續擬采用基于馬氏距離的適應性過采樣方法增加小樣本數據量[19],以期待獲取更好的分類結果。
(3)提高輸入文本質量。影響標引結果的重要一方面為文中關鍵信息理解不當,主要表現在以下幾個方面:一是一些專指度較高的詞語、國名、縮略詞,如“一帶一路”“土耳其”等,系統無法識別。針對此情況,本文將漢語主題詞表中相關術語詞添加到自定義詞典中,并在F大類中進行測試,測試結果并無明顯的提升。二是主要因素理解錯誤,以“民用航空器客艙物體表面消毒效果評價”一文為例,其描述重在“消毒”,應分到R187(消毒),而非系統理解的R851(航空航天衛生學)。針對此種情況,本文擬參考N Poerner等人思路[20]引入知識圖譜作為輔助信息,以增強文獻主題權重。目前這項工作僅在R54(心臟、血管疾病)類中進行測試,準確率提升較為明顯,但其通用性需進一步驗證。
針對多主題文獻,《中圖法》將其劃分為并列關系、從屬關系、應用關系等,并說明了對應分類規則。但對錯誤數據分析發現系統對重點內容以及規則的判定結果不理想,如“美歐服務貿易自由化對中國經濟的影響及對策”,“服務貿易”和“中國經濟”是“A對B的影響”, 按規則“一個主題對另一個或多個主題影響另一主題的文獻,分入受影響主題所屬類目”,應入F12(中國經濟),而不是機器分類的F752(中國對外貿易)。人工分析原因可能是文本預處理時將關系指示詞,如“對”等作為停用詞刪除。為驗證BERT環境下分詞是否對分類結果有影響,本文以F類進行了對比實驗,發現未進行預處理的情況下,模型分類準確率下降約1%。本次測試中,字長選取128,為測試輸入內容對分類結果的影響,將字長分別調整為256和512,重新進行測試,測試結果略有提升,幅度不足0.3%。
(4)充分利用作者分類信息。《全國報刊索引》收錄的數據中可直接用于輔助標引信息的主要有期刊分類號以及作者分類號,這兩類數據可以為自動標引提供一定的助力。仍以2019年《全國報刊索引》收錄數據為例,95%的文獻集中在一個大類的期刊有431種;有作者分類號的文獻有200 939篇,其中分類號一級類目正確的有109 235篇,占比為54.36%;擴展到刊的層面,在涉及到的4 000多種刊中,作者分類號正確率在95%以上的,有92種。由于目前尚未找出如何適當使用作者分類號的方法,本文僅使用期刊分類號用于輔助一級類目分類結果。測試結果顯示,使用期刊分類號后一級類目準確率能提高0.86%。
3 結語
本實驗是為了在現有技術水平下,盡可能地增加標引數據量。《全國報刊索引》編輯部根據實際情況,已在會議論文分類工作中投入使用基于BERT的文本分類系統,用以標引R類會議文獻。一方面為了解決人力問題,增加標引量;另一方面在實際工作中驗證系統的準確率以及可能存在的問題,以便于進一步改進。后續工作重點主要集中在以下兩個方面:一是梳理人工分類經驗,及時統一內部分類規則,盡量保證同一主題文獻分到同一類目下,為文本分類提供高質量訓練數據;二是嘗試將人工分類經驗引入到分類模型中,為文本分類提供一定助力。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
