基于mRMR-BP算法的辛烷值損失預測模型研究
2022-05-05 07:22:16姬子恒朱建偉陳海江
智能計算機與應用 2022年3期
姬子恒,朱建偉,陳海江
(長安大學 機械學院,西安 710064)
0 引 言
汽油是小型車輛的主要燃料,汽油燃燒產生的尾氣排放對大氣環境影響嚴重。汽油清潔化的重點是降低汽油中的硫、烯烴含量,同時保持其辛烷值。中國每年從國外進口大量的含硫和高硫的原油,且其中的重油通常占比高達40%-60%。為了有效利用重油資源,中國開發了一種以裂化催化為核心的重油輕質化工藝技術,將重油轉化為汽油、柴油和低碳烯烴。為了滿足對汽油質量的要求,必須對催化裂化汽油進行精制處理,降低其中的硫、烯烴含量。然而,現有的技術在對催化裂化汽油進行脫硫和降烯烴處理過程中,普遍降低了汽油辛烷值,影響了汽油的燃燒性能。據研究結果表明,辛烷值每降低一個單位,相當于每噸損失150元。因此,在汽油精制過程中盡量保持其辛烷值,是提高石化企業經濟效益的關鍵。
為了控制汽油精制處理過程中辛烷值的含量,本文將通過數據挖掘技術,建立汽油辛烷值(RON)損失的預測模型,并給出每個樣本的優化操作條件。
1 尋找建模主要變量
某石化企業的催化裂化汽油精制脫硫裝置運行4年,積累了大量歷史數據,其中包括7個原料性質、2個待生吸附劑性質、2個再生吸附劑性質、2個產品性質以及354個操作變量,合計367個變量。如此龐大的樣本數據,不利于建模過程的優化。因此,需要通過降維的方法,從367個變量中篩選出建模主要變量,使得降維后的主要變量減少為30個以下,并使主要變量之間盡量具有代表性和獨立性。建模主要變量篩選流程如圖1所示。

圖1 建模主要變量篩選流程Fig.1 Flow chart of main variables screening in modeling
1.1 互信息法
在對海量數據或大數據進行數據挖掘時,通常會面臨“維度災難”。其原因是數據集的維度可以不斷增加直至無窮多,但計算機的處理能力和速度卻是有限的。典型的數據降維思路,是基于特征選擇的降維。本文采用基于統計分析的方法,通過計算汽油精制過程中不同操作變量與汽油辛烷值之間的互信息量,對求出的互信息按大小進行排序,篩選出其中排序靠前的若干個變量。
通常情況下,兩個離散變量和的互信息如圖2所示,可定義為:
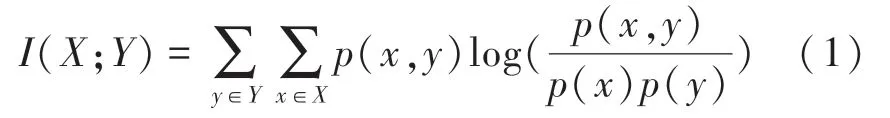
其中,(,)是和的聯合概率分布函數,而()和()分別是和的邊緣概率分布函數。
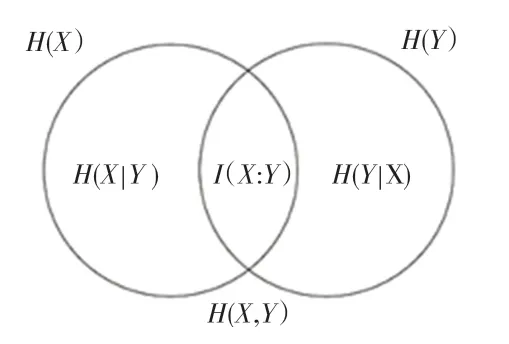
圖2 互信息示意圖Fig.2 Schematic diagram of mutual information
當求解某個變量與辛烷值的聯合分布密度(,)時,可根據隨機變量、的取值范圍,將整個區域等分為100個小網格,對于任意一個小網格xy,定義聯合分布密度(x,y)p,其值為落在該小網格上的樣本數據點數與樣本數據總點數之比。
當分別求解某個變量與辛烷值的邊緣概率分布函數(x)和(y)時,可分別對聯合分布列的第行和第列的聯合概率密度求和,即:
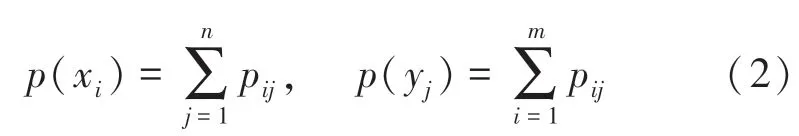
將其代入公式(1),即可求出第個變量與辛烷值的互信息(;),共計366個互信息值。將這些變量的互信息值按從大到小的順序排列,篩選出排序靠前的變量,即與辛烷值的相關性最高的若干變量。
1.2 mRMR算法特征選擇
mRMR算法主要是為了解決通過最大化特征與目標變量的相關關系度,得到的最好的個特征中存在冗余特征的問題。采用mRMR算法可以篩選出辛烷值的操作變量中相關性較小的變量,保證了可操作變量與辛烷值之間最大相關性的同時,彼此之間又有最小的冗余性。
首先,利用互信息計算(;)((;)越大,其之間的關聯度就越大)。找出含有(x)個特征的特征子集,使得找出的個特征和類別的相關性最大,即找出與關系最密切的個特征。
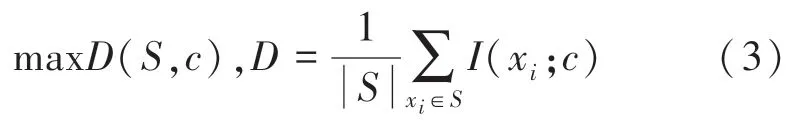
特征集與類別的相關性由各個特征x和類之間的所有互信息值的平均值定義,由此選出個平均互信息最大的集合。之后,消除個特征之間的冗余:
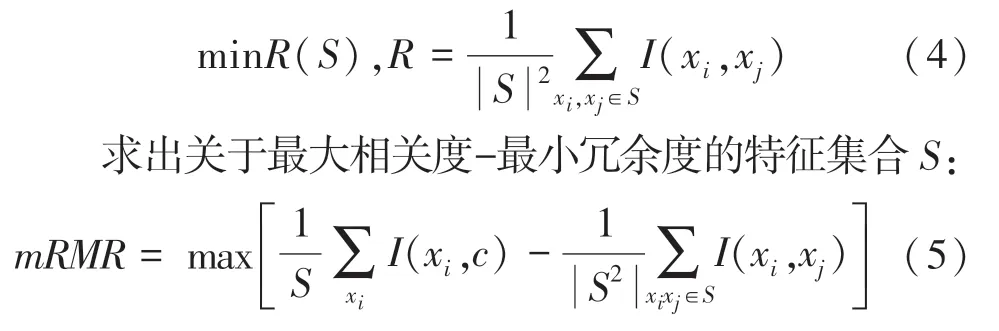
最終,篩選出同時滿足與辛烷值之間具有最大相關性,且彼此之間又有最小冗余性的18個可操作變量。
2 建立辛烷值(RON)損失預測模型
通過比較每個自變量和因變量之間互信息的大小,把互信息值大的變量篩選出來,最終得到了18個用于建模的主要變量。本文主要利用BP神經網絡,對辛烷值損失建立預測模型。
2.1 BP神經網絡構建
BP神經網絡屬于前向神經網絡,強調網絡采用誤差反向傳播的學習算法。其中包括一個輸入層、若干隱含層和一個輸出層組成。其核心思想是通過樣本訓練集,不斷修正神經網絡的權值和閾值,逐步逼近期望的輸出值。在訓練開始時沿著網絡正向傳播,然后根據網絡的輸出值與期望的輸出值之間的誤差,反向傳播調整權值和閾值。通過反復更新網絡權值和閾值實現誤差最小,即完成網絡訓練。本文設計的網絡結構示意如圖3所示,其實現步驟如下:
設計網絡結構層
(1)輸入輸出層:將提取的18個主要變量作為輸入,產品辛烷值損失量作為輸出。故輸入層神經元個數18,輸出層神經元個數1。
(2)隱含層:在網絡設計過程中,隱含層神經元數的確定十分重要。隱含層神經元個數過多,會加大網絡計算量,并容易產生過度擬合問題;而神經元個數過少,則會影響網絡性能,達不到預期效果。由于,涉及數據較少,本文設置迭代次數為1000,訓練誤差目標為0.000001,學習率為0.4。分別設定隱含層神經元數為:45,60,90,120,在此基礎上討論不同隱含層神經元數的測試誤差。誤差平均值見表1。
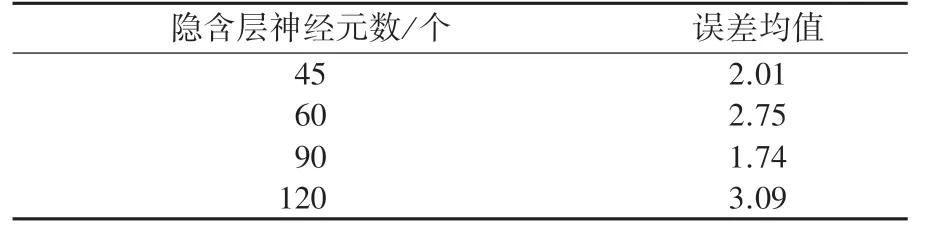
表1 不同隱含層神經元數的誤差均值Tab.1 Error mean of neurons in different hidden layers
從表1可以看出,當隱含層神經元數為90時,誤差均值最低。因此,設置隱含層神經元數為90。
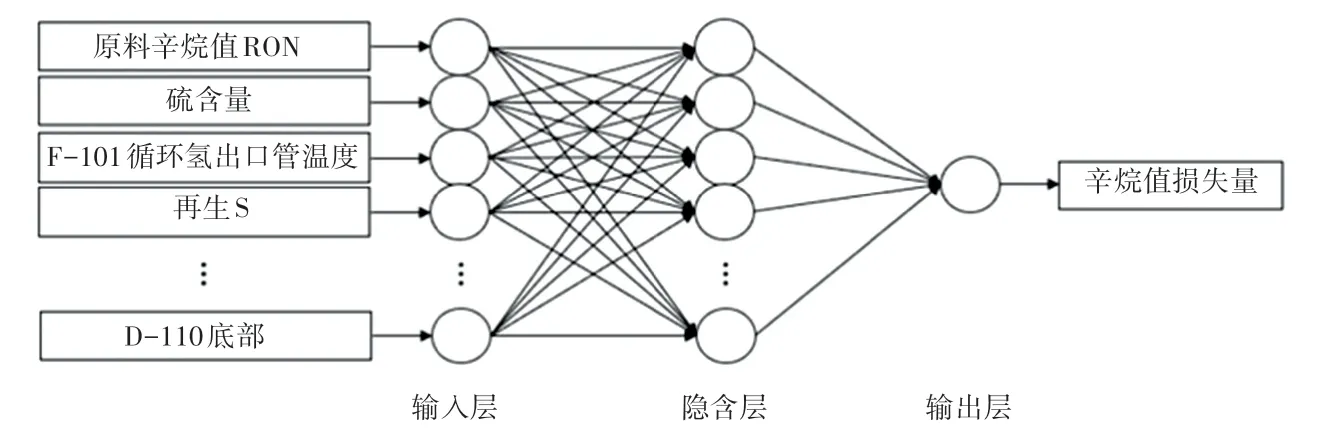
圖3 神經網絡結構示意圖Fig.3 Structure diagram of neural network
確定訓練數據和測試數據
通過前文的指標篩選,得到325行18列的變量數據,即神經網絡的輸入層數據,輸出層數據為325行1列的數據。本文設置前260行數據為訓練數據,后65行為測試數據。基于此,數據標準化按照公式(6)進行。
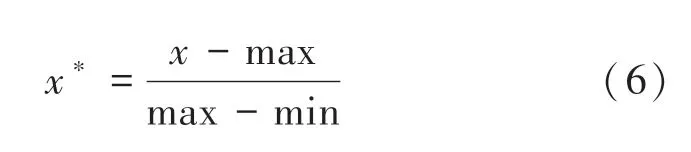
選取激勵函數
激勵函數的作用是提供規模化的非線性化能力,使得神經網絡可以任意逼近任何非線性函數,模擬神經元被激發的狀態變化。若不用激勵函數,無論神經網絡有多少層,輸出都是輸入的線性組合。
目前,常用的激勵函數有:Sigmoid、Thah和ReLU。ReLU使得SGD的收斂速度比Sigmoid和Thah快很多,使過程計算量減少,此外還解決了梯度消失問題。出于此種考慮,本文選擇ReLU(Rectified Linear Uni)作為本神經網絡的激勵函數。其形式如下:
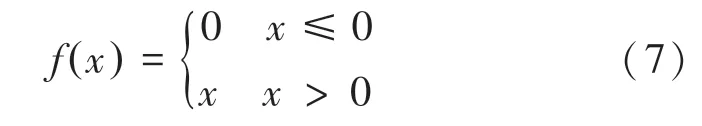
上述算法流程如圖4所示。
2.2 預測模型驗證
對降維后篩選出18個主要變量的325個樣本數據進行BP神經網絡分析,經過數據訓練與學習,產生辛烷值損失的預測結果。將測試集導入訓練好的RON損失預測模型中,對預測得到的結果與其真實值進行對比,其結果如圖5所示。
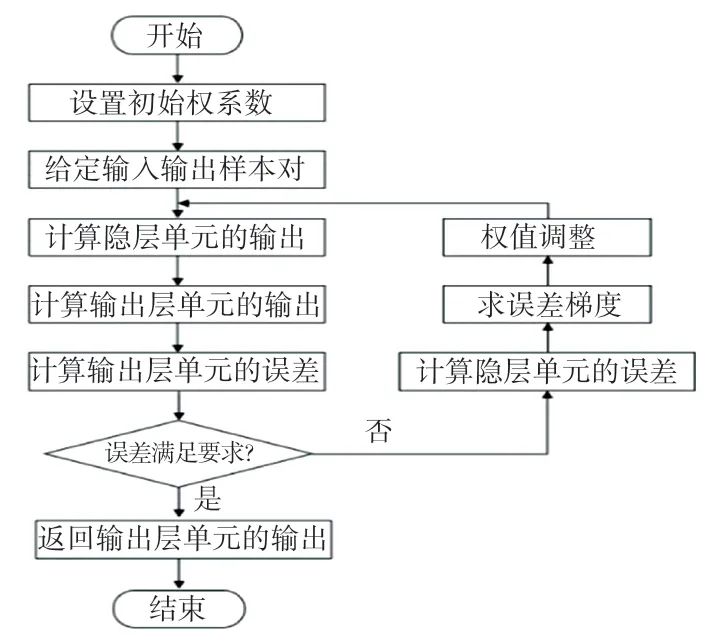
圖4 BP神經網絡算法框圖Fig.4 Block diagram of BP neural network algorithm
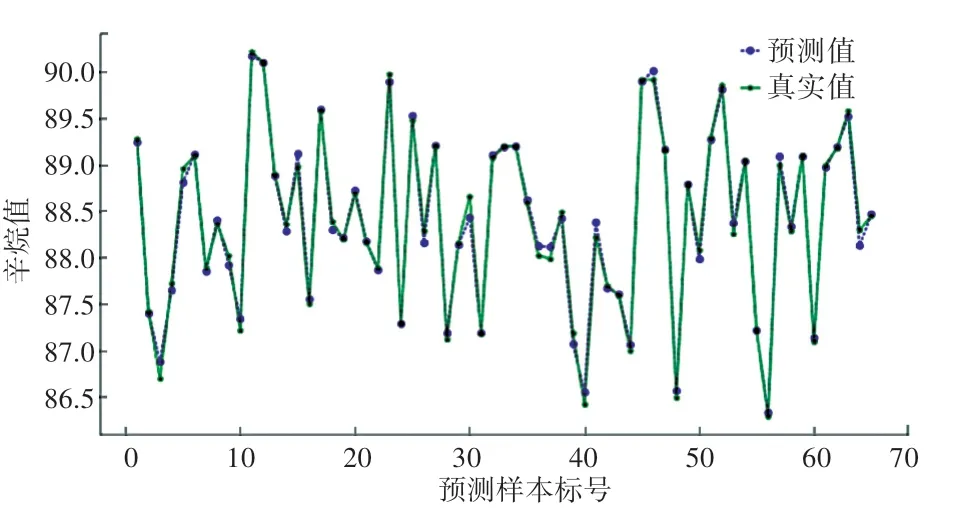
圖5 BP神經網絡預測結果與真實值對比Fig.5 Comparison between BP neural network prediction results and real values
從圖5可以看出,預測值與真實值十分相近,說明該模型具有較好的回歸結果,可較為真實的反應辛烷值的損失。各樣本預測誤差百分比計算結果如圖6所示。
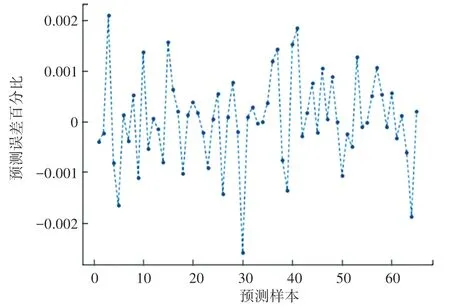
圖6 BP神經網絡預測誤差百分比Fig.6 Percentage of prediction error of BP neural network
從圖6可以看出,訓練得到的BP神經網絡模型預測結果較為準確,樣本中預測的誤差百分比最大只有0.25%。
3 主要操作變量對辛烷值損失的影響
經查閱相關文獻可知,在S Zord吸附脫硫技術中,主要有烯烴加氫飽和反應和烯烴異構化反應。而烯烴加氫飽和會形成烷烴,從而大大降低精制汽油的辛烷值,使辛烷值損失過大。因此,為了減少精制汽油的辛烷值損失,應該抑制烯烴的加氫飽和反應,增強汽油在反應器中的烯烴異構化反應。
3.1 再生吸附劑S含量
在S Zord實際的生產過程中,主要通過再生吸附劑的含量來調整吸附劑的活性。由優化分析可知,當調整主要操作變量——再生吸附劑含量,該主要操作變量的含量越高,再生吸附劑的活性就越大,精制汽油的辛烷值損失就越小。因此,在保證精制汽油的硫含量不大于5μg/g的前提下,盡可能提高再生吸附劑含量,從而降低精制汽油中的辛烷值損失。
3.2 F-101循環氫出口管溫度
由于烯烴加氫飽和反應是強放熱的過程,所以通過增加反應溫度,可有效抑制此反應的進行。如果反應器內烯烴加氫飽和反應大量發生,則反應器的溫度將會大幅度提高,同時耗氫量也會增加。總而言之,烯烴加氫飽和反應是S Zord裝置脫硫過程最不希望發生的反應,所以應盡可能通過調節反應溫度、反應壓力、再生吸附劑含量等主要操作變量來抑制此反應的發生。反應溫度對辛烷值損失的影響曲線如圖7所示。

圖7 反應溫度對辛烷值損失的影響Fig.7 Effect of reaction temperature on octane number loss
3.3 反吹氣體聚集器/補充氫差壓
由于烯烴加氫飽和反應是一個體積減少的過程,增加反應壓力將促使氫分壓增加,使烯烴加氫的速率增加,從而加速了烷烴的形成,導致精制汽油中的烯烴含量的減少,增加辛烷值的損失。所以,合理有效地控制反吹氣體聚集器/補充氫差壓,降低反應壓力則會減少辛烷值的損失。反應壓力對辛烷值損失的影響曲線如圖8所示。
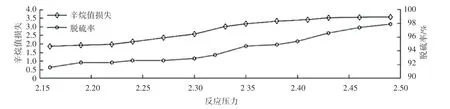
圖8 反應壓力對辛烷值損失的影響Fig.8 Effect of reaction pressure on octane number loss
4 結束語
本文構建了基于mRMR-BP算法的辛烷值損失預測模型,通過互信息和mRMR算法篩選出主要操作變量,解決了傳統的數據關聯模型中變量相對較少的問題,使主要操作變量更具有代表性和獨立性。經對模型驗證,表明該模型在預測精度上有較好的表現。通過分析主要操作變量對辛烷值損失的影響,為企業汽油精制處理過程中的實際操作提供可靠參考,幫助企業實現經濟效益最大化。
