基于YOLOv5網(wǎng)絡模型的火焰檢測
2022-05-05 07:21:48涂沛馳傅鈺雯熊宇璇楊健晟
智能計算機與應用 2022年3期
涂沛馳,傅鈺雯,熊宇璇,楊健晟
(1 貴州大學 電氣工程學院,貴陽 550025;2 貴州交通職業(yè)技術學院 物流系,貴陽 550025;3 貴州大學 外國語學院,貴陽 550025)
0 引 言
近年來,隨著現(xiàn)代工業(yè)的不斷發(fā)展,發(fā)電站的發(fā)電量與日俱增。其中,燃煤發(fā)電作為主要的發(fā)電方式之一,有著十分重要的地位。在煤礦的開采過程中,會伴隨著采出一種伴生資源煤層氣,煤層氣俗稱瓦斯。在煤礦的開采過程中,如果將瓦斯直接排放至大氣中,將會產(chǎn)生十分嚴重的溫室效應。研究發(fā)現(xiàn)瓦斯熱值高于通用煤1~4倍,與天然氣相當,且燃燒后較為純凈,不會產(chǎn)生工業(yè)廢氣。因此,瓦斯可以作為一種良好的工業(yè)化工發(fā)電的燃料,但當瓦斯中空氣濃度達到5%~16%時,遇到火焰會發(fā)生爆炸,這也是瓦斯發(fā)電站爆炸事故的根源。在瓦斯發(fā)電站中,火焰可能導致嚴重安全事故的發(fā)生,目前大多數(shù)工廠仍采用人工巡檢的方式對瓦斯發(fā)電站進行檢查,巡檢效率會隨著時間的延長而降低;由于火勢蔓延十分的迅速,人工巡檢很難早期發(fā)現(xiàn)并及時撲滅火焰。因此,急需一種能實時定位、識別火焰的方法來監(jiān)測瓦斯發(fā)電站內(nèi)可能出現(xiàn)的火焰。
與人工巡檢監(jiān)測火焰的方式相比,利用計算機視覺檢測火焰具有更高的效率。張汝峰等人以及蘇展等人將火焰圖片經(jīng)過圖像預處理操作后,再通過采用RGB、GBR與HSI兩兩結(jié)合的顏色模型,根據(jù)火焰的顏色、亮度等進行檢測;何愛龍等人采用視頻檢測及圖像處理的方法,通過將火焰圖片進行預處理后提取火焰區(qū)域,并選取其中較為明顯的火焰特征構(gòu)建火焰特征工程,進行火焰的識別;侯易呈等人通過采用Faster R-CNN(Faster Region-Convolutional Neural Networks)網(wǎng)絡與深度殘差網(wǎng)絡相結(jié)合的方法提取火焰特征,采用激勵網(wǎng)絡減少相關度較低的冗余特征,最后使用多尺度特征融合結(jié)構(gòu),豐富深層特征,以此來提高火焰識別的精度。但以上方法,對火焰的檢測主要集中在對火焰特征的提取,進而以良好的準確率識別檢測火焰,但在現(xiàn)實生活中,火勢蔓延十分迅速,故火焰檢測的實時性也是十分重要的一個環(huán)節(jié)。
隨著深度學習的發(fā)展,基于深度學習的目標檢測算法發(fā)展迅速,其主要分為單步目標檢測算法以及雙步目標檢測算法。雙步目標檢測算法分為圖像的識別和定位兩個步驟,首先使用區(qū)域候選算法從待檢測圖像中提取候選區(qū)域;通過卷積神經(jīng)網(wǎng)絡對圖像進行特征提取及分類識別。雙步目標檢測算法具有較高的準確率,但是計算量大,運算速度慢,針對于實時性要求高的目標檢測不太適用。單步目標檢測算法是將提取候選區(qū)域以及分類識別兩個部分融合到一個網(wǎng)絡里,直接由輸入圖像得到圖像中存在的物體類別及位置。單步目標檢測算法,在精度不會丟失太多的同時兼具了運算速度快,實時性好,對硬件要求低等優(yōu)點,被廣泛應用于目標實時檢測領域中。
1 YOLOv5模型的組成及原理
YOLO(You Only Look Once)算法是一種單步端到端的目標檢測算法,將提取候選區(qū)域及識別分類融合在一起,具有檢測速度快、模型文件小等優(yōu)點。通過更新迭代,現(xiàn)如今更新到了YOLOv5模型。YOLOv5模型共有YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x 4個版本,其中YOLOv5s網(wǎng)絡是YOLOv5系列中深度最小、模型文件最小,是其他版本網(wǎng)絡的基礎。綜合檢測的實時性與模型準確性,本文采用YOLOv5s網(wǎng)絡作為火焰檢測的網(wǎng)絡。
YOLOv5的網(wǎng)絡架構(gòu)主要可分為4部分,依次為輸入端、骨干網(wǎng)絡、頸部網(wǎng)絡、輸出端。
1.1 輸入端
YOLOv5網(wǎng)絡的輸入端采用Mosaic數(shù)據(jù)增強、自適應錨框計算、自適應圖片縮放3種算法。
Mosaic數(shù)據(jù)增強方法在輸入的數(shù)據(jù)中隨機選取4張圖片進行隨機的縮放、裁剪及排列。可將數(shù)據(jù)擴容,使得網(wǎng)絡的魯棒性得以提升;其次,通過圖片的拼接可以一次計算4張圖片的數(shù)據(jù),從而提升模型的訓練速度,降低模型的內(nèi)存要求。Mosaic數(shù)據(jù)增強操作原理如圖1所示。

圖1 Mosaic數(shù)據(jù)增強操作原理Fig.1 Mosaic data enhancement operation principle
自適應錨框計算方法是在建立的數(shù)據(jù)集中設定指定長寬的錨點框,以輸入圖像的每一個像素作為中心點,以此生成多個邊界框。當網(wǎng)絡進入到訓練階段時,會在初始錨點框上輸出與其對應的預測框,計算其與真實框的差距,進行反向更新,進而迭代更新網(wǎng)絡參數(shù)。
1.2 骨干網(wǎng)絡
YOLOv5網(wǎng)絡的骨干網(wǎng)絡采用了Focus結(jié)構(gòu)及CSP(Cross Stage Partial)結(jié)構(gòu)。Focus結(jié)構(gòu)對輸入圖片切片操作,每一張圖片采集某個像素點的值后,不采集相鄰像素點的值,而是中間隔開一個像素點,采集下一個像素點,從而擴充輸入通道數(shù);最后,將獲得的拼接圖片通過卷積操作,得到?jīng)]有特征信息丟失的二倍下采樣特征圖。Focus切片操作原理如圖2所示。
2.1.1 主莖。“鴻福金鉆蔓綠絨”及其親本的主莖均為圓柱形,“鴻福金鉆蔓綠絨”主莖上部為紅紫色,下部為黃綠色,莖節(jié)為紅紫色,其親本為黃綠色,莖節(jié)為紅紫色(表2)。種植12個月時“鴻福金鉆蔓綠絨”的平均主莖長為12.3 cm,主莖粗為2.5 cm,其親本的主莖長為12.3 cm,主莖粗為2.6 cm,差異不顯著(表3)。
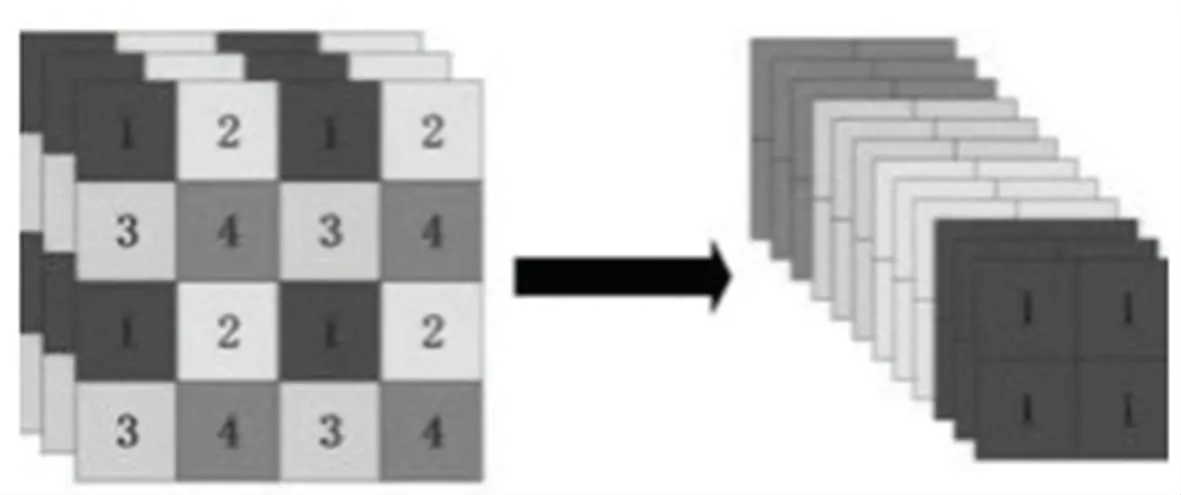
圖2 Focus切片操作原理Fig.2 Focus slicing operation principle
以YOLOv5s位列,輸入圖像尺寸為640×640×3,將圖像輸出至Focus結(jié)構(gòu)中,通過切片操作,得到320×320×12的特征圖,最后經(jīng)過卷積核為32的卷積層,得到320×320×32的特征圖。
CSP結(jié)構(gòu)在Yolov5s網(wǎng)絡中有兩處應用,Csp_1結(jié)構(gòu)應用于骨架網(wǎng)絡中,Csp_2結(jié)構(gòu)則是應用于頸部網(wǎng)絡中。Csp_1結(jié)構(gòu)中包含了CBL(Conv+BN+LeakyRelu)模塊以及多個殘差組件(Res unit)。CBL模塊與殘差組件的組成,如圖3所示。
殘差組件是借鑒了Resnet網(wǎng)絡中的殘差結(jié)構(gòu),應用于較深的網(wǎng)絡中,可以解決網(wǎng)絡層數(shù)過深而導致的梯度消失的問題。Csp_2結(jié)構(gòu)中,使用普通的CBL模塊代替了殘差組件。Csp結(jié)構(gòu)用兩條支路,通過支路實現(xiàn)特征融合,提取更為豐富的特征信息。

圖3 CBL模塊及殘差組件的組成Fig.3 Composition of CBL module and residual components
SPP(Spatial Pyramid Pooling)是為了解決卷積神經(jīng)網(wǎng)絡輸入圖像數(shù)據(jù)大小固定的問題而提出來的一種結(jié)構(gòu),卷積神經(jīng)網(wǎng)絡是由卷積層和全連接層構(gòu)成,卷積層對輸入圖像數(shù)據(jù)大小沒有規(guī)定,但第一個全連接層對輸入圖像的數(shù)據(jù)大小是有要求的。因此卷積神經(jīng)網(wǎng)絡基本上對輸入數(shù)據(jù)的大小有所規(guī)定,針對許多數(shù)據(jù)高寬比不固定的情況,如果直接對圖片進行切割,那么會存在丟失特征信息的可能性。因此,為了解決上述問題,提出了SPP結(jié)構(gòu),SPP結(jié)構(gòu)工作原理如圖4所示。YOLOv5中引進了SPP結(jié)構(gòu),用來解決圖像由于裁剪、縮放等操作而引起的特征丟失等問題。

圖4 SPP結(jié)構(gòu)工作原理Fig.4 SPP structure working principle
1.3 頸部網(wǎng)絡
YOLOv5網(wǎng)絡的頸部網(wǎng)絡采用的是FPN(Feature Pyramid Networks)+PAN(Path Aggregation Network)結(jié)構(gòu)。FPN是自頂向下的,將高層特征通過上采樣和低層特征做融合得到進行預測的特征圖。FPN是自頂向下的,將高層的強語義特征傳遞下來,對整個金字塔進行增強,不過只增強了語義信息,對定位信息沒有傳遞,而在FPN的后面添加一個自底向上的金字塔,是對FPN的補充,將低層的強定位特征傳遞上去。
FPN就是把深層的語義特征傳到淺層,從而增強多個尺度上的語義表達。而PAN則是把淺層的定位信息傳導到深層,增強多個尺度上的定位能力。FPN+PAN結(jié)構(gòu)如圖5所示。

圖5 FPN+PAN結(jié)構(gòu)示意圖Fig.5 Schematic diagram of FPN+PAN structure
1.4 輸出端

其中,A為預測框與真實框的最小外接矩形,為A中不屬于預測框與真實框的部分。當真實框與預測框越接近時,越小,從而使得越小。
YOLOv5網(wǎng)絡處于預測階段時,會產(chǎn)生許多圍繞同一目標的預測框,通過使用非極大值抑制使得預測框合并。將GIoU損失函數(shù)與非極大值抑制結(jié)合可以更好的識別圖像中有重疊的目標。
2 數(shù)據(jù)采集及數(shù)據(jù)集制作
2.1 數(shù)據(jù)來源
本文的火焰圖片數(shù)據(jù)來自公開數(shù)據(jù)集以及手動拍攝兩部分,手動拍攝的數(shù)據(jù)為丁烷點火器生成的火焰視頻,將視頻截取成火焰圖片。此次數(shù)據(jù)共采集600張火焰圖片,通過數(shù)據(jù)增強的方法將原有數(shù)據(jù)進行旋轉(zhuǎn)及亮度變換等操作,擴容至3000張圖片,火焰數(shù)據(jù)圖片如圖6所示。

圖6 部分火焰圖片數(shù)據(jù)Fig.6 Part of the flame picture data
2.2 數(shù)據(jù)集建立
將得到的火焰圖片數(shù)據(jù)使用Labelimg軟件進行標注。在標注過程中,盡可能的選取完整的火焰區(qū)域,防丟失圖像特征。本次實驗對象為火焰一個類,通過手動標注后自動生成txt文件,標簽文件中包含了標簽類別、預測框坐標等信息。標注結(jié)果如圖7所示。

圖7 火焰數(shù)據(jù)標注圖像Fig.7 Flame data labeled image
火焰樣本數(shù)據(jù)標注完成后,通過腳本文件自動劃分成訓練集和測試集。以便后續(xù)輸入模型訓練。
3 實驗結(jié)果及分析
3.1 實驗環(huán)境
此次實驗采用Windows10專業(yè)版操作系統(tǒng),Pytorch1.7版本框架,集成開發(fā)環(huán)境為Pycharm。平臺硬件參數(shù)如下:CPU為i9,內(nèi)存大小為32 GByte,GPU為Nvidia QUADRO RTX4000。
3.2 實驗結(jié)果
本文實驗采用YOLOv5目標檢測模型,總體訓練輪數(shù)設置為200輪,分組大小設置為20,學習率設置為0.001。網(wǎng)絡訓練過程中,訓練前期模型的損失函數(shù)迭代收斂速度較快,隨著訓練次數(shù)的增多,損失函數(shù)收斂速度逐漸趨于緩和,最終實現(xiàn)收斂,并結(jié)束模型的訓練。訓練完成后將保存一個最新訓練的權(quán)值文件與一個最優(yōu)權(quán)值文件。網(wǎng)絡訓練結(jié)果如圖8所示,可以看出,值為096。

圖8 模型訓練結(jié)果Fig.8 Model training results
平均精度與召回率是目標檢測中常用的評價指標,其計算公式如式(2)~(3)。

其中,表示將正類別預測為正確類別的個數(shù);表示將負類別預測為正確類別的個數(shù);表示將正類別預測為負類別的個數(shù)。
將訓練好的權(quán)重文件導入模型之后,輸入火焰圖片進行識別,識別所耗時間為0.245 s,識別效果如圖9所示。

圖9 火焰識別效果圖Fig.9 Flame recognition effect diagram
從圖9可以看出,針對不同情況下的火焰,訓練后的模型對其識別后置信度為91%-93%,因此,經(jīng)過訓練的YOLOv5模型對火焰的識別具有較高的準確性,同時訓練完成的檢測模型兼具良好的實時性。
4 結(jié)束語
針對火焰檢測存在實時性不足的問題,本文提出了基于深度學習的火焰檢測方法,使用YOLOv5s目標檢測算法模型,通過3000張火焰圖片數(shù)據(jù)的訓練后,使用訓練結(jié)果最優(yōu)的權(quán)重參數(shù)文件。實驗后期采用火焰圖片數(shù)據(jù)對模型進行檢測,具有較高的準確性和良好的實時性,可以滿足實時性要求較高的火焰檢測場景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
