基于ExtraTree的軟件缺陷預測方法研究
2022-05-05 07:21:26王馨煜崔藝凝段盈盈
智能計算機與應用 2022年3期
王馨煜,崔藝凝,段盈盈
(北京信息科技大學 計算機學院,北京 100101)
0 引 言
隨著時代的發展和科技進步,計算機在人們的生活中越來越多地被使用。軟件是計算機領域中非常重要的一部分,軟件存在的缺陷也不可小覷。軟件缺陷預測技術旨在預測出模型中的缺陷數和缺陷傾向性,從而根據預測結果對資源進行合理的分配,是缺陷檢測技術的重要輔助手段。早期,研究人員通過經驗來估計模型中可能存在的缺陷;后來出現了軟件體積度量元和缺陷的關系式,用關系式來計算系統在測試之前存在的缺陷數;有研究者將代碼對應具體文檔位置,從而給出了缺陷率的公式;也有研究者假設模塊規模符合指數分布,給出了缺陷密度的估算公式。
融合多分類器模型對軟件缺陷預測技術有重大的研究意義,通過融合多分類器模型,不僅可以發現不同模型之間潛在的聯系,還可以度量軟件的可靠性。另外,融合多個效果較弱的分類器為一個性能較好的多分類器,還可以提高弱分類器的預測性能。
本文首先通過選擇不同的分類器模型對提取的軟件模塊進行預測并輸出結果;其次,對單個分類器模型與融合后的分類器模型的預測結果進行比對;采用基于集成學習的靜態軟件缺陷預測方法對軟件模塊缺陷進行預測。
1 相關研究
1.1 背景
軟件缺陷預測技術旨在預測出軟件模塊的缺陷,明確存在缺陷模塊的缺陷數和缺陷傾向性。軟件模塊存在缺陷可能會造成財產損失和安全隱患。如:1996年6月因導航系統的計算機軟件故障導致歐洲“阿麗亞娜”號航天飛機墜毀;1999年美國火星探測飛船墜毀事件,不包括損失時間,其工程成本耗費3.27億美元。軟件缺陷預測技術是避免軟件運行故障,減少不必要損失的重要手段,該技術自開始研究后就受到了眾多的關注。
早期的軟件缺陷通過員工的經驗來估計,后來Akiyama明確給出了最早的軟件缺陷與代碼行的關系量化式,但只是在程序開始前初步對可能存在的軟件缺陷進行估算,并不完美。隨著測試軟件的規模與其復雜度的逐步提高,開發者更加重視的是軟件缺陷預測技術的精準度及模塊測試的正確率是否能夠保證在一個穩定的范圍里,是否可以更加高效地完成測試。成熟的軟件缺陷預測技術可以在軟件發布之前預測出真正有缺陷的程序模塊,從而提高軟件的質量,減少資源消耗。
1.2 國內外研究現狀
目前,國內外研究人員從不同的角度研究了靜態缺陷預測和數據驅動缺陷預測等方法。在異常值檢測和處理、高維度數據、類不平衡問題和數據差異等方面進行了研究,主要使用機器學習和統計方法來預測缺陷模塊。如:Freund和Schapire研究的Adaboost迭代算法,可以增強預測模型的精度;Wolpert提出的Stacking算法,可以集成若干基分類器的分類性能,從而提高分類效果等。
越來越多的預測模型的出現使研究者的注意力更多地集中在模型預測精度上,實驗數據集的差異性和單一分類器預測性能的局限性是影響軟件缺陷預測精度的兩大原因。針對數據集的差異性,Sun等提出了通過特征選擇提高預測精度的方法;Xu等提出了Logistic方法通過尋找最佳擬合參數來提高預測效率;針對單一分類器預測性能局限性的問題,Zhu等人提出了無監督的特征選擇方法。除此之外,集成學習方法也是解決單一分類器的預測性能不夠泛化問題的重要途徑,通過將多個弱分類器集成為一個強分類器,進而提高軟件缺陷預測的性能。
1.3 本文研究內容
本文針對不同預測模型對軟件缺陷預測結果差異性較大的問題,對結構復雜、類別不平衡、缺乏歷史數據的靜態軟件缺陷模塊采用基于集成學習的軟件靜態缺陷預測方法,利用已有的缺陷數據集,選擇Extra-Trees(極度隨機樹)來將多個弱分類器集成,并通過實驗對多個分類模型進行了驗證,并對融合前后各個模型的預測結果進行了比對。
在實驗中使用SMOTE方法(Synthetic Minority Oversampling Technique)對數據集進行預處理,選擇5種基分類器并結合Extra-Trees集成方法進行驗證。為了能夠有效評價分類結果,本文選擇了準確率、召回率、F值3個業界認可的評價指標對預測結果進行評價。
2 相關理論與技術基礎
2.1 SMOTE采樣
為解決樣本少,特征缺失的問題,Chawla等人提出了SMOTE過采樣方法,可以減少模型的過擬合。在訓練模型時,樣本數量少的類所能提供的信息也比較少,SMOTE方法通過對少數類樣本的分析,將少數類樣本合成新的樣本并加入數據集中,重復分析、合成過程直到達到數據樣本平衡。
生成新樣本的方法如式(1)所示。
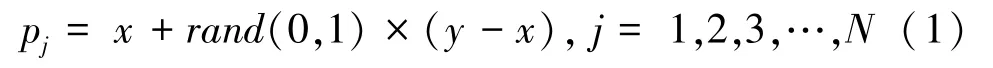
其中,P表示新樣本;x是少數類樣本點,對于每一個少數類樣本x,從其k近鄰中隨機選擇若干個樣本,假設選擇的近鄰為y;N表示生成樣本數量。
2.2 基于ExtraTree的缺陷預測方法
集成學習是解決類不平衡問題的方法之一,從數據中顯式或隱式地學習多個模型,將這些模型有效結合,得到可靠、準確的預測。單一分類器模型的測試能力逐漸趨于飽和,并且對缺陷模塊預測的范圍并不具有廣泛性,通過結合多個單一學習器,并聚合其預測結果的學習任務,聚集多個分類方法來提高分類的精度,可以獲得比單一學習器更顯著的泛化性能,也可以稱作多分類系統。
目前,集成學習的主要問題就是如何將多個弱分類器合成一個強分類器,有效提高預測的精度。在實驗中采用了ExtraTree(極度隨機樹)來集成多分類器模型,但使用這種方法前需要檢查樣本的數據是否適用ExtraTree缺陷預測方法。ExtraTree具有很少的關鍵超參數和用于配置這些超參數的合理啟發式方法,能夠處理很高維度的數據。相比于從訓練數據集的引導樣本開發每個決策樹的隨機森林,ExtraTree更適合整個訓練數據集上的每個決策樹,每個決策樹都采用原始訓練集,不會隨機采樣,訓練速度更快。
2.3 分類器模型評價指標
軟件缺陷預測模型可用于對軟件模塊的缺陷情況作分類處理,評價指標用于區分預測模型的優劣。在本次實驗中選取了軟件缺陷預測常用的評價指標:準確率(Accur acy),精確率(Precision),召回率(Recall)以及F1。
準確率()又叫查準率,是被正確預測出的有缺陷的樣本數量與被預測為無缺陷的樣本數量之比,如式(2):
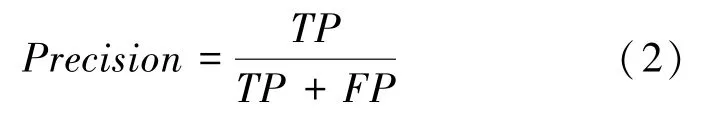
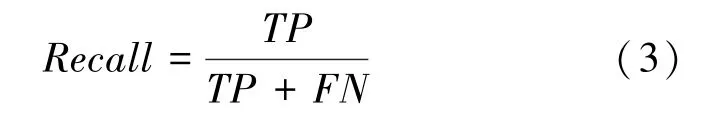
1可以看作是模型精確率和召回率的一種調和平均,如式(4):

其中,表示被正確預測出的有缺陷的樣本數量;表示被預測為有缺陷的無缺陷樣本數量;表示被預測為無缺陷的有缺陷樣本數量;表示被正確預測出的無缺陷樣本數量。
3 實驗與結果分析
3.1 數據集
本實驗采用數據集為NASA公布的MDP軟件缺陷數據集,來自于十三個實際軟件項目,數據集的基本信息包括樣本集名稱、模塊總數、缺陷模塊數、屬性個數以及缺陷所占比例,不同數據集缺陷所占比例不同。從NASA MDP數據集中選取缺陷所占比例不同的數據子集KC1、KC3、MC2、MW1、PC1、PC3、PC4作為本文的實驗數據集,見表1。
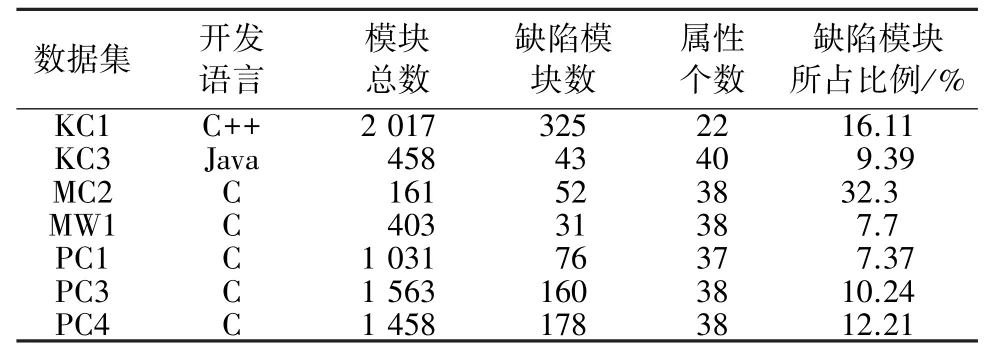
表1 NASA MDP數據子集Tab.1 NASA MDP Subset of the data
召回率(),又叫查全率,也就是被正確預測出的有缺陷的樣本數量與實際有缺陷的樣本數量之比,如式(3):
3.2 實驗方法
選擇的是決策樹分類器、隨機森林分類器、梯度提升分類器、基于直方圖的梯度提升分類器、自適應增強分類器5種基礎模型,通過極度隨機樹的集成學習方法融合5個基礎模型。
為了保證所對模型的數據對比的有效性,每個實驗的過程是相同的,5種基礎模型以及極度隨機樹集成學習方法在NASA的數據子集上進行一次十字交叉驗證,使、、13個對比指標數據進行同一數據集不同模型的數值對比。
3.3 實驗結果分析
5個基礎模型以及極度隨機樹集成學習方法在7個數據集中進行實驗,得到的指標數據見表2。從表2可以看出,極度隨機樹集成學習方法在KC3、MC2、MW1、PC3這4個數據集上達到了比其他5種基礎模型更好的1值,說明極度隨機樹對于特定數據集可以將弱分類器集成融合成一個較強分類器。隨機森林分類器、基于直方圖的梯度提升分類器、自適應增強分類器分別在KC1、PC4、PC1這3個數據集上1值達到最佳,該現象與KC1、PC4、PC13個數據集的類不平衡有一定關系。
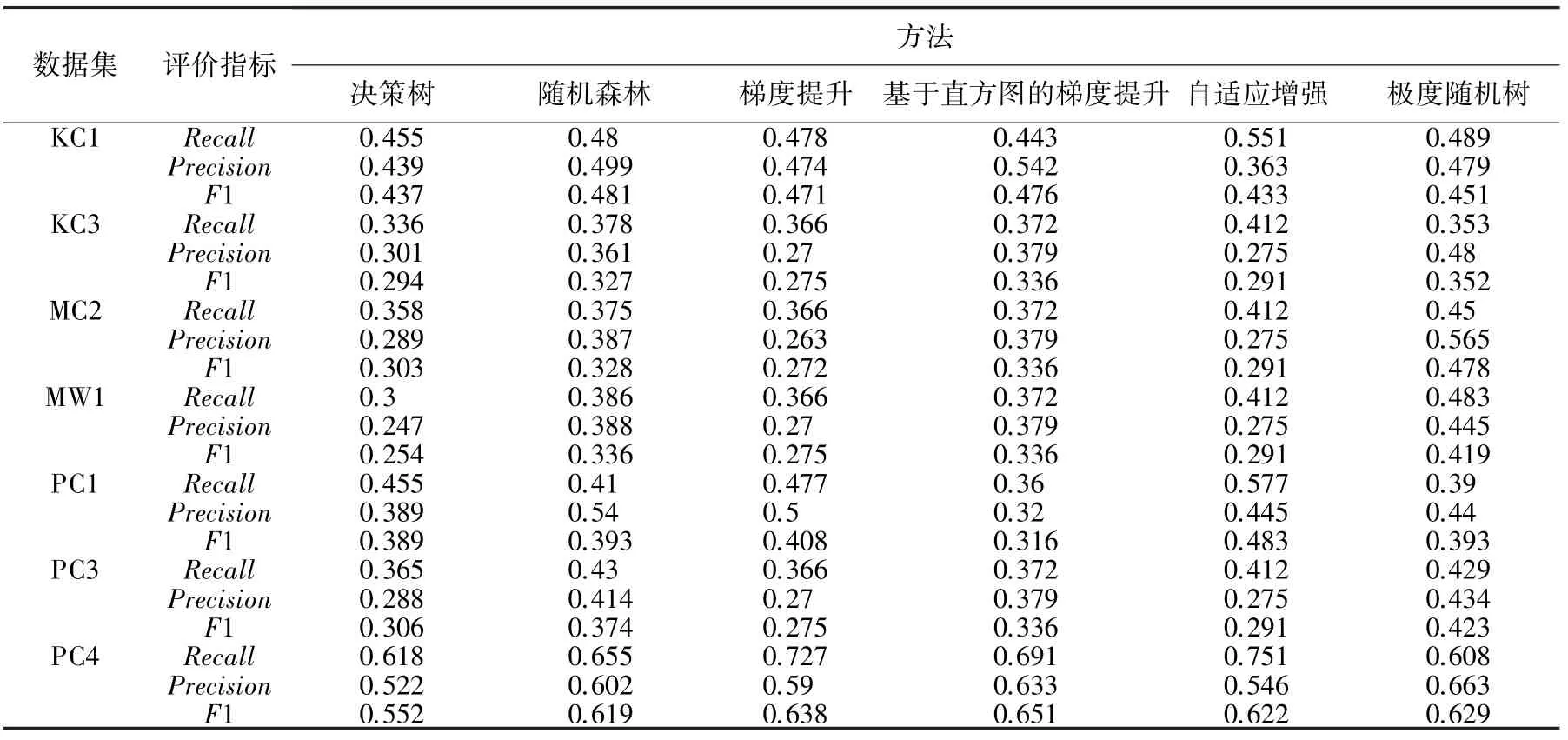
表2 NASA MDP數據集實驗結果Tab.2 NASA MDP Experimental results of the data sets
4 結束語
本文基于極度隨機數集成學習方法對決策樹分類器、隨機森林分類器、梯度提升分類器、基于直方圖的梯度提升分類器和自適應增強分類器5個單個弱學習器進行了融合;用各個單分類器及基于ExtraTree的集成分類器分別對7個數據集進行了缺陷預測。本文就是選用了極度隨機樹這一集成學習方法,對5個性能較差的弱分類器進行了融合得到一個多分類器融合模型,然后對比單個分類器的預測結果和多分類器的預測結果,比較兩者的預測性能,對軟件缺陷預測模型的預測性能問題進行了研究。預測的結果得出融合后的學習器在選中的7個數據集中有4個數據集預測出的F1值都是優于任何一個單分類器的,在其他3個數據集中預測出的F1均處于第二或第三的位置。該集成學習方法無法在每個數據集中都達到最好的預測性能,后續將改進缺陷預測模塊分布的稀疏性引起的相關問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
