基于YOLOv4-Efficient的目標檢測和識別
2022-05-05 07:20:56史健婷劉文斌安祥澤
智能計算機與應用 2022年3期
史健婷,李 旭,2,劉文斌,安祥澤,2
(1黑龍江科技大學 計算機與信息工程學院,哈爾濱 150022;2黑龍江科技大學 研究生學院,哈爾濱 150022)
0 引 言
目標檢測是計算機視覺和數字圖像處理的一個熱門方向,廣泛應用于視頻監控、自動駕駛、航空航天等諸多領域。近年來目標檢測成為研究和應用的主攻領域,再加上深度學習的廣泛運用,目標檢測得到了更加快速的發展。
目前主流的目標檢測算法大概可以分為兩大類:
(1)One-Stage目標檢測算法,這類算法不需要候選區域階段,直接對物體進行檢測和識別。YOLO系列就是一階段的代表性算法,速度較快,但精確度較差;
(2)Two-Stage目標檢測算法,這類算法主要分為兩個階段,第一階段是產生候選區域,也就是目標的大概位置;第二階段對所產生的候選區域進行類別和位置信息的預測識別。R-CNN是兩階段的代表性算法,雖速度較慢,但有較高的精度。兩類算法各有優勢,隨著研究的不斷深入,兩類算法都在做著改進,并能在速度和準確度上取得很好的表現。
隨著網絡的深度不斷加深,為了獲得更多的目標信息,勢必要擴大網絡的通道數,這樣就會帶來大量的參數運算。本文將 EfficientNet網絡和YOLOv4中的檢測網絡相結合,以達到參數量的大量減少,檢測速度盡可能提高的目標檢測算法。
1 相關算法
1.1 YOLOv4算法
YOLOv4是YOLOv3的改進版,在其基礎上融合了許多創新性的小技巧。YOLOv4可以分為4部分,其中包括:輸入端、BackBone主干網絡、Neck、Prediction。
輸入端的創新,主要是訓練時對輸入端的改進,包括Mosaic數據增強等;BackBone主干網絡是將各種創新結合起來,其中包括:CSPDarknet53、Mish激活函數、Dropblock等;Neck部分是在BackBone和最后的輸出層之間插入一些層,如YOLOv4中的SPP模塊、FPN+PAN結構;Prediction部分主要改進訓練時的損失函數_。YOLOv4的網絡結構如圖1所示。
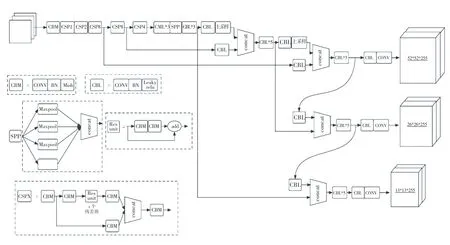
圖1 YOLOv4網絡結構圖Fig.1 YOLOv4 network structure diagram
若以輸入的圖像尺寸為416×416為例,其處理過程如下:
圖像進行Mosaic數據增強后,主干提取網絡CSPDarknet53進行特征提取,將提取到的特征進行SPP 3次不同尺度的最大池化,并通過PANet進行特征融合;將不同尺度的特征圖進行融合,獲得3種尺度的特征圖(52×52、26×26、13×13);最后分別對這3種不同尺度的特征圖進行分類回歸預測結果。
1.2 EfficientNet算法
EfficientNet算法具有的特點:利用殘差結構來提高網絡的深度,通過更深層次的神經網絡實現更多特征信息的提取;改變每一層提取的特征層數,實現更多層的特征提取,來提升寬度;通過增大輸入圖片的分辨率,使網絡學習到更加豐富的內容,達到提高精確度的目的。
EfficientNet使用一組固定的縮放系數統一縮放網絡深度、寬度和分辨率,網絡可以平衡縮放,進入網絡中圖像的分辨率、網絡寬度和網絡深度,減少了模型參數量,增強了特征提取能力,使網絡的速度和精度達到最佳。EfficientNet有多個MBConv模塊。其總體的設計思路是Inverted residuals結構和殘差結構,首先進行1?1卷積操作進行升維,在3?3或5?5的深度可分離卷積后,增加了一個通道的注意力機制,最后利用1?1卷積進行降維后,增加一個大的殘差邊,進行特征層的相加操作。MBConv模塊如圖2所示。
1.3 CIOU損失函數
YOLOv4在損失函數方面,將作為回歸。為了使目標框回歸更加穩定,收斂的更快,考慮了多重因素。其中包括:目標框與錨框之間的距離,重疊率、尺度以及懲罰項,提高定位的精度,防止出現與(真實框和預測框的交集和并集之比)在訓練過程中相同的發散問題。如式(1):

式中:、b分別表示錨框和目標框的中心點;為計算兩個中心點的歐式距離;為權重系數;為長寬比相似性;、分別表示預測框的寬度和高度;w、h分別表示真實框的寬度和高度。
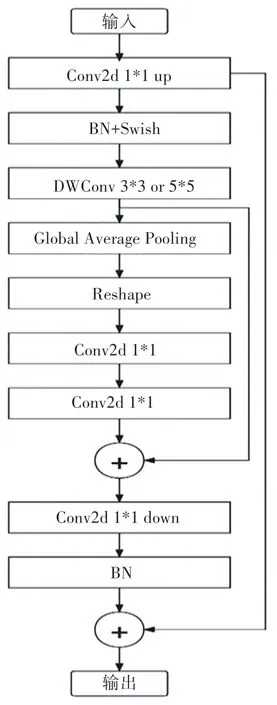
圖2 MBConv模塊結構Fig.2 MBConv module structure diagram
2 YOLOv4-Efficient網絡結構
2.1 主干提取網絡
YOLOv4中CSPDarknet53主干特征提取網絡的提取能力和檢測精度非常強,在各個領域都有非常優秀的表現。但主干巨大的參數量對計算設備的性能有著較高的要求,使其對車輛的實時監測和算法的移植有較高的難度。YOLOv4-tiny雖然具有較低的參數量,較快的檢測速度,但是特征提取能力和泛化能力較差,在復雜的場景變化中檢測能力較差,對物體識別效果不太理想。
依據上述分析結果,為了解決既提高速度又具備較強檢測能力的問題,將特征提取的主干換成EfficientNet輕量級網絡,因其具有較少的參數量和較高的特征提取能力,可以大大減少運算時間提高實時監測能力,并且該算法可以移植到較低算力的設備上。YOLOv4-Efficient網絡結構如圖3所示。
EfficientNet系列網絡有8種不同類型的模型,可以應對不同的場景。如:應對自動駕駛中對車輛的檢測時,考慮到速度和精度,可選擇EfficientNet-B2模型,將EfficientNet-B2最后的池化層和全連接層去掉之后,代替YOLOv4原始的CSPDarknet53特征提取網絡。EfficientNet-B2網絡結構見表1。
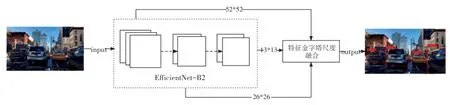
圖3 YOLOv4-Efficient網絡結構Fig.3 YOLOv4-Efficient network structure
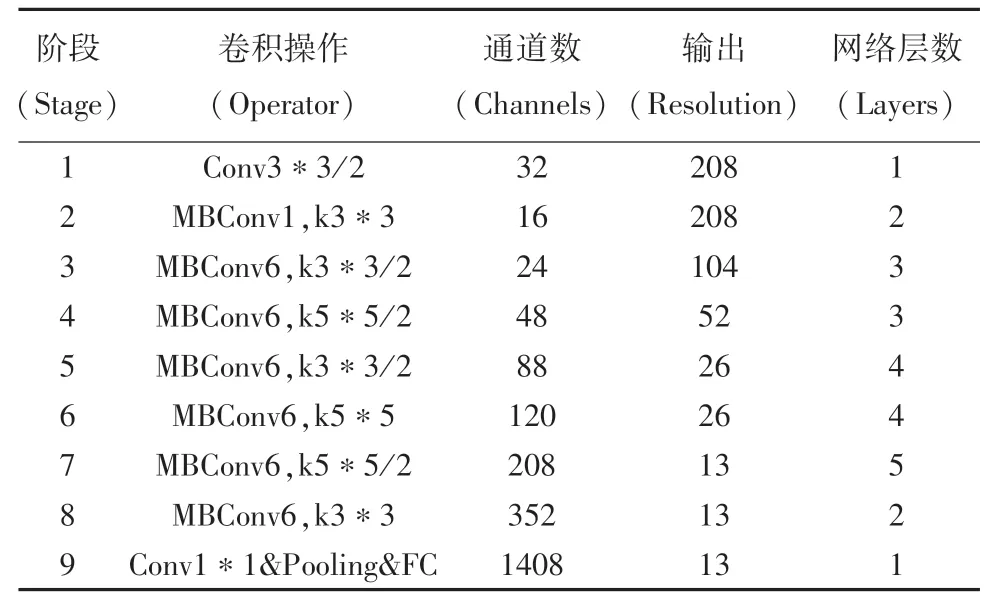
表1 EfficientNet-B2網絡結構Tab.1 EfficientNet-B2 network structure
2.2 改進PANet特征融合
本文對PANet特征融合的改進主要涉及兩個方面:一是引入深度可分離卷積,二是在進行特征融合上采樣時,加入了SENet注意力模塊。
由于PANet中使用了大量的卷積,會導致巨大的參數量,所以在PANet中引入了深度可分離卷積,使PANet特征金字塔部分的參數量大幅度減少,提高整個模型的檢測速度。
深度可分離卷積分為逐通道卷積和逐點卷積。在逐通道卷積中,一個卷積核負責一個通道,一個通道只被一個卷積核卷積。如圖4所示。
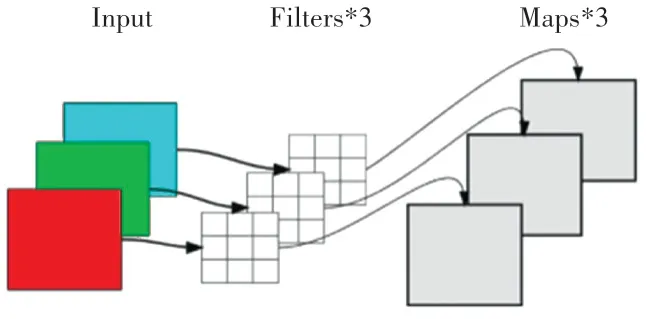
圖4 逐通道卷積結構Fig.4 Channel by channel convolution structure
逐點卷積運算和常規卷積運算類似,其卷積核尺寸為1×1×M(上一層的通道數)。這里的卷積運算會將逐通道卷積產生特征圖,在深度方向上進行加權組合,生成新的特征圖。有幾個卷積核就輸出幾個特征圖。
為了使不同的特征層進行融合時保證其關鍵信息得到加強,所以在PANet特征融合進行上采樣時加入SENet(Squeeze-and-Excitation Network,即“壓縮和激勵”SE塊)。SE塊通過控制scale的大小,將一些重要特征進行增強,而對一些不重要的特征進行抑制,從而讓提取到的特征有更強的指向性。SE模塊的結構如圖5所示。
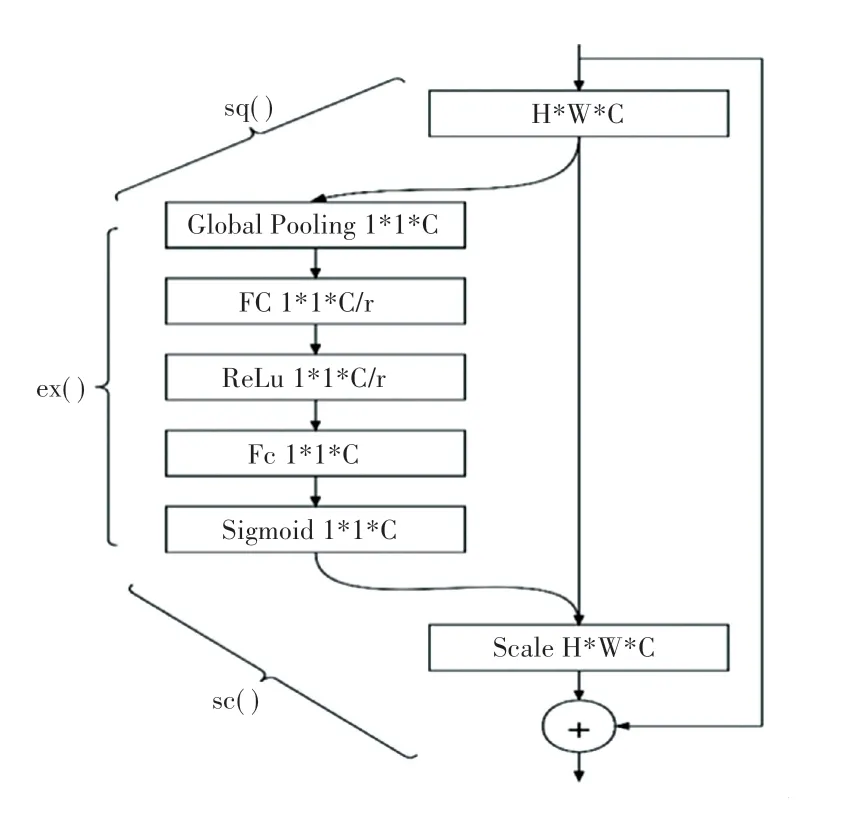
圖5 SE模塊結構圖Fig.5 SE module structure diagram
圖中:sq()代表Squeeze過程;ex()代表Excitation過程;sc()是將Excitation得到的結果作為權重,乘到輸入特征上。
3 實驗結果與分析
本次實驗環境配置中,軟件環境為:python3.6編程語言、CUDA版本為11.2、深度學習框架pytorch1.2;硬件環境配置:GPU為RTX1050,CPU為i7-7700HQ。通過標注和處理1521張來自BDD100K自動駕駛的圖片,構成本次實驗的數據集。
實驗中,將改進的YOLOv4-Efficient模型與YOLOv4模型、YOLOv4-tiny進行對比。在輸入圖片分辨率為416?416的情況下,通過精度()、參數量()、召回率()和平均準確率()等性能指標進行評價。計算公式如式(5)(6):

式中:為圖像中車的區域,預測為車的正確情況;為圖像中為車的區域,預測為不是車錯誤情況;為實際不是車的區域,但是預測此區域是車的情況。
將YOLOv4-Efficient與YOLOv4,YOLOv4-tiny模型進行對比測試,測試結果見表2。
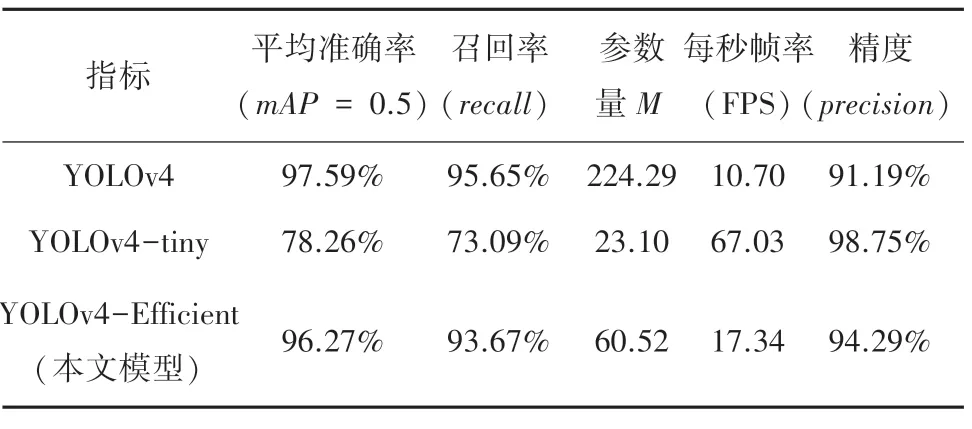
表2 模型檢測性能對比Tab.2 Performance comparison of models
通過表中數據可以看出,本文算法整體性要優于YOLOv4和YOLOv4-tiny。在平均準確率()和召回率()對比中,明顯高于YOLOv4-tiny;在參數量和精度方面要優于YOLOv4;在平均準確率和召回率方面略低于YOLOv4。進行綜合對比后,在減少近4倍的參數量后,仍然有較好的檢測性能。pr曲線和精度曲線如圖6~7所示。
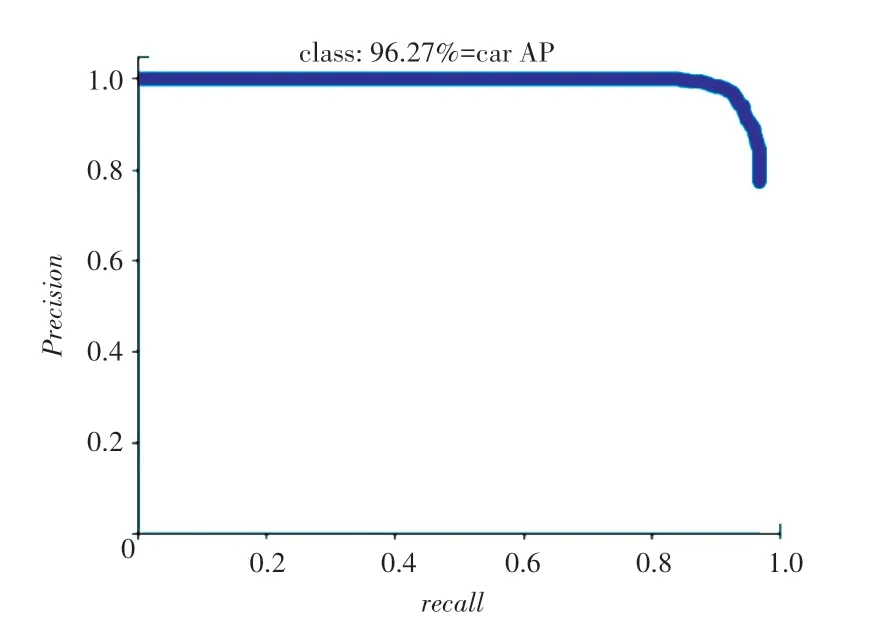
圖6 pr曲線Fig.6 Pr curve
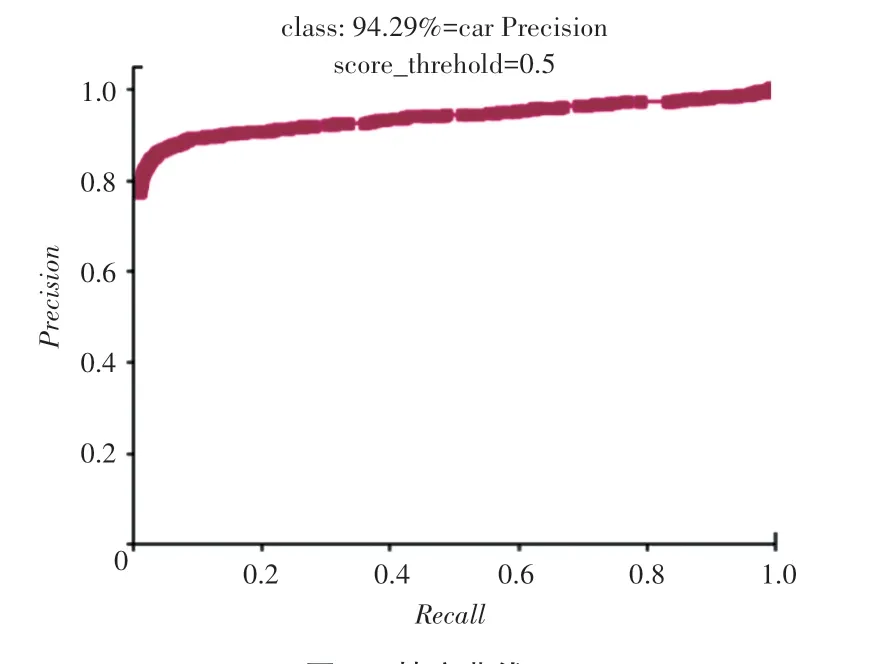
圖7 精度曲線Fig.7 Precision curve
利用YOLOv4-Efficient測試結果如圖8所示。

圖8 測試結果Fig.8 Test result
4 結束語
本文在YOLOv4的基礎上提出了一種輕量級的車輛檢測算法YOLOv4-Efficient,將YOLOv4的主干提取網絡改為EfficientNet-B2后,在保證檢測精度的情況下,減少了模型的參數量,提高了檢測速度。相比YOLOv4的參數量,改進后的模型參數量少了近4倍。經過實驗對比,在YOLOv4-Efficient對車輛的檢測中,參數量和精度方面要優于YOLOv4,其精度達到了94.29%,參數量也僅僅有60.52 M,改進后的模型更適合于移動端的設備。后期工作中,在提高模型數據量來增強魯棒性的同時,還要進一步研究在不同復雜環境和天氣下對目標的檢測。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
