基于Luong Attention機制和特征優(yōu)選策略的超短期負荷預(yù)測方法
2022-04-26 04:45:08劉立立唐子卓
電力系統(tǒng)及其自動化學(xué)報 2022年4期
劉立立,劉 洋,唐子卓
(四川大學(xué)電氣工程學(xué)院,成都 610065)
隨著高級量測技術(shù)的發(fā)展,用電信息除電力負荷數(shù)據(jù)外,還包括電壓、電流、水、氣、熱能耗等數(shù)據(jù)[1]。有效地利用多源異構(gòu)的數(shù)據(jù)信息進行精確的超短期負荷預(yù)測,對于實時發(fā)電計劃和電力市場清算價格的制定具有重要意義[2]。
近年來,以深度學(xué)習(xí)為代表的人工智能方法在學(xué)習(xí)數(shù)據(jù)深層特征方面表現(xiàn)出優(yōu)異的性能,其中循環(huán)神經(jīng)網(wǎng)絡(luò)RNN(recurrent neural network)相較其他神經(jīng)網(wǎng)絡(luò)能更好地對動態(tài)時序數(shù)據(jù)進行建模[3]。門控循環(huán)單元GRU(gated recurrent unit)神經(jīng)網(wǎng)絡(luò)和長短期記憶LSTM(long short term memory)神經(jīng)網(wǎng)絡(luò)通過引入特殊的門結(jié)構(gòu),可以進一步解決原始RNN中具有的梯度消失問題,被廣泛用于時序數(shù)據(jù)模型中[4-5]。文獻[5]指出GRU網(wǎng)絡(luò)相較LSTM網(wǎng)絡(luò)在保持較高預(yù)測精度的同時具有更高的計算效率,在負荷預(yù)測領(lǐng)域被廣泛使用。
但傳統(tǒng)GRU模型由于其在負荷預(yù)測任務(wù)中輸入序列和輸出序列長度的限制,一次只能預(yù)測一個時間步長,并在下次預(yù)測時更新網(wǎng)絡(luò)狀態(tài),這種序列到點的預(yù)測模式會極大程度上受到先前時間步長預(yù)測結(jié)果的影響[6],而且當(dāng)輸入的時間序列較長時,傳統(tǒng)GRU模型難以提取數(shù)據(jù)關(guān)鍵信息,模型預(yù)測精度仍然較低[7]。
此外,現(xiàn)有用電信息呈現(xiàn)出海量高維的特點,將全部特征變量輸入模型進行訓(xùn)練不僅會造成巨大的計算開銷,而且不相關(guān)的特征變量反而會對模型的預(yù)測精度產(chǎn)生負面作用[8]。現(xiàn)有負荷預(yù)測研究在進行輸入數(shù)據(jù)特征選擇時,多是通過特征變量與負荷數(shù)據(jù)之間的相關(guān)性分析或?qū)<医?jīng)驗判別,其選擇流程過于粗糙,易丟失影響負荷預(yù)測精度的關(guān)鍵特征變量[9]。
因此,本文提出一種基于Luong注意力LA(Luong attention)機制和特征優(yōu)選策略的超短期負荷預(yù)測方法。首先,以輕量型梯度提升機LightGBM(light gradient boosting machine)算法內(nèi)部的樹模型參數(shù)作為量化各個輸入特征重要度的評價指標(biāo),并通過后向搜索策略得到最利于模型訓(xùn)練的優(yōu)選特征集合;其次,通過序列到序列門控循環(huán)神經(jīng)網(wǎng)絡(luò)S2S-GRU(sequence-to-sequence gated recurrent unit)模型對輸入特征集合及目標(biāo)預(yù)測數(shù)據(jù)進行有監(jiān)督學(xué)習(xí),并引入LA機制對不同輸入步長賦予不同的權(quán)重,突出影響負荷預(yù)測精度的關(guān)鍵時間步長信息。本方法旨在獲取更適合預(yù)測模型學(xué)習(xí)的優(yōu)選特征集合,并通過改進模型結(jié)構(gòu)和引入LA機制,進而更準(zhǔn)確地預(yù)測負荷變化。算例結(jié)果表明,本文所提負荷預(yù)測方法在算法精度和算法效率上均具有優(yōu)越性。
1 輸入數(shù)據(jù)特征選擇
在基于深度學(xué)習(xí)的負荷預(yù)測任務(wù)中,首先需要對預(yù)測模型進行訓(xùn)練。本文訓(xùn)練樣本集D包括輸入數(shù)據(jù)變量和目標(biāo)預(yù)測變量。每個輸入數(shù)據(jù)變量可表示為矩陣x∈RT×F,包含歷史電力負荷數(shù)據(jù)及相關(guān)特征變量,α=1,2,…,T,β=1,2,…,F,其中T為輸入時間跨度,F(xiàn)為輸入數(shù)據(jù)的特征維度。輸入數(shù)據(jù)變量x定義為
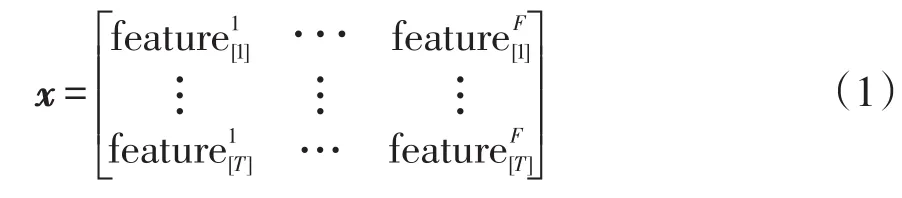
每個輸入數(shù)據(jù)變量對應(yīng)1個目標(biāo)預(yù)測變量y,y∈RN×1,其中N為預(yù)測時間跨度,target[N]為預(yù)測時間步長為N時的負荷值。目標(biāo)預(yù)測變量y定義為

輸入數(shù)據(jù)變量和目標(biāo)預(yù)測變量的對應(yīng)關(guān)系如圖1所示。對于訓(xùn)練樣本集的時間步長t,從t+1到t+T的連續(xù)負荷數(shù)據(jù)及相關(guān)特征變量生成1個輸入數(shù)據(jù)變量,t+T+1到t+T+N的負荷數(shù)據(jù)形成相應(yīng)的目標(biāo)預(yù)測變量。
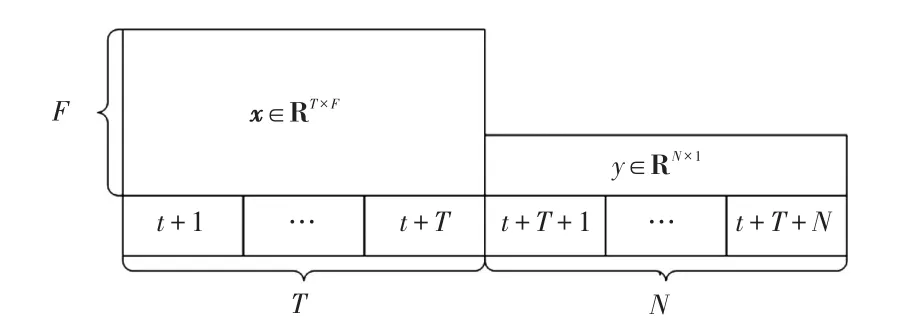
圖1 訓(xùn)練樣本數(shù)據(jù)Fig.1 Training sample data
為了降低輸入數(shù)據(jù)變量的特征冗余度,提高模型的學(xué)習(xí)能力,本文提出一種基于LightGBM的嵌入式特征選擇算法。首先通過LightGBM算法對訓(xùn)練樣本集中的輸入數(shù)據(jù)變量和目標(biāo)預(yù)測變量做回歸分析,然后利用其樹模型的內(nèi)部參數(shù)作為每個特征的重要度度量指標(biāo),最后通過后向搜索策略得到最優(yōu)的特征集合。該算法利用模型回歸分析的誤差作為選擇特征集合的評價指標(biāo),且其內(nèi)部結(jié)構(gòu)參數(shù)可作為特征重要性度量的依據(jù),同時兼顧了特征選擇的準(zhǔn)確性和高效性。
1.1 LightGBM算法
LightGBM算法在梯度提升決策樹[10]的基礎(chǔ)上,引入了梯度單邊采樣技術(shù)GOSS(gradient-based one-side sampling)和獨立特征合并技術(shù)MEF(merge exclusive features)[11]。GOSS 可以剔除很大一部分梯度較小的數(shù)據(jù),在保證信息增益的同時減小訓(xùn)練量,提高模型的泛化能力。MEF可以將互斥特征進行組合,以減少數(shù)據(jù)特征規(guī)模,提高模型的訓(xùn)練速度。


1.2 重要度度量指標(biāo)
LightGBM是基于樹模型的結(jié)構(gòu),算法在運行過程中,每層會貪心地選取1個特征分割點作為葉子節(jié)點,使在分割之后整棵樹增益值最大。在分割過程中,每個葉子節(jié)點的權(quán)重可以表示為w(gi,hi),其中g(shù)i和hi分別為

式中,訓(xùn)練誤差L(yi,f(xi))表示目標(biāo)變量yi和預(yù)測變量f(xi)之間的差距。根據(jù)所有葉子節(jié)點的權(quán)重,每個特征作為分割點的增益G為

式中:wle為葉子節(jié)點左子樹的總權(quán)值;wri為葉子節(jié)點右子樹的總權(quán)值;wnos為分割前的葉子節(jié)點的總權(quán)值。
在算法運行過程中特征分裂的次數(shù)越多,說明該特征給整棵樹帶來的正向增益越大,其特征重要度越高。因此,可以將分裂特征的次數(shù)B和特征平均增益Gave作為特征的重要性度量指標(biāo)。B和Gave的計算公式分別為

式中:X為所求特征被分割到所有葉子節(jié)點的集合;count()為計數(shù)函數(shù);GbX為集合X中第b個葉子節(jié)點由式(10)得到的在特征被分割時節(jié)點所獲得的增益。
1.3 輸入數(shù)據(jù)特征選擇整體流程
本文所提輸入數(shù)據(jù)特征選擇方法流程如圖2所示,具體步驟如下。
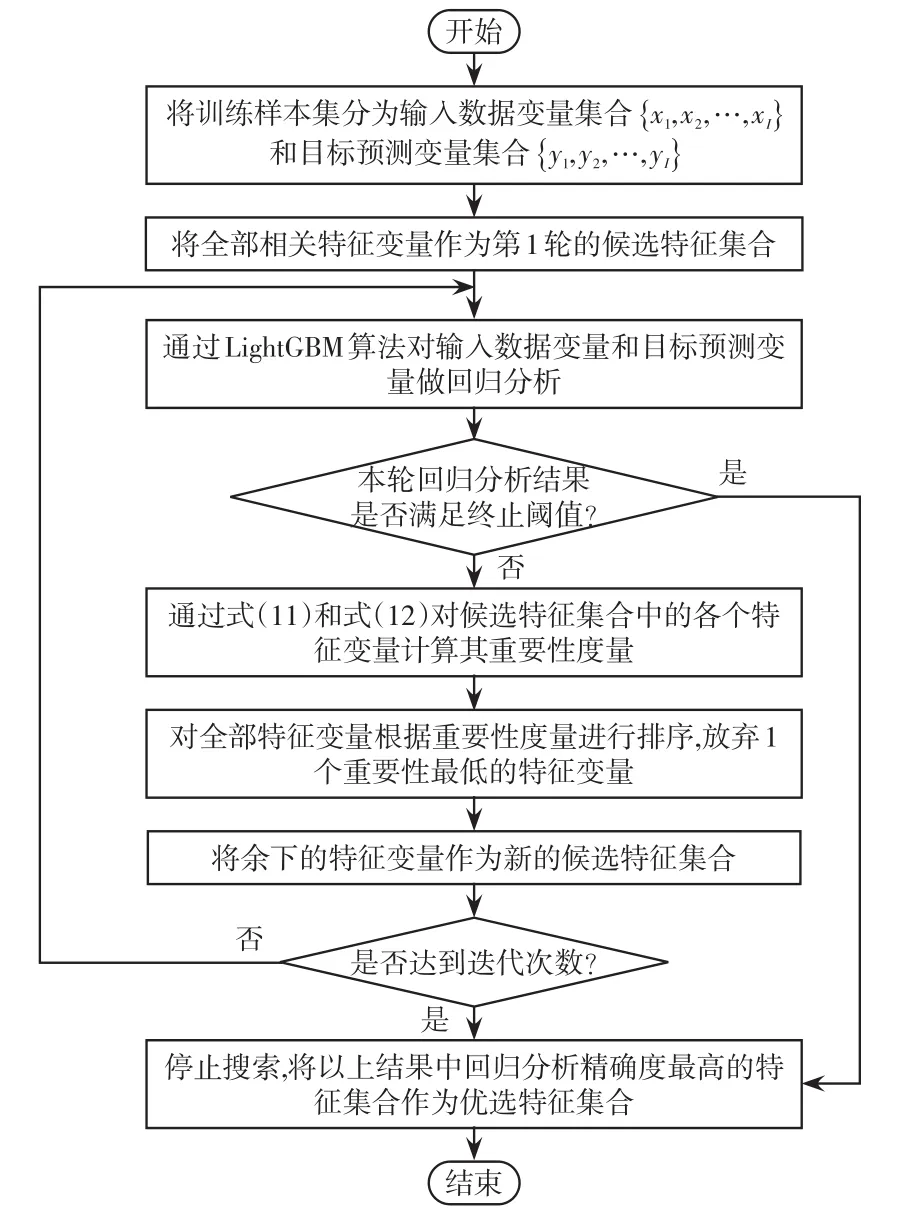
圖2 特征選擇算法框架Fig.2 Framework of feature selection algorithm
步驟1將訓(xùn)練樣本集分為輸入數(shù)據(jù)變量集合{x1,x2,…,xI}和目標(biāo)預(yù)測變量集合{y1,y2,…,yI}。
步驟2通過LightGBM對訓(xùn)練樣本集中的輸入數(shù)據(jù)變量和目標(biāo)預(yù)測變量做回歸分析。
步驟3將式(11)和式(12)的評價值作為每個特征的重要性度量指標(biāo),按照重要性度量指標(biāo)對特征進行排序,并舍棄1個重要性最低的特征變量,將余下的特征變量作為新的候選特征集合。
步驟4從完整的特征集合開始,重復(fù)進行步驟1~3直至LightGBM算法做回歸分析的結(jié)果滿足終止閾值或達到迭代次數(shù)。
步驟5將上述輪次中回歸分析準(zhǔn)確率最高的特征集合作為最終優(yōu)選特征集合,回歸分析的準(zhǔn)確率評價指標(biāo)采用平均絕對誤差MAE(mean absolute error)評價函數(shù)。
2 基于LA機制S2S-GRU負荷預(yù)測模型
2.1 S2S-GRU模型結(jié)構(gòu)
S2S模型是一種通用的編碼-解碼框架[12],在本文中編碼器和解碼器由GRU神經(jīng)元構(gòu)成[5]。S2S模型可以將1個原始序列通過編碼和解碼2個步驟轉(zhuǎn)換到另1個序列,可以更好地學(xué)習(xí)數(shù)據(jù)之間的時序關(guān)系,避免傳統(tǒng)GRU模型序列到點學(xué)習(xí)模式的缺陷,其結(jié)構(gòu)如圖3所示。
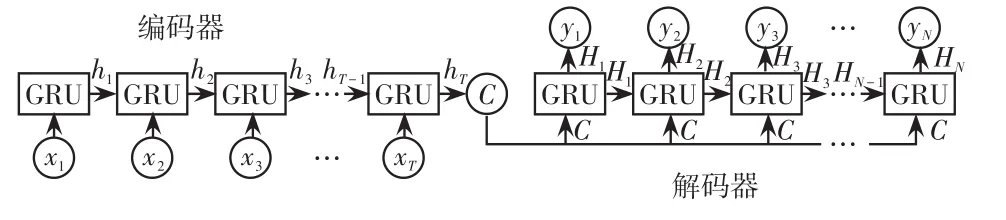
圖3 S2S-GRU模型示意Fig.3 Schematic of S2S-GRU model
2.2 LA機制
在傳統(tǒng)S2S模型中,編碼端將輸入序列中的所有信息壓縮在固定的中間變量C中,所有時刻的輸入對輸出均具有相同的影響權(quán)值,使得整個模型的信息處理能力受到限制。本文在傳統(tǒng)S2S模型中進一步引入LA機制[13],該機制能夠通過動態(tài)可變的中間變量Cn對輸入數(shù)據(jù)賦予不同的影響權(quán)重,使得模型在解碼的各個時刻有不同的側(cè)重點,提升對于信息的利用能力。LA機制在解碼層時間步長n下的示意如圖4所示,其中⊕表示變量之間的關(guān)聯(lián)。
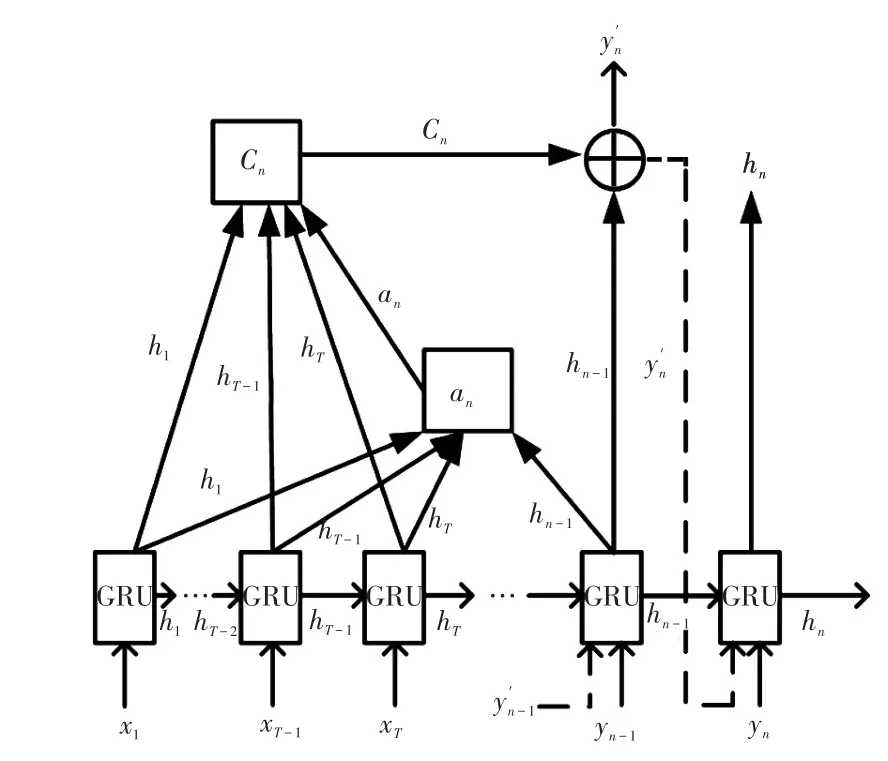
圖4 LA機制示意Fig.4 Schematic of LA mechanism
編碼層的隱含層狀態(tài)hn和輸出在時間步長n下的計算公式分別為

式中:[·]表示變量的連接;f為GRU細胞單元;g為Softmax函數(shù);中間變量Cn是編碼器隱藏狀態(tài)的加權(quán)和,即

式中,αnj為編碼層時間步長j下輸入的隱藏層狀態(tài)對解碼層時間步長n下輸出的注意力權(quán)重。αnj的計算公式為

式中,enm和enj分別為編碼層時間步長m、j下輸入的隱藏層狀態(tài)對解碼層時間步長n下輸出的注意力值。enj的計算公式為

式中,S為對齊函數(shù),用來計算編碼層時間步長j下輸入的隱藏層狀態(tài)對解碼層時間步長n下輸出的相關(guān)程度。
2.3 本文整體預(yù)測流程
本文的超短期負荷預(yù)測方法的總體實施過程如圖5所示。過程主要分為訓(xùn)練樣本及測試樣本生成、輸入數(shù)據(jù)特征選擇、預(yù)測模型訓(xùn)練及預(yù)測3部分。訓(xùn)練樣本生成通過數(shù)據(jù)分段的方式,測試樣本的生成過程采用滑動窗口的方式,以使不同的測試樣本不重疊。輸入數(shù)據(jù)特征選擇方法采用本文所提的基于LightGBM的嵌入式特征選擇算法,對輸入特征變量進行篩選后得到優(yōu)選特征集合。負荷預(yù)測模型采用本文所提的基于LA機制S2S-GRU負荷預(yù)測模型,通過對優(yōu)選特征集合和目標(biāo)預(yù)測變量進行訓(xùn)練,并將測試樣本集輸入訓(xùn)練完成的預(yù)測模型得到最終的超短期負荷預(yù)測結(jié)果。
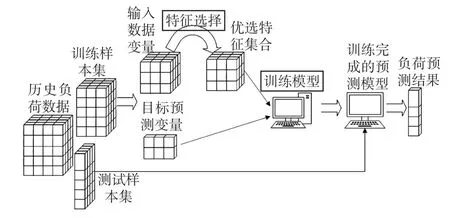
圖5 算法實施過程示意Fig.5 Schematic of algorithm implementation process
3 實例分析
本文選取加州大學(xué)歐文分校UCI(University of California Irvine)數(shù)據(jù)庫中的“Individual household electric power consumption Data Set”[14]作為實驗數(shù)據(jù)集。該數(shù)據(jù)集是1個多特征時間序列數(shù)據(jù)集,描述1個用戶從2006年12月—2010年11月期間收集到的用電信息。本文實驗選取其中2009年11月—2010年11月每天48個采集點的用電信息,數(shù)據(jù)共有8個時序特征變量,包括家庭總有功能耗(kW)、家庭總無功能耗(kVar)、電壓(V)、電流(A)、廚房的有功能耗(kW)、洗衣房的有功能耗(kW)、氣候控制系統(tǒng)的有功能耗(kW)、其他有功能耗(kW),其中家庭總有功能耗為本文負荷預(yù)測實驗的目標(biāo)預(yù)測數(shù)據(jù)。
超短期負荷預(yù)測一般指當(dāng)前時刻往后1 h內(nèi)的負荷預(yù)測,本文針對當(dāng)前時刻后30 min的負荷點進行預(yù)測,由于待預(yù)測時刻負荷數(shù)據(jù)通常與前1天負荷具有較強的相關(guān)性,因此本文實驗設(shè)置輸入時間跨度T為48,預(yù)測時間跨度N為1。此外,超短期負荷預(yù)測任務(wù)的待預(yù)測樣本點較少,難以體現(xiàn)負荷預(yù)測模型的效果,因此本文通過迭代預(yù)測的方法,針對連續(xù)7 d的負荷數(shù)據(jù)進行預(yù)測,以展現(xiàn)本文負荷預(yù)測模型實驗效果的統(tǒng)計特性。
首先將本文所提特征選擇方法與基于最大信息系數(shù)MIC(maximum information coefficient)的特征選擇方法[15]、基于XGBoost的特征選擇方法[16]進行對比,以驗證本文所提特征選擇方法的先進性;其次將本文所提負荷預(yù)測模型與LSTM、GRU、S2SLSTM、S2S-GRU、S2S-LSTM+LA進行對比,以驗證本文負荷預(yù)測模型的先進性。
假設(shè)S2S模型的編碼層的隱含層大小設(shè)置為[F,64],其中F為輸入特征維度,解碼層的隱含層為[65,64]。LA中對齊函數(shù)S選用dot-product函數(shù)。傳統(tǒng)LSTM、GRU模型的隱含層為[F,64],所有深度學(xué)習(xí)模型的學(xué)習(xí)率為0.001,批處理參數(shù)為256,迭代次數(shù)為100次。
3.1 實驗環(huán)境和評價指標(biāo)設(shè)置
本文實驗通過Python實現(xiàn),采用PyTorch作為深度學(xué)習(xí)框架,具體實驗環(huán)境信息包括處理器Intel(R)Core(TM)i5-4210U CPU@1.70 GHz、內(nèi)存6 GB、硬盤500 GB、操作系統(tǒng)Windows10、Python版本3.6.0、PyTorch版本1.1.0。
誤差指標(biāo)采用MAE和平均絕對百分比誤差MAPE(mean absolute percentage error),計算公式分別為
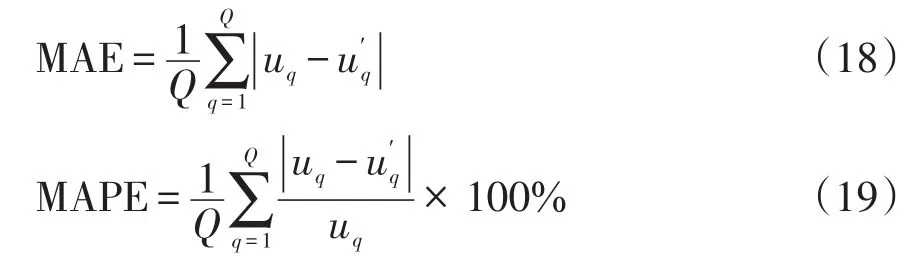
式中:Q為預(yù)測點個數(shù);uq為第q點的實際負荷值;為第q點的預(yù)測負荷值。指標(biāo)值越小表示模型預(yù)測精度越高。
3.2 不同特征選擇算法效果對比
本文所提特征選擇算法超參數(shù)的設(shè)置通過多次實驗獲取,本實驗設(shè)置模型的學(xué)習(xí)率為0.05,決策樹的最大分割次數(shù)為200次,訓(xùn)練樣本和測試樣本的比例與本文負荷預(yù)測模型相同。MIC特征選擇算法選取MIC系數(shù)大于0.5的特征作為優(yōu)選特征集合;基于XGBoost的特征選擇算法的超參數(shù)設(shè)置與基于LightGBM的特征選擇算法相同。模型訓(xùn)練樣本為2009年11月—2010年10月的數(shù)據(jù)信息,測試樣本為2010年11月7日—2010年11月14日的數(shù)據(jù)信息。
首先分別通過3種算法得到優(yōu)選特征集合,然后將優(yōu)選特征集合中的數(shù)據(jù)作為輸入特征變量輸入所有負荷預(yù)測模型進行負荷預(yù)測。本文所提特征選擇方法得到的優(yōu)選特征集合為[家庭總有功能耗,電流]。基于MIC的特征選擇算法得到的優(yōu)選特征集合為[家庭總有功能耗,電流,氣候控制系統(tǒng)的有功能耗,其他有功能耗]。基于XGBoost特征選擇方法得到的優(yōu)選特征集合為[家庭總有功能耗]。分別測試不同輸入特征集合作為模型輸入數(shù)據(jù)的負荷預(yù)測結(jié)果,MAE、MAPE指標(biāo)如圖6所示。不同特征選擇算法在S2S-GRU+LA模型的預(yù)測結(jié)果如圖7所示。
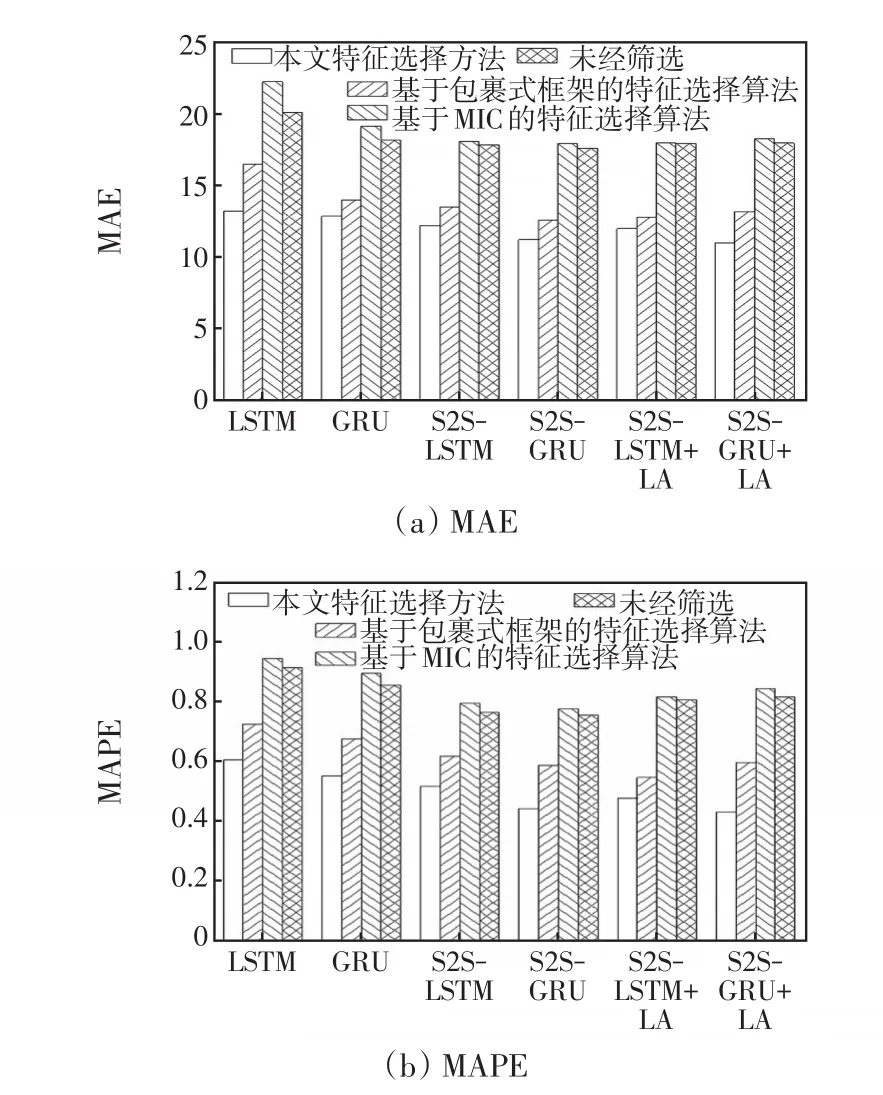
圖6 特征選擇算法對比Fig.6 Comparison among feature selection algorithms
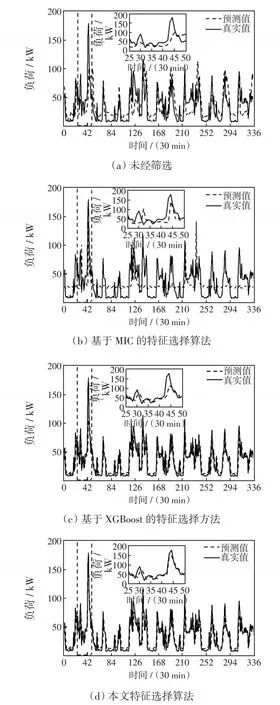
圖7 不同特征選擇算法下負荷預(yù)測結(jié)果對比Fig.7 Comparison of load forecasting results among different feature selection algorithms
可以看出,不同特征變量集合得到的負荷預(yù)測結(jié)果存在較大差異,未經(jīng)選擇的特征變量集合其負荷預(yù)測結(jié)果存在較大波動;經(jīng)基于XGBoost特征選擇算法選取后的單一特征變量所能提供的信息量較少;基于MIC特征選擇算法只考慮了變量和負荷數(shù)據(jù)之間的相關(guān)性,沒有考慮到特征集合對預(yù)測模型的綜合影響;而本文的特征選擇算法考慮了特征變量之間的綜合影響,選取了對負荷預(yù)測模型增益最大的特征集合,其選擇后的特征集合最有利于模型進行負荷預(yù)測。
此外,對比不同特征選擇算法的計算效率,本文特征選擇算法的平均計算時間為23.87 s,基于MIC的特征選擇算法和基于XGBoost的特征選擇方法的平均計算時間分別為226.21 s、47.32 s。可以看出,本文所提特征選擇算法在算法效率上也具有明顯優(yōu)勢。
3.3 不同負荷預(yù)測模型對比
對所有6種負荷預(yù)測模型進行超短期負荷預(yù)測實驗,驗證本文所提模型的精度優(yōu)勢。設(shè)定輸入變量為經(jīng)過本文特征選擇算法選擇后的優(yōu)選特征集合,模型訓(xùn)練樣本為2009年11月—2010年10月的數(shù)據(jù)信息,采用負荷預(yù)測模型對連續(xù)7 d(2010年11月7日—2010年11月14日)的負荷數(shù)據(jù)進行超短期負荷預(yù)測,不同模型實驗結(jié)果的MAE、MAPE值如圖8所示。
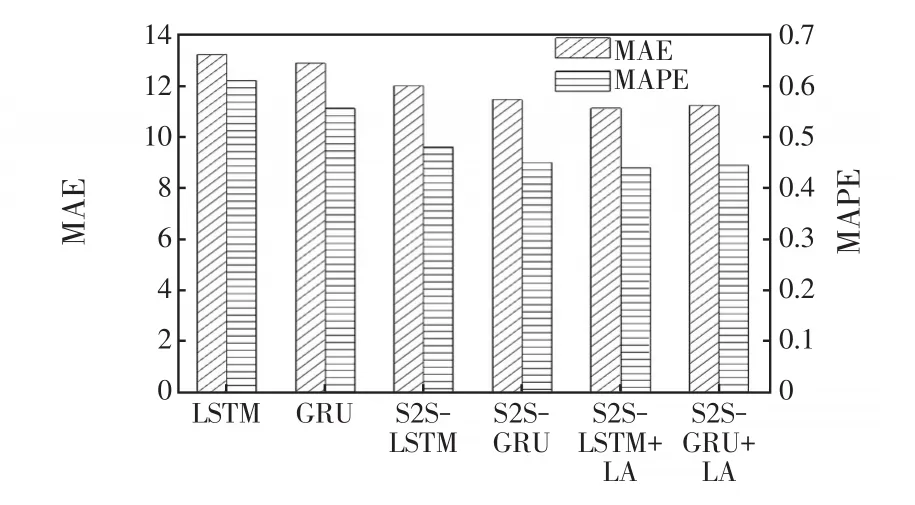
圖8 不同負荷預(yù)測模型對比Fig.8 Comparison among different load forecasting models
由圖8可知,S2S模型相較LSTM、GRU模型具有明顯的預(yù)測精度優(yōu)勢,這是由于S2S模型可以有效降低負荷的隨機波動特性對模型預(yù)測過程的影響,而LA機制可以突出影響負荷預(yù)測精度的關(guān)鍵時間步長信息,進一步提高模型的預(yù)測精度。另一方面,LSTM類模型和GRU類模型的預(yù)測精度較為接近,說明GRU類模型雖然相較LSTM類模型簡化了網(wǎng)絡(luò)結(jié)構(gòu),但其依舊保持了較強的時序數(shù)據(jù)學(xué)習(xí)能力。
對比不同負荷預(yù)測模型的計算效率,引入LA機制前后的預(yù)測模型的訓(xùn)練收斂速度如圖9所示。在負荷預(yù)測模型訓(xùn)練達到收斂狀態(tài)時,GRU迭代次數(shù)為57,S2S-GRU迭代次數(shù)為81,而S2SGRU+LA的迭代次數(shù)僅為41,其算法收斂速度顯著提升。可以看出,引入LA機制可以明顯提升預(yù)測模型對時序數(shù)據(jù)關(guān)聯(lián)特性的學(xué)習(xí)能力。
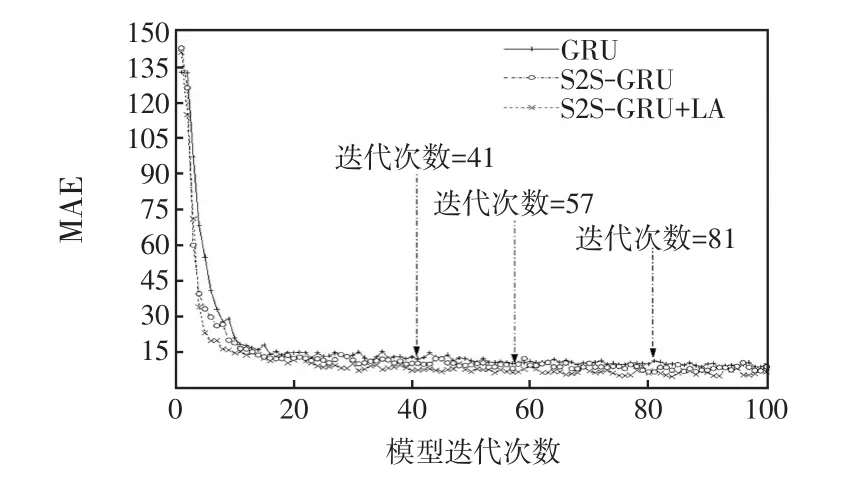
圖9 不同算法收斂速度對比Fig.9 Comparison of convergence rate among different algorithms
此外,對比各個負荷預(yù)測模型的單次訓(xùn)練時長和總體預(yù)測時長如表1所示。可以看出,S2S模型的單次訓(xùn)練時長相較LSTM/GRU模型無明顯增加,LA機制會使得S2S模型的單次訓(xùn)練時長平均增加16.9%。但是LA機制彌補了S2S模型訓(xùn)練收斂速度慢的不足,有效節(jié)約了模型的總訓(xùn)練時長,總體運算效率有顯著提升。GRU類模型相較LSTM類模型因其簡化了門結(jié)構(gòu),可以在保持較高學(xué)習(xí)精度的同時具有較高的計算效率。
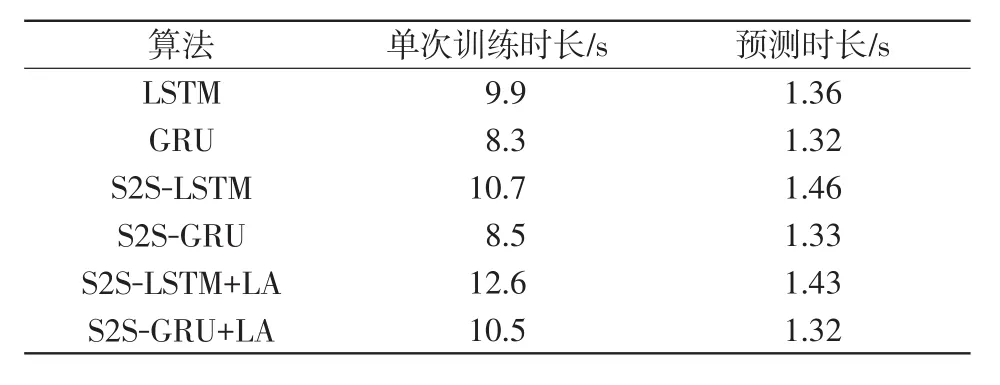
表1 不同算法單次訓(xùn)練時長對比Tab.1 Comparison of single training time among different algorithms
4 結(jié)論
(1)基于LightGBM算法的嵌入式特征選擇方法與基于MIC的特征選擇方法、基于XGBoost的特征選擇方法相比,本文方法具有更高的效率,且經(jīng)過篩選后的優(yōu)選特征可以有效提高負荷預(yù)測精度。
(2)S2S-LSTM/GRU+LA模型在算法精度上的表現(xiàn)均優(yōu)于傳統(tǒng)LSTM、GRU和S2S-LSTM/GRU模型,GRU類模型在保持高預(yù)測精度的同時較LSTM類模型具有更高的計算效率,且引入LA機制可以進一步提高模型的收斂性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
