基于循環(huán)神經(jīng)網(wǎng)絡(luò)的砂土液化預(yù)測模型
2022-04-26 07:07:40呂俊超俞社鑫
四川建材 2022年4期
關(guān)鍵詞:模型
呂俊超,俞社鑫,周 淵
(江西理工大學(xué) 土木與測繪工程學(xué)院,江西 贛州 341000)
0 前 言
液化是飽和非黏性土在地震等動力荷載作用下抗剪強度快速降低的結(jié)果。地震液化引起的噴砂冒水、側(cè)向位移、地基下沉、地面隆起和結(jié)構(gòu)物上浮現(xiàn)象,是橋梁破壞、壩基失穩(wěn)等地震災(zāi)害的主要來源。因此,準(zhǔn)確評價和預(yù)測液化是巖土工程領(lǐng)域研究的重要問題之一。
多年來,標(biāo)準(zhǔn)貫入試驗常用于建立各類基于地震液化數(shù)據(jù)的預(yù)測方法。基于SPT的液化判別方法主要分為兩大類:①傳統(tǒng)的經(jīng)驗方法;②數(shù)據(jù)驅(qū)動的統(tǒng)計方法。其中經(jīng)驗方法主要包括液化循環(huán)阻力法[1]和臨界孔隙比法[2]等。統(tǒng)計方法主要包括決策樹[3]、貝葉斯網(wǎng)絡(luò)[4]和logistic回歸[5-6]。由于地震作用的隨機性、土性參數(shù)的不確定性以及參數(shù)與液化判別結(jié)果之間高度的非線性關(guān)系,因此,很難選擇合適的經(jīng)驗方程進行回歸分析。近年來,基于機器學(xué)習(xí)[7-9]的研究方法在地震液化判別的應(yīng)用逐漸興起,如:Lee等[10]提出了一種基于SVM的地震液化預(yù)測模型;Karthikeyan等[11]我國臺灣以集集地震的SPT數(shù)據(jù)為基礎(chǔ),將相關(guān)向量機方法應(yīng)用于砂土液化勢預(yù)測問題。Hoang等[12]通過對現(xiàn)有液化數(shù)據(jù)進行學(xué)習(xí)和訓(xùn)練,將Fisher判別理論和最小二乘支持向量機相結(jié)合建立了砂土地震液化的KFDA-LSSVM預(yù)測模型。毛立勇等[13]在探討砂土液化主要影響因素以及SVM最優(yōu)參數(shù)的選擇基礎(chǔ)上,采用Adaboost 算法確定預(yù)測器,建立了GA_SVM_Adaboost 砂土地震液化預(yù)測模型。雖然支持向量機能處理包含定性變量的訓(xùn)練學(xué)習(xí),但其需多次進行核函數(shù)的選擇、核函數(shù)參數(shù)的選擇以及正則化參數(shù)的選擇以確定最優(yōu)參數(shù),導(dǎo)致工作量增加且耗費大量時間。
循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)是一類非常強大的用于處理和預(yù)測序列數(shù)據(jù)的神經(jīng)網(wǎng)絡(luò)模型。循環(huán)結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò)克服了傳統(tǒng)機器學(xué)習(xí)方法對輸入和輸出數(shù)據(jù)的許多限制,使其成為深度學(xué)習(xí)領(lǐng)域中一類非常重要的模型。而地震液化判別正是一種復(fù)雜的序列分類問題,涉及地震學(xué)、地形和巖土參數(shù)。因此,針對地震液化判別序列數(shù)據(jù),提出了一種基于RNN循環(huán)神經(jīng)網(wǎng)絡(luò)模型的預(yù)測方法,包括3層(輸入層、隱藏層和輸出層)網(wǎng)絡(luò)結(jié)構(gòu)的詳細設(shè)計以及網(wǎng)絡(luò)訓(xùn)練和網(wǎng)絡(luò)預(yù)測的實現(xiàn)算法。在此基礎(chǔ)上,為提高預(yù)測模型的準(zhǔn)確性,進一步提出了基于自適應(yīng)的RNN預(yù)測模型參數(shù)優(yōu)選算法。應(yīng)用Hanna等[14]建立的72個SPT實測場地(620個數(shù)據(jù)樣本)液化數(shù)據(jù)展開實驗,利用多個評價指標(biāo)驗證該循環(huán)神經(jīng)網(wǎng)絡(luò)模型的準(zhǔn)確性,并與Adam-RNN和SVM模型進行了對比分析。
1 RNN及自適應(yīng)算法
1.1 RNN
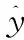
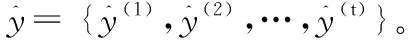
h(t)=f(Ux(t)+Wh(t-1)+b)
(1)
式中,f(·)是激活函數(shù),它通常是sigmoid函數(shù);b為偏差值。因此,最終輸出層的輸出可以表示為:
(2)
1.2 自適應(yīng)優(yōu)化算法
Adam是一種自適應(yīng)的學(xué)習(xí)方法,該算法使用了自適應(yīng)學(xué)習(xí)率的功能來找到每個參數(shù)的單獨學(xué)習(xí)率。傳統(tǒng)的梯度隨機下降保持單一的學(xué)習(xí)率η對參數(shù)進行更新,而Adam 算法會根據(jù)損失函數(shù)計算梯度的一階矩估計和二階矩估計來為不同參數(shù)提供獨立的自適應(yīng)性學(xué)習(xí)率。
Adam算法結(jié)合了動量算法和均方根反向傳播RMSProp(Root Mean Square Prop)算法的優(yōu)點。而Rectified Adam算法[15]具有收斂快、精度高的特點,可以看做Adam算法的一種修正。
2 地震液化循環(huán)神經(jīng)網(wǎng)絡(luò)的建立
2.1 研究數(shù)據(jù)
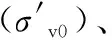
2.2 RA-RNN預(yù)測模型
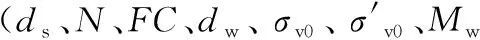
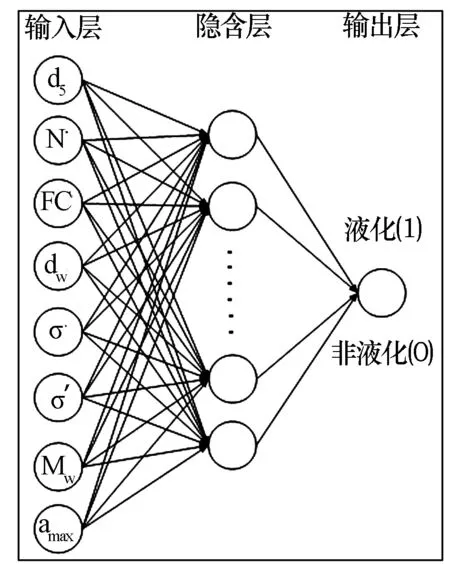
圖1 RA-RNN模型的最優(yōu)結(jié)構(gòu)
3 算例分析
3.1 RA-RNN模型參數(shù)選擇
為驗證RA-RNN 模型的合理性,采用變量控制的方法分別對RNN的學(xué)習(xí)率和隱藏層神經(jīng)元個數(shù)進行分析,使用總體精度(ACC)對模型的預(yù)測性能進行評價,該指標(biāo)反映液化樣本和非液化樣本被正確識別的比例。分析結(jié)果如表1所示。
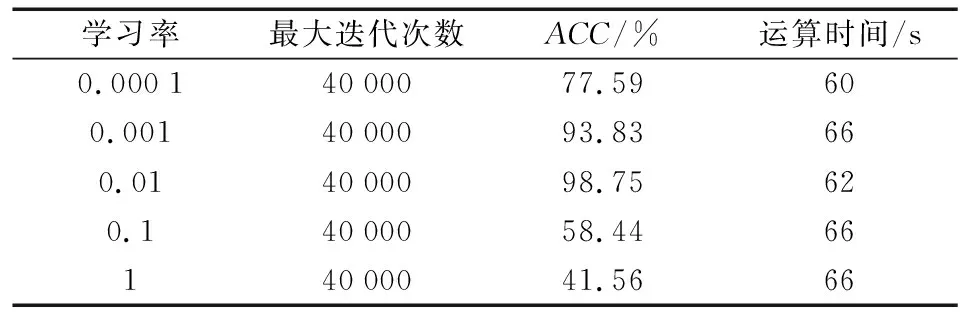
表1 不同學(xué)習(xí)率RNN總體精度統(tǒng)計
由表1可知,在保證其余變量相同的情況下,隨著RNN學(xué)習(xí)率的增加,ACC有明顯提升。當(dāng)學(xué)習(xí)率為0.01時,相較于學(xué)習(xí)率為0.001時的93.83%,模型在保證總體精度的情況下,運算時長縮短了2 s。但在RNN學(xué)習(xí)率增至0.1時其值降至58.44%,總體精度明顯下降。在循環(huán)網(wǎng)絡(luò)中,適當(dāng)增加學(xué)習(xí)率可以減少運算時間,加快模型的收斂速度,但學(xué)習(xí)率過高會造成參數(shù)的更新幅度過大,模型難以收斂,因此本文采用學(xué)習(xí)率為0.001的RNN效果最佳。
表2為學(xué)習(xí)率取0.001時不同神經(jīng)元個數(shù)RNN的總體精度。由表2可知,在學(xué)習(xí)率為0.001、神經(jīng)元個數(shù)為20時,ACC為98.43%,計算時長為62 s,為綜合最佳;繼續(xù)增加神經(jīng)元個數(shù)后性能提升不明顯,但計算時長有所增長。因此,最后模型達到輸入層8維、隱藏層20維、輸出層1維的框架結(jié)構(gòu)。
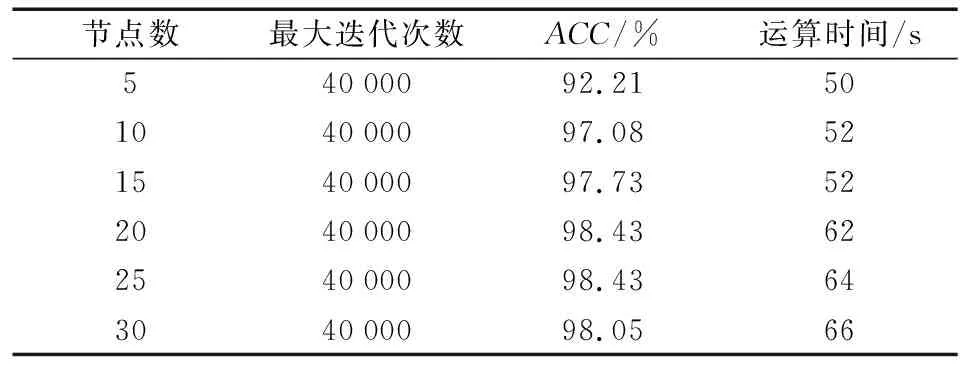
表2 不同隱藏層節(jié)點RNN總體精度統(tǒng)計
3.2 計算結(jié)果分析
為了突出本文算法在液化判別精度方面的優(yōu)勢,采用Adam-RNN模型以及SVM模型與本文提出的RA-RNN模型進行對比,在多次實驗后,記錄每種模型在測試集上的最優(yōu)預(yù)測結(jié)果,如表3所示,其中Adam-RNN模型與SVM模型均在Matlab中實現(xiàn)。Adam-RNN模型采用深度學(xué)習(xí)的優(yōu)化器Adam進行訓(xùn)練,而SVM模型采用徑向基核函數(shù),由于該模型的預(yù)測結(jié)果很大程度上受到核參數(shù)以及懲罰因子的影響,因此,經(jīng)反復(fù)多次實驗后根據(jù)在測試集上的預(yù)測結(jié)果確定該模型的最優(yōu)參數(shù)。
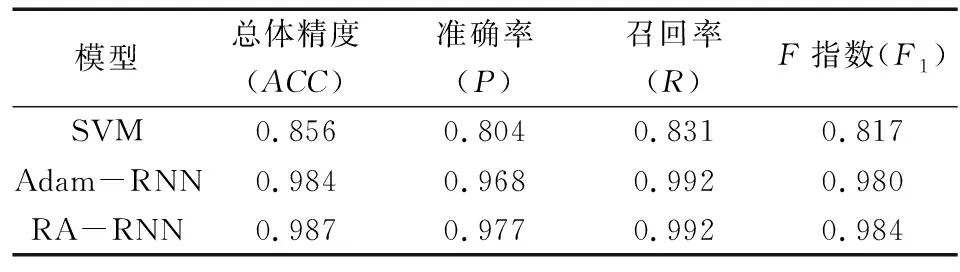
表3 不同模型預(yù)測結(jié)果對比
從表3可看出,由于循環(huán)神經(jīng)網(wǎng)絡(luò)RNN可以很好地把握液化判別結(jié)果與輸入?yún)?shù)之間的非線性關(guān)系,Adam-RNN模型和RA-RNN模型與SVM模型相比,有較高的預(yù)測精度,其中,Adam-RNN模型和RA-RNN模型的ACC分別為0.984和0.987,與SVM相比,分別提升了12.8%和13.1%。對于F測度而言,Adam-RNN模型和RA-RNN模型的準(zhǔn)確率P、召回率R和F1值也都要高于SVM模型。因此,Adam-RNN模型和RA-RNN模型的學(xué)習(xí)效果要好于SVM模型。此外,Adam-RNN模型和RA-RNN模型的召回率均為0.992,這說明兩個模型對于液化樣本的識別能力相當(dāng)。除召回率外,RA-RNN模型的總體精度ACC、準(zhǔn)確率P和F1值均略高于Adam模型,突出了考慮Rectified Adam優(yōu)化的RA-RNN模型的預(yù)測優(yōu)勢。
3.3 輸入?yún)?shù)影響程度研究
如上文所述,地震液化判別是一種復(fù)雜的序列分類問題,涉及地震學(xué)、地形和巖土參數(shù)。為研究基于SPT 獲得的8個參數(shù)對于神經(jīng)網(wǎng)絡(luò)的總體精度影響程度,并探究是否可以在不影響總體精度的情況下通過減少輸入?yún)?shù)的數(shù)目來簡化神經(jīng)網(wǎng)絡(luò),開展了以下試驗。根據(jù)不同的參數(shù)組合,建立了8種神經(jīng)網(wǎng)絡(luò)模型,如表4所示,每種模型分別去掉了一個參數(shù)用以檢驗缺失該參數(shù)情況下的網(wǎng)絡(luò)總體精度,如果去掉某參數(shù)后預(yù)測總體精度下降越大則說明該參數(shù)越重要,反之則說明不重要,可考慮簡化網(wǎng)絡(luò)結(jié)構(gòu)。
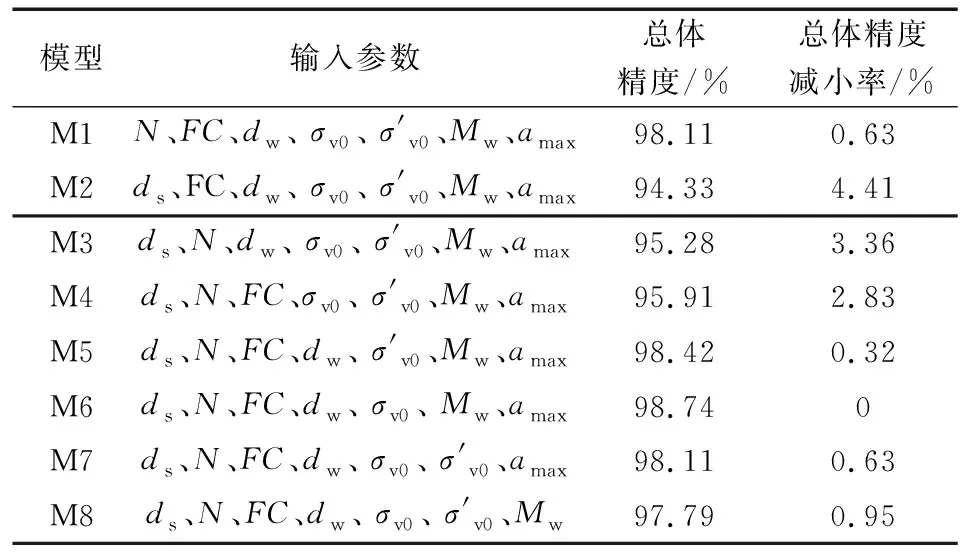
表4 輸入?yún)?shù)研究
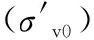
地震震級(Mw)和地表歸一化峰值水平加速度(amax)均表示了地震的作用強度,是地震液化問題必不可少的參數(shù)。其中,地震震級表示了地震整體烈度,若震源較深或者研究區(qū)距離震中很遠則無法明確地對表征地震。而地表歸一化峰值水平加速度表示了研究區(qū)地表受地震影響的程度,相對震級來說更加能夠表征地震作用強度,因此,缺失了地表歸一化峰值水平加速度后總體精度下降程度高于缺失地震震級。其余幾個參數(shù)均表示了研究區(qū)沉積物物理力學(xué)性質(zhì),地下水位、細粒含量、標(biāo)準(zhǔn)擊數(shù)對總體進度的影響程度依次增高表明了從中可獲得的沉積物物理力學(xué)性質(zhì)的表征程度依次增高。
4 結(jié) 論
本文基于SPT測試的場地液化震害勘測點數(shù)據(jù),采用精度更高的RNN循環(huán)神經(jīng)網(wǎng)絡(luò)對地震液化判別序列數(shù)據(jù)進行預(yù)測,模型能夠?qū)W習(xí)地震、地形、巖土參數(shù)與地震液化之間復(fù)雜的相互關(guān)系,結(jié)果表明所提出的RNN預(yù)測模型及其參數(shù)優(yōu)選算法在地震液化判別序列預(yù)測中具有優(yōu)越性。主要結(jié)論如下。
1)利用改進自適應(yīng)算法優(yōu)化RNN結(jié)構(gòu),建立的地震液化RA-RNN預(yù)測模型,Rectified Adam算法的引入,降低了手動工作量的同時提高了模型的準(zhǔn)確性。
2)在砂土地震液化預(yù)測中,RA-RNN模型具有較好的穩(wěn)定性和較高的準(zhǔn)確率,且預(yù)測效果優(yōu)于Adam-RNN和SVM模型。當(dāng)RA-RNN模型達到輸入層8維、隱藏層20維、輸出層1維、學(xué)習(xí)率為0.01時預(yù)測效果最好。
3)在選取的8個不同影響因素中,標(biāo)貫擊數(shù)和細粒含量對循環(huán)神經(jīng)網(wǎng)絡(luò)預(yù)測結(jié)果影響較其他參數(shù)最為敏感,在液化判別中起著重要的作用;有效垂向應(yīng)力對結(jié)果總體精度影響最小,可簡化網(wǎng)絡(luò)結(jié)構(gòu)。
[ID:012950]
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
