圖像均衡化與FaceNet算法相結合的方法研究
2022-04-24 09:58:50王欣汪寧于曉昀公安部第一研究所
警察技術 2022年2期
王欣 汪寧 于曉昀 公安部第一研究所
引言
迄今為止,計算機人臉識別的準確性依然受到光照條件等因素的影響,特別在公安實戰(zhàn)環(huán)境下,由于受到光照以及攝像頭角度等因素影響,獲取的線索照片一般比較模糊,質(zhì)量不高,降低了識別率,影響了實戰(zhàn)應用效果[1]。因此,本文提出了圖像均衡化與FaceNet算法相結合的方法,用于提升光線不足、過曝等圖像的識別準確率。
一、研究現(xiàn)狀
人臉識別的研究始于20世紀60年代,人臉識別因其便捷、高效、易普及的優(yōu)點成為最受關注的研究問題之一[2]。
人臉識別的方法主要分為四類,分別是神經(jīng)網(wǎng)絡方法、稀疏表示方法、子空間方法、基于三維形變模型的方法[3]。
稀疏矩陣標識方法,其中稀疏標識在一個含有大量訓練樣本的空間,樣本可以由空間的同類樣本線性表示,并可通過將噪聲考慮在內(nèi),增加算法的魯棒性。
子空間方法是通過尋找映射矩陣,將原始高維樣本映射至低維空間,同時樣本結構保持不變。但子空間算法常常會發(fā)生“小樣本問題”。
因為人臉是三維結構,所以采用三維形變模型可以更好的表示人臉,但三維形變模型理論不是很完善,還有很多問題需要研究。
近年來,基于深度學習的人臉識別方法受到了廣泛研究。使用深度學習進修人臉識別的早期,研究人員傾向于使用多個深度卷積神經(jīng)網(wǎng)絡提取人臉特征,再進行融合。而基于深度學習的人臉識別方法的趨勢是使用單個網(wǎng)絡,多網(wǎng)融合特征逐漸被VGGNet、GoogleNet和ResNet這三種深度人臉識別的代表性網(wǎng)絡架構所取代。其中,GoogleNet通過增加網(wǎng)絡結構的稀疏性來解決網(wǎng)絡參數(shù)過多的問題,大大減少了計算量。FaceNet使用Inception模塊實現(xiàn)了輕量級的深度人臉識別模型,可以在前端設備上實時運行。
通常,圖像質(zhì)量受采集環(huán)境、采集設備和采集距離等因素影響,如何提升低質(zhì)量圖像識別精度是一個值得關注的問題。
二、圖像均衡化與FaceNet算法相結合的方法研究
(一)FaceNet算法
傳統(tǒng)的基于深度卷積神經(jīng)網(wǎng)絡(CNN)的方法,一般利用CNN的Siamese網(wǎng)絡來提取人臉特征,然后利用SVM等方法進行分類。
FaceNet則利用DNN直接學習到從原始圖片到歐氏距離空間的映射,從而使得在歐式空間里的距離的度量直接關聯(lián)著相似度,并且引入Triplet損失函數(shù),增強模型學習能力。
FaceNet算法的本質(zhì)是通過CNN學習圖像到128維歐幾里得空間的映射,該映射將圖像映射為128維的特征向量,通過使用特征向量之間距離的倒數(shù)來表征圖像之間的相似度,對于相同個體的不同圖片,其特征向量之間的距離較小,對于不同個體的圖像,其特征向量之間的距離較大。最后基于特征向量之間的相似度來解決圖像的識別、驗證和聚類等問題。
(二)圖像均衡化
圖像均衡化技術可以在圖像增強、光照補償?shù)榷鄠€領域取得很好的效果[3]。該項技術能夠?qū)⒁粋€灰度級別分布不均勻的圖像,通過變換得到一個均勻分布。
直方圖是圖像中像素強度分布的圖形表達方式,它統(tǒng)計了每一個強度值所具有的像素個數(shù),是一種常用的灰度變換方法,主要用于增強動態(tài)范圍偏小的圖像對比度。
直方圖均衡化是一種簡單有效的圖像增強技術,通過改變圖像的直方圖來改變圖像匯總個像素的灰度,通過拉伸像素強度分布范圍來增強圖像對比度。
(三)圖像均衡化與FaceNet算法相結合
為了提高別準確率,本文把輸入的圖片先進行圖像均衡化處理,提高圖像的對比度,然后再進行邊緣檢測提取,最終通過FaceNet模型進行識別與比對,用于提升識別的準確率。
具體流程如下:
(1)輸入圖片
(2)圖像均衡化處理
本文采用直方圖均衡化技術進行圖像預處理。
① 映射函數(shù)應該是一個累積分布函數(shù)(cdf)。對于直方圖H(i),它的累積分布H(i)是:
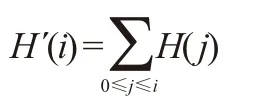
② 要使用其作為映射函數(shù),須對最大值為255(或者用圖像的最大強度值)的累積分布H(i)進行歸一化。
③ 最后,通過映射過程來獲得均衡化后像素的強度值:
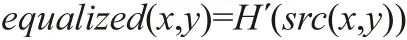
(3)檢測對齊
檢測對齊采用基于深度學習的MTCNN算法。該算法利用檢測任務和分類任務來輔助關鍵點檢測。其總體框架包含三個階段:Proposal Network(P-Net)、Refine Network(R-Net)、Output Network(O-Net),這三個階段的輸入為不同大小的圖片,用于檢測不同大小的人臉[4]。
P-Net的輸入是一個12×12×3的RGB圖像,在訓練的時候,該網(wǎng)絡要判斷該圖像中是否存在人臉,并且給出人臉框的回歸和關鍵點定位。
為了去除大量的非人臉框,R-Net輸入是P-Net生成的邊界框,輸出是人臉框的回歸和人臉關鍵點定位。
進一步將R-Net的所得到的區(qū)域進行縮放,輸入ONet。O-Net輸入大小為48×48×3的圖像,輸出包含P個邊界框的坐標信息,score以及關鍵點位置。
(4)采用FaceNet算法計算
具體流程如下:
① 采用CNN結構提取特征;
② 特征歸一化(使其特征的 | |f(x) | |2 = 1 ,所有圖像的特征都會被映射到一個超球面上);
③ 再接入一個Embedding層(嵌入函數(shù)),嵌入過程可以表達為一個函數(shù),即把圖像x通過函數(shù)f(x)映射到d維歐式空間;
④ 此外,對嵌入函數(shù)f(x)的值,即值閾,做了限制。使得x的映射f(x)在一個超球面上;
⑤ 使用Triplet損失函數(shù)(優(yōu)化函數(shù))進行特征優(yōu)化。
(5)輸出結果
本文采用Inception ResNet v1神經(jīng)網(wǎng)絡結構,基于數(shù)據(jù)集CASIA-WebFace,進行模型訓練。選取了LFW數(shù)據(jù)集和網(wǎng)絡爬取的圖片,經(jīng)過粗略的人工篩選,去除不符合要求的圖片,并對所有圖片進行了Gamma變換,降低亮度,模擬暗處拍出的圖片,組成了一個5000余張的測試集,進行測試。
?
測試效果示例如圖1所示,其中圖片左側為原圖,中間為對原圖Gamma處理后的圖像,右側為對中間圖像進行直方圖均衡化處理后的圖片。

結果如圖2所示,通過直方圖均衡化預處理后,對相對較暗的圖片,識別的準確率有了明顯的提升。
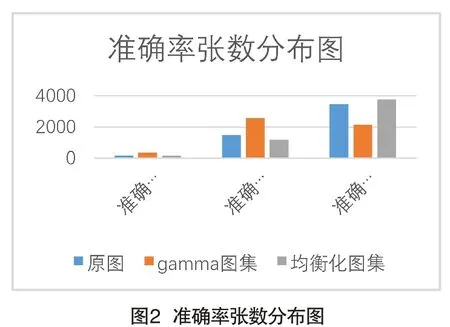


?
三、應用展望
本研究提出的方法可作為人員身份核實的一個步驟應用于分析研判、比對等業(yè)務中。如在公安分析研判業(yè)務中,利用該算法將圖像進行比對,基于比對結果進行分析,如通行分析、聚集分析等,并可進行預警反饋。
四、結語
本文提出了一種基于圖像均衡化和FaceNet人臉識別算法相結合的方法,針對于提升光線不足、過曝等圖像的人臉識別準確率。通過實驗證明本文提出的方法對人臉識別準確率有明顯提升。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2017年17期)2017-12-18 06:40:55
電子制作(2017年1期)2017-05-17 03:54:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
計算機工程(2015年8期)2015-07-03 12:19:07
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
