Spark平臺下基于加權詞向量的文本分類方法
2022-04-22 11:19:14蔡宇翔王佳斌鄭天華
現代計算機 2022年3期
蔡宇翔,王佳斌,鄭天華
(華僑大學工學院,泉州 362021)
0 引言
隨著信息時代的發展,互聯網上的文本數據呈現爆發式的增長。海量的數據未經過分類,人們無法高效地對其提取有用的信息,也浪費了網絡資源。文本分類作為文本處理重要的技術之一,被廣泛地用于各項自然語言處理任務當中。文本分類即是通過特定的算法,分析文本數據中的潛在規則,再將新的文本和對應的類別相匹配。Spark計算框架是基于內存計算,并不會產生IO開銷,可以大幅度提高文本分類的處理效率。文本分類任務中的難點是如何將文本表現為向量形式。文獻[6]中使用TF-IDF算法,對亞馬遜評論文本進行向量化,并使用了Spark mllib庫下的三種機器學習分類算法:邏輯回歸、支持向量機和樸素貝葉斯,其中支持向量機的效果最優,精度達到了86%,但是使用TF-IDF方法在文本數量龐大的情況下,會將文本映射成一個高維的、稀疏的向量,導致維度災難,且這種方法是將詞語進行獨立計算,無法衡量單詞和單詞之間的語義關系。分布式表示法又被稱為詞嵌入、詞向量。Word2Vec是谷歌發布的一款計算詞向量的工具,通過在語料庫上的訓練,可以很好地表示詞與詞之間的相似性。它使用單詞的上下文計算單詞的向量,充分利用了單詞之間的語義關系。文獻[9]中使用了Word2Vec詞嵌入技術對建筑文本進行向量化,并使用Spark并行化分類算法,使得訓練時間極大地縮短。文獻[10]為了更加全面地表示詞向量,使用外部語料庫對Word2Vec模型進行預先訓練,再結合改進后的CNN對新聞文本進行分類,在Spark平臺并行化后,相較于單機傳統的方法,運行效率和精度都得到了提升。相對于傳統的建模方法,使用Word2Vec對文本進行表示的方法更好。然而,單獨使用Word2Vec詞嵌入技術,只是將文本表示為文本中所有單詞的詞向量的平均值,這種方法無法體現每一個單詞在句子中的重要程度。針對此問題,本文結合Spark平臺提出了基于加權詞向量的文本表示方法,并使用SVM分類器進行文本分類。
1 Spark平臺下基于加權詞向量的文本分類方法
1.1 文本表示方法
TF-IDF是一種常用的計算詞語權重的方法,TF(term frequency)表示詞語在單個文檔中出現的次數,IDF(inverse document frequency)表示包含某個詞語的文檔數越少,該詞語的區分能力就越高。TF-IDF算法的核心思想是如果一個詞語在某個文本中出現的頻次較高,那它可能是對文本比較重要的單詞,也有可能是一些普通程度的常用單詞。為了區分這種情況,將詞頻和逆文檔頻率相乘,如果該詞語較多地出現在該文本內,又較少地出現在其他文本內,則可以認為該詞語對這個文本的重要性高,相應的TF-IDF值也會較高。TF-IDF考慮了詞語在文檔中的分類情況,以此來表示詞語的重要程度。
TF-IDF的計算公式如下:
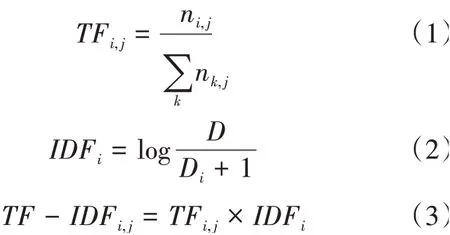
TF表示單詞的詞頻,n表示詞語在文檔中出現的次數,分母表示文檔中的總單詞數。IDF表示單詞的逆文檔頻率,表示數據集中的總文檔數,D表示含有單詞的文檔數,分母加一是為了避免分母為0導致運算錯誤。本文使用TF-IDF值作為單詞在文檔中的權重。
Word2Vec是2013年由谷歌開源的一款詞嵌入工具,它使得詞語可以被分布式表示。它是MIKOLOV提出的一種基于神經網絡的概率模型,它在詞向量的維數通常設置為100~300,對比傳統的高維向量,可以簡化計算,且不會引起維度災難。
Word2Vec分為skip-gram和CBOW兩種方式,CBOW模型是通過前后的個詞來預測中心詞出現的概率,它的數學表示為:
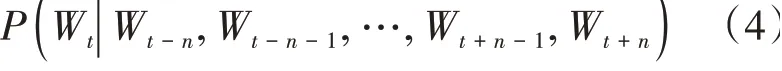
而skip-gram模型則是通過中心詞來預測前后的個詞,數學表示為:
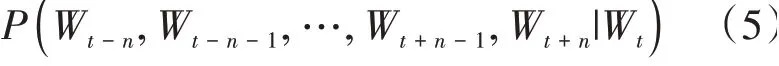
兩種模型之中,skip-gram模型的語義準確率高,但是同樣的計算代價高,訓練時間較長。skip-gram模型有三層神經網絡構成,包括輸入層,投影層和輸出層。輸入層為中心詞語的One-Hot向量,乘上模型訓練后的權值矩陣,輸出層為詞語分布在中心詞語前后的概率矩陣。本文使用skip-gram模型進行訓練。skip-gram模型如圖1所示。
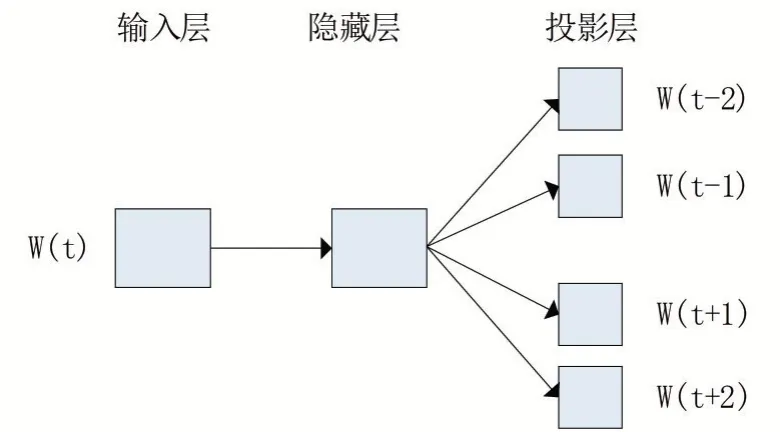
圖1 skip-gram模型
如果單純的使用文本的平均詞向量來作為文本表示,無法顯示單詞的重要性。本文基于Spark ML下的特征庫,計算每個單詞的詞頻以及TF-IDF值,將TF-IDF值歸一化后作為權值與詞向量相乘,提升重要單詞的權重,降低非重要單詞的權重,單詞權重值的公式如下:
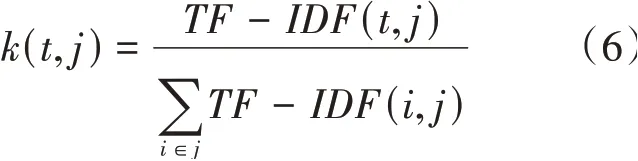
(,)表示為文檔中詞語的權重值,得到權重值后將文檔j表示為:
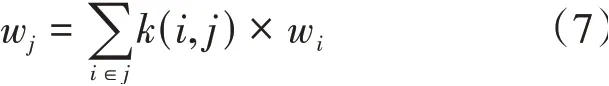
w表示文檔的特征向量,w表示單詞的詞向量。將得到的特征向量作為文本表示。向量化的流程圖如下,將向量化后的文本作為分類器的輸入。
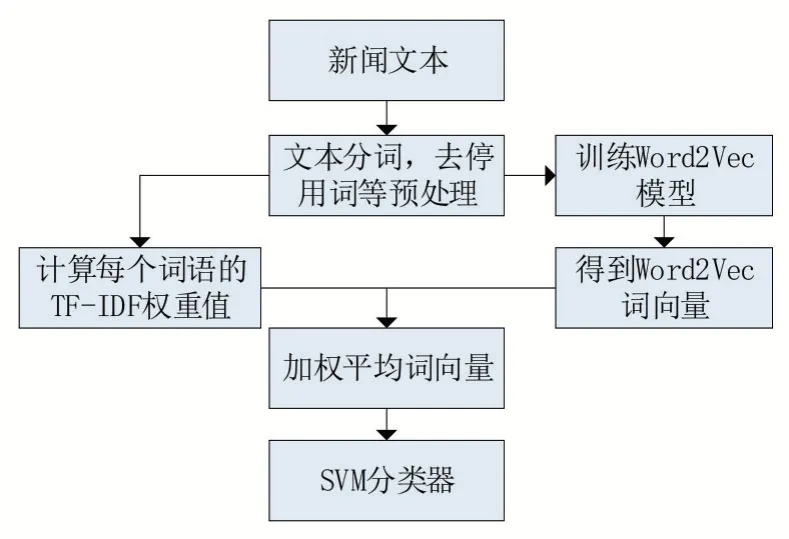
圖2 向量化流程
1.2 文本分類器選擇
文本分類是自然語言處理的基礎任務,新聞分類,情感分析等技術都屬于文本分類的子任務。分類算法的流程就是對文本的內容進行訓練,構建分類器,使用分類器對待測試文本進行測試,將其分到相近的類別中。通常文本分類常用的機器學習算法有支持向量機、樸素貝葉斯、決策樹、隨機森林算法等。其中支持向量機的原理是尋找一個超平面,使得樣本與超平面的間隔最大。由于系統健壯性好,正確率高等優點,被廣泛運用在文本分類,語音識別等分類任務中。因此,本文使用基于Spark ML機器學習庫的支持向量機方法進行分類,在驗證加權詞向量文本表示方法有效性的同時,提高計算效率。
2 實驗與分析
2.1 實驗環境
本文的實驗集群由3臺虛擬機組成,其中1臺作為Master,兩臺作為Slave,系統版本為CentOS7,Spark版本為2.4,Hadoop版本為2.7,使用的開發語言為Scala 2.12。
2.2 實驗數據即數據預處理
本次實驗數據使用由清華大學自然語言處理實驗室整理的新聞文本數據集,從體育、財經、房產、家居、教育、科技、時尚、時政、游戲、娛樂十個類別中各挑選5000條新聞文本作為訓練數據,1500條作為測試數據,數據共65000條。訓練文本的平均長度為422個單詞,測試文本的平均長度為445個單詞,可以看出該數據集屬于長文本。
對數據預處理的過程包括分詞,去停用詞等。由于中文文本的單詞之間沒有明確的邊界,所以需要使用分詞工具對文本進行分詞。目前常用的分詞工具有jieba,THULAC等。本文使用jieba分詞工具對中文文本進行分詞操作,以單詞為單位組成文本。其中有一些單詞,類似于“和”“且”“了”等并沒有實際意義的單詞,和一些標點符號,空白字符等字符,需要去除,本文結合了哈工大停用詞表,四川大學機器智能實驗室停用詞表,對文本中無意義的詞語進行了去停用詞操作。數據預處理前后對比如表1所示:

表1 文本預處理
2.3 評價標準
本文使用精確率,召回率和1值作為評價指標。精確率和召回率,1值是分類任務中廣泛運用的指標。表2是分類任務中的混淆矩陣:表示實際屬于該類,并且被分類器判定為該類的文本,表示被分類器判定為該類,但實際不屬于該類的文本。表示真實屬于該類,但被分類器判定為不屬于該類的文本;表示實際不屬于該類其分類器也判定其不屬于該類的文本。

表2 混淆矩陣
準確率的數學公式為:
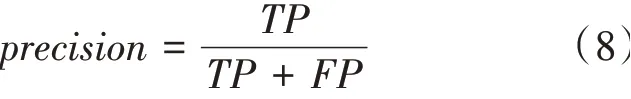
召回率的數學公式為:
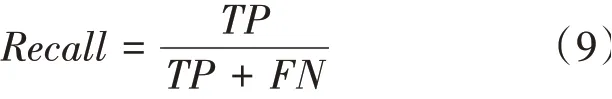
1綜合考慮了召回率和精確率,1值的數學公式為:
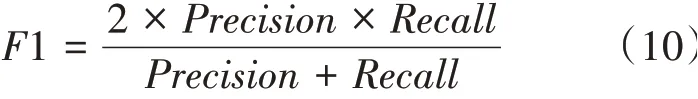
2.4 文本分類結果分析
本文使用SparkML庫中的各種模型,可以使用SparkSQL語句對DataFrame進行操作,簡化計算。首先訓練Word2Vec模型,將前文中預處理好的文本數據送入SparkML庫中的Word2Vec模型中進行訓練,詞向量維度設置為100,上下窗口為5,得到詞向量庫。同時將處理好的語料進行TF-IDF計算處理。先使用CountVectorize工具對文本進行詞頻統計,在使用IDF模型得到詞語的TF-IDF值。然后使用詞語的TF-IDF值作為詞語的權重,將文本的特征向量表示為文本中所有詞語詞向量的加權平均值。
將訓練文本通過上述操作向量化后送入SVM分類器進行訓練,SparkML庫中的SVM分類器采用數據并行的原理,相比于單機算法,可以有效提高訓練速度。最后使用訓練好的SVM分類器對已標注的測試文本進行測試。從而計算準確率。
為了測試該方法的性能,本文同時采用了TF-IDF向量化和未加權的平均Word2Vec詞向量方法進行測試,對比三種方法性能的優劣。表3是采用加權詞向量方法的各類分類結果:
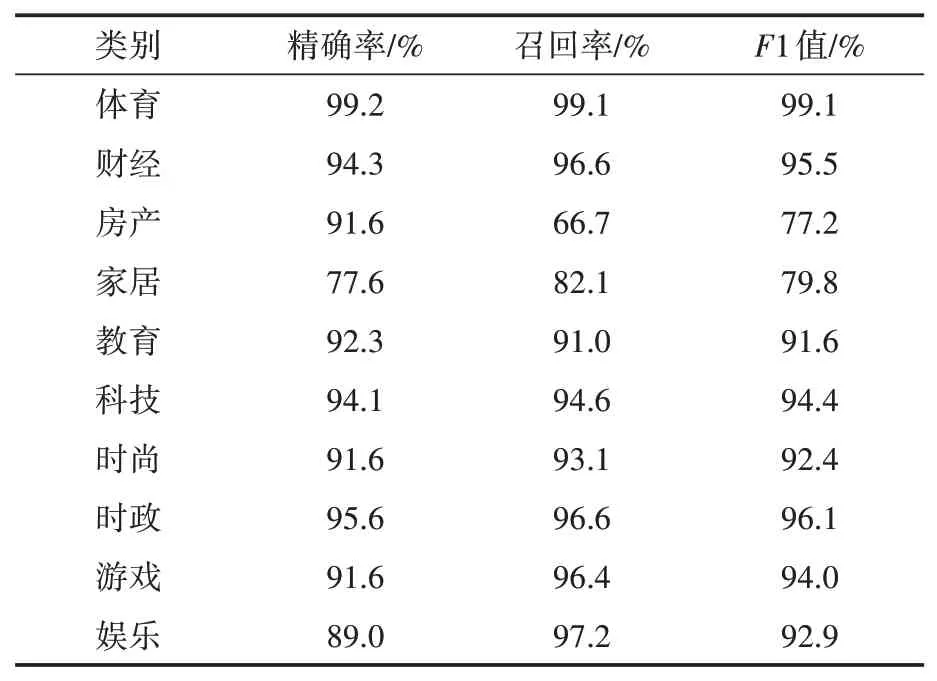
表3 TFIDF-Word2Vec+SVM分類結果
由表3可以看出,該方法在十個類別中有八個類別的1值達到了90%以上,說明該分類器的性能優異。其中F1值最低的是房產和家居兩個類別,是因為兩個類別的詞匯重合度較大,不易區分,但是也達到了75%以上。表4是采用了平均詞向量方法的分類結果
由表4可知,平均詞向量文本表示方法同樣在八個類別中取得了1值90%以上的性能表現,但是同樣由于“房產”和“家居”區分難度較高的原因,導致了這兩個類別分類效果下降。相比于平均詞向量方法,TF-IDF加權詞向量方法在這兩個類的1值分別高出了10.2%和3.6%,說明該方法在易混淆,區分難度大的分類中獲得更好的效果。TF-IDF向量化的分類結果如表5所示。
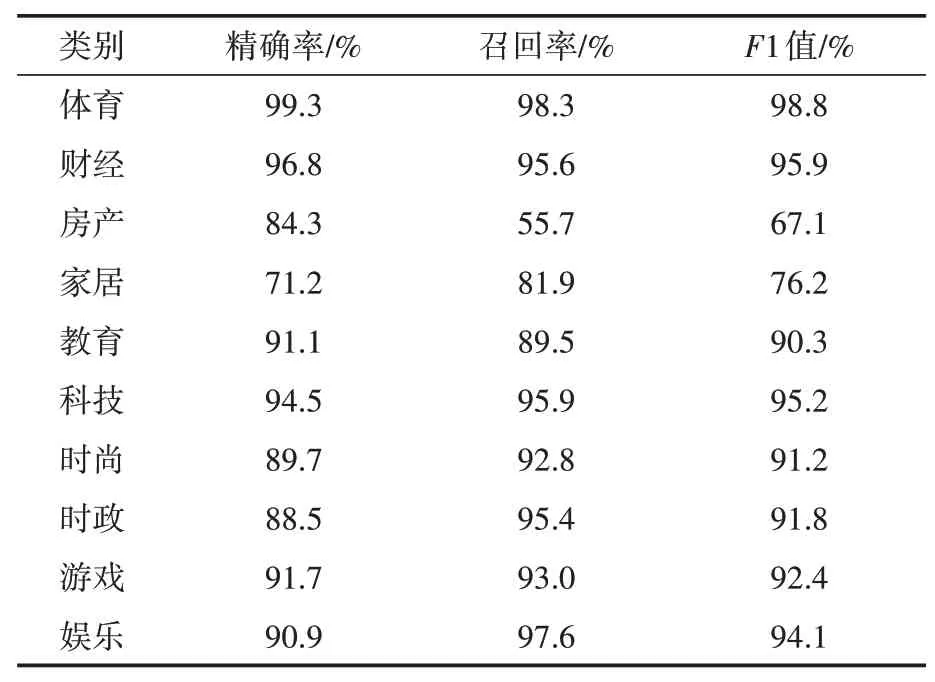
表4 avg-Word2Vec+SVM分類結果

表5 TF-IDF向量化的分類結果
由表5可以看出,TF-IDF方法的整體性能并不如加權詞向量方法和平均詞向量方法,且在詞庫較大的情況下出現向量維度過高,特征稀疏的問題,導致計算復雜度上升。表6是三種方法的綜合對比。
由表6可以看出,TF-IDF加權詞向量的分類結果作為出色,精確率,召回率和1值分別比平均詞向量方法高出了2%,1.7%,2%,此方法綜合了TF-IDF和Word2Vec詞向量的優點,考慮了詞語的重要性和詞語上下文間的語義關系,實驗數據說明TF-IDF加權詞向量相比于平均詞向量可以更好地表示文本,從而提高分類的精度。在Spark平臺上實現可以加快文本分類的計算效率。
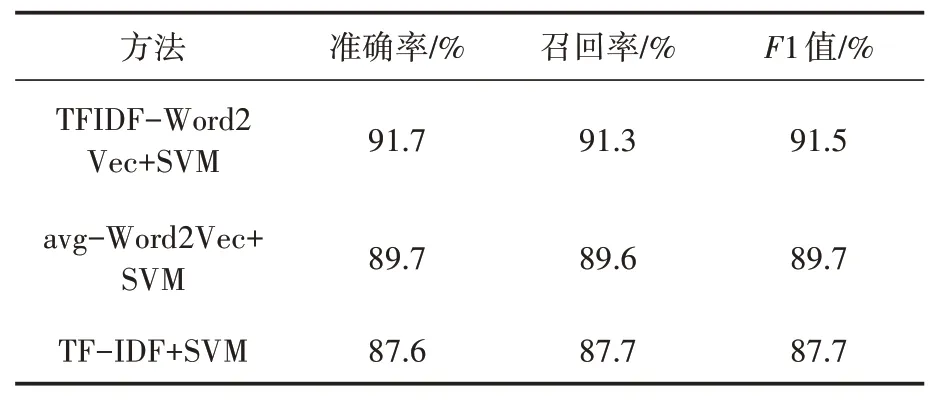
表6 性能對比
3 結語
本文結合Spark ML庫,在傳統的平均詞向量文本表示法的基礎上,使用了詞語的TF-IDF值表示詞語的重要性,作為詞向量的權重,使用加權詞向量作為文本的向量表示。由實驗結果可以看出,相比于平均詞向量和TF-IDF文本表示法,加權詞向量可以有效的提升SVM分類器的精度。但是詞向量的權重不應該只考慮TF-IDF值,所以在下一步的工作中,需要結合詞語的語法,語序等信息,更加充分地設計詞語的權重值,使得文本可以被更完善地表示出來,結合Spark平臺,設計出更加適合大規模文本的分類系統。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
