OxCal校正軟件在考古年代學中的應用
2022-04-14 11:45:10宋殷
東南文化 2022年1期
宋 殷
(北京大學考古文博學院 北京 100871)
內容提要:OxCal校正軟件是一款常用的處理碳十四數據的程序,擁有72個基本指令與若干模型。該軟件的基本指令有兩種,分別是賦值型指令和結構型指令。OxCal校正軟件運用在具體考古遺址(如王城崗龍山文化城墻和城壕以及古埃及阿馬爾納遺址)研究中時,要注意序列或階段的選擇。
一、前言
碳十四測年有三次革命,分別是碳十四測年技術的出現即碳十四革命、校正曲線革命和AMS革命[1]。在最初幾代校正曲線發布的時候,碳十四數據的校正方法主要采用校正表的方式校正,如1972年發布的“達曼表”和1984年發布的“新表”[2]。然而,隨著計算機技術的發展并運用于碳十四數據的校正,通過查表來進行碳十四數據校正的方法迅速過時,同時,20世紀90年代貝葉斯統計被引入考古學界。使用貝葉斯統計來處理碳十四數據同樣需要大量的數學運算,運用計算機軟件來進行數據的校正和貝葉斯統計成為碳十四年代學這一領域的發展趨勢。
在這樣的背景下誕生了各種可用于處理碳十四數據的校正軟件,比如 CALIB[3]、OxCal[4]、BCal[5]、CalPal[6]等。每種軟件各有優勢和劣勢,本文不擬在此對各種校正軟件的應用進行一一介紹,僅聚焦于在夏商周斷代工程期間被介紹進中國并產生較大影響的OxCal校正軟件。OxCal校正軟件的開發和更新主要由牛津大學的蘭姆希教授(Christopher Bronk Ramsey)完成,該軟件自1994年首次發布以來經歷了大約133次更新,最近一次更新版本OxCalv4.4.4完成于2021年11月24 日[7]。
OxCal校正軟件雖然為碳十四數據的校正和貝葉斯統計處理帶來了很多便利,但是OxCal校正軟件是非開源的,即用戶無法在OxCal校正軟件上根據自己的需求設計代碼以實現任務,因此理解那些在OxCal校正軟件上的指令就至為關鍵。
二、基本指令與模型
OxCal校正軟件擁有72個基本指令,可以完成數據的基本校正。其模型包括貝葉斯統計模型、樹輪扭擺匹配(Tree-ring Sequence)、沉積模型(Deposition Model)、異常值模型(Outlier Model)等。其中,貝葉斯統計模型具體又包括連續模型(Contiguous Model)、非連續模型(Sequential Model)、重疊模型(Overlapping Model)、梯形模型(Trapezium Model)等。一般可以這樣來理解,基本指令相當于一塊塊積木,而模型相當于用積木搭起來的建筑。
上述基本指令與模型在OxCal校正軟件上都有簡單的英文描述[8],為了方便理解和應用,本文結合實際使用經驗,在此簡要介紹一些重要指令和模型。
基本指令有兩種,分別是賦值型指令和結構型指令。賦值型指令是指可以賦予一定數值來實現功能的指令;結構型指令是指這種指令可以容納一系列的賦值型指令并構成一定的結構以實現某種功能。模型一般是由一個結構型指令或一群結構型指令構成的。
舉例來說,R_Date這一指令即屬于賦值型指令,每一個R_Date可以賦予三個值,分別是名稱、碳十四原始數據(以5568年為半衰期,以BP為單位)、碳十四原始數據的誤差(即正負多少年)。一個R_Date指令代表了一個實測的碳十四數據。同樣是年代數值,C_Date也可以賦予三個值,分別是名稱、指定日歷年代(輸入數值即公元多少年,公元前多少年要加上負號)、誤差(正態分布的一個標準差),且C_Date一般符合正態分布,C_Date作為已知年代的指令,可以放入模型中與碳十四年代結果進行比對。
在R_Date基礎之上衍生出了R_Combine和R_Simulate。R_Combine是容納R_Date的結構型指令,其主要目的是對R_Combine所涵蓋的數據進行取平均值處理,這樣可以有效減小結果年代的誤差。R_Combine的使用前提是確定若干個碳十四數據是完全“共時”的。例如從一個馬坑內不同馬個體的骨骼樣本測出來的碳十四數據,即可以用R_Combine處理,以獲得馬坑的誤差范圍更小的年代。而R_Simulate可以賦予三個值,分別是名稱、設定日歷年代和誤差。R_Simulate的設計理念是給定一個已知的日歷年代,系統會返回一個包含該日歷年代的碳十四年代。R_Simulate的主要用途是模擬貝葉斯統計過程,即在一個貝葉斯統計模型中每隔一定時間間距加入一個R_Simulate,觀察在一定模擬的日歷年代范圍內加入多少個數據可以得到最高的準確度。
OxCal校正軟件中還有兩個指令可以計算年代差值,分別是Difference和Interval。Difference是賦值型指令,有四個值,分別是名稱、參數一、參數二和先驗條件表達式。使用Difference時,首先列出兩個R_Date,然后插入Difference,并將參數一和參數二分別填入兩個R_Date的名稱,運行后即可得到兩個R_Date的年代差。Interval可以計算一個序列(Sequence)中的一個階段(Phase)的起止年代差,做法是將Interval放入一個Phase指令內數據的最后,運行程序即可得到該Phase的起止年代差。
對于區域補償值(Offset)[9]已知的情況,可以利用Delta_R來對校正曲線進行微調。Delta_R有三個值,分別是名稱、補償值和誤差。比如牛津大學經過研究,得到了埃及尼羅河地區的區域補償值為19±5年[10],因此在研究古埃及年代的時候,就可以插入Delta_R,并將補償值設為19年,誤差設為5年。如果知道某測年樣品的補償值,可以用Offset指令引入補償值。具體做法為:點擊欲加入補償值的R_Date,插入Offset指令并輸入補償值和誤差。舉例來說,對于大量食用水生生物的人類個體骨骼,如果知道該個體的補償值,即可通過Offset指令得到去除儲存庫效應影響后的較為準確的年代。
OxCal校正軟件還可以在地圖上顯示年代數據,具體有三個指令,分別是經度(Longitude)、緯度(Latitude)和顏色(Color)。具體做法為:輸入一個R_Date之后,如圖一所示,可以點擊R_Date,插入經、緯度和顏色,在程序運行完之后選擇觀看(View)里的地圖上顯示(Plot on map)可以生成地圖,同時可以得到地圖隨年代進行掃描的動態圖,如圖二所示,圓圈代表碳十四數據,圓圈的大小代表年代概率。

圖一// 年代經緯度和顏色指令舉例

圖二// 地圖顯示碳十四年代舉例
此外,OxCal校正軟件還有觀察大批量碳十四數據分布情況的Sum和KDE_Model兩個指令。Sum是結構型指令,可以在Sum內加入欲分析的碳十四數據R_Date,Sum得到的結果是碳十四數據校正后年代的概率密度的直接疊加。KDE_Model是核密度估計分析的指令,可以用于計算年代數據的分布曲線,操作方法與Sum類似。但需要注意的是,在數據量較少的情況下,KDE_Model會對結果的數據年代有所壓縮,數據量越多,越能反映真實的年代分布情況[11],KDE_Model的應用實例如圖三所示,該圖顯示了夏家店下層文化所有新測碳十四數據可以分為A、B、C三群,而這是單個測年數據所無法展示的年代分布規律[12]。
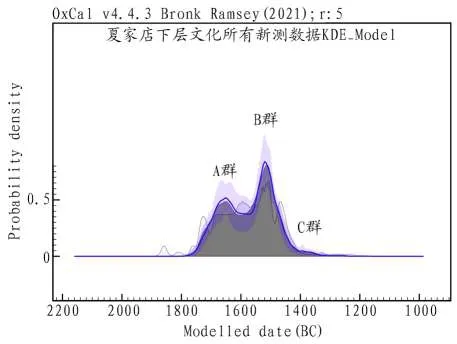
圖三// 夏家店下層文化新測碳十四數據的KDE_Model指令結果
三、在考古年代學中的應用
為了便于理解OxCal校正軟件的具體操作,本文使用河南登封王城崗龍山文化大城城墻的地層序列一、王城崗龍山文化大城城壕的地層序列三[13]以及牛津大學在研究古埃及年表時所使用的貝葉斯統計模型[14]為例,具體分析如何應用OxCal校正軟件。對于王城崗龍山文化的例子,本文只試圖說明報告中所用模型設計及其與考古學信息的聯系,不擬重新設計模型。
序列(Sequence)和階段(Phase)是理解如何在OxCal校正軟件中建立貝葉斯統計模型的關鍵概念。對于序列和階段的選擇直接決定了貝葉斯統計模型的結果。
圖四是依據王城崗龍山文化大城城墻的地層序列一在OxCal校正軟件中所建立的貝葉斯統計模型。由于地層是有先后時間順序的,所以首先設置了一個序列,命名為“王城崗地層序列一”。然后在這個序列下面依照地層的順序放入數據,地層的序列為“W5T0670⑤→W5T0670Q1→W5T0670⑧→⑧層下灰坑”。需要注意的是在Boundary_Bound之后設置了一個階段,命名為“⑧層下灰坑”,由于H72、H73、H74都位于⑧層下,三者無法區分早晚,所以放在一個階段里面。需要注意的是,“階段”里的數據是不分早晚的。由于不清楚夯土墻三個數據的先后順序,所以設置為一個階段。在這個序列中,每兩個有相互疊壓關系的單位之間設置一個邊界(Boundary),這屬于貝葉斯統計模型中的連續模型(Contiguous Model),由于位于模型中間的階段或數據前后都有邊界,為公平起見,模型的起始與結束都加邊界,以對起始和結束的階段或數據加以約束。

圖四// 王城崗龍山文化大城城墻的地層序列的貝葉斯統計模型
圖五是依據王城崗龍山文化大城城墻的地層序列三在OxCal校正軟件中所建立的貝葉斯統計模型。由于地層單位存在早晚關系,首先建立一個序列并命名為“王城崗地層序列三”。圖五所示模型與圖四所示模型大體相似,可依據層位關系“W5T0672HG4⑥→W5T0672HG2①→W5T0672HG1→W5T0672H76”建立模型,每兩個單位之間設置一個Boundary。唯一區別為龍山文化壕溝HG1的數據按照層位由早到晚被放入一個序列里,并被命名為“龍山壕溝”。因此,在使用序列的時候,需要確保同一個“序列”里的數據是有早晚關系的。除了注意階段和序列的區別,還要注意貝葉斯統計模型里的層級關系。此外,這里的模型開頭設置了校正曲線的選擇,在此選擇2004年國際校正曲線IntCal04,如果不設置的話軟件默認使用最新的IntCal20校正曲線。
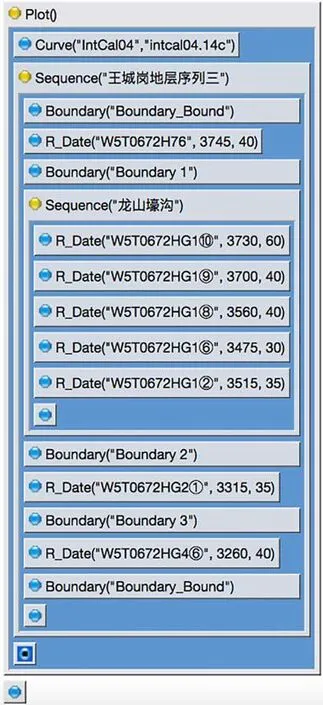
圖五// 王城崗龍山文化大城城墻的地層序列三的貝葉斯統計模型
最后是用碳十四測年研究古埃及年表的例子,如下所示是其中的一個貝葉斯統計模型[15]。



選擇(Options)下設置了碳十四數據的分辨率為5年。整個分析使用的區域補償值為19±5年。該模型研究了公元前14世紀中晚期的阿馬爾納(Tell el-Amarna)遺址,并在一個序列下設置了該遺址最初使用的階段、阿馬爾納到圖坦卡門序列、遺址廢棄后的希臘化時代的階段。阿馬爾納到圖坦卡門序列又包括由長年樣品的階段和短年樣品的階段組成的阿馬爾納期和圖坦卡門期。“//R_Date”所標注的年代是經過前期異常值檢驗(Outlier Check)發現的異常值。阿馬爾納遺址集中使用的時間主要是公元前14世紀中晚期,經過貝葉斯統計模型的處理,可以發現統計處理后的年代與歷史文獻的記載即1350—1335 BC很好地吻合(圖六)。該應用中使用了R_Combine來處理Amarna Akhenaten SL時期的短年樣品。這樣做雖然可以得到十分精準的年代結果,但在中國的考古實踐中需注意樣品的“同時性”是否可以保證,一般而言只有同一座墓葬中同時被埋葬的不同個體的測年結果,或灰坑在短時間內形成的堆積中的短年樣品測年結果可以使用R_Combine以縮小測年誤差。

圖六// 公元前14世紀中晚期阿馬爾納遺址的貝葉斯統計結果(本圖為Radiocarbon and the Chronologies of Ancient Egypt.Oxford:Oxbow Books,2013,P142程序代碼運行結果)
四、結語
本文介紹了OxCal校正軟件的若干常用基本指令和OxCal校正軟件的應用實例,并主要以王城崗遺址龍山文化城墻和城壕為例展示了如何設計貝葉斯統計模型,以及如何選擇序列或階段。但是,田野考古發掘中遇到的年代學問題遠遠不是幾個簡單的模型可以解決。對OxCal校正軟件中的關鍵概念即序列和階段的如何使用直接決定了結果的成敗,這涉及諸如碳十四測年樣品來源問題、遺跡單位的生命史、測年樣本與遺跡單位的年代關系等若干田野考古中的關鍵問題,因此尋找最契合考古發掘實際的貝葉斯統計模型也是測年學者的不懈追求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
西安航空學院學報(2014年5期)2014-07-13 01:27:52
