基于迭代訓練的古文短文本聚類方法研究
2022-04-14 03:26:40李曉璐趙慶聰
現代計算機 2022年2期
李曉璐,趙慶聰,3,齊 林
(1.北京信息科技大學信息管理學院,北京 100192;2.北京信息科技大學經濟管理學院,北京 100192;3.綠色發展大數據決策北京市重點實驗室,北京 100192;4.北京世界城市循環經濟體系(產業)協同創新中心,北京 100192)
0 引言
中國傳統文化源遠流長,中華民族創造了無數文化瑰寶,現階段需要通過科技的力量將這些寶貴的文化財富融入現代生活中。但是由于傳統文化體系龐大,加大了獲取和理解傳統文化的難度,因此實現中國傳統文化的體系分類是一項需迫切解決的問題。本研究基于課題組的中國傳統文化素材庫進行主題聚類研究,該素材庫的數據源為《四庫全書》和《太平御覽》。從上述數據源抽取出古文短文本數據集,通過自然語言處理以及聚類算法挖掘出該數據集的內在聯系和潛在信息,得到每一條文本所屬具體類別。該數據集表現為短文本詞條的形式,短文本不同于傳統文本,短文本包含的有效信息量少,具有特征稀疏等特點,且部分詞條內容夾雜古文,基于機器學習的傳統文本聚類算法效果不佳。
傳統短文本聚類往往利用向量空間來進行文本的表示,而該文本表示方法具有特征稀疏、特征維度高,且忽略文本語義等特點。Shangfu Gong等在分析傳統互信息缺陷的基礎上,提出了一種基于二次TF-IDF互信息的特征選擇方法,實驗證明該方法對特征降維有效。郭頌等從信息增益的角度進行特征降維,提出了一種基于特征分布差異因子加權的算法,改善了文本表示的表征能力。這些降維方法可以有效的提高長文本的聚類效果,但是短文本由于其自身的特點并不適用。隨著深度學習的發展,王月等使用BERT(Bidirectional Encoder Representation From Transformers)預訓練模型來代替Word2vec的Skip-gram和CBOW來進行詞向量的訓練,實驗表明,該方法極大地提高了詞向量的表征能力。Rakib等提出一種基于迭代分類的聚類增強算法,實驗表明,其可提高任意基線聚類算法的聚類結果。Pugachev等在Rakib工作的基礎上,引入了BERT預訓練模型,實驗結果表明該方法提高了其在英文公開數據集上的聚簇效果。結合該古文數據集特征稀疏,上下文語義信息聯系緊密等特點,本文嘗試采用BERT預訓練模型作為生成詞向量的方法,結合K-means聚類算法+迭代分類模型進行訓練,提出一種BERT+K-means+迭代分類思想的融合模型,對該古文短文本進行聚類研究。
1 相關研究
1.1 文本表示方法
短文本表示是文本挖掘、信息檢索以及自然語言處理(NLP)等研究的基礎,文本表示是為了將非結構化的文本數據轉化為計算機可以處理的數據格式。學術界目前提出了多種文本表示模型,傳統的文本表示方法有向量空間模型(Vector Space Model,VSM)、語言模型、本體等。利用高效的文本特征提取方法來構造文本表示模型是提高短文本聚簇效果的關鍵。隨著計算機性能的不斷提升,深度學習在自然語言處理(NLP)中也發揮著越來越重要的作用,基于語義信息的詞向量表示模型成為現在研究的重點。
1.1.1 向量空間模型
向量空間模型(VSM)由G.Salton首次提出,是一種基于詞袋模型的文本表示方法。向量空間模型將文本轉換為空間中的向量形式,特征詞的個數即為向量的維數。假如一個文本文檔包含n個特征項,則文本可以表示為如下公式:D=((t,w),(t,w),…,(t,w)),其中t表示文本第i個特征詞,w表示文本第i個特征詞的權重值。表1描述了文檔集-特征項矩陣表示的文本集。

表1 VSM文檔集-特征項矩陣示例
傳統的向量空間模型一般使用TF-IDF來計算文檔中特征項的權重,TF-IDF是一種基于統計的方法,可以有效評估一個詞對所屬文檔的重要程度。TF-IDF計算公式如下:
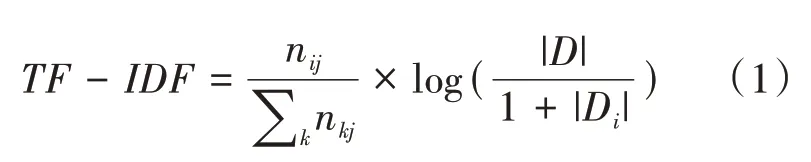
其中,n表示詞i在文檔j中的出現頻次,|D|表示文檔集中總文檔數。
向量空間模型使用向量來表示文本,使模型具有了可計算性,可以有效評估不同詞語對文檔的重要程度,VSM簡單直接但是由于維數過高而產生特征稀疏問題,并且VSM假設詞與詞之間獨立,割裂了詞語之間的上下文語義關系。
1.1.2 詞向量模型
由于傳統的文本表示方法具有維度高、性能差、并且不能發揮文本中同義詞的作用等特點。Hinton首先提出了詞向量的分布式表示,其基本思想是將每個詞語映射到低維稠密且維度固定的向量表示中,也被稱為詞嵌入(Word Embedding)。經多年發展之后,產生了多種詞向量模型。Bengio等提出了一種G-gram的神經概率模型,該模型使用Softmax作為輸出層,模型復雜度會隨著詞匯表的增加而增大,無形中增加了訓練的難度。隨后,Morin和Bengio對該算法進行了改進,將輸出層的Softmax與哈夫曼樹相結合,該改變大大降低了訓練的復雜度。
Mikolov等提出了將特征詞轉換為詞向量的Word2vec語言模型,該模型包括兩種詞向量訓練模型CBOW和Skip-gram,前者通過學習特征詞上下文環境的獨熱編碼,輸出預測詞的獨熱編碼向量,后者與之相反。該模型根據上下文環境預測特征詞的詞向量,很好的保留了文本的語義相關性,也實現了特征項從高維到低維的映射。詞向量訓練模型CBOW和Skip-gram的結構圖如圖1所示。

圖1 CBOW和Skip-gram模型結構
隨 著ELMo(Embeddings From Language Models)、GPT(Generative Pre-Training)、BERT等預訓練模型的出現,不僅改變了自然語言處理任務中的模型結構,在自然語言處理領域中的諸多任務中也都取得了最優的結果。不同于Word2vec、Glove等詞向量模型中一個詞只對應一個詞向量,上述預訓練模型會根據上下文語料創建高度相關的詞向量表示,解決了Word2vec、Glove等詞向量模型無法解決的一詞多義問題。
文獻[15]提出了BERT預訓練模型,該模型是一種基于Transformer模型的雙層編碼器表示,BERT模型根據上下文語料動態生成詞語對應的詞向量表示,解決了上述多義詞問題。BERT不是只根據出現過的詞來預測下一個詞,而是將整個句子中的一部分詞進行隨機掩蓋,使用雙向Transformer來預測掩蓋的詞,BERT網絡結構如圖2所示。
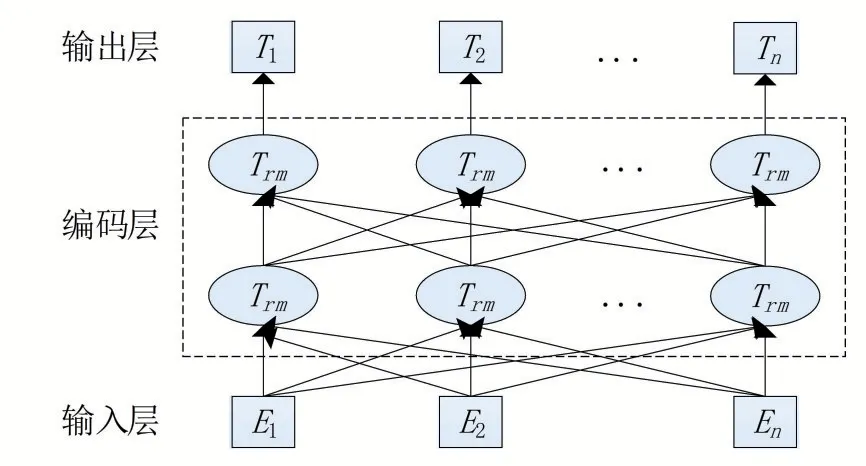
圖2 Bert網絡結構
1.2 聚類算法
文本聚類就是將文檔集中的文檔根據一定的規則劃分成不同的聚簇的過程,通過計算文本向量之間的相似度進行聚類,如果相似度高則說明為同一聚簇。常見的文本聚類方法大致分為基于層次的聚類和基于劃分的聚類,層次聚類是將文本對象組織成一個聚類的樹,然而層次聚類算法相比較而言時間復雜度高,不適合大量文本的聚類操作。基于劃分的聚類恰恰相反,典型的有K-means算法,這是一種基于質心的聚類算法,其原理是首先選擇k個文檔作為初始的聚類點,然后通過計算文本相似度,將高于閾值的文檔劃分為一個簇,依次迭代計算。K-means聚類算法流程如下:
算法1 K-means聚類算法
輸入:語料集D,聚類簇數K,誤差平方差收斂條件
輸出:聚簇劃分C={C,C,C,…,C}
①從語料集中隨機選擇K個樣本作為初始聚簇中心。
②采用歐式距離計算每個樣本點與初始聚簇中心的相似度,按照最小距離原則將樣本點劃分到最臨近聚簇中心。
③計算所有聚簇樣本點的均值,并由此更新聚類中心。
④計算誤差平方和,若滿足收斂條件,則繼續執行,若不滿足,繼續重復②③。
⑤輸出聚簇劃分C={C,C,C,…,C}。
2 基于迭代分類的古文短文本聚類算法
2.1 實驗流程
本論文總體實驗流程如圖3所示。
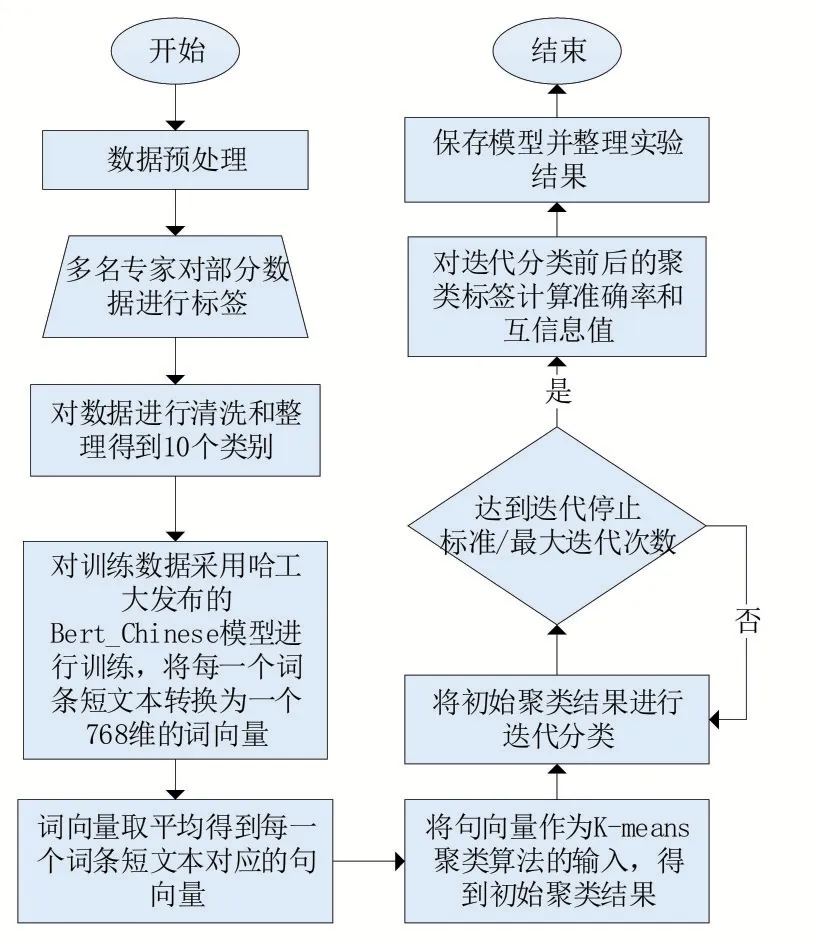
圖3 實驗流程
使用初始聚類結果進行迭代訓練,對每一個聚簇結果采用孤立森林(Isolation Forest)作為離群值檢測算法,記錄每一個聚簇結果的離群值與非離群值。將非離群值作為訓練集,離群值作為測試集。使用訓練集訓練分類器,然后利用該分類器對測試集進行分類,直到達到停止標準或者最大迭代次數。對迭代后的聚類結果計算準確率和互信息值,保存模型并整理實驗結果,實驗證明迭代分類增強了聚類結果。
2.2 數據預處理
分詞是數據預處理的核心步驟,是指通過某些策略將沒有分隔符的句子分成若干詞語,這對于中文文本的處理尤為重要。目前中文分詞技術主要包括三種:基于規則的分詞技術(正向最大匹配法、逆向最大匹配法、雙向最大匹配法等)、基于統計的分詞(隱馬爾可夫、條件隨機場等)以及混合分詞。Jieba分詞作為一個開源的中文分詞工具,采用基于規則和統計兩種方法的混合分詞技術。
首先基于詞典的方式進行分詞,得到一個包含所有分詞結果的有向無環圖,對于標注語料,采取動態規劃的策略來獲取最大概率路徑。對于未登錄詞Jieba采用了隱馬爾可夫模型,并通過Viterbi算法進行推導。Jieba分詞包含三種切分模式:精確模式、全模式、搜索引擎模式。精確模式是指以最精確的方式將句子切分,適用于文本分析;全模式試圖將所有可以組詞的詞語都切分出來,但沒有解決歧義問題;搜索引擎模式則是基于精準模式的結果,對長詞再進行下一步的切分,適用于搜索引擎問題。本文利用精確模式對文檔集進行分詞操作。分詞示例如表2所示。

表2 分詞結果
分詞結束之后對分詞結果進行去停用詞操作,停用詞是指文本中沒有意義的語氣詞、助詞等。本論文停用詞表采用哈工大實驗室的停用詞詞表,在該詞表基礎上,加入本文數據集中與古文相關的助詞與語氣詞,進一步提高停用詞的篩選效果。
2.3 BERT預訓練
常見的主流預訓練有兩種feature-based和fine-tuning。feature-based將語言模型的中間結果即LM embedding作為額外的特征,引入到原任務的模型中。最典型的是ELMo,其首先對語料庫進行訓練,以language model為目標訓練出bi-direction LSTM,再通過LSTM得到詞語的向量表示。然而ELMo究其根本是兩個單向語言模型的拼接,并沒有實現真正的雙向。fine-tuning是指在已經訓練好的模型的基礎上,加入特定任務的模型參數進行微調,進而更好的完成下游任務,OpenAIGPT采用了該方法,使用單向的transformer decoder進行訓練。由于ELMo和GPT采用的都是單向的語言模型,無法充分的獲取詞語的上下文語義,2018年Google提出的BERT,才是真正采用了雙向Transformer的預訓練模型,能捕獲基于字的序列信息、上下文語義信息等,解決了一詞多義問題。BERT使用Transformer來代替Bi-LSTM,Transformer的并行能力遠強于Bi-LSTM,并且可以采用多層注意力機制疊加的方式來提高表征能力。
BERT模型的主要創新點在于預訓練方法上的改進,預訓練階段分為兩個階段,分別采用掩蔽語言模型(masked language model,MLM)和下一句預測(next sentence prediction,NSP)兩種方法聯合訓練來獲取詞和句子層面的上下文語義表達,其中MLM真正采用了雙向語言模型。
2.3.1 掩蔽語言模型(MLM)
MLM模型通過隨機掩蔽一定比例的輸入tokens,然后根據上下文預測得到這些被掩蔽的token,這個過程也可稱為完形填空法。論文中mask每一句子中15%的token。由于在后續fine-tuning過程中,輸入不會出現[mask],這就造成了預訓練與fine-tuning不匹配的問題。為了減輕不匹配問題的影響,將這15%需要被mask的token分為以下三種情況:80%的概率用[mask]代替被掩蔽的token、10%的概率用一個隨機詞來代替、剩下10%采用原有單詞不做改變。由于隨機替換句子中token的概率只有1.5%(15%×10%),并不會對模型的語言表達能力造成太大影響。
2.3.2 下一句預測(NSP)
MLM是基于token級別的預訓練,但是自然語言處理任務中的許多下游任務,比如問答、自然語言推理等,都需要句子關系層面的理解。然而這種句子層面的理解不能通過語言建模直接訓練得到,于是BERT提出一種方法對獲取下一個句子進行預訓練。具體方法是:在語料庫中選擇50%正確句子對,有50%的概率A與B構成上下句,剩余50%情況不構成上下句。該訓練過程類似于構建一個二分類模型,用來判斷句子之間的關系。
2.4 迭代分類算法流程
迭代增強聚類算法流程如算法2所示:
算法2迭代增強聚類算法
輸入:文檔集D(n個文檔),初始文檔標簽L,聚類簇數K
輸出:增強后的聚簇劃分C={C,C,C,…,C}
1.設定迭代次數max Iter=50
2.計算每一簇的平均文檔數avgTexts=n K
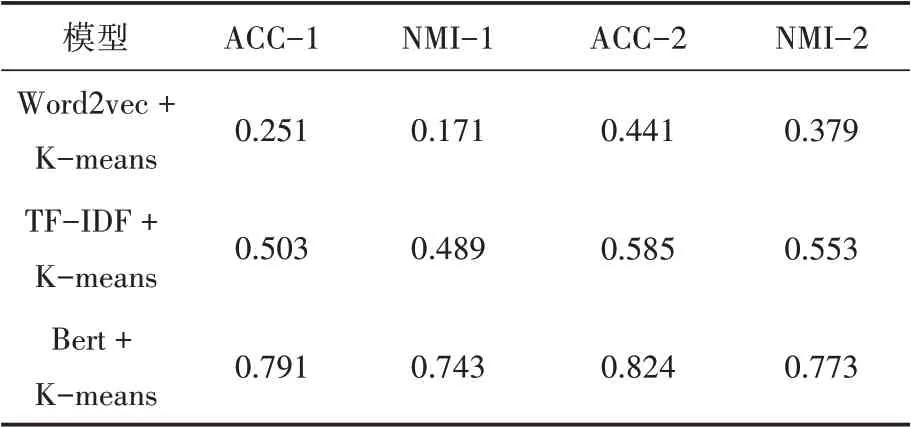
3.while i 4. 從區間[P,P]隨機選擇一個數P 5. 利用離群檢測算法從D中根據標簽P移除每一個簇的離群值 6. 若簇中的文檔數n≥P×avgTexts: 7. 隨機的移除簇中文檔使得簇中文檔數保持在P×avgTexts以內 8. 將步驟5、6、7中移除的文檔作為testSet,剩余文檔作為trainSet 9. 使用trainSet訓練分類器對testSet中的文檔進行分類,更新testSet中的L 10.end 本研究通過重復的將初始聚簇中的離群值重新分配來更新聚類的簇劃分結果,并將這個重復過程稱為迭代分類。在每次的迭代過程中,通過離群值算法將初始聚類劃分為離群值和非離群值,將非離群值作為訓練集,離群值作為測試集。從區間[P,P]中選取P值,將額外的文檔從訓練集移到測試集,即離群值和額外的文檔共同組成了測試集。利用非離群值訓練分類器,對測試集中的文檔重新分配標簽。重復這個過程,直到迭代結束。 本文數據來源于《四庫全書》和《太平御覽》,課題組專家從上述兩本巨著中抽取出傳統文化要素相關的詞條短文本,總計12000條數據。為了對本文算法進行評估,對其中2000條數據進行了標簽標注工作,共包含10個標簽,分別為:朝代、年號、軍事戰役、歷史事件、史料典籍、史學名家、考古、民俗文化、江湖志、野史筆記。 本論文采用準確率(ACC)和歸一化互信息(NMI)來衡量算法的性能,互信息表明了兩個隨機變量互相依賴的程度,歸一化互信息常用來評估聚類效果,通過預測標簽集和真實標簽集來計算兩個聚類結果的相似程度,公式如下: 其中N表示正確聚類的文檔數量,N表示總文檔數,H(X)和H(Y)分別是X,Y的熵。歸一化互信息取值在0~1之間,值越大聚類效果越好。 為了驗證短文本特征提取方法的有效性,本論文分別使用TF-IDF、Word2vec、BERT預訓練模型進行文本的特征提取,并將該三種方法提取的文本表示向量分別作為K-means聚類算法的輸入,得到三組初始聚類結果。對這三組初始聚類結果使用上述迭代訓練算法進行聚類結果的增強,實驗結果如表3所示。相較TFIDF和Word2vec詞向量表示,使用BERT預訓練模型對聚類效果的提高更為顯著。作用于本文古文短文本數據集中,使用Word2vec訓練詞向量,迭代訓練之后ACC和NMI均提高了接近20%,TF-IDF和BERT預訓練模型分別提高了8%和3%,實驗進一步驗證了迭代訓練對中文短文本基類聚類結果均有提高作用。 表3 對比實驗結果 針對傳統短文本聚類算法文本表示特征稀疏、特征維度高、忽略文本語義信息等特點,本文提出了BERT+K-means+迭代訓練的融合模型對古文短文本進行聚類研究。對比了其他兩種詞向量表示方法,實驗結果證明,該模型具有最優的結果。因此證明了BERT預訓練模型更好的提高了詞向量的表征能力,以及迭代訓練算法在古文短文本聚類算法中的有效性。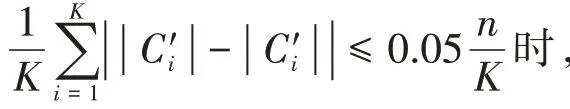
3 算法驗證與結果分析
3.1 實驗數據
3.2 評價指標
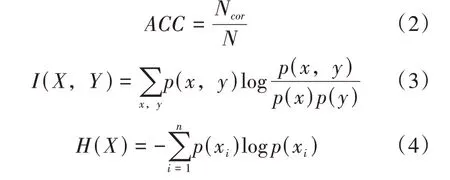
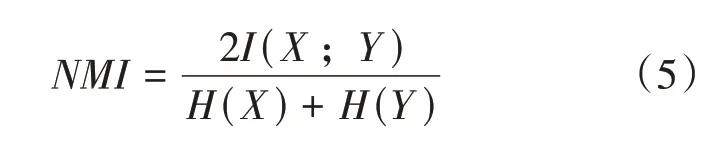
3.3 實驗對比及分析
4 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
