垃圾博客自動識別及檢測技術(shù)研究
2022-04-11 06:57:02王赫楠
智庫時(shí)代 2022年15期
王赫楠
(遼寧中醫(yī)藥大學(xué))
一、研究的背景
進(jìn)入數(shù)字時(shí)代以來,全球的數(shù)據(jù)量呈爆炸式增長,各個(gè)機(jī)構(gòu)或企業(yè)的服務(wù)器都積累了海量用戶數(shù)據(jù)和行為數(shù)據(jù)。如此大規(guī)模的數(shù)據(jù)早已超過了專家人工分析的能力范疇,利用計(jì)算機(jī)自動挖掘、分析海量數(shù)據(jù)成為了學(xué)者們關(guān)注的課題。在此背景下,數(shù)據(jù)挖掘領(lǐng)域應(yīng)運(yùn)而生。數(shù)據(jù)挖掘是指通過計(jì)算機(jī)算法搜索隱藏在海量數(shù)據(jù)中的有價(jià)值信息。文本分類[1-4]是數(shù)據(jù)挖掘中的常用技術(shù),根據(jù)輸入文本的內(nèi)容自動將其劃分到預(yù)定義的類別中。博客分類是文本分類技術(shù)的典型應(yīng)用。
博客繼電子郵件(E-Mail)、即時(shí)通信(IM)、網(wǎng)絡(luò)論壇(BBS)之后,以其方便、快捷、具有共享價(jià)值的特點(diǎn)收到公眾的廣泛使用。2002年至2009年期間,博客用戶數(shù)呈現(xiàn)大規(guī)模增長的趨勢,如圖1所示。博客具有的三大特點(diǎn)吸引了大量用戶:一是以“自由、開放、共享”為理念,提供新形式的人際交流平臺;二是個(gè)性化的信息管理模式;三是改變了傳統(tǒng)的文化初版模式,以獨(dú)立的媒體傳播形態(tài)凸顯用戶生活和工作的方方面面。
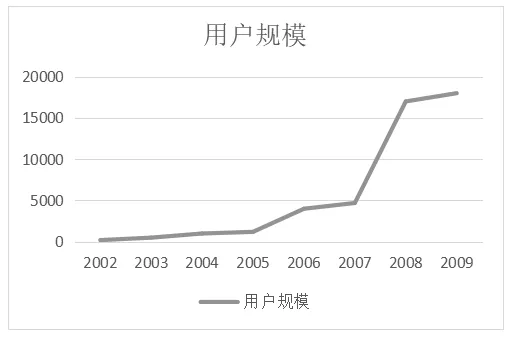
圖1 用戶規(guī)模
在博客蓬勃發(fā)展的同時(shí),垃圾博客 (Spam Blog or Splog)[5-9]這種不良產(chǎn)物隨之而來,嚴(yán)重拉低了博客內(nèi)容的檢索質(zhì)量,破壞博客的網(wǎng)絡(luò)生態(tài)。Umbria[2006]進(jìn)行了為期一周的博客內(nèi)容調(diào)查,統(tǒng)計(jì)發(fā)現(xiàn),2030萬篇博客中270萬篇為垃圾博客,占比超過13%。在用戶數(shù)較多的三種博客網(wǎng)站檢索發(fā)現(xiàn),平均100篇博客中44篇為無價(jià)值的垃圾博客。垃圾博客帶來的主要問題有兩點(diǎn),一是導(dǎo)致信息檢索質(zhì)量的下降,二是嚴(yán)重浪費(fèi)網(wǎng)絡(luò)和存儲資源。垃圾博客的檢測和識別對實(shí)時(shí)性和提前性要求很高,不能帶有任何主觀偏見,且需要保證誤判率低,是一項(xiàng)富有挑戰(zhàn)性的工作。
隨著博客對公眾的吸引力與日俱增,博客網(wǎng)絡(luò)世界也承受了巨大壓力:惡意評論、刷好評、營銷引流等垃圾博客激增,嚴(yán)重降低了博客有價(jià)值內(nèi)容的檢索速度和效率,影響博客用戶有效使用博客中蘊(yùn)含的大量資源。如果不對垃圾博客進(jìn)行控制,那么未來網(wǎng)絡(luò)博客世界將成為毫無價(jià)值的垃圾場。因此,自動過濾垃圾博客迫在眉睫。不僅如此,垃圾博客的存在嚴(yán)重影響了市場調(diào)研領(lǐng)域調(diào)查結(jié)果的準(zhǔn)確性。市場調(diào)研的前提是數(shù)據(jù)的真實(shí)有效,因此必須首先識別出垃圾博客并進(jìn)行自動過濾,為進(jìn)一步的統(tǒng)計(jì)分析奠定基礎(chǔ)。
二、垃圾博客自動識別及檢測技術(shù)
近年來,垃圾博客的數(shù)量和種類明顯增加,如表1所示的各種垃圾博客的占比量。垃圾博客檢測領(lǐng)域受到學(xué)者們的廣泛關(guān)注,但仍處于起步階段。垃圾博客檢測與垃圾郵件檢測任務(wù)類
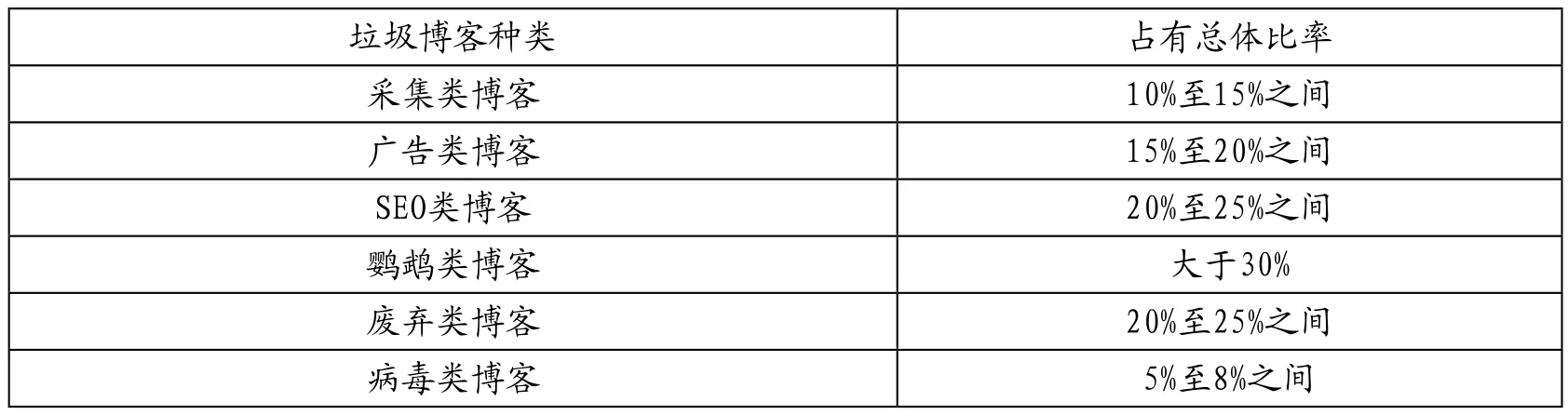
表1 垃圾博客的占有比率
似,都是基于文本內(nèi)容進(jìn)行的識別,但郵件有固定的格式、主題等,更具規(guī)律性,而垃圾博客由于其個(gè)性化的特點(diǎn),識別難度更大。Gy?ngyi and GarciaMolina(2005)首次提出垃圾郵件分類任務(wù),為處理互聯(lián)網(wǎng)存在的其他垃圾提供思路,同時(shí)提出對網(wǎng)絡(luò)垃圾郵件的處理問題[10-11]。Gy?ngyietal(2006、2004)首 先構(gòu)建了一個(gè)種子頁面,在此基礎(chǔ)上設(shè)計(jì)了信任分?jǐn)?shù),從而實(shí)現(xiàn)垃圾郵件的判斷。而內(nèi)容分析是識別垃圾郵件的另一重要方法,可以自動檢測與垃圾郵件頁面鏈接相關(guān)的頁面或關(guān)鍵詞條。Fetterly和Ntoulas在2006年通過研究發(fā)現(xiàn),傳統(tǒng)垃圾郵件通過手動添加鏈接或復(fù)制靜態(tài)頁面實(shí)現(xiàn),但隨著科技發(fā)展,目前,一定數(shù)量的垃圾郵件由機(jī)器自動生成。Fetterly研究了通過拼接高搜索量關(guān)鍵詞自動生成的垃圾郵件網(wǎng)頁的特征。Urvoyetal從超文本標(biāo)記語言的源代碼入手,基于相似度識別垃圾電子郵件。
垃圾博客是垃圾電子郵件的一種特例,可以參考垃圾郵件的識別方法。Kolarietal、Lin等把每篇博客看作為單一、靜態(tài)的頁面,使用基于內(nèi)容特征的詞包和錨的方式,并結(jié)合鏈接特征進(jìn)行垃圾博客識別。Salvetti和Nicolov通過研究發(fā)現(xiàn)垃圾博客中的一些短語是垃圾URL的組成部分,通過URL技術(shù)可以不讀取博客內(nèi)容實(shí)現(xiàn)初步過濾。Hanetal(2006)提出一種協(xié)同過濾方法,但該技術(shù)需要手動識別部分垃圾博客,同時(shí)需要保證信息共享機(jī)制的可信性。
Manually通過創(chuàng)建垃圾博客URL和IP的黑名單,并更新ping服務(wù)器,實(shí)現(xiàn)垃圾博客的過濾。Jindal 等基于二分類學(xué)習(xí)器分類垃圾博客評論[12-13],并通過計(jì)算重復(fù)性進(jìn)一步過濾手工標(biāo)注代價(jià)高的垃圾博客評論。Archana等人從博客內(nèi)容相似度、句子個(gè)數(shù)、重復(fù)詞語、錨文本數(shù)量、停用詞比例等方面進(jìn)行博客垃圾評論的特征統(tǒng)計(jì),但由于中英文的差異,該方法并不能直接應(yīng)用于中文博客。垃圾評論、垃圾電子郵件的內(nèi)容呈現(xiàn)出靜態(tài)化的特點(diǎn),而垃圾博客是動態(tài)變化的,需要實(shí)時(shí)跟隨熱點(diǎn)話題,才能持續(xù)被搜索引擎排在前面,達(dá)到引流的目的。此外,垃圾博客可以利用自動框架生成。因此,只依靠博客文本的基本特征不能夠滿足檢測要求,加入博客的動態(tài)時(shí)序特征可大幅提高垃圾博客的識別率。
目前國內(nèi)在垃圾博客識別領(lǐng)域的研究成果有待完善,大部分學(xué)者著眼于博客文本的統(tǒng)計(jì)學(xué)特征,或鏈接中帶有的垃圾標(biāo)簽特征構(gòu)造識別模型,無法檢測到隱秘性較強(qiáng)的垃圾博客,雖準(zhǔn)確率很高,但召回率低,不能滿足現(xiàn)有需求。劉緯、廖祥文等(2008)分析博客內(nèi)容的統(tǒng)計(jì)特征,根據(jù)文本結(jié)構(gòu)、詞性差異、句子長短等角度選取特征,并綜合各項(xiàng)統(tǒng)計(jì)特征構(gòu)建垃圾博客檢測算法[14]。何海江等人基于向量空間模型(VSM)計(jì)算博客相關(guān)度,從而判斷該篇博客是否為垃圾博客[15],但這種方法存在缺陷, 若某篇博客沒有使用正常博客中常出現(xiàn)的詞語, 而是用近義詞表達(dá),這些詞會被認(rèn)為是其他詞,從而被誤判為垃圾博客。Kolarietal(2006)通過支持向量機(jī)分類器構(gòu)建垃圾博客自動檢測模型,但該方法嚴(yán)重依賴訓(xùn)練語料,人工標(biāo)注成本高,實(shí)際運(yùn)用困難。楊宇航(2007)主要在中文領(lǐng)域進(jìn)行研究,分析中文特征,不需要任何先驗(yàn)知識和訓(xùn)練過程整合的基于多特征的作弊評論識別方法,實(shí)時(shí)性強(qiáng),可在線識別博客,但由于其特征維度過高,大幅降低了識別速度,因此,如何有效提取文本特征是檢測任務(wù)的關(guān)鍵。
三、總結(jié)
博客作為近年來較受歡迎的網(wǎng)絡(luò)交流媒介,為公眾提供了表達(dá)個(gè)人觀點(diǎn)、交流思想和感情的社交平臺。但是隨著博客的受眾面越來越廣,以博客為載體的網(wǎng)絡(luò)垃圾日益凸顯,對網(wǎng)絡(luò)生態(tài)造成負(fù)面影響。繼垃圾郵件、垃圾短信之后,垃圾博客成為了數(shù)字化時(shí)代的第三大污染。目前對于垃圾博客還沒有統(tǒng)一的定義,但本質(zhì)上是指出于某種經(jīng)濟(jì)利益,通過未經(jīng)授權(quán)復(fù)制他人文章等方式,提升帶有某些關(guān)鍵字的博客在搜索引擎排名位置,插入垃圾鏈接或宣傳盈利廣告,導(dǎo)致用戶的時(shí)間和大量網(wǎng)絡(luò)資源的浪費(fèi)。除此之外,博客中包含的海量信息對各個(gè)領(lǐng)域有重要意義,垃圾博客的泛濫降低了相關(guān)調(diào)查研究的準(zhǔn)確性。因此,基于人工智能實(shí)現(xiàn)垃圾博客的自動識別和過濾具有重要意義。
對自動識別、檢測垃圾博客的任務(wù),常用的做法是使用機(jī)器學(xué)習(xí)中的二分類算法。對垃圾博客的識別,主要依靠分類器的識別功能。常用算法有支持向量機(jī)(SVM)[14](Sculley,2007;Datta,2008)、貝葉斯 (Datta,2008)、 決 策 樹 (Decision Tree)(Ntoulas,2006; 劉,2008),集成學(xué)習(xí)之AdaBoost算法(Freund ,1995 )等單一的算法識別垃圾博客效果不夠理想。
猜你喜歡
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
