基于KPCA-WOA-ELM的爆破飛石距離預測?
2022-04-08 01:39:16陳資李昌
爆破器材 2022年2期
關鍵詞:模型
陳 資 李 昌
廣東理工學院工業自動化系(廣東肇慶,526100)
引言
爆破飛石是由爆炸能量突然引起的拋擲泥土和巖石碎片[1]。飛散到爆破安全區以外的飛石容易造成爆破周邊地區工作人員傷亡、建(構)筑物以及機械設備損壞[2]。根據調查統計,20%~40%的爆破相關事故是由飛石引起的[3]。因而,在工程爆破前實現對爆破飛石距離的精準預測、確定合理的爆破安全區域顯得十分重要。
爆破飛石距離受到巖石性質、爆破設計參數、炸藥參數等眾多因素影響[4]。而基于傳統經驗公式法預測爆破飛石距離方法考慮的影響因素少,且無法描述各個因素之間復雜的、不確定性的非線性關系,所以預測準確性不高[5]。鑒于此,一些學者以機器語言算法為基礎理論預測飛石距離,包括BP神經網絡[6]、Elman神經網絡[7]、深度神經網絡(DNN)[8]、粒子群算法優化的人工神經網絡(PSOANN)[9]、支持向量回歸和灰狼算法組合算法(SVRGWO)[10]等。以上方法對爆破飛石距離的預測取得了一定成果,但是大部分方法采用過多關聯因素進行分析,增加了預測模型的復雜度和冗余度,降低了預測效率和準確性。
綜上所述,針對影響因素間存在非線性關系的特征,利用核主成分分析(kernel principal component analysis,KPCA)方法篩選出包含主要信息的主成分作為預測模型輸入變量,并通過全局搜索能力強的鯨魚算法(whale optimization algorithm,WOA)對極限學習機(extreme learning machine,ELM)的主要參數進行優化,克服ELM易陷入局部最優解的缺點,最終建立KPCA-WOA-ELM爆破飛石預測模型,為爆破安全防護工作提供新方法。
1 基礎理論
1.1 核主成分分析(KPCA)法
KPCA是一種在主成分分析法基礎上改進的線性主元分析方法。其基本思想是將低維樣本數據通過核函數非線性映射到高維空間,然后對樣本數據在高維度進行線性降維[11]。KPCA能在不丟失原始樣本信息的基礎上最大限度處理非線性數據,在非線性樣本數據特征提取問題上得到廣泛應用[12-13]。KPCA原理和具體步驟參見文獻[14]。
1.2 鯨魚算法(WOA)
WOA是一種新型的啟發式搜索優化算法。其主要思路是模擬鯨魚包圍獵物、獵殺獵物、搜索獵物等一系列狩獵行為,最終獲得獵物的坐標位置,即最優解[15]。
在捕食行為中,鯨魚會通過收縮包圍獵物,其不斷迭代過程可以通過以下數學模型描述:
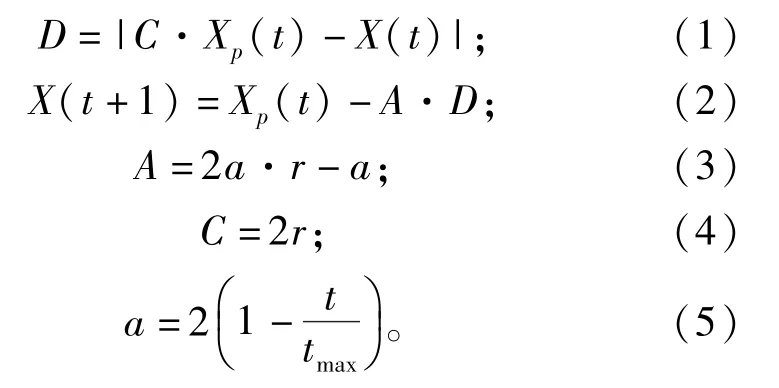
式中:D為鯨魚與獵物間的向量距離;X和Xp分別表示鯨魚和獵物的位置向量;t為當前的迭代次數;r為隨機向量;A為系數向量,用于判斷算法離最優解的距離;C是包含[0,2]隨機值系數的向量,用于增加狩獵過程隨機性,避免算法得到局部最優解;a為收斂因子;tmax為最大迭代次數。
另外,依據獵物所處的位置使用螺旋方程來更新鯨魚的位置:

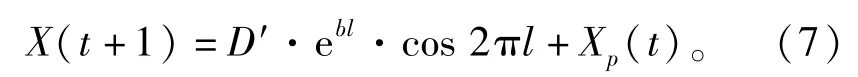
式中:D′為捕食時的鯨魚與獵物間的向量距離;b為螺旋形狀的常數;l為[-1,1]之間的隨機數。
鯨魚在捕食過程中會同時通過收縮包圍獵物和螺旋形狀繞著獵物游動,鯨魚位置通過以上2種方法的50%概率來獲取:
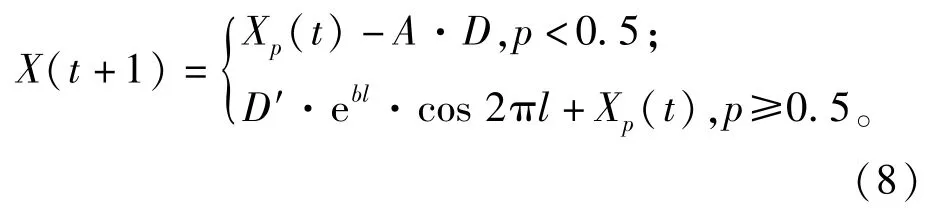
1.3 極限學習機(ELM)
ELM是在單隱層前饋神經網絡基礎上改進的新型智能學習算法,ELM設置參數少、學習速度快、泛化能力好、對非線性樣本數據具有較好適用性,被廣泛應用于各種預測、分類和回歸問題。
對于輸入層神經元個數為n、隱含層的節點個數為L、輸出層神經元個數為m的ELM結構網絡,給定訓練樣本(xj,tj)、輸入向量xj=[xj1,xj2,…,xjn]T、期望輸出向量tj=[tj1,tj2,…,tjm]T,其中,j=1,2,…,N。則期望輸出值為:
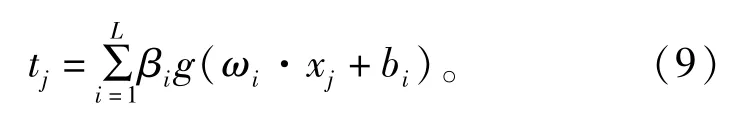
式中:ωi為輸入權值矩陣;bi為隱含層神經元閾值;βi為輸出權值;g(x)為激活函數。
將式(9)轉換成行列式形式:

式中:H為隱含層的輸出矩陣;T為目標期望輸出矩陣。
輸出權值矩陣β為:

式中:H+為矩陣H的Moore-Penrose廣義逆矩陣。
2 KPCA-WOA-ELM模型的建立
為提高爆破飛石預測結果的精度和效率,消除爆破飛石距離影響因素之間的非線性、強耦合和高冗余,解決ELM參數選擇不足等問題,建立爆破飛石距離KPCA-WOA-ELM預測模型,具體流程如圖1所示。

圖1 KPCA-WOA-ELM模型流程圖Fig.1 Flow chart of KPCA-WOA-ELM model
為了驗證KPCA-WOA-ELM模型的預測性能,引入均方根誤差RMSE、決定系數R2以及平均絕對誤差RMAE作為模型評價指標,計算公式如下:
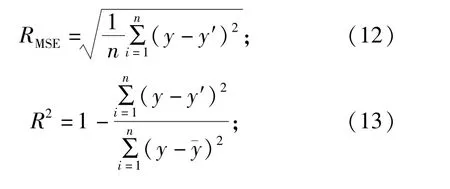
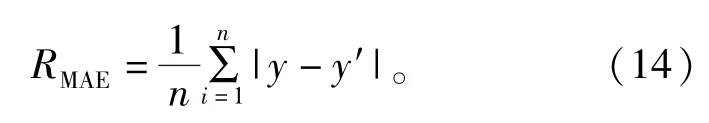
式中:y、y′、ˉy分別是爆破飛石距離真實值、預測值和真實值的平均值。
3 實例分析
3.1 因素分析與數據獲取
爆破飛石距離Df與許多方面因素有關,如爆破參數、裝藥工藝、巖石性質等。合理選取影響因素是確保預測有效性的前提。通過參考國內外相關的文獻以及咨詢相關礦業專家和現場施工人員的具體意見,選取炮孔直徑dB、炮孔深度hD、堵塞長度L、炮孔排距與孔距比B/S、最大段藥量mC、炸藥單耗Q和巖石質量指標RQD7個主要影響因素對爆破飛石距離進行研究。選取某露天礦的40組監測數據作為原始樣本集,如表1所示。
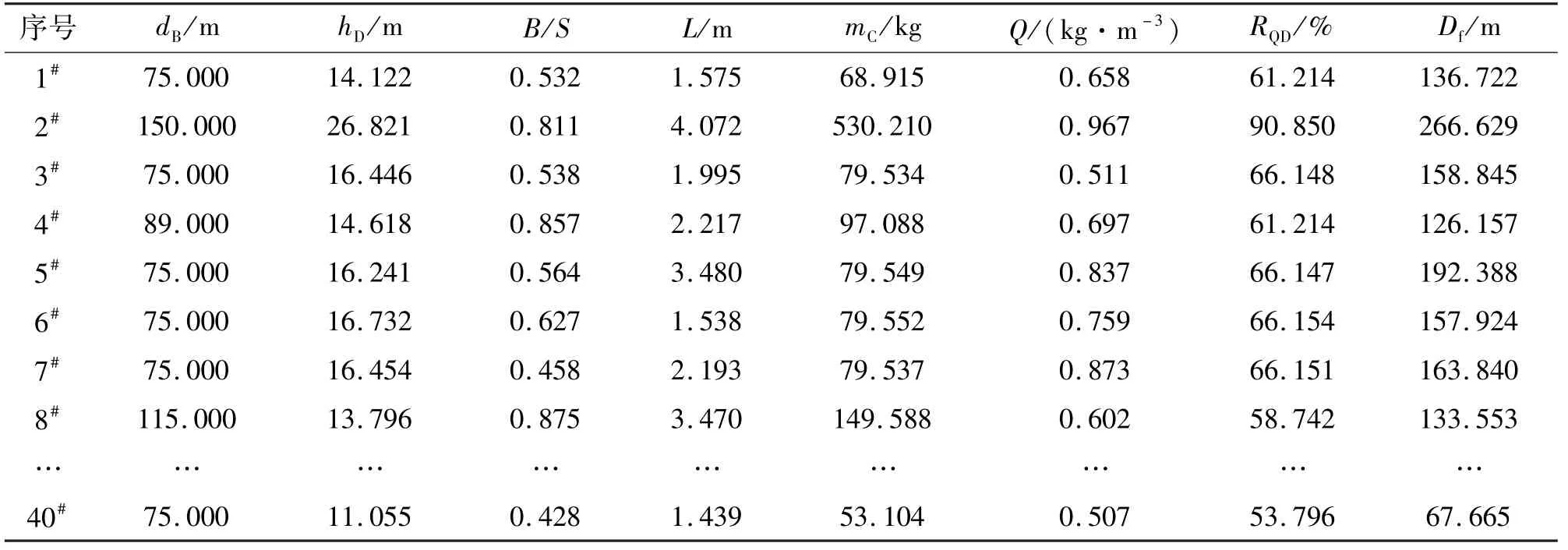
表1 原始樣本參數Tab.1 Data of original samples
3.2 KPCA降維
利用KPCA對原始數據樣本集進行核主成分提取,各核主成分累計貢獻率和特征值如圖2所示。由圖2可知,前4個主成分的累計貢獻率已經達到95.76%,故提取前4個核主成分F1、F2、F3和F4代替原來的7個影響因素,降維后的樣本數據如表2所示。
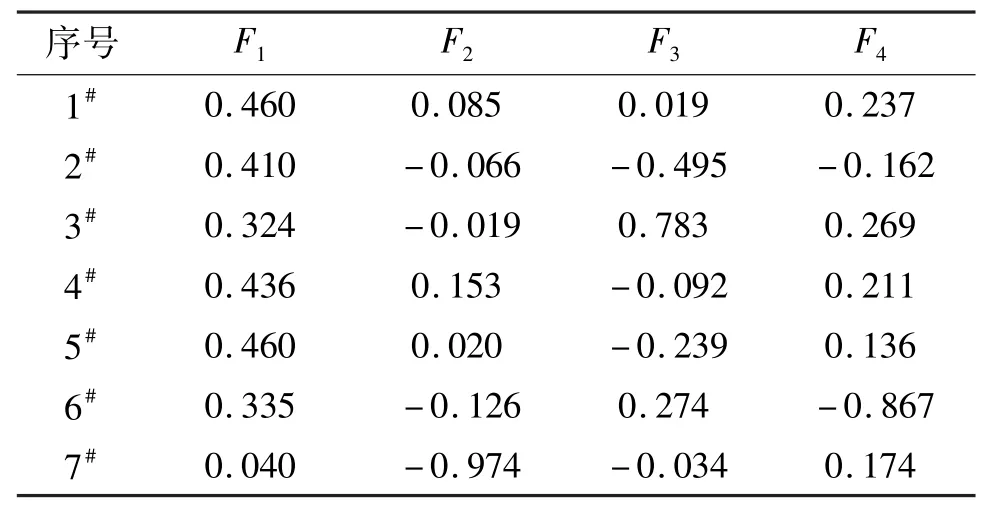
表2 降維后的樣本數據Tab.2 Sample data after dimensionality reduction
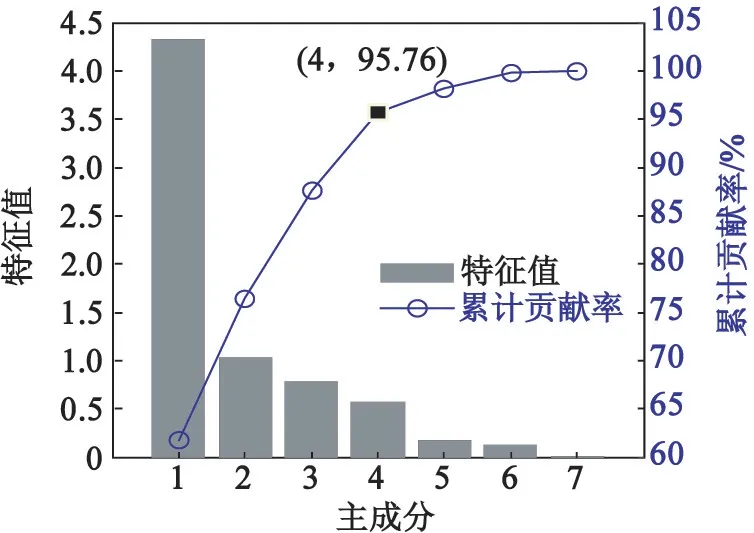
圖2 各核主成分累計貢獻率和特征值Fig.2 Cumulative contribution rate and eigenvalues of each nuclear principal component
3.3 模型訓練及結果分析
將得到的4個主成分作為預測模型輸入變量,以爆破飛石距離為輸出變量,并選取KPCA重構后的數據中前80%作為預測模型的訓練樣本,剩余20%作為測試樣本。
模型中相關參數設定:ELM模型中隱含層激勵函數為Sigmoid函數,輸入層神經元個數為1,隱含層的節點個數為6,輸出層神經元個數為1;WOA算法中,鯨魚種群規模為30,最大迭代次數為200。
為驗證KPCA-WOA-ELM模型在爆破飛石距離預測中的可靠性和有效性,對原始樣本數據分別建立WOA-ELM和PSO-ELM模型,并對3種模型預測結果進行分析。3種模型預測的迭代過程、預測結果以及相對誤差對比分別如圖3、表3和圖4所示。 由圖3可知,相較于使用PSO-ELM,使用WOAELM收斂速度更快,并且經過KPCA降維,同樣也能提高收斂效率。由表3可知,KPCA-WOA-ELM、WOA-ELM和PSO-ELM模型的平均相對誤差分別為4.271%、5.998%和8.997%,說明在相同的條件下,KPCA-WOA-ELM模型預測精度更高。并且由圖4可知,KPCA-WOA-ELM模型相對誤差曲線的波動最小,證明了該模型預測結果穩定性更強。
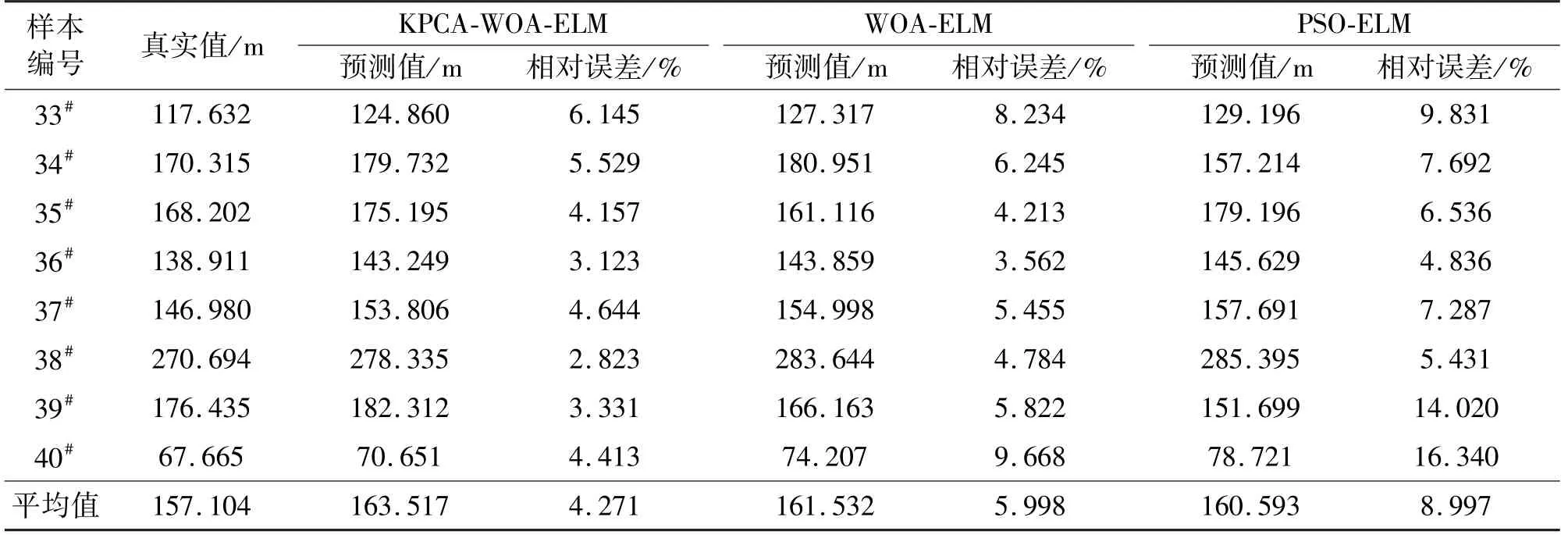
表3 飛石距離預測結果Tab.3 Prediction results of flyrock distance

圖3 不同模型的迭代過程曲線Fig.3 Iteration process curves of different models
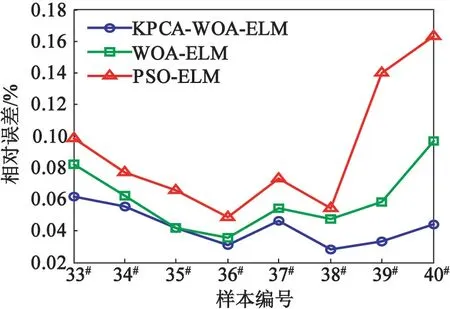
圖4 不同模型相對誤差對比Fig.4 Comparison of relative errors of different models
為了深入比較3種模型預測效果,采用均方根誤差、決定系數以及平均絕對誤差作為評判指標,結果如表4所示。分析表4可知:KPCA-WOA-ELM模型的RMSE和RMAE分別為6.681和6.413,顯著優于其他模型;另外,該預測模型的R2為0.985,比WOA-ELM模型的和PSO-ELM的R2更接近于1,反映出KPCA-WOA-ELM模型擬合度更高,預測精度更好。

表4 模型評價指標結果對比Tab.4 Comparison of model evaluation index results
綜上分析可知:在KPCA-WOA-ELM模型中,KPCA能在保留原有信息的前提下,降低影響因素之間信息的重疊;并且WOA算法能夠克服ELM易陷入局部最優解的問題,提高模型預測精度和效率,使得預測值更貼近于真實值。
4 結論
1)選取影響爆破飛石距離的7個主要因素,在不遺失原始樣本信息的前提下,通過KPCA篩選出包含主要信息的4個主成分,降低了樣本數據間的耦合性和冗雜性,有效提高模型的預測效率和精度。
2)使用WOA算法對ELM參數進行尋優,解決了傳統ELM參數人工選擇具有盲目性、收斂速度慢、容易陷入局部最優等問題,強化了模型學習能力和泛化能力。
3)應用實例結果表明,KPCA-WOA-ELM預測模型的各項評價指標均優于WOA-ELM和PSOELM模型。該模型的提出為爆破飛石距離預測提供了一種更為可行的新思路。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
