融合多粒度全局信息的臨床問診信息抽取模型
2022-04-08 11:23:58李珊如喬曉輝楊丹青
中國新技術新產品 2022年2期
李珊如 喬曉輝 楊丹青 劉 彥
(1.河北漢光重工有限責任公司, 河北 邯鄲 056017;2.河北省雙介質動力技術重點實驗室,河北 邯鄲 056017)
0 引言
電子病歷(Electronic Medical Record,EMR) 在現代醫療信息系統中被廣泛應用,但醫生為病人寫電子病歷是一項非常耗費精力和時間的任務。因此,為了減輕醫生的沉重負擔,將醫患對話自動轉換為電子病歷是近年來自然語言處理領域的新興課題。
為了應對上述挑戰,該文提出了一個新的醫學信息抽取模型,該模型充分利用了對話中潛在的相關上下文,這是因為當前轉折后的對話內容可能會改變醫學實體的狀態。首先,模型從當前對話窗口中檢索詞級的相關信息,并將整個窗口文本編碼為窗口。其次,該文在整個對話中合并2種類型的信息:1)細粒度信息。集成了整個對話中的所有共現詞特征。2)粗粒度信息。選擇一個信息最豐富的下方窗口作為該文的全局信息,并與當前窗口進行融合,從而預測所有可能的醫學標簽。
在試驗中,該文用公開的研究性數據集MIE對該文的模型性能進行評估。該文在完成MIE任務過程中獲得了48.61%的分數(分數為準確率和召回率的調和平均數),該結果是目前最先進的結果,這也驗證了該文所提出的模型的有效性。
1 相關工作
從醫學對話文本中提取信息是一個新的研究熱點。文獻[3]提出通過一個管道模型(包括5個模塊)來生成電子病歷,主要研究基于規則與監督的機器學習相結合的提取醫學知識的方法。文獻[4]旨在提取癥狀及其對應的狀態,在工作中預先定義了186個癥狀和3個狀態,還提出了一個跨屬性標記模型,該模型預測所提到的癥狀的文本段,然后使用上下文特性進一步預測癥狀名稱和狀態。還用BIO(即開端、內部或其他)模式注釋了中文在線醫學對話。但是,該方法只將癥狀標注為實體類別,而沒有考慮其狀態,這與實際場景并不兼容。
最新的工作是執行MIE任務,它有一個更詳細的標注模式,其包括4個醫學類別、71個子項和5個狀態。研究人員提出的管道模型由4個子模塊組成,迭代地對整個標簽集進行分類預測。雖然該文的標簽與MIE是一致的,但是MIE部署了不合理的狀態更新機制,后續的狀態會盲目覆蓋之前的狀態。由該文對MIE數據集的分析可知,這種機制只對一小部分實體有效,對其他實體無效。
2 模型
該文所述的模型是一個端到端的臨床問診醫學信息抽取模型。模型的框架如圖1所示,它包括5個部分:1)窗口編碼層將原始輸入轉換為上下文。2) 細粒度文檔感知融合模塊。該模塊利用每個詞在全局對話中的共現實體信息。3) 標簽-句子注意力機制。采用窗口對標簽信息的相關度進行建模。4) 粗粒度全局上下文信息融合模塊。該模塊將全局窗口中信息最豐富的窗口融合到當前窗口中。5)MIE預測器模塊。該模塊用1個二分類器去預測標簽集中的所有候選項。
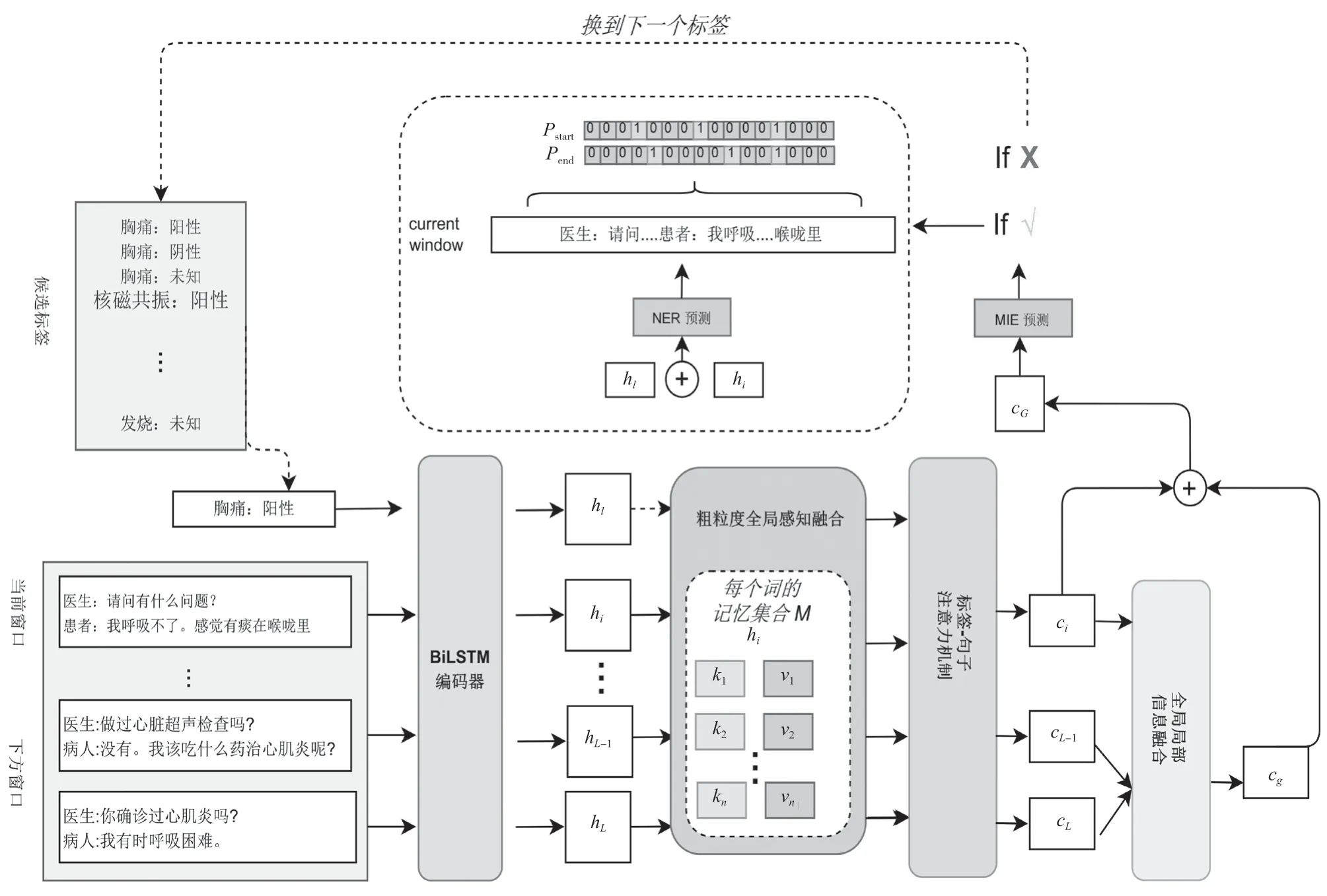
圖1 模型結構圖
2.1 窗口編碼層
該文將2個連續的語句定義為1個窗口,分別由醫生和病人所表達的句子組成。因此,整個問診文本可以劃分為多個窗口={,,…,x},為窗口的個數。對于每個窗口x來說,該文連接醫患話語,并使用BiLSTM網絡將其編碼為語境詞,如公式(1)所示。

式中:x為窗口;h為窗口的LSTM隱層。
對每個候選標簽來說,該文也采用公式(1)所表述的方法將其編碼為標簽h。該文的模型還設計了標簽-句子注意機制,利用該機制對提取出來的詞級標簽相關信息()在窗口()內的上下文相關性進行建模。因此,該文將標簽h作為注意機制的一個詢問,從而計算窗口的注意力分數,進而可以得到特定于標簽的窗口c,如公式(2)~公式(4)所示。

式中:a為注意力分數;p為注意力權重;c為特定于標簽的窗口;h為第個窗口;h為標簽。
2.2 細粒度的文檔感知信息融合
每個實體的狀態與整個對話中同一實體的所有實例有關。例如,對實體“冠心病”來說,上文窗口的“冠心病”狀態信息直接由下文窗口的“冠心病”決定。因此,為了獲得一些上下文知識,模型必須將所有來自其他實例的整體信息利用到當前實體中。
通過利用MemoryNet,該文引入了每個實體的文檔感知。該文定義了1個內存集={,},{,},…,{k,v}為每個詞存儲對話中的所有共現詞的實例。其中,鍵值k為x的詞嵌入向量;值v為第個詞的隱藏狀態;為實例個數。詞嵌入在訓練過程中會被微調,從而更新記憶網絡的參數。
對每個單詞x來說,為了融合其文檔感知,該文用其詞向量k作為注意力的鍵值,計算記憶集中隱藏狀態v之間的注意得分,如公式(5)所示。

式中:d為單詞嵌入的維數;o為注意力得分;k為鍵值v(轉置后)的值。
文檔感知如公式(6)~公式(7)所示。

式中:α為注意力分數;d為文檔感知;o為注意力得分;為單詞個數;為文檔個數。
該文將當前詞的隱藏狀態h與文檔感知d融合,并將其提供給標簽-句子注意力模塊,如公式(8)所示。

式中:為超參數,用于平衡隱藏狀態h和文檔感知d。
2.3 標簽-句子注意力機制
標簽-句子注意力機制在窗口g中對所提取的詞級標簽相關信息h的上下文相關性進行建模。具體來說,該文將標簽h作為注意力機制中的一個查詢來計算窗口的注意力得分,從而該文可以獲得標簽特定的窗口c,如公式(9)~公式(11)所示。

式中:α為注意力分數;h為標簽;p為注意力權重;c為標簽特定的窗口。
綜上可得,模型可以將當前標簽的信息融合到當前的對話窗口中。
2.4 粗粒度全局上下文信息融合
因為當前窗口的狀態不僅由當前對話窗口信息決定,而且還由下方窗口的相關信息決定,所以該文需要考慮窗口之間的交互信息。值得注意的是,由于狀態更新是基于下方的問診文本,而不是之前的文本,因此該文沒有必要考慮當前窗口之前的窗口,即歷史信息。
該文采用了一個動態的注意機制來融合下方窗口信息。具體來說,該文將當前窗口c作為注意力機制的查詢,將下面的窗口{c+1,…,c}作為鍵矩陣和值矩陣。當當前窗口下降時,后續窗口的個數減少,最后一個窗口沒有后續窗口。
其中,下方窗口中注意力得分最高的窗口c被認為是對當前窗口信息最充分的下方窗口,該文將采用c作為全局信息,并將其連接到當前窗口,以輔助預測后續的狀態。具體步驟如下:給定當前窗口c,計算下方窗口的注意力分數,如公式(12)~公式(13)所示(∈(+ 1,))。將注意力分數最高的窗口c連接到該文當前的窗口c,將其作為該文的全局c(如公式(14)所示),表示連接操作,如果當前窗口是問診文本中的最后一個窗口,則c被設置為0。

2.5 MIE預測器
將全局-局部上下文聚合模塊c的輸出作為該模塊的輸入。具體來說,該文迭代每個MIE中的標簽項,并采用二分類器來預測該窗口是否表達了后續的MIE標簽,如公式(15)~公式(16)所示。

式中:forward為前饋神經網絡;sigmoid為二分類器;c為前饋神經網絡結果;y為二分類概率。。
3 試驗
該文在MIE數據集上進行試驗。首先,該文在3.1節中詳細地闡述了模型細節、基線和評價指標。其次,在3.2節中提供了詳細的試驗結果,也分析了不同模型成分對消融研究的影響。最后,該文提供了1個案例研究和1個應用場景。
3.1 基線模型與評估指標
在試驗中,該文對MIE任務中提出的基線模型進行了對比。其中,Plain-Classifier利用1個基本的類分類器模型,使用1條簡單的策略來完成任務。MIE-single表示只考慮單個話語內的交互的模型,所獲得的表示相互獨立。multi能夠捕捉不同話語之間的相互作用。為了獲取其他話語的相關狀態信息,它將類別表示作為查詢,獲取對狀態的注意值,然后獲得該話語的候選表示。
對MIE任務來說,該文只使用對話級度量,因為窗口級度量包括大量的標簽冗余,所以每個標簽都可能被多次計算,從而對其進行評估。首先,該文將屬于同一個臨床問診窗戶的結果進行合并。其次,評估每篇問話文本的結果。最后,報告測試集中的微平均值。
對模型參數和試驗設置來說,為了保證公平,該文基本上與MIE任務保持一致。該文使用300維Skip-Gram詞嵌入,預先訓練了來自中國在線健康社區的醫學對話,前饋網絡和Bi-LSTM的隱藏狀態大小均為400。該文使用Adam優化,使用學習率衰退和正則化來緩解過擬合問題,并采用根據驗證集的得分進行訓練的提前停止(Early Stop)。
3.2 結果與分析
在測試集中,該文分別評估了該文所述模型在類別級(Category Only)和全級(Category and State)中的性能。其中,類別級表示模型只需要關注醫學標簽本身,不需要關注其狀態;而在全級中,模型只有在醫學標簽和狀態都正確的狀態下才會被認為模型預測是正確的。
該試驗結果見表1和表2。MIE-single和MIE-multi模型所獲得的結果都比Plain-Classifier模型獲得的結果好,這表明MIE體系結構比基本的LSTM表示方法更有效。與MIE中的基線模型相比,該文的模型不僅可以捕獲話語和標簽之間的交互,還可以整合來自以下窗口的信息。因此,該文提出的CLINER在類別級和全級評價中分別比這些基線高2.78%和0.58%(分值)。
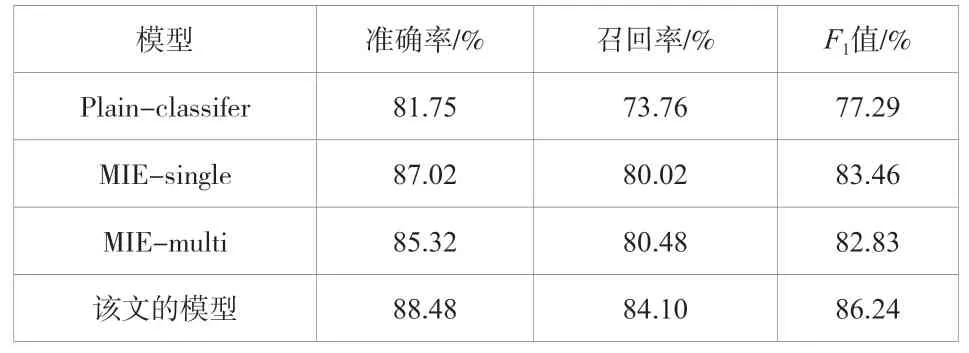
表1 MIE數據上類別級的試驗結果
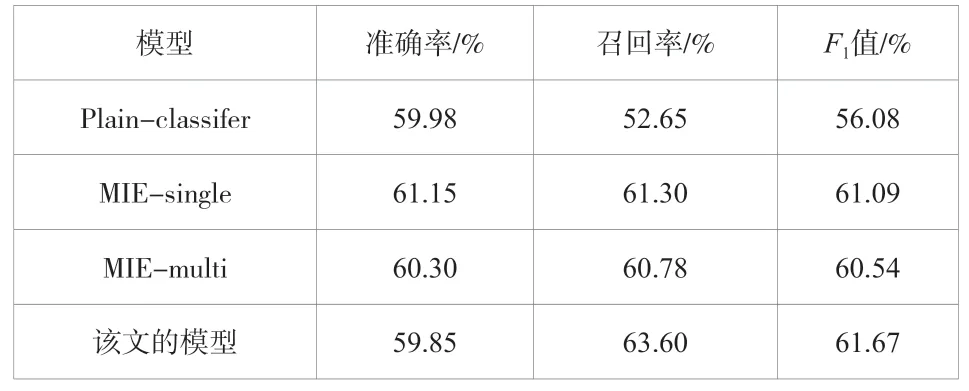
表2 MIE數據上全級的試驗結果
同時,該文對模型進行消融試驗,從而評估在MIE數據中不同模型組件的有效性。其中,該文所述模型代表了具有最佳性能的所有模塊的完整模型。表3的結果表明,去除細粒度的文檔感知將導致值下降1.25%。該文可以推斷模型性能與實體的所有實例的信息有直接關系,這些信息決定了實體級狀態的變化。此外,在去掉粗粒度的全局上下文聚合的情況下,模型性能下降了1.70%,它沒有將信息量最大的窗口嵌入下面的文本中(以幫助當前窗口捕獲狀態的變化)。如果忽略標簽 - 句子注意力信息,那么模型的值在MIE任務中降低了1.12%,這表明標簽句注意能夠捕捉當前候選標簽與話語之間的交互信息(會強調話語中最相關的單詞)。
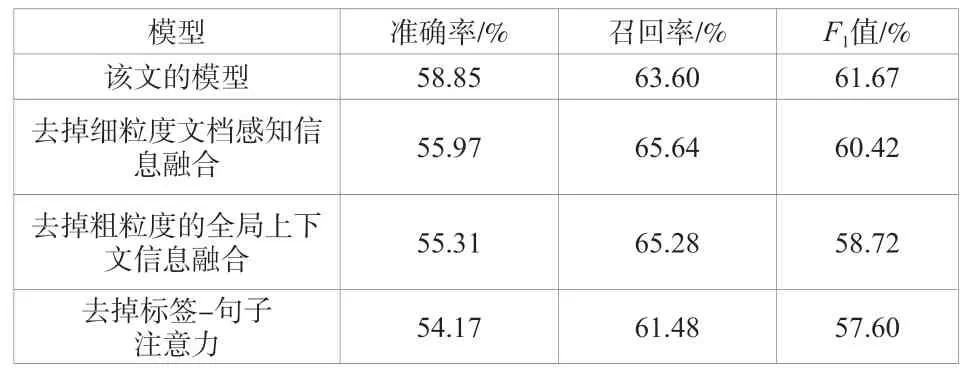
表3 不同設置下的消融試驗
為了進一步驗證該文所述模型的有效性,該文在測試集中挑選了圖2中的實例,并對對話級和窗口級注意力熱圖進行可視化操作。對話級注意可視化表明,該文的模型檢測到與給定類別“心肌梗死”語義相關的標記。該文可以很容易地發現標簽“心肌梗死”與當前窗口中權重最大的文本“心肌梗死”相關。
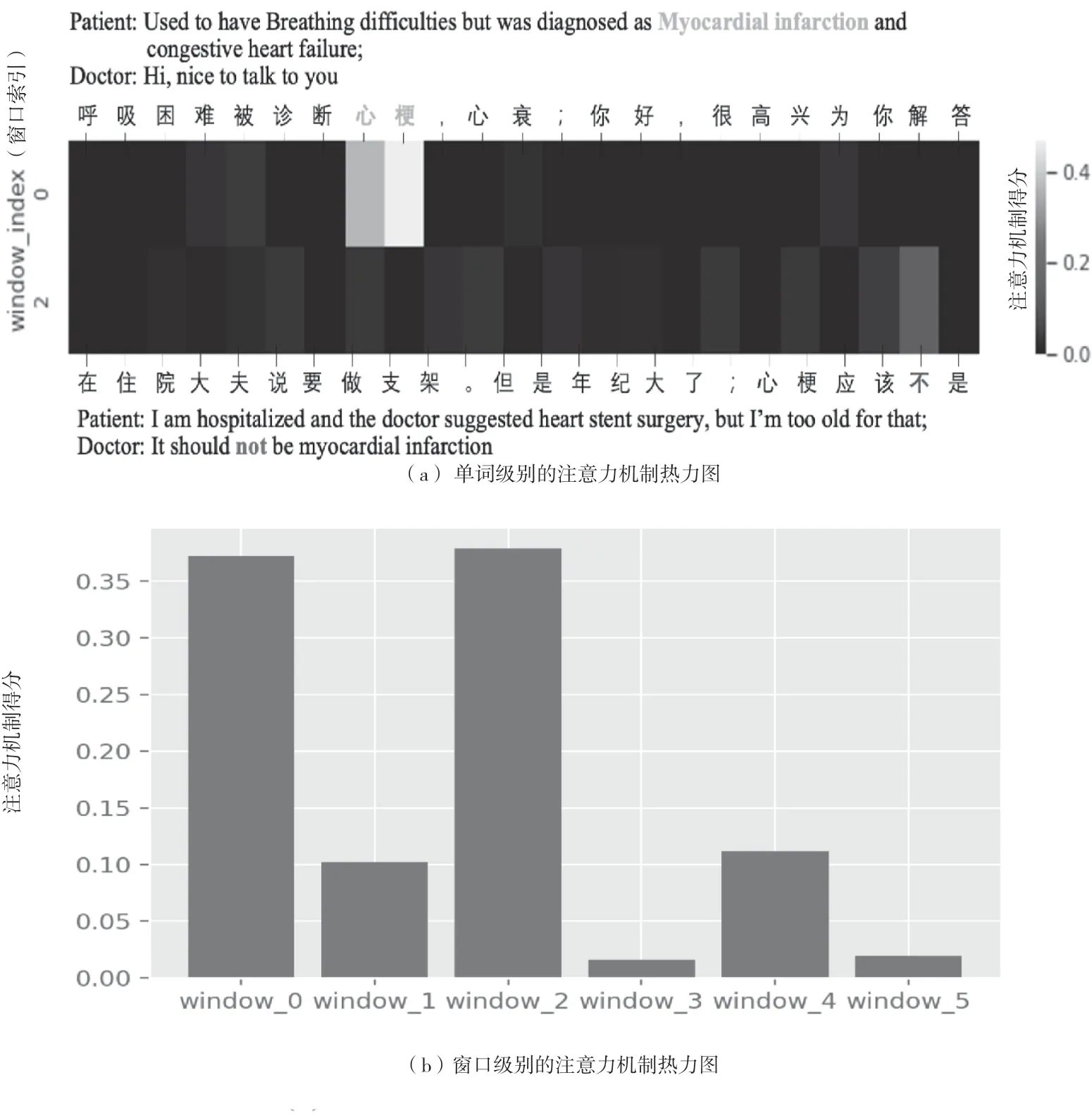
圖2 該文所述模型的可視化例子
為了進一步確定狀態,模型計算當前窗口和以下窗口之間的注意分數。該文選擇關注度最高的窗口2作為該文的全局信息,并將其添加到狀態預測中。在熱力圖中,該文注意到標記“No”被突出顯示,并進一步用作關鍵參考,以正確預測當前窗口中給定標簽的狀態為“negative”。而傳統的方法如果不考慮窗口2的信息,則無法正確預測該標簽,最終導致該窗口狀態預測失敗。
4 結論
在該文中,該文建立了1個臨床醫學對話文本的信息抽取的模型,該模型由4個模塊組成,可以充分利用以下窗口中的相關上下文,從而更好地捕獲狀態的更新情況。在MIE任務中的試驗表明,該文的模型可以有效地提高性能(性能優于基線模型)。該模型在臨床試驗中有較高的應用價值,為提取臨床問診信息的提取提供了一種很有前景的解決方案。在未來的工作中,該文將進一步利用標簽中的內部關系,嘗試將豐富的醫學領域知識引入該文的模型中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
