煤礦大數據安全預警云平臺設計
2022-04-08 11:26:06劉斌
中國新技術新產品 2022年2期
劉 斌
(神木市能源局信息指揮中心,陜西 神木 719300)
0 引言
煤炭開采活動受限于多變的復雜環境,近年來,由于國家高度重視礦山生產安全,2019年《煤安監【2019】42號國家煤礦安監局關于加快推進煤礦安全風險監測預警系統建設的指導意見》等文件先后出臺,在現有安全預警系統和政策監管的共同作用下,國內煤炭開采活動形式略有好轉,但仍事故頻發。
目前國內眾多學者對數字礦山、智慧礦區領域進行了不同的研究,略有成果。闕建立、羅香玉等人通過分析智慧礦區的特點,介紹了支撐智慧礦山的技術架構,呂情緒、竇林名等人通過大數據、云平臺等技術智能判識沖擊礦壓風險與多參量監測預警。以上學者分別從不同角度對智慧礦區如何解決精穩預警難題進行深入探討,但仍存在以下幾個問題:首先基于大數據的智慧礦山預警平臺須保證數據的精確實時性,但實際數據采集過程中難以達到數據準確性,在遇到大面積懸頂隱患、老空水害、自燃發火隱患等問題時無法及時預警。
智慧礦山的建設離不開海量多元異構數據的處理,鑒于此,以數據為基礎,以大數據云平臺技術為依托,提出一種煤礦大數據安全預警云平臺技術方案,以期分析煤礦安全數據,為礦區安全精穩預警決策提供數據支撐。
1 煤礦安全預警平臺建設面臨問題
自陜西煤礦安全監察局【2020】152號文件《關于做好礦用設備監察管理系統聯網和設備管理工作的通知》發布以來,保證人員與設備的可靠環境任務重中之重,這些人員與設備的可靠環境包括通、采、掘、機、運等80多個子系統,這些子系統相互協同配合,構建成了一個龐大復雜的運行體系,在工業互聯網、工業物聯網、大數據、云平臺背景下,這一運行體系也逐步從機械化、自動化、數字化向智能化、智慧化方向發展。陜西省煤礦信息化建設也逐步由數字礦山、感知礦山向智慧礦山轉變,雖然取得一定成果,但是在數據處理方面仍存在多方面挑戰。
1.1 保證獲取數據準確性
礦山的生產數據主要由基礎數據、傳感器感知數據和外部數據組成。目前,填報數據獲取的真實性、周期性較差,一些非結構化視頻數據獲取的真實性、實時性較好,感知層采集的數據真實性、實時性仍需增強。因此如何增強數據的可依賴性成為建設智慧礦山的關鍵因素之一。
1.2 全方位融合分析數據
數據作為信息的原始資料,是通過數字、圖形、 文字、及介質來描述的事件、現象的特征,數據類型的研究是數據融合技術的基礎。煤礦的安全預警平臺經過多年信息化演變,已經衍生出海量的結構化和非結構化數據,它包括礦山礦壓監測數據、GIS數據、瓦斯監測數據、礦圖數據等,其中技術人員分析重點在不到5%的結構化數據,因此數據采集過程后并沒有對數據進行深入分析、挖掘、關聯、融合,使數據存在大量信息孤島、業務鴻溝和系統煙囪,無法從更多的角度感知事故風險,進而不能真正將虛數據變成實數據,從而不能精穩實現風險預警和智能研判,難以實現安全關口前移。
2 煤礦安全預警平臺關鍵技術
該文將大數據預處理技術和Hadoop云平臺框架應用于煤礦災害監測預警系統中,使用大數據預處理技術對感知層采集的數據進行清洗、集成、規約和變換,利用Hadoop計算框架和分布式框架及生態技術實現數據分析的可視化顯示。
2.1 Hadoop云平臺
Hadoop是一種分布式計算框架,可以對海量的數據進行分布式存儲和分析,Hadoop項目結構如圖1所示。
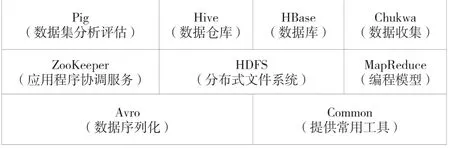
圖1 Hadoop項目結構
云平臺是以虛擬化技術為基礎,以網絡為載體的超級計算,其通過基礎架構平臺或軟件等服務形式,整合了大規模可擴展的計算,存儲數據應用等分布式計算資源來進行協同工作。從技術方面看,云平臺的體系結構由物理資源、虛擬資源、管理中間控件和服務接口組成。從實現角度看,云平臺體系結構由用戶界面、系統管理、部署工具、服務器集群、服務目錄和資源監控組成。
其中HDFS是一種分布式文件存儲系統,它具有存儲數據量大、流式數據訪問等特點。一個HDFS集群具備兩個管理節點NameNode和Secondary NameNode,還擁有多個數據節點DateNode。NameNode作為主服務器,它用來監控DateNode節點的運行狀況以及協調存儲任務或者文件分接任務的分派,Secondary NameNode的主要作用是協助主服務器處理映象文件和事務日志,而DateNode節點屬于數據存儲的基本單元,負責存儲本地數據并定期上傳到主服務器。
2.2 基于數據融合的大數據預處理技術
現實環境中單一傳感器采集的數據容易受到煤塵、高溫、水蒸氣和輻射等因素干擾,大部分數據存在異常或缺失的臟數據,因此,要對數據進行清洗、集成、規約和變換,就要將異常數據進行丟棄或者填補,但直接將數據丟棄會導致數據樣本減少,從而降低分析精準度。所以往往通過填補方法進行數據預處理,常見的填補方法有移動平均線插值法、AR模型插值法,但以上幾種方法都是基于單一傳感器對環境進行監測并且上述方法會將誤差進行傳導,存在采集信息有限、數據準確性低等問題。
數據融合技術是一種將通信信息、數據分析、人工智能等多種技術集成于一體的數據處理技術。可以有效解決以上幾種問題,因此根據一些特定監測場景,例如瓦斯氣體在巷道中運動的特性和在開采過程中巖移運動對支架圍巖所產生的作用力的礦壓特性,實現多元傳感器集群的數據融合、采集、剖析、處理等過程。
3 煤礦安全預警平臺設計
3.1 系統功能設計
基于大數據預處理和Hadoop云平臺的煤礦安全預警平臺主要由多元傳感器集群、煤礦數據云存儲中心以及交互中心三個部分組成,系統總體結構如圖2所示。
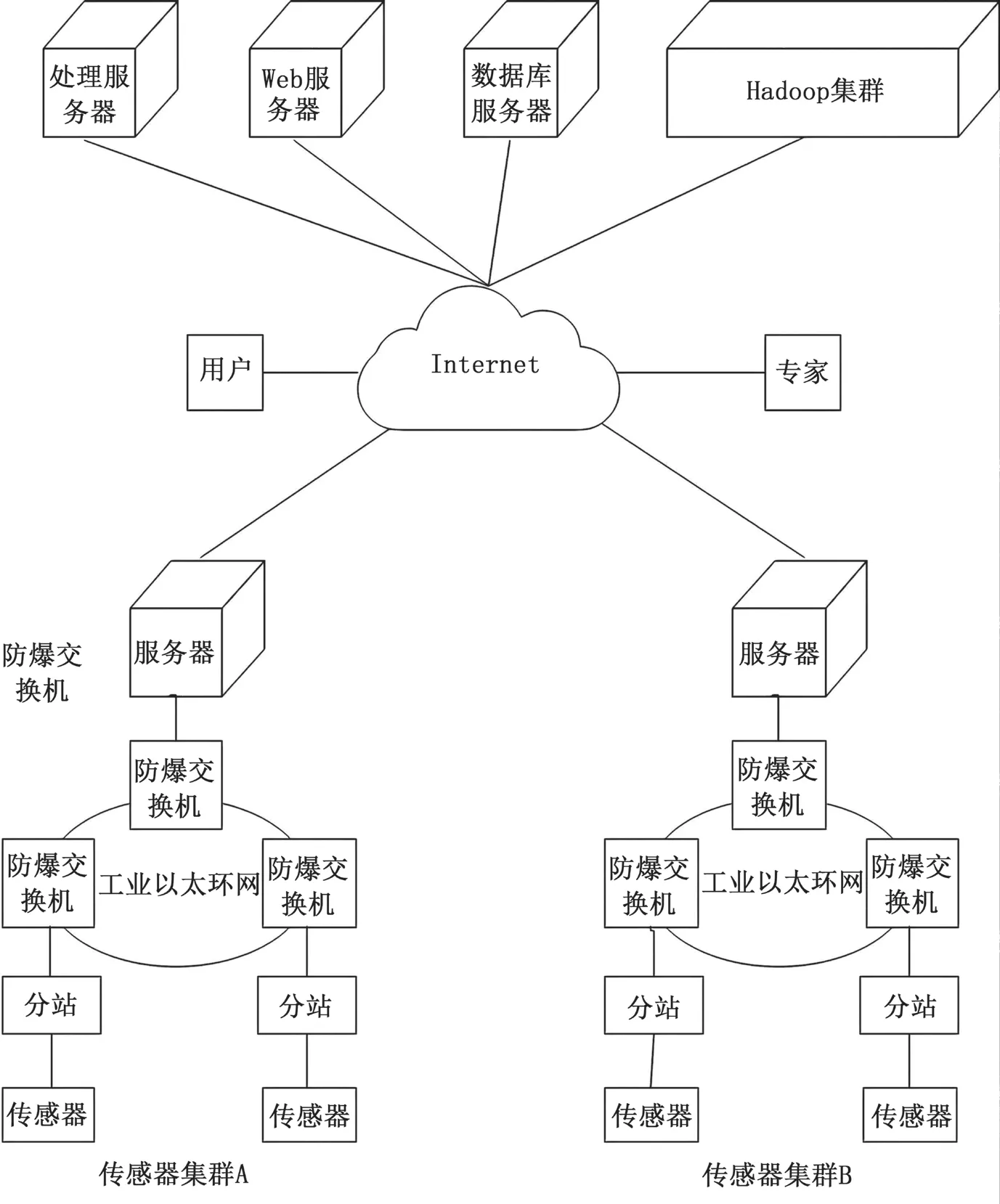
圖2 系統總體結構圖
該平臺的主要功能:將傳感器集群采集到的數據通過較優的存儲策略上傳并存儲到平臺上;將傳感器集群采集的數據匯總起來進行資源和管理的再分配,并對這些數據進行深度挖掘和數據融合處理,對礦山風險進行有效預警,實現安全關口前移。
數據采集功能的結構由微震與圍巖應力測量系統以及它們各自的接入端、云處理服務器和通信網絡組成。數據采集功能流程為:各個煤礦將接入端實時生成、更新的微震和圍巖應力測量數據以包的形式通過工業以太環網上傳到云處理服務器中,隨后云處理服務器將這些包文件進行歸類轉換,礦區上傳的數據包文件類型主要有W震動波型文件Data文件、含有文字和圖表的壓縮圖文文件Surfer文件、報表文件Plot文件、數據庫類型文件SOS文件以及其他類型文件,云處理服務器將Data文件和Surfer文件進行圖形化處理后轉換成圖片格式存到云端,再將處理后的Surfer文件底圖與SOS數據庫文件相結合經過數據融合技術最終顯示到云共享平臺上。因此數據采集功能主要有文件歸類、文件轉存、可視化功能,功能結構圖如圖3所示。
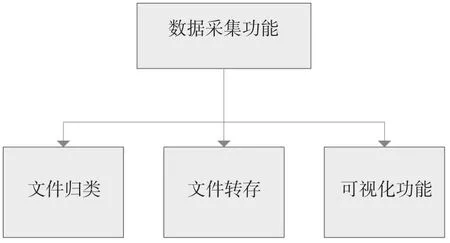
圖3 數據采集功能功能結構圖
煤礦災害數據具有數據規模大、數據種類的以及數據延伸范圍廣等特點,針對以上數據特點若采用關系型數據庫,則會遇到數據結構不便調整等問題,因此該文選用云存儲這種具有擴展性強、可靠性高的存儲架構作為處理龐大的安監數據最適合。各個煤礦將接入端實時生成、更新的微震和圍巖應力測量數據通過工業以太環網上傳到云處理服務器中并存儲到MySQL數據庫或Hbase數據庫,對上傳文件類型來說,則將分好類的文件存到HDFS中,因此云存儲框架如圖4所示。
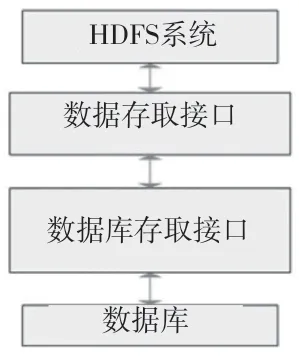
圖4 云存儲框架
該文設計的HDFS集群包括4個Node節點,通過副技術可以有效提高數據的可靠性,但在實際情況中副本存在性能和存儲差異并且煤礦災害的突發性導致經常要對數據進行讀寫操作,HDFS系統通常采用默認副本策略,該策略會使數據副本隨機集中存在某個上Node節點上,發生監測數據在Node節點分布不均的情況,嚴重則導致負載溢出的現象。因此該文采取基于節點性能的副本存儲策略,該策略可以有效將讀寫或并發操作發散到多個節點進行并行處理,降低系統響應時間,提高資源利用率。具體實現思路如下:首先將4個Node節點的存儲空間利用率、CPU利用率、磁盤讀取速率、傳輸速率、內存占用率作為指標列建立一個4×5的指標矩陣并對其進行規范化處理,依次定義每個指標的權值為=0.2、=0.1、=0.3、=0.3、=0.1,對矩陣進行賦權后得到矩陣,通過分析可知每列指標的最大值和最小值,然后通過歐式距離法求出每個Node與最大值和最小值的距離,最后選出個節點作為最佳存儲副本的節點。
操作人員通過構建數學模型對傳感器集群采集的多源數據進行影像重構操作,生成優化數據層,再應用到云共享平臺,最終顯示當前預警信息圖件。該文采用基于特征的數據融合技術,在處理服務器把Data文件和Surfer文件進行圖形化處理并轉換成圖片后,抽取原始信息中的特征信息,特征信息需具備原始信息的充分表示量或充分統計量特點,根據生成的圖像波普利用小波變換對其進行頻率域-空間域的變換和多層分解,再對待融合數據統計方差和均值,確定子帶和基子帶的融合值,最后通過小波逆變換重構圖像。
3.2 云平臺設計
在3.1.1中提到將分類好的監測數據通過計算機群組搭建的Hadoop集群將海量多元異構數據文件批量存儲到云端上;在數據層上,HDFS集群可以對其進行刪、改、查等操作;云共享平臺的預警顯示是采用B/S模式,通過應用層的接口調用HDFS API,進行Hadoop集群交互,訪問HDFS;通過用戶層可以進行注冊、登錄、訪問云平臺獲取一系列的災害分析情況。該文的Hadoop云存儲框架如圖5所示。
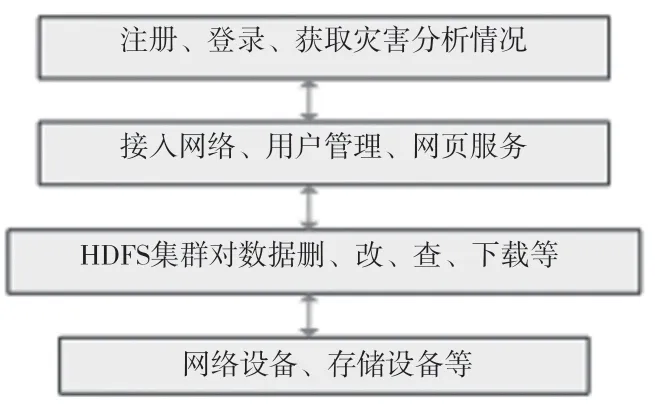
圖5 云存儲平臺結構劃分
該文搭建的Hadoop集群硬件信息見表1。
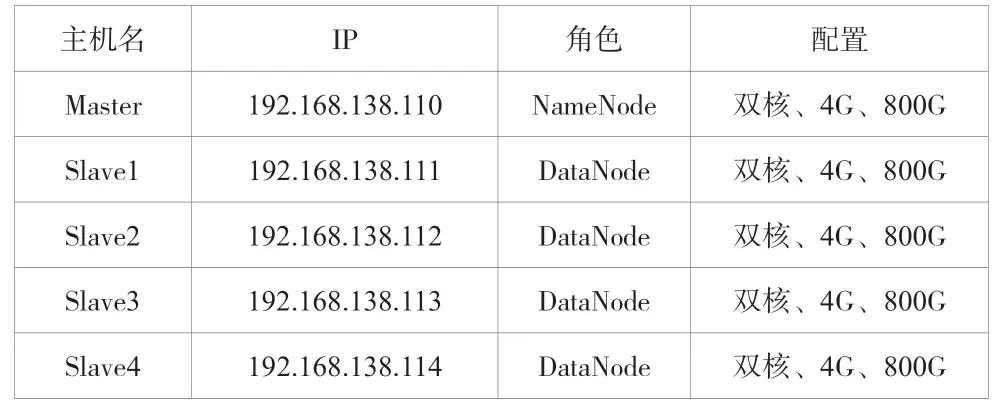
表1 硬件信息
軟件平臺為Linux Ubuntu 14.06操作系統,開發工具為IDEA,軟件所需環境見表2。
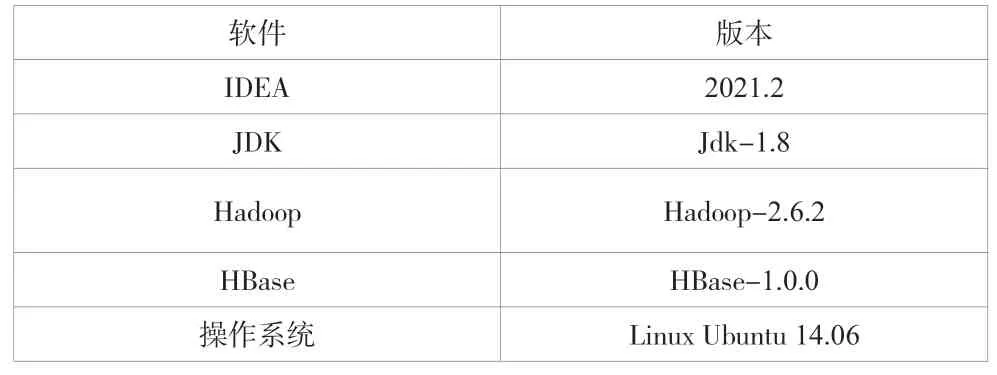
表2 軟件環境
4 結論
該文以煤礦安全預警平臺為背景,針對傳統煤礦安全預警數據采集過程中難以達到數據準確性,數據存在大量信息孤島、業務鴻溝和系統煙囪不利于對數據進行深度挖掘、分析和融合等問題,結合大數據技術和云平臺框架對海量數據進行處理,該平臺保證了煤礦生產高效、穩定、可靠運行。
猜你喜歡
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
現代礦業(2021年12期)2022-01-17 07:30:32
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
河北地質(2021年2期)2021-08-21 02:43:50
神劍(2021年3期)2021-08-14 02:30:08
昆鋼科技(2021年2期)2021-07-22 07:47:06
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
礦產勘查(2020年7期)2020-12-25 02:43:42
無線電工程(2020年11期)2020-10-29 01:25:46
