基于機(jī)器學(xué)習(xí)的丙型肝炎肝纖維化預(yù)測算法對比研究
2022-04-02 01:25:14劉懷進(jìn)
肇慶學(xué)院學(xué)報(bào) 2022年2期
李 芳,劉懷進(jìn),田 慶
(1.肇慶學(xué)院 計(jì)算機(jī)科學(xué)與軟件學(xué)院,廣東 肇慶 526061;2.華僑大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,福建 廈門 361021)
丙型肝炎病毒(HCV)感染在全球范圍內(nèi)影響超過1億7 千萬人[1].中國是世界上丙型肝炎患病率最高的國家之一,其患病率達(dá)到13%~15%.HCV感染的特點(diǎn)是具有持續(xù)性和向慢性肝炎發(fā)展的高趨勢性,并在部分患者中發(fā)展為肝硬化或肝癌.迄今為止,尚無指標(biāo)或可靠的標(biāo)準(zhǔn)來確定纖維化的進(jìn)展速度,以及何時(shí)會發(fā)展為肝硬化.HCV的治療中連續(xù)肝活檢通常是診斷肝纖維化進(jìn)展的“金標(biāo)準(zhǔn)”.肝活檢是侵入性的,伴有嚴(yán)重的并發(fā)癥,給患者帶來諸多困難且治療費(fèi)用相當(dāng)昂貴[2].最近機(jī)器學(xué)習(xí)技術(shù)在醫(yī)療領(lǐng)域的發(fā)展給肝纖維化預(yù)測帶來了前景,其目標(biāo)是開發(fā)、評估和驗(yàn)證一種替代侵入性技術(shù)的預(yù)測模型,并將預(yù)測模型作為預(yù)測肝纖維化進(jìn)展的一種測量方法.首先采用ARIMA模型對全國2005年到2013年丙型肝炎進(jìn)行建模,為今后丙型肝炎疾病的預(yù)防和控制提供了理論支持[3].基于隨機(jī)森林的丙型肝纖維化預(yù)測的分類模型,對123 例丙型肝炎的血清學(xué)指標(biāo)進(jìn)行分析預(yù)測得到的分類正確率為68.29%[4].基于K近鄰的肝炎預(yù)測模型對數(shù)據(jù)進(jìn)行歸一化的分類正確率為79%[5].使用C4.5決策樹對3 719 例埃及慢性丙型肝炎患者的治療結(jié)果預(yù)測進(jìn)行數(shù)據(jù)挖掘評估的分類準(zhǔn)確性為73%[6].線性優(yōu)化最優(yōu)解(LP)和Bayesian 網(wǎng)絡(luò)分類法(BN)被用來評估和識別HCV序列與纖維化進(jìn)展率(RFP)之間的關(guān)系,其最大分類準(zhǔn)確率達(dá)到了85%[7].針對39 567名慢性丙型肝炎患者建立了預(yù)測纖維化風(fēng)險(xiǎn)的決策樹、遺傳算法、粒子群優(yōu)化和多線性回歸模型,對多種機(jī)器學(xué)習(xí)方法建模的分類準(zhǔn)確度在66.3%~84.4%之間[8].通過減少錯(cuò)誤技術(shù)構(gòu)建的決策樹對427例丙型肝炎患者在預(yù)測晚期纖維化方面的準(zhǔn)確率為88%[9].一種基于非侵入性方法的新模型對401 例慢性肝炎患者的預(yù)測分類準(zhǔn)確率為85.9%[10].慢性丙型肝炎病毒(HCV)感染為發(fā)生肝纖維化及肝硬化的主要原因,但由于肝纖維化具有可逆性,若能及時(shí)干預(yù)對患者具有積極意義[11].大量研究表明,由于機(jī)器學(xué)習(xí)技術(shù)能夠從醫(yī)學(xué)數(shù)據(jù)庫中發(fā)現(xiàn)隱藏的預(yù)測模式,因此它是預(yù)測肝纖維化的強(qiáng)大工具.因此對HCV感染肝纖維化的準(zhǔn)確評估,不僅有助于指導(dǎo)臨床醫(yī)師及時(shí)制定合理的治療方案,而且對改善患者病情具有重要的意義.
1 方法
1.1 丙型肝炎
丙型肝炎由丙型肝炎病毒(HCV)感染所致,主要由血液和體液傳播.丙型肝炎是一種全球性傳染病,可導(dǎo)致慢性炎癥肝壞死和肝纖維化,最后發(fā)展為肝硬化甚至是肝癌.肝纖維化對丙型肝炎患者而言是一項(xiàng)重要的影響預(yù)后因素,肝活組織病理學(xué)檢查一直被認(rèn)為是肝纖維化診斷的“金標(biāo)準(zhǔn)”,它可提供肝纖維化分期的重要信息[12].病理科醫(yī)師通過閱片進(jìn)行肝纖維化程度劃分,分期標(biāo)準(zhǔn)參照肝纖維化分期法[13],共分為5 期(F0~F4),F(xiàn)0為無纖維化,F(xiàn)1為匯管區(qū)有纖維化但無纖維間隔形成,F(xiàn)2為匯管區(qū)纖維化伴少量纖維間隔形成,F(xiàn)3為大量纖維間隔形成,F(xiàn)4為肝硬化.
1.2 數(shù)據(jù)集分析
本研究展示的HCV肝纖維化數(shù)據(jù)集.數(shù)據(jù)中包括了1 741 名接受治療的丙型肝炎患者的數(shù)據(jù).患者的數(shù)據(jù)由埃及艾因沙姆斯大學(xué)醫(yī)學(xué)院在埃爾德梅爾達(dá)什醫(yī)院收集[14].患者接受干擾素-阿爾法和利巴韋林的聯(lián)合治療超過15 個(gè)月.所收集的數(shù)據(jù)有幾種形式和結(jié)構(gòu).因此,在專家建議的基礎(chǔ)上應(yīng)用了改進(jìn)的預(yù)處理階段.從診斷的角度來看,HCV 數(shù)據(jù)集包含1 741 條記錄和29 個(gè)數(shù)據(jù)特征屬性(包含28 個(gè)屬性特征和1 個(gè)分類標(biāo)簽),所有的特征屬性都是數(shù)字,如表1所示.“基線組織學(xué)分期”是具有值{F0,F(xiàn)1,F(xiàn)2,F(xiàn)3,F(xiàn)4}的類別標(biāo)簽.這些標(biāo)簽代表了肝纖維化的不同等級,如下所示:無纖維化(F0)、門靜脈區(qū)纖維化(F1)、少數(shù)纖維間隔(F2)、大量纖維間隔(F3)、肝硬化(F4).
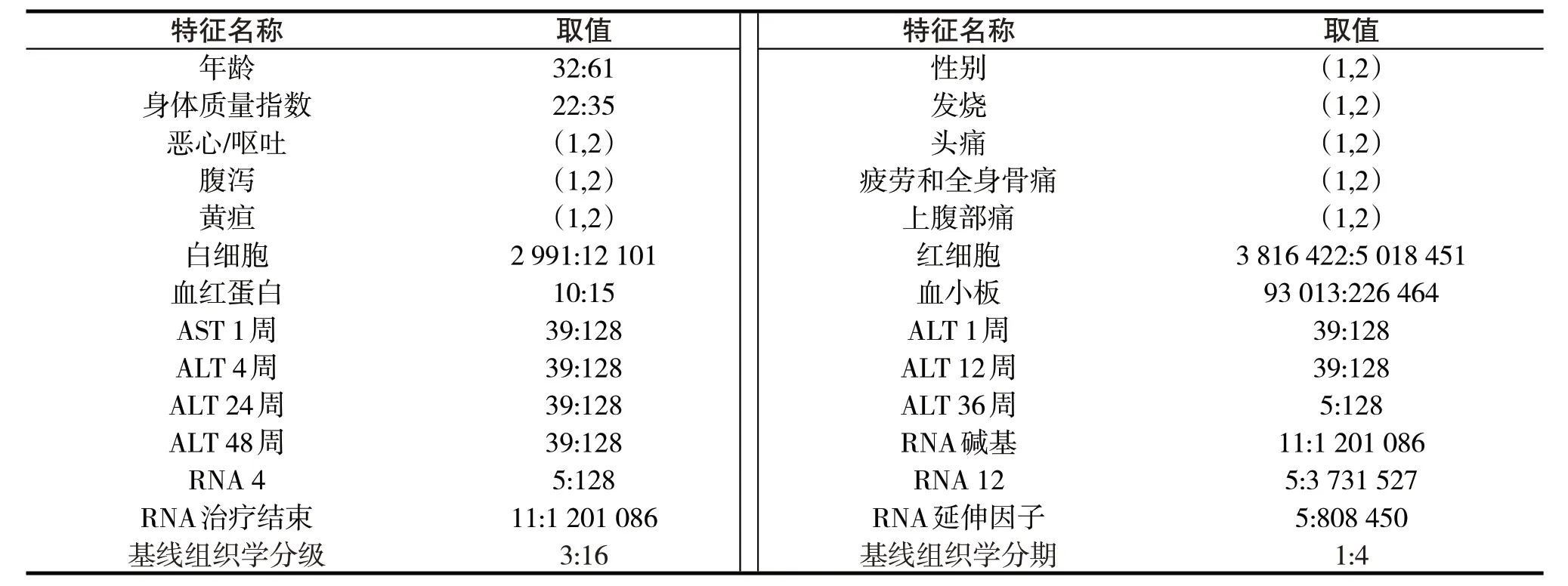
表1 描述數(shù)據(jù)集的特征
2 非集成算法
2.1 審查分類算法
審查算法前并不知道哪些非集成分類算法對HCV問題最有效,所以需要通過一系列實(shí)驗(yàn)進(jìn)行驗(yàn)證,以找到預(yù)測HCV問題最有效的算法.本文將選擇6 種經(jīng)典的非集成分類算法(包括線性和非線性算法)對HCV問題進(jìn)行預(yù)測,通過分類準(zhǔn)確度(Accuracy)評估算法的結(jié)果.其中線性分類算法包括邏輯回歸(LR)[15]和線性判別分析(LDA)[16],非線性分類算法包括K近鄰(KNN)[17]、分類與回歸樹(CART)[18]、樸素貝葉斯(NB)[19]和支持向量機(jī)(SVM)[20].
通過使用10折交叉驗(yàn)證評估模型的預(yù)測性能,采用6種分類算法對原始數(shù)據(jù)進(jìn)行建模,算法性能評估主要通過分類準(zhǔn)確度的平均值和標(biāo)準(zhǔn)方差來比較.實(shí)驗(yàn)結(jié)果如表2所示,從數(shù)據(jù)可以看出,LR和KNN值得進(jìn)一步的分析和研究.

表2 原始數(shù)據(jù)的分類準(zhǔn)確度的平均值和標(biāo)準(zhǔn)方差
為了更加準(zhǔn)確分類算法,通常還需要查看所有算法每次得出的數(shù)據(jù)結(jié)果分布狀況.這里使用箱線圖來表示所有數(shù)據(jù)結(jié)果的分布情況,如圖1所示.

圖1 非集成算法對原始數(shù)據(jù)預(yù)測結(jié)果分布狀況
從圖1可以看出,KNN的執(zhí)行結(jié)果比較緊湊,說明算法對數(shù)據(jù)的處理比較準(zhǔn)確.為了使原始數(shù)據(jù)分布均勻,我們對數(shù)據(jù)進(jìn)行預(yù)處理,然后重新評估算法.表3為正態(tài)化數(shù)據(jù)處理后的算法比較結(jié)果.

表3 正態(tài)化數(shù)據(jù)的分類準(zhǔn)確度的平均值和標(biāo)準(zhǔn)方差
從表3可以看出,KNN依然有較好的執(zhí)行結(jié)果,同時(shí)SVM的結(jié)果也有了極大的改善.我們再通過箱線圖來看一下所有算法每次執(zhí)行結(jié)果的分布情況,如圖2所示.
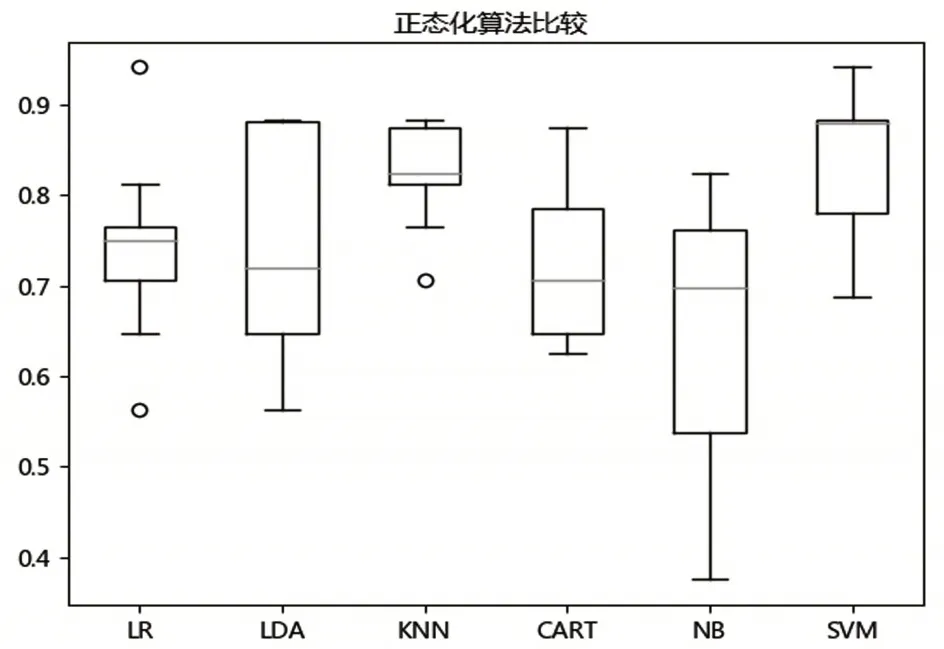
圖2 非集成算法對正態(tài)化數(shù)據(jù)預(yù)測結(jié)果分布狀況
從圖2可以看出,KNN和SVM的數(shù)據(jù)分布也是比較緊湊的.
2.2 算法調(diào)參
通過對6種算法的評估發(fā)現(xiàn)KNN和SVM值得進(jìn)一步研究.如圖3所示.
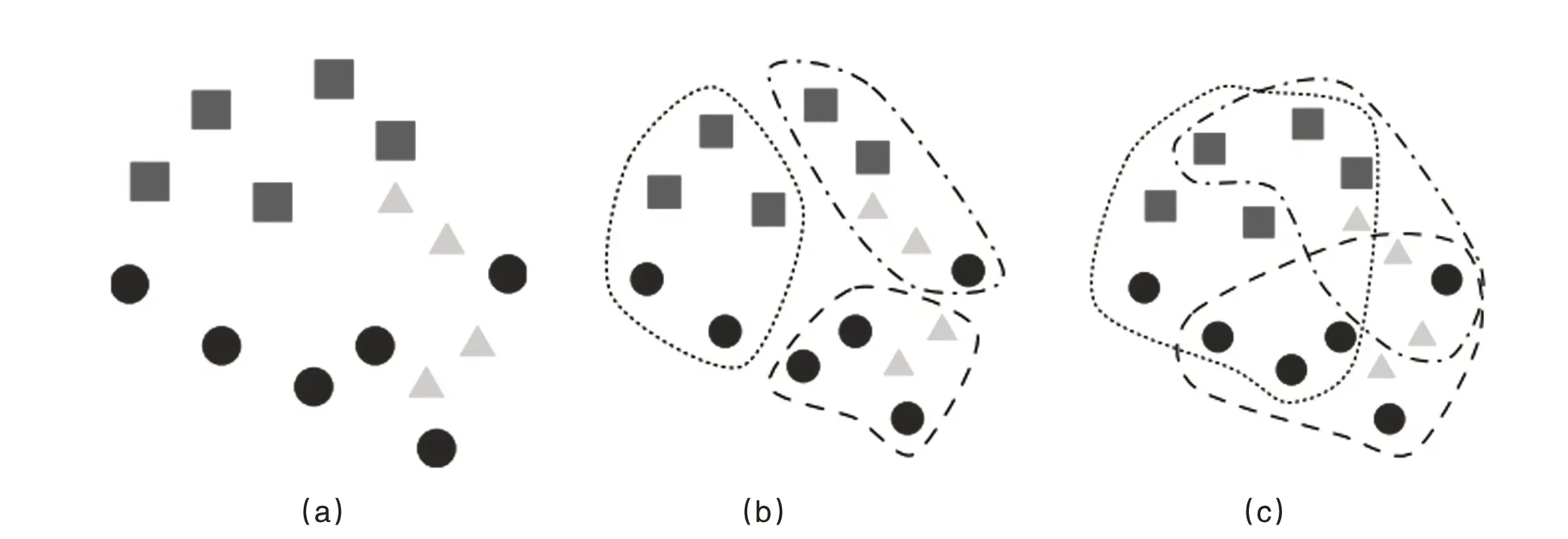
圖3 集群分類增強(qiáng)過程的可視化說明
圖3中(a)為初始化的樣本集,(b)和(c)為在初始化樣本在目標(biāo)集群下進(jìn)行的搜索分類.通過遍歷計(jì)算未知點(diǎn)x與已知群集中點(diǎn)的歐指距離判斷是否屬于群集T1的類型,其中,T1={(x1,y1),(x2,y2),……(xn,yn)}.
KNN的原理是,若一個(gè)樣本與數(shù)據(jù)集中的k個(gè)樣本最相似,且這k個(gè)樣本中的大多數(shù)屬于某一個(gè)類別,則該樣本也屬于這個(gè)類別.在判斷兩個(gè)樣本相似性時(shí),一般使用的歐式距離,如公式(1)所示.

綜上所述,對未知類型屬性的數(shù)據(jù)集中的每個(gè)點(diǎn)依次執(zhí)行以下操作:
(1)計(jì)算已知類別數(shù)據(jù)集中的點(diǎn)與當(dāng)前點(diǎn)之間的距離;
(2)按照距離增序排序;
(3)選取與當(dāng)前點(diǎn)距離最近的k個(gè)點(diǎn);
(4)決定這k個(gè)點(diǎn)所屬類別的出現(xiàn)頻率;
(5)返回前k個(gè)點(diǎn)出現(xiàn)頻率最高的類別作為當(dāng)前點(diǎn)的預(yù)測分類.
SVM是一種二類分類模型,如圖4(a)所示,其基本模型定義為特征空間上的間隔最大的線性分類器,其中,紅色集群為I1,藍(lán)色集群為I2,通過計(jì)算樣本的正負(fù)性判斷集群種類.然而,對某個(gè)實(shí)際問題函數(shù)來尋找一個(gè)二分類是非常困難的,因此使用合適的核函數(shù)對空間進(jìn)行映射是非常有效的方法,如圖4(b)所示.
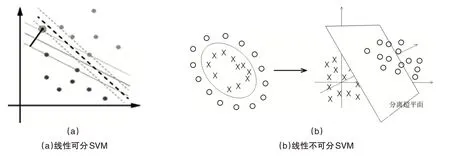
圖4 SVM模型的說明
SVM的工作流程主要有2種:第一種為線性可分SVM超平面:y=wx+b,通過非線性最優(yōu)化求使幾何間隔最大的分離超平面.第二種為線性不可分SVM超平面:將樣本映射到特征空間得到y(tǒng)k=wkx+b,通過非線性最優(yōu)化求使幾何間隔最大的分離超平面.
下面分別對KNN 和SVM 算法進(jìn)行調(diào)參,以進(jìn)一步優(yōu)化算法模型.KNN 默認(rèn)的鄰近點(diǎn)的個(gè)數(shù)(n_neighbors)是5,我們對n_neighbors從1到20的奇數(shù)進(jìn)行網(wǎng)格搜索優(yōu)化參數(shù),以確定KNN算法的最優(yōu)參數(shù).執(zhí)行結(jié)果如表4所示,從執(zhí)行結(jié)果來看,最優(yōu)的n_neighbors數(shù)是1,準(zhǔn)確度達(dá)到0.85.
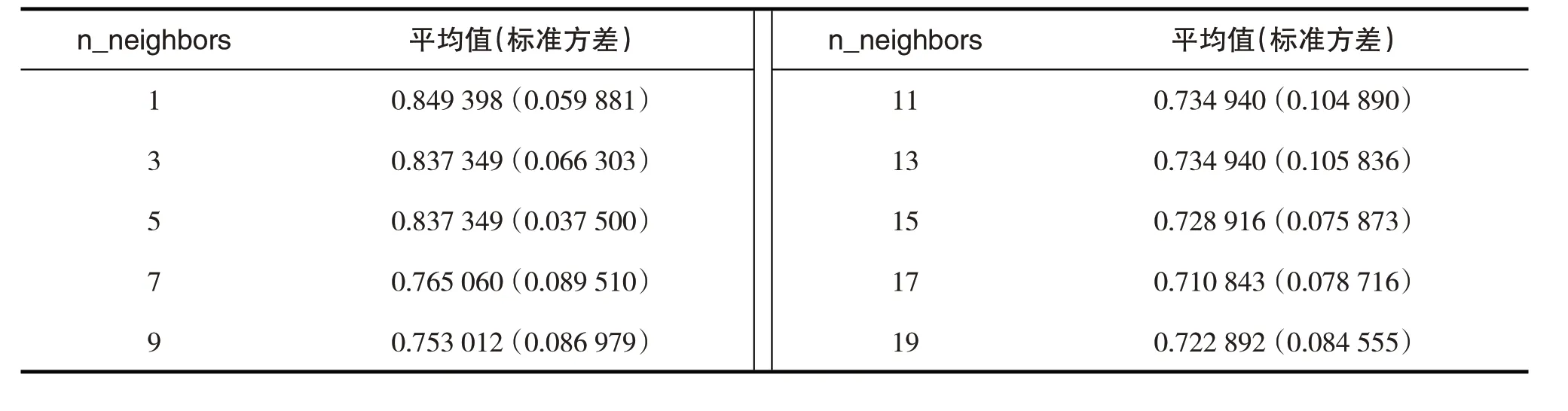
表4 KNN參數(shù)遍歷結(jié)果
接下來對SVM進(jìn)行調(diào)參,SVM有兩個(gè)重要的參數(shù)分別是懲罰系數(shù)(C)和核函數(shù)(kernel),C參數(shù)默認(rèn)的值是1,kernel 參數(shù)默認(rèn)的值是rbf.我們同樣采用網(wǎng)格搜索算法遍歷參數(shù)C={0.1,0.3,…,1.7,2.0}和kernel={‘linear’ ,‘poly’ ,‘rbf’ ,‘sigmoid’ },以確定SVM 算法的最優(yōu)解.執(zhí)行結(jié)果如表5 所示,從執(zhí)行結(jié)果來看,最優(yōu)的C數(shù)是1.5,kernel數(shù)是rbf,準(zhǔn)確度達(dá)到0.87.
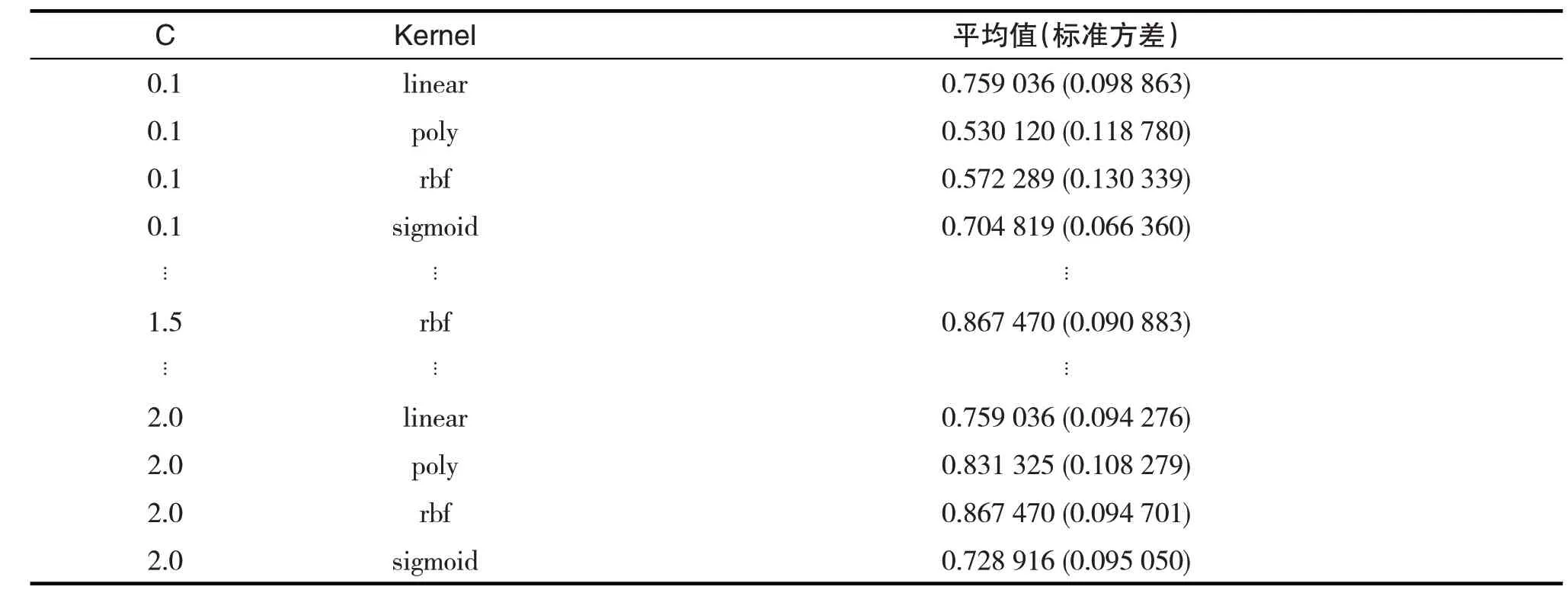
表5 SVM算法參數(shù)遍歷結(jié)果
3 集成算法
在機(jī)器學(xué)習(xí)中,除了算法調(diào)參提高分類準(zhǔn)確度以外,還可以通過集成算法提高分類準(zhǔn)確度.我們采用四種經(jīng)典集成算法進(jìn)行預(yù)測,分別是隨機(jī)森林(RF)[21]、極端隨機(jī)樹(ET)[22]、AdaBoost(AB)[23]和梯度提升機(jī)(GBM)[24].依然正態(tài)化數(shù)據(jù)和采用10折交叉驗(yàn)證分離評估算法,執(zhí)行結(jié)果如表6所示.

表6 集成算法分類準(zhǔn)確度的平均值和標(biāo)準(zhǔn)方差
通過箱線圖來查看集成算法預(yù)測數(shù)據(jù)結(jié)果的分布情況,如圖5 所示.從圖5 可以看出,GBM具有最高的準(zhǔn)確度,且數(shù)據(jù)結(jié)果分布比較緊湊.GBM 默認(rèn)的弱學(xué)習(xí)器的數(shù)量(n_estimators)是100,為了優(yōu)化模型,通過網(wǎng)格搜索算法對參數(shù)n_estimators 從10 到900 間隔為50 進(jìn)行遍歷.最后執(zhí)行結(jié)果顯示n_estimators=500 時(shí),GBM 達(dá)到最大準(zhǔn)確度0.86.
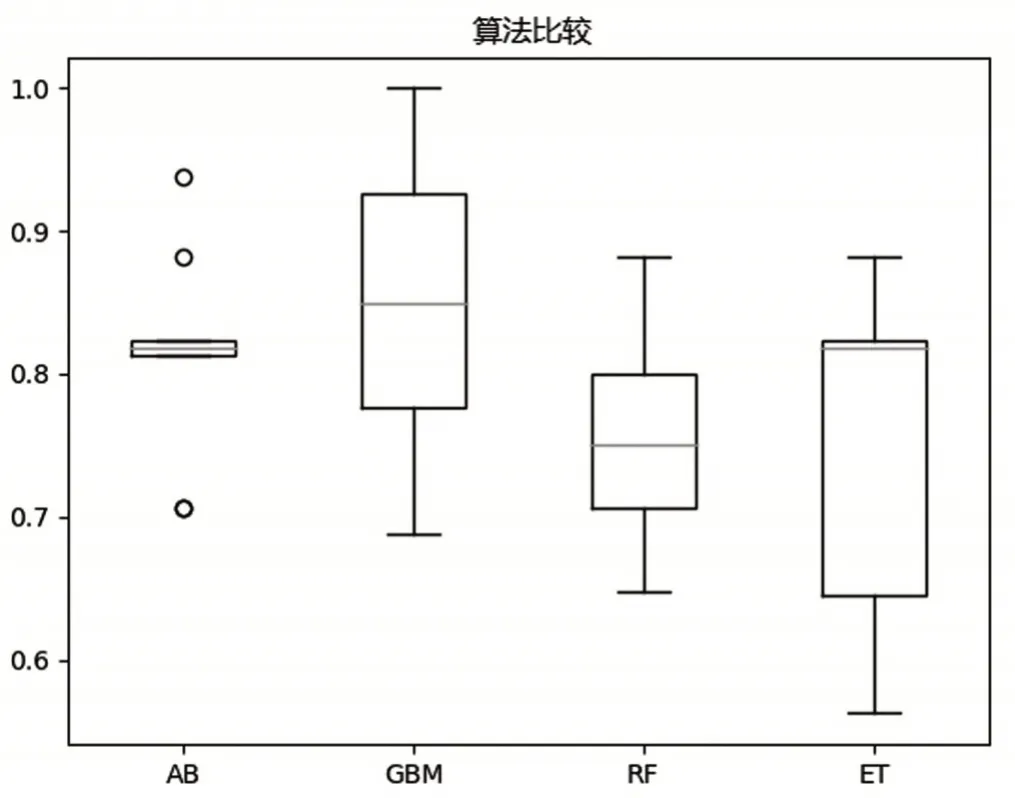
圖5 集成算法對正態(tài)化數(shù)據(jù)預(yù)測結(jié)果分布狀況
綜合前面一系列的算法評估,我們最終得到非集成算法SVM對HCV預(yù)測具有最大的準(zhǔn)確度.所以我們采用SVM 算法對訓(xùn)練集進(jìn)行建模,采用測試集來評估模型.在訓(xùn)練模型過程中,對數(shù)據(jù)進(jìn)行正態(tài)化處理,并設(shè)置SVM 的參數(shù)C=1,5和kernel=‘rbf’ .從執(zhí)行結(jié)果來看,優(yōu)化后的SVM模型對HCV分類準(zhǔn)確度為87%.
4 深度學(xué)習(xí)算法
由于傳統(tǒng)的機(jī)器學(xué)習(xí)算法對HCV數(shù)據(jù)進(jìn)行訓(xùn)練預(yù)測并未達(dá)到期望的分類效果,本節(jié)將采用深度學(xué)習(xí)算法對HCV進(jìn)行建模預(yù)測.由于卷積神經(jīng)網(wǎng)絡(luò)適用于圖像分類,所以我們只選擇了多層感知機(jī)網(wǎng)絡(luò)(MLP)[25]和長短時(shí)記憶網(wǎng)絡(luò)(LSTM)[26]進(jìn)行建模預(yù)測.
首先我們構(gòu)建一個(gè)4層的MLP,它包括一個(gè)輸入層、兩個(gè)隱藏層和一個(gè)輸出層,隱藏層使用Relu激活函數(shù),輸出層使用softmax激活函數(shù).基于MLP的HCV預(yù)測模型的網(wǎng)絡(luò)結(jié)構(gòu)定義代碼如表7所示.
在搭建LSTM網(wǎng)絡(luò)模型訓(xùn)練HCV數(shù)據(jù)時(shí),需要先處理一下原始的特征數(shù)據(jù)維度.我們將原來的二維特征數(shù)據(jù)(samples,n_features)變成了三維數(shù)據(jù)(samples,seq_steps,n_features),序列步長seq_steps設(shè)置為1,標(biāo)簽數(shù)據(jù)維度保持不變.然后構(gòu)建了一個(gè)3層的循環(huán)神經(jīng)網(wǎng)絡(luò)(LSTM),它包括一個(gè)輸入層、一個(gè)隱藏層和一個(gè)輸出層,隱藏層使用sigmoid和tanh激活函數(shù),輸出層使用softmax激活函數(shù).基于LSTM的丙型肝炎預(yù)測模型的網(wǎng)絡(luò)結(jié)構(gòu)的定義代碼如表7所示.

表7 網(wǎng)絡(luò)模型結(jié)構(gòu)定義
除了自定義的MLP 網(wǎng)絡(luò)結(jié)構(gòu)外,MLP 模型設(shè)置的具體網(wǎng)絡(luò)參數(shù)如表8所示,其中隱藏層神經(jīng)元個(gè)數(shù)和學(xué)習(xí)速率是通過經(jīng)驗(yàn)和實(shí)驗(yàn)調(diào)參相結(jié)合確定的最優(yōu)值.
除了定義的LSTM網(wǎng)絡(luò)結(jié)構(gòu)外,LSTM模型設(shè)置的具體網(wǎng)絡(luò)參數(shù)和MPL模型設(shè)置的網(wǎng)絡(luò)參數(shù)基本一樣,具體參考表8所示.

表8 模型參數(shù)
在定義好網(wǎng)絡(luò)模型之后,我們對HCV數(shù)據(jù)進(jìn)行訓(xùn)練和測試.從圖6的實(shí)驗(yàn)結(jié)果對比來看,我們發(fā)現(xiàn)在隱藏層神經(jīng)元個(gè)數(shù)為30,學(xué)習(xí)速率為0.01時(shí),隨著迭代次數(shù)epoch的不斷增加,MLP模型在測試集上的分類精確度達(dá)到89.10%,LSTM模型在測試集上的分類精確度達(dá)到了90.48%.
5 LSTM算法的改進(jìn)
在深入研究LSTM 算法的過程中,我們發(fā)現(xiàn)反向傳播算法可以進(jìn)行優(yōu)化改進(jìn).如圖6 所示,在描述LSTM 反向傳播優(yōu)化算法之前,我們先簡單介紹一下LSTM 算法原理.LSTM 主要有細(xì)胞狀態(tài)、隱藏狀態(tài)和三個(gè)門控組成,門控包括遺忘門、輸入門和輸出門.LSTM 算法主要分為前向傳播算法和反向傳播算法,具體原理和算法請參考文獻(xiàn)[26].
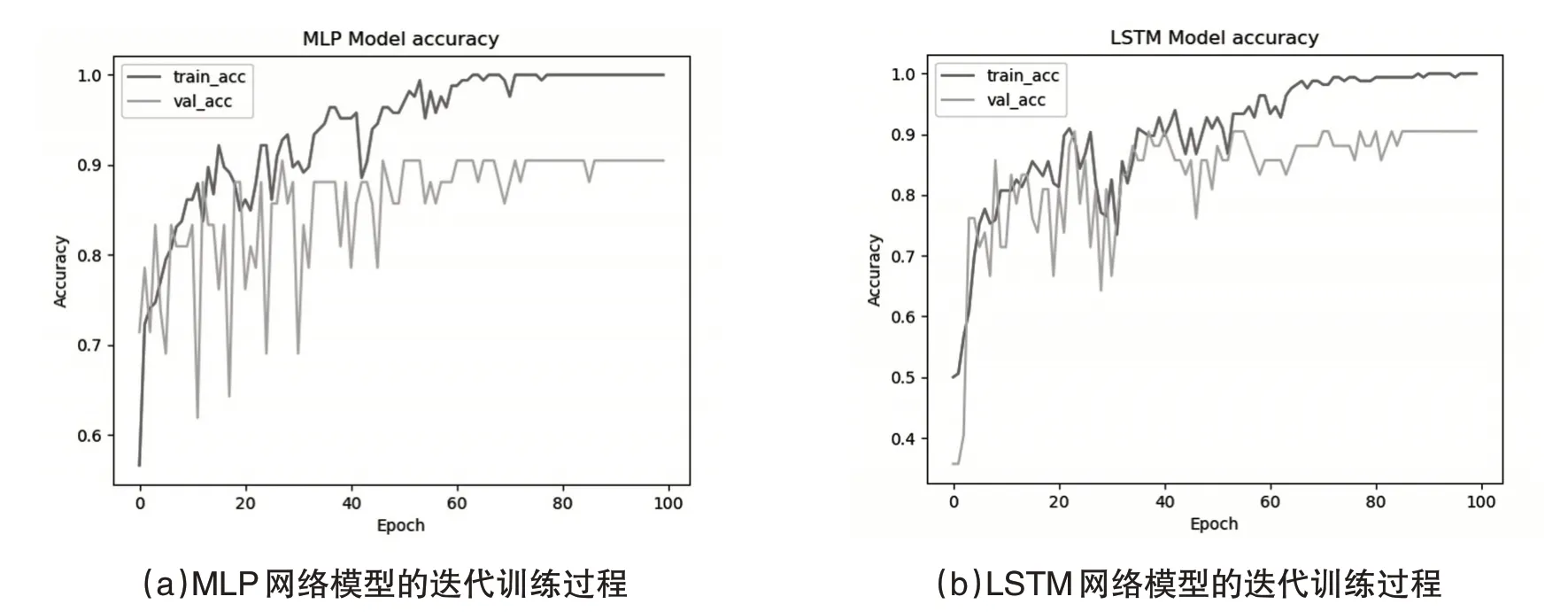
圖6 MLP和LSTM模型對HCV數(shù)據(jù)訓(xùn)練過程
在LSTM反向傳播算法過程中,通過梯度下降法更新算法參數(shù)的關(guān)鍵是計(jì)算出隱藏狀態(tài)的損失梯度誤差δth和細(xì)胞狀態(tài)的損失梯度誤差δtc.為了方便找到梯度的遞推模式,我們根據(jù)前向傳播算法簡單畫出了LSTM的數(shù)據(jù)前向流動(dòng)示意圖,如圖7所示.
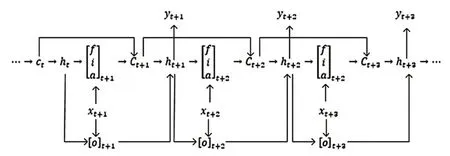
圖7 LSMT數(shù)據(jù)流動(dòng)示意圖
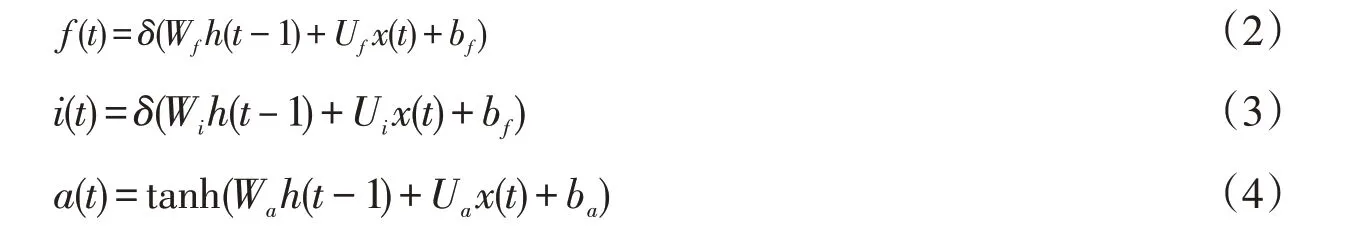
其中,f(t)代表了遺忘上一層隱藏細(xì)胞狀態(tài)的概率,輸入門由兩部分組成,第一部分使用了sigmoid激活函數(shù),輸出為i(t),第二部分使用了tanh激活函數(shù),輸出a(t).如公式(5)所示,細(xì)胞狀態(tài)C(t)由兩部分組成,第一部分是C(t—1)和遺忘門輸出f(t)的乘積,第二部分是輸入門的i(t)和的乘積,其中°是Hadamard積:

對于隱藏層h(t),它的更新由兩部分組成,第一部分是o(t),它由上一序列的隱藏狀態(tài)h(t—1)和本序列數(shù)據(jù)x(t),以及激活函數(shù)sigmoid得到,第二部分由隱藏狀態(tài)C(t)和tanh激活函數(shù)組成,即:

由于δth的梯度誤差由本層的梯度誤差和下一層的梯度誤差共同決定,我們根據(jù)鏈?zhǔn)椒▌t和全微分方程可以求出隱藏狀態(tài)的損失梯度誤差δth和細(xì)胞狀態(tài)的損失梯度誤差δtc,如公式(8)和(9)所示.
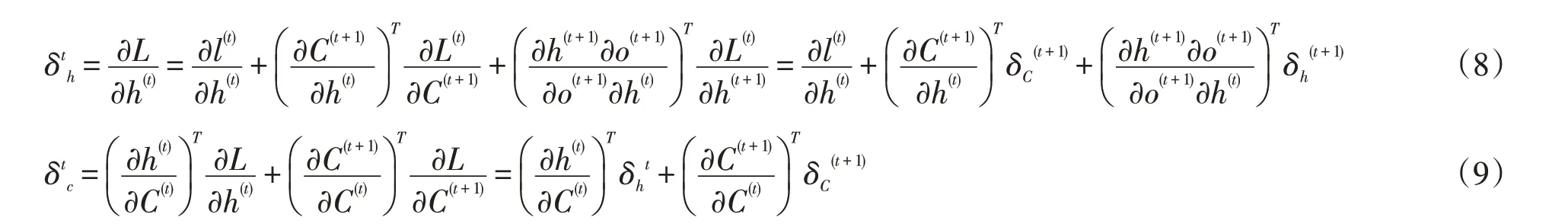
對比文獻(xiàn)[26]求隱藏狀態(tài)的損失梯度誤差δth和細(xì)胞狀態(tài)的損失梯度誤差δtc,這里給出公式如(10)和(11)所示,明顯我們的反向傳播算法更加簡潔,計(jì)算復(fù)雜度更低.
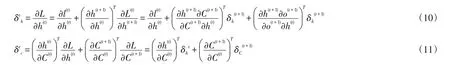
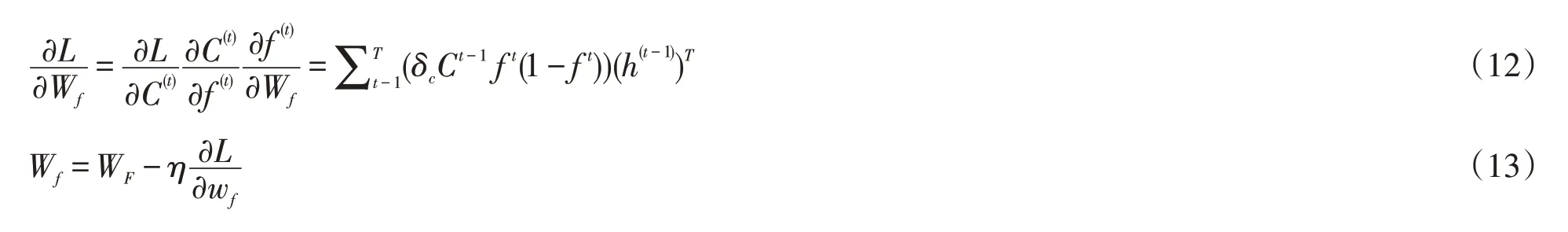
6 總結(jié)
本文采用多種機(jī)器學(xué)習(xí)和深度學(xué)習(xí)分類算法對病人數(shù)據(jù)進(jìn)行肝纖維化預(yù)測,以尋求優(yōu)質(zhì)的算法模型運(yùn)用到丙型肝炎預(yù)測中.經(jīng)過正態(tài)化數(shù)據(jù)處理、交叉驗(yàn)證調(diào)參優(yōu)化和網(wǎng)絡(luò)模型結(jié)構(gòu)搭建之后,得到如下結(jié)論:
(1)基于機(jī)器學(xué)習(xí)算法的非集成算法模型SVM和集成算法模型GBM,相對于其他傳統(tǒng)的機(jī)器學(xué)習(xí)算法在應(yīng)用于HCV預(yù)測具有較好的分類性能,不過分類準(zhǔn)確度并沒有達(dá)到預(yù)期效果.
(2)基于深度學(xué)習(xí)算法的MLP和LSTM模型的分類預(yù)測效果要優(yōu)于傳統(tǒng)的機(jī)器學(xué)習(xí)算法,同時(shí)LSTM的分類精確度高于MLP模型,更適合HCV的預(yù)測.
(3)通過對LSMT前向反向傳播算法分析和遞推,發(fā)現(xiàn)LSTM算法的反向傳播算法可以進(jìn)一步優(yōu)化.通過數(shù)學(xué)鏈?zhǔn)椒▌t和矩陣向量求導(dǎo)規(guī)則,我們推導(dǎo)的反向傳播算法更加簡潔,計(jì)算復(fù)雜度更低.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03

- 肇慶學(xué)院學(xué)報(bào)的其它文章
- 基于感覺統(tǒng)合訓(xùn)練的智障兒童體育游戲調(diào)整與設(shè)計(jì)
- 師范認(rèn)證背景下田徑課程建設(shè)面臨的問題及對策
——以肇慶學(xué)院為例 - 微(納)米塑料介導(dǎo)下多環(huán)芳烴的毒性效應(yīng)研究進(jìn)展
- 地方應(yīng)用型高校應(yīng)用統(tǒng)計(jì)學(xué)重點(diǎn)專業(yè)建設(shè)研究
——以肇慶學(xué)院為例 - 應(yīng)用型本科院校數(shù)值分析教學(xué)改革與課程思政
- 基于WSN動(dòng)態(tài)協(xié)調(diào)節(jié)點(diǎn)優(yōu)化的豬舍環(huán)境監(jiān)控系統(tǒng)研究