全景視頻數據的網絡同步與合成技術研究
2022-03-24 09:12:04丘美玲晏細蘭陳惠紅
科技創新與應用 2022年6期
關鍵詞:區域
丘美玲,晏細蘭,陳惠紅
(廣州番禺職業技術學院,廣東 廣州 511483)
1 全景視頻瀏覽參數計算
在一般圖像瀏覽軟件中,圖像是完整讀入到內存,再通過驅動模塊顯示到顯示器,其縮放和局部瀏覽的操作均由驅動模塊后臺完成。而對于超大尺寸的圖像,其需要的儲存空間往往超過一般電腦內存的承受能力,以上顯示圖像的方式就不再適用。對于超大圖像,一般使用塊存儲格式存儲,其格式中包含的不同分辨率下圖像的縮略圖和實際分辨率下按塊劃分的多個子圖,在高分辨率瀏覽時按照感興趣區域對各塊分布抽樣或讀取,再組合成一個區域圖像[1-2]。在一般的全景系統中,各個全景子圖是單獨存儲在各運算子機中的,類似于超大圖像格式中的按塊存儲,區別在于全景子圖中各子圖可能存在一定的重疊[3-5]。利用塊存儲提取原理,可以計算出各個子圖中的需求內容。
對于單一圖像的瀏覽是利用視窗(實際觀察區域)和圖像做重疊區域計算得到的,計算得到的參數包括視窗在圖像中的偏移坐標(XS,YS)、視窗大小(WS,HS)、視窗縮放系數(αx,αy)。如圖1 所示,偏移坐標(Xi,Yi)為視窗原點在圖像中的坐標,視窗大小為視窗在圖像分辨率下的大小,視窗縮放系數為視窗大小與顯示窗口大小(WQ,HQ)的比值。那么,我們瀏覽區域圖像Is 和原圖I 的相對關系如式(1),其中T 代表對圖像的最近鄰域抽樣或像素平均后雙線性內插等操作。

圖1 窗口關系
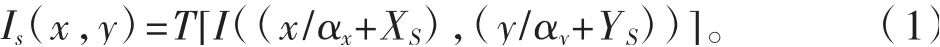
以上原理對于全景圖像同樣適用,利用該方法能計算出視窗與全景的對應關系,再利用各個子圖與全景的坐標變換關系,可以算出各個子圖與顯示窗口的坐標變換關系。首先計算子圖與視窗是否重疊與重疊范圍,計算方法采用四點排序方法,方法步驟如下:
Step1:計算兩個坐標方向上是否有重疊,假設x 方向上矩形1 的范圍為X1=[x11,x12],矩形2 的范圍為X2=[x21,x22],那么X 方向上是否重疊如式(2):

如果x 方向和y 方向均重疊,那么兩個矩形區域存在重疊區域。
Step2:如果重疊,計算重疊范圍,設X=[X1,X2],對X進行由小到大的排序,有x 方向上的重疊長度Lx為次大值和次小值的差:

同理求出Ly。
考慮到圖像在融合過程中,為了達到公共區域的平穩過渡,同時考慮了多個重疊子圖的信息。但是在特定情況下,視窗與子圖的重疊區域只存在子圖與其他子圖的重疊區域中,即其他子圖已經包含了該區域的所有信息。
圖2 中,子圖A 與子圖B 與視窗S 均重疊,但是由于有(B-A)∩S=?,即子圖B 與視窗S 的公共區域全部都在A 里面,那么子圖A 就包含了該公共區域的所有信息,這樣我們就不需要對A 和B 做融合后分別把其與視窗重疊區域發送至合成端,只需要把A 的完整重疊信息發送至合成端,對于子圖B 中,B 與S 的重疊區域存在與B 唯一相交的區域,即(B-A)∩S≠? 時,必須把B 與S重疊的信息發送至合成端,全景圖像中局部圖像合成次數的多少會影響全景合成中與各個子圖的控制復雜度。

圖2 窗口與子圖的重疊關系
2 網絡數據的快速提取
網絡數據的提取主要是根據子圖與視窗的重疊區域參數來計算提取的,對于一個實時系統而言,點提取采用像素平均后做雙線性內插值方法是非常耗費運算資源的,所以可以采用圖像效果相對較差,但運算效率相對較高的最近鄰抽樣方法。采用該方法的另外一個好處是重疊參數一旦確定后,窗口子圖與全景子圖上的坐標成了一一對應的關系,利用這一特點,可以在重疊參數改變后生成一個坐標對應關系查找表,利用查找表可以把原來的數值運算變成賦值運算。直接計算和查表分別如式(4)和(5),其中K 為最近鄰查找,Ic為輸出圖像,Iw為投影后的圖像,Tx和Ty分別為x 和y 方向坐標的對應查找表。

可以看出直接計算,每個坐標點需要做2 次除法、2 次加法、2 次最近鄰查找和1 次賦值運算,而查表法只需要做3 次賦值運算。在當今擁有多級緩存和高速內存的硬件環境下,賦值運算比數值運算速度快得多。表1 中,分別利用重疊參數直接計算和查表形式對一個圖像做1 000 次數據提取計算,查表法大概要比直接計算快40%。

表1 裁剪速度對比
對于全景子圖,除了坐標變換還需要對圖像做融合,事先生成了一個融合系數模板Mask,利用模板切割的方法同樣可以生成一個和顯示子圖對應的融合查找表TM,融合查找表返回的是一個浮點型數,而浮點型運算在計算機中相對是比較費時間的。實際觀察中發現,RGB 圖像點分量的等級為256,所以對于融合系數的精度要求只需要達到1/256。利用這一特點,可以考慮把融合查找表轉換成uchar(0~255)型數,生成一個0 到255 各乘以1/256 到1 的系數查找表T256。一幀720 p 圖像用直接計算來投影和裁剪需要約35 ms,采用查找表法后,投影和裁剪需要約25 ms,即使系統最終全景幀率是由多個并行環節中最慢的一部分決定的(實際測試該環節為網絡傳輸),但這部分節約的功耗最終會分配到其他環節,從而提升了系統的最終效率。
3 全景視頻的網絡生成
網絡數據在按照提取參數提取出來后,會統一發送到服務器進行組合,由于數據在計算節點就被投影,同時還乘上了融合系數,因此服務器只需要把各個數據按照其偏移坐標疊加到顯示模板即可。但是在全景生成前,還要考慮數據的同步問題[6]。
3.1 合成數據的網絡同步
由于全景視頻是由多個有一定重疊區域圖像組成的,對于運動目標而言,在時域上存在一定的空間差異性,當全景拼接采用了不同步的圖片,且公共區域內出現了運動目標,即使背景拼接成功,融合拼接后運動目標會出現重影。對于一個監控系統,視頻中運動物體才是人們感興趣的,如果出現數據不同步將會大大影響監控質量。全景視頻系統的同步要求包括兩個方面,一方面是攝像機數據的采集同步,另外一方面是數據在網絡數據計算過程中的同步。攝像機數據采集的不同步,主要是由于攝像機本身硬件差異產生的輸出波動和啟動時間不同而產生的。假設各個攝像機的幀率相同,那么它們同時間采集一幀會存在一定的物理誤差,這個誤差會在一幀時間以內,對于非高速運動的目標,該誤差影響非常小,并且這個物理誤差是不可避免的,所以一般把這個物理不同步忽略掉。
對于網絡計算過程的不同步,主要是由于各個計算節點效率的不相同和同一計算節點在時域上計算效率的不穩定,到各個節點數據的輸出頻率在并行和串行上都不一致,還有就是網絡傳輸效率的不一致。由于各個攝像機計算延時的不相同,有時候服務器同一時間在各個節點接收到的數據會存在1~2 幀甚至更多的差異。
如上所述情況不包括個別計算節點存在超負荷工作狀態,指的是各個計算節點在總體輸出效率相當,但個別時間點出現了輸出水平的波動的情況。解決這一問題主要是采用緩存機制,利用緩存機制在服務器輸入前端做幀對齊,能保證視頻合成過程中連續穩定,但弊端是引入了一定的人為延時。計算延時是不可避免的,在系統流暢運行的情況下一般為300 ms,而人為延時可以通過緩存大小設定其上限值,這里設定為1 000 ms,在本系統即10 幀。
為了實現時域上幀對齊,必須利用各幀采集時間來標識。忽略掉物理不同步,攝像機數據返回到采集節點時數據為實時數據,該數據的時間標識即為當前計算機的系統時間。所以首先要實現各個計算節點和服務器的時間同步,步驟如下:
Step1:在網絡底負荷的情況下,服務器給計算節點發送測試命令,計算節點收到命令后立馬返回,服務器接到返回后計算返回時間差。
Step2:重復Step1 多次,計算平均時間差Tp。
Step3:服務器把系統時間發送到計算節點,計算節點計算其與服務器的系統時間誤差Δt,如式(6):

Step4:重復Step3 多次,計算平均系統時間誤差ΔT,更新當前時間,如式(7):

圖像在采集時打上的時間戳不會因為各種處理有所改變,最終發送到服務器的子圖像的時間標識仍然是該圖像采集時的時間戳。在全景視頻開始時,由于各個節點的啟動時間不一致,必須對服務器上并行數據做首幀對齊,如圖3 所示,步驟如下:

圖3 首幀數據
Step1:計算幀差時間,如幀率為10 fps,幀差時間Δt為100 ms。
Step2:找出首幀中超前的1 幀,如圖中T11,設定全景起點為t0=T11,生成全景播放序列tn=t0+n·Δt。
Step3:排序各路數據,如果該幀時間戳在tn到tn+1之間,該幀的播放時間被安排到tn,如果該段時間內沒有數據或數據沒到,即插入空白幀。
因為全景視頻是由服務器主動合成的,所以其播放也必須由服務器主動觸發,觸發時間根據生成的全景視頻播放時間序列而定。真正觸發時間并不是由該序列的標識時間決定的,該時間僅僅用于緩存對齊和決定全景視頻的起點,真正觸發全景視頻的是幀差時間。首幀對齊決定了全景視頻播放序列的排序,但是在播放過程中仍然會出現以下不同步的問題:
(1)丟幀。對于某一時刻,采集端出現了短暫數據采集的丟失,這樣的數據在時序上是不可恢復的。對于該情況,通過在丟失時序上插入空白幀,保證全景播放流暢,但是全景內容會出現缺失。
(2)幀滯后。該情況主要由于計算滯后和網絡滯后產生的,即數據沒有丟失,但是數據到達時間比其他節點慢。對于緩存機制的優點就是能允許數據出現滯后,但由于緩存大小有限,當滯后長度超過緩存長度滯后仍然沒有回復,即新來滯后數據時間戳比當前播放序列標識超前,對于這樣的數據服務器會直接丟棄,直到滯后恢復為止。采用本文的同步機制能使全景視頻流暢播放,其播放幀率與視頻采集幀率一致,缺點是全景視頻播放在某個節點出現問題時全景數據會出現丟失。
3.2 全景視頻數據的合成
全景視頻數據的合成,只需要根據視頻的偏移坐標,把子圖像疊加到一個和顯示窗口大小一致的空白圖像模板中,如式(8)。圖像在發送到服務器前就完成了偏移值的計算、裁剪縮放和融合的操作,所以在其疊加過程中不會出現子圖超出模板范圍或者個別坐標點超出值域的問題。

需要注意的是,當視窗改變后,合成參數被重新計算,計算節點會更新查找表,服務器接收的數據會改變。在這種情況下,緩存中的數據不再適用,這時必須清空緩存,重新進行數據的幀對齊和生成新的全景視頻播放時間序列,在這個過程中全景視頻會出現短暫的卡屏,卡屏的時長和各個節點切換速度有關,一般在500 ms 左右。
4 結束語
本文主要闡述了在分散式系統環境下的全景視頻多分辨的局部瀏覽方法,通過本方法,可以把在監控過程中感興趣的局部區域從運算節點的有效數據中提取出來。提取出來的數據量主要和屏幕大小有關系,這樣可以限定各運算節點傳輸到服務器的數據量,防止造成網絡堵塞,并且運算節點保存的是視頻源投影前的數據,運算節點只需要把觀察區域做投影和融合,減少了計算節點的計算開支,所以使得系統能用更少的計算節點來完成全景視頻的生成。
猜你喜歡
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
科學(2020年5期)2020-11-26 08:19:22
軟件(2020年3期)2020-04-20 01:45:18
商周刊(2018年15期)2018-07-27 01:41:20
敦煌學輯刊(2018年1期)2018-07-09 05:46:42
北京教育·普教版(2017年1期)2017-02-05 13:26:23
新疆農墾科技(2016年2期)2016-08-21 13:50:16
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
新疆財經大學學報(2015年3期)2015-12-10 03:49:15
