基于嵌入式平臺的卷積神經網絡壓縮加速方法*
2022-03-01 08:27:42賀彥鈞張旭博
通信技術 2022年12期
賀彥鈞,張旭博
(中國電子科技集團公司第三十研究所,四川 成都 610041)
0 引言
近年來,深度學習模型發展快速,在機器視覺任務上取得了長足的進步,在某些任務上,其辨識能力甚至超過了人類,例如,卷積神經網絡(Convolutional Neural Network,CNN)目標檢測技術在智能監控、工業檢測、智慧城市等領域起到了支撐作用。雖然深度學習模型的網絡架構被設計得越來越深,性能變得越來越優,但參數量資源消耗大成了一個普遍的問題。例如,主流的ResNet50的參數量達到25.5 MB,運行時內存占用約1.4 GB,同樣的還有DensNet、Unet等[1]。此外,目前的無人機、無人車及智能家居、物聯網等低算力平臺同樣希望能夠AI賦能,即能夠在平臺硬件資源有限的情況下去完成一些較為智能的任務,例如目標檢測、人臉識別、圖像分割等任務,而如何在嵌入式設備和移動平臺上運行深度學習智能模型成為目前業界共同關注的問題,也是學術界和工業界的研究熱點。
目前學術界已基本證實,大部分的深度神經網絡模型存在參數過度冗余,且巨量模型參數中存在較多的無效參數,然而可以通過一些方法來減少模型的參數去除冗余,同時保持較少的精度損失或者不損失精度。目前學術界已提出許多方法來壓縮和加速深度神經網絡,如模型剪枝、模型量化、模型蒸餾、低秩分解、緊湊架構設計等方法。例如,Zhang等人[2]提出的Shufflenet引入了一種高效的框架,采用點組卷積和通道洗牌兩種操作,在保持相當的分類精度的同時顯著降低了計算復雜度。同時,Dai等人[3]提出的PolyNet證明在網絡設計中多樣化的結構作為一種超越深度和寬度的替代維度,可以提高圖像識別的性能。
本文針對無人車嵌入式設備上深度神經網絡模型的壓縮加速問題,提出了一套結合模型蒸餾、網絡結構搜索、模型量化的通用模型壓縮方法,并提出了一種新的基于無錨點(anchor-free)的輕量級自分組卷積神經網絡目標檢測模型。該方法首先通過對網絡通道的壓縮、小卷積核替換和自分組卷積來搭建輕量級主干(backbone)[4]網絡;其次結合Anchor-Free的目標檢測方法來搭建小網絡,同時通過知識蒸餾來進行網絡訓練,讓小網絡學習當前最優效果(State of The Art,SOTA)的目標檢測模型的檢測能力;最后通過深度模型的非對稱統計后量化的方法進一步壓縮模型大小,以達到提速的目標。通過綜合實驗表明,該方法顯著地減少了網絡模型的規模,并且在多種流行的視覺數據庫PascalVoc和ImageNet的測試上,顯示出優越的性能,并在無人車平臺上達到了實時目標檢測的效果,這為嵌入式平臺或移動平臺的深度學習模型的部署和應用提供了重要的指導。
1 基于無人車的模型壓縮加速方法
1.1 方案設計
無人車選用基于樹莓派和Nano板的機器人操作系統(Robot Operating System,ROS)平臺,該平臺在當前的無人機和無人車上的應用比較普遍且具有代表性。在此基礎上,設計基于分組卷積的輕量級實時網絡結構(LightWeight CNN,LT-CNN),用于無人車目標檢測的模型基礎架構。然后選用當前檢測效果非常好的大模型,即Anchor-free的全卷積單階段的目標檢測模型(Fully Convolutional One-Stage Object Detection,FCOS)網絡,來進行知識蒸餾,通過teacher-net與student-net進行聯合蒸餾訓練的方式,讓LT-CNN網絡學習到當前SOTA網絡的特征提取能力,從而獲得相當的目標檢測能力。最后,將訓練完成得到的模型進行進一步的模型參數壓縮,即使用后統計非對稱量化方法,壓縮模型參數的大小,以提高模型的加載與推理速度,同時起到降低模型推理時硬件功耗的目的。
1.2 輕量級模型LT-CNN結構設計
FCOS目標檢測算法是一種基于全卷積網絡(Fully Convolutional Networks,FCN)的逐像素目標檢測算法,實現了無錨點(anchor-free)、無提議(proposal free)的解決方案,并且引入了中心度center-ness的思想。該算法在召回率等方面的表現接近甚至超過目前很多先進主流的基于錨框目標的檢測算法。因此,本文選擇FCOS網絡作為輕量級模型的設計對標基礎和模型蒸餾的teacher網絡。Iandola等人[5]提出的SqueezeNet實現了與AlexNet相同的精度,但只用了1/50的參數量,其采用的squeeze模塊先利用1×1卷積進行降維,然后利用1×1和3×3卷積組合升維,并將Pooling采樣延后,給卷積層提供更大的激活圖,以提供更高的準確率。在MobileNets中,采用深度可分離卷積(Depth-Wise Separable Convolution)結構來實現在不降低網絡性能的前提下減少網絡參數和計算量的目的。在SENet中,通過學習的方式來自動獲取每個特征通道的重要程度,利用特征通道之間的關系來提升網絡性能。
本文設計的輕量級模型LT-CNN將SqueezeNet、SE-Net和MobileNets的思想融入到hourglass架構中。LT-CNN將residual block替換為SqueezeNet中的Fire module,將3×3標準卷積替換為MobileNets的3×3深度可分離卷積,同時順著空間維度來進行特征壓縮,利用SE-Net的Squeeze操作和Excitation操作來提升模型的性能[4]。具體的網絡結構如圖1所示。
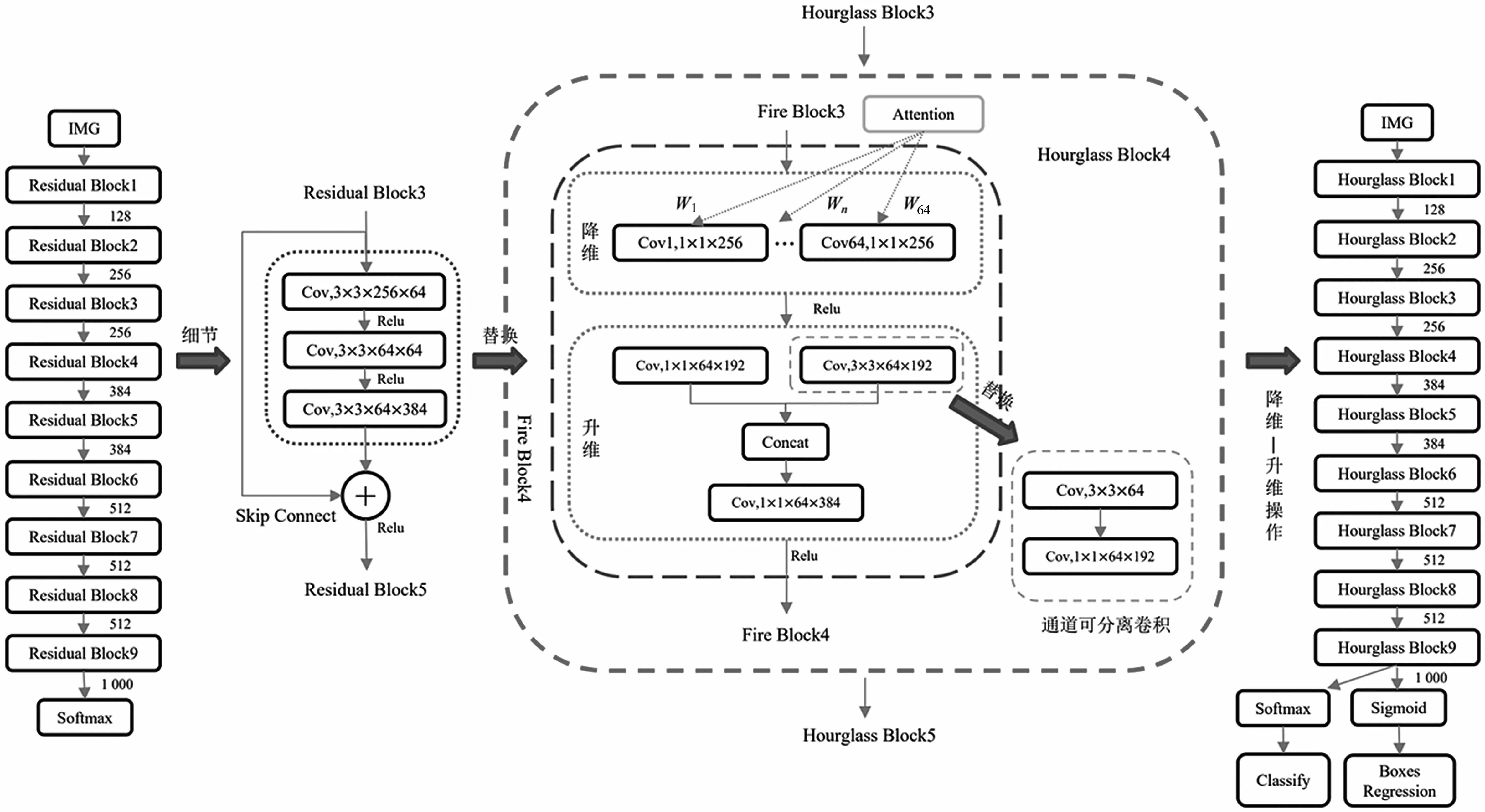
圖1 LT-CNN網絡結構
LT-CNN網絡的基礎架構是帶skip的Hourglass結構,并采用anchor-free的目標檢測網絡架構,在backbone后接一個分類分支和一個框回歸分支。同時大量地使用了3×3深度可分離卷積和1×1的卷積結構,并創新地結合卷積通道的attention結構,讓網絡推理快速且準確[6-7]。
1.3 模型的知識蒸餾
搭建了基本的輕量網絡結構LT-CNN以后,本文采用模型蒸餾訓練的方式來實現知識遷移,通過構建FCOS與LT-CNN的知識蒸餾網絡來實現FCOS模型檢測能力到LT-CNN的遷移。
1.3.1 知識蒸餾
Hinton的文章Distilling the Knowledge in a Neural Network首次提出了知識蒸餾(暗知識提取)的概念,如圖2所示,通過引入與復雜但預測精度優越的教師網絡(Teacher network)相關的軟目標(Soft-target)作為Total loss的一部分,以誘導精簡、低復雜度、更適合推理部署的學生網絡(Student network)的訓練,實現知識遷移(Knowledge transfer)[8]。
如圖2所示,教師網絡(左側)的預測輸出除以溫度參數(Temperature)之后,再做Softmax計算,可以獲得軟化的概率分布(軟目標或軟標簽),數值介于0~1之間,且取值分布較為緩和。其中,Temperature數值越大,分布越緩和;而Temperature數值減小,容易放大錯誤分類的概率,引入不必要的噪聲。針對較困難的分類或檢測任務,Temperature通常取1,確保教師網絡中正確預測的貢獻。Total loss設計為軟目標與硬目標所對應的交叉熵的加權平均(表示為KD loss與CE loss)。另外,教師網絡的預測精度通常要優于學生網絡,而模型容量則無具體限制,且教師網絡推理精度越高,越有利于學生網絡的學習。
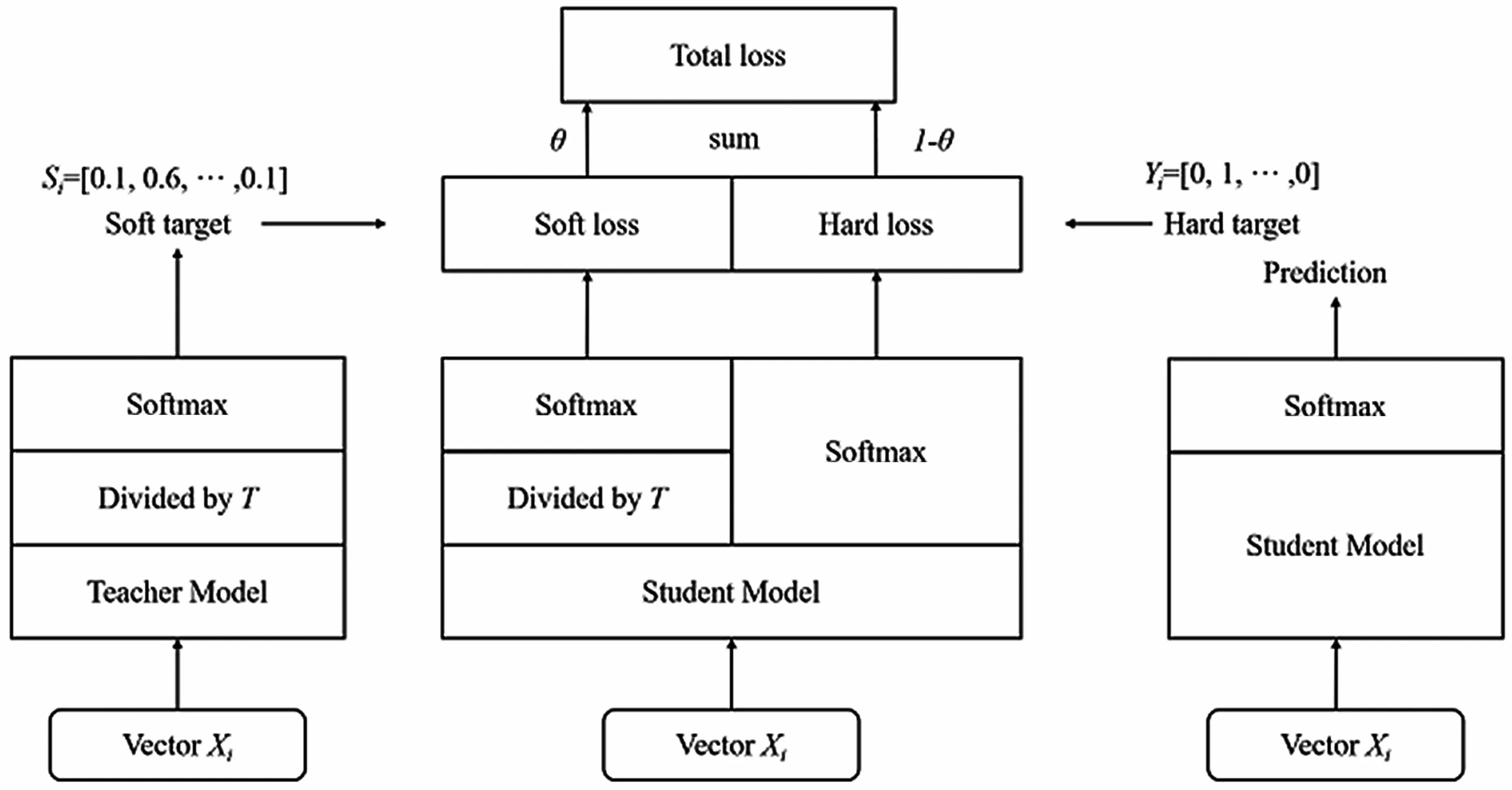
圖2 知識蒸餾
設標簽為y,網絡預測結果為則CE損失函數為:
Hinton的KD方法是在softmax之后做KL散度,同時加入了一個RL領域常用的超參溫度參數T,也有一個半監督的工作在softmax之后接L2 loss,其表達式為:
Hinton等人做了3組實驗,其中兩組都驗證了知識蒸餾方法的有效性。在美國國家標準與技術研究院收集的MNIST數據集上的實驗表明,即便有部分類別的樣本缺失,新模型也表現得很不錯,且只需要修改相應的偏置項,就可以與原模型表現相當。語音任務實驗也表明,蒸餾得到的模型比從頭訓練的模型捕捉了更多數據集中的有效信息,表現僅比集成模型低了0.3個百分點。總體來說,知識蒸餾是一個簡單而有效的模型壓縮和訓練的方法。
1.3.2 蒸餾訓練設計
蒸餾訓練就是先訓練好一個大網絡,在最后的softmax層使用合適的溫度參數T,最后訓練得到的概率稱為“軟目標”。以這個軟目標和真實標簽作為目標,去訓練一個比較小的網絡,訓練的時候也使用在大模型中確定的溫度參數T。在蒸餾結構搭建時有比較常用的結構,例如共享學習低水平特征,teacher-student網絡模型使用通用模型的權重進行初始化,或者使用逐級蒸餾的方式,逐步進行知識遷移。
本文根據目標檢測網絡FCOS的網絡對稱結構的特點對蒸餾結構進行改進,讓teacher網絡不但能在最終的軟目標對student小網絡進行指導,而且能在中間層對student小網絡進行指導。這種特殊的改進不但能讓網絡訓練速度更快,也能讓student網絡習得更多的知識,過擬合風險更小,從而得到一個不錯的表現。具體的模型蒸餾結構如圖3所示。
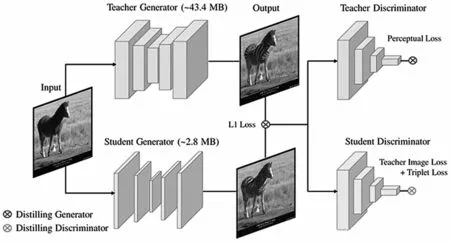
圖3 模型蒸餾結構
1.4 模型的量化壓縮
深度神經網絡模型由于其網絡大且深,模型的參數量巨大,導致最終訓練得到的模型文件都比較大,例如ALexNet的單個模型文件可以達到200 MB。深度卷積神經網絡模型的參數一般都是浮點數形式,普通的壓縮算法很難壓縮它們。同時,模型推理也使用浮點數,計算時消耗的計算資源量(內存、顯存空間和CPU、GPU時間)也比較大。
量化壓縮技術可以在不影響模型準確率的情況下,在模型內部采用比較簡單的數值類型進行計算,計算速度會提高很多,從而消耗的計算資源會大大減小。特別是對無人車或無人機等低算力設備來說,這一點尤其重要。模型量化后依然可以較好地保持模型的準確率,其原因主要有以下3點:
(1)訓練好的神經網絡模型里,權重、活化張量的數值通常分布在一個相對較小的范圍中,如權重的數值范圍為-15~15,活化張量的數值范圍為-500~1 000;
(2)神經網絡對噪聲的適應性強,將數量化到一個更小的數集中并不會對整體的結果帶來很大的影響;
(3)通過量化操作,可以有效提高點乘的計算效率。
量化一般分為直接統計量化和量化感知訓練,本文使用的是后統計量化的方法,直接對模型進行量化,不需要對模型進行再訓練。因為小模型是蒸餾訓練完成的,再進行Finetune可能會引起準確率較大的波動,所以直接進行后統計量化更為有效和便捷。
2 驗證實驗設計與分析
2.1 實驗條件
模型蒸餾實驗在Win10系統下進行,CPU為Intel Core i7-8086K,GPU為NVIDIAGTX1080TI,軟件平臺為CUDA8.0、CUDNN5.1以及Python3.7等。
無人車端實驗在Ubuntu 16.04系統下進行。硬件使用Pixahwk 2.4.8控制器,并采用新標準的32位處理器STM32f427,搭配5611氣壓計。無人車控制固件搭建Ardupilot系統,提供先進的、功能齊全的、可靠的自動駕駛軟件系統。
2.2 數據及評價指標
2.2.1 目標檢測實驗數據集
本文利用ImageNet數據集進行圖像分類的預訓練,以提高特征提取網絡的圖像分類性能。預訓練之前,需在ImageNet數據集中提取出與PASCAL VOC數據集相同的20種類別的圖像組成的預訓練圖像集,并結合PASCAL VOC 2007和2012的trainval訓練驗證集(共16 551張圖像)作為本算法的訓練集。通過隨意翻轉、隨機縮放、任意裁剪和色彩抖動等方法,對訓練集進行數據增強。測試集采用PASCAL VOC 2007的測試集。
2.2.2 評價指標
參數量(params):表示模型中的參數數量,用于反映模型規格。
浮點運算次數(Floating Point Operations,FLOPs):表示網絡計算量,用于衡量模型的時間復雜度。
精準度(accuracy):表示模型對圖像分類的精準程度。
平均精度(Average Precision,AP):用于評價模型對單個類別的檢測結果,綜合地反映目標檢測模型的性能。
平均精度均值(mean Average Precision,mAP):用于評價模型對存在多個類別的目標的檢測效果。
每秒幀數(Frame Per Second,FPS):用于評價目標網絡每秒可以處理(檢測)多少幀(多少張圖片)。
2.3 LT-CNN模型實驗結果及分析
LT-CNN與CenterNet-ResNet101的對比實驗結果見表1。
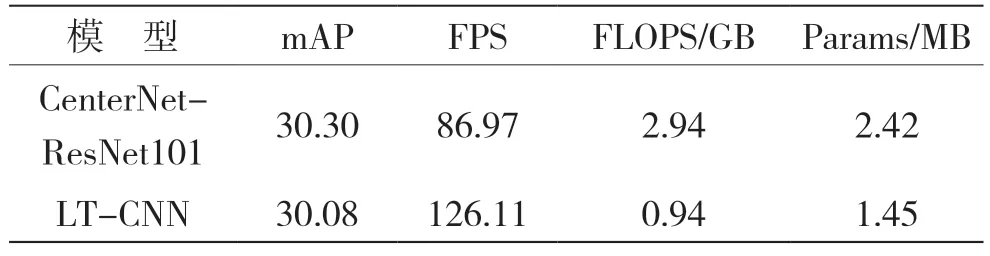
表1 對比實驗結果
利用LT-CNN模型對無錨框目標檢測算法CenterNet的主干網絡進行通道剪枝,對剪枝后的算法在PASCAL VOC數據集上進行實驗驗證,結果發現,剪枝后的CenterNet-ResNet101在mAP僅損失0.7%的情況下,FPS提升了45.0%,參數量減少了40.0%,計算量降低了40.0%,表明LT-CNN模型算法可以有效提高無錨框目標檢測算法的檢測速度,減少計算量和資源消耗。
3 結語
本文所設計的LT-CNN模型,通過在結構中引入attention機制,采用分組卷積與快速卷積結構使模型推理速度加快,并通過知識蒸餾學習當前SOTA目標檢測模型Fast的目標檢測能力,最后通過后統計量化方法將推理模型進一步壓縮提速,實現了面向Nano無人車嵌入式平臺的輕量級卷積神經網絡壓縮加速方法。模型不僅在無人車上具備保持大型目標檢測網絡檢測精度的能力,而且也達到了高精度實時運行的能力。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
